【Effective Modern C++】第1章 型别推导
【Effective Modern C++】第1章 型别推导
文章目录
- 【Effective Modern C++】第1章 型别推导
- 条款1:理解模板型别推导
- 基础概念
- 模板型别推导的三种情况
- 情景一 ParamType 是一个指针或者引用,但非通用引用
- 情景二 ParamType是一个通过引用
- 情景三 ParamType既不是指针也不是引用时
- 数组实参和函数实参的型别推导
- 数组实参
- 函数实参
- 要点
- 条款2:理解auto型别推导
- 一般情景
- 特例
- auto推导函数返回值和lambda形参
- 要点
- 条款3:理解decltype
- 要点
- 条款4:掌握查看型别推导结果的方法
- IDE编辑器
- 编译器诊断
- 运行时输出
- 要点
条款1:理解模板型别推导
在现代C++编程中,模板已经成为不可或缺的一部分。模板使得我们可以编写出更为通用和灵活的代码。然而,模板型别推导的复杂性也常常令开发者感到困惑。本文将总结其核心内容,并结合实际例子帮助读者更好地理解模板型别推导。
基础概念
模板型别推导的基本机制是编译器根据传入的实参推导出模板参数的具体类型。C++模板分为函数模板和类模板,这里主要讨论函数模板的型别推导。
template<typename T>
void f(T param);
而一次调用形如:
f(expr) // 以某表达式调用f
在编译期间,编译器使用 expr 进行两个类型推导:一个是针对 T 的,另一个是针对ParamType 的。这两个类型通常是不同的,因为 ParamType 包含一些修饰,比如 const 和引用修饰符。举个例子,如果模板这样声明:
template<typename T>
void f(const T& param); //ParamType是const T&
当调用函数模板 f 时,编译器会尝试推导参数 T 的类型。例如:
int x = 0;
f(x); //T 被推导为 int , ParamType 却被推导为 const int&
模板型别推导的三种情况
T 的类型推导不仅取决于 expr 的类型,也取决于 ParamType 的类型。这里有三种情况:
情景一 ParamType 是一个指针或者引用,但非通用引用
在这种情况下,类型推导会这样进行:
- 如果
expr的类型是一个引用,忽略引用部分 - 然后
expr的类型与ParamType进行模式匹配来决定T
举个例子,如果这是我们的模板,
template<typename T>
void f(T& param); //param是一个引用
我们声明这些变量,
int x=27; //x是int
const int cx=x; //cx是const int
const int& rx=x; //rx是指向作为const int的x的引用
在不同的调用中,对param和T推导的类型会是这样:
f(x); //T是int,param的类型是int&
f(cx); //T是const int,param的类型是const int&
f(rx); //T是const int,param的类型是const int&
如果param是一个指针(或者指向const的指针)而不是引用,情况本质和上面也一样。
情景二 ParamType是一个通过引用
这样的形参被声明为像右值引用一样(也就是,在函数模板中假设有一个类型形参T,那么通用引用声明形式就是T&&)。推导规则:
- 如果
expr是左值,T和ParamType都会被推导为左值引用。这非常不寻常,第一,这是模板类型推导中唯一一种T被推导为引用的情况。第二,虽然ParamType被声明为右值引用类型,但是最后推导的结果是左值引用。 - 如果
expr是右值,就使用正常的(也就是情景一)推导规则
举个例子:
template<typename T>
void f(T&& param); //param现在是一个通用引用类型int x=27; //如之前一样
const int cx=x; //如之前一样
const int & rx=cx; //如之前一样f(x); //x是左值,所以T是int&,//param类型也是int&f(cx); //cx是左值,所以T是const int&,//param类型也是const int&f(rx); //rx是左值,所以T是const int&,//param类型也是const int&f(27); //27是右值,所以T是int,//param类型就是int&&
情景三 ParamType既不是指针也不是引用时
我们通过传值(pass-by-value)的方式处理:
template<typename T>
void f(T param); //以传值的方式处理param
这意味着无论传递什么param都会成为它的一份拷贝——一个完整的新对象。事实上param成为一个新对象这一行为会影响T如何从expr中推导出结果。
- 和之前一样,如果
expr的类型是一个引用,忽略这个引用部分 - 如果忽略
expr的引用性(reference-ness)之后,expr是一个const,那就再忽略const。如果它是volatile,也忽略volatile
因此
int x=27; //如之前一样
const int cx=x; //如之前一样
const int & rx=cx; //如之前一样f(x); //T和param的类型都是int
f(cx); //T和param的类型都是int
f(rx); //T和param的类型都是int
param是一个完全独立于cx和rx的对象——是cx或rx的一个拷贝。具有常量性的cx和rx不可修改并不代表param也是一样。
认识到只有在传值给形参时才会忽略const(和volatile)这一点很重要,正如我们看到的,对于reference-to-const和pointer-to-const形参来说,expr的常量性constness在推导时会被保留。但是考虑这样的情况,expr是一个const指针,指向const对象,expr通过传值传递给param:
template<typename T>
void f(T param); //仍然以传值的方式处理paramconst char* const ptr = //ptr是一个常量指针,指向常量对象 "Fun with pointers";f(ptr); //传递const char * const类型的实参
在这里稍微有点复杂,解引用符号(*)的右边的const表示ptr本身是一个const:ptr不能被修改为指向其它地址,也不能被设置为null(解引用符号左边的const表示ptr指向一个字符串,这个字符串是const,因此字符串不能被修改)。当ptr作为实参传给f,组成这个指针的每一比特都被拷贝进param。像这种情况,ptr自身的值会被传给形参,根据类型推导的第三条规则,ptr自身的常量性constness将会被省略,所以param是const char*,也就是一个可变指针指向const字符串。在类型推导中,这个指针指向的数据的常量性const将会被保留,但是当拷贝ptr来创造一个新指针param时,ptr自身的常量性const将会被忽略。
数组实参和函数实参的型别推导
上面的内容几乎覆盖了模板类型推导的大部分内容,但这里还有一些小细节值得注意。在模板类型推导时,数组名或者函数名实参会退化为指针,除非它们被用于初始化引用。
数组实参
数组类型不同于指针类型,虽然它们两个有时候是可互换的。关于这个错觉最常见的例子是,在很多上下文中数组会退化为指向它的第一个元素的指针。这样的退化允许像这样的代码可以被编译:
const char name[] = "J. P. Briggs"; //name的类型是const char[13]const char * ptrToName = name; //数组退化为指针
在这里const char*指针ptrToName会由name初始化,而name的类型为const char[13],这两种类型(const char*和const char[13])是不一样的,但是由于数组退化为指针的规则,编译器允许这样的代码。
但是现在难题来了,虽然函数不能声明形参为真正的数组,但是可以接受指向数组的引用!所以我们修改f为传引用:
template<typename T>
void f(T& param); //传引用形参的模板
我们这样进行调用,
f(name); //传数组给f
T被推导为了真正的数组!这个类型包括了数组的大小,在这个例子中T被推导为const char[13],f的形参(该数组的引用)的类型则为const char (&)[13]。是的,这种语法看起来又臭又长,但是知道它将会让你在关心这些问题的人的提问中获得大神的称号。
有趣的是,可声明指向数组的引用的能力,使得我们可以创建一个模板函数来推导出数组的大小:
//在编译期间返回一个数组大小的常量值(//数组形参没有名字,
//因为我们只关心数组的大小)
template<typename T, std::size_t N> //关于
constexpr std::size_t arraySize(T (&)[N]) noexcept //constexpr
{ //和noexceptreturn N; //的信息
} //请看下面
函数实参
对于数组类型推导的全部讨论都可以应用到函数类型推导和退化为函数指针上来。结果是:
void someFunc(int, double); //someFunc是一个函数,//类型是void(int, double)template<typename T>
void f1(T param); //传值给f1template<typename T>
void f2(T & param); //传引用给f2f1(someFunc); //param被推导为指向函数的指针,//类型是void(*)(int, double)
f2(someFunc); //param被推导为指向函数的引用,//类型是void(&)(int, double)
要点
- 在模板类型推导时,有引用的实参会被视为无引用,他们的引用会被忽略
- 对于通用引用的推导,左值实参会被特殊对待
- 对于传值类型推导,
const和/或volatile实参会被认为是non-const的和non-volatile的 - 在模板类型推导时,数组名或者函数名实参会退化为指针,除非它们被用于初始化引用
条款2:理解auto型别推导
auto类型推导就是模板型别推导,除了一个奇妙的特例除外。
一般情景
当一个变量使用auto进行声明时,auto扮演了模板中T的角色,变量的类型说明符扮演了ParamType的角色。废话少说,这里便是更直观的代码描述,考虑这个例子:
auto x = 27;
这里x的类型说明符是auto自己,另一方面,在这个声明中:
const auto cx = x;
类型说明符是const auto。另一个:
const auto& rx = x;
类型说明符是const auto&。在这里例子中要推导x,cx和rx的类型,编译器的行为看起来就像是认为这里每个声明都有一个模板,然后使用合适的初始化表达式进行调用(对比上面的auto):
template<typename T> //概念化的模板用来推导x的类型
void func_for_x(T param);func_for_x(27); //概念化调用://param的推导类型是x的类型template<typename T> //概念化的模板用来推导cx的类型
void func_for_cx(const T param);func_for_cx(x); //概念化调用://param的推导类型是cx的类型template<typename T> //概念化的模板用来推导rx的类型
void func_for_rx(const T & param);func_for_rx(x); //概念化调用://param的推导类型是rx的类型
正如我说的,auto类型推导除了一个例外(我们很快就会讨论),其他情况都和模板类型推导一样。
条款一基于ParamType——在函数模板中param的类型说明符,把模板类型推导分成三个部分来讨论。在使用auto作为类型说明符的变量声明中,类型说明符代替了ParamType,因此Item1描述的三个情景稍作修改就能适用于auto:
- 情景一:类型说明符是一个指针或引用但不是通用引用
- 情景二:类型说明符一个通用引用
- 情景三:类型说明符既不是指针也不是引用
我们早已看过情景一和情景三的例子:
auto x = 27; //情景三(x既不是指针也不是引用)
const auto cx = x; //情景三(cx也一样)
const auto & rx=cx; //情景一(rx是非通用引用)
情景二像你期待的一样运作:
auto&& uref1 = x; //x是int左值,//所以uref1类型为int&
auto&& uref2 = cx; //cx是const int左值,//所以uref2类型为const int&
auto&& uref3 = 27; //27是int右值,//所以uref3类型为int&&
条款一讨论并总结了对于non-reference类型说明符,数组和函数名如何退化为指针。那些内容也同样适用于auto类型推导:
const char name[] = //name的类型是const char[13]"R. N. Briggs";auto arr1 = name; //arr1的类型是const char*
auto& arr2 = name; //arr2的类型是const char (&)[13]void someFunc(int, double); //someFunc是一个函数,//类型为void(int, double)auto func1 = someFunc; //func1的类型是void (*)(int, double)
auto& func2 = someFunc; //func2的类型是void (&)(int, double)
就像你看到的那样,auto类型推导和模板类型推导几乎一样的工作,它们就像一个硬币的两面。
特例
开始提到的与模板型别推导不同的一个特例:C++11的统一初始化(uniform initialization)的语法:
int x1 = 27; // C++98
int x2(27); // C++98
int x3 = { 27 };
int x4{ 27 };
但是条款5解释了使用auto说明符代替指定类型说明符的好处,所以我们应该很乐意把上面声明中的int替换为auto,我们会得到这样的代码:
auto x1 = 27;
auto x2(27);
auto x3 = { 27 };
auto x4{ 27 };
这些声明都能通过编译,但是他们不像替换之前那样有相同的意义。前面两个语句确实声明了一个类型为int值为27的变量,但是后面两个声明了一个存储一个元素27的 std::initializer_list<int>类型的变量。
auto x1 = 27; //类型是int,值是27
auto x2(27); //同上
auto x3 = { 27 }; //类型是std::initializer_list<int>,//值是{ 27 }
auto x4{ 27 }; //同上
这就造成了auto类型推导不同于模板类型推导的特殊情况。当用auto声明的变量使用花括号进行初始化,auto类型推导推出的类型则为std::initializer_list。如果这样的一个类型不能被成功推导(比如花括号里面包含的是不同类型的变量),编译器会拒绝这样的代码:
auto x5 = { 1, 2, 3.0 }; //错误!无法推导std::initializer_list<T>中的T
就像注释说的那样,在这种情况下类型推导将会失败,但是对我们来说认识到这里确实发生了两种类型推导是很重要的。一种是由于auto的使用:x5的类型不得不被推导。因为x5使用花括号的方式进行初始化,x5必须被推导为std::initializer_list。但是std::initializer_list是一个模板。std::initializer_list<T>会被某种类型T实例化,所以这意味着T也会被推导。 推导落入了这里发生的第二种类型推导——模板类型推导的范围。在这个例子中推导之所以失败,是因为在花括号中的值并不是同一种类型。
对于花括号的处理是auto类型推导和模板类型推导唯一不同的地方在于,auto会假定用大括号括起的初始化表达式代表一个std::initializer_list,但模板型别推导却不会:
auto x = { 11, 23, 9 }; //x的类型是std::initializer_list<int>template<typename T> //带有与x的声明等价的
void f(T param); //形参声明的模板f({ 11, 23, 9 }); //错误!不能推导出T
然而如果在模板中指定T是std::initializer_list<T>而留下未知T,模板类型推导就能正常工作:
template<typename T>
void f(std::initializer_list<T> initList);f({ 11, 23, 9 }); //T被推导为int,initList的类型为//std::initializer_list<int>
一个非常重要的点就是:如果你想要拥抱统一初始化的哲学——就是说,会自然而然吧初始化值扩在大括号里面的话,那么务必请牢记这条规则。
auto推导函数返回值和lambda形参
对于C++11故事已经说完了。但是对于C++14故事还在继续,C++14允许auto用于函数返回值并会被推导,而且C++14的lambda函数也允许在形参声明中使用auto。但是在这些情况下auto实际上使用模板类型推导的那一套规则在工作,而不是auto类型推导,所以说下面这样的代码不会通过编译:
auto createInitList()
{return { 1, 2, 3 }; //错误!不能推导{ 1, 2, 3 }的类型
}
同样在C++14的lambda函数中这样使用auto也不能通过编译:
std::vector<int> v;
…
auto resetV = [&v](const auto& newValue){ v = newValue; }; //C++14
…
resetV({ 1, 2, 3 }); //错误!不能推导{ 1, 2, 3 }的类型
要点
auto类型推导通常和模板类型推导相同,但是auto类型推导假定花括号初始化代表std::initializer_list,而模板类型推导不这样做- 在C++14中
auto允许出现在函数返回值或者lambda函数形参中,但是它的工作机制是模板类型推导那一套方案,而不是auto类型推导
条款3:理解decltype
decltype是一个奇怪的东西。给它一个名字或者表达式decltype就会告诉你这个名字或者表达式的类型。通常,它会精确的告诉你你想要的结果。但有时候它得出的结果也会让你挠头半天。
先从一般案例开始:
const int i = 0; //decltype(i)是const intbool f(const Widget& w); //decltype(w)是const Widget&//decltype(f)是bool(const Widget&)struct Point{int x,y; //decltype(Point::x)是int
}; //decltype(Point::y)是intWidget w; //decltype(w)是Widgetif (f(w))… //decltype(f(w))是booltemplate<typename T> //std::vector的简化版本
class vector{
public:…T& operator[](std::size_t index);…
};vector<int> v; //decltype(v)是vector<int>
…
if (v[0] == 0)… //decltype(v[0])是int&
在C++11中,decltype最主要的用途就是用于声明函数模板,而这个函数返回类型依赖于形参类型。举个例子,假定我们写一个函数,一个形参为容器,一个形参为索引值,这个函数支持使用方括号的方式(也就是使用“[]”)访问容器中指定索引值的数据,然后在返回索引操作的结果前执行认证用户操作。函数的返回类型应该和索引操作返回的类型相同。
对一个T类型的容器使用operator[] 通常会返回一个T&对象,比如std::deque就是这样。但是std::vector有一个例外,对于std::vector<bool>,operator[]不会返回bool&,它会返回一个全新的对象。关于这个问题的详细讨论请参见条款6,这里重要的是我们可以看到对一个容器进行operator[]操作返回的类型取决于容器本身。
使用decltype使得我们很容易去实现它,这是我们写的第一个版本,使用decltype计算返回类型,这个模板需要改良,我们把这个推迟到后面:
template<typename Container, typename Index> //可以工作,
auto authAndAccess(Container& c, Index i) //但是需要改良->decltype(c[i])
{authenticateUser();return c[i];
}
函数名称前面的auto不会做任何的类型推导工作。相反的,他只是暗示使用了C++11的尾置返回类型语法,即在函数形参列表后面使用一个”->“符号指出函数的返回类型,尾置返回类型的好处是我们可以在函数返回类型中使用函数形参相关的信息。在authAndAccess函数中,我们使用c和i指定返回类型。如果我们按照传统语法把函数返回类型放在函数名称之前,c和i就未被声明所以不能使用。
