Redis源码学习:Redis对象和5种数据类型的工作原理
Redis 提供 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(哈希)、Zset(有序集合),这些数据类型可以供用户直接使用。
RedisObject
RedisObject 是 Redis 中的一个数据结构,表示 Redis 中的所有数据类型(字符串、列表、集合、有序集合和哈希)的统一抽象。定义如下:
typedef struct redisObject {// 表示对象的类型,比如字符串、列表、集合等unsigned type:4;// 表示对象的编码方式,不同的编码方式在内存中的存储形式不同unsigned encoding:4;// 用于 LRU 或 LFU 过期策略unsigned lru:LRU_BITS;// 引用计数,用于内存管理int refcount;// 指向实际数据的指针void *ptr;
} robj;
5种数据类型及实现
String
字符串是最常用的 Redis 数据类型,可以存储普通文本或二进制数据。字符串的实现主要有三种编码方式:
RAW:使用普通的动态字符串(SDS,Simple Dynamic String),存储上限时 512 mb(但是,你不能这么干)。EMBSTR:优化的 SDS 存储方式,用于小于等于 44 字节的字符串,此时 object head 与 SDS 是一段连续的空间。申请内存时只需要一次内存分片,效率更高。INT:用于表示可以用整数存储的字符串,且大小在 LONG_MAX 范围内,直接将数据保存在 RedisObject 的 ptr 指针位置(8字节),不再需要 SDS 了。
List
列表是一种有序的字符串链表,现在只使用 quicklist 实现 List。
在 object.c 文件中可以找到创建列表对象的代码:
robj *createQuicklistObject(void) {quicklist *l = quicklistCreate();robj *o = createObject(OBJ_LIST,l);o->encoding = OBJ_ENCODING_QUICKLIST;return o;
}在插入元素时,使用的也是 quicklist:
void listTypePush(robj *subject, robj *value, int where) {if (subject->encoding == OBJ_ENCODING_QUICKLIST) {int pos = (where == LIST_HEAD) ? QUICKLIST_HEAD : QUICKLIST_TAIL;if (value->encoding == OBJ_ENCODING_INT) {char buf[32];ll2string(buf, 32, (long)value->ptr);quicklistPush(subject->ptr, buf, strlen(buf), pos);} else {quicklistPush(subject->ptr, value->ptr, sdslen(value->ptr), pos);}} else {serverPanic("Unknown list encoding");}
}
Set
集合是一组无序的字符串集合,集合中的元素是唯一的,查询效率高。集合的实现有两种主要的编码方式:
INTSET:整数集合,用于存储数据都是整数,数量不超过 set-max-intset-entriesHT:哈希表,用于存储字符串的大集合,dic 中的 key 存储元素,value 都是 null。
创建集合
在创建集合对象时,通过对 value 的类型判断,来选择不同的编码:
robj *setTypeCreate(sds value) {// 判断 value 是否是数值类型Long Long,如果是数值类型,采用 IntSet 编码// 否则,采用 HT 编码if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)return createIntsetObject();return createSetObject();
}
选择编码方式的逻辑
int setTypeAdd(robj *subject, sds value) {long long llval;if (subject->encoding == OBJ_ENCODING_HT) {// 已经是 HT 编码,直接添加元素dict *ht = subject->ptr;dictEntry *de = dictAddRaw(ht,value,NULL);if (de) {dictSetKey(ht,de,sdsdup(value));dictSetVal(ht,de,NULL);return 1;}} else if (subject->encoding == OBJ_ENCODING_INTSET) {if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {// 目前是 IntSet// 判断 value 是否是整数uint8_t success = 0;// 是整数,直接添加元素到 setsubject->ptr = intsetAdd(subject->ptr,llval,&success);if (success) {// 当intset 元素数量超过 set_max_intset_entries,则转为 HT/* Convert to regular set when the intset contains* too many entries. */size_t max_entries = server.set_max_intset_entries;/* limit to 1G entries due to intset internals. */if (max_entries >= 1<<30) max_entries = 1<<30;if (intsetLen(subject->ptr) > max_entries)setTypeConvert(subject,OBJ_ENCODING_HT);return 1;}} else {// 不是整数,直接转为 HT/* Failed to get integer from object, convert to regular set. */setTypeConvert(subject,OBJ_ENCODING_HT);/* The set *was* an intset and this value is not integer* encodable, so dictAdd should always work. */serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);return 1;}} else {serverPanic("Unknown set encoding");}return 0;
}
Zset
有序集合(ZSet)的实现主要有两种编码方式:压缩列表(ziplist)和跳表(skiplist)。
定义
在 server.h 文件中,zset 结构体的定义如下:
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
