executor行为相关Spark sql参数源码分析
0、前言
| 参数名和默认值 |
|---|
| spark.default.parallelism=Default number of partitions in RDDs |
| spark.executor.cores=1 in YARN mode 一般默认值 |
| spark.files.maxPartitionBytes=134217728(128M) |
| spark.files.openCostInBytes=4194304 (4 MiB) |
| spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=1 不同版本算法task提交数据 |
【重点】在spark sql中有对应参数为:
spark.sql.files.maxPartitionBytes=134217728(128M) 本次重点源码分析
spark.sql.files.openCostInBytes=4194304 (4 MiB) 本次重点源码分析
spark.default.parallelism = math.max(totalCoreCount.get(), 2)
对应源码位置如下:
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend#defaultParallelism
org.apache.spark.sql.internal.SQLConf#FILES_MAX_PARTITION_BYTES
org.apache.spark.sql.internal.SQLConf#FILES_OPEN_COST_IN_BYTES
1、 环境准备
create database bicoredata;CREATE TABLE bicoredata.dwd_start_log_dm(
`device_id` string,
`area` string,
`uid` string,
`app_v` string,
`event_type` string,
`os_type` string,
`channel` string,
`language` string,
`brand` string,
`entry` string,
`action` string,
`error_code` string
)
comment 'dwd用户启动日志信息'
partitioned by (`dt` string)
stored as orc
tblproperties("orc.compress"="ZLIB")
location '/bicoredata/dwd_start_log_dm';-- 解析ods日志到dwd表insert overwrite table bicoredata.dwd_start_log_dm
partition(dt='20220721')
select get_json_object(line, '$.attr.device_id'),
get_json_object(line, '$.attr.area'),
get_json_object(line, '$.attr.uid'),
get_json_object(line, '$.attr.app_v'),
get_json_object(line, '$.attr.event_type'),
get_json_object(line, '$.attr.os_type'),
get_json_object(line, '$.attr.channel'),
get_json_object(line, '$.attr.language'),
get_json_object(line, '$.attr.brand'),
get_json_object(line, '$.app_active.json.entry'),
get_json_object(line, '$.app_active.json.action'),
get_json_object(line, '$.app_active.json.error_code')
from
(
select split(str, ' ')[7] as line
from biods.ods_start_log
where dt='20220721'
)t
2、 代码准备
package org.example.sparksqlimport org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSessionobject SparkSqlHive {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")// 动态分配参数必须 在 yarn环境下才能生效,client/clusterval ss = SparkSession.builder().master("yarn").appName("the test of SparkSession").config("spark.deploy.mode","cluster").config("yarn.resourcemanager.hostname", "hadoop2")// 注意只有设置为true,才是文件读取算子,否则是表读取算子。.config("spark.sql.hive.convertMetastoreOrc", "true").config("spark.sql.files.maxPartitionBytes","34008864") //注意不是spark.files.maxPartitionBytes.config("spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version","2").config("spark.dynamicAllocation.enabled","true").config("spark.shuffle.service.enabled","true").config("spark.driver.host","192.168.150.1").enableHiveSupport().getOrCreate()ss.sql("DROP TABLE IF EXISTS temp.temp_ods_start_log");val df = ss.sql("insert overwrite table bicoredata.dwd_start_log_dm " +"partition(dt='20210721') " +"select get_json_object(line, '$.attr.device_id')," +"get_json_object(line, '$.attr.area')," +"get_json_object(line, '$.attr.uid')," +"get_json_object(line, '$.attr.app_v')," +"get_json_object(line, '$.attr.event_type')," +"get_json_object(line, '$.attr.os_type')," +"get_json_object(line, '$.attr.channel')," +"get_json_object(line, '$.attr.language')," +"get_json_object(line, '$.attr.brand')," +"get_json_object(line, '$.app_active.json.entry')," +"get_json_object(line, '$.app_active.json.action')," +"get_json_object(line, '$.app_active.json.error_code') " +"from " +"(" +"select split(str, ' ')[7] as line " +"from biods.ods_start_log " +"where dt='20210721'" +")t")Thread.sleep(1000000)ss.stop()}
}输入:
hdfs中该日期分区存有2个文件,大小分别为245M和94M