在这种声明中,authAndAccess函数返回operator[]应用到容器中返回的对象的类型,这也正是我们期望的结果。
C++11允许自动推导单一语句的lambda表达式的返回类型, C++14扩展到允许自动推导所有的lambda表达式和函数,甚至它们内含多条语句。对于authAndAccess来说这意味着在C++14标准下我们可以忽略尾置返回类型,只留下一个auto。使用这种声明形式,auto标示这里会发生类型推导。更准确的说,编译器将会从函数实现中推导出函数的返回类型。
template<typename Container, typename Index> //C++14版本,
auto authAndAccess(Container& c, Index i) //不那么正确
{authenticateUser();return c[i]; //从c[i]中推导返回类型
}
条款2解释了函数返回类型中使用auto,编译器实际上是使用的模板类型推导的那套规则。如果那样的话这里就会有一些问题。正如我们之前讨论的,operator[]对于大多数T类型的容器会返回一个T&,但是条款1解释了在模板类型推导期间,表达式的引用性(reference-ness)会被忽略。基于这样的规则,考虑它会对下面用户的代码有哪些影响:
std::deque<int> d;
…
authAndAccess(d, 5) = 10; //认证用户,返回d[5],//然后把10赋值给它//无法通过编译器!
在这里d[5]本该返回一个int&,但是模板类型推导会剥去引用的部分,因此产生了int返回类型。函数返回的那个int是一个右值,上面的代码尝试把10赋值给右值int,C++11禁止这样做,所以代码无法编译。
要想让authAndAccess像我们期待的那样工作,我们需要使用decltype类型推导来推导它的返回值,即指定authAndAccess应该返回一个和c[i]表达式类型一样的类型。C++期望在某些情况下当类型被暗示时需要使用decltype类型推导的规则,C++14通过使用decltype(auto)说明符使得这成为可能。我们第一次看见decltype(auto)可能觉得非常的矛盾(到底是decltype还是auto?),实际上我们可以这样解释它的意义:auto说明符表示这个类型将会被推导,decltype说明decltype的规则将会被用到这个推导过程中。因此我们可以这样写authAndAccess:
template<typename Container, typename Index> //C++14版本,
decltype(auto) //可以工作,
authAndAccess(Container& c, Index i) //但是还需要
{ //改良authenticateUser();return c[i];
}
现在authAndAccess将会真正的返回c[i]的类型。现在事情解决了,一般情况下c[i]返回T&,authAndAccess也会返回T&,特殊情况下c[i]返回一个对象,authAndAccess也会返回一个对象。
decltype(auto)的使用不仅仅局限于函数返回类型,当你想对初始化表达式使用decltype推导的规则,你也可以使用:
Widget w;const Widget& cw = w;auto myWidget1 = cw; //auto类型推导//myWidget1的类型为Widget
decltype(auto) myWidget2 = cw; //decltype类型推导//myWidget2的类型是const Widget&
但是这里有两个问题困惑着你。一个是之前提到的authAndAccess的改良至今都没有描述。现在说一说这个问题。
再看看C++14版本的authAndAccess声明:
template<typename Container, typename Index>
decltype(auto) authAndAccess(Container& c, Index i);
容器通过传引用的方式传递非常量左值引用(lvalue-reference-to-non-const),因为返回一个引用允许用户可以修改容器。但是这意味着在不能给这个函数传递右值容器,右值不能被绑定到左值引用上(除非这个左值引用是一个const(lvalue-references-to-const),但是这里明显不是)。
公认的向authAndAccess传递一个右值是一个edge case(译注:在极限操作情况下会发生的事情,类似于会发生但是概率较小的事情)。一个右值容器,是一个临时对象,通常会在authAndAccess调用结束被销毁,这意味着authAndAccess返回的引用将会成为一个悬置的(dangle)引用。但是使用向authAndAccess传递一个临时变量也并不是没有意义,有时候用户可能只是想简单的获得临时容器中的一个元素的拷贝,比如这样:
std::deque<std::string> makeStringDeque(); //工厂函数//从makeStringDeque中获得第五个元素的拷贝并返回
auto s = authAndAccess(makeStringDeque(), 5);
要想支持这样使用authAndAccess我们就得修改一下当前的声明使得它支持左值和右值。重载是一个不错的选择(一个函数重载声明为左值引用,另一个声明为右值引用),但是我们就不得不维护两个重载函数。另一个方法是使authAndAccess的引用可以绑定左值和右值,Item24解释了那正是通用引用能做的,所以我们这里可以使用通用引用进行声明:
template<typename Containter, typename Index> //现在c是通用引用
decltype(auto) authAndAccess(Container&& c, Index i);
在这个模板中,我们不知道我们操纵的容器的类型是什么,那意味着我们同样不知道它使用的索引对象(index objects)的类型,对一个未知类型的对象使用传值通常会造成不必要的拷贝,对程序的性能有极大的影响,还会造成对象切片行为(参见条款41),以及给同事落下笑柄。但是就容器索引来说,我们遵照标准模板库对于索引的处理是有理由的(比如std::string,std::vector和std::deque的operator[]),所以我们坚持传值调用。
然而,我们还需要更新一下模板的实现,让它能听从条款25的告诫应用std::forward实现通用引用:
template<typename Container, typename Index> //最终的C++14版本
decltype(auto)
authAndAccess(Container&& c, Index i)
{authenticateUser();return std::forward<Container>(c)[i];
}
这样就能对我们的期望交上一份满意的答卷,但是这要求编译器支持C++14。如果你没有这样的编译器,你还需要使用C++11版本的模板,它看起来和C++14版本的极为相似,除了你不得不指定函数返回类型之外:
template<typename Container, typename Index> //最终的C++11版本
auto
authAndAccess(Container&& c, Index i)
->decltype(std::forward<Container>(c)[i])
{authenticateUser();return std::forward<Container>(c)[i];
}
另一个问题是就像在本条款的开始唠叨的那样,decltype通常会产生你期望的结果,但并不总是这样。在极少数情况下它产生的结果可能让你很惊讶。老实说如果你不是一个大型库的实现者你不太可能会遇到这些异常情况。
为了完全理解decltype的行为,你需要熟悉一些特殊情况。它们大多数都太过晦涩以至于几乎没有书进行有过权威的讨论,这本书也不例外,但是其中的一个会让我们更加理解decltype的使用。
将decltype应用于变量名会产生该变量名的声明类型。虽然变量名都是左值表达式,但这不会影响decltype的行为。(译者注:这里是说对于单纯的变量名,decltype只会返回变量的声明类型)然而,对于比单纯的变量名更复杂的左值表达式,decltype可以确保报告的类型始终是左值引用。也就是说,如果一个不是单纯变量名的左值表达式的类型是T,那么decltype会把这个表达式的类型报告为T&。这几乎没有什么太大影响,因为大多数左值表达式的类型天生具备一个左值引用修饰符。例如,返回左值的函数总是返回左值引用。
这个行为暗含的意义值得我们注意,在:
int x = 0;
中,x是一个变量的名字,所以decltype(x)是int。但是如果用一个小括号包覆这个名字,比如这样(x) ,就会产生一个比名字更复杂的表达式。对于名字来说,x是一个左值,C++11定义了表达式(x)也是一个左值。因此decltype((x))是int&。用小括号覆盖一个名字可以改变decltype对于名字产生的结果。
在C++11中这稍微有点奇怪,但是由于C++14允许了decltype(auto)的使用,这意味着你在函数返回语句中细微的改变就可以影响类型的推导:
decltype(auto) f1()
{int x = 0;…return x; //decltype(x)是int,所以f1返回int
}decltype(auto) f2()
{int x = 0;return (x); //decltype((x))是int&,所以f2返回int&
}
注意不仅f2的返回类型不同于f1,而且它还引用了一个局部变量!这样的代码将会把你送上未定义行为的特快列车,一辆你绝对不想上第二次的车。
当使用decltype(auto)的时候一定要加倍的小心,在表达式中看起来无足轻重的细节将会影响到decltype(auto)的推导结果。为了确认类型推导是否产出了你想要的结果,请参见条款4描述的那些技术。
同时你也不应该忽略decltype这块大蛋糕。没错,decltype(单独使用或者与auto一起用)可能会偶尔产生一些令人惊讶的结果,但那毕竟是少数情况。通常,decltype都会产生你想要的结果,尤其是当你对一个变量使用decltype时,因为在这种情况下,decltype只是做一件本分之事:它产出变量的声明类型。
要点
decltype总是不加修改的产生变量或者表达式的类型。- 对于
T类型的不是单纯的变量名的左值表达式,decltype总是产出T的引用即T&。 - C++14支持
decltype(auto),就像auto一样,推导出类型,但是它使用decltype的规则进行推导。