创建集合
在 t_zset.c 文件中,可以找到创建有序集合对象的代码:
robj *createZsetObject(void) {zset *zs = zmalloc(sizeof(*zs));robj *o;zs->dict = dictCreate(&zsetDictType, NULL);zs->zsl = zslCreate();o = createObject(OBJ_ZSET, zs);o->encoding = OBJ_ENCODING_SKIPLIST;return o;
}
当元素数量不多时,HT 和 Skiplist 的优势不明显,而且更耗内存。因此,在满足以下条件的情况下,Zset 会采用 Ziplist 来节省内存。
- 元素数量小于 zset-max-ziplist-entries,默认值 128
- 每个元素都小于 zset-max-ziplist-value 字节,默认值 64
// zadd 添加元素时,先根据 key 找到 zset,不存在则创建新的 zset
zobj = lookupKeyWrite(c->db,key);
if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;
if (zobj == NULL) {if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */// zset_max_ziplist_entries 设置为0就是禁用了ziplist// 或者 value 大小超过了 zset_max_ziplist_value,采用 HT + Skiplistif (server.zset_max_ziplist_entries == 0 ||server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr)){zobj = createZsetObject();} else {// 否则,采用 ziplistzobj = createZsetZiplistObject();}dbAdd(c->db,key,zobj);
}// 采用 ziplist 编码
robj *createZsetZiplistObject(void) {unsigned char *zl = ziplistNew();robj *o = createObject(OBJ_ZSET, zl);o->encoding = OBJ_ENCODING_ZIPLIST;return o;
}
选择编码方式的逻辑
在有序集合的插入操作中,Redis 会根据特定条件选择编码方式。在插入操作中,Redis 会检查 zobj 的编码类型,如果是 ZIPLIST 编码,会进行 ziplist 相关的操作;如果是 SKIPLIST 编码,会进行 skiplist 相关的操作。源码如下:
int zsetAdd(robj *zobj, double score, sds ele, int *incr, double *newscore) {if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {// 使用 ziplist 进行插入操作的代码// 如果 ziplist 超过一定大小,会转换为 skiplist} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {// 使用 skiplist 进行插入操作的代码}return 1;
}
判断是否需要转换
在 t_zset.c 文件中的 zsetAdd 函数中,有一个逻辑会判断是否需要将 ziplist 转换为 skiplist:
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {// 如果 ziplist 的元素数量超过一定阈值,或者单个元素的长度超过一定阈值if (ziplistLen(zobj->ptr) > server.zset_max_ziplist_entries ||ziplistBlobLen(zobj->ptr) > server.zset_max_ziplist_value){zsetConvert(zobj, OBJ_ENCODING_SKIPLIST);}
}
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有 zset 通过编码实现:
- ziplist是连续内存,因此 score 和 element 是紧挨在一起的两个 entry,element 在前, score 在后
- score 越小越接近队首,score 越大越接近队尾,按照 score 值升序排列
Hash
Hash 底层采用的编码与 Zset 基本一致,只需要把排序相关的 Skiplist 去掉即可。
创建哈希
在 t_hash.c 文件中,可以找到创建哈希对象的代码:
robj *createHashObject(void) {unsigned char *zl = ziplistNew();robj *o = createObject(OBJ_HASH, zl);o->encoding = OBJ_ENCODING_ZIPLIST;return o;
}
Hash 结构默认采用 ziplist 编码,用来节省内存。 ziplist 中相邻的两个 entry 分别保存 field 和 value。
选择编码方式的逻辑
在 t_hash.c 文件中的 hashTypeSet 函数中,会判断是否需要将 ziplist 转换为 hashtable
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {int i;size_t sum = 0;// 已经是 ziplist 编码了,就什么都不做if (o->encoding != OBJ_ENCODING_ZIPLIST) return;// 依次遍历命令种的 field、valuefor (i = start; i <= end; i++) {if (!sdsEncodedObject(argv[i]))continue;size_t len = sdslen(argv[i]->ptr);// 如果 field 或 value 超过了hash_max_ziplist_value,则转为 hashtableif (len > server.hash_max_ziplist_value) {hashTypeConvert(o, OBJ_ENCODING_HT);return;}sum += len;}// ziplist 大小超过 1g,也要转if (!ziplistSafeToAdd(o->ptr, sum))hashTypeConvert(o, OBJ_ENCODING_HT);
}
当满足4个条件中的任意一个时,需要转换:
ziplist的元素数量是否超过server.hash_max_ziplist_entries(默认 512 )ziplist的大小超过 1G- field 或 value 的长度是否超过
server.hash_max_ziplist_value(默认 64 字节)
总结
本文讲解了什么Redis对象,已经面向用户的5种常用数据类型的底层逻辑,希望对你有帮助。
相关文章:

Redis源码学习:Redis对象和5种数据类型的工作原理
Redis 提供 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(哈希)、Zset(有序集合),这些数据类型可以供用户直接使用…...
从理论到实践掌握UML
统一建模语言(UML)是软件工程师用来设计软件系统的一种工具,就像是一套图形化的说明书。它让开发团队能够以图形化的方式来理解、设计和开发软件系统,比起用文字来描述,更加直观易懂。本文通过UML实例化的理论和实践相…...
LabVIEW Windows与RT系统的比较与选择
LabVIEW是一种系统设计和开发环境,广泛应用于各类工程和科学应用中。LabVIEW Windows和LabVIEW RT(Real-Time)是LabVIEW的两个主要版本,分别适用于不同的应用场景。以下从多个角度详细分析两者的区别,并提供选择建议。…...
docker搭建mongo副本集
1、mongo集群分类 MongoDB集群有4种类型,分别是主从复制、副本集、分片集群和混合集群。 MongoDB的主从复制是指在一个MongoDB集群中,一个节点(主节点)将数据写入并同步到其他节点(从节点)。主从复制提供…...
关于Pytorch转换为MindSpore的一点建议
一、事先准备 必须要对Mindspore有一些了解,因为这个框架确实有些和其它流程不一样的地方,比如算子计算、训练过程中的自动微分,所以这两个课程要好好过一遍,官网介绍文档最好也要过一遍 1、零基础Mindspore:https://…...

