【NLP练习】Transformer实战-单词预测
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
任务:自定义输入一段英文文本进行预测
一、定义模型
from tempfile import TemporaryDirectory
from typing import Tuple
from torch import nn,Tensor
from torch.nn import TransformerEncoder, TransformerEncoderLayer
import math, os, torchclass TransformerModel(nn.Module):def __init__(self, ntoken: int, d_model: int, nhead: int, d_hid: int, nlayers: int, dropout: float = 0.5):super().__init__()self.pos_encoder = PositionalEncoding(d_model, dropout)#定义编码器层encoder_layers = TransformerEncoderLayer(d_model, nhead, d_hid, dropout)#定义编码器,pytorch将Transformer编码器进行了打包,这里直接调用即可self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)self.embedding = nn.Embedding(ntoken,d_model)self.d_model = d_modelself.linear = nn.Linear(d_model, ntoken)self.init_weights()#初始化权重def init_weights(self) -> None:initrange = 0.1self.embedding.weight.data.uniform_(-initrange, initrange)self.linear.bias.data.zeros_()self.linear.weight.data.uniform_(-initrange, initrange)def forward(self, src:Tensor, src_mask: Tensor = None) -> Tensor:"""Arguments:src: Tensor, 形状为[seq_len, batch_size]src_mask: Tensor, 形状为[seq_len, seq_len]Returns:输出的Tensor,形状为[seq_len, batch_size, ntoken]"""src = self.embedding(src) * math.sqrt(self.d_model)src = self.pos_encoder(src)output = self.transformer_encoder(src, src_mask)output = self.linear(output)return outputclass PositionalEncoding(nn.Module):def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):super().__init__()self.dropout = nn.Dropout(p = dropout)#生成位置编码的位置张量position = torch.arange(max_len).unsqueeze(1)#计算位置编码的除数项div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))#创建位置编码张量pe = torch.zeros(max_len, 1, d_model)#使用正弦函数计算位置编码中的基数维度部分pe[:, 0, 1::2] = torch.sin(position * div_term)#使用余弦函数计算位置编码中的偶数维度部分pe[:, 0, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x: Tensor) -> Tensor:"""Arguments:x: Tensor, 形状为[seq_len, batch_size, embedding_dim]"""#将位置编码添加到输入张量x = x + self.pe[:x.size(0)]#应用dropoutreturn self.dropout(x)
二、加载数据集
本实验使用torchtext生成Wikitext-2数据集。在此之前,你需要安装下面的包:
- pip install portalocker
- pip install torchdata
import torchtext
from torchtext.datasets.wikitext2 import WikiText2