输出:
最终结果分区中,有6个文件。

可见缩小spark.sql.files.maxPartitionBytes值,增大了读取task数量。
3 、源码分析
3.1 、物理执行计划如下
Execute InsertIntoHadoopFsRelationCommand hdfs://hadoop1:9000/bicoredata/dwd_start_log_dm, Map(dt -> 20210721), false, [dt#55], ORC, Map(orc.compress -> ZLIB, serialization.format -> 1, partitionOverwriteMode -> dynamic), Overwrite, CatalogTable(
Database: bicoredata
Table: dwd_start_log_dm
Owner: root
Created Time: Sun Dec 11 17:47:33 CST 2022
Last Access: UNKNOWN
Created By: Spark 2.2 or prior
Type: MANAGED
Provider: hive
Comment: dwd????????
Table Properties: [orc.compress=ZLIB, transient_lastDdlTime=1670752053]
Location: hdfs://hadoop1:9000/bicoredata/dwd_start_log_dm
Serde Library: org.apache.hadoop.hive.ql.io.orc.OrcSerde
InputFormat: org.apache.hadoop.hive.ql.io.orc.OrcInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat
Storage Properties: [serialization.format=1]
Partition Provider: Catalog
Partition Columns: [`dt`]
Schema: root|-- device_id: string (nullable = true)|-- area: string (nullable = true)|-- uid: string (nullable = true)|-- app_v: string (nullable = true)|-- event_type: string (nullable = true)|-- os_type: string (nullable = true)|-- channel: string (nullable = true)|-- language: string (nullable = true)|-- brand: string (nullable = true)|-- entry: string (nullable = true)|-- action: string (nullable = true)|-- error_code: string (nullable = true)|-- dt: string (nullable = true)
), org.apache.spark.sql.execution.datasources.CatalogFileIndex@df5f9368, [device_id, area, uid, app_v, event_type, os_type, channel, language, brand, entry, action, error_code, dt]
+- Project [ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.device_id) as string) AS device_id#43, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.area) as string) AS area#44, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.uid) as string) AS uid#45, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.app_v) as string) AS app_v#46, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.event_type) as string) AS event_type#47, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.os_type) as string) AS os_type#48, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.channel) as string) AS channel#49, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.language) as string) AS language#50, ansi_cast(get_json_object(split(str#1, , -1)[7], $.attr.brand) as string) AS brand#51, ansi_cast(get_json_object(split(str#1, , -1)[7], $.app_active.json.entry) as string) AS entry#52, ansi_cast(get_json_object(split(str#1, , -1)[7], $.app_active.json.action) as string) AS action#53, ansi_cast(get_json_object(split(str#1, , -1)[7], $.app_active.json.error_code) as string) AS error_code#54, 20210721 AS dt#55]+- *(1) ColumnarToRow+- FileScan orc biods.ods_start_log[str#1,dt#2] Batched: true, DataFilters: [], Format: ORC, Location: InMemoryFileIndex[hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721], PartitionFilters: [isnotnull(dt#2), (dt#2 = 20210721)], PushedFilters: [], ReadSchema: struct<str:string>
如上所示,本质上分三部分:
(1)读取表
FileScan orc biods.ods_start_log
(2)转换
Project [ansi_cast(get_json_object(split(str#1, , -1)[7]
(3)写入目标表
Execute InsertIntoHadoopFsRelationCommand
3.2 、FileScan和InsertIntoHadoopFsRelationCommand 算子
从InsertIntoHadoopFsRelationCommand 开始源码分析如下:
org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand#run
org.apache.spark.sql.execution.datasources.FileFormatWriter$#write
org.apache.spark.sql.execution.FileSourceScanExec#inputRDD
FileSourceScanExec#createNonBucketedReadRDD
org.apache.spark.sql.execution.FileSourceScanExec#createNonBucketedReadRDD
首次出现3个相关参数
private def createNonBucketedReadRDD(readFile: (PartitionedFile) => Iterator[InternalRow],selectedPartitions: Array[PartitionDirectory],fsRelation: HadoopFsRelation): RDD[InternalRow] = {// 对应spark.sql.files.openCostInBytes 参数 val openCostInBytes = fsRelation.sparkSession.sessionState.conf.filesOpenCostInBytes// 基于3个参数计算出来val maxSplitBytes =FilePartition.maxSplitBytes(fsRelation.sparkSession, selectedPartitions)logInfo(s"Planning scan with bin packing, max size: $maxSplitBytes bytes, " +s"open cost is considered as scanning $openCostInBytes bytes.")// 逻辑分割orc文件,返回分区的文件对象PartitionedFileval splitFiles = selectedPartitions.flatMap { partition =>partition.files.flatMap { file =>// getPath() is very expensive so we only want to call it once in this block:val filePath = file.getPath// orc文件是可以分割的,对应org.apache.spark.sql.hive.orc.OrcFileFormat#isSplitable函数,返回trueval isSplitable = relation.fileFormat.isSplitable(relation.sparkSession, relation.options, filePath)PartitionedFileUtil.splitFiles(sparkSession = relation.sparkSession,file = file,filePath = filePath,isSplitable = isSplitable,maxSplitBytes = maxSplitBytes,partitionValues = partition.values)}}.sortBy(_.length)(implicitly[Ordering[Long]].reverse)// 基于分区文件对象,最大分割尺寸,返回文件分区FilePartition对象(逻辑层面)val partitions =FilePartition.getFilePartitions(relation.sparkSession, splitFiles, maxSplitBytes)// 返回rddnew FileScanRDD(fsRelation.sparkSession, readFile, partitions)
}
FilePartition和PartitionedFile区别(1)FilePartition对象:会被单个任务读取的PartitionedFile集合
对应源码在 org.apache.spark.sql.execution.datasources.FilePartition
--》特点是,一个FilePartition对应1个task(2)PartitionedFile对象:用于读取的单个文件的部分,包含文件路径,开始偏移量,读取长度偏移量
-->特点是,一个PartitionedFile对应1个文件的部分,有对应的开始偏移量和读取偏移量
FilePartition#maxSplitBytes
org.apache.spark.sql.execution.datasources.FilePartition#maxSplitBytes
综合以上3个关键参数,计算出最大分割大小。
def maxSplitBytes(sparkSession: SparkSession,selectedPartitions: Seq[PartitionDirectory]): Long = {// 对应 spark.sql.files.maxPartitionBytes 参数,默认128Mval defaultMaxSplitBytes = sparkSession.sessionState.conf.filesMaxPartitionBytes// 对应spark.sql.files.openCostInBytes 参数 ,默认4Mval openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes// 对应 spark.default.parallelism参数,默认应该会取到2(yarn cluster集群默认环境下测试结果)val defaultParallelism = sparkSession.sparkContext.defaultParallelismval totalBytes = selectedPartitions.flatMap(_.files.map(_.getLen + openCostInBytes)).sumval bytesPerCore = totalBytes / defaultParallelismMath.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
}
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend#defaultParallelism
override def defaultParallelism(): Int = {conf.getInt("spark.default.parallelism", math.max(totalCoreCount.get(), 2))
}
PartitionedFileUtil#splitFiles
org.apache.spark.sql.execution.PartitionedFileUtil#splitFiles
