堆的结构与实现
堆的结构与实现
- 二叉树的顺序结构
- 堆的概念及结构
- 堆的实现
- 堆的创建
- 向上调整建堆
- 向下调整建堆
- 堆的操作链接
二叉树的顺序结构
堆其实是具有一定规则限制的完全二叉树。
普通的二叉树是不太适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树会更适合使用顺序结构进行存储。如下图:
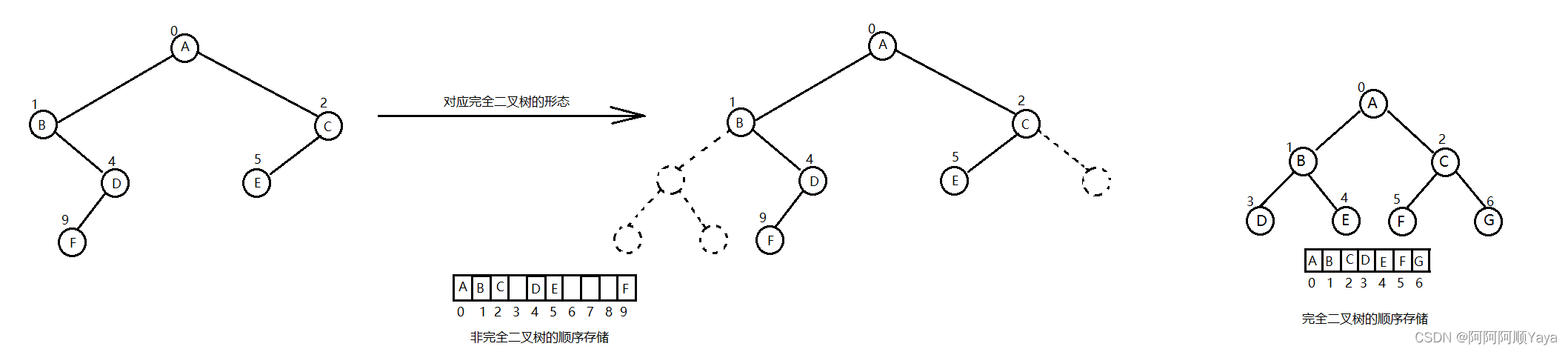
堆的概念及结构
如果有一个关键码的集合K={k0,k1,k2,...,kn−1}K=\{k_0, k_1, k_2, ..., k_{n-1}\}K={k0,k1,k2,...,kn−1},当把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并且满足:Ki≤K2∗i+1K_i\leq K_{2*i+1}Ki≤K2∗i+1且Ki≤K2∗i+2K_i\leq K_{2*i+2}Ki≤K2∗i+2(Ki≥K2∗i+1K_i\ge K_{2*i+1}Ki≥K2∗i+1且Ki≥K2∗i+2K_i\ge K_{2*i+2}Ki≥K2∗i+2),i=0, 1, 2, …,则称之为小堆(大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值
- 堆总是一棵完全二叉树。