JetBrains IDEA 新旧UI切换
JetBrains IDE 新旧UI切换 IntelliJ IDEA 的老 UI 以其经典的布局和稳定的性能,成为了许多开发者的首选。而新 UI 则在此基础上进行了全面的改进,带来了更加现代化、响应式和高效的用户体验。无论是新用户还是老用户,都可以通过了解和适应这…...

iOS KeychainAccess的了解与使用
KeychainAccess 是一个用于 iOS、macOS、tvOS 和 watchOS 上的 Swift 密钥链访问库。它提供了一个简单且安全的 API,用于在设备的密钥链中存储和检索数据。 KeychainAccess 的一些主要特点包括: 简单易用的 API:该库提供了一个直观的 API,可以轻松地将数据存储和检…...
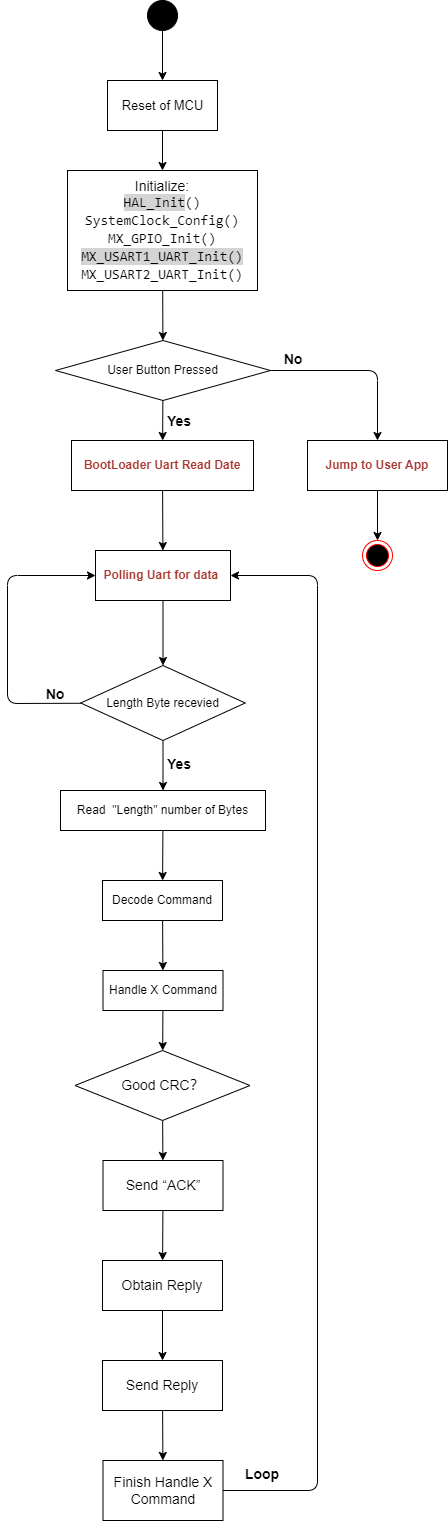
STM32 Customer BootLoader 刷新项目 (二) 方案介绍
STM32 Customer BootLoader 刷新项目 (二) 方案介绍 文章目录 STM32 Customer BootLoader 刷新项目 (二) 方案介绍1. 需求分析2. STM32 Memery介绍3. BootLoader方案介绍4. 支持指令 1. 需求分析 首先在开始编程之前,我们先详细设计一下BootLoder的方案。 本项目做…...
