Map-JAVA面试常问
1.HashMap底层实现
底层实现在jdk1.7和jdk1.8是不一样的
jdk1.7采用数组加链表的方式实现 jdk1.8采用数组加链表或者红黑树实现
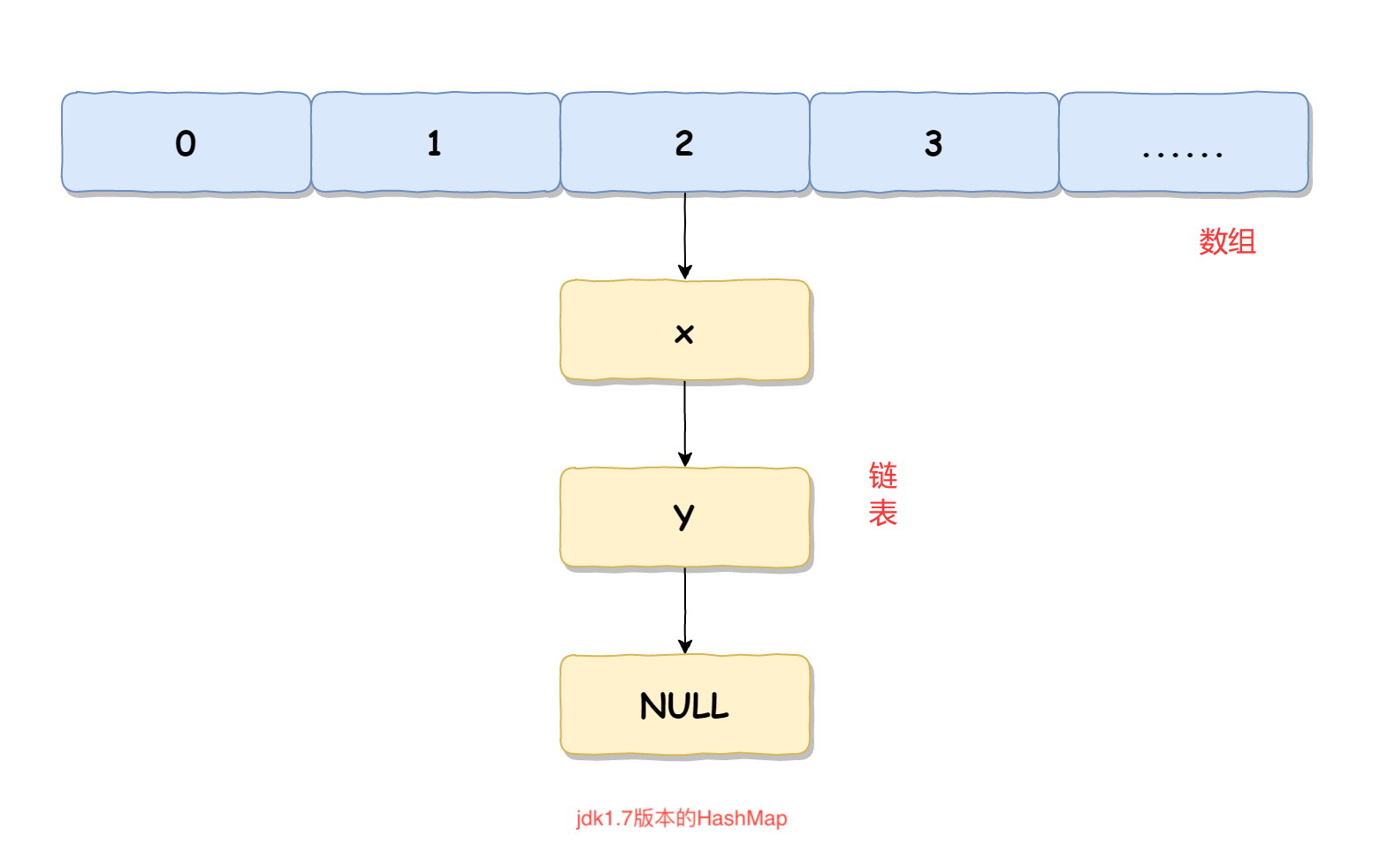
HashMap中每个元素称之为一个哈希桶(bucket),哈希桶包含的内容有以下4项
hash值(哈希函数计算出来的值)
Key
value
next(下一个节点默认).
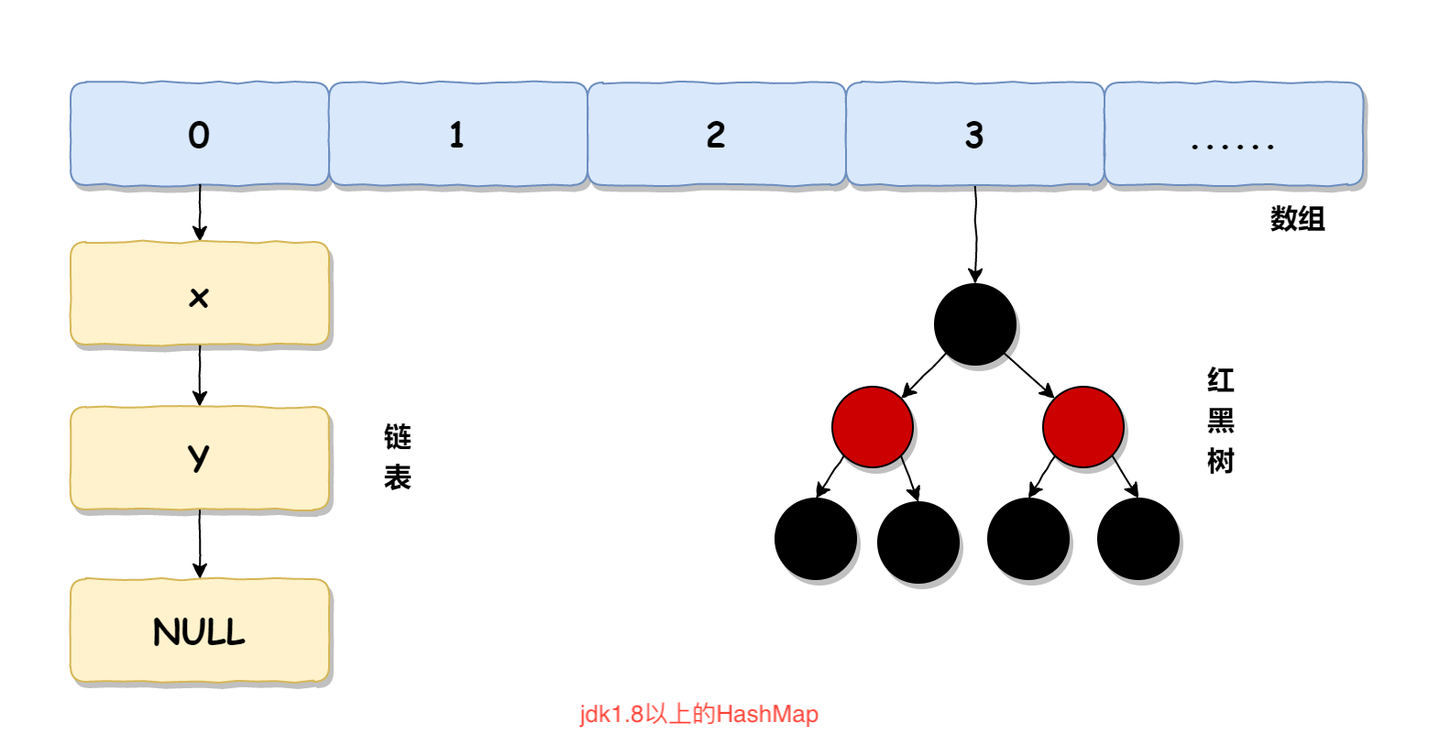
默认情况下,在jdk1.8+版本中,HashMap使用的是数组加链表的形式存储的,而当数组的长度大于64,并且链表的长度大于8时,就会将链表升级成红黑树,以增加HashMap的查询时的性能
初始容量:HashMap的初始容量为0,这是一种懒加载的方式,直到第一次put操作才会初始化数组大小默认为16
2.ConcurrentHashMap原理?为什么要这样改进
ConcurrentHashMap在不同的JDK版本中实现也是不同的。
在JDK1.7中它使用的是数组加链表的形式实现的,而数组分为:大数组Segment和小数组HashEntry。 而大数组Segment可以理解为MYSQL中的数据库,而每个数据库(Segment)中又有很多张表HashEntry,每一个HashEntry又有多条数据,这些数据用链表连接的,如下图所示:
而在JDK1.7中,ConcurrentHashMap是通过在Segment加锁来保证其安全性的,所以我们把它称为分段锁或片段锁,如下图所示
它实现的源码如下:
从上面的源码可以看出,JDK1.7时,ConcurrentHashMap主要用ReentrantLock进行加锁来实现线程安全的。 而在JDK1.8中,它是使用了数组+链表/红黑树的方式优化了concurrentHashMap的实现,具体结构如下
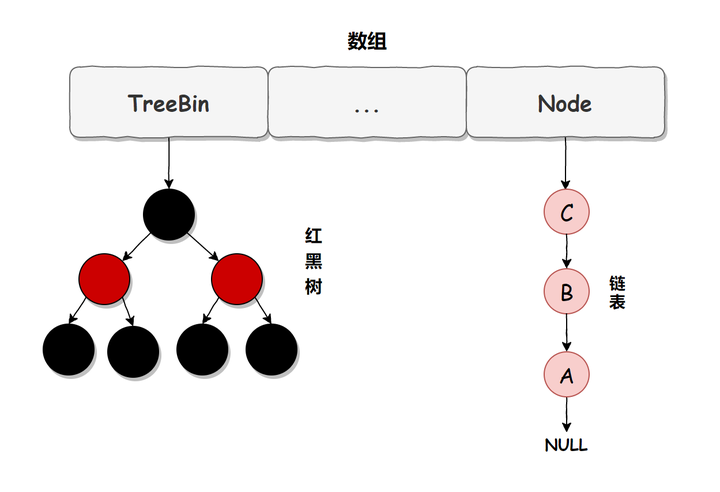
链表升级为红黑树的规则:当链表长度大于8,并且数组的长度大于64时,链表就会升级为红黑树的结构。
注意:ConcurrentHashMap在jdk1.8+虽然保留了Segment的定义,但这只是为了保证序列化时的兼容性,不再有任何结构上的用处了。
在JDK1.8中的ConcurrentHashMap使用的是CAS+volatile或者syncHronized的方式来保证线程安全的,他的核心实现源码如下。
//ConcurrentHashMap使用volatile修饰节点数组,保证其可见性,禁止指令重排。 //而HashMap没有使用volatile, transient Node<K,V>[] table; transient volatile Node<K,V>[] table; public V put(K key, V value) {return putVal(key, value, false); }final V putVal(K key, V value, boolean onlyIfAbsent) {// key和value都不能为nullif (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) { //死循环,可视为乐观锁Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)// 