GitCode热门开源项目推荐:Spider网络爬虫框架
在数字化高速发展时代,数据已成为企业决策和个人研究的重要资源。网络爬虫作为一种强大的数据采集工具受到了广泛的关注和应用。在GitCode这一优秀的开源平台上,Spider网络爬虫框架凭借其简洁、高效和易用性,成为了众多开发者的首选。

一、系统基本介绍
Spider是一个轻量级的网络爬虫框架,由Python语言编写,旨在帮助开发者快速构建复杂的爬虫系统,从网页中提取所需的数据。无论是用于数据分析、信息监控还是自动化任务,Spider都能提供强大的支持。该项目拥有简洁的API和高效的爬取能力,既适合初学者快速上手,也满足有经验开发者的定制需求。系统可以实现下列相关功能:
- 定时去检查网站的某页面或某几个页面,获取此时发布的信息,并与数据库中的数据对比,如果检测到新发布的信息,则将其加入数据库中,并通过微信公众号进行自动发布;
- 可以实现关键词过滤功能,检查发布信息标题及内容页是否有指定关键词,如果没有的话忽略此信息;
- 实现了一个相对比较通用的程序架构,可以很方便的向其中添加新网站。
二、系统技术特点
- 简洁易用:Spider提供了丰富的文档和示例代码,帮助开发者快速理解并掌握框架的使用方法。同时,其简洁的API设计使得开发者能够轻松构建自己的爬虫系统。
- 高效稳定:Spider采用异步IO和事件驱动的方式,实现了高效的网页爬取。同时,框架内部进行了大量的优化和测试,确保了爬虫的稳定性和可靠性。
- 灵活可定制:Spider支持多种爬虫策略和数据解析方式,开发者可以根据自己的需求进行灵活定制。此外,框架还提供了丰富的扩展接口,方便开发者集成其他工具和库。
三、系统使用方法
Python版本:Python 3.4 & Python 3.5测试通过,不兼容Python 2.x
依赖包:requests、beautifulsoup4
运行前需要将微信的corpid及corpsecret写入wchat文件中,此文件为文本文件,第一行是corpid,第二行是corpsecret,将此文件置于根目录下再运行Spider.py文件即可。
目前程序中检测的网站是按照我目前的需求添加的,可根据需要进行修改。2.1 添加新网站
复制Template.py文件,在此模板的基础上进行修改即可。
1.类名改为需要的名字
2.__init__(self, Name, DBName, AgentID, KeyWords)
子类的构造函数中调用了基类的构造函数,基类构造函数的参数说明如下:
# Name:网站名称
# DBName:数据库名称,不要包含后缀
# AgentID:微信发布时需要用到的AgentID
# CheckContent:是否需要打开URL检查内容,True or False
# KeyWords:过滤用关键词List,如果不需要设置为[]
# KeyWordsThreshold:关键词阈值,内容页包含的关键词个数超过这个值才认为符合要求
# encoding:网站的编码格式,不设置的话默认为utf-8
__init__(self, Name, DBName, AgentID, CheckContent, KeyWords, KeyWordsThreshold, encoding = 'utf-8')
此构造函数的输入参数根据具体网站确定,可以一个参数都不用传入,全部固定下来,也可以添加一些其他需要的参数。
3.GetPageRange(self)
需要返回一个List,这个List中包含了需要采集的子页面的信息,可以是一些固定的字符串,也可以是一个range。如果只有一个页面,此处返回range(1)即可。
4.GetMainPage(self, page)
返回需要监测的页面,返回结果是由requests.get()方法返回的response对象。输入参数中的page就是之前GetPageRange(self)函数中返回的List中的元素,在需要监测多个页面的情况下根据此参数返回对应的页面即可。
5.GetEnclose(self, soup)
返回感兴趣的页面范围,输入参数soup是根据之前获取到的页面创建的beautifulsoup对象,此处也要返回一个beautifulsoup对象。最常见的情况是选取原始soup中的一个标签返回,如:
return soup.find('table')
如果不需要进行范围缩小,直接返回传入的soup即可。
6.GetTags(self, soup)
返回tag List,其中每一个元素都是一个tag,对应一条消息记录。此List一般通过soup.find_all()方法获得,不过某些情况下也需要手工生成,可以使用soup.contents等方法进行遍历后生成。
7.GetTitle(self, tag)
输入参数为一条消息记录对应的tag,需要从中找出标题信息并返回string,必须要返回一个string。
8.GetURL(self, tag)
输入参数为一条消息记录对应的tag,需要从中找出URL信息并返回string,可以返回''。
9.GetPublishTime(self, tag)
输入参数为一条消息记录对应的tag,需要从中找出发布日期信息并返回string,可以返回''。
10.AdditionCheck(self, tag)
输入参数为一条消息记录对应的tag,可对其进行一些额外的检查工作来判断此条消息是否是需要的消息,如果是需要的符合要求的消息则返回True,否则返回False。如果不需要判断直接返回True。
11.GetBrief(self, tag, keywordstring)
输入参数为一条消息记录对应的tag,之前关键词过滤结果keywordstring。如果进行了关键词过滤,keywordstring的格式类似于*** 关键词:关键词1;关键词2;,如果没有进行关键词过滤,keywordstring为空。需要返回的是消息的摘要信息,如果不需要的话直接返回''即可。
按上述方法添加好了网站子类后在Spider.py文件中实例化一个对象,并将其添加到WebList中即可。三、系统部分代码解析
以下是一个简单的Spider爬虫示例代码,用于从指定网页中提取标题和链接:
# 导入Spider框架
from spider import Spider # 定义一个名为MySpider的爬虫类,继承自Spider框架的基类
class MySpider(Spider): # 设置爬虫的名称 name = 'my_spider' # 设置允许爬取的域名列表 allowed_domains = ['example.com'] # 设置起始URL列表 start_urls = ['http://example.com/'] # 定义解析网页内容的函数 def parse(self, response): # 从网页中提取所有的h1标签的文本内容作为标题 for title in response.css('h1::text'): # 使用yield关键字返回提取到的标题数据,以字典形式组织 yield {'title': title.get()} # 从网页中提取所有的a标签的href属性值作为链接 for link in response.css('a::attr(href)').getall(): # 判断链接是否属于允许的域名范围 if link.startswith('http://example.com/'): # 如果属于,则发起新的请求,并指定回调函数为parse(即递归爬取) yield self.request(url=link, callback=self.parse) if __name__ == '__main__': # 创建MySpider的实例 spider = MySpider() # 调用start方法开始爬取 spider.start()在上面的代码中,我们首先定义了一个名为MySpider的爬虫类,该类继承了Spider框架的基类。然后,我们设置了爬虫的名称、允许爬取的域名和起始URL。在parse方法中,我们定义了如何解析网页内容并提取所需的数据。最后,我们创建了一个MySpider的实例并调用其start方法开始爬取。
四、项目访问地址
如果你对Spider网络爬虫框架感兴趣或者想进一步了解和使用它,请访问以下Gitcode地址:
Spider网络爬虫框架 Gitcode地址
Spider网络爬虫框架凭借其简洁、高效和易用性,成为了Gitcode平台上的热门开源项目。通过学习和使用Spider,你将能够轻松构建自己的爬虫系统,从网页中提取所需的数据,为自己的工作和研究提供有力的支持。
相关文章:
GitCode热门开源项目推荐:Spider网络爬虫框架
在数字化高速发展时代,数据已成为企业决策和个人研究的重要资源。网络爬虫作为一种强大的数据采集工具受到了广泛的关注和应用。在GitCode这一优秀的开源平台上,Spider网络爬虫框架凭借其简洁、高效和易用性,成为了众多开发者的首选。 一、系…...