条款4:掌握查看型别推导结果的方法
IDE编辑器
在IDE中的代码编辑器通常可以显示程序代码中变量,函数,参数的类型,你只需要简单的把鼠标移到它们的上面,举个例子,有这样的代码中:
const int theAnswer = 42;auto x = theAnswer;
auto y = &theAnswer;
IDE编辑器可以直接显示x推导的结果为int,y推导的结果为const int*。
为此,你的代码必须或多或少的处于可编译状态,因为IDE之所以能提供这些信息是因为一个C++编译器(或者至少是前端中的一个部分)运行于IDE中。如果这个编译器对你的代码不能做出有意义的分析或者推导,它就不会显示推导的结果。
对于像int这样简单的推导,IDE产生的信息通常令人很满意。正如我们将看到的,如果更复杂的类型出现时,IDE提供的信息就几乎没有什么用了。
编译器诊断
另一个获得推导结果的方法是使用编译器出错时提供的错误消息。这些错误消息无形的提到了造成我们编译错误的类型是什么。
举个例子,假如我们想看到之前那段代码中x和y的类型,我们可以首先声明一个类模板但不定义。就像这样:
template<typename T> //只对TD进行声明
class TD; //TD == "Type Displayer"
如果尝试实例化这个类模板就会引出一个错误消息,因为这里没有用来实例化的类模板定义。为了查看x和y的类型,只需要使用它们的类型去实例化TD:
TD<decltype(x)> xType; //引出包含x和y
TD<decltype(y)> yType; //的类型的错误消息
使用“变量名字+Type”的结构来命名变量,因为这样它们产生的错误消息可以有助于我们查找。对于上面的代码,我的编译器产生了这样的错误信息,我取一部分贴到下面:
error: aggregate 'TD<int> xType' has incomplete type and cannot be defined
error: aggregate 'TD<const int *> yType' has incomplete type andcannot be defined
另一个编译器也产生了一样的错误,只是格式稍微改变了一下:
error: 'xType' uses undefined class 'TD<int>'
error: 'yType' uses undefined class 'TD<const int *>'
除了格式不同外,几乎所有我测试过的编译器都产生了这样有用的错误消息。
运行时输出
使用printf的方法使类型信息只有在运行时才会显示出来(尽管我不是非常建议你使用printf),但是它提供了一种格式化输出的方法。现在唯一的问题是只需对于你关心的变量使用一种优雅的文本表示。“这有什么难的,“你这样想,”这正是typeid和std::type_info::name的价值所在”。为了实现我们想要查看x和y的类型的需求,你可能会这样写:
std::cout << typeid(x).name() << '\n'; //显示x和y的类型
std::cout << typeid(y).name() << '\n';
这种方法对一个对象如x或y调用typeid产生一个std::type_info的对象,然后std::type_info里面的成员函数name()来产生一个C风格的字符串(即一个const char*)表示变量的名字。
调用std::type_info::name不保证返回任何有意义的东西,但是库的实现者尝试尽量使它们返回的结果有用。实现者们对于“有用”有不同的理解。举个例子,GNU和Clang环境下x的类型会显示为”i“,y会显示为”PKi“,这样的输出你必须要问问编译器实现者们才能知道他们的意义:”i“表示”int“,”PK“表示”pointer to konstconst“(指向常量的指针)。(这些编译器都提供一个工具c++filt,解释这些“混乱的”类型)Microsoft的编译器输出得更直白一些:对于x输出”int“对于y输出”int const *“
因为对于x和y来说这样的结果是正确的,你可能认为问题已经接近了,别急,考虑一个更复杂的例子:
template<typename T> //要调用的模板函数
void f(const T& param);std::vector<Widget> createVec(); //工厂函数const auto vw = createVec(); //使用工厂函数返回值初始化vwif (!vw.empty()){f(&vw[0]); //调用f…
}
在这段代码中包含了一个用户定义的类型Widget,一个STL容器std::vector和一个auto变量vw,这个更现实的情况是你可能在会遇到的并且想获得他们类型推导的结果,比如模板类型形参T,比如函数f形参param。
从这里中我们不难看出typeid的问题所在。我们在f中添加一些代码来显示类型:
template<typename T>
void f(const T& param)
{using std::cout;cout << "T = " << typeid(T).name() << '\n'; //显示Tcout << "param = " << typeid(param).name() << '\n'; //显示… //param
} //的类型
GNU和Clang执行这段代码将会输出这样的结果
T = PK6Widget
param = PK6Widget
我们早就知道在这些编译器中PK表示“pointer to const”,所以只有数字6对我们来说是神奇的。其实数字是类名称(Widget)的字符串长度,所以这些编译器告诉我们T和param都是const Widget*。
Microsoft的编译器也同意上述言论:
T = class Widget const *
param = class Widget const *
这三个独立的编译器产生了相同的信息并表示信息非常准确,当然看起来不是那么准确。在模板f中,param的声明类型是const T&。难道你们不觉得T和param类型相同很奇怪吗?比如T是int,param的类型应该是const int&而不是相同类型才对吧。
遗憾的是,事实就是这样,std::type_info::name的结果并不总是可信的,就像上面一样,三个编译器对param的报告都是错误的。因为它们本质上可以不正确,因为std::type_info::name规范批准像传值形参一样来对待这些类型。正如条款1提到的,如果传递的是一个引用,那么引用部分(reference-ness)将被忽略,如果忽略后还具有const或者volatile,那么常量性constness或者易变性volatileness也会被忽略。那就是为什么param的类型const Widget * const &会输出为const Widget *,首先引用被忽略,然后这个指针自身的常量性constness被忽略,剩下的就是指针指向一个常量对象。
同样遗憾的是,IDE编辑器显示的类型信息也不总是可靠的,或者说不总是有用的。还是一样的例子,一个IDE编辑器可能会把T的类型显示为(我没有胡编乱造):
const
std::_Simple_types<std::_Wrap_alloc<std::_Vec_base_types<Widget,
std::allocator<Widget>>::_Alloc>::value_type>::value_type *
同样把param的类型显示为
const std::_Simple_types<...>::value_type *const &
这个比起T来说要简单一些,但是如果你不知道“...”表示编译器忽略T的部分类型那么可能你还是会产生困惑。如果你运气好点你的IDE可能表现得比这个要好一些。
比起运气如果你更倾向于依赖库,那么你乐意被告知std::type_info::name和IDE不怎么好,Boost的TypeIndex库(通常写作Boost.TypeIndex)是更好的选择。这个库不是标准C++的一部分,也不是IDE或者TD这样的模板。Boost库(可在boost.com获得)是跨平台,开源,有良好的开源协议的库,这意味着使用Boost和STL一样具有高度可移植性。
这里是如何使用Boost.TypeIndex得到f的类型的代码
#include <boost/type_index.hpp>template<typename T>
void f(const T& param)
{using std::cout;using boost::typeindex::type_id_with_cvr;//显示Tcout << "T = "<< type_id_with_cvr<T>().pretty_name()<< '\n';//显示param类型cout << "param = "<< type_id_with_cvr<decltype(param)>().pretty_name()<< '\n';
}
boost::typeindex::type_id_with_cvr获取一个类型实参(我们想获得相应信息的那个类型),它不消除实参的const,volatile和引用修饰符(因此模板名中有“with_cvr”)。结果是一个boost::typeindex::type_index对象,它的pretty_name成员函数输出一个std::string,包含我们能看懂的类型表示。 基于这个f的实现版本,再次考虑那个使用typeid时获取param类型信息出错的调用:
std::vetor<Widget> createVec(); //工厂函数
const auto vw = createVec(); //使用工厂函数返回值初始化vw
if (!vw.empty()){f(&vw[0]); //调用f…
}
在GNU和Clang的编译器环境下,使用Boost.TypeIndex版本的f最后会产生下面的(准确的)输出:
T = Widget const *
param = Widget const * const&
在Microsoft的编译器环境下,结果也是极其相似:
T = class Widget const *
param = class Widget const * const &
这样近乎一致的结果是很不错的,但是请记住IDE,编译器错误诊断或者像Boost.TypeIndex这样的库只是用来帮助你理解编译器推导的类型是什么。它们是有用的,但是作为本章结束语我想说它们根本不能替代你对Item1-3提到的类型推导的理解。
要点
- 类型推断可以从IDE看出,从编译器报错看出,从Boost TypeIndex库的使用看出
- 这些工具可能既不准确也无帮助,所以理解C++类型推导规则才是最重要的
参考:Effective Modern C++(中文版)和这里。
相关文章:

【Effective Modern C++】第1章 型别推导
【Effective Modern C】第1章 型别推导 文章目录 【Effective Modern C】第1章 型别推导条款1:理解模板型别推导基础概念模板型别推导的三种情况情景一 ParamType 是一个指针或者引用,但非通用引用情景二 ParamType是一个通过引用情景三 ParamType既不是…...
服装连锁实体店bC一体化运营方案
一、引言 随着互联网的快速发展和消费者购物习惯的变化,传统服装连锁实体店在面对新的市场环境下亟需转型升级。BC(Business to Consumer)一体化运营方案的实施将成为提升服装连锁实体店竞争力和顾客体验的关键举掖。商淘云详细介绍服装连锁…...
IDEA中SpringMVC的运行环境问题
文章目录 一、IEAD 清理缓存二、用阿里云和spring创建 SpringMVC 项目中 pom.xml 文件的区别 一、IEAD 清理缓存 springMVC 运行时存在一些之前运行过的缓存导致项目不能运行,可以试试清理缓存 二、用阿里云和spring创建 SpringMVC 项目中 pom.xml 文件的区别 以下…...

Python初体验
# Java基础知识学的差不多了,项目上又没什么事,学学py,方便以后对接 1、打包flask应用(好痛苦,在什么平台打包就只在那个平台可用想在linux用只能参考方法2了) pyinstaller --onefile app.py -n myapp 2…...

