【机器学习】ChatTTS:开源文本转语音(text-to-speech)大模型天花板

目录
一、引言
二、TTS(text-to-speech)模型原理
2.1 VITS 模型架构
2.2 VITS 模型训练
2.3 VITS 模型推理
三、ChatTTS 模型实战
3.1 ChatTTS 简介
3.2 ChatTTS 亮点
3.3 ChatTTS 数据集
3.4 ChatTTS 部署
3.4.1 创建conda环境
3.4.2 拉取源代码
3.4.3 安装环境依赖
3.4.4 启动WebUI
3.4.5 WebUI推理
3.5 ChatTTS 代码
四、总结
一、引言
我很愿意推荐一些小而美、高实用模型,比如之前写的YOLOv10霸榜百度词条,很多人搜索,仅需100M就可以完成毫秒级图像识别与目标检测,相关的专栏也是CSDN付费专栏中排行最靠前的。今天介绍有一个小而美、高实用性的模型:ChatTTS。
二、TTS(text-to-speech)模型原理
2.1 VITS 模型架构
由于ChatTTS还没有公布论文,我们也不好对ChatTTS的底层原理进行武断。这里对另一个TTS里程碑模型VITS原理进行简要介绍,让大家对TTS模型原理有多认知。VITS详细论文见链接
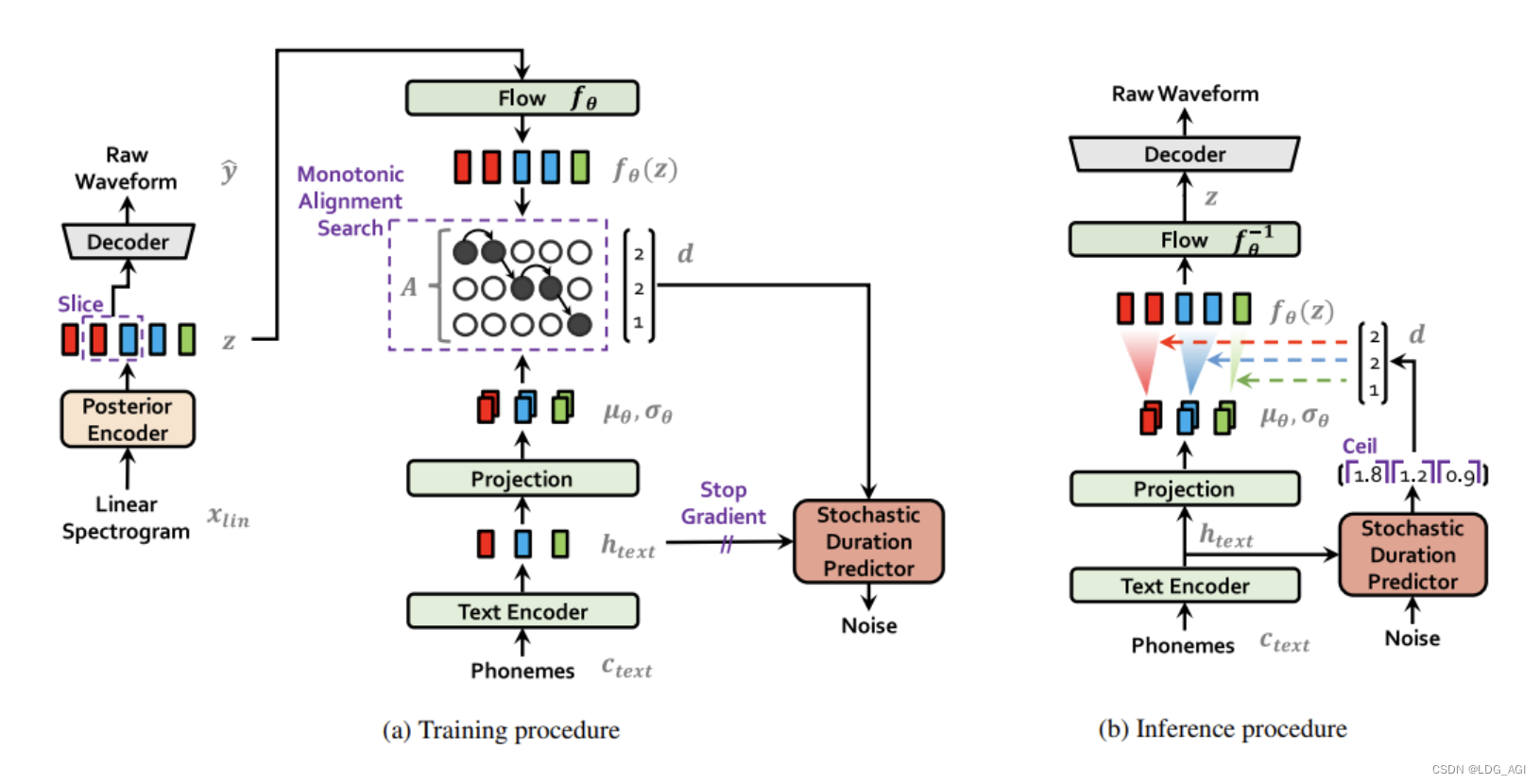
VITS论文对训练和推理两个环节分别进行讲述:
2.2 VITS 模型训练
VITS模型训练:在训练阶段,音素(Phonemes)可以被简单理解为文字对应的拼音或音标。它们经过文本编码(Text Encode)和映射(Projection)后,生成了文本的表示形式。左侧的线性谱(Linear Sepctrogram)是从用于训练的音频中提取的 wav 文件的音频特征。这些特征通过后验编码器(Posteritor)生成音频的表示,然后通过训练对齐这两者(在模块 A 中)。节奏也是表达的重要因素,因此还加入了一个随机持续时间预测器(Stochasitic Duration Predictor)模块,根据音素和对齐结果对输出音频长度进行调整。
2.3 VITS 模型推理