实现一个二叉树的前序遍历、中序遍历和后序遍历方法。
package test3;public class Test_A27 {// 前序遍历(根-左-右)public void preOrderTraversal(TreeNode root){if(rootnull){return;}System.out.println(root.val"");preOrderTraversal(root.left);preOrderTraversal(root.right);}// 中序遍…...
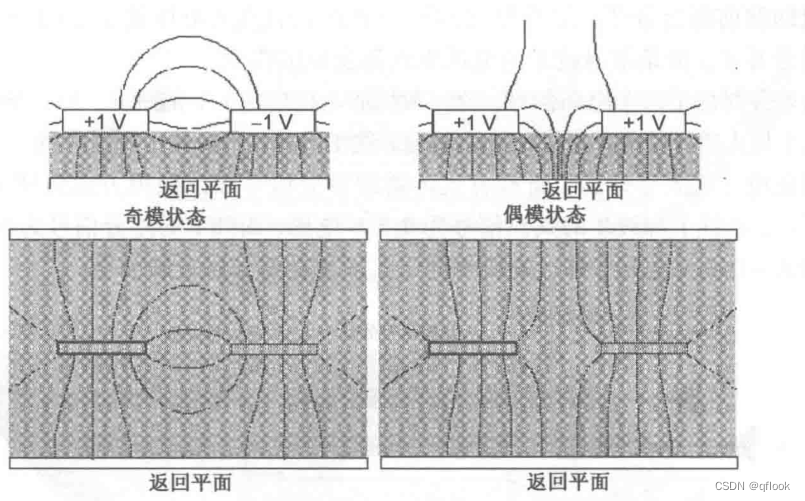
串扰(二)
三、感性串扰 首先看下串扰模型及电流方向: 由于电感是阻碍电流变化,受害线的电流方向和攻击线的电流方向相反。同时由于受害线阻抗均匀,故有Vb-Vf(感应电流属于电池内部电流)。 分析感性串扰大小仍然是按微分的方法…...
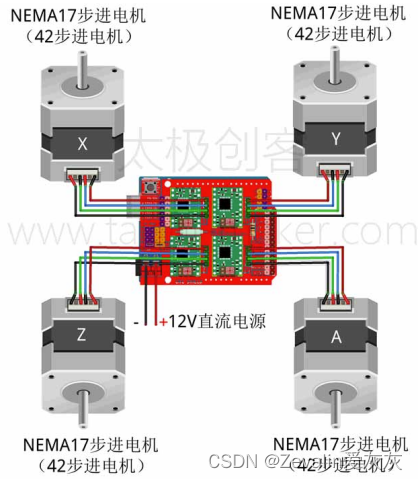
零基础入门学用Arduino 第四部分(三)
重要的内容写在前面: 该系列是以up主太极创客的零基础入门学用Arduino教程为基础制作的学习笔记。个人把这个教程学完之后,整体感觉是很好的,如果有条件的可以先学习一些相关课程,学起来会更加轻松,相关课程有数字电路…...