堆的实现
堆的创建
下面给出一个数组,这个数组逻辑上可以看做一棵完全二叉树,但是还不满足堆的条件。现在我们可以通过算法,将它构建成一个堆。
int a[] = {27,15,19,18,28,34,65,49,25,37};
要将其构建成一个堆结构,有两种调整建堆的方法:一种是向上调整建堆,一种是向下调整建堆。
向上调整建堆
向上调整建堆主要是用于在堆数据结构中,堆在插入数据后,为了继续维持堆的结构,所进行的一种调整。
大致调整过程如下:
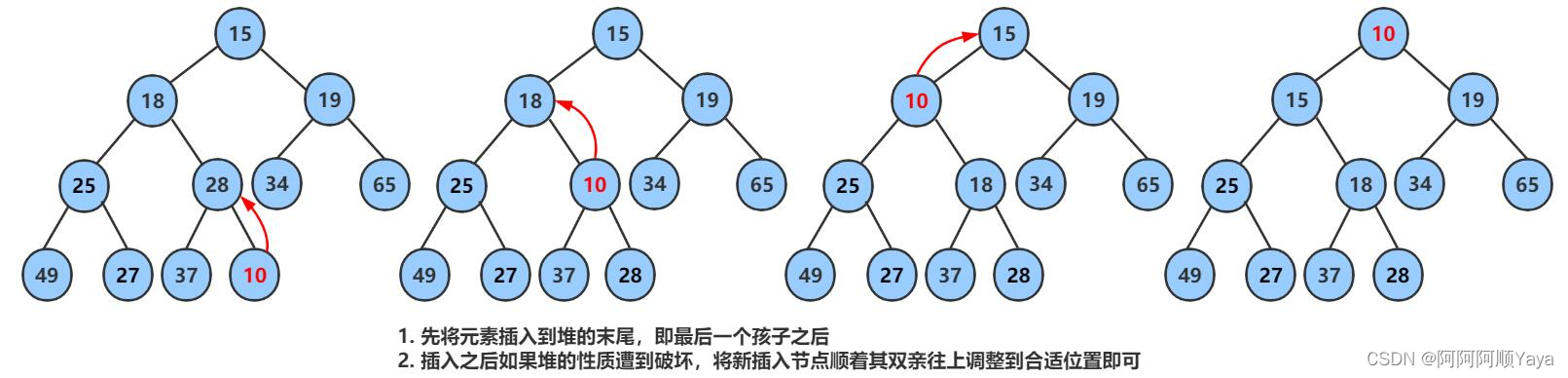
经过一次向上调整后,本来因为插入数据所导致的堆的结构的破坏就被恢复了。
有了这个思路,可以将过程实现如下:
//a - 堆的顺序存储数组
//child - 需要进行向上调整的孩子下标
void AdjustUp(HDataType* a, int child)
{assert(a != NULL);int parent = (child - 1) / 2;while (child > 0)//child为0时,child就到了堆顶,调整结束{//建小堆 - 孩子比双亲小,就互换位置if (a[child] < a[parent]){Swap(&a[child], &a[parent]);//交换函数child = parent;parent = (child - 1) / 2;}else{break;}}
}
以上只是对一个数据进行的调整,要想实现堆的创建,需要将数组中的所有数据都进行一遍调整(堆顶元素除外),所以可以更进一步,完成一棵完全二叉树到堆的创建。
for (int i = 1; i < n; ++i)
{AdjustUp(a, i);
}
以上就是向上调整建堆的过程,我们可以分析一下它的时间复杂度。
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化,使用满二叉树来证明。(时间复杂度看的本来就是近似值,多几个节点并不影响最终结果)
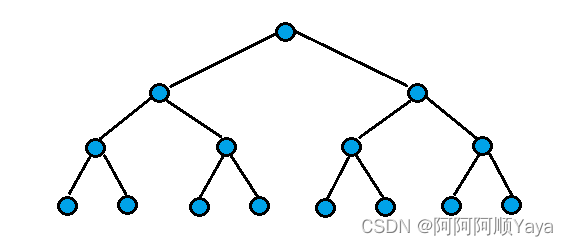
假设树的高度为h
第1层,202^020个节点,需要向上调整0层。
第2层,212^121个节点,需要向上调整1层。
第3层,222^222个节点,需要向上调整2层。
第4层,232^323个节点,需要向上调整3层。
…
第h-1层,2h−22^{h-2}2h−2个节点,需要向上调整h-2层。
第h层,2h−12^{h-1}2h−1个节点,需要向上调整h-1层。
则需要移动节点总的移动步数为:
T(n)=20∗0+21∗1+22∗2+23∗3+......+2(h−2)∗(h−2)+2(h−1)∗(h−1)T(n)=2^0*0+2^1*1+2^2*2+2^3*3+......+2^{(h-2)}*(h-2)+2^{(h-1)}*(h-1)T(n)=20∗0+21∗1+22∗2+23∗3+......+2(h−2)∗(h−2)+2(h−1)∗(h−1)
2T(n)=21∗0+22∗1+23∗2+24+3+......+2(h−1)∗(h−2)+2h∗(h−1)2T(n)=2^1*0+2^2*1+2^3*2+2^4+3+......+2^{(h-1)}*(h-2)+2^h*(h-1)2T(n)=21∗0+22∗1+23∗2+24+3+......+2(h−1)∗(h−2)+2h∗(h−1)
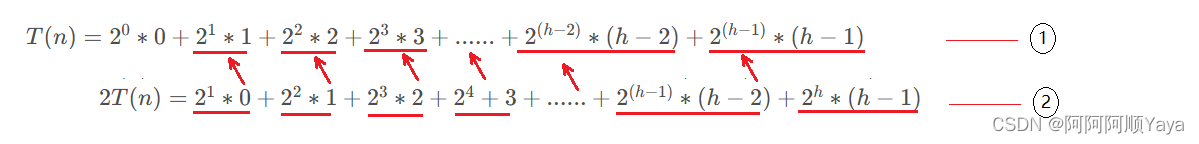
由错位相减得:
T(n)=−20−21−22−23−24−2(h−2)−2(h−1)+2h∗(h−1)T(n)=-2^0-2^1-2^2-2^3-2^4-2^{(h-2)}-2^{(h-1)}+2^h*(h-1)T(n)=−20−21−22−23−24−2(h−2)−2(h−1)+2h∗(h−1)