VITS模型推理:在推理过程中,输入是文本对应的音素。将映射和对长度采样输入模型,将其转换为语音表示流,然后通过解码器将其转换为音频格式。
根据论文中描述的逻辑,文本数据被转换为音素(即词的拼音)并输入模型。模型学习了音素与音频之间的关系,包括说话者的音质、音高、口音和发音习惯等。
三、ChatTTS 模型实战
3.1 ChatTTS 简介
ChatTTS 是一款专门为对话场景(例如 LLM 助手)设计的文本转语音模型。
3.2 ChatTTS 亮点
- 对话式 TTS: ChatTTS 针对对话式任务进行了优化,能够实现自然且富有表现力的合成语音。它支持多个说话者,便于生成互动式对话。
- 精细的控制: 该模型可以预测和控制精细的韵律特征,包括笑声、停顿和插入语。
- 更好的韵律: ChatTTS 在韵律方面超越了大多数开源 TTS 模型。我们提供预训练模型以支持进一步的研究和开发。
3.3 ChatTTS 数据集
- 主模型使用了 100,000+ 小时的中文和英文音频数据进行训练。
- HuggingFace 上的开源版本是一个在 40,000 小时数据上进行无监督微调的预训练模型。
3.4 ChatTTS 部署
3.4.1 创建conda环境
conda create -n chattts
conda activate chattts3.4.2 拉取源代码
git clone https://github.com/2noise/ChatTTS
cd ChatTTS3.4.3 安装环境依赖
pip install -r requirements.txt3.4.4 启动WebUI
export CUDA_VISIBLE_DEVICES=3 #指定显卡
nohup python examples/web/webui.py --server_name 0.0.0.0 --server_port 8888 > chattts_20240624.out 2>&1 & #后台运行执行后会自动跳转出webui,地址为server_name:server_port
3.4.5 WebUI推理
个人感觉:其中夹杂着“那个”、“然后”、“嗯...”等口头禅,学的太逼真了,人类说话不就是这样么。。