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator#从torchtext库中导入WikiTetx2数据集
train_iter = WikiText2(split = 'train')#获取基本的英语分词器
tokenizer = get_tokenizer('basic_english')
#通过迭代器构建词汇表
vocab = build_vocab_from_iterator(map(tokenizer, train_iter), specials=['<unk>'])
#将默认索引设置为'<unk>'
vocab.set_default_index(vocab['<unk>'])def data_process(raw_text_iter: dataset.IterableDataset) -> Tensor:"""将原始文本转换为扁平的张量"""data = [torch.tensor(vocab(tokenizer(item)),dtype = torch.long) for item in raw_text_iter]return torch.cat(tuple(filer(lambda t: t.numel() > 0, data)))#由于构建词汇表时"train_iter"被使用了,所以需要重新创建
train_iter, val_iter, test_iter = WikiText2()#队训练、验证和测试数据进行处理
train_data = data_process(train_iter)
val_data = data_process(val_iter)
test_data = data_process(test_iter)#检查是否有可用的CUDA设备,将设备设置为GPU或者CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def batchify(data: Tensor, bsz: int) -> Tensor:"""将数据划分为bsz个单独的序列,去除不能完全容纳的额外元素。参数:data: Tensor,形状为``[N]``bsz:int,批大小返回:形状为[N // bsz, bsz]的张量"""seq_len = data.size(0) // bszdata = data[:seq_len * bsz]data = data.view(bsz, seq_len).t().contiguous()return data.to(device)#设置批大小和评估批大小
batch_size = 20
eval_batch_size = 10
#将训练、验证和测试数据进行批处理
train_data = batchify(train_data, batch_size) #形状为[seq_len, batch_size]
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data, eval_batch_size)
bptt = 35#获取批次数据
def get_batch(source:Tensor, i: int) -> Tuple[Tensor, Tensor]:"""参数:source: Tensor,形状为``[full_seq_len, batch_size]``i : int, 当前批次索引返回:tuple(data, target),-data形状为[seq_len, batch_size],-target形状为[seq_len * batch_size]"""#计算当前批次的序列长度,最大为bptt,确保不超过source的长度seq_len = min(bptt, len(source) - 1 - i)#获取data,从i开始,长度为seq_lendata = source[i:i+seq_len]#获取target,从i+1开始,长度为seq_len,并将其形状转换为一维张量target = source[i+1:i+1+seq_len].reshape(-1)return data, target
三、初始化实例
ntokend = len(vocab)
emsize = 200
d_hid = 200
nlayers = 2
nhead = 2
dropout = 0.2
#创建transformer模型
model = TransformerModel(ntokend,emsize,nhead,d_hid,nlayers,dropout).to(device)
四、训练模型
结合使用CrossEntropyLoss与SGD(随机梯度下降优化器)。训练期间,使用torch.nn.utils.clip_grad_norm_来防止梯度爆炸
import time
criterion = nn.CrossEntropyLoss() #定义交叉熵损失函数
lr = 5.0
optimizer = torch.optim.SGD(model.parameters(),lr = lr)
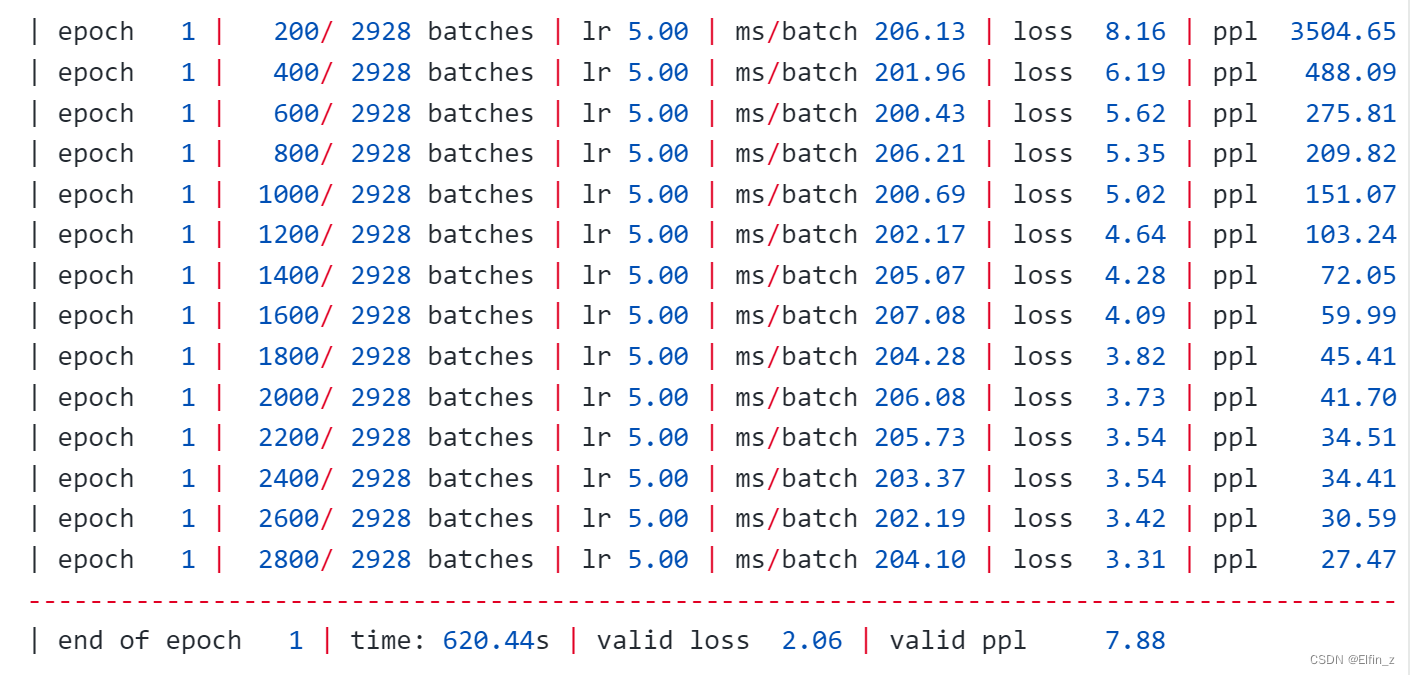