T(n)=2h∗(h−1)−(20+21+22+23+24+2(h−2)+2(h−1))T(n)=2^h*(h-1)-(2^0+2^1+2^2+2^3+2^4+2^{(h-2)}+2^{(h-1)})T(n)=2h∗(h−1)−(20+21+22+23+24+2(h−2)+2(h−1))
T(n)=2h∗(h−1)−(2h−1)=2h∗(h−2)+1T(n)=2^h*(h-1)-(2^h-1)=2^h*(h-2)+1T(n)=2h∗(h−1)−(2h−1)=2h∗(h−2)+1
因为是满二叉树,所以节点数n与高度h之间存在如下关系:
n=2h−1n=2^h-1n=2h−1,h=log2(n+1)h=log_2(n+1)h=log2(n+1)
所以T(n)=(n+1)∗(log2(n+1)−2)+1T(n)=(n+1)*(log_2(n+1)-2)+1T(n)=(n+1)∗(log2(n+1)−2)+1
因此,得出向上建堆的时间复杂度是O(n∗log2nn*log_2nn∗log2n)。
向下调整建堆
堆的删除
向下调整建堆主要是用于在堆数据结构中,堆在删除数据后,为了继续维持堆的结构,所进行的一种调整。
这里要说明的是,堆的删除是指删除堆顶的数据。要删除堆顶的数据并不是像顺序表那样覆盖删除。虽然堆的物理存储结构是顺序结构,但他逻辑上是树形结构,如果直接覆盖删除,本来是兄弟节点的变成父子节点,关系会完全打乱。并不能保证最终覆盖删除之后的结构还是堆的结构。
所以,堆的删除有另一种巧妙的方法。先将堆顶的数据跟堆的最后一个数据进行交换,然后删除堆的最后一个数据,就将堆顶数据删除了。
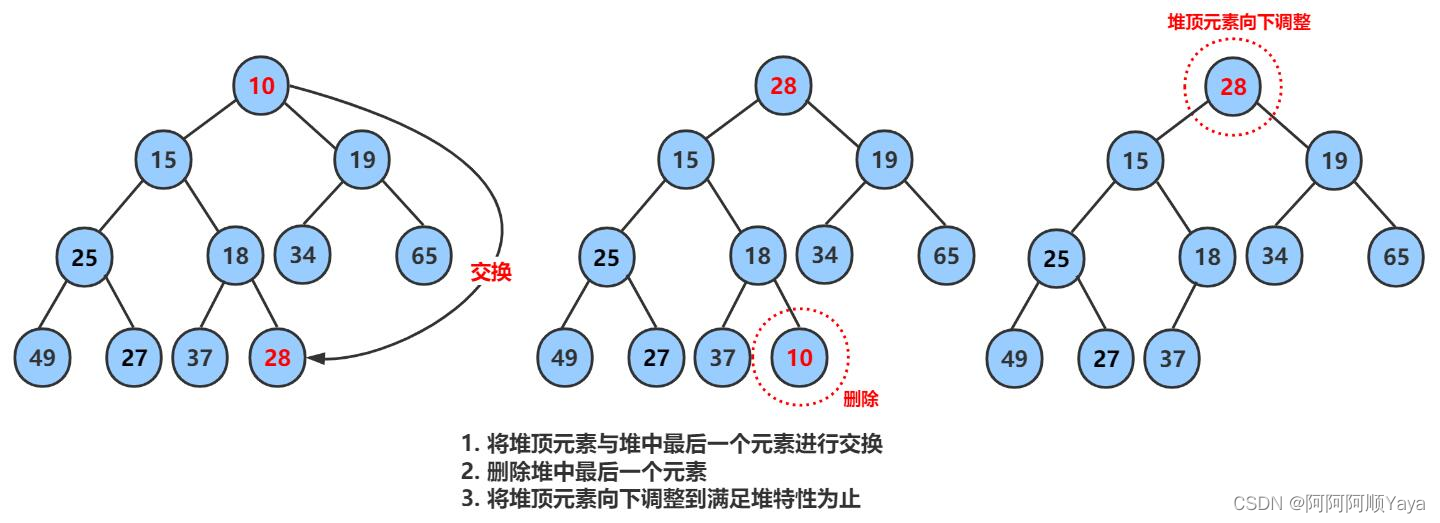
但是,堆顶的数据删除了,并没有因此就万事大吉。因为和堆顶数据进行交换的数据,现在处于堆顶位置,并不代表它就是堆中最小或最大的数据,堆的结构可能通过交换后就此被破坏。所以,这里就要通过向下调整算法来恢复堆的结构。
大致调整过程如下:
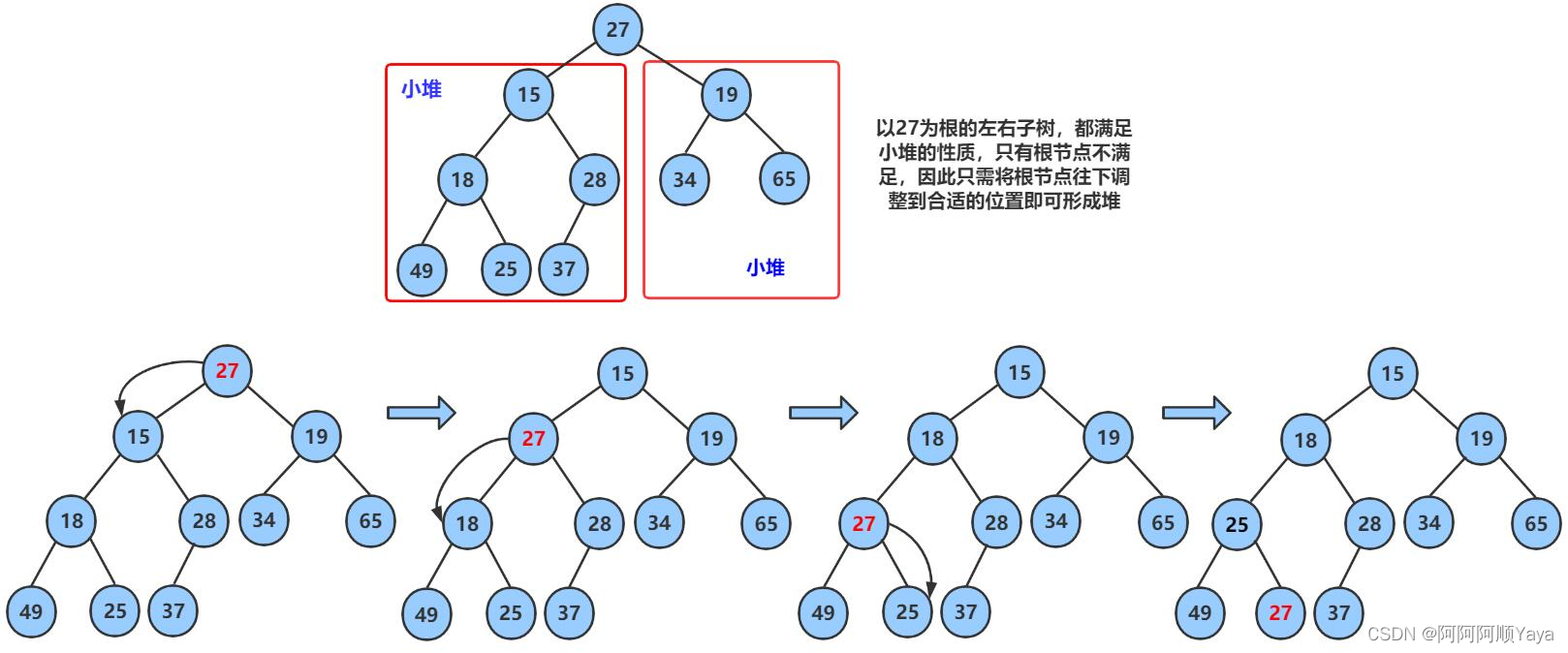
要注意的是:向下调整算法有一个前提,左右子树必须都是堆,才能调整。
经过一次向下调整后,本来因为删除数据所导致的堆的结构的破坏就被恢复了。
有了这个思路,可以将过程实现如下:
//a - 堆的顺序存储数组
//size - 堆的顺序存储数组的数据个数
//parent - 需要进行向下调整的双亲下标
void AdjustDown(HDataType* a, int size, int parent)
{assert(a != NULL);//此时child代表左孩子int child = 2 * parent + 1;//孩子下标在数组范围内进入循环while (child < size){//child+1代表右孩子//建小堆 - 右孩子存在的话,左右孩子谁更小,child存储的就是谁的下标变量if (child + 1 < size && a[child + 1] < a[child]){++child;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = 2 * parent + 1;}else{break;}}
}
以上只是对一个数据进行的调整,要想实现堆的创建,这里我们从倒数第一个非叶子节点所形成的的子树开始调整,一直调整到根节点的树,就可以调整成堆。所以可以更进一步,完成一棵完全二叉树到堆的创建。
//n-1是最后一个数据的下标,((n-1)-1)/2是倒数第一个非叶子节点的下标
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{AdjustDown(a, n, i);
}
以上就是向下调整建堆的过程,我们可以分析一下它的时间复杂度。