- [uv_break]、[laugh]等符号进行断句、微笑等声音控制。
- Audio Seed:用于初始化随机数生成器的种子值。设置相同的 Audio Seed 可以确保重复生成一致的语音,便于实验和调试。推荐 Seed: 3798-知性女、462-大舌头女、2424-低沉男。
- Text Seed:类似于 Audio Seed,在文本生成阶段用于初始化随机数生成器的种子值。
- Refine Text:勾选此选项可以对输入文本进行优化或修改,提升语音的自然度和可理解性。
- Audio Temperature️:控制输出的随机性。数值越高,生成的语音越可能包含意外变化;数值较低则趋向于更平稳的输出。
- Top_P:核采样策略,定义概率累积值,模型将只从这个累积概率覆盖的最可能的词中选择下一个词。
- Top_K:限制模型考虑的可能词汇数量,设置为一个具体数值,模型将只从这最可能的 K 个词中选择下一个词。
3.5 ChatTTS 代码
import os, sysif sys.platform == "darwin":os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"now_dir = os.getcwd()
sys.path.append(now_dir)import random
import argparseimport torch
import gradio as gr
import numpy as npfrom dotenv import load_dotenv
load_dotenv("sha256.env")import ChatTTS# 音色选项:用于预置合适的音色
voices = {"默认": {"seed": 2},"音色1": {"seed": 1111},"音色2": {"seed": 2222},"音色3": {"seed": 3333},"音色4": {"seed": 4444},"音色5": {"seed": 5555},"音色6": {"seed": 6666},"音色7": {"seed": 7777},"音色8": {"seed": 8888},"音色9": {"seed": 9999},"音色10": {"seed": 11111},
}def generate_seed():new_seed = random.randint(1, 100000000)return {"__type__": "update","value": new_seed}# 返回选择音色对应的seed
def on_voice_change(vocie_selection):return voices.get(vocie_selection)['seed']def generate_audio(text, temperature, top_P, top_K, audio_seed_input, text_seed_input, refine_text_flag):torch.manual_seed(audio_seed_input)rand_spk = chat.sample_random_speaker()params_infer_code = {'spk_emb': rand_spk,'temperature': temperature,'top_P': top_P,'top_K': top_K,}params_refine_text = {'prompt': '[oral_2][laugh_0][break_6]'}torch.manual_seed(text_seed_input)if refine_text_flag:text = chat.infer(text,skip_refine_text=False,refine_text_only=True,params_refine_text=params_refine_text,params_infer_code=params_infer_code)wav = chat.infer(text,skip_refine_text=True,params_refine_text=params_refine_text,params_infer_code=params_infer_code)audio_data = np.array(wav[0]).flatten()sample_rate = 24000text_data = text[0] if isinstance(text, list) else textreturn [(sample_rate, audio_data), text_data]def main():with gr.Blocks() as demo:gr.Markdown("# ChatTTS Webui")gr.Markdown("ChatTTS Model: [2noise/ChatTTS](https://github.com/2noise/ChatTTS)")default_text = "四川美食确实以辣闻名,但也有不辣的选择。[uv_break]比如甜水面、赖汤圆、蛋烘糕、叶儿粑等,这些小吃口味温和,甜而不腻,也很受欢迎。[laugh]"text_input = gr.Textbox(label="Input Text", lines=4, placeholder="Please Input Text...", value=default_text)with gr.Row():refine_text_checkbox = gr.Checkbox(label="Refine text", value=True)temperature_slider = gr.Slider(minimum=0.00001, maximum=1.0, step=0.00001, value=0.3, label="Audio temperature")top_p_slider = gr.Slider(minimum=0.1, maximum=0.9, step=0.05, value=0.7, label="top_P")top_k_slider = gr.Slider(minimum=1, maximum=20, step=1, value=20, label="top_K")with gr.Row():voice_options = {}voice_selection = gr.Dropdown(label="音色", choices=voices.keys(), value='默认')audio_seed_input = gr.Number(value=2, label="Audio Seed")generate_audio_seed = gr.Button("\U0001F3B2")text_seed_input = gr.Number(value=42, label="Text Seed")generate_text_seed = gr.Button("\U0001F3B2")generate_button = gr.Button("Generate")text_output = gr.Textbox(label="Output Text", interactive=False)audio_output = gr.Audio(label="Output Audio")# 使用Gradio的回调功能来更新数值输入框voice_selection.change(fn=on_voice_change, inputs=voice_selection, outputs=audio_seed_input)generate_audio_seed.click(generate_seed,inputs=[],outputs=audio_seed_input)generate_text_seed.click(generate_seed,inputs=[],outputs=text_seed_input)generate_button.click(generate_audio,inputs=[text_input, temperature_slider, top_p_slider, top_k_slider, audio_seed_input, text_seed_input, refine_text_checkbox],outputs=[audio_output, text_output])gr.Examples(examples=[["四川美食确实以辣闻名,但也有不辣的选择。