Oracle 数据库表和视图 的操作
1. 命令方式操作数据库(采用SQL*Plus)
1.1 创建表
1.1.1 基本语法格式
CREATE TABLE[<用户方案名>]<表名>
(<列名1> <数据类型> [DEFAULT <默认值>] [<列约束>]<列名2> <数据类型> [DEFAULT <默认值>] [<列约束>]
[,...n]<表约束>[,...n]
)[AS<子查询>]1.1.2 说明
用户方案名
用户方案是指该表所属的用户,如果省略则默认为当前登录的用户
DEFAULT
关键字DEFAULT指定某一列的默认值。默认值的数据类型必须与该列的数据类型相匹配,列的长度必须足以容纳这一表达式的值。
列约束
定义一个完整性约束作为列定义的一部分,该子句的语法为:
NOT NULL UNIQUE PRIMARY KEY REFERENCES[<用户方案名>.]<表名>(<列名>) CHECK(<条件表达式>)NOT NULL: 用于确保列中的值不能为空。
column_name datatype NOT NULLUNIQUE: 用于确保列中的值唯一。
column_name datatype UNIQUEPRIMARY KEY: 用于定义主键,确保列中的值唯一且不为空。通常它结合NOT NULL使用。
column_name datatype PRIMARY KEYREFERENCES [<用户方案名>]<表名>(<列名>): 用于定义外键,确保列中的值在另一个表的指定列中存在。这里有几个注意点:
[<用户方案名>]这个部分是可选的,用于指定数据库方案名称。<表名>和<列名>是必要的,用于指定被引用的表和列。column_name datatype REFERENCES schema_name.table_name(column_name)CHECK (<条件表达式>): 用于确保列中的值满足某些条件。条件表达式必须是合法的布尔表达式。
column_name datatype CHECK (condition)
表约束
定义一个完整性约束作为表定义的一部分、实例如下:
CREATE TABLE 部门 (部门编号 NUMBER PRIMARY KEY,部门名称 VARCHAR2(50) NOT NULL,经理编号 NUMBER,位置编号 NUMBER,CONSTRAINT dept_unique UNIQUE (部门名称) );
AS<子查询>
表示将由子查询返回的行插入到所创建的表中。
使用AS子句时,要注意以下事项:
① 表中的列数必须等于子查询中的表达式数
② 列的定义只能指定列名、默认值和完整性约束,不能指定数据类型
③ 不能在含有 AS 子句的 CREATE TABLE 语句中定义引用完整性。相反,必须先创建没有约束的表,然后再用 ALTER TABLE 语句来添加约束。(即不能在含有 AS 子句的
CREATE TABLE语句中定义引用完整性,必须先创建没有约束的表,然后再用ALTER TABLE语句添加约束。)
Oracle 从子查询中推导出数据类型和长度,同时也遵循下列完整性约束。
① 如果子查询选择列而不是包含列的表达式,Oracle 自动地为新表中的列定义任何 NOT NULL 约束,该列与被选表中的列相一致。
② 如果
CREATETABLE语句同时包含 AS 子句和 CONSTRAINT 子句, Oracle 就忽略 AS 子句。若任何行违反了该约束规则,Oracle都不创建表并返回一个错误信息。③ 如果子查询中的全部表达式是列,则在表定义中可完全忽略这些列。在这种情况下,表的列名和子查询中的列名相同。
示例解释
全部表达式是列
SELECT 员工编号, 姓名, 姓氏, 电子邮件, 入职日期FROM 员工WHERE 入职日期 >= TO_DATE('2023-01-01', 'YYYY-MM-DD');在这个查询中:
- 在这个查询中,选择的每一项(
员工编号,姓名,姓氏,电子邮件,入职日期)都是员工表中的一个列,而不是计算结果或别名。这就是 "全部表达式是列" 的情况。部分或全部表达式不是列
SELECT 员工编号, 姓名 || ' ' || 姓氏 AS 全名, UPPER(电子邮件) AS 大写邮件, 入职日期FROM 员工WHERE 入职日期 >= TO_DATE('2023-01-01', 'YYYY-MM-DD');在这个查询中:
姓名 || ' ' || 姓氏 AS 全名是一个表达式,连接了姓名和姓氏列,并起了一个别名全名。UPPER(电子邮件) AS 大写邮件是一个表达式,将电子邮件列转换为大写,并起了一个别名大写邮件。
示例:
使用 AS 子查询从现有表中创建一个新表,同时插入数据:
CREATE TABLE new_employees ASSELECT employee_id, first_name, last_name, email, hire_dateFROM employeesWHERE hire_date >= TO_DATE('2023-01-01', 'YYYY-MM-DD');在这个例子中,从
employees表中选择hire_date在 2023 年 1 月 1 日及之后的员工,并将这些行插入到新创建的new_employees表中。
1.2 修改表
1.2.1 语法格式
ALTER TABLE <表名>ADD (<列定义1>, <列定义2>, ...),MODIFY (<列修改1>, <列修改2>, ...),DROP (<列名1>, <列名2>, ...);
1.2.2 说明
(1)ADD 子句:用于向表中增加一个新列。
新的列定义和创建表时的列定义的格式一样,一次课添加多个列,中间用逗号隔开。
示例:
添加列:
ALTER TABLE employeesADD (email VARCHAR2(100) NOT NULL, hire_date DATE);添加主键:
ALTER TABLE employeesADD CONSTRAINT pk_employees PRIMARY KEY (employee_id);ALTER TABLE employeesADD CONSTRAINT "pk_employees" PRIMARY KEY (employee_id);主要区别在于前者使用双引号,使得约束名 "pk_employees" 区分大小写,必须以完全相同的大小写形式引用。例如,如果你将来想删除该约束,必须使用完全相同的名称和大小写。
ALTER TABLE employeesDROP CONSTRAINT "pk_employees";而对于不使用双引号的版本,约束名将不区分大小写,你可以使用任何大小写组合来引用该约束。
ALTER TABLE employeesDROP CONSTRAINT PK_EMPLOYEES;一般来说,除非有特殊需要(如保留大小写信息、使用保留字或特殊字符),不建议在标识符中使用双引号,以避免不必要的复杂性。
(2)MODIFY 子句:用于修改表中某列的属性(数据类型、默认值等)。
在修改数据类型时需要注意,如果表中该列所存数据的类型与将要修改的列类型冲突,则会发生错误。例如,原来 char 类型的列要修改为 number 类型,而原来列值中有字符型数据“a”,则无法修改。
示例:
ALTER TABLE employeesMODIFY (salary NUMBER(8,2), job_id VARCHAR2(10) DEFAULT 'IT_PROG');
(3)DROP 子句:该子句用于从表中删除指定的字段或约束。
示例:
ALTER TABLE employeesDROP COLUMN phone_number;ALTER TABLE employeesDROP CONSTRAINT emp_email_uk;
删除 PRIMARY KEY 或 UNIQUE 约束前的注意事项
在关系数据库中,删除主键(PRIMARY KEY)或唯一约束(UNIQUE constraint)之前必须先删除相关的外键约束(FOREIGN KEY constraint),这是因为外键约束依赖于主键或唯一约束来确保引用完整性。下面是更详细的原因:
引用完整性
引用完整性是关系数据库的重要特性之一,用于确保表与表之间的数据关系的一致性。具体来说,引用完整性确保一个表中的外键值必须在另一个表的主键或唯一约束中存在。
解释:
例如,在一个订单表中,
customer_id外键引用了客户表中的customer_id主键,以确保所有订单都属于现有的客户。如果允许在不删除外键约束的情况下直接删除主键或唯一约束,引用完整性就会被破坏。删除主键或唯一约束后,原本依赖这些约束的外键就失去了参照目标,数据库将无法保证这些外键值的有效性,导致数据不一致。例如,删除客户表的主键
customer_id后,订单表中的customer_id就可能引用不存在的客户。因此,为了维持数据一致性和引用完整性,数据库管理系统(DBMS)要求在删除主键或唯一约束之前,必须先删除所有引用这些约束的外键。
这样可以确保在主键或唯一约束被删除时,不会留下任何无效的外键引用。
1.3 删除表
1.3.1 语法格式
DROP TABLE[<用户方案名>]<表名>
1.4 插入记录
1.4.1 语法格式1
INSERT INTO<表名>[(<列名1)>,(<列名2>,...n)]VALUES(<列值1>,<列值2>,...n)说明
列值表和列名表的顺序和数据类型:
- 在插入时,列值表必须与列名表的顺序和数据类型一致。如果不指定表名后面的列名列表,则在
VALUES子句中要给出每一列的值,VALUES中的值要与原表中字段的顺序和数据类型一致,并且不能缺少字段项。
VALUES子句中的值类型:
VALUES中描述的值可以是一个常量、变量或一个表达式。字符串类型的字段必须要用单引号括起来。字符串转换函数TO_DATE可以将字符串形式的日期数据转换成 Oracle 规定的合法的日期型数据。空值处理:
- 如果列值为空,则值必须置为
NULL。如果列值指定为该列的默认值,则用DEFAULT。部分列插入:
- 在对表进行插入行操作时,如果新插入的行中所有可取空值的列均取空值,则可以在
INSERT语句中通过列表指出插入的行值所包含的非空列,并在VALUES中只给出这些列的值。
示例:
示例1:插入所有列的值
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date)VALUES (101, 'John', 'Doe', 'john.doe@example.com', TO_DATE('2023-01-01', 'YYYY-MM-DD'));示例2:插入部分列的值
INSERT INTO employees (employee_id, first_name, last_name)VALUES (102, 'Jane', 'Smith');示例3:插入默认值
INSERT INTO employees (employee_id, first_name, last_name, hire_date)VALUES (103, 'Alice', 'Johnson', DEFAULT);示例4:插入空值
INSERT INTO employees (employee_id, first_name, last_name, email)VALUES (104, 'Bob', 'Brown', NULL);
同样可以使用 INSERT 语句把一个表中的部分数据插入到另一个表中,但结果集中每行数据集的字段数、字段的数据类型要与被操作的表完全一致。