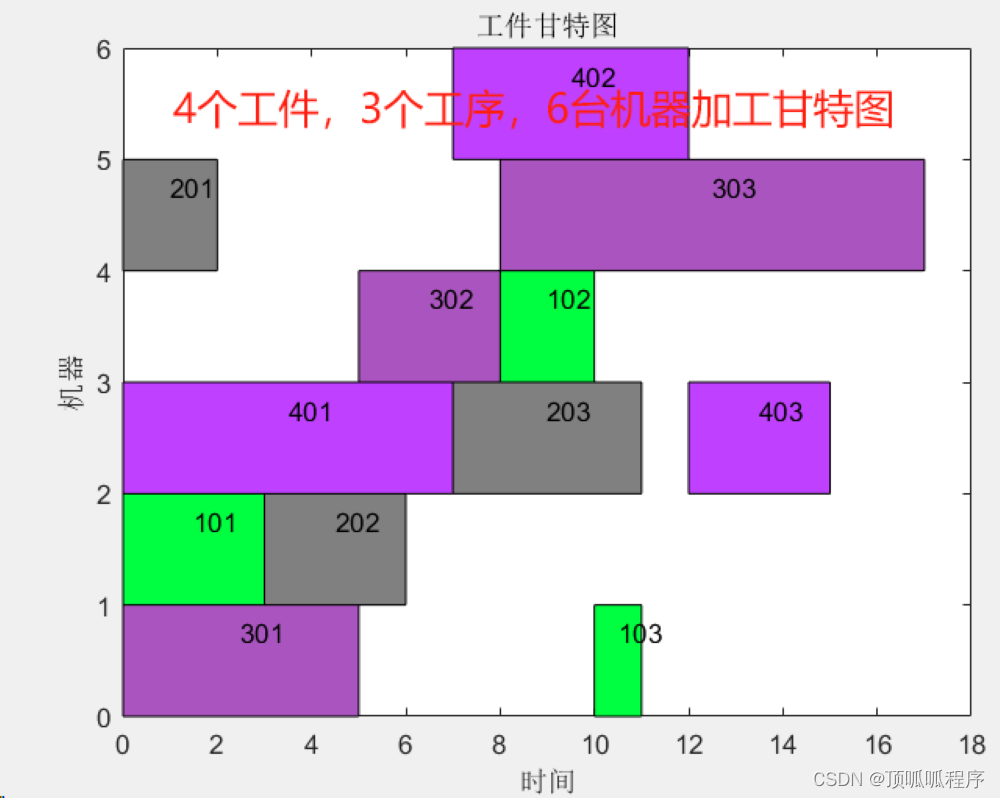
2-14 基于matlab的GA优化算法优化车间调度问题
基于matlab的GA优化算法优化车间调度问题。n个工作在m个台机器上加工。已知每个工作中工序加工顺序、各工序的加工时间以及每个工件所包含的工序,在满足约束条件的前提下,目的是确定机器上各工件顺序,以保证某项性能指标最优。程序功能说明&a…...
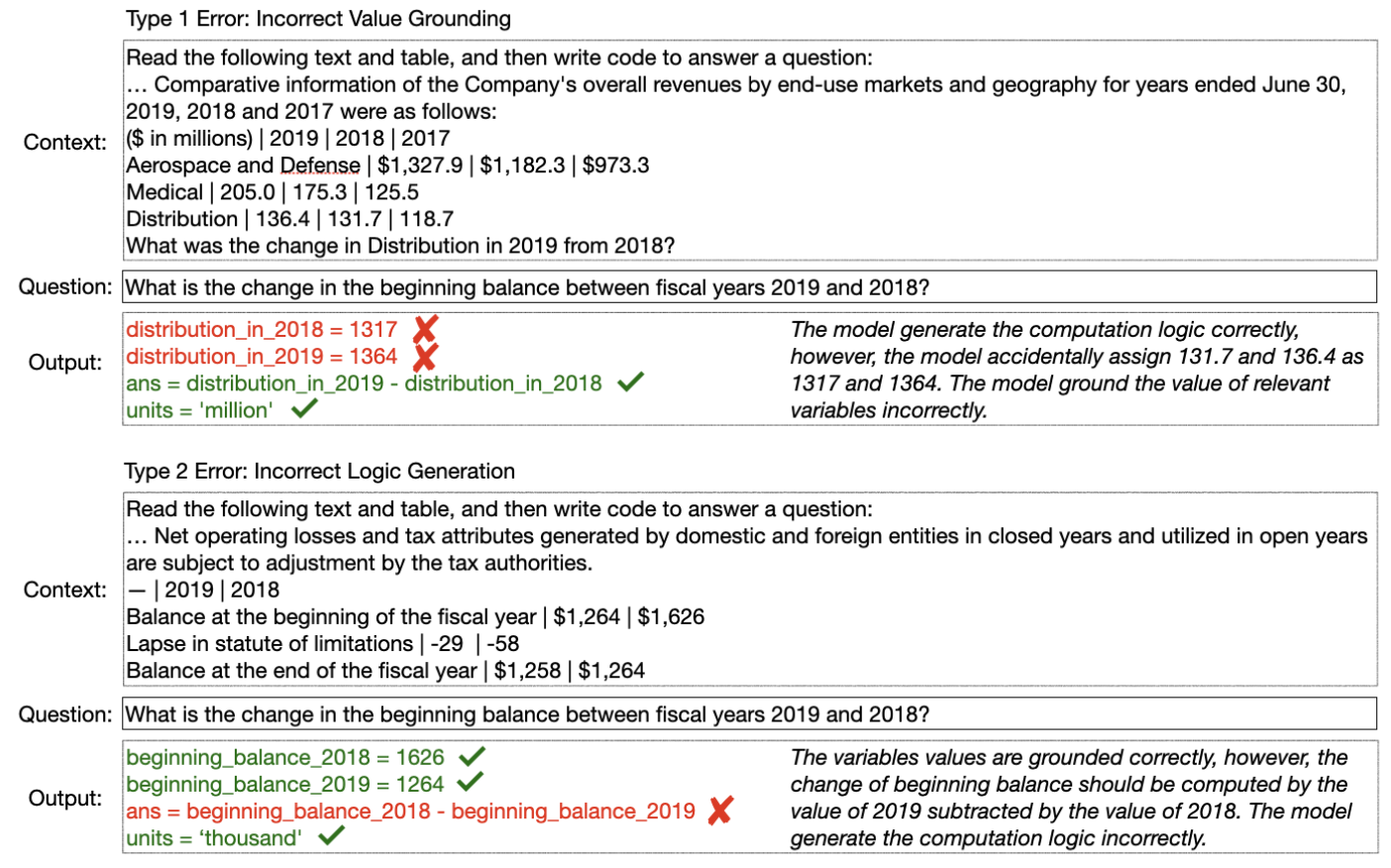
Program-of-Thoughts(PoT):结合Python工具和CoT提升大语言模型数学推理能力
Program of Thoughts Prompting:Disentangling Computation from Reasoning for Numerical Reasoning Tasks github:https://github.com/wenhuchen/Program-of-Thoughts 一、动机 数学运算和金融方面都涉及算术推理。先前方法采用监督训练的形式,但这…...