如果tab未初始化或者个数为0,则初始化node数组tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))// 如果使用CAS插入元素时,发现已经有元素了,则进入下一次循环,重新操作// 如果使用CAS插入元素成功,则break跳出循环,流程结束break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)// 如果要插入的元素所在的tab的第一个元素的hash是MOVED,则当前线程帮忙一起迁移元素tab = helpTransfer(tab, f);else { //发生hash冲突// 如果这个tab不为空且不在迁移元素,则锁住这个tab(分段锁)// 并查找要插入的元素是否在这个tab中// 存在,则替换值(onlyIfAbsent=false)// 不存在,则插入到链表结尾或插入树中V oldVal = null;synchronized (f) {// 再次检测第一个元素是否有变化,如果有变化则进入下一次循环,从头来过if (tabAt(tab, i) == f) {// 如果第一个元素的hash值大于等于0(说明不是在迁移,也不是树)// 那就是tab中的元素使用的是链表方式存储if (fh >= 0) {// tab中元素个数赋值为1binCount = 1;// 遍历整个tab,每次结束binCount加1for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {// 如果找到了这个元素,则赋值了新值(onlyIfAbsent=false),并退出循环oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {// 如果到链表尾部还没有找到元素,就把它插入到链表结尾并退出循环pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {// 如果第一个元素是树节点Node<K,V> p;// tab中元素个数赋值为2binCount = 2;// 调用红黑树的插入方法插入元素,如果成功插入则返回null,否则返回寻找到的节点if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {// 如果找到了这个元素,则赋值了新值(onlyIfAbsent=false),并退出循环oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// 如果binCount不为0,说明成功插入了元素或者寻找到了元素if (binCount != 0) {// 如果链表元素个数达到了8,则尝试树化// 因为上面把元素插入到树中时,binCount只赋值了2,并没有计算整个树中元素的个数,所以不会重复树化if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);// 如果要插入的元素已经存在,则返回旧值if (oldVal != null)return oldVal;// 退出外层大循环,流程结束break;}}}// 成功插入元素,元素个数加1(是否要扩容在这个里面)addCount(1L, binCount);// 