比如甜水面、赖汤圆、蛋烘糕、叶儿粑等,这些小吃口味温和,甜而不腻,也很受欢迎。", 0.3, 0.7, 20, 2, 42, True],["What is [uv_break]your favorite english food?[laugh][lbreak]", 0.5, 0.5, 10, 245, 531, True],["chat T T S is a text to speech model designed for dialogue applications. [uv_break]it supports mixed language input [uv_break]and offers multi speaker capabilities with precise control over prosodic elements [laugh]like like [uv_break]laughter[laugh], [uv_break]pauses, [uv_break]and intonation. [uv_break]it delivers natural and expressive speech,[uv_break]so please[uv_break] use the project responsibly at your own risk.[uv_break]", 0.2, 0.6, 15, 67, 165, True],],inputs=[text_input, temperature_slider, top_p_slider, top_k_slider, audio_seed_input, text_seed_input, refine_text_checkbox],)parser = argparse.ArgumentParser(description='ChatTTS demo Launch')parser.add_argument('--server_name', type=str, default='0.0.0.0', help='Server name')parser.add_argument('--server_port', type=int, default=8080, help='Server port')parser.add_argument('--root_path', type=str, default=None, help='Root Path')parser.add_argument('--custom_path', type=str, default=None, help='the custom model path')args = parser.parse_args()print("loading ChatTTS model...")global chatchat = ChatTTS.Chat()if args.custom_path == None:chat.load_models()else:print('local model path:', args.custom_path)chat.load_models('custom', custom_path=args.custom_path)demo.launch(server_name=args.server_name, server_port=args.server_port, root_path=args.root_path, inbrowser=True)if __name__ == '__main__':main()
通过import ChatTTS和chat = ChatTTS.chat()以及chat.infer对ChatTTS类进行引用,通过装载多个配置项进行不同语音类型的生成。
四、总结
本文首先以VITS为例,对TTS基本原理进行简要讲解,让大家对TTS模型有基本的认知,其次对ChatTTS模型进行step by step实战教学,个人感觉4万小时语音数据开源版本还是被阉割的很严重,可能担心合规问题吧。其次就是没有特定的角色与种子值对应关系,需要人工去归类,期待更多相关的工作诞生。
实用性上来讲,对于语音聊天助手,确实是一种技术上的升级,不需要特别多的GPU资源就可以搭建语音聊天服务,比LLM聊天上升了一个档次。最近好忙,主要在做一个人工智能助手,3天涨了1.3万粉丝。最近计划把ChatTTS应用于这个人工智能助手(微博:面子小行家)的私信回复中,涉及到音频文件与业务相结合。期待我的成果吧!
如果您还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
AI智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个DNN网络
AI智能体研发之路-模型篇(七):【机器学习】基于YOLOv10实现你的第一个视觉AI大模型
AI智能体研发之路-模型篇(八):【机器学习】Qwen1.5-14B-Chat大模型训练与推理实战
AI智能体研发之路-模型篇(九):【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
AI智能体研发之路-模型篇(十):【机器学习】Qwen2大模型原理、训练及推理部署实战
《AI—Transformers应用》
【AI大模型】Transformers大模型库(一):Tokenizer
【AI大模型】Transformers大模型库(二):AutoModelForCausalLM
【AI大模型】Transformers大模型库(三):特殊标记(special tokens)
【AI大模型】Transformers大模型库(四):AutoTokenizer
【AI大模型】Transformers大模型库(五):AutoModel、Model Head及查看模型结构
【AI大模型】Transformers大模型库(六):torch.cuda.OutOfMemoryError: CUDA out of memory解决
【AI大模型】Transformers大模型库(七):单机多卡推理之device_map
【AI大模型】Transformers大模型库(八):大模型微调之LoraConfig
相关文章:
【机器学习】ChatTTS:开源文本转语音(text-to-speech)大模型天花板
目录 一、引言 二、TTS(text-to-speech)模型原理 2.1 VITS 模型架构 2.2 VITS 模型训练 2.3 VITS 模型推理 三、ChatTTS 模型实战 3.1 ChatTTS 简介 3.2 ChatTTS 亮点 3.3 ChatTTS 数据集 3.4 ChatTTS 部署 3.4.1 创建conda环境 3.4.2 拉取源…...
宏集物联网工控屏通过 S7 ETH 协议采集西门子 1200 PLC 数据
前言 为了实现和西门子PLC的数据交互,宏集物联网HMI集成了S7 PPI、S7 MPI、S7 Optimized、S7 ETH等多个驱动来适配西门子200、300、400、1200、1500、LOGO等系列PLC。 本文主要介绍宏集物联网HMI如何通过S7 ETH协议采集西门子1200 PLC的数据,文中详细介…...
C语言学习记录(十一)——指针基本知识及运算
文章目录 前言1. 指针的概念2.指针变量的说明3. 指针的含义4. 指针运算①指针加减:②指针的关系运算符 前言 一个学习嵌入式的小白~ 有问题评论区或私信指出~ 提示:以下是本篇文章正文内容,下面案例可供参考 1. 指针的概念 在C语言中&…...
的语法及在对应不同需求下应如何使用)
Oracle中 ROW_NUMBER()的语法及在对应不同需求下应如何使用
Oracle数据库中的ROW_NUMBER()函数是一个窗口函数,它为查询结果集中的每一行分配一个唯一的序号。这个函数在数据分析、分页查询、数据去重和排名问题等方面非常有用。ROW_NUMBER()函数的语法如下: ROW_NUMBER() OVER ( [ PARTITION BY column ] ORDER …...