1.4.2 语法格式2
INSERT INTO<表名><结果集>其中,<结果集>是一个由 SELECT 语句查询所得到的新表。
如果要将 table1 中的部分数据插入到 table2 中,可以使用以下 SQL 语句:
INSERT INTO table2 (id, name, age)SELECT id, name, ageFROM table1WHERE age > 30;
然后再运行COMMIT 命令(不可回退)
这将确保所有的更改都被永久性地应用到数据库中。
COMMIT;
1.5 删除记录
1.5.1 DELETE 语句
DELETE FROM <表名> [WHERE <条件>];
删除 table1 中所有年龄大于30的记录:
DELETE FROM table1 WHERE age > 30;
1.5.2 TRUNCATE TABLE 语句
如果要删除一个大表里的全部记录,可以用此语句,他可以释放占用的数据块表空间,此操作不可回退。语法格式为:
TRUNCATE TABLE <表名>;
删除 table1 中所有记录,并释放表空间:
TRUNCATE TABLE table1;
总结
DELETE语句 用于按条件删除表中的记录,可以回退,并保留表的结构和索引。适合删除特定条件下的记录。TRUNCATE TABLE语句 用于删除表中的所有记录,并释放表空间,操作不可回退。适合快速清空大表的所有数据。DELETE语句如果不加WHERE条件,会删除表中的所有记录,但表的结构和索引会保留。
1.6 修改记录
UPDATE 语句可以用来修改表总的数据行,语法格式为:
UPDATE<表名>SET <列名>={<新值>|<表达式>}[,...n][WHERE <条件表达式>]示例:
UPDATE XSBSET 备注='辅修计算机专业'WHERE 学号='15014';UPDATE aSET 总学分=总学分+5;2. 数据库的查询和视图
2.1 选择、投影、连接
2.1.1 选择
选择(Selection),简单来说就是通过一定条件把自己所需要的数据检索出来。选择是单目运算,其对象是一个表。该运算按给定的条件,从表中选出满足条件的行形成一个新表,作为运算结果。
假设有一个表 Employees,包含以下列:
| EmployeeID | FirstName | LastName | Age | Department |
|---|---|---|---|---|
| 1 | John | Doe | 30 | HR |
| 2 | Jane | Smith | 25 | IT |
| 3 | Mike | Brown | 40 | Sales |
如果我们只选择 Age 大于 30 的员工,SQL 查询如下:
SELECT *FROM EmployeesWHERE Age > 30;
查询结果为:
| EmployeeID | FirstName | LastName | Age | Department |
|---|---|---|---|---|
| 3 | Mike | Brown | 40 | Sales |
2.1.2 投影
投影(Projection)也是单目运算。投影就是选择表中指定的列,这样在查询结果中只显示指定数据列,减少了显示的数据量,也可调高查询的性能。
假设我们仍然使用上面的 Employees 表,如果我们只对 FirstName 和 Department 进行投影,SQL 查询如下:
SELECT FirstName, DepartmentFROM Employees;
查询结果为:
| FirstName | Department |
|---|---|
| John | HR |
| Jane | IT |
| Mike | Sales |
组合投影和选择
我们也可以将投影和选择组合在一起使用。例如,我们想选择 Age 大于 30 的员工,并只显示他们的 FirstName 和 Department,SQL 查询如下:
SELECT FirstName, DepartmentFROM EmployeesWHERE Age > 30;
查询结果为:
| FirstName | Department |
|---|---|
| Mike | Sales |
表的选择和投影运算分别从行和列两个方向上分割表,而以下要讨论的连接运算则是对两个表的操作。
2.1.3 连接
连接(JOIN)是把两个表的行按照给定的条件进行拼接而形成新表。
2.1.3.1 等值连接
等值连接是最常见的一种连接方式。它根据两个表中列的相等条件连接表中的行。假设有两个表,表A和表B,通过等值连接可以根据它们某一列的值相等来生成一个新表。
示例:
假设有两个表:
表A:
ID Name 1 Alice 2 Bob 3 Carol 表B:
ID Age 1 25 2 30 4 22 我们希望通过等值连接在ID列上将这两个表连接起来,查询如下:
SELECT A.ID, A.Name, B.AgeFROM AJOIN B ON A.ID = B.ID;连接后的结果为:
ID Name Age 1 Alice 25 2 Bob 30
2.1.3.2 自然连接
自然连接是一种特殊的等值连接,它自动根据两个表中具有相同名称的列进行连接,并且会在结果中去除重复的列。即如果两个表中有相同名称的列,自然连接会使用这些列进行连接,并只保留一份这些列。
示例:
假设有两个表:
表A:
ID Name 1 Alice 2 Bob 3 Carol 表B:
ID Age 1 25 2 30 4 22 我们希望通过自然连接在ID列上将这两个表连接起来,查询如下:
SELECT *FROM ANATURAL JOIN B;连接后的结果为:
ID Name Age 1 Alice 25 2 Bob 30 自然连接会自动根据表A和表B中名称相同的列ID进行连接,并在结果中只保留一份ID列。
总结
- 投影运算是选择表中指定的列,减少显示的数据量。
- 连接运算将两个表按照给定条件拼接形成新表。
- 等值连接根据两个表中列的相等条件进行连接。
- 自然连接自动根据列名相同的列进行连接,并在结果中去除重复的列。
2.2 数据库的查询
SELECT 语句主要的语法格式:
SELECT<列> /*指定要选择的列及其限定*/FROM <表或视图> /*FROM 子句,指定表或视图*/[WHERE <条件表达式>] /*WHERE 子句,指定查询条件*/ [GROUP BY <分组表达式>] /*GROUP BY 子句,指定分组表达式*/[HAVING <分组条件表达式>] /*HAVING 子句,指定分组统计条件*/[ORDER BY <排序表达式>[ASC|DESC]] /*ORDER BY 子句,指定排序表达式和顺序*/下面讨论 SELECT 的基本语法和主要功能。
2.2.1 选择列
选择表中的列组成结果集,语法格式为:
SELECT [ALL|DISTINCT]<列名列表>ALL:默认行为,返回所有符合条件的行,包括重复行。DISTINCT:只返回唯一的行,去除重复的行。
其中<列名列表>指出了结果的形式,其主要格式为:
{ * /*选择当前表或视图的所有列*/|{<表名>|<视图>} * /*选择指定的表或视图的所有列*/|{<列名>|<表达式>.} [[AS}<列别名>] /*选择指定的列*/|<列标题>=<列名表达式> /*选择指定列并更改列标题*/
}[,...n]详细解释和示例
1. 选择当前表或视图的所有列
SELECT *FROM Employees;
这个语句将选择 Employees 表中的所有列。
2. 选择指定的表或视图的所有列
SELECT Employees.*FROM Employees;
这个语句也将选择 Employees 表中的所有列,与上面的语句效果相同。
3. 选择指定的列或表达式
SELECT FirstName, LastName, Age + 5 AS AgePlusFiveFROM Employees;
这个语句选择 FirstName 和 LastName 列,并选择一个表达式 Age + 5,同时将其命名为 AgePlusFive。
4. 为选定的列或表达式指定别名
SELECT FirstName AS FName, LastName AS LName, Age + 5 AS AgePlusFiveFROM Employees;
这个语句选择 FirstName 和 LastName 列,并分别将它们重命名为 FName 和 LName。
5. 选择指定列或表达式并更改列标题
-- 查询,临时重命名列
SELECT FName = FirstName, LName = LastNameFROM Employees;
这一改变仅对当前查询有效,并不会对表的实际结构产生影响。
建议
为了确保 SQL 语句的可移植性和标准化,通常建议使用 AS 来指定别名,除非明确知道目标数据库系统支持 = 并且有特殊的需求。
组合示例
假设我们有一个表 Employees,其结构如下:
| EmployeeID | FirstName | LastName | Age | Department |
|---|---|---|---|---|
| 1 | John | Doe | 30 | HR |
| 2 | Jane | Smith | 25 | IT |
| 3 | Mike | Brown | 40 | Sales |
我们希望选择所有列并且对某些列进行别名处理:
SELECT EmployeeID, FirstName AS FName, LastName AS LName, Age + 5 AS AgePlusFive,DepartmentFROM Employees;
查询结果如下:
| EmployeeID | FName | LName | AgePlusFive | Department |
|---|---|---|---|---|
| 1 | John | Doe | 35 | HR |
| 2 | Jane | Smith | 30 | IT |
| 3 | Mike | Brown | 45 | Sales |
2.2.2 选择行
WHERE <表达式>其中,<条件表达式>为查询条件,格式为:
<条件表达式>::={ [NOT]<判定运算>|(条件表达式)}[{AND|OR} [NOT]{<判定运算>|(条件表达式)}]}[,...n]其中,<判定运算>的结果为TRUE,FALSE或UNKNOWN,经常用到的格式为:
<判定运算>::=
{ <表达式1>{=|<|<=|>|>=|<>|!=}<表达式2> /*比较运算*/|<字符串表达式1>[NOT] LIKE<字符串表达式2>[ESCAPE'<转义字符>'] /*字符串匹配模式*/|<表达式>[NOT] BETWEEN<表达式1>AND<表达式2> /*指定范围*/|<表达式>IS [NOT] NULL /* 是否空值判断*/|<表达式> [NOT] IN (<子查询>|<表达式>[,...n]) /*IN 子句*/|EXIST(<子查询>) /*EXIST 子查询*/
}判定运算包括比较运算、模式匹配、范围比较、空值比较和子查询。
比较时注意限制:
在使用字符串和日期数据进行比较时,注意要符合下面一些限制。
(1)字符串和日期必须是用单引号括起来。
(2)字符串数据区分大小写。
(3)日期数据的格式是敏感的,默认的日期格式是 DD-MM月-YY,可使用 ALTER SESSION 语句将默认日期修改为 YYYY-MM-DD。