Mp3文件结构全解析(一)
Mp3文件结构全解析(一) MP3 文件是由帧(frame)构成的,帧是MP3 文件最小的组成单位。MP3的全称应为MPEG1 Layer-3 音频 文件,MPEG(Moving Picture Experts Group) 在汉语中译为活动图像专家组,特指活动影音压缩标准,MPEG 音频文件…...

ES 8.14 Java 代码调用,增加knnSearch 和 混合检索 mixSearch
1、pom依赖 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>8.14.0</version></dependency><dependency><groupId>co.elastic.clients<…...

被腰斩的颍川郡守赵广汉
在颍川,他发明了举报箱,铁腕扫黑除恶。因为曾经在郡府所在地阳翟(禹州)当过县令,熟悉颍川社情民意,所以,任职郡守后雷厉风行,才不到一年,不但制服了骄横的豪门大族&#…...
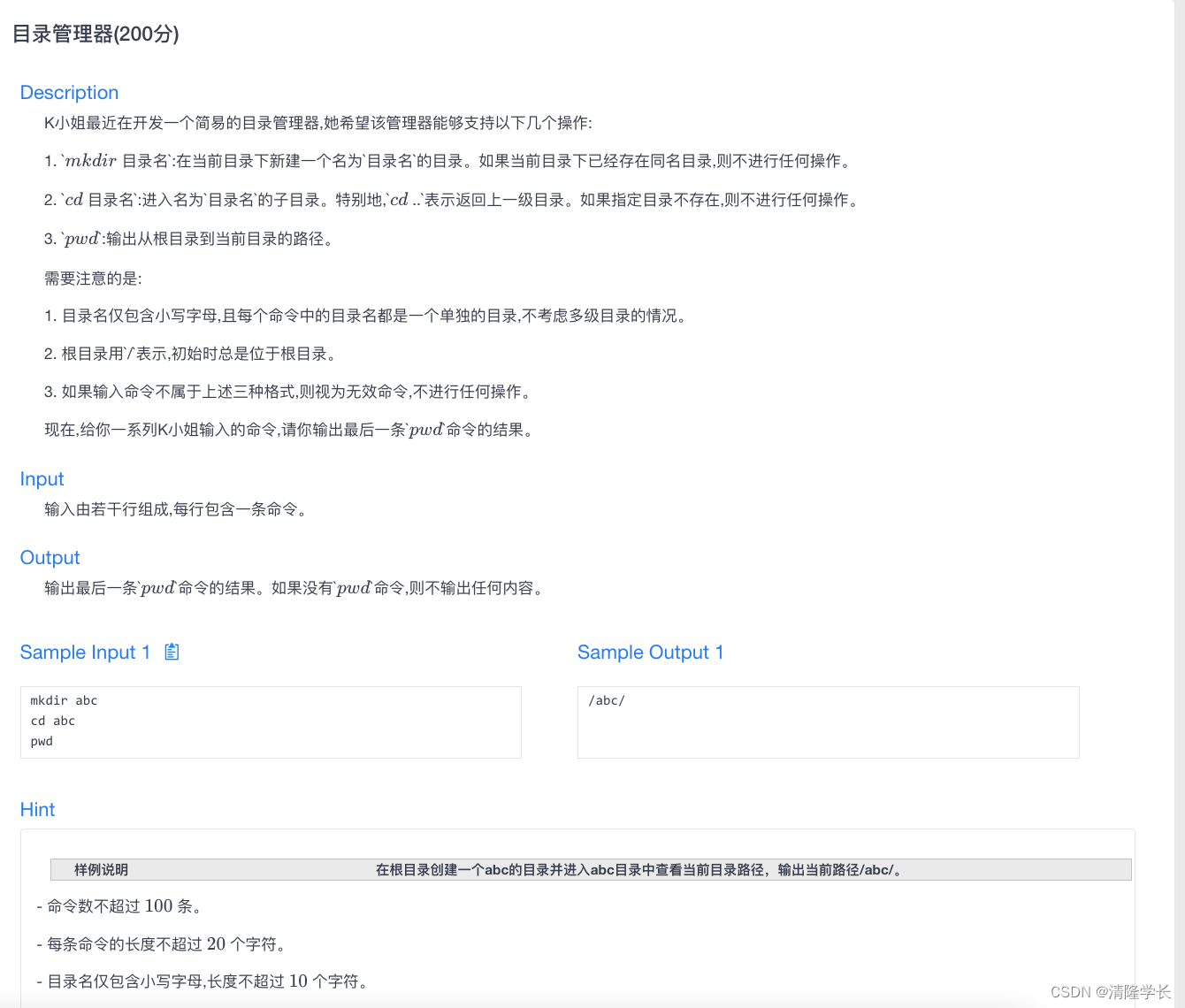
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 目录管理器(200分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 📎在线评测链接 目录管理器(200分) 🌍 评测功能需要订阅专栏后私信联系清隆…...