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gama = 0.95)def train(model: nn.Module) -> None:model.train() #开启训练模式total_loss = 0.log_interval = 200 #start_time = time.time()num_batches = len(train_data) // bpttfor batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):data, targets = get_batch(train_data, i)output = model(data)output_flat = output.view(-1, ntokens)loss = criterion(output_flat, targets) #计算损失optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)optimizer.step()total_loss += loss.item()if batch % log_interval == 0 and batch > 0:lr = scheduler.get_last_lr()[0]ms_per_batch = (time.time() - start_time) * 1000 / log_intervalcur_loss = total_loss / log_intervalppl = math.exp(cur_loss)print(f'| epoch{epoch:3d} | {batch:5d} / {num_batches:5d} batches |'f'lr{lr:02.2f} | ms/batch {ms_per_batch:5.2f} |'f'loss {cur_loss:5.2f}|ppl{ppl:8.2f}')total_loss = 0start_time = time.time()def evaluate(model:nn.Module, eval_data:Tensor) -> float:model.eval()total_loss = 0.with torch.no_grad():for i in range(0,eval_data.size(0) - 1, bptt):data, targets = get_batch(eval_data,i)seq_len = data.size(0)output = model(data)output_flat = output.view(-1,ntokens)total_loss += seq_len * criterion(output_flat, targets).item()return total_loss / (len(eval_data) - 1)best_val_loss = float('inf')
epochs = 1with TemporaryDirectory() as tempdir:best_model_params_path = os.path.join(tempdir, "best_model_params.pt")for epoch in range(1, epochs + 1):epoch_start_time = time.time()train(model)val_loss = evaluate(model, val_data)val_ppl = math_exp(val_loss)elapsed = time.time() - epoch_start_time#打印当前epoch的信息,包括耗时、验证损失和困惑度print('-' * 89)print(f'|end of epoch {epoch:3d} | time:{elapsed: 5.2f}s |'f'valid loss {val_loss:5.2f} | valid ppl {val_ppl: 8.2f}')print('-' * 89)if val_loss < best_val_loss:best_val_loss = val_losstorch.save(model.state_dict(), best_model_params_path)scheduler.step() #更新学习率model.load_state_dict(torch.load(best_model_params_path))
代码输出:
五、总结
加载数据集时,注意包的版本关联关系。另外,注意结合使用优化器提升优化性能。
相关文章:
【NLP练习】Transformer实战-单词预测
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 任务:自定义输入一段英文文本进行预测 一、定义模型 from tempfile import TemporaryDirectory from typing import Tuple from torch import nn…...