德邦快递大件可以寄2米长物品吗?大件跨省行李用哪个快递便宜?
搬家或寄送特殊尺寸物品时,快递的选择尤为关键。特别是2米长的大件物品,是否能够承运?哪家快递在跨省大件行李方面更经济?今天,就为你解答这些疑问。 1、祺祺寄快递小程序: “祺祺寄快递”小程序ÿ…...

C# 在WPF .net8.0框架中使用FontAwesome 6和IconFont图标字体
文章目录 一、在WPF中使用FontAwesome 6图标字体1.1 下载FontAwesome1.2 在WPF中配置引用1.2.1 引用FontAwesome字体文件1.2.2 将字体文件已资源的形式生成 1.3 在项目中应用1.3.1 使用方式一:局部引用1.3.2 使用方式二:单个文件中全局引用1.3.3 使用方式…...
万能自定义预约小程序源码系统 适合任何行业在线预约报名 前后端分离 带完整的安装代码包以及搭建教程
系统概述 在当今数字化时代,线上预约已成为各行各业不可或缺的一部分。为满足广大企业和个人对在线预约系统的需求,我们特别推出了这款“万能自定义预约小程序源码系统”。该系统以其高度的灵活性和可扩展性,为各行各业提供了完美的在线预约…...

【MySQL备份】mysqldump篇
目录 1.简介 2.基本用途 3.命令格式 3.1常用选项 3.2常用命令 4.备份脚本 5.定时执行备份脚本 1.简介 mysqldump 是 MySQL 数据库管理系统的命令行实用程序,用于创建数据库的逻辑备份。它能够导出数据库的结构(如表结构、视图、触发器等…...
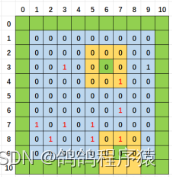
控制台扫雷(C语言实现)
目录 博文目的实现思路项目创建文件解释 具体实现判断玩家进行游戏还是退出扫雷棋盘的确定地图初始化埋雷玩家扫雷的实现雷判断函数 源码game.cgame.h扫雷.c 博文目的 相信不少人都学习了c语言的函数,循环,分支那我们就可以写一个控制台的扫雷小游戏来检…...

操作系统期末复习 | 批处理程序 | PV实现同步互斥 | 调度算法 | 页面置换算法 | 磁盘调度算法
操作系统引论 批处理程序 单道批处理:引入脱机输入/输出技术,并由监督程序负责控制作业的输入、输出。主要优点是缓解了一定程度的人机速度矛盾,资源利用率有所提升。主要缺点是内存中仅能有一道程序运行,只有该程序运行结束之后…...

字符串的六种遍历方式
在 Java 中,有多种遍历字符串的方法。以下是几种常见的遍历字符串的方法,并附有示例代码 1. 使用 for 循环 这是最常见和基础的遍历方法,通过索引访问每个字符。 public class StringTraversal {public static void main(String[] args) {S…...
上建立分支(Branch)的步骤如下:)
在码云(Gitee)上建立分支(Branch)的步骤如下:
步骤一:登录码云 首先,打开码云的官方网站(gitee.com),输入用户名和密码登录你的账号。 步骤二:创建仓库 登录后,在页面右上方的搜索框中输入仓库名称,并点击“创建”按钮创建新的仓…...