SQL> SELECT SYSDATE AS CurrentDateTime2 FROM dual;CURRENTDATETIM
--------------
16-6月 -24SQL>ALTER SESSION SET NLS_DATE_FORMAT = 'YYYY-MM-DD';
说明:
IN 关键字既可以指定范围,也可以表示子查询。
在 SQL 中,返回逻辑值(TRUE 或 FALSE)的运算符或关键字都快称为谓词。
2.2.2.1 表达式比较
<表达式1>{=|<|<=|>|>=|<>|!=}<表达式2> 2.2.2.2 模式匹配
<字符串表达式1>[NOT] LIKE<字符串表达式2>通配符的功能介绍
假设我们有一个表 Employees,其结构如下:
| EmployeeID | FirstName | LastName | Age | Department |
|---|---|---|---|---|
| 1 | John | Doe | 30 | HR |
| 2 | Jane | Smith | 25 | IT |
| 3 | Mike | Brown | 40 | Sales |
①通配符
%
%表示任意数量的字符(包括零个字符)。示例 1:查找姓氏以
S开头的员工SELECT * FROM Employees WHERE LastName LIKE 'S%';结果:
EmployeeID FirstName LastName Age Department 2 Jane Smith 25 IT 示例 2:查找名字包含
e的员工SELECT * FROM Employees WHERE FirstName LIKE '%e%';结果:
EmployeeID FirstName LastName Age Department 2 Jane Smith 25 IT 4 Anna White 22 HR 5 James Black 28 IT 6 Jenna Green 35 Sales
②通配符
_
_表示任意单个字符。示例 3:查找名字的第二个字母是
o的员工SELECT * FROM Employees WHERE FirstName LIKE '_o%';③结合
%和_示例 4:查找名字以
J开头并且长度为 4 个字符的员工SELECT * FROM Employees WHERE FirstName LIKE 'J___';结果:
EmployeeID FirstName LastName Age Department 1 John Doe 30 HR 2 Jane Smith 25 IT
④使用转义字符
假设我们要查找包含
%或_字符的字符串,需要使用ESCAPE关键字定义转义字符。例如,使用\作为转义字符:示例 5:查找名字中包含
%的员工假设我们有一个名字中包含
%字符的员工,例如John%:
EmployeeID FirstName LastName Age Department 7 John% Grey 29 IT SELECT * FROM Employees WHERE FirstName LIKE '%\%%' ESCAPE '\';结果:
EmployeeID FirstName LastName Age Department 7 John% Grey 29 IT 示例 6:查找名字中包含
_的员工假设我们有一个名字中包含
_字符的员工,例如Jane_:
EmployeeID FirstName LastName Age Department 8 Jane_ Blue 26 HR SELECT * FROM Employees WHERE FirstName LIKE '%\_%' ESCAPE '\';结果:
EmployeeID FirstName LastName Age Department 8 Jane_ Blue 26 HR
总结
通配符
%和_在模式匹配中非常强大,可以帮助我们查找符合特定模式的记录。而通过使用ESCAPE关键字,我们还可以查找包含这些通配符本身的字符。了解这些用法有助于在 SQL 查询中实现更复杂和灵活的数据筛选。
2.2.2.3 范围比较
BETWEEN 操作
<表达式>[NOT] BETWEEN<表达式1>AND<表达式2>①
SELECT * FROM Employees WHERE Age BETWEEN 25 AND 35;②
SELECT * FROM Employees WHERE Age NOT BETWEEN 25 AND 35;
IN 操作
<表达式> [NOT] IN (<表达式>[,...n])查找年龄为 25, 30 或 40 的员工:
SELECT * FROM Employees WHERE Age IN (25, 30, 40);结果:
EmployeeID FirstName LastName Age Department 1 John Doe 30 HR 2 Jane Smith 25 IT 3 Mike Brown 40 Sales NOT IN 操作,与上面差不多这里省略。
2.2.2.4 空值比较
语法格式
<表达式> IS [NOT] NULL
示例:
假设我们有一个表
Employees,其结构如下:
EmployeeID FirstName LastName Age Department 1 John Doe 30 HR 2 Jane Smith NULL IT 3 Mike Brown 40 Sales 我们希望找到
Age列中值为空的记录:SELECT * FROM EmployeesWHERE Age IS NULL;结果:
EmployeeID FirstName LastName Age Department 2 Jane Smith NULL IT 我们希望找到
Age列中值不为空的记录:SELECT * FROM EmployeesWHERE Age IS NOT NULL;结果:
EmployeeID FirstName LastName Age Department 1 John Doe 30 HR 3 Mike Brown 40 Sales
2.2.2.5 子查询
语法格式
<表达式> {=|<|<=|>|>=|<>|!=} (子查询)
<表达式> [NOT] IN (子查询)
<表达式> [NOT] EXISTS (子查询)
(1)比较子查询
SELECT EmployeeID, FirstName, LastName, Salary
FROM Employees
WHERE Salary = (SELECT MIN(Salary) FROM Employees WHERE DepartmentID = 10);
(2)IN 子查询
示例:
假设我们有两个表 Employees 和 Departments,结构如下:
Employees 表:
| EmployeeID | FirstName | LastName | Age | Department |
|---|---|---|---|---|
| 1 | John | Doe | 30 | HR |
| 2 | Jane | Smith | 25 | IT |
| 3 | Mike | Brown | 40 | Sales |
Departments 表:
| Department | Location |
|---|---|
| HR | New York |
| IT | San Francisco |
| Sales | Chicago |
我们希望找到 IT 部门的员工:
SELECT * FROM EmployeesWHERE Department = (SELECT Department FROM Departments WHERE Department = 'IT');
结果:
| EmployeeID | FirstName | LastName | Age | Department |
|---|---|---|---|---|
| 2 | Jane | Smith | 25 | IT |
我们希望找到不在 IT 部门的员工:
SELECT * FROM EmployeesWHERE Department <> (SELECT Department FROM Departments WHERE Department = 'IT');
结果:
| EmployeeID | FirstName | LastName | Age | Department |
|---|---|---|---|---|
| 1 | John | Doe | 30 | HR |
| 3 | Mike | Brown | 40 | Sales |
注意:IN 和 NOT IN 子查询只能返回一列数据。对于较复杂的查询,可使用嵌套的子查询。
查询未选修离散数学的学生情况:
SELECT 学号,姓名,专业,总学分FROM XSBWHERE 学号 NOT IN(SELECT 学号FROM CJBWHERE 课程号 IN(SELECT 课程号FROM KCBWHERE 课程号='离散数学'));(3) EXISTS 子查询
假设我们有以下两个表:
Students表(学生表),结构如下:
| StudentID | Name | Major |
|---|---|---|
| 1 | Alice | CS |
| 2 | Bob | Math |
| 3 | Charlie | Physics |
| 4 | David | CS |
Enrollments表(选课表),结构如下:
| StudentID | CourseID |
|---|---|
| 1 | 101 |
| 2 | 102 |
| 3 | 103 |
| 4 | 101 |
| 1 | 102 |
示例 1:EXISTS
查询所有选修了 101 课程的学生信息。
SELECT *
FROM Students
WHERE EXISTS (SELECT 1FROM Enrollments eWHERE e.StudentID = s.StudentID AND e.CourseID = 101
);
解释:
- 外层查询从
Students表中选择所有学生。 - 内层子查询从
Enrollments表中查找CourseID为101的记录,并且匹配Students表中的StudentID。 EXISTS只需检查子查询是否返回任何记录。如果子查询返回至少一条记录,则EXISTS返回TRUE,否则返回FALSE。- 最终结果是所有选修了
101课程的学生。
结果:
| StudentID | Name | Major |
|---|---|---|
| 1 | Alice | CS |
| 4 | David | CS |
示例 2:NOT EXISTS
查询所有没有选修 101 课程的学生信息。
SELECT *
FROM Students
WHERE NOT EXISTS (SELECT 1FROM Enrollments eWHERE e.StudentID = s.StudentID AND e.CourseID = 101
);
无论子查询中是 SELECT 1、SELECT * 还是 SELECT e.CourseID,效果都是相同的,因为 EXISTS 子句只关心子查询是否返回了至少一条记录。
结果:
| StudentID | Name | Major |
|---|---|---|
| 2 | Bob | Math |