使用Lua脚本保证原子性的Redis分布式锁实现
这是原来的代码: Override public void unlock() {// 获取线程标示String threadId ID_PREFIX Thread.currentThread().getId();// 判断标示是否一致String id stringRedisTemplate.opsForValue().get(KEY_PREFIX name);if (threadId.equals(id)) {// 释放锁st…...

什么是nginx到底怎么配置,什么是网关到底怎么配置?
那使用upstream里面具体哪个服务器是怎么决定和区分的呢? AI生成 在Nginx中,使用upstream里面具体哪个服务器是通过负载均衡算法来决定的。upstream块定义了一组服务器,Nginx会根据配置的负载均衡算法来选择一个服务器来处理当前的请求。常见的负载均衡算法包括轮询(round-…...
)
轻量级服务器内存不够编译的情况解决方案(以安装Ta-Lib库为例)
安装 TA-Lib 时遇到的问题通常与系统缺少必要的编译依赖项或者内存不足有关。以下是一些解决步骤,你可以按照这些步骤尝试解决问题: 问题描述:编译安装Tal-ib库出现以下问题: root@tianbaobao12:~/shipan/ta-lib# pip install ta-lib Collecting ta-libUsing cached TA-L…...

学校校园考场电子钟,同步授时,助力考场公平公正-讯鹏科技
随着教育技术的不断发展,学校对于考场管理的需求也日益提高。传统的考场时钟往往存在时间误差、维护不便等问题,这在一定程度上影响了考试的公平性和公正性。为了解决这些问题,越来越多的学校开始引入考场电子钟,通过同步授时技术…...
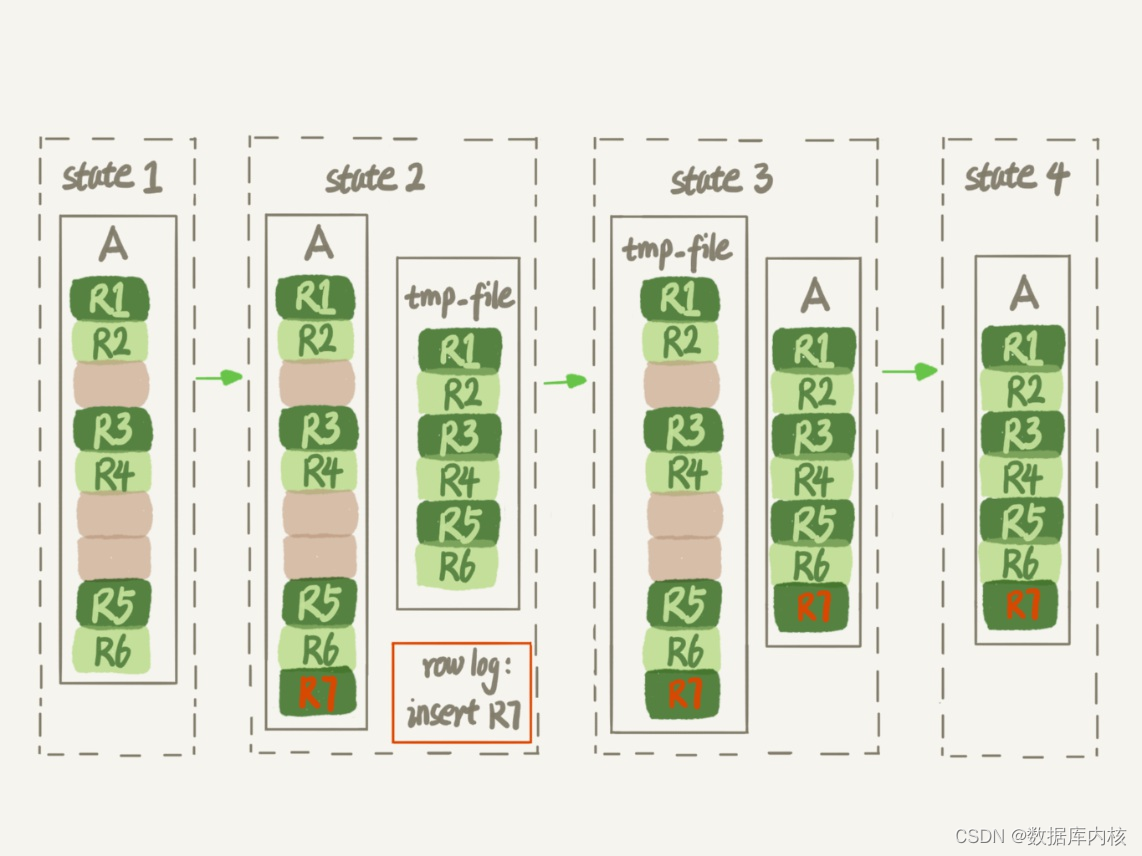
MySQL存储管理(一):删数据
从表中删除数据 从表中删除数据,也即是delete过程。 什么是表空间 表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。默认情况下,InnoDB存储引擎有一个共享表空间idbdata1,即所有数据都存放在这个表…...