JVM专题四:JVM的类加载机制
Java中类的加载阶段 类加载 Java中的类加载机制是Java运行时环境的一部分,确保Java类可以被JVM(Java虚拟机)正确地加载和执行。类加载机制主要分为以下几个阶段: 加载(Loading):这个阶段&#x…...
Python爬取中国天气网天气数据.
一、主题式网络爬虫设计方案 1.主题式网络爬虫名称 名称:Python爬取中国天气网天气数据 2.主题式网络爬虫爬取的内容与数据特征分析 本次爬虫主要爬取中国天气网天气数据 3.主题式网络爬虫设计方案概述(包括实现思路与技术难点) reques…...

EXCEL快速填充空白内容
** EXCEL快速填充空白内容 ** 1.全选所有需要填充的内容,按住电脑的F5或者CTRLG点击定位 2.可以看到空白处被自动选定,之后按电脑和⬆,最后CTRLenter 可以看到空白处已经被填充。...
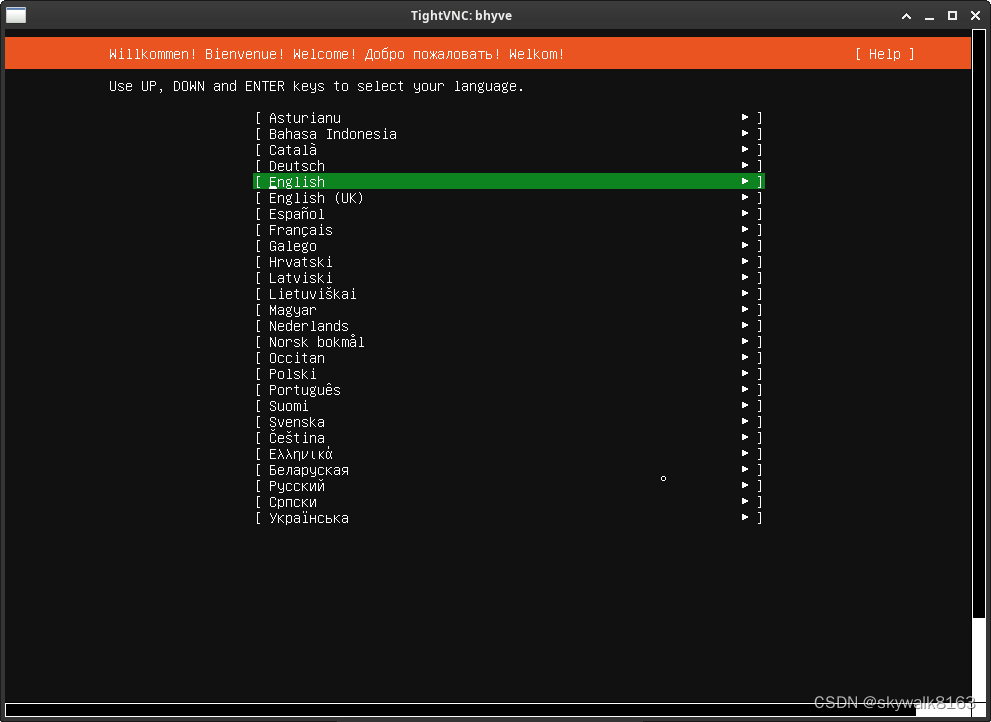
CBSD创建和管理bhyve容器Ubuntu@FreeBSD
bhyve介绍:bhyve:FreeBSD下的原生虚拟机管理器_freebsd 虚拟化平台bhyve-CSDN博客 两个bhyve的管理软件:使用bvm管理bhyve虚拟机管理系统FreeBSD-CSDN博客 vm-bhyve:bhyve虚拟机的管理系统FreeBSD-CSDN博客 现在,我…...