def splitFiles(sparkSession: SparkSession,file: FileStatus,filePath: Path,isSplitable: Boolean,maxSplitBytes: Long,partitionValues: InternalRow): Seq[PartitionedFile] = {if (isSplitable) {(0L until file.getLen by maxSplitBytes).map { offset =>val remaining = file.getLen - offsetval size = if (remaining > maxSplitBytes) maxSplitBytes else remainingval hosts = getBlockHosts(getBlockLocations(file), offset, size)// 基于偏移量,size构造分区file对象PartitionedFile(partitionValues, filePath.toUri.toString, offset, size, hosts)}} else {Seq(getPartitionedFile(file, filePath, partitionValues))}
}
逻辑分割结果,11个文件,降序排列:
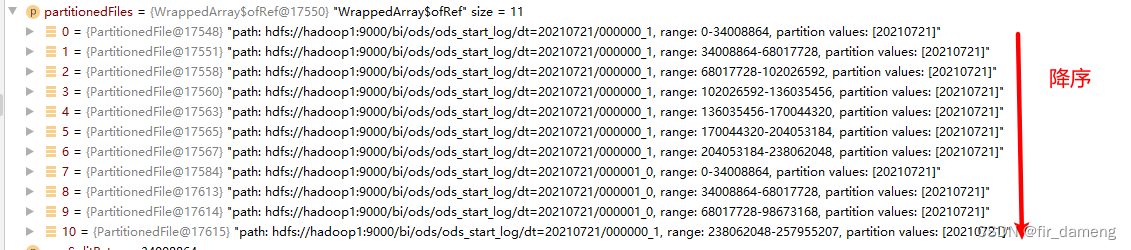
FilePartition#getFilePartitions
org.apache.spark.sql.execution.datasources.FilePartition#getFilePartitions
def getFilePartitions(sparkSession: SparkSession,partitionedFiles: Seq[PartitionedFile],maxSplitBytes: Long): Seq[FilePartition] = {val partitions = new ArrayBuffer[FilePartition]val currentFiles = new ArrayBuffer[PartitionedFile]var currentSize = 0L/** Close the current partition and move to the next. */def closePartition(): Unit = {if (currentFiles.nonEmpty) {// 将PartitionedFile文件数组封装成1个FilePartition对象val newPartition = FilePartition(partitions.size, currentFiles.toArray)partitions += newPartition}currentFiles.clear()currentSize = 0}val openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes// Assign files to partitions using "Next Fit Decreasing"partitionedFiles.foreach { file =>if (currentSize + file.length > maxSplitBytes) {closePartition()}// Add the given file to the current partition.currentSize += file.length + openCostInBytescurrentFiles += file}// 处理最后1个分区文件closePartition()partitions
}
总体调用流程
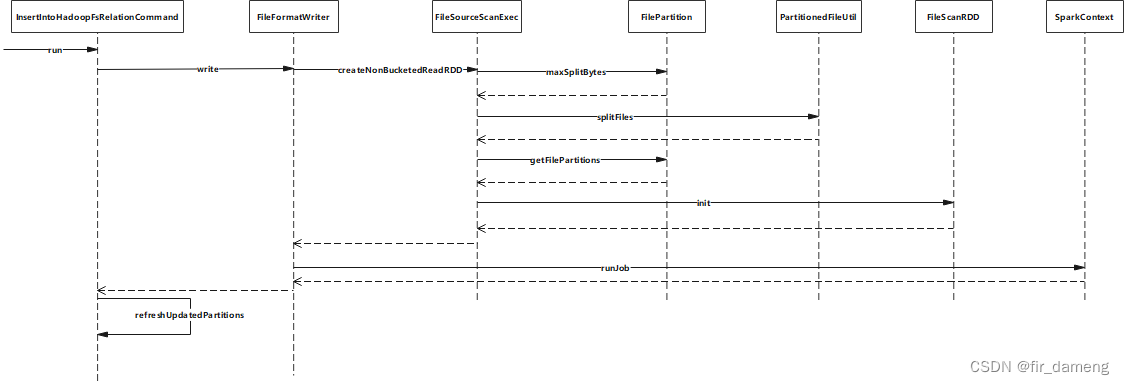
InsertIntoHadoopFsRelationCommand为物理逻辑计划的最后1个算子,其run方法,包含写入数据和更新元数据过程;其中写入数据又包含生成FileScanRDD(11个分区)和提交job过程。
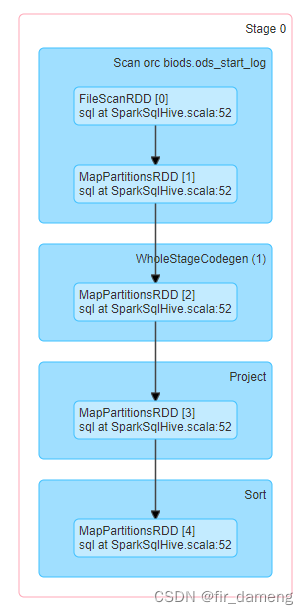
stage0的初始rdd,即为FileScanRDD。
由于FileScanRDD包含11个FilePartition,所以 最终生成11个task
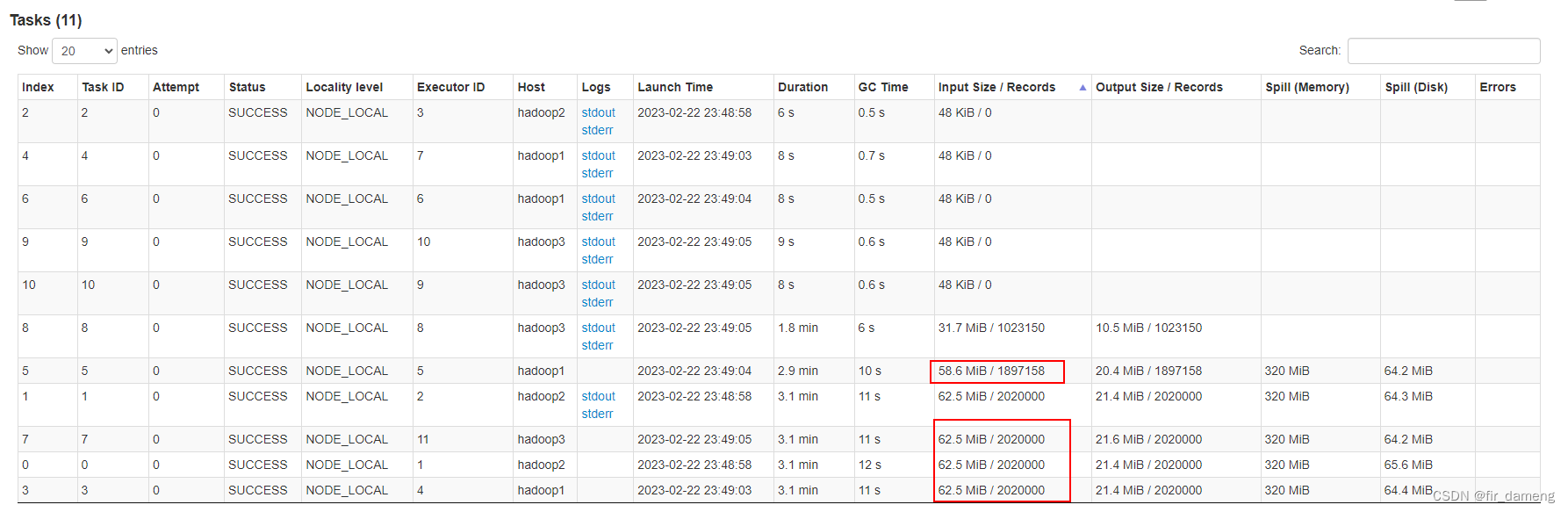
4、疑问
4.1、预期11 个task 大小均匀分布 32M左右,但为什么实际存在一些task空跑,其他task输入大小为62M多?
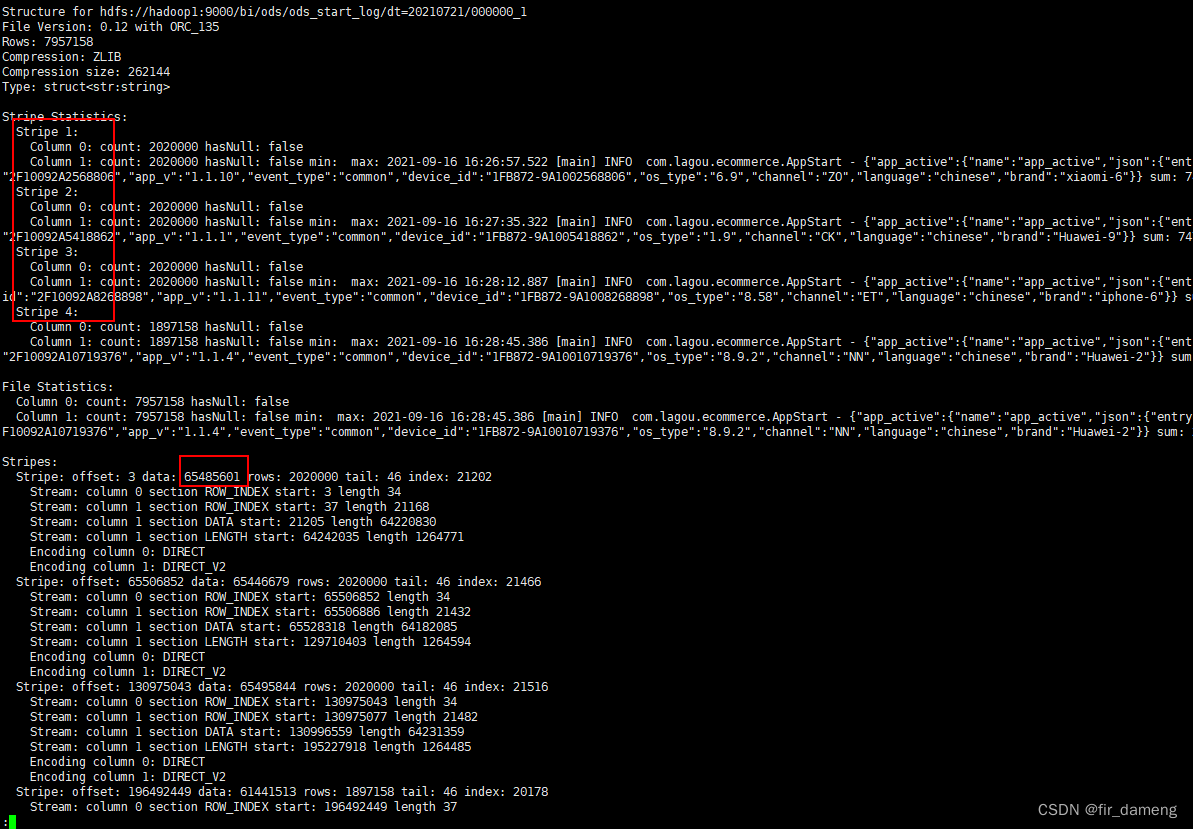
经了解发现,以hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000000_1orc文件为例,其由4个stripe组成,大小刚好为62.5M,62.5M,62.5M,58.6M,且不可分割,这就与task中大小和数量不谋而合。
orc原理参考: https://www.jianshu.com/p/0ba4f5c3f113
查看orc文件的stripe个数等信息
hive --orcfiledump hdfs://hadoop1:9000/bi/ods/ods_start_log/dt=20210721/000001_0 | less
结果如下
4.2、测试sql中不涉及join,group by等shuffle操作,为什么会溢出到内存,甚至磁盘?
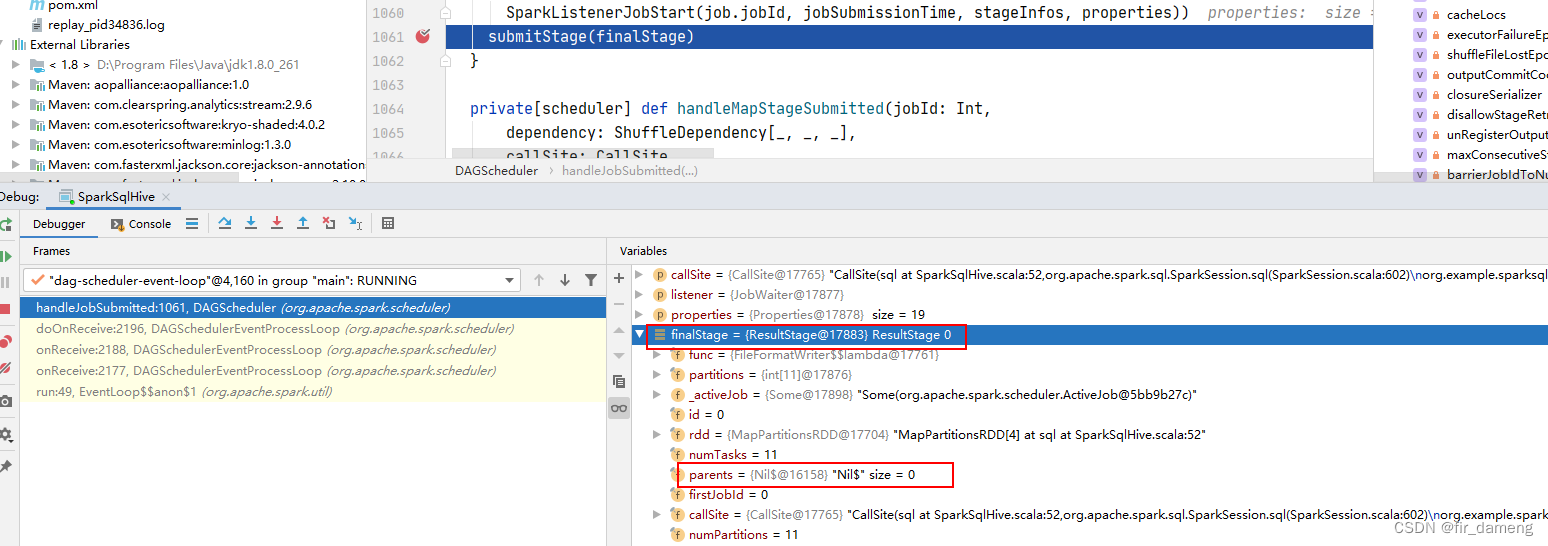
下面是exectuor中,spark task运行的线程dump中,可以发现有堆内存溢出的操作。
猜测:可能有shuffle或者排序,因为如果是纯map task任务,如果excutor内存不足,会直接报oom错误。
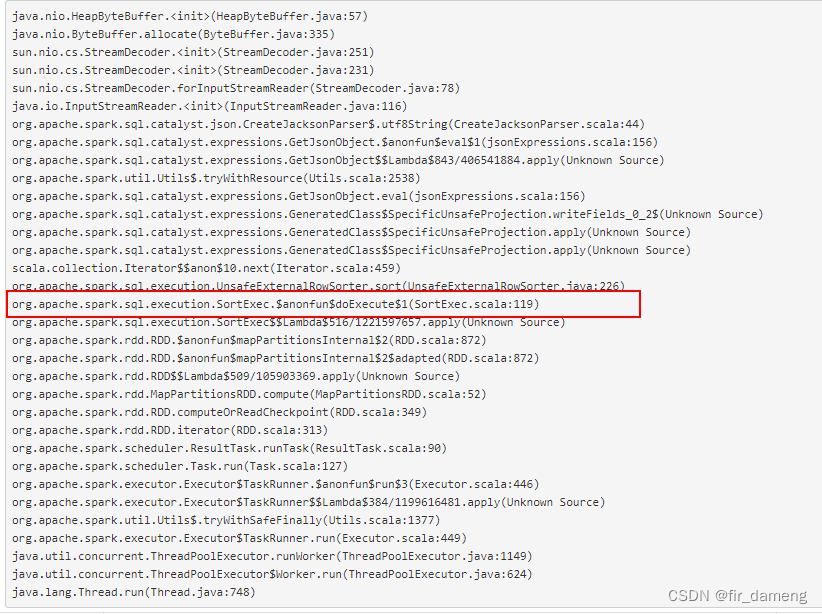
org.apache.spark.sql.execution.SortExec#doExecute
//task执行过程中,会到这一步。
protected override def doExecute(): RDD[InternalRow] = {val peakMemory = longMetric("peakMemory")val spillSize = longMetric("spillSize")val sortTime = longMetric("sortTime")child.execute().mapPartitionsInternal { iter =>val sorter = createSorter()val metrics = TaskContext.get().taskMetrics()// Remember spill data size of this task before execute this operator so that we can// figure out how many bytes we spilled for this operator.val spillSizeBefore = metrics.memoryBytesSpilled// 说明sort过程会 溢出数据到内存val sortedIterator = sorter.sort(iter.asInstanceOf[Iterator[UnsafeRow]])sortTime += NANOSECONDS.toMillis(sorter.getSortTimeNanos)peakMemory += sorter.getPeakMemoryUsagespillSize += metrics.memoryBytesSpilled - spillSizeBeforemetrics.incPeakExecutionMemory(sorter.getPeakMemoryUsage)sortedIterator}