深度剖析现阶段的多模态大模型做不了医疗
导读 在人工智能的这波浪潮中,以ChatGPT为首的大语言模型(LLM)不仅在自然语言处理(NLP)领域掀起了一场技术革命,更是在计算机视觉(CV)乃至多模态领域展现出了令人瞩目的潜力。 这些…...
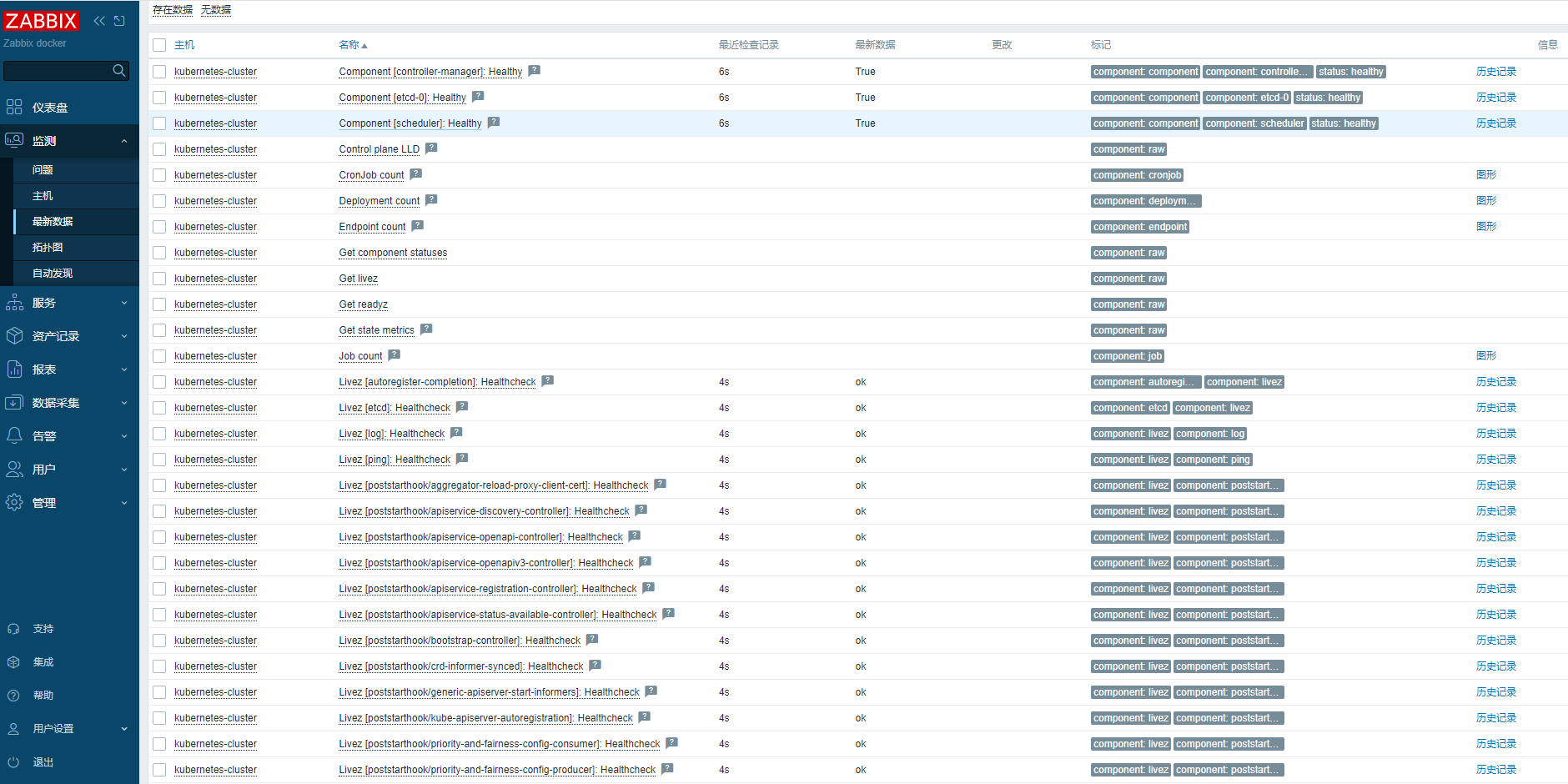
Zabbix 监控 Kubernetes 集群
Zabbix 监控 Kubernetes 集群 Zabbix作为一个成熟且功能强大的监控系统,被许多企业广泛采用。它能够对各种IT基础设施进行全面的监控,包括服务器、网络设备、应用程序等。而将Zabbix与Kubernetes结合,可以实现对Kubernetes集群的全面监控&am…...

网上预约就医取号系统
摘 要 近年来,随着信息技术的发展和普及,我国医疗信息产业快速发展,各大医院陆续推出自己的信息系统来实现医疗服务的现代化转型。不可否认,对一些大型三级医院来说,其信息服务质量还是广泛被大众所认可的。这就更需要…...
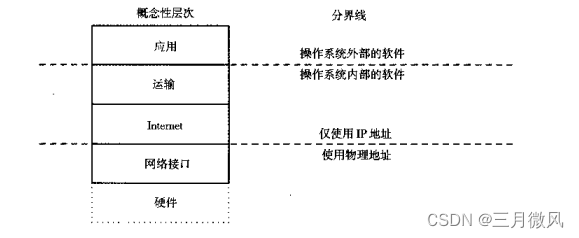
概念描述——TCP/IP模型中的两个重要分界线
TCP/IP模型中的两个重要分界线 协议的层次概念包含了两个也许不太明显的分界线,一个是协议地址分界线,区分出高层与低层寻址操作;另一个是操作系统分界线,它把系统与应用程序区分开来。 高层协议地址界限 当我们看到TCP/P软件的…...