同上,采取满二叉树的结构来进行复杂度的计算。
假设树的高度为h
第1层,202^020个节点,需要向下调整h-1层。
第2层,212^121个节点,需要向下调整h-2层。
第3层,222^222个节点,需要向下调整h-3层。
第4层,232^323个节点,需要向下调整h-4层。
…
第h-1层,2h−22^{h-2}2h−2个节点,需要向下调整1层。
第h层,2h−12^{h-1}2h−1个节点,需要向下调整0层。
则需要移动节点总的移动步数为:
T(n)=20∗(h−1)+21∗(h−2)+22∗(h−3)+23∗(h−4)+......+2(h−2)∗1+2(h−1)∗0T(n)=2^0*(h-1)+2^1*(h-2)+2^2*(h-3)+2^3*(h-4)+......+2^{(h-2)}*1+2^{(h-1)}*0T(n)=20∗(h−1)+21∗(h−2)+22∗(h−3)+23∗(h−4)+......+2(h−2)∗1+2(h−1)∗0
2T(n)=21∗(h−1)+22∗(h−2)+22∗(h−3)+24∗(h−4)+......+2(h−1)∗1+2h∗02T(n)=2^1*(h-1)+2^2*(h-2)+2^2*(h-3)+2^4*(h-4)+......+2^{(h-1)}*1+2^h*02T(n)=21∗(h−1)+22∗(h−2)+22∗(h−3)+24∗(h−4)+......+2(h−1)∗1+2h∗0
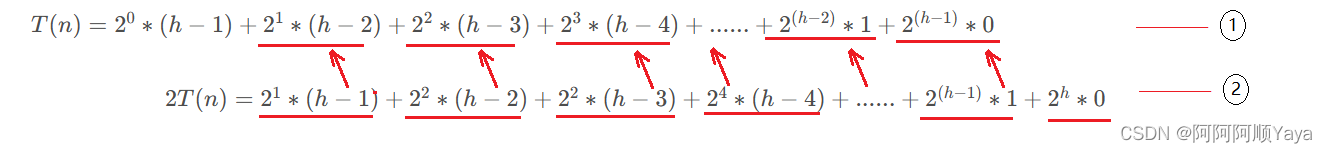
由错位相减得:
T(n)=(1−h)+21+22+23+24+2(h−2)+2(h−1)T(n)=(1-h)+2^1+2^2+2^3+2^4+2^{(h-2)}+2^{(h-1)}T(n)=(1−h)+21+22+23+24+2(h−2)+2(h−1)
T(n)=20+21+22+23+24+2(h−2)+2(h−1)−hT(n)=2^0+2^1+2^2+2^3+2^4+2^{(h-2)}+2^{(h-1)}-hT(n)=20+21+22+23+24+2(h−2)+2(h−1)−h
T(n)=2h−1−hT(n)=2^h-1-hT(n)=2h−1−h
因为是满二叉树,所以节点数n与高度h之间存在如下关系:
n=2h−1n=2^h-1n=2h−1,h=log2(n+1)h=log_2(n+1)h=log2(n+1)
所以T(n)=n−long2(n+1)T(n)=n-long_2(n+1)T(n)=n−long2(n+1)
因此,得出向下建堆的时间复杂度是O(n)。
通过比较,向上建堆的时间复杂度是O(n∗log2nn*log_2nn∗log2n),向下建堆的时间复杂度是O(n),所以采取向下建堆会更优一些。
以上过程都是对小堆的建立,如果要建大堆,只需要将判断条件略作更改即可:
//建小堆
if (a[child] < a[parent])
if (child + 1 < size && a[child + 1] < a[child])
if (a[child] < a[parent])//建大堆:
if (a[child] > a[parent])
if (child + 1 < size && a[child + 1] > a[child])
if (a[child] > a[parent])
堆的操作链接
最后,对于堆的各种操作需求,可以参考阿顺的这篇堆(C语言实现)
相关文章:
堆的结构与实现
堆的结构与实现二叉树的顺序结构堆的概念及结构堆的实现堆的创建向上调整建堆向下调整建堆堆的操作链接二叉树的顺序结构 堆其实是具有一定规则限制的完全二叉树。 普通的二叉树是不太适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树会更适合使用顺…...