sortExec工作原理 : https://zhuanlan.zhihu.com/p/582664919
当没有足够的内存来存储指针阵列列表或分配的内存页,或者UnsafeInMemorySorter的行数大于或等于溢出阈值numElementsForSpillThreshold时,内存中的数据将被分割到磁盘。
为什么会有sortExec算子?
在 InsertIntoHadoopFsRelationCommand 命令,提交job之前。
org/apache/spark/sql/execution/datasources/FileFormatWriter.scala:170
// 查看requiredChildOrderings针对排序有特殊需求的添加SortExec节点
val rdd = if (orderingMatched) {empty2NullPlan.execute()
} else {// SPARK-21165: the `requiredOrdering` is based on the attributes from analyzed plan, and// the physical plan may have different attribute ids due to optimizer removing some// aliases. Here we bind the expression ahead to avoid potential attribute ids mismatch.val orderingExpr = bindReferences(requiredOrdering.map(SortOrder(_, Ascending)), outputSpec.outputColumns)// 这里绑定上了sortexec 算子,返回的是rdd,并非已经开始计算了SortExec(orderingExpr,global = false,child = empty2NullPlan).execute()
}val rddWithNonEmptyPartitions = if (rdd.partitions.length == 0) {sparkSession.sparkContext.parallelize(Array.empty[InternalRow], 1)} else {rdd}val jobIdInstant = new Date().getTimeval ret = new Array[WriteTaskResult](rddWithNonEmptyPartitions.partitions.length)
// 然后这里才提交了jobsparkSession.sparkContext.runJob(rddWithNonEmptyPartitions,(taskContext: TaskContext, iter: Iterator[InternalRow]) => {executeTask(description = description,jobIdInstant = jobIdInstant,sparkStageId = taskContext.stageId(),sparkPartitionId = taskContext.partitionId(),sparkAttemptNumber = taskContext.taskAttemptId().toInt & Integer.MAX_VALUE,committer,iterator = iter)},rddWithNonEmptyPartitions.partitions.indices,(index, res: WriteTaskResult) => {committer.onTaskCommit(res.commitMsg)ret(index) = res})
参考:https://developer.aliyun.com/article/679260
4.3、resulttask
不涉及shuffle的sql 最终生成的只有resultTask, 当然也只有resultstage。
org.apache.spark.rdd.RDDCheckpointData$
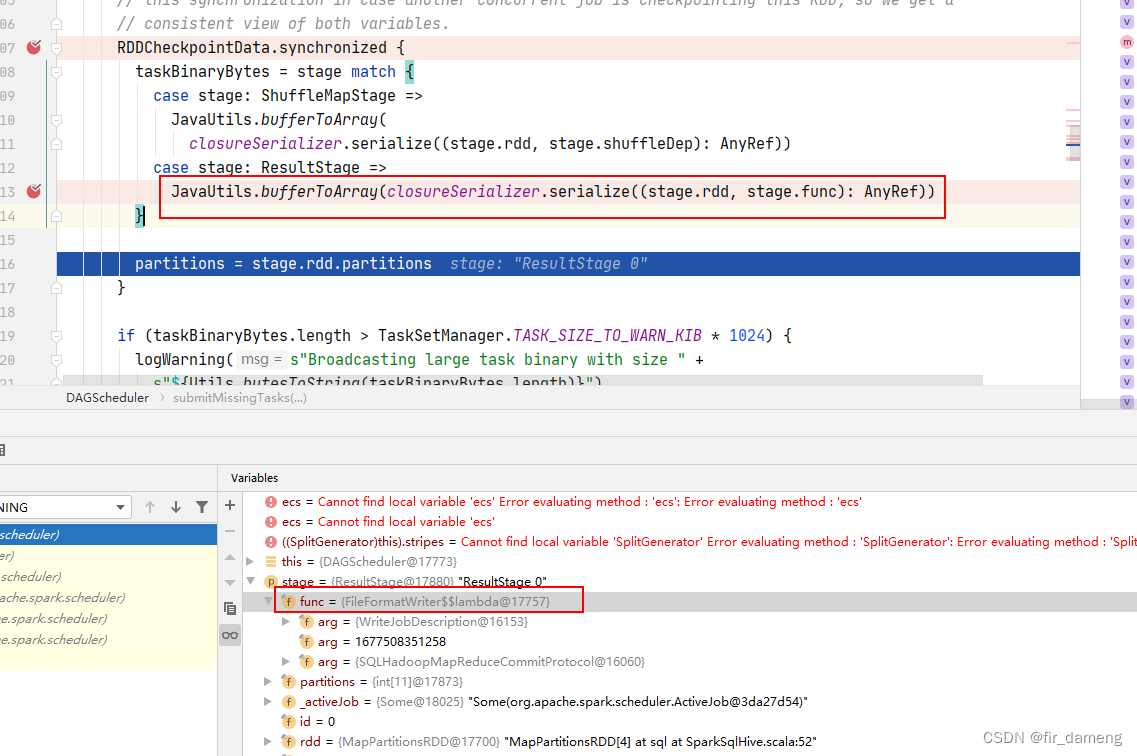
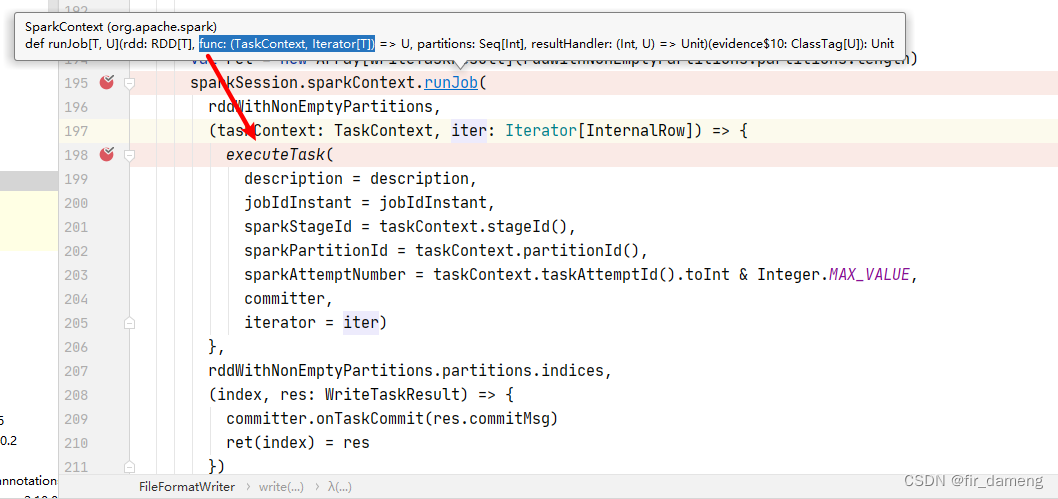
executetask即 传入 rdd上执行的func
org.apache.spark.scheduler.ResultTask#runTask
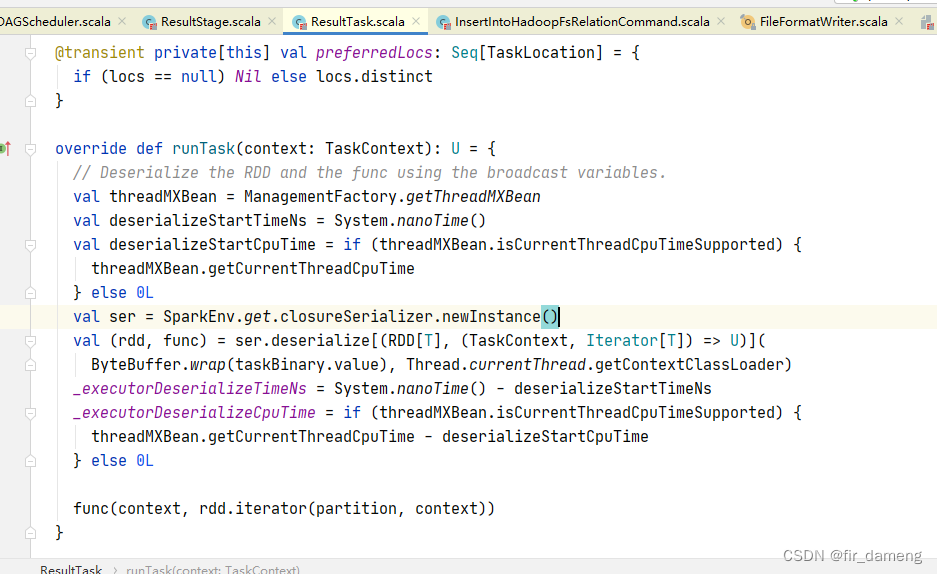
org.apache.spark.sql.execution.datasources.FileFormatWriter#executeTask
里面包含提交task的过程
参考:https://blog.csdn.net/weixin_42588332/article/details/122440644#:~:text=%E5%AF%B9%E4%BA%8E%20Aggregate%20%E6%93%8D%E4%BD%9C%EF%BC%8CSpark%20UI%20%E4%B9%9F%E8%AE%B0%E5%BD%95%E7%9D%80%E7%A3%81%E7%9B%98%E6%BA%A2%E5%87%BA%E4%B8%8E%E5%B3%B0%E5%80%BC%E6%B6%88%E8%80%97%EF%BC%8C%E5%8D%B3%20Spill%20size%20%E5%92%8C,%E7%9A%84%E5%B3%B0%E5%80%BC%E6%B6%88%E8%80%97%EF%BC%8C%E8%AF%81%E6%98%8E%E5%BD%93%E5%89%8D%203GB%20%E7%9A%84%20Executor%20Memory%20%E8%AE%BE%E7%BD%AE%EF%BC%8C%E5%AF%B9%E4%BA%8E%20Aggregate%20%E8%AE%A1%E7%AE%97%E6%9D%A5%E8%AF%B4%E6%98%AF%E7%BB%B0%E7%BB%B0%E6%9C%89%E4%BD%99%E7%9A%84%E3%80%82
https://zhuanlan.zhihu.com/p/431015932
https://blog.csdn.net/chongqueluo2709/article/details/101006130
相关文章:
executor行为相关Spark sql参数源码分析
0、前言 参数名和默认值spark.default.parallelismDefault number of partitions in RDDsspark.executor.cores1 in YARN mode 一般默认值spark.files.maxPartitionBytes134217728(128M)spark.files.openCostInBytes4194304 (4 MiB)spark.hadoop.mapreduce.fileoutputcommitte…...
双通道5.2GSPS(或单通道10.4GSPS)射频采样FMC+模块
概述 FMC140是一款具有缓冲模拟输入的低功耗、12位、双通道(5.2GSPS/通道)、单通道10.4GSPS、射频采样ADC模块,该板卡为FMC标准,符合VITA57.1规范,该模块可以作为一个理想的IO单元耦合至FPGA前端,8通道的JE…...