关于自学\跳槽\转行做网络安全行业的一些建议
很好,如果你是被题目吸引过来的,那请看完再走,还是有的~ 为什么写这篇文章 如何自学入行?如何小白跳槽,年纪大了如何转行等类似问题 ,发现很多人都有这样的困惑。下面的文字其实是我以前的一个回答&#…...

计算机网络(1) OSI七层模型与TCP/IP四层模型
一.OSI七层模型 OSI 七层模型是国际标准化组织ISO提出的一个网络分层模型,它的目的是使各种不同的计算机和网络在世界范围内按照相同的标准框架实现互联。OSI 模型把网络通信的工作分为 7 层,从下到上分别是物理层、数据链路层、网络层、传输层、会话层、…...

认识QML
为什么使用Qt Quick? Qt4的设计用于满足开发者在主流桌面操作系统上有一套表现一致的窗口组件可以 使用。如今Qt的使用者面临了新的问题,他们需要提供可触碰交互的用户界面以满 足软件界面需求,并在主流桌面操作系统和移动操作系统上实现这些…...

llama-factory微调chatglm3
一、定义 案例/多卡 二、实现 案例 1. 下载chatglm3-6b-32k模型 2. 配置数据集微调指令 CUDA_VISIBLE_DEVICES0,1 llamafactory-cli train \--stage sft \--do_train True \--model_name_or_path /home/chatglm3-6b-32k \--finetuning_type lora \--template chatglm3 \--d…...