成功插入元素返回nullreturn null; } public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;// 计算hashint h = spread(key.hashCode());// 判断数组是否为空,通过key定位到数组下标是否为空if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 如果第一个元素就是要找的元素,直接返回if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}else if (eh < 0)// hash小于0,说明是树或者正在扩容// 使用find寻找元素,find的寻找方式依据Node的不同子类有不同的实现方式return (p = e.find(h, key)) != null ? p.val : null;// 遍历整个链表寻找元素while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null; } public V remove(Object key) {// 调用替换节点方法return replaceNode(key, null, null); }final V replaceNode(Object key, V value, Object cv) {// 计算hashint hash = spread(key.hashCode());// 循环遍历数组for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;//校验参数if (tab == null || (n = tab.length) == 0 ||(f = tabAt(tab, i = (n - 1) & hash)) == null)break;else if ((fh = f.hash) == MOVED)// 如果正在扩容中,协助扩容tab = helpTransfer(tab, f);else {V oldVal = null;// 标记是否处理过boolean validated = false;//用 synchronized 同步锁,保证并发时元素移除安全synchronized (f) {// 再次验证当前tab元素是否被修改过if (tabAt(tab, i) == f) {if (fh >= 0) {// fh>=0表示是链表节点validated = true;// 遍历链表寻找目标节点for (Node<K,V> e = f, pred = null;;) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {V ev = e.val;if (cv == null || cv == ev ||(ev != null && cv.equals(ev))) {oldVal = ev;if (value != null)e.val = value;else if (pred != null)pred.next = e.next;elsesetTabAt(tab, i, e.next);}break;}pred = e;// 遍历到链表尾部还没找到元素,跳出循环if ((e = e.next) == null)break;}}else