理解java反射
是什么Java反射是Java编程语言的一个功能,它允许程序在运行时(而不是编译时)检查、访问和修改类、对象和方法的属性和行为。使用反射创建对象相比直接创建对象有什么优点使用反射创建对象相比直接创建对象的主要优点是灵活性和可扩展性。当我…...

EasyRcovery16免费的电脑照片数据恢复软件
电脑作为一种重要的数据储存设备,其中保存着大量的文档,邮件,视频,音频和照片。那么,如果电脑照片被删除了怎么办?今天小编给大家介绍,误删除的照片从哪里可以找回来,误删除的照片如…...
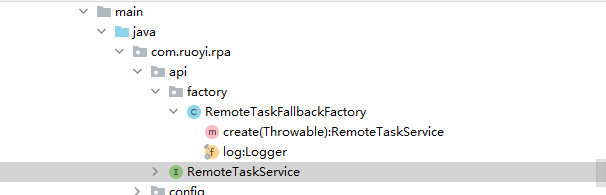
若依微服务版在定时任务里面跨模块调用服务
第一步 在被调用的模块中添加代理 RemoteTaskFallbackFactory.java: package com.ruoyi.rpa.api.factory;import com.ruoyi.common.core.domain.R; import com.ruoyi.rpa.api.RemoteTaskService; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springf…...