ECharts,拿来吧你!
作为一名前端程序员,在日常的项目开发中,我们会遇到各种各样的图表设计,那么,为了提高我们的开发效率,ECharts便应运而生了!它提供了丰富的图表样式和多浏览器支持的API接口,不仅能够将静态的数据转换为图表,还可以动态的请求后端传递过来的数据,将其以可视化的形式展现给用户,…...

【DICOM】BitsAllocated字段值为8和16时区别
一、读取dicom C# 使用fo-dicom操作dicom文件-CSDN博客 二、DICOM中BitsAllocated字段值为8和16时区别 位深度差异: 当BitsAllocated为8时,意味着每个像素使用8位来表示其灰度值。这允许每个像素有2^8256种不同的灰度等级,适用于那些不需要高…...
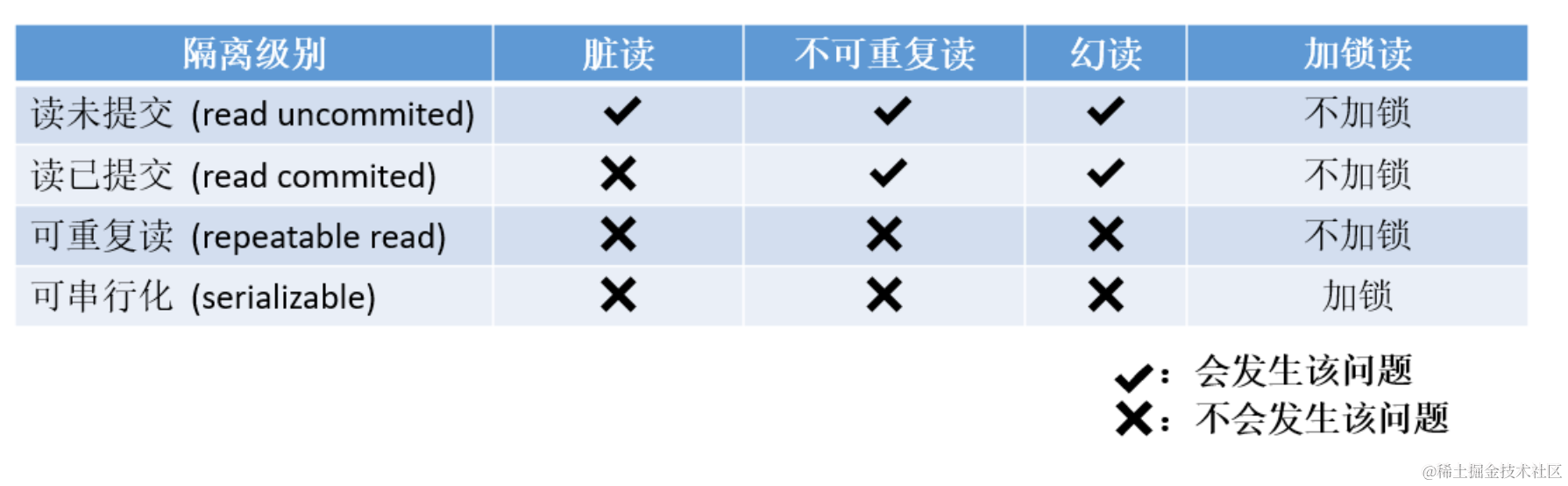
【MySQL】 -- 事务
如果对表中的数据进行CRUD操作时,不加控制,会带来一些问题。 比如下面这种场景: 有一个tickets表,这个数据库被两个客户端机器A和B用时连接对此表进行操作。客户端A检查tickets表中还有一张票的时候,将票出售了&#x…...

c#调用c++生成的dll,c++端使用opencv, c#端使用OpenCvSharp, 返回一张图像
c代码: // OpenCVImageLibrary.cpp #include <opencv2/opencv.hpp> #include <vector> extern "C" { __declspec(dllexport) unsigned char* ReadImageToBGR(const char* filePath, int* width, int* height, int* step) { cv::Mat i…...