从零开始如何学习人工智能?
说说我自己的情况:我接触AI的时候,是在研一。那个时候AlphaGo战胜围棋世界冠军李世石是大新闻,人工智能第一次出现我面前,当时就想搞清楚背后的原理以及这些技术有什么作用。 就开始找资料,看视频。随着了解的深入&am…...

【仿真建模-anylogic】动态生成ConveyorCustomStation
Author:赵志乾 Date:2024-06-18 Declaration:All Right Reserved!!! 0. 背景 直接使用Anylogic组件开发的模型无法动态改变运输网布局;目前需求是要将运输网布局配置化;运输网配置化…...
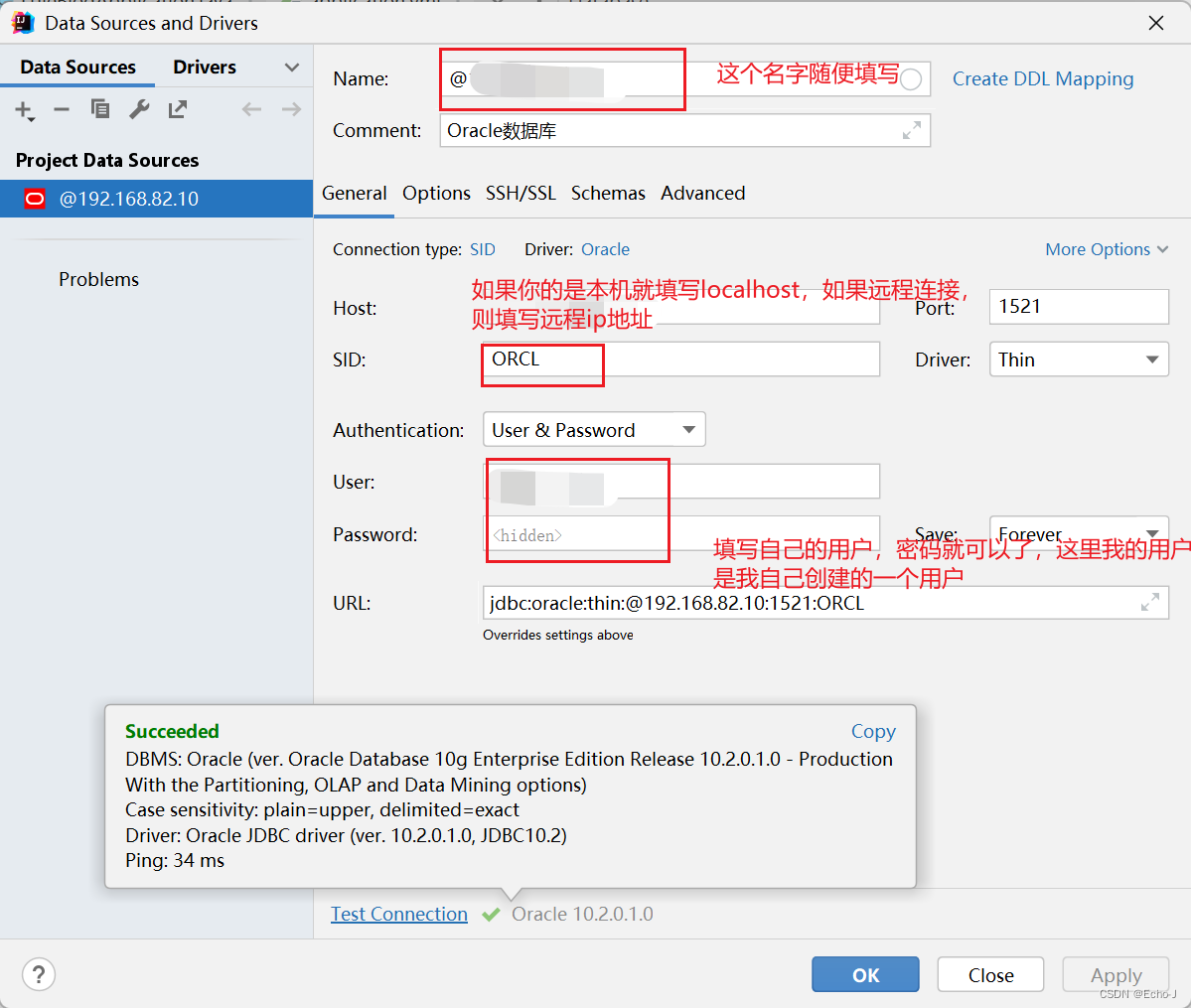
如何使用idea连接Oracle数据库?
idea版本:2021.3.3 Oracle版本:10.2.0.1.0(在虚拟机Windows sever 2003 远程连接数据库) 数据库管理系统:PLSQL Developer 在idea里面找到database,在idea侧面 选择左上角加号,新建ÿ…...