SpringMVC简单配置
1、pom.xml配置 <dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc</artifactId><version>5.1.12.RELEASE</version></dependency></dependencies><build><…...

xcat快速入门工作流程指南
目录一、快速入门指南一、先决条件二、准备管理节点xcatmn.mydomain.com三、第1阶段:添加你的第一个节点并且用带外BMC接口控制它四、第 2 阶段 预配节点并使用并行 shell 对其进行管理二:工作流程指南1. 查找 xCAT 管理节点的服务器2. 在所选服务器上安…...

C++回顾(十九)—— 容器string
19.1 string概述 1、string是STL的字符串类型,通常用来表示字符串。而在使用string之前,字符串通常是 用char * 表示的。string 与char * 都可以用来表示字符串,那么二者有什么区别呢。 2、string和 char * 的比较 (1)…...

Hadoop入门
数据分析与企业数据分析方向 数据是什么 数据是指对可观事件进行记录并可以鉴别的符号,是对客观事物的性质、状态以及相互关系等进行记载的物理符号或这些物理符号的组合,它是可以识别的、抽象的符号。 他不仅指狭义上的数字,还可以是具有一…...

高校如何通过校企合作/实验室建设来提高大数据人工智能学生就业质量
高校人才培养应该如何结合市场需求进行相关专业设置和就业引导,一直是高校就业工作的讨论热点。亘古不变的原则是,高校设置不能脱离市场需求太远,最佳的结合方式是,高校具有前瞻性,能领先市场一步,培养未来…...

提升学习 Prompt 总结
NLP现有的四个阶段: 完全有监督机器学习完全有监督深度学习预训练:预训练 -> 微调 -> 预测提示学习:预训练 -> 提示 -> 预测 阶段1,word的本质是特征,即特征的选取、衍生、侧重上的针对性工程。 阶段2&…...
)
JavaScript学习笔记(2.0)
BOM--(browser object model) 获取浏览器窗口尺寸 获取可视窗口高度:window.innerWidth 获取可视窗口高度:window.innerHeight 浏览器弹出层 提示框:window.alert(提示信息) 询问框:window.confirm(提示信息) 输…...

直击2023云南移动生态合作伙伴大会,聚焦云南移动的“价值裂变”
作者 | 曾响铃 文 | 响铃说 2023年3月2日下午,云南移动生态合作伙伴大会在昆明召开。云南移动党委书记,总经理葛松海在大会上提到“2023年,云南移动将重点在‘做大平台及生态级新产品,做优渠道转型新动能,做强合作新…...

STM32F1开发实例-振动传感器(机械)
振动(敲击)传感器 振动无处不在,有声音就有振动,哒哒的脚步是匆匆的过客,沙沙的夜雨是暗夜的忧伤。那你知道理科工程男是如何理解振动的吗?今天我们就来讲一讲本节的主角:最简单的机械式振动传感器。 下图即为振动传…...
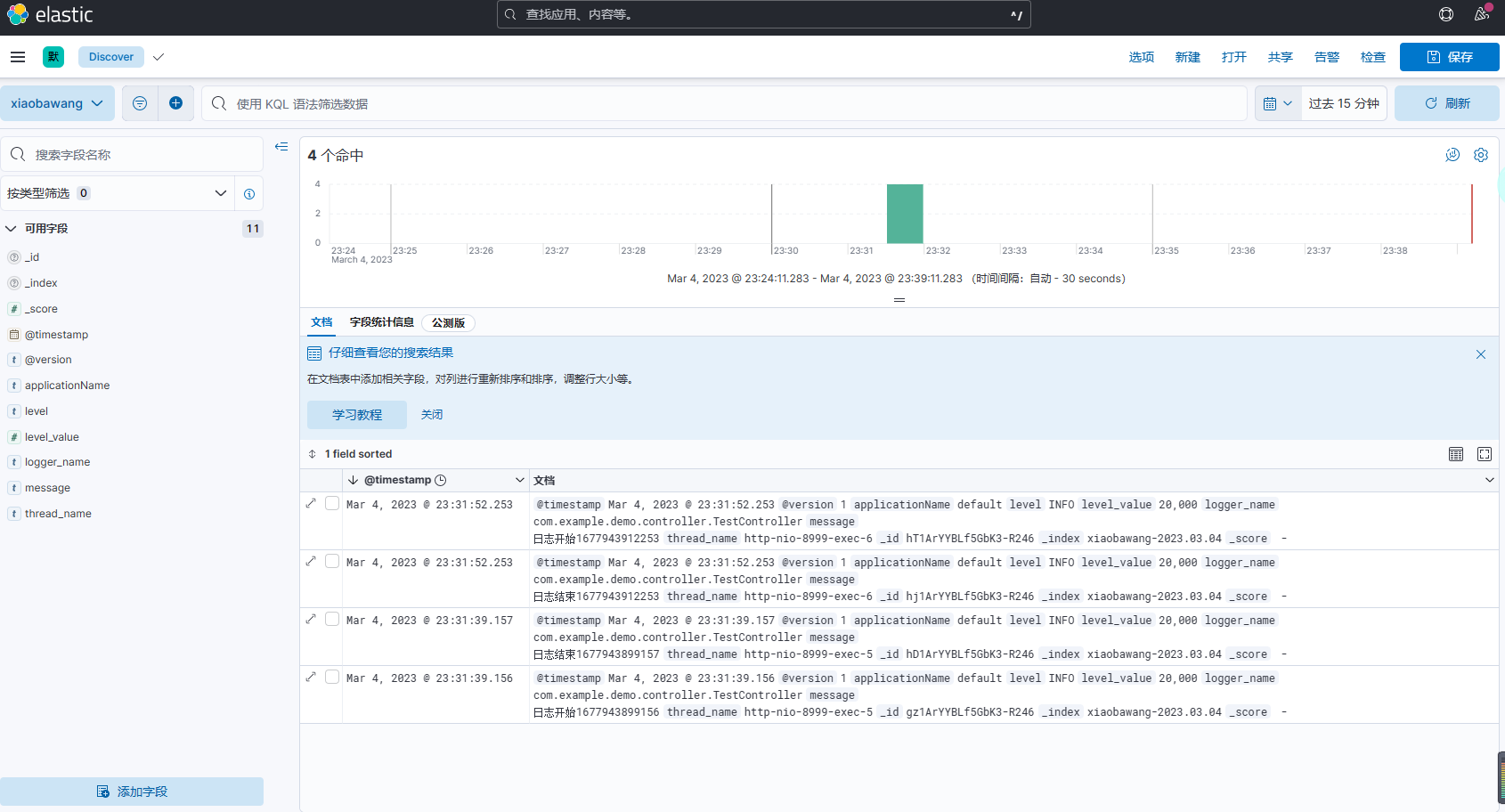
2023最新ELK日志平台(elasticsearch+logstash+kibana)搭建
去年公司由于不断发展,内部自研系统越来越多,所以后来搭建了一个日志收集平台,并将日志收集功能以二方包形式引入自研系统,避免每个自研系统都要建立一套自己的日志模块,节约了开发时间,管理起来也更加容易…...