大文件上传实现
分片上传 将大文件分割成多个小片(chunk),逐个上传。每个片上传成功后,服务器可以返回确认信息。所有片上传完成后,服务器端将这些片重新组合成原始文件。 以下是一个简单的分片上传的前端实现示例: func…...
为何Proteus用户争相拥抱SmartEDA?揭秘背后的强大吸引力!
在电路设计与仿真领域,Proteus一度以其稳定性能和丰富功能赢得了众多用户的青睐。然而,近年来,越来越多的Proteus用户开始转向SmartEDA,这一新兴电路仿真软件正迅速崭露头角,成为行业内的翘楚。那么,究竟是…...
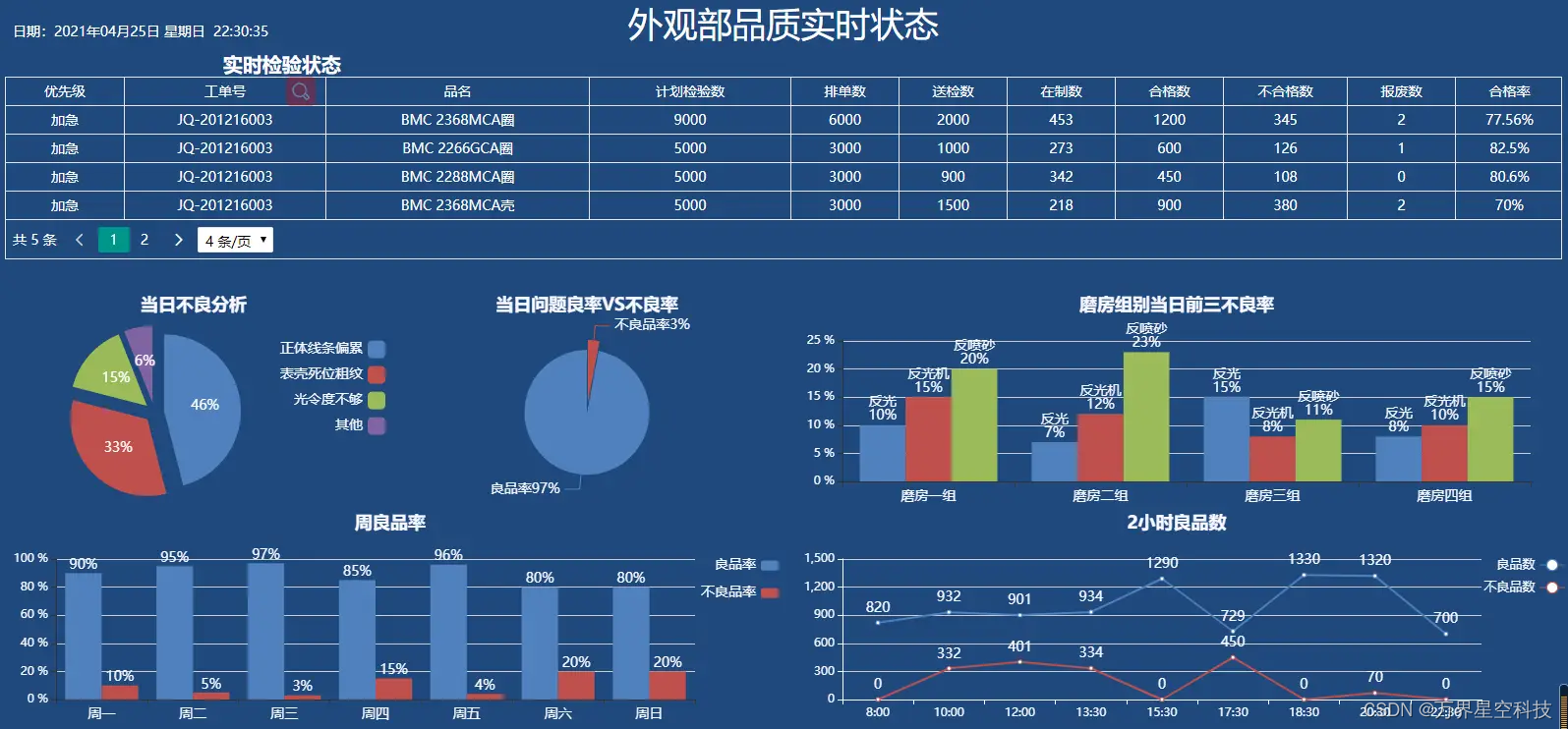
万界星空科技QMS质量管理介绍
产品的生产质量是企业发展之根本,对所有企业来说,建立完善质量控制体系,对企业生产经营以及发展竞争具有至关重要的影响,可以说是企业质量保证的防火墙。QMS质量管理系统对任何一家企业都具有重要意义,可帮助企业提高生…...

神经网络 torch.nn---nn.LSTM()
torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io) LSTM — PyTorch 2.3 documentation LSTM层的作用 LSTM层:长短时记忆网络层,它的主要作用是对输入序列进行处理,对序列中的每个元素进行编码并保存它们的状态,以便后续的处理。 …...

Web前端JSP软件:深度解析与探索之旅
Web前端JSP软件:深度解析与探索之旅 在当今数字化时代,Web前端技术日新月异,JSP(Java Server Pages)软件作为其中的佼佼者,扮演着举足轻重的角色。本文将从四个方面、五个方面、六个方面和七个方面&#x…...