if (f instanceof TreeBin) {// 如果是树节点validated = true;TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> r, p;// 遍历树找到了目标节点if ((r = t.root) != null &&(p = r.findTreeNode(hash, key, null)) != null) {V pv = p.val;if (cv == null || cv == pv ||(pv != null && cv.equals(pv))) {oldVal = pv;if (value != null)p.val = value;else if (t.removeTreeNode(p))setTabAt(tab, i, untreeify(t.first));}}}}}// 如果处理过,不管有没有找到元素都返回if (validated) {// 如果找到了元素,返回其旧值if (oldVal != null) {// 如果要替换的值为空,元素个数减1if (value == null)addCount(-1L, -1);return oldVal;}break;}}}// 没找到元素返回空return null; }从上述代码可以看出,在JDK1.8中,添加元素首先会判断容器是否为空,如果为空则使用volatile加cas来初始化。如何容器不为空则根据存储的元素计算改位置是否为空,如果为空则利用cas设置该节点;如果不为空则使用synchronize加锁,遍历桶中的数据,替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
put操作总结
做插入操作时,首先进入乐观锁,在乐观锁中判断容器是否初始化,
如果没初始化则初始化容器;如果已经初始化,则判断该hash位置的节点是否为空,
如果为空,则通过CAS操作进行插入。
如果该节点不为空,再判断容器是否在扩容中,如果在扩容,则帮助其扩容。如果没有扩容,则进行最后一步,先加锁,然后找到hash值相同的那个节点(hash冲突),
循环判断这个节点上的链表,决定做覆盖操作还是插入操作。
循环结束,插入完毕。get操作总结
步骤如下:
- 判断数组是否为空,通过key定位到数组下标是否为空;
- 判断node节点第一个元素是不是要找到,如果是直接返回;
- 如果是红黑树结构,就从红黑树里面查询;
- 如果是链表结构,循环遍历判断。
ConcurrentHashMap的get()方法没有加synchronized锁,为什么可以不加锁?因为table有volatile关键字修饰,保证每次获取值都是最新的。【Hashtable的get(Object key)方法加了synchronized锁,性能较差】
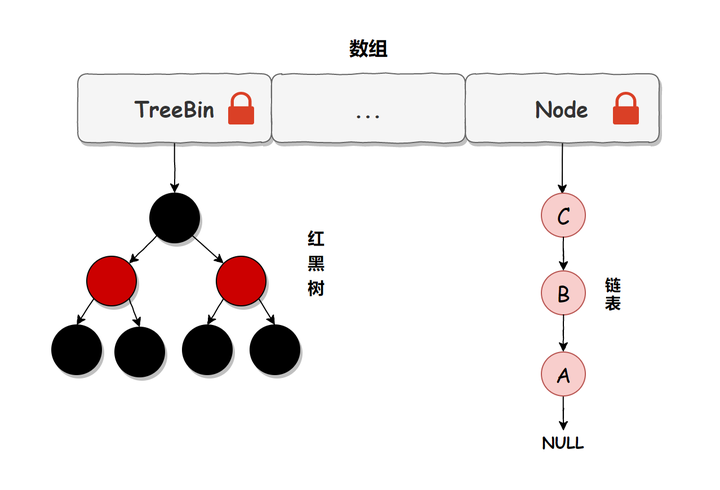
总结:我们把上述流程简化一下,可以简单的认为在JDK1.8中,ConcurrentHashMap是在头节点加锁来保证线程安全的,锁的粒度相比JDK1.7的Segment来说就更小了,发生冲突和加锁的频率降低了,并发操作的性能就提高了,而且JDK1.8使用的红黑树优化了之前的固定链表,那么当数据量比较大的时候,查询效率也得到了很大的提升,从之前的O(n)优化到了O(logn)的时间复杂度,具体加锁示意图如下所示:



3.HashMap为什么是线程不安全的
- 在jdk1.7中,在多线程的环境下,扩容时会出现死循环,数据丢失 的问题
- 在jdk1.8+中,在多线程的环境下,会发生数据覆盖的问题
原因:
在jdk1.7中,HashMap扩容时使用的是头插法插入元素 。具体原因:在HashMap出发扩容时,正好两个线程同时在操作同一个链表,当线程A被挂起,线程B完成数据插入,等cpu资源释放,线程A重新执行之前的逻辑,数据已经发生改变,线程A,B,数据会形成环形链表造成死循环,数据丢失问题
在jdk1.8中,HashMap扩容使用了尾插法 这样避免了死循环问题,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),如果两个线程并发执行 put 操作,并且两个数据的 hash 值冲突,就可能出现数据覆盖。具体原因:线程 A 判断 hash 值位置为 null,还未写入数据、由于时间片耗尽导致被挂起,此时线程 B 正常插入数据。接着线程 A 获得时间片,由于线程 A 之前已进行hash碰撞的判断,所以此时不会再进行判断、而是直接进行插入,就会把刚才线程 B 写入的数据覆盖掉
jdk1.7扩容代码如下
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}}在多线程下安全使用HashMap,可以使用一下策略
- 使用线程安全替代类 :ConcurrentHashMap集合类,强烈推荐
- 使用线程局部变量 : 为每个线程维护一个独立的HashMap实例,以避免线程间竞争。ThreadLocal<Map<String, Integer>> threadLocalMap = ThreadLocal.withInitial(HashMap::new);
4.HashMap和ConcurrentHashMap区别
线程是否安全
HashMap不是线程安全的
concurrentHashMap是线程安全的,是通过segment分段锁-继承ReentrantLock(JDK1.7可重入锁),cas和synchronized(jdk1.8内置锁)来进行加锁,实现线程安全
底层数据结构
HashMap:在jdk1.7时,数组+链表,jdk1.8时采用数组+链表+红黑树
ConcurrentHashMap:JDK1.8之前Segment+数组+链表,JDK1.8之后数组+链表+红黑树
5.HashMap和HashTable区别
Hashtable和HashMap都是 基于hash表实现的K-V结构的集合,Hashtable是jdk1.0引入的一个线程安全的集合类,内部使用数组+链表的形式来实现
从功能特性的角度来说
1、Hashtable是线程安全的(HashTable 对每个方法都增加了 synchronized),而HashMap不是
2、HashMap的性能要比Hashtable更好,因为Hashtable采用了全局同步锁来保证安全性,对性能影响较大
从内部实现的角度来说
1)Hashtable使用数组加链表,HashMap JDK1.7数组+链表、JDK1.8 数组+链表+红黑树
2)HashMap初始容量是16,Hashtable初始容量是11
3)HashMap可以使用null作为key;而Hashtable不允许 null 作为 Key,会抛出NullPointerException异常
他们两个的key的散列算法不同:Hashtable直接是使用key的hashcode对数组长度取模;而HashMap对key的hashcode做了二次散列,从而避免key的分布不均匀影响到查询性能
6.HashMap、Hashtable、ConcurrentHashMap区别
HashMap、Hashtable、ConcurrentHashMap都是 基于hash表实现的K-V结构的集合,在线程安全、底层数据结构方面有所区别
- HashMap:线程不安全,因为HashMap中操作都没有加锁,因此在多线程环境下会导致数据覆盖之类的问题,所以,在多线程中使用HashMap是会抛出异常的
- Hashtable:线程安全,但是Hashtable只是单纯的在添加put、删除remove、查询get方法上加synchronized,保证插入时阻塞其他线程的插入操作。虽然安全,但因为设计简单,所以性能低下(HashMap的性能要比Hashtable更好,因为Hashtable采用了全局同步锁来保证安全性,对性能影响较大)
- ConcurrentHashMap:线程安全,ConcurrentHashMap并非锁住整个方法,而是通过原子操作和局部加锁的方法保证了多线程的线程安全,且尽可能减少了性能损耗。Segment分段锁–继承 ReentrantLock(JDK1.7重入锁)、CAS和synchronized(JDK1.8内置锁)
7.为什么 HashMap 采用拉链法而不是开放地址法?
Java 给予 HashMap 的定位是一个相对通用的散列表容器,它应该在面对各种输入的时候都表现稳定。而开发地址法相对来说容易出现数据堆积,在数据量较大时可能出现连续冲突的情况,性能不够稳定。
我们可以举个反例,在 Java 原生的数据结构中,也存在使用开放地址法的散列表 —— 就是 ThreadlLocal。因为项目中不会大量使用 ThreadLocal 线程局部存储,所以它是一个小规模数据场景,这里使用开发地址法是没问题的。
8.Map对比
| 实现类 | 数据结构 | 是否线程安全 | key是否可为null | 是否有序 |
|---|---|---|---|---|
| HashMap | 哈希表结构,jdk1.7 数组+链表,jdk1.8 数组+链表+红黑树 | 否 | 是 | 否 |
| ConcurrentHashMap | 哈希表结构,jdk1.7 数组+链表,jdk1.8 数组+链表+红黑树 | 是 | 否 | 否 |
| Hashtable | 哈希表结构,数组+链表 | 是 | 否 | 否 |
| LinkedHashMap | 继承自HashMap,数组+链表+红黑树+双重链接列表 | 否 | 是 | 是 |
| TreeMap | 红黑树 | 否 | 否 | 是 |
相关文章:
Map-JAVA面试常问
1.HashMap底层实现 底层实现在jdk1.7和jdk1.8是不一样的 jdk1.7采用数组加链表的方式实现 jdk1.8采用数组加链表或者红黑树实现 HashMap中每个元素称之为一个哈希桶(bucket),哈希桶包含的内容有以下4项 hash值(哈希函数计算出来的值) Key value next(…...
prometheus+grafana搭建监控系统
1.prometheus服务端安装 1.1下载包 使用wget下载 (也可以直接去官网下载包Download | Prometheus) wget https://github.com/prometheus/prometheus/releases/download/v2.44.0/prometheus-2.44.0.linux-amd64.tar.gz1.2解压 tar xf prometheus-2.44…...