| 3 | Charlie | Physics |
2.2.3 查询对象
前面介绍了 SELECT 选择表的列和行的操作,这里介绍 SELECT 查询对象(即数据源)的构成形式。
查找与 151101 号同学所选修课程一致的同学的学号:
SELECT DISTINCT 学号FROM CJB 成绩1WHERE NOT EXISTS(SELECT *FROM CJB 成绩2WHERE 成绩2.学号='151101'AND NOT EXISTS(SELECT *FROM CJB 成绩3WHERE 成绩3.学号=成绩1.学号AND 成绩3.课程号=成绩2.课程号));目标
查询的目的是从
CJB表中找到所有学号,这些学号的学生选修了学号为151101的学生选修过的所有课程。分解解释
外层查询
SELECT DISTINCT 学号 FROM CJB 成绩1 WHERE NOT EXISTS (...)
- 从
CJB表中选择所有不同的学号。成绩1是CJB表的别名。第一层子查询 (
NOT EXISTS)WHERE NOT EXISTS (SELECT *FROM CJB 成绩2WHERE 成绩2.学号 = '151101'AND NOT EXISTS (...) )检查是否不存在这样的记录,这些记录满足条件:
- 成绩2.学号 = '151101':成绩2 中的学号为
151101。- 内层子查询返回结果。
第二层子查询 (
NOT EXISTS)AND NOT EXISTS (SELECT *FROM CJB 成绩3WHERE 成绩3.学号 = 成绩1.学号AND 成绩3.课程号 = 成绩2.课程号 )检查是否不存在这样的记录,这些记录满足条件:
成绩3.学号 = 成绩1.学号:成绩3 中的学号等于外层查询中的学号。成绩3.课程号 = 成绩2.课程号:成绩3 中的课程号等于成绩2 中的课程号。总结
该查询逻辑如下:
- 外层查询遍历
CJB表中的每个成绩1学号。- 第一层子查询检查该学号是否不满足某个条件。
- 该条件是:学号为
151101的学生在成绩2中的每一门课程,在成绩3中是否存在学号为成绩1的学生也选修了该课程。- 如果
成绩1中的学号满足此条件,则表示该学生选修了学号为151101的学生选修过的所有课程。
2.2.4 连接
连接是二元运算,可以对两个或多个表进行查询,结果通常是含有参加连接运算的两个(或多个)表指定列的表。
2.2.4.1 连接谓词
可以在 SELECT 语句的 WHERE 子句中使用比较运算符给出连接条件对表进行连接,将这种表现形式称为连接谓词。
SELECT XSB.*,CJB.*FROM XSB,CJBWHERE XSB.学号=CJB.学号;若选择的字段名在各个表中是唯一的,则可以省略字段名前的表名。例如:
SELECT XSB.*,CJB.课程号,成绩FROM XSB,CJBWHERE XSB.学号=CJB.学号;连接和子查询可能都要涉及两个或多个表,区别是连接可以合并两个或多个表的数据,而带子查询的 SELECT 语句的结果只能来自一个表,子查询的结果是用来作为选择结果数据时进行参照的。
有的查询既可以使用子查询也可以使用连接表达。通常,使用子查询表达式可以将一个复杂的查询分解为一系列逻辑步骤,条理清晰;而使用连接表达有执行速度快的优点。因此,应尽量使用连接表示查询。
2.2.4.2 以 JOIN 关键字指定的连接
连接表的格式:
<表名><连接类型><表名>ON<条件表达式>
|<表名>CROSS JOIN<表名>
|<连接表>其中,<连接类型>的格式:
<连接类型>::={INNER|{LEFT|RIGHT|FULL} [OUTER] CROSS JOIN1. 内连接 (INNER JOIN)
INNER 为默认,可省略
内连接只返回两个表中匹配的记录。简单来说,只有当连接条件满足时,才会返回记录。
示例:
两表连接
假设我们有两个表:
Employees 表
EmployeeID Name DepartmentID 1 Alice 10 2 Bob 20 3 Carol 30 Departments 表
DepartmentID DepartmentName 10 HR 20 IT 40 Finance 查询所有员工及其部门名称:
SELECT e.Name, d.DepartmentName FROM Employees e INNER JOIN Departments d ON e.DepartmentID = d.DepartmentID;结果:
Name DepartmentName Alice HR Bob IT 多表连接
查询选修课成绩在90分以上的学生学号、姓名、课程号、成绩:
SELECT XSB.学号,姓名,课程号,成绩FROM XSBJOIN CJB JOIN KCB ON CJB.课程号 = KCB.课程号ON XSB.学号 = CJB.学号WHERE 成绩>=90;自连接
作为一种特例,可以将一个表与它自身进行连接。
查询不同课程成绩相同的学生的学号、课程号和成绩:
SELECT a.学号,a.课程号,b.课程号,a.成绩FROM CJB a JOIN CJB bON a.成绩=b.成绩 AND a.学号=b.学号 AND a.课程号!=b.课程号;
2. 外连接 (OUTER JOIN)
外连接返回包括不满足连接条件的记录,根据不同类型的外连接会返回左表、右表或两个表的所有记录。
左外连接 (LEFT OUTER JOIN)
左外连接返回左表的所有记录,即使右表中没有匹配的记录,未匹配的右表列用
NULL填充。示例:
查询所有员工及其部门名称,即使某些员工没有对应的部门:
SELECT e.Name, d.DepartmentName FROM Employees e LEFT OUTER JOIN Departments d ON e.DepartmentID = d.DepartmentID;结果:
Name DepartmentName Alice HR Bob IT Carol NULL 右外连接 (RIGHT OUTER JOIN)
右外连接返回右表的所有记录,即使左表中没有匹配的记录,未匹配的左表列用
NULL填充。示例:
查询所有部门及其员工姓名,即使某些部门没有员工:
SELECT e.Name, d.DepartmentName FROM Employees e RIGHT OUTER JOIN Departments d ON e.DepartmentID = d.DepartmentID;结果:
Name DepartmentName Alice HR Bob IT NULL Finance 全外连接 (FULL OUTER JOIN)
全外连接返回两个表的所有记录,不管是否有匹配。未匹配的记录用
NULL填充。示例:
查询所有员工及其部门名称,包括没有对应部门的员工和没有员工的部门:
SELECT e.Name, d.DepartmentName FROM Employees e FULL OUTER JOIN Departments d ON e.DepartmentID = d.DepartmentID;结果:
Name DepartmentName Alice HR Bob IT Carol NULL NULL Finance 注意:外连接只能对两个表进行。
3. 交叉连接
交叉连接实际上是将两个表进行笛卡尔积运算,结果表是有第1个表的每一行与第2个表的每一行拼接后形成的表,因此其行数等于两表行数之积。
列出学生所有可能的选课情况:
SELECT 学号,姓名,课程号,课程名FROM XSB CROSS JOIN KCB;注意:交叉连接也可以使用 WHERE 子句进行条件限定。
2.2.5 汇总
1. 统计函数
SUM 和 AVG 函数
SELECT AVG(成绩) AS 课程101平均成绩FROM CJBWHERE 课程号='101';MAX 和 MIN 函数
SELECT MAX(成绩) AS 课程101的最高分,MIN(成绩) AS 课程101的最低分FORM CJBWHERE 课程号='101';COUNT 函数
SELECT COUNT(*) AS 学生总数FROM XSB;
2. GROUP BY 子句
用于SQL中按一个或多个列对结果集进行分组。
SELECT 课程号,AVG(成绩) AS 平均成绩,COUNT(学号) AS 选修人数FROM CJBGROUP BY 课程号;
3. HAVING 子句
使用 GROUP BY 子句和统计函数对数据进行分组后,还可以使用 HAVING 子句对分组数据进一步筛选。
如查找平均成绩在85分以上的学生和学号和平均成绩。
SELECT 学号,AVG(成绩) AS 平均成绩FROM CJBGROUP BY 学号HAVING AVG(成绩)>=85;
2.2.6 排序
在 Oracle 中,可以使用 ORDER BY 子句对查询结果进行排序。默认情况下,排序是按升序 (ASC),也可以指定为降序 (DESC)。
示例:
按姓氏升序排序:
SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME, SALARYFROM EMPLOYEES
ORDER BY LAST_NAME ASC;
按工资降序排序:
SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME, SALARYFROM EMPLOYEES
ORDER BY SALARY DESC;
按姓氏升序、工资降序排序:
SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME, SALARYFROM EMPLOYEES
ORDER BY LAST_NAME ASC, SALARY DESC;
2.2.7 合并
Oracle 提供了几种合并查询结果的方法,包括 UNION, UNION ALL, INTERSECT 和 MINUS。
UNION 和 UNION ALL:
UNION用于合并两个查询结果,默认去除重复记录。UNION ALL也用于合并两个查询结果,但不去除重复记录。
示例:
假设有两个表 EMPLOYEES 和 MANAGERS,结构如下:
- EMPLOYEES: EMPLOYEE_ID, FIRST_NAME, LAST_NAME
- MANAGERS: MANAGER_ID, FIRST_NAME, LAST_NAME
使用 UNION 合并两个表中的记录:
SELECT FIRST_NAME, LAST_NAME FROM EMPLOYEES
UNION
SELECT FIRST_NAME, LAST_NAME FROM MANAGERS;
使用 UNION ALL 合并两个表中的记录:
SELECT FIRST_NAME, LAST_NAME FROM EMPLOYEES
UNION ALL
SELECT FIRST_NAME, LAST_NAME FROM MANAGERS;
INTERSECT:
INTERSECT返回两个查询的交集,即同时存在于两个查询结果中的记录。
示例:
查询员工和经理中都存在的名字:
SELECT FIRST_NAME, LAST_NAME FROM EMPLOYEES
INTERSECT
SELECT FIRST_NAME, LAST_NAME FROM MANAGERS;
MINUS:
MINUS返回在第一个查询中存在但在第二个查询中不存在的记录。
示例:
查询在员工表中存在但不在经理表中的名字:
SELECT FIRST_NAME, LAST_NAME FROM EMPLOYEES
MINUS
SELECT FIRST_NAME, LAST_NAME FROM MANAGERS;
2.3 数据库视图
2.3.1 视图的概念
视图(View)是基于 SQL 查询的虚拟表,包含了来自一个或多个表的数据。视图不存储实际数据,而是存储一个查询,以便在访问视图时动态生成数据。视图可以简化复杂查询、提高安全性和实现数据抽象。
视图的优点:
- 简化复杂查询:可以将复杂的 SQL 查询封装在视图中,简化用户的操作。
- 安全性:通过限制视图访问,保护底层表的敏感数据。
- 数据抽象:提供与表结构无关的数据视图,便于数据管理和使用。
2.3.2 创建视图
语法格式:
CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW [<用户方案名>.] <视图名>[(<列名>[,...n])] AS<SELECT 查询语句>[WITH CHECK OPTION [CONSTRAINT <约束名>]][WITH READ ONLY]说明
(1)OR REPLACE:如果视图已经存在,则替换现有的视图。这可以避免先删除旧视图再创建新视图的步骤。
(2)FORCE:即使基表不存在或无效,也强制创建视图;NOFORCE:只有在基表存在且有效时才创建视图(默认选项)。
(3)<用户方案名>:指定视图所属的用户或方案。通常省略,默认为当前用户。
(4)(<列名>[,...n]):为视图中的列指定别名。如果省略,使用SELECT语句中的列名。
(5)WITH CHECK OPTION:确保所有通过视图进行的INSERT或UPDATE操作都符合视图的定义条件。
(6)CONSTRAINT <约束名>:为CHECK OPTION定义一个约束名。如果省略,Oracle 会自动生成一个默认名。
(7)WITH READ ONLY:将视图定义为只读,防止通过视图进行INSERT、UPDATE或DELETE操作。基本示例:
CREATE VIEW emp_dept_view AS SELECT e.FIRST_NAME, e.LAST_NAME, d.DEPARTMENT_NAMEFROM EMPLOYEES eJOIN DEPARTMENTS d ON e.DEPARTMENT_ID = d.DEPARTMENT_ID;使用 OR REPLACE 和 列别名:
CREATE OR REPLACE VIEW emp_dept_view (FirstName, LastName, DeptName) AS SELECT e.FIRST_NAME, e.LAST_NAME, d.DEPARTMENT_NAMEFROM EMPLOYEES eJOIN DEPARTMENTS d ON e.DEPARTMENT_ID = d.DEPARTMENT_ID;使用 FORCE:
CREATE FORCE VIEW emp_dept_view AS SELECT e.FIRST_NAME, e.LAST_NAME, d.DEPARTMENT_NAMEFROM EMPLOYEES eJOIN DEPARTMENTS d ON e.DEPARTMENT_ID = d.DEPARTMENT_ID;使用 WITH CHECK OPTION:
CREATE VIEW emp_dept_view AS SELECT e.FIRST_NAME, e.LAST_NAME, d.DEPARTMENT_NAME FROM EMPLOYEES eJOIN DEPARTMENTS d ON e.DEPARTMENT_ID = d.DEPARTMENT_IDWITH CHECK OPTION CONSTRAINT emp_dept_check;使用 WITH READ ONLY:
CREATE VIEW emp_dept_view AS SELECT e.FIRST_NAME, e.LAST_NAME, d.DEPARTMENT_NAMEFROM EMPLOYEES eJOIN DEPARTMENTS d ON e.DEPARTMENT_ID = d.DEPARTMENT_IDWITH READ ONLY;
2.3.3 查询视图
视图创建后,可以像查询表一样查询视图。
查询刚刚创建的视图:
SELECT * FROM emp_dept_view;
2.3.4 更新视图
一般情况下,视图是只读的。保证视图是可更新视图,需要满足以下条件:
① 没有使用连接函数、集合运算函数和组函数:
- 视图中的
SELECT语句不能包含复杂的连接(如多个表的JOIN)、集合运算(如UNION、INTERSECT、MINUS)和聚合函数(如SUM、AVG、MAX、MIN、COUNT)。② 没有
GROUP BY、CONNECT BY、START WITH子句及DISTINCT关键字:
- 视图中的
SELECT语句不能包含任何聚合操作,也不能使用分组、层次查询或去重关键字。③ 不包含从基表列通过计算所得的列:
- 视图中的列必须直接引用基表的列,而不是基于基表列的计算结果。例如,不能在视图中使用诸如
SALARY * 1.1这样的计算列。④ 没有包含只读属性:
- 视图的定义中不能包含
WITH READ ONLY选项。
2.3.5 修改视图的定义
可以使用 CREATE OR REPLACE VIEW 语句来修改视图的定义。
CREATE OR REPLACE VIEW <视图名>
ASSELECT <列名>FROM <表名>WHERE <条件表达式>;
2.3.6 删除视图
DROP VIEW <视图名>;
2.4 含替换变量的查询
Oracle SQL*Plus 提供了使用替换变量的功能,允许用户在运行时输入值,从而提高查询的灵活性。常用的替换变量有单一替换变量(&)、多次替换变量(&&),以及定义和接受命令(DEFINE 和 ACCEPT)。
2.4.1 &替换变量
& 替换变量用于在查询中提示用户输入值。每次执行查询时,用户都会被提示输入一个值。
SELECT * FROM EMPLOYEES WHERE EMPLOYEE_ID = &employee_id;
注意:
替换变量是字符类型或日期类型的数据,输入值必须要用单引号括起来。为了在输入数据是不需要输入单引号,也可以使用在 SELECT 语句中把变量用单引号括起来。
因此,上面的也可以使用如下语句:
SELECT * FROM EMPLOYEES WHERE EMPLOYEE_ID = &'employee_id';
为了在执行变量替换之前,显示如何执行替换的值,可以使用 SET VERIFY 命令
SET VERIFY ON示例:
SQL> SELECT *2 FROM EMPLOYEES3 WHERE HOURLY_RATE>&HOURLY_RATE;
输入 hourly_rate 的值: 20
原值 3: WHERE HOURLY_RATE>&HOURLY_RATE
新值 3: WHERE HOURLY_RATE>20EMPLOYEE_ID EMPLOYEE_NAME HOURLY_RATE
----------- -------------------- -----------4 Emily 22.258 Amy 21.59 Michael 2310 Michelle 24.752.4.2 &&替换变量
&& 替换变量用于多次使用同一个值。用户在第一次输入后,后续的查询中将不会再次提示输入。
查询选修课程超过两门且成绩在75以上的学生的学号:
SELECT &&columnFROM CJBWHERE 成绩>=75GROUP BY &columnHAVING COUNT(*)>2; 用户输入 学号 后,SQL*Plus 会记住这个值。在同一会话中,再次使用 &&column 时,不会提示用户再次输入。
2.4.3 DEFINE 和 ACCEPT 命令
DEFINE 命令:用于创建一个替换变量,并赋予初始值。DEFINE 命令创建的变量在会话期间有效,直到被显式取消(UNDEFINE)。
DEFINE [<变量名>[=<变量值>]]
使用 DEFINE 变量
- 使用
DEFINE命令
如果不带任何参数,直接使用
DEFINE命令,则显示所有用户定义的变量。
DEFINE <变量名>是显示指定变量的值和数据类型。
DEFINE <变量名>=<变量值>是创建一个 CHAR 类型的变量。(由于DEFINE命令创建的变量是字符类型,所以在某些情况下,可能需要特别注意数据类型的隐式转换。例如,如果在查询中使用字符类型的变量进行数值比较或运算,Oracle 会自动进行必要的类型转换。)
假设我们使用 DEFINE 命令创建一个变量,并为其赋值:
DEFINE employee_id = 101
在这个例子中,employee_id 是一个字符类型(CHAR)的变量,尽管它的值看起来像是一个数字。
-- 设置 VERIFY 模式以显示变量替换
SET VERIFY ON;-- 创建一个字符类型的变量
DEFINE employee_id = 101-- 使用变量进行查询
SELECT * FROM EMPLOYEES WHERE EMPLOYEE_ID = &employee_id;
使用 UNDEFINE 取消变量
可以使用 UNDEFINE 命令取消已定义的变量,这样下一次使用该变量时会提示用户重新输入值:
-- 取消变量定义
UNDEFINE employee_id-- 再次提示用户输入变量值
SELECT * FROM EMPLOYEES WHERE EMPLOYEE_ID = &employee_id;
总结
- 使用
DEFINE命令创建的变量默认是字符类型(CHAR)。- 在查询中使用这些变量时,Oracle 会自动处理必要的类型转换。
- 可以使用
UNDEFINE命令取消变量定义,使得下一次使用时重新提示输入值。
ACCEPT 命令
用于提示用户输入一个值,并将该值赋予一个变量。与 DEFINE 不同的是,ACCEPT 会在执行时提示用户输入。
ACCEPT <变量名> [<数据类型>] [FORMAT<格式模式>][PROMPT <提示文本>] [HIDE]基本用法
ACCEPT employee_id PROMPT 'Enter Employee ID: '/*输入一个id*/
SELECT * FROM EMPLOYEES WHERE EMPLOYEE_ID = &employee_id;指定数据类型和格式模式
ACCEPT salary NUMBER FORMAT '99999.99' PROMPT 'Enter Salary: '/*同上*/
SELECT *
FROM EMPLOYEES
WHERE SALARY > &salary;
隐藏输入内容
ACCEPT password CHAR FORMAT 'X' HIDE PROMPT 'Enter Password: 'SELECT *
FROM USERS
WHERE PASSWORD = '&password';
说明:ACCEPT password CHAR FORMAT 'X' HIDE:定义一个名为 password 的字符变量,指定格式模式为 'X'(隐藏输入内容),并且输入时不显示用户输入内容。
注意事项
- 使用
ACCEPT命令定义的变量,可以在同一个会话中多次使用。- 可以通过
UNDEFINE <变量名>命令取消已定义的变量,以便重新定义或重新输入。
本篇分享到此为止,感谢支持~🌹
相关文章:

Oracle 数据库表和视图 的操作
1. 命令方式操作数据库(采用SQL*Plus) 1.1 创建表 1.1.1 基本语法格式 CREATE TABLE[<用户方案名>]<表名> (<列名1> <数据类型> [DEFAULT <默认值>] [<列约束>]<列名2> <数据类型> [DEFAULT <默认…...

美国ARC与延锋安全合作,推动汽车安全气囊技术新突破
在汽车安全领域,安全气囊作为关键被动安全配置,对于保障乘客生命安全至关重要。随着汽车工业的快速发展和科技创新的持续推进,安全气囊技术的升级与革新显得尤为重要。2022年10月25日,美国ARC公司与延锋安全携手合作,共…...

Docker:centos79-docker-compose安装记录
1.安装环境:centos7.9 x86 2.安装最新版: [rootlocalhost ~]# curl -fsSL get.docker.com -o get-docker.sh [rootlocalhost ~]# sh get-docker.sh # Executing docker install script, commit: e5543d473431b782227f8908005543bb4389b8desh -c yum in…...
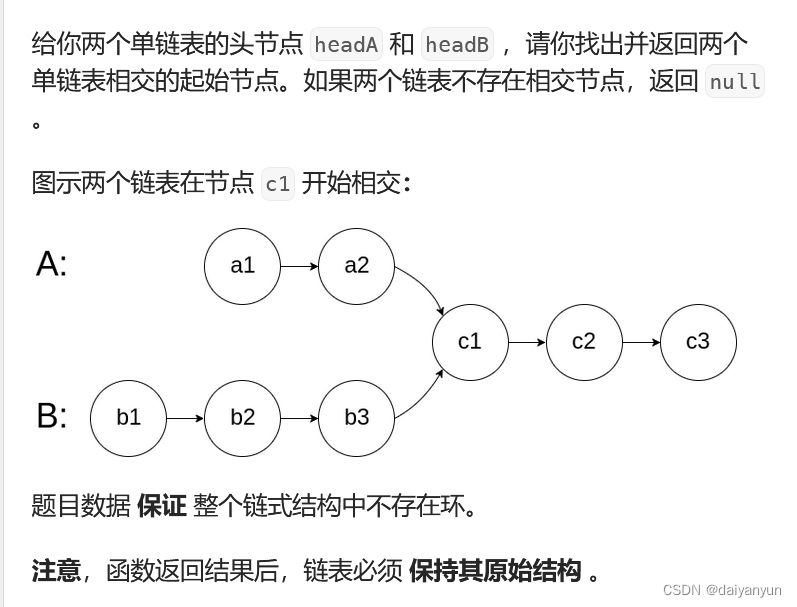
相交链表(Leetcode)
题目分析: . - 力扣(LeetCode) 相交链表:首先我想到的第一个思路是:如图可知,A和B链表存在长度差,从左边一起遍历链表不好找交点,那我们就从后面开始找,但是这是单链表&…...
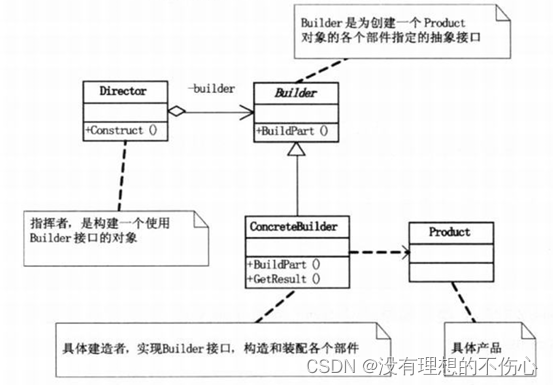
建造者模式(大话设计模式)C/C++版本
建造者模式 C 参考:https://www.cnblogs.com/Galesaur-wcy/p/15907863.html #include <iostream> #include <vector> #include <algorithm> #include <string> using namespace std;// Product Class,产品类,由多个…...