人生的乐趣,在于对真知的追求
子曰:朝闻道,夕死可矣! 孔子说:早上听到关于世界的真理,哪怕晚上就die了都可以。 这句话很有力量而经常被人引用,表达出我们如何看待沉重的肉身和精神世界。 我们的生活目的:道。 —— 要了解…...

IPython大揭秘:神奇技巧让你掌握无敌编程力量!
IPython技巧 基础技巧文件操作技巧输入输出技巧魔术命令技巧调试技巧程序性能优化技巧输入输出重定向技巧魔术命令控制技巧自定义显示格式技巧多线程多进程技巧异常处理技巧数据可视化技巧自定义魔术命令技巧安装扩展包技巧Jupyter Notebook集成技巧文档显示技巧代码块执行技巧…...

逻辑卷管理器 (LVM) 简介
古老的 e5 主机目前有这些存储设备 (硬盘): 系统盘 (M.2 NVMe SSD 480GB), 数据盘 (3.5 英寸 SATA 硬盘 4TB x2). 窝决定使用 LVM 对数据盘进行管理. 逻辑卷管理器 (LVM) 可以认为是一种 (单机) 存储虚拟化 技术. 多个物理存储设备 (PV) 组成一个存储池 (VG), 然后划分虚拟分区…...

别再死记硬背了!我用700多页图解八股文,帮你把Java面试考点画成故事
用视觉叙事重构Java面试:700页图解背后的认知科学实践 翻开任何一本Java面试指南,你大概率会看到密密麻麻的文字罗列——"JVM内存结构分为哪几部分?""Synchronized和ReentrantLock有什么区别?"这些被称为&quo…...

Qwerty Learner:终极打字练习与单词记忆完全指南
Qwerty Learner:终极打字练习与单词记忆完全指南 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https://gitcode.…...

基于ReAct范式的链式追踪工具:提升学术研究效率的AI智能体实践
1. 项目概述与核心价值如果你经常需要做文献调研、追踪某个科学概念的源头,或者想搞清楚一个复杂话题背后的证据链,那你一定体会过在搜索引擎和无数个学术网站之间反复横跳的痛苦。传统的搜索方式,比如在Google Scholar里输入一个关键词&…...

JoyCon-Driver:让Switch手柄在Windows上重获新生的完整方案
JoyCon-Driver:让Switch手柄在Windows上重获新生的完整方案 【免费下载链接】JoyCon-Driver A vJoy feeder for the Nintendo Switch JoyCons and Pro Controller 项目地址: https://gitcode.com/gh_mirrors/jo/JoyCon-Driver 你是否曾经想过,让闲…...

如何轻松获取九大网盘直链下载地址:LinkSwift完整使用指南
如何轻松获取九大网盘直链下载地址:LinkSwift完整使用指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...

Halcon实战:高效遍历指定文件夹图像文件的两种核心方案
1. 工业视觉项目中的图像读取痛点 在工业视觉检测项目中,我们经常需要处理大量存储在本地文件夹中的图像文件。这些文件可能来自产线相机拍摄的产品照片、X光检测图像或是其他光学设备生成的图片。实际项目中,图像文件的命名往往不规范,格式…...
搭建免费工业数据模拟环境)
告别付费!手把手教你用Matrikon OPC Server Simulation(v1.7.2)搭建免费工业数据模拟环境
零成本构建工业数据模拟环境:Matrikon OPC Server Simulation全攻略 在工业自动化领域,数据采集与监控系统(SCADA)的开发与测试往往需要真实的OPC服务器环境。然而,商业OPC服务器的高昂成本常常成为初学者和小型团队的…...

NoFences:彻底告别混乱桌面的免费开源分区神器
NoFences:彻底告别混乱桌面的免费开源分区神器 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天面对杂乱无章的Windows桌面感到焦虑?在几十个…...

A*搜索算法原理与工业级优化实践
1. A*搜索算法核心原理与工程实现A搜索算法作为路径规划领域的经典算法,其核心优势在于将Dijkstra算法的完备性与贪心算法的高效性相结合。在实际工程项目中,我经常使用A来解决各类移动机器人的导航问题,它的表现始终稳定可靠。1.1 算法核心三…...

混排稿交上去,最怕字数对不上
混排稿交上去,最怕字数对不上 限 5000 字,Word 里一个数,网页后台又一个数,翻译那边还跟你聊「按字符」——挺正常的,不是谁刁难,是各家数「字」的法子本来就不一样。 先打开这个: https://ge…...