flink学习-flink sql
动态表 在flink的数据处理中,数据流是源源不断的,是无界的,所以对于flink处理的数据表是一张动态表,所以对于动态表的查询也是持续的,每接收一条新数据会进行一次新的查询。 持续查询 因为数据在一直源源不动的到来…...

高考填报志愿攻略,5个步骤选专业和院校
在高考完毕出成绩的时候,很多人会陷入迷茫中,好像努力了这么多年,却不知道怎么规划好未来。怎么填报志愿合适?在填报志愿方面有几个内容需要弄清楚,按部就班就能找到方向,一起来了解一下正确的步骤吧。 第…...

Kubernetes排错(十)-处理容器数据磁盘被写满
容器数据磁盘被写满造成的危害: 不能创建 Pod (一直 ContainerCreating)不能删除 Pod (一直 Terminating)无法 exec 到容器 如何判断是否被写满? 容器数据目录大多会单独挂数据盘,路径一般是 /var/lib/docker,也可能是 /data/docker 或 /o…...

使用QtGui显示QImage的几种方法
问题描述 我是一名刚学习Qt的新手,正在尝试创建一个简单的GUI应用程序。当点击一个按钮时,显示一张图片。我可以使用QImage对象读取图片,但是否有简单的方法调用一个Qt函数,将QImage作为输入并显示它? 方法一:使用QLabel显示QImage 最简单的方式是将QImage添加到QLabe…...