【地质灾害监测实现有效预警,44人提前安全转移】
6月13日14时,国信华源地质灾害监测预警系统提前精准预警,安全转移10户44人。 该滑坡隐患点通过科学部署国信华源裂缝计、倾角加速度计、雨量计、预警广播等自动化、智能化监测预警设备,实现了对隐患点裂缝、位移、降雨量等关键要素的实时动态…...

Ruby 数据库访问 - DBI 教程
Ruby 数据库访问 - DBI 教程 本文将详细介绍如何使用 Ruby 的 DBI(Database Interface)库来访问和操作数据库。DBI 是 Ruby 语言中一个常用的数据库接口库,它提供了一套统一的接口来访问不同的数据库系统,如 MySQL、PostgreSQL、SQLite 等。通过本文的学习,您将掌握如何使…...
Linux环境搭建之CentOS7(包含静态IP配置)
🔥 本文由 程序喵正在路上 原创,CSDN首发! 💖 系列专栏:虚拟机 🌠 首发时间:2024年6月22日 🦋 欢迎关注🖱点赞👍收藏🌟留言🐾 安装VMw…...
Dell戴尔灵越Inspiron 16 Plus 7640/7630笔记本电脑原装Windows11下载,恢复出厂开箱状态预装OEM系统
灵越16P-7630系统包: 链接:https://pan.baidu.com/s/1Rve5_PF1VO8kAKnAQwP22g?pwdjyqq 提取码:jyqq 灵越16P-7640系统包: 链接:https://pan.baidu.com/s/1B8LeIEKM8IF1xbpMVjy3qg?pwdy9qj 提取码:y9qj 戴尔原装WIN11系…...