【Android面试八股文】你能说一说View绘制流程与自定义View注意点吗?
文章目录 一、自定义View的构造函数以及各参数的用法二、自定义View的几种方式三、自定义View的绘制流程四、自定义View需要注意的一些点五、举个例子一、自定义View的构造函数以及各参数的用法 在Android中,自定义View通常需要提供多个构造函数,以适应不同的使用场景。主要…...
【第24章】Vue实战篇之用户信息展示
文章目录 前言一、准备1. 获取用户信息2. 存储用户信息3. 加载用户信息 二、用户信息1.昵称2.头像 三、展示总结 前言 这里我们来展示用户昵称和头像。 一、准备 1. 获取用户信息 export const userInfoService ()>{return request.get(/user/info) }2. 存储用户信息 i…...
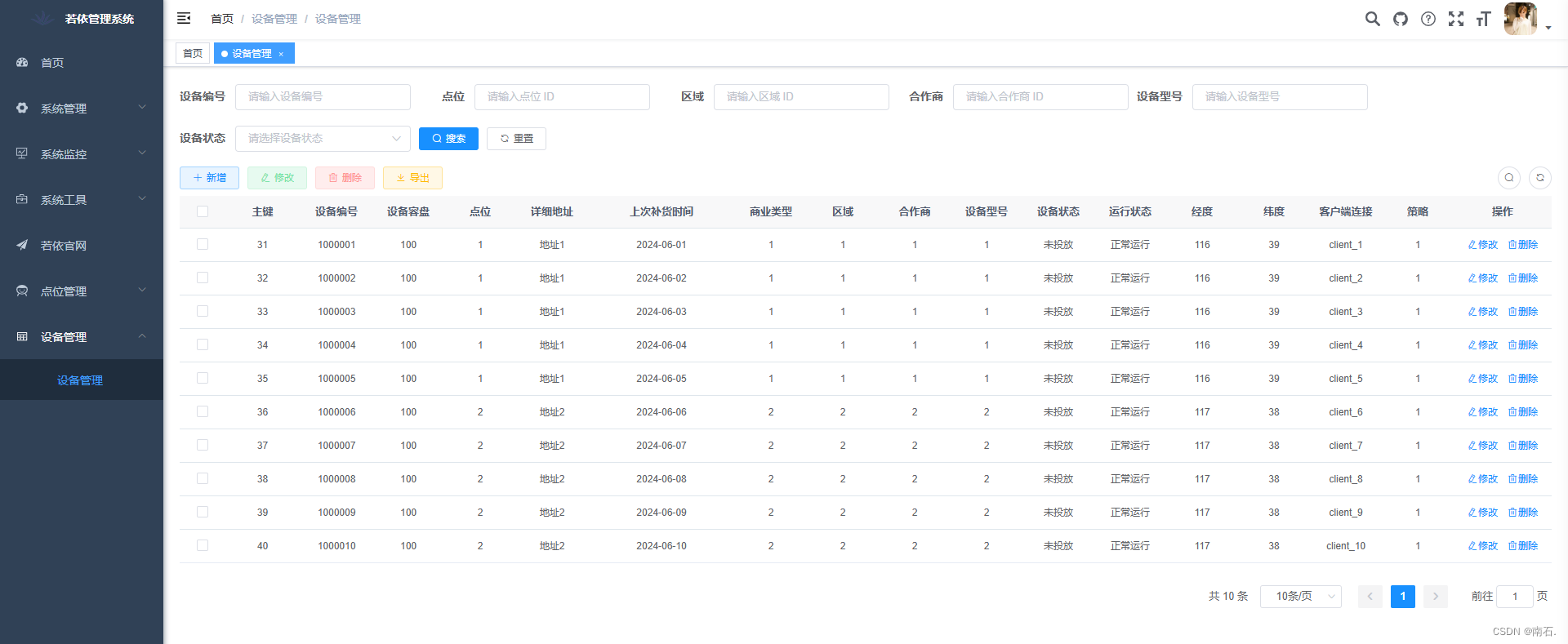
“打造智能售货机系统,基于ruoyi微服务版本生成基础代码“
目录 # 开篇 1. 菜单 2. 字典配置 3. 表配置 3.1 导入表 3.2 区域管理 3.3 合作商管理 3.4 点位管理 4. 代码导入 4.1 后端代码生成 4.2 前端代码生成 5. 数据库代码执行 6. 点位管理菜单顺序修改 7. 页面展示 8. 附加设备表 8.1 新增设备管理菜单 8.2 创建字…...
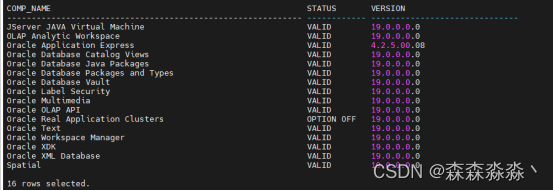
oracle12c到19c adg搭建(五)dg搭建后进行切换19c进行数据字典升级
一、备库切主库升级 12c切换为19c主库的时候是由低版本到高版本所以cdb和pdb的数据字典需要进行升级才可以让数据与软件版本兼容。 1.1切换 SQL> alter database recover managed standby database finish; Database altered. SQL> alter database commit to switcho…...