谈谈kafaka的并行处理,顺带讲讲rabbitmq
简介 Kafka 是一个分布式流处理平台,它支持高效的并行处理。Kafka 的并行处理能力主要体现在以下几个方面: 分区(Partition)并行 Kafka 将数据存储在称为"分区"的逻辑单元中。每个分区可以独立地并行地进行读写操作。生产者可以根据分区策略,将数据写入到指定的分…...

P3056 [USACO12NOV] Clumsy Cows S
[USACO12NOV] Clumsy Cows S 题目描述 Bessie the cow is trying to type a balanced string of parentheses into her new laptop, but she is sufficiently clumsy (due to her large hooves) that she keeps mis-typing characters. Please help her by computing the min…...

智赢选品,OZON数据分析选品利器丨萌啦OZON数据
在电商行业的激烈竞争中,如何快速准确地把握市场动态、洞察消费者需求、实现精准选品,是每个电商卖家都面临的挑战。而在这个数据驱动的时代,一款强大的数据分析工具无疑是电商卖家们的得力助手。今天,我们就来聊聊这样一款选品利…...

Canal自定义客户端
一、背景 在Canal推送数据变更信息至MQ(消息队列)时,我们遇到了特定问题,尤其是当消息体的大小超过了MQ所允许的最大限制。这种限制导致数据推送过程受阻,需要相应的调整或处理。 二、解决方法 采用Canal自定义客户…...
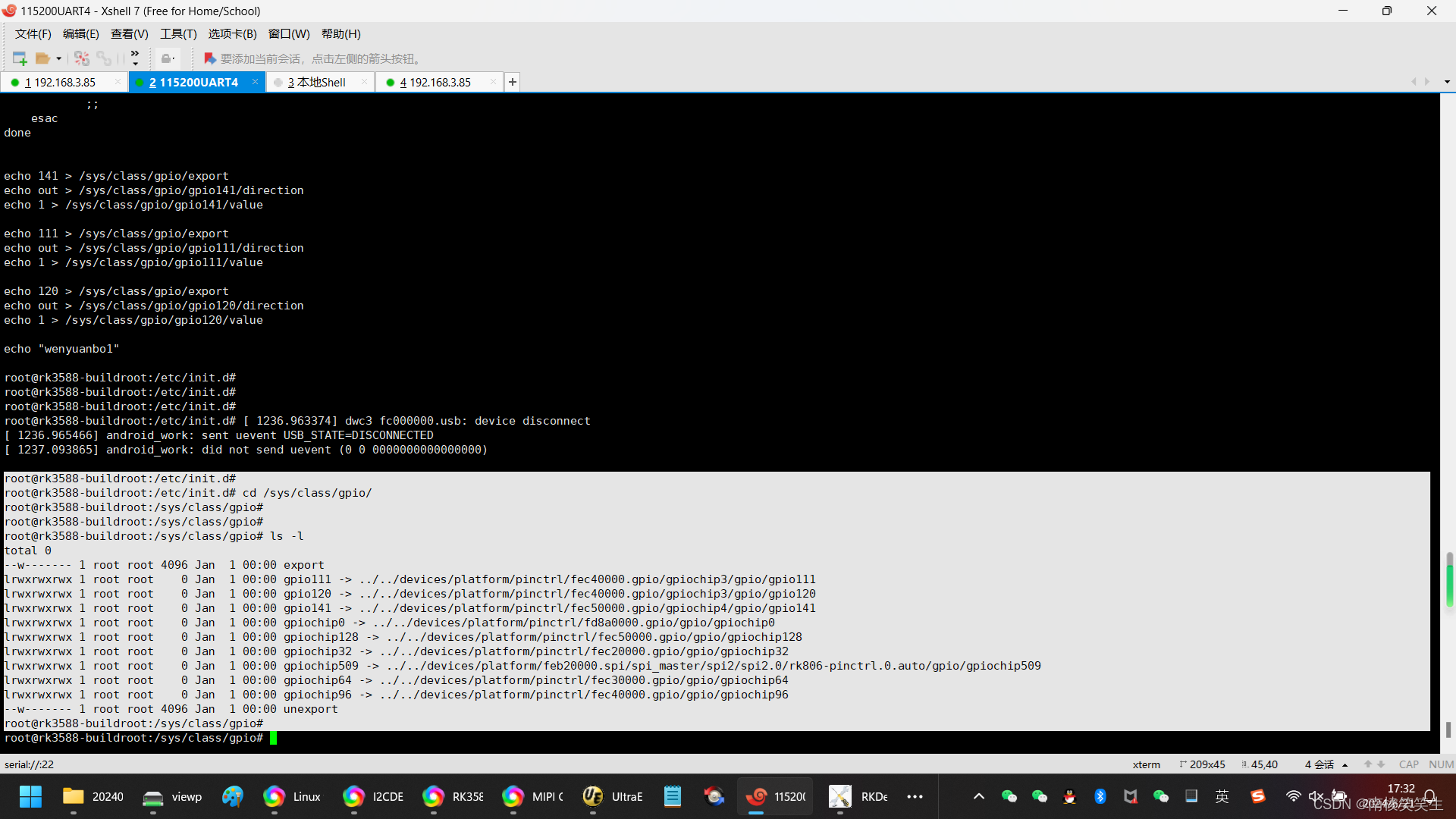
20240621将需要自启动的部分放到RK3588平台的Buildroot系统的rcS文件中
20240621将需要自启动的部分放到RK3588平台的Buildroot系统的rcS文件中 2024/6/21 17:15 开发板:飞凌OK3588-C SDK:Rockchip原厂的Buildroot 缘起:在凌OK3588-C的LINUX R4系统启动的时候,需要拉高GPIO4_B5、GPIO3_B7和GPIO3_D0。…...
掌握数据魔方:Xinstall引领ASA全链路数据归因新纪元
一、引言 在数字化时代,数据是App推广和运营的核心驱动力。然而,如何准确获取、分析并应用这些数据,却成为了许多开发者和营销人员面临的痛点。Xinstall作为一款专业的App全渠道统计服务商,致力于提供精准、高效的数据解决方案&a…...