Pandas快速入门
Pandas是Python中非常流行的数据处理库之一,它提供了一种简单而强大的方法来处理和分析数据。在本篇文章中,我将向你介绍Pandas的基础知识,以便你可以开始使用它来处理和分析数据。 安装Pandas 首先,你需要安装Pandas。可以通过…...
LVGL学习笔记18 - 表Table
目录 1. Parts 1.1 LV_PART_MAIN 1.2 LV_PART_ITEMS 2. 样式 2.1 设置行列数 2.2 设置单元格字符串 2.3 设置单元格宽度 2.4 设置表格高度和宽度 2.5 设置字符串颜色 2.6 设置边框颜色 2.7 设置背景颜色 3. 事件 4. CELL CTRL 表格是由包含文本的行、列和单元格构…...

嵌入式安防监控项目——html框架分析和环境信息刷新到网页
目录 一、html控制LED 二、模拟数据上传到html 一、html控制LED 简单来说就是html给boa服务器发了一个控制指令信息,然后boa转发给cgi进程,cgi通过消息队列和主进程通信。主进程再去启动LED子线程。 这是老师给的工程。 以前学32都有这工具那工具来管…...
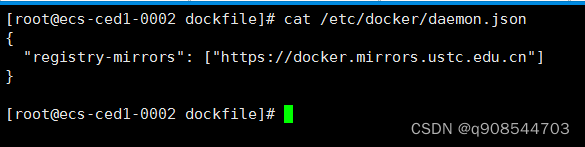
centos安装docker详细步骤
目录 一.前言 1.环境要求2.官网中文安装参考手册 二.安装步骤 1.卸载旧版本2.安装需要的软件包3.设置docker镜像源 1.配置docker镜像源 方式1:官网地址(外国):方式2:阿里云源:2.查看配置是否成功 4.更新yum软件包索引5.可以查看…...
初识HTML、W3C标准、如何利用IDEA创建HTML项目、HTML基本结构、网页基本信息
一、什么是HTML? HTML——Hyper Text Markup Languagr(超文本标记语言) 超文本包括:文字、图片、音频、视频、动画等 目前网页中常用——HTML5 HTML5提供了一些新的元素和一些有趣的新特性,同时也建立了一些新的规则…...