C++ lamda
1 lamada 的函数指针存在哪里?需要通过分析编译后的二进制; 2 捕获了什么? 为什么捕获?捕获的范围是什么? 捕获的生命周期是什么? lambda 定义匿名函数,使得代码更加灵活简洁; lam…...
Linux_应用篇(27) CMake 入门与进阶
在前面章节内容中,我们编写了很多示例程序,但这些示例程序都只有一个.c 源文件,非常简单。 所以,编译这些示例代码其实都非常简单,直接使用 GCC 编译器编译即可,连 Makefile 都不需要。但是,在实…...
51单片机STC89C52RC——8.1 8*8 LED点阵模块(点亮一个LED)
目录 目的/效果 一,STC单片机模块 二,8*8 LED点阵模块 2.1 电路图 2.1.1 8*8 点阵模块电路图 2.1.2 74HC595(串转并)模块 电路图 2.1.3 芯片引脚 2.2 引脚电平分析 2.3 74HC595 串转并模块 2.3.1 装弹(移位…...

2024最新免费版轻量级Navicat Premium Lite 下载和安装教程
2024最新免费版轻量级Navicat Premium Lite 下载和安装教程 关于猫头虎 大家好,我是猫头虎,别名猫头虎博主,擅长的技术领域包括云原生、前端、后端、运维和AI。我的博客主要分享技术教程、bug解决思路、开发工具教程、前沿科技资讯、产品评…...

PHP+laravel 生成word
此功能较为繁琐我会从源头讲起 首先是数据库设置,下面是我的数据库结构 合同模版表 CREATE TABLE contract_tpl (id bigint unsigned NOT NULL AUTO_INCREMENT,name varchar(191) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 合同名称,file varchar(191) COLL…...

redis集群简单介绍及其搭建过程
Redis集群 1、哨兵模式 哨兵可以有多个,从服务器也可以有多个,从服务器也可以有多个,在Redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异常,则会实现主从切换&#x…...

linux桌面运维----第五天
1、创建用户命令useradd: 作用:创建用户 语法:useradd [选项名] 用户名 选项: -d<登入目录> 指定用户登入时的起始目录。 【掌握】 -g<群组> 指定用户所属的群组(基本组)。【掌握】…...
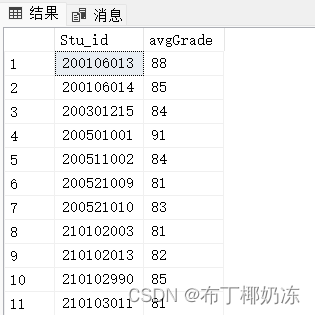
【SQL Server数据库】简单查询
目录 用SQL语句完成下列查询。使用数据库为SCHOOL数据库 1. 查询学生的姓名、性别、班级名称,并把结果存储在一张新表中。 2. 查询男生的资料。 3. 查询所有计算机系的班级信息。 4.查询艾老师所教的课程号。 5. 查询年龄小于30岁的女同学的学号和姓名。…...

Docker 从入门到精通(大全)
一、概述 1.1 基本概念 Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。…...
基于JSP的在线教育资源管理系统
开头语: 你好呀,我是计算机学长猫哥!如果你对在线教育资源管理系统感兴趣或者有相关需求,欢迎在文末找到我的联系方式。 开发语言:Java 数据库:MySQL 技术:JSP技术 工具:IDE、N…...