在公司的一些笔记
6.19 记住挂载在windows上的账户是DAHUATECH\401593,不是401593Windows与linux不能同时挂载在虚拟盘上 6.21 /******************************************************************************* pdc_ledSy7806e.c* * Description: 提供I2C访问sy7806e。 * * …...

2020C++等级考试二级真题题解
202012数组指定部分逆序重放c #include <iostream> using namespace std; int main() {int a[110];int n, k;cin >> n >> k;for (int i 0; i < n; i) {cin >> a[i];}for (int i 0; i < k / 2; i) {swap(a[i], a[k - 1 - i]);}for (int i 0…...

HttpOnly Cookie 深度解析
一、什么是 HttpOnly Cookie HttpOnly 是一个可以附加在 Set-Cookie 响应头上的标志位(flag)。当一个 Cookie 被标记为 HttpOnly 后,客户端脚本(如 JavaScript)将无法通过 document.cookie 等 API 访问该 Cookie&…...

个人自动化技能库构建指南:从Python脚本到Cron定时任务
1. 项目概述:一个为“摸鱼”场景设计的自动化技能库最近在GitHub上看到一个挺有意思的项目,叫my-copaw-skill。光看这个名字,就透着一股子“打工人”的幽默感——“copaw”这个词,我琢磨着应该是“copilot”(副驾驶/助…...
)
保姆级教程:用Python+NumPy复现经典Laplacian曲面编辑算法(附源码)
从理论到代码:Python实现Laplacian曲面编辑的完整指南 在三维图形处理领域,Laplacian曲面编辑技术因其出色的细节保持能力而备受推崇。这项技术允许开发者对三维模型进行直观的变形操作,同时保持模型表面的几何细节不被破坏。本文将带您从零开…...

Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题!
Windows Cleaner终极指南:3分钟彻底解决C盘爆红问题! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统越用越慢而烦恼吗&…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...

OpenClaw实战教程:声明式配置驱动的高效数据抓取方案
1. 项目概述:一个关于“OpenClaw”的实战教程 最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看名字,你可能会有点摸不着头脑,这“OpenClaw”到底是个啥?是某种开源机械爪?还是一个代号&…...

动态提示词工程:让AI提示词具备上下文学习能力的实践指南
1. 项目概述:当提示词遇上上下文学习最近在折腾大语言模型应用时,我反复遇到一个痛点:精心设计的提示词(Prompt)在特定任务上效果拔群,但换个场景或数据,效果就大打折扣。每次都得重新调整、测试…...

微服务架构实战:从DDD设计到K8s部署的完整指南
1. 项目概述与核心价值最近几年,微服务架构的热度一直居高不下,从互联网大厂到初创团队,几乎人人都在谈微服务。但说实话,真正能把微服务玩转、落地,并且能稳定支撑业务发展的团队,其实并不多。很多项目要么…...

毫米波ISAC技术:车联网中的感知与通信融合方案
1. 毫米波ISAC系统概述在智能交通系统快速发展的今天,毫米波集成感知与通信(ISAC)技术正成为解决车联网(V2X)需求的关键方案。这项技术的核心创新点在于,它巧妙地将雷达感知和无线通信两大功能整合到同一硬件平台上,通过共享60GHz毫米波频段资…...

Linux磁盘挂载与开机自启配置
Linux磁盘挂载与开机自启配置磁盘挂载是 Linux 存储管理中的基础操作。很多线上问题都与挂载配置有关,例如重启后数据盘没挂上、路径指向错误分区、应用因挂载点缺失而启动失败。中级阶段不仅要会临时挂载,更要理解永久挂载的配置方式和风险控制。一、先…...