为什么程序员喜欢这些键盘?
文章目录程序员的爱介绍个人体验程序员的爱 程序员是长时间使用计算机的群体,他们需要一款高品质的键盘来保证舒适的打字体验和提高工作效率。在键盘市场上,有很多不同类型的键盘,但是对于程序员来说,机械键盘是他们最钟爱的选择…...

JS中数组去重的几种方法
JS 中有多种方法可以实现数组去重,下面是几种常用的方法:1、使用 Set 去重:Set 数据结构中不能有重复元素,可以将数组转成 Set 类型,再转回数组。let arr [1,2,3,4,5,6,2,3,4]; let uniqueArr [...new Set(arr)]; co…...

Nginx 配置实例-负载均衡
一、实现效果 浏览器地址栏输入地址 http://192.168.137.129/edu/a.html,负载均衡效果,将请求平均分配到8080和8081两台服务器上。 二、准备工作 1. 准备两台tomcat服务器,一台8080,一台8081 (具体操作如下两个链接) Nginx配置实…...

引出生命周期、生命周期_挂载流程、生命周期_更新流程、生命周期_销毁流程、生命周期_总结——Vue
目录 一、引出生命周期 二、生命周期_挂载流程 三、生命周期_更新流程 四、生命周期_销毁流程 五、生命周期_总结 一、引出生命周期 生命周期: 1.又名:生命周期回调函数、生命周期函数、生命周期钩子。 2.是什么:Vue在关键时刻帮我们调…...

C++ STL学习之【vector的使用】
✨个人主页: Yohifo 🎉所属专栏: C修行之路 🎊每篇一句: 图片来源 The power of imagination makes us infinite. 想象力的力量使我们无限。 文章目录📘前言📘正文1、默认成员函数1.1、默认构造…...

方差分析与单因素方差分析
研究分类型自变量对数值型因变量的影响。检验统计的设定和检验方法与变量间的方差是否相等有关。 例如研究行业、服务等级对投诉数的影响:如表格中给出4个行业、每个行业有3个服务等级、样本容量为7、观测值为投诉数。则构成一个3维的矩阵。 在上述基础上…...

分布式链路追踪组件skywalking介绍
SkyWalking组件概念 一个开源的可观测平台, 用于从服务和云原生基础设施收集, 分析, 聚合及可视化数据。SkyWalking 提供了一种简便的方式来清晰地观测分布式系统, 甚至横跨多个云平台。SkyWalking 更是一个现代化的应用程序性能监控(Application Performance Monitoring)系统…...
SUBMIT的用法
SUBMIT的用法 一、简介 系统MB52/MB51/MB5B等类似的报表 ,虽然数据很全面,执行效率也够快,但是经常会不满足用户需求(增添字段、添加查询条件等),很多ABAP 会选择去COPY出标准程序,然后去做修改…...