2023-3-10 刷题情况
打家劫舍 IV 题目描述 沿街有一排连续的房屋。每间房屋内都藏有一定的现金。现在有一位小偷计划从这些房屋中窃取现金。 由于相邻的房屋装有相互连通的防盗系统,所以小偷 不会窃取相邻的房屋 。 小偷的 窃取能力 定义为他在窃取过程中能从单间房屋中窃取的 最大…...

如何建立一个成功的MES?
制造执行系统(MES)是一种为制造业企业提供实时生产过程控制、管理和监视的信息系统。一个成功的MES系统可以帮助企业提高生产效率,降低成本,提高产品质量,提高客户满意度等。下面是一些关键步骤来建立一个成功的MES系统…...

Kafka生产者幂等性/事务
Kafka生产者幂等性/事务幂等性事务Kafka 消息交付可靠性保障: Kafka 默认是:至少一次最多一次 (at most once) : 消息可能会丢失,但绝不会被重复发送至少一次 (at least once) : 消息不会丢失,但有可能被重复发送精确一次 (exact…...

JavaWeb--案例(Axios+JSON)
JavaWeb--案例(AxiosJSON)1 需求2 查询所有功能2.1 环境准备2.2 后端实现2.3 前端实现2.4 测试3 添加品牌功能3.1 后端实现3.2 前端实现3.3 测试1 需求 使用Axios JSON 完成品牌列表数据查询和添加。页面效果还是下图所示: 2 查询所有功能 …...

css制作动画(动效的序列帧图)
相信 animation 大家都用过很多,知道是 CSS3做动画用的。而我自己就只会在 X/Y轴 上做位移旋转,使用 animation-timing-function 规定动画的速度曲线,常用到的 贝塞尔曲线。但是这些动画效果都是连续性的。 今天发现个新功能 animation-timi…...

互联网大厂Java求职者面试全解析:技术点与场景详解
面试场景介绍 本文通过一场严肃的面试官与搞笑的水货程序员谢飞机之间的面试对话,带你深入了解互联网大厂Java面试的全套流程。涵盖Java核心语言与平台、Spring生态、微服务、安全、消息队列等热点技术,融合多种业务场景,如电商、内容社区、在…...

实战指南:基于快马生成代码构建支持验证码的2048论坛登录系统
实战指南:基于快马生成代码构建支持验证码的2048论坛登录系统 最近在开发一个2048游戏社区时,需要为论坛设计一个安全可靠的登录入口。这个登录系统不仅要考虑用户体验,还要兼顾安全性。通过InsCode(快马)平台生成的代码作为基础,…...

大厂裁员潮下,软件人的“抗风险”能力清单
在当今科技行业,大厂裁员潮已成为不可忽视的现实。2025年至2026年间,多家头部企业为优化成本,纷纷缩减规模,导致软件测试从业者面临前所未有的职业挑战。裁员不仅源于经济压力,更反映了行业转型——基础手工测试正被自…...

深度拆解 JDK1.8 ConcurrentHashMap 核心方法:从 put 到扩容,彻底吃透并发神器
在 Java 高并发编程中,ConcurrentHashMap是线程安全 Map 的绝对首选,而 JDK1.8 版本对它的重构堪称并发设计的巅峰之作 —— 彻底抛弃分段锁,用CAS 桶级 synchronized实现极致细粒度并发,搭配多线程协同扩容、链表红黑树转换、高…...

注CO2驱替煤层气THM耦合模型与自定义PDE耦合固体力学
注co2驱替煤层气THM耦合模型 自定义pde耦合固体力学今天,我来分享一下关于CO2驱替煤层气的THM(热-水-力学)耦合模型的构建过程。这个模型听起来有点复杂,但其实拆开来理解,每一步都还挺有意思的。尤其是其中涉及的自定…...

InfluxDB服务文件被误删怎么办?记录一次完整的1.8.6版本灾难恢复过程
InfluxDB服务文件误删灾难恢复实录:从崩溃边缘到完美复原 那天下午,服务器监控大屏突然亮起一片刺眼的红色告警——InfluxDB服务全线离线。作为团队里负责时序数据库运维的老兵,我立刻意识到问题的严重性。这套运行着1.8.6版本的InfluxDB承载…...
)
告别龟速下载!手把手教你用Aspera ascp命令高效获取SRA数据(附常见错误排查)
告别龟速下载!手把手教你用Aspera ascp命令高效获取SRA数据(附常见错误排查) 在生物信息学研究中,获取公共数据库中的测序数据是许多分析的第一步。然而,传统的FTP下载方式往往速度缓慢,尤其是当需要下载大…...
)
故障诊断指南:用STFT在5分钟内定位工业设备异常时间点(MATLAB版)
故障诊断实战:STFT在工业设备异常定位中的高效应用(MATLAB实现) 工业设备的异常检测如同医生听诊,需要精准捕捉故障的"心跳节律"。传统方法往往只能告诉我们"设备病了",却难以定位"何时发病…...

实战详解:从零构建 LangChain 智能 Agent,让大模型真正“动起来”!
文章目录📖 一、为什么我们需要 Agent?🔄 Agent 核心工作流图解🛠️ 二、环境准备与核心组件核心组件介绍💻 三、实战代码:构建“全能数据分析师”Agent1. 定义工具 (Tools)2. 构建 Agent 逻辑 (ReAct 模式…...

3个高效技巧:深度解析ComfyUI节点管理的实战指南
3个高效技巧:深度解析ComfyUI节点管理的实战指南 【免费下载链接】ComfyUI-Easy-Use In order to make it easier to use the ComfyUI, I have made some optimizations and integrations to some commonly used nodes. 项目地址: https://gitcode.com/gh_mirrors…...