ansible setup模块
用于收集有关目标主机的系统和网络信息,并将这些信息存储为一个facts变量,可以在Playbook的后续任务中使用。setup模块可以用来获取主机的操作系统、软件包、IP地址、内存、磁盘和其他硬件信息。这些信息对编写Playbook和进行条件判断非常有用。当你在Pl…...

【2024最新华为OD-C/D卷试题汇总】[支持在线评测] LYA的测试用例执行计划(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 📎在线评测链接 https://app5938.acapp.acwing.com.cn/contest/2/problem/OD…...

NSIS 入门教程 (一)
介绍 大多数应用程序都附带一个安装程序,它将所需的文件复制到正确的文件夹中,创建注册表项,并提供卸载例程以(希望)从计算机中彻底删除应用程序. 有多种解决方案可以为自主开发的应用程序配备安装程序。除了Install …...

cve-2015-3306-proftpd-vulfocus
1.原理 proftp是用于搭建基于ftp协议的应用软件 ProFTPD是ProFTPD团队的一套开源的FTP服务器软件。该软件具有可配置性强、安全、稳定等特点。 ProFTPD 1.3.5中的mod_copy模块允许远程攻击者通过站点cpfr和site cpto命令读取和写入任意文件。任何未经身份验证的客户端都可以…...

超详细!想进华为od的请疯狂看我!
三分钟带你全面了解华为OD 【合同及管理】签约方为科锐国际/外企德科(人力服务公司),劳动合同期为4年,试用期6个月。员工关系合同管理、五险一金、考勤发薪由科锐国际/外企德科负责;定级定薪、员工培训、工作安排、绩…...

MQTT协议与TCP/IP协议在性能上的区别
MQTT协议与TCP/IP协议在性能上的区别主要体现在以下几个方面: 1.协议开销与传输效率: ① MQTT:MQTT协议针对消息传递进行了优化,使用了小型的控制包和变长的包头设计,极大程度地减少了数据传输过程中的冗余和带宽消耗…...