网页基本标签、图像标签、链接标签、块内元素和块元素、列表标签、表格标签
一、网页基本标签 标题标签 段落标签 未写段落标签前,文本没有按照想要的格式排列显示 写段落标签后: 每句都是一段,所以句与句距离比较宽 换行标签 同一段,只是把文字换行,所以比较紧凑 水平线标签 字体样式标签 …...
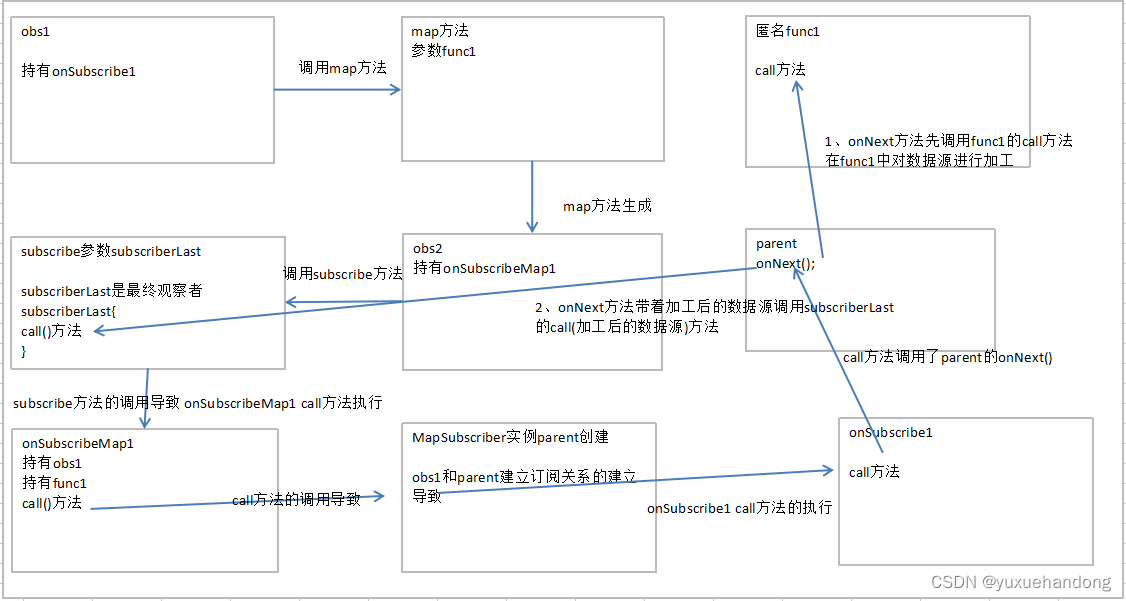
RxJava操作符变换过程
要使用Rxjava首先要导入两个包,其中rxandroid是rxjava在android中的扩展 implementation io.reactivex:rxandroid:1.2.1implementation io.reactivex:rxjava:1.2.0我们在使用rxjava的操作符时都觉得很方便,但是rxjava是怎么实现操作符的转换呢࿰…...

开放平台订单接口
custom-自定义API操作 注册开通 taobao.custom 公共参数 名称 类型 必须 描述 key String 是 调用key(必须以GET方式拼接在URL中) secret String 是 调用密钥 api_name String 是 API接口名称(包括在请求地址中&a…...

CDN相关知识点
1、什么是CDN?CDN的作用是什么? CDN(Content Delivery Network,内容分发网络)是一种通过在多个节点上分布内容以提高网络性能、可靠性和可扩展性的网络解决方案。CDN通过在不同的地理位置部署服务器,使用户…...
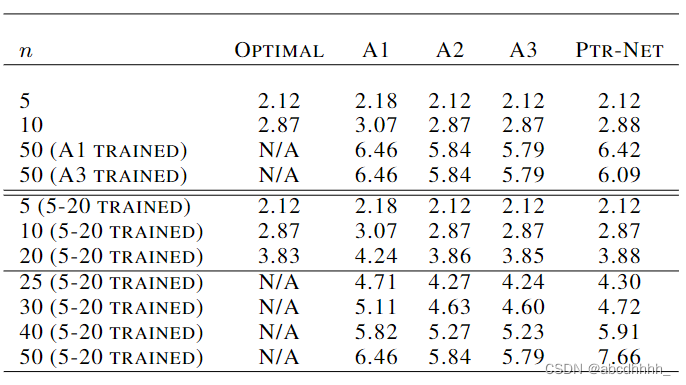
【论文阅读】注意力机制与二维 TSP 问题
前置知识 注意力机制 见 这篇 二维 TSP 问题 给定二维平面上 nnn 个点的坐标 S{xi}i1nS\{x_i\}_{i1}^nS{xi}i1n,其中 xi∈[0,1]2x_i\in [0,1]^2xi∈[0,1]2,要找到一个 1∼n1\sim n1∼n 的排列 π\piπ ,使得目标函数 L(π∣s)∥xπ…...
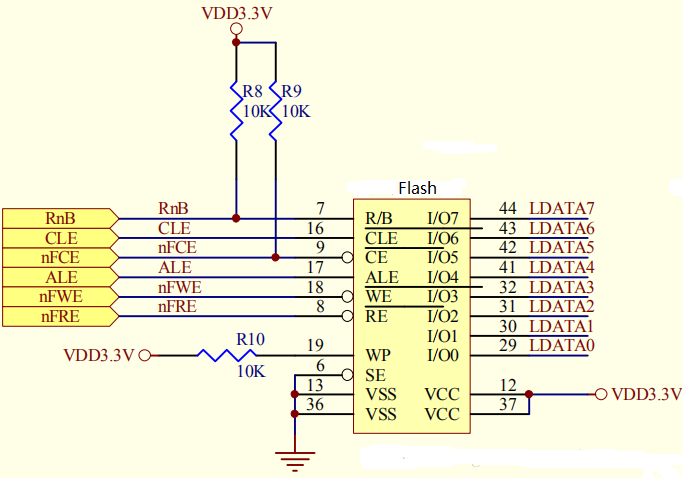
[深入理解SSD系列 闪存实战2.1.7] NAND FLASH基本编程(写)操作及原理_NAND FLASH Program Operation 源码实现
前言 上面是我使用的NAND FLASH的硬件原理图,面对这些引脚,很难明白他们是什么含义, 下面先来个热身: 问1. 原理图上NAND FLASH只有数据线,怎么传输地址? 答1.在DATA0~DATA7上既传输数据,又传输地址 当ALE为高电平时传输的是地址, 问2. 从N...