IIS代理配置-反向代理
前后端分离项目,前端在开发中使用proxy代理解决跨域问题,打包之后无效。 未配置前无法访问 部署环境为windows IIS,要在iis设置反向代理 安装代理模块 需要在iis中实现代理,需要安装Application Request Routing Cache和URL重…...
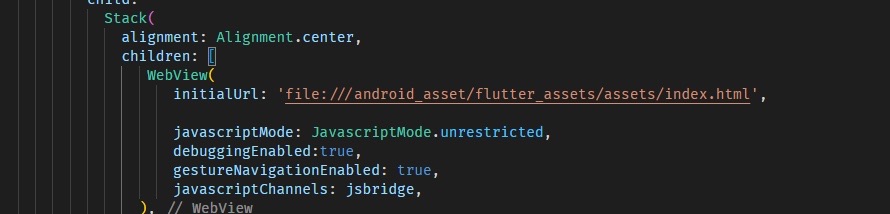
Flutter调用本地web
前言: 在目前Flutter 环境中,使用在线 webview 是一种很常见的行为 而在 app 环境中,离线使用则更有必要 1.环境准备 将依赖导入 2.引入前端代码 前端代码有两种情况 一种是使用打包工具 build 而来的前端代码 另一种情况是直接使用 HTML 文件 …...

AI大模型部署Ubuntu服务器攻略
一、下载Ollama 在线安装: 在linux中输入命令curl -fsSL https://ollama.com/install.sh | sh 由于在linux下载ollama需要经过外网,网络会不稳定,很容易造成连接超时的问题。 离线安装: 步骤一: 下载Ollama离线版本…...

vlan、vxlan、vpc学习
文章目录 前言VLAN (Virtual Local Area Network)定义工作原理优点应用场景限制 VXLAN (Virtual eXtensible Local Area Network)工作原理优点应用场景与VLAN的区别 VPC (Virtual Private Cloud)定义特点优势应用场景与VLAN/VXLAN的关联 总结 前言 VLAN(Virtual Lo…...

低代码开发:加速工业数智化转型发展
引言 在当今全球经济一体化和信息化的深度融合的大环境下,工业数智化转型已经成为推动制造业高质量发展的关键因素。这一转型不仅涉及生产过程的智能化、网络化,还涉及到企业管理、市场服务等全方位的数字化升级,其最终目标是为了实现更高效能…...

python“__main__“的解读
Tutorial Gross tutorial 有些模块包含了仅供脚本使用的代码,比如解析命令行参数或从标准输入获取数据。 如果这样的模块被从不同的模块中导入,例如为了单元测试,脚本代码也会无意中执行。 这就是 if name ‘main’ 代码块的用武之地。除非…...
Linux Debian12使用podman安装pikachu靶场环境
一、pikachu简介 Pikachu是一个带有漏洞的Web应用系统,在这里包含了常见的web安全漏洞。 二、安装podman环境 Linux Debian系统如果没有安装podman容器环境,可以参考这篇文章先安装podman环境, Linux Debian11使用国内源安装Podman环境 三…...

告别top!用htop监控Linux进程,这10个高效用法运维新手必看
告别top!用htop监控Linux进程,这10个高效用法运维新手必看 如果你还在用top命令监控Linux服务器状态,就像拿着算盘处理大数据——虽然能用,但效率实在堪忧。作为top的现代化替代品,htop以其彩色界面、鼠标支持和直观的…...

Claude Code 代码保存全攻略:告别丢失,高效管理开发成果
日常开发中,用 Claude Code 生成代码后,很多人都会遇到这些糟心事:生成的代码片段零散复制,换个会话就找不到;手动保存步骤繁琐,遗漏文件或格式错乱;切换不同 AI 模型时,代码记录无法…...

2026 年全球网络安全威胁态势与关键技术防御研究
摘要 本文基于 Security Affairs 2026 年第 576 期安全通讯披露的最新网络攻击事件与漏洞情报,系统分析 Linux 无文件远控、内核提权、AI 供应链投毒、钓鱼攻击工业化、关键信息基础设施入侵等新型威胁的技术机理、传播路径与危害特征。研究结合 Quasar Linux RAT、…...

RAG视觉锚定:让大模型精准定位PDF中的图与表
1. 项目概述:让大模型真正“看见”文档里的图与表 “Visual Grounding for Advanced RAG Frameworks”——这个标题乍看像学术论文的副标题,但在我过去三年落地二十多个企业级RAG项目的过程中,它直指当前最棘手、也最容易被忽视的痛点&#x…...

量子计算误差缓解技术:Qiskit实现与工程实践
1. 量子计算误差缓解的必要性与挑战在当前的NISQ(Noisy Intermediate-Scale Quantum)时代,量子计算机的硬件限制使得误差累积成为阻碍实用化的主要瓶颈。以氢分子基态能量计算为例,未经误差缓解的VQE计算结果可能偏离理论值达20%以…...

开源硬件测试框架OpenClaw Harness:从GPIO到CI/CD的自动化测试实践
1. 项目概述:一个开源硬件测试框架的诞生最近在折腾一些嵌入式开发和硬件原型项目,发现一个挺普遍的问题:当你手头有一堆传感器、执行器或者自己设计的电路板时,怎么高效、可靠地对它们进行功能测试和性能验证?用万用表…...

Python包安装全攻略:从pip、conda到离线安装,总有一种方法适合你
Python包安装全攻略:从pip、conda到离线安装,总有一种方法适合你 在Python开发中,依赖管理是每个开发者必须掌握的核心技能。无论是数据科学家搭建机器学习环境,还是Web开发者部署Django应用,都离不开Python包的安装与…...

BBDown完全指南:5分钟掌握B站视频下载终极方案
BBDown完全指南:5分钟掌握B站视频下载终极方案 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown 你是否经常遇到想收藏B站优质视频却找不到合适工具的困扰?当网络…...

放心API和4SAPI怎么选?从开发者选型角度看差异
很多开发者在选 Claude API 中转站时,都会遇到一个问题:**到底是选更偏个人友好的放心API,还是选更偏企业级的4SAPI?**这个问题没有标准答案,只有场景答案。---## 一、先给结论如果你的项目处于以下阶段:- …...

Blitz.js全栈开发框架:基于Next.js的Zero-API数据层实践
1. 项目概述:Blitz.js,一个被低估的全栈开发框架如果你和我一样,在过去几年里一直在用 Next.js 构建全栈应用,那你肯定经历过这种场景:前端页面写得飞快,但一到后端 API 路由、数据库操作、身份验证这些环节…...