在java中代理http请求,如何避免陷入循环?
在 Java 中,代理 HTTP 请求时,如果不小心配置不当,可能会导致循环请求。循环请求通常发生在代理服务器将请求再次发送回自己,形成一个死循环。为了避免这种情况,可以采取以下几种方法: 将域名设置为指定的…...

国内镜像源网址
腾讯:腾讯软件源 (tencent.com) 阿里:阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区 (aliyun.com) 清华:清华大学开源软件镜像站 | Tsinghua Open Source Mirror...
合适的智能猫砂盆到底怎么挑?开放式封闭式一次说清!
想当初我也是在网上看了各种测评,纠结了好久才下定决心入手了智能猫砂盆。封闭式和开放式都用过,各有各的利与弊,不过最后的我还是选择了开放式的智能猫砂盆,因为开放式的设计结构会更加方便我观察小猫,哪个铲屎官不喜…...

阿里云开启ssl证书过程记录 NGINX
🤞作者简介:大家好,我是思无邪,2024 毕业生,某厂 Go 开发工程师.。 🐂我的网站:https://www.yishanicode.top/ ,持续更新,希望对你有帮助。 🐞如果文章或网站…...
)
NotebookLM审稿意见回复全链路避坑清单,含8个高频雷区+对应话术库(限时开放2024最新版PDF)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM审稿意见回复全链路避坑清单导论 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,在学术协作与论文修订场景中展现出独特优势,但其在处理审稿意见回复时存在隐…...

38岁大厂P9被裁后卖保险:成年人的职场,没有铁饭碗
来自:推荐一个程序员编程资料站:http://cxyroad.com副业赚钱专栏:https://xbt100.top2024年IDEA最新激活方法后台回复:激活码CSDN免登录复制代码插件下载:CSDN复制插件以下是正文。01 | P9也不是免死金牌最近在网上看到…...

BepInEx.ConfigurationManager:3步打造专业级Unity插件配置界面
BepInEx.ConfigurationManager:3步打造专业级Unity插件配置界面 【免费下载链接】BepInEx.ConfigurationManager Plugin configuration manager for BepInEx 项目地址: https://gitcode.com/gh_mirrors/be/BepInEx.ConfigurationManager 你是否曾为Unity游戏…...

终极指南:5步掌握番茄小说下载器的完整使用方案
终极指南:5步掌握番茄小说下载器的完整使用方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读时代,我们常常面临一个共同的问题࿱…...

从校赛到区域赛:ACM-ICPC竞赛中的经典算法与实战策略解析
1. ACM-ICPC竞赛与算法能力培养 ACM国际大学生程序设计竞赛(ACM-ICPC)是全球最具影响力的大学生计算机赛事,被誉为"计算机界的奥林匹克"。这项赛事不仅考验选手的编程能力,更注重算法设计、团队协作和心理素质的综合表现…...

VHD2VL:破解硬件描述语言转换难题的开源解决方案
VHD2VL:破解硬件描述语言转换难题的开源解决方案 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,技术团队常常面临VHDL与Verilog两种硬件描述语言之间的转换挑战。当项目需要跨语言协作、工…...

如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南
如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫…...

构建高可用AI模型代理服务:统一接口、智能路由与生产级部署
1. 项目概述:一个无处不在的AI助手接口最近在折腾AI应用开发的朋友,可能都遇到过这样一个痛点:想在自己的项目里快速接入一个靠谱的、能处理复杂对话的AI模型,但要么被OpenAI的API调用限制和网络问题搞得焦头烂额,要么…...

CC2530与ESP8266物联网网关:ZigBee转Wi-Fi通信协议转换实战
1. 项目概述:当ZigBee遇上Wi-Fi最近在折腾一个智能家居的传感器节点,核心是TI的CC2530 ZigBee芯片。这玩意儿功耗低、组网方便,是很多低功耗传感网络的绝佳选择。但问题来了,ZigBee网络的数据最终怎么方便地送到我们手机上去看呢&…...

CursorTouch/Web-Use:用JavaScript在桌面端模拟移动端触摸交互
1. 项目概述:当光标变成你的手指你有没有想过,在电脑上浏览网页时,如果能像在手机上那样,直接用手指滑动、点击、缩放,体验会不会更流畅?尤其是在处理一些需要精细操作或快速浏览长文档的场景时,…...