LeetCode 每日一题 2024/6/17-2024/6/23
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 6/17 522. 最长特殊序列 II6/18 2288. 价格减免6/19 2713. 矩阵中严格递增的单元格数6/20 2748. 美丽下标对的数目6/21 LCP 61. 气温变化趋势6/22 2663. 字典序最小的美丽字…...
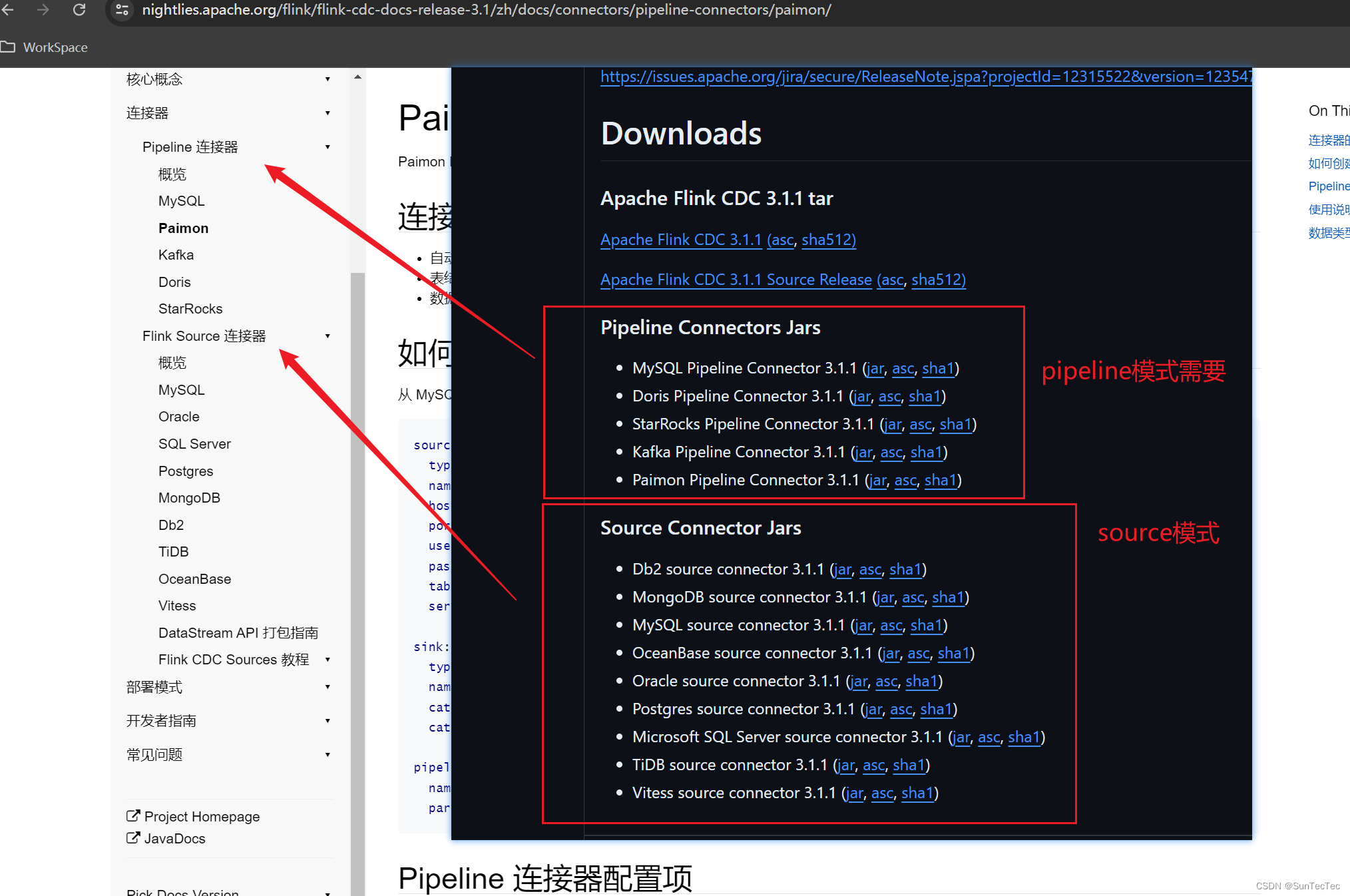
FlinkCDC pipeline模式 mysql-to-paimon.yaml
flinkcdc 需要引入: source端: flink-cdc-pipeline-connector-mysql-xxx.jar、mysql-connector-java-xxx.jar、 sink端: flink-cdc-pipeline-connector-paimon-xxx.jar flinkcdc官方提供connect包下载地址,pipeline模式提交作业和…...

mysql数据库入门手册
数据库 常见的数据库查看当前用户及其权限创建用户授权用户访问数据库撤销用户权限修改用户密码删除用户增创建一个数据库创建表表中插入数据表中添加字段(三种方式) 删删除表记录删除表字段删除表(三种方式)删除数据库 改修改表名…...