.NET C# 装箱与拆箱
.NET C# 装箱与拆箱 目录 .NET C# 装箱与拆箱1 装箱 (Boxing)1.1 过程:1.2 示例: 2 拆箱 (Unboxing)2.1 过程:2.2 示例: 3 性能影响4 性能优化4.1 使用泛型集合示例: 4.2 使用Nullable<T>示例: 4.3 避…...

springboot与flowable(9):候选人组
act_id_xxx相关表存储了所有用户和组的数据。 一、维护用户信息 Autowiredprivate IdentityService identityService;/*** 维护用户*/Testvoid createUser() {User user identityService.newUser("zhangsan");user.setEmail("zhangsanqq.com");user.setF…...

为什么要选择华为 HCIE-Security 课程?
2020 年我国网络安全市场规模达到 680 亿元,同比增长 25%。随着对网络安全的愈加重视及布局,市场规模将持续扩大。 近年来,随着“云大物工移智”等新兴技术的快速发展和普及应用,数字化已经融入社会经济生活的方方面面,…...

C++之std::queue::emplace
std::queue::emplace 是 C STL 中 std::queue 容器的成员函数,它用于在队列的末尾就地构造一个新元素。这个函数类似于 std::queue::push,但是 emplace 允许你通过传递参数来构造元素,而不需要显式地创建一个元素对象。 理解 std::queue::em…...

Vue3 - 在项目中使用vue-i18n不生效的问题
检查和配置 Vue I18n 确保你已经正确安装了Vue I18n并且配置了组合API模式。 安装 Vue I18n npm install vue-i18nnext配置 i18n.js import { createI18n } from vue-i18n; import messages from ./messages;const i18n createI18n({legacy: false, // 使用组合 API 模式l…...

Day 44 Ansible自动化运维
Ansible自动化运维 几种常用运维工具比较 Puppet —基于 Ruby 开发,采用 C/S 架构,扩展性强,基于 SSL,远程命令执行相对较弱ruby SaltStack —基于 Python 开发,采用 C/S 架构,相对 puppet 更轻量级,配置语法使用 YAML,使得配置脚本更简单 Ansible —基于 …...

Excel/WPS《超级处理器》功能介绍与安装下载
超级处理器是基于Excel或WPS开发的一款插件,拥有近300个功能,非常简单高效的处理表格数据,安装即可使用。 点击此处:超i处理器安装下载 Excel菜单,显示如下图所示: WPS菜单显示,如下图所示&am…...

U-Net for Image Segmentation
1.Unet for Image Segmentation 笔记来源:使用Pytorch搭建U-Net网络并基于DRIVE数据集训练(语义分割) 1.1 DoubleConv (Conv2dBatchNorm2dReLU) import torch import torch.nn as nn import torch.nn.functional as F# nn.Sequential 按照类定义的顺序去执行模型&…...

POI导入带有合并单元格的excel,demo实例,直接可以运行
直接可以运行 import org.apache.poi.hssf.usermodel.HSSFWorkbook; import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet; import org.apache.poi.ss.usermodel.Workbook; import org.apache.poi.s…...

【C语言】解决C语言报错:Use-After-Free
文章目录 简介什么是Use-After-FreeUse-After-Free的常见原因如何检测和调试Use-After-Free解决Use-After-Free的最佳实践详细实例解析示例1:释放内存后未将指针置为NULL示例2:多次释放同一指针示例3:全局或静态指针被释放后继续使用示例4&am…...

C语言经典例题-19
1.字符串左旋结果 题目内容:写一个函数,判断一个字符串是否为另外一个字符串旋转之后的字符串。 例:给定s1 AABCD和s2 BCDAA,返回1 给定s1 abcd和s2 ACBD,返回0 AABCD左旋一个字符得到ABCDA AABCD左旋两个字符得到BCDAA AABCD右旋一…...

避坑指南:Teamcenter 13四层架构安装中,Weblogic域创建与部署的那些“坑”
Teamcenter 13四层架构部署实战:Weblogic域创建与部署全流程避坑指南 在工业PLM领域,Teamcenter的四层架构部署一直是系统管理员的技术试金石。特别是Weblogic中间件层的配置,往往成为项目推进道路上的"拦路虎"。我曾参与过多个汽…...

避坑指南:Vivado增量综合的‘甜蜜区’与‘雷区’——从日志文件看何时该用、何时该弃
Vivado增量综合实战决策手册:如何精准识别高效区间与风险边界 在FPGA开发领域,时间就是竞争力。当项目进入迭代优化阶段,每次按下综合按钮后的等待时间,都可能成为团队效率的隐形杀手。Vivado的增量综合功能就像一把双刃剑——用对…...

3步搞定Football Manager面部包管理:NewGAN-Manager完全指南
3步搞定Football Manager面部包管理:NewGAN-Manager完全指南 【免费下载链接】NewGAN-Manager A tool to generate and manage xml configs for the Newgen Facepack. 项目地址: https://gitcode.com/gh_mirrors/ne/NewGAN-Manager 你是否厌倦了在Football M…...

5分钟快速上手:OBS实时字幕插件终极配置指南
5分钟快速上手:OBS实时字幕插件终极配置指南 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin 想要为你的直播或录播内容添加专业的实…...

创新设计与智能系统设计融合
在智能制造与工业大模型时代,创新设计(以生成式AI、变型衍生、大规模定制为核心)与智能系统设计(以端-边-云协同、工业智能体、自主控制为核心)的融合,是制造企业实现研发与生产双向闭环的终极路径 。两者的…...

【亲测免费】 ImageNet标签文件及读取脚本:加速您的计算机视觉研究
ImageNet标签文件及读取脚本:加速您的计算机视觉研究 【下载地址】ImageNet标签文件及读取脚本 ImageNet 标签文件及读取脚本 项目地址: https://gitcode.com/open-source-toolkit/56c9e 项目介绍 在计算机视觉领域,ImageNet数据集是图像分类任务…...

04_运算符表达式与类型转换
运算符、表达式与类型转换 一、本篇文章要解决什么问题 你已经知道怎么定义变量、怎么输入输出了。但程序光有数据不行,还得对数据做运算——加减乘除、比较大小、逻辑判断。 这篇文章就帮你搞定三件事: C 语言里有哪些运算符?算术的、赋值的…...

别再为焊缝偏差头疼了!手把手教你用ROBOGUIDE V9.4配置FANUC机器人电弧跟踪
工业机器人焊接精度革命:FANUC电弧跟踪技术实战解析 焊接车间里刺眼的弧光下,老师傅擦了擦护目镜上的焊渣,第3次调整机器人路径——这批不锈钢管件的装配误差比预期大了0.8毫米,传统示教点焊出的焊缝像醉汉走路般歪歪扭扭。这正是…...

G-Helper深度解析:如何用1MB工具彻底替代华硕Armoury Crate
G-Helper深度解析:如何用1MB工具彻底替代华硕Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenboo…...

国产巴伦替代 Mini-Circuits TCM1‑63AX+,H3‑TCM1‑63AX+ 现货可原位替代
最近很多做射频 / 通信 / 无线项目的朋友都在找Mini TCM1‑63AX 的国产替代,既要性能对标、又要现货快交、还要价格友好。给大家分享一款恒利泰 H3‑TCM1‑63AX,完全原位替代 TCM1‑63AX,参数一致、脚位兼容,直接替换不用改板。 ✅…...