基于LLM的Python脚本自我进化:构建AI驱动的代码优化框架
1. 项目概述:当Python脚本学会自我进化几年前,如果有人告诉我,我写的Python脚本能在我喝咖啡的时候自己给自己“打补丁”、优化逻辑,我肯定会觉得这是科幻小说里的情节。但今天,这已经是我日常工作流的一部分。这个项目…...

教育云平台数据泄露与网络钓鱼风险防控研究—— 基于牛津大学 Canvas 安全事件的分析
摘要 教育数字化转型背景下,云学习管理平台的数据安全与风险防控已成为全球高校共同面临的挑战。2026 年 5 月,全球主流教育云平台 Canvas 发生大规模未授权访问事件,牛津大学等多所高校用户数据遭泄露,核心风险直指数据泄露后的…...

浏览器端微信使用指南:告别繁琐安装,开启轻量沟通新时代
浏览器端微信使用指南:告别繁琐安装,开启轻量沟通新时代 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信PC版的庞大…...

大型机场U型机坪推出等待点运行优化【附案例】
✨ 长期致力于机场、U型机坪区、推出等待点、运行程序优化、启发式算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)单通道U型机坪推出等待点位优化…...

SAP Fiori Launchpad Designer保姆级教程:手把手教你为ME29N采购订单审批创建自定义磁贴
SAP Fiori Launchpad Designer保姆级教程:手把手教你为ME29N采购订单审批创建自定义磁贴 当你所在的企业尚未部署HR模块,却需要快速启用ME29N采购订单审批功能时,SAP Fiori Launchpad Designer(FLPD_CUST)将成为你的得…...

绩效考核的量化迷思:如何衡量不可直接测量的技术贡献
一、量化绩效考核的困境:软件测试的“隐形”价值在软件行业的绩效考核体系中,量化指标似乎成了“公平”与“高效”的代名词。代码行数、Bug数量、测试用例覆盖率……这些清晰可统计的数字,被当作衡量技术人员贡献的核心标尺。然而,…...

别再乱接电源了!STM32的VDDA、VSSA、VBAT引脚,一个没接对,ADC采样全是噪声
STM32电源设计实战:VDDA、VSSA与VBAT的噪声抑制艺术 当你的STM32项目遇到ADC采样值跳变、RTC计时不准或程序下载失败时,电源引脚的设计往往是罪魁祸首。许多工程师在PCB布局时,对这些看似简单的电源引脚处理过于随意,结果在调试阶…...

Vivado 伪双口RAM IP核的配置精髓与实战避坑指南
1. 伪双口RAM的本质与真双口RAM的差异 第一次接触伪双口RAM(Simple Dual Port RAM)时,很多人会疑惑它和真双口RAM(True Dual Port RAM)到底有什么区别。这个问题困扰了我很久,直到在实际项目中踩了几个坑才…...

nlux框架:快速构建可定制AI对话界面的JavaScript解决方案
1. 项目概述:一个面向未来的对话式AI集成框架如果你最近在关注AI应用开发,尤其是想在自己的产品里快速集成一个类似ChatGPT那样的智能对话界面,那你很可能已经听说过或者搜索过“nlux”或“nlkitai/nlux”这个项目。简单来说,nlux…...

CANN/asc-devkit bfloat16转half API
__bfloat162half_ru 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://git…...