增强大型语言模型(LLM)可访问性:深入探究在单块AMD GPU上通过QLoRA微调Llama 2的过程
Enhancing LLM Accessibility: A Deep Dive into QLoRA Through Fine-tuning Llama 2 on a single AMD GPU — ROCm Blogs 基于之前的博客《使用LoRA微调Llama 2》的内容,我们深入研究了一种称为量化低秩调整(QLoRA)的参数高效微调࿰…...

IDEA 2018.2.3 下 Maven 依赖包消失?别慌,可能是版本兼容性在作祟
IDEA 2018.2.3 下 Maven 依赖包消失的深度排查指南 当你打开一个尘封已久的老项目,准备继续维护或迁移时,突然发现IDEA的External Libraries里空空如也,只剩下孤零零的JDK包,整个项目文件一片飘红——这种场景对许多维护历史代码库…...

抖音图片怎么去水印?2026年在线去水印工具+方法盘点,总有一款适合你
开篇:为什么要去水印? 保存抖音图片时,总会遇到水印的困扰。这些水印包含抖音logo、发布者名称,有时还会有账号信息。对于自媒体创作者、内容整理者或普通用户来说,去除水印往往是必需的。本文将介绍当下最实用的抖音图…...

ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具
ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,我们经常面临一个尴…...

告别手动框选!用SUSTechPOINTS的V键批量标注,5分钟搞定一帧点云
解锁SUSTechPOINTS的V键批量标注:点云处理效率革命 在自动驾驶与机器人研发领域,点云标注是构建高精度感知模型的基础环节,但传统逐帧手动标注方式往往成为项目进度的瓶颈。我曾参与过一个城市级点云数据集标注项目,团队最初采用常…...

深入解析go-containerregistry:无守护进程的容器镜像操作利器
1. 项目概述:容器镜像的“瑞士军刀”如果你在容器化这条路上已经走了一段时间,那么对“镜像”这个概念一定不会陌生。无论是 Docker Hub 上的nginx:latest,还是你公司私有仓库里的myapp:v1.2.3,这些镜像都是容器世界的基石。但你是…...

轻量级HTTP代理monica-proxy:精准流量转发与多场景部署指南
1. 项目概述与核心价值最近在折腾一些需要跨网络环境访问特定服务的项目,发现一个挺有意思的工具叫ycvk/monica-proxy。这本质上是一个基于 Go 语言开发的轻量级 HTTP/HTTPS 代理服务器,但它和我们常见的那些“全能型”代理不太一样。它的设计初衷非常聚…...

人性最残忍的真相是:你越不把自己当回事,别人就越不把你当回事
那个总给别人买贵东西的人,最后都怎么样了? 目录 那个总给别人买贵东西的人,最后都怎么样了? 我们为什么会忍不住过度付出? 真正的爱,从来都不是单方面的牺牲 爱自己,是所有健康关系的前提 昨天刷到一句话,瞬间戳中了我:“永远不要拿自己辛苦钱,去给别人买自己都舍不…...

【仿真学习框架】HoloMotion 从入门到精通:全身人形控制 Foundation Model 完全指南
HoloMotion 从入门到精通:全身人形控制 Foundation Model 完全指南 目标读者:具身智能研究者、人形机器人开发者、RL/机器人学习工程师 目录 第1章 HoloMotion 全景概览 1.1 什么是 HoloMotion 1.2 技术定位:"小脑"基座模型 1.3 4-Any 愿景与路线图 1.4 核心能力矩…...

Godot引擎实验项目解析:从角色控制到着色器优化的实战指南
1. 项目概述与核心价值如果你是一名游戏开发者,尤其是对独立游戏开发充满热情,那么“Godot”这个名字对你来说一定不陌生。它是一个功能强大、开源免费的游戏引擎,以其轻量、高效和友好的编辑器而闻名。然而,引擎本身只是一个工具…...

Docker Compose编排微服务
Docker Compose编排微服务 引言 Docker Compose是Docker官方提供的容器编排工具,用于定义和运行多容器Docker应用。通过Compose,可以使用YAML文件定义服务、网络、数据卷等资源,然后通过简单的命令启动和停止整个应用。Docker Compose特别适合…...