STM32开发实战:SPI接口在W25Q64 Flash存储器中的应用
摘要 本文将深入探讨STM32微控制器如何利用SPI接口与W25Q64 Flash存储器进行通信。W25Q64是一款常用的SPI串行Flash存储器,具有8Mbit的存储容量。本教程将指导读者完成硬件连接、SPI配置、读写操作,并提供实际的代码实现。 1. SPI接口概述 SPI是一种串…...

python一些进阶用法:hook 钩子函数以及Registry机制
写在前面 一句话讲,register机制 和 hook 都是函数/类 调用和传参机制的一种灵活运用,将函数作为传参对象,进行回调和封装,通常扩展了或修改了原始函数的行为;这些高级用法都是编程经验中沉淀下来的常用范式࿰…...
工作实践:11种API性能优化方法
一、索引优化 接口性能优化时,大家第一个想到的通常是:优化索引。 确实,优化索引的成本是最小的。 你可以通过查看线上日志或监控报告,发现某个接口使用的某条SQL语句耗时较长。 此时,你可能会有以下疑问ÿ…...
正版软件 | WIFbox:智能化文件管理工具,让效率与隐私并行
在数字化办公日益普及的今天,文件管理成为了提升工作效率的关键。WIFbox 一款智能文件管理工具,利用强大的人工智能技术,帮助您快速对文件进行分类,完成复杂的智能文件分类任务。 智能分类,效率倍增 WIFbox 通过精细化…...

oh-my-iflow:基于多智能体协作的自动化命令行开发工作流
1. 项目概述:当命令行遇上多智能体工作流如果你和我一样,每天有大量时间泡在终端里,那你肯定对命令行工具的效率又爱又恨。爱的是它直接、强大,恨的是很多复杂任务依然需要我们手动串联多个命令,或者在不同工具间来回切…...

JPlag代码抄袭检测:你的学术诚信守护神
JPlag代码抄袭检测:你的学术诚信守护神 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 你是否曾为学生的代码…...
:8大核心维度,适配信创+全行业场景)
2026设备管理系统选型标准(技术向):8大核心维度,适配信创+全行业场景
对于企业IT运维、采购人员而言,设备管理系统选型需兼顾技术适配、合规要求、落地效率与长期扩展性。本文从技术与实践角度,梳理出8大核心选型标准,重点覆盖独享云部署、Excel导入能力、自定义扩展、信创适配等关键维度,为技术选型…...

从规范到验证:构建企业级环境变量与密钥安全管理体系
1. 项目概述:从“裸奔”到“装甲车”的密钥管理进化在开发一个现代应用时,我们几乎不可避免地要和一堆敏感信息打交道:数据库密码、API密钥、第三方服务的访问令牌、加密盐值……这些信息,我们通常称之为“环境变量”或“密钥”。…...

Nodejs后端服务如何稳定调用Claude并避免封号风险
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Nodejs后端服务如何稳定调用Claude并避免封号风险 1. 后端集成Claude的常见挑战 在Node.js后端服务中集成Claude模型,…...

关于岐金兰AI元人文构想与江畅《论道德真理》之关系的理论说明
关于岐金兰AI元人文构想与江畅《论道德真理》之关系的理论说明——致敬江畅教授,并申明独立研究的道路岐金兰2026年5月12日一、相遇:迟到的阅读,及时的对话2026年3月11日,我在一个偶然的学术检索中读到了江畅教授的《论道德真理》…...

STM32F103C8T6与DHT11单总线通信:从时序解析到数据校验的实战指南
1. 认识STM32F103C8T6与DHT11这对黄金搭档 第一次接触嵌入式开发的朋友可能会觉得,让单片机读取温湿度数据是个复杂的事情。但当你用STM32F103C8T6这颗性价比超高的Cortex-M3内核芯片,搭配DHT11这个经典温湿度传感器时,事情就变得简单多了。…...

Windows10系统V-rep安装避坑指南:从百度网盘资源到环境配置
1. 为什么选择V-rep以及准备工作 如果你是机器人学或仿真技术的初学者,V-rep(现更名为CoppeliaSim)绝对是一个值得尝试的仿真平台。它轻量级、跨平台,而且对硬件要求不高,特别适合在个人电脑上进行算法验证和教学演示…...

企业级长文档AI落地避坑指南,从PDF解析失真到语义断裂修复——Claude 2026六大隐性能力详解
更多请点击: https://intelliparadigm.com 第一章:PDF解析失真问题的根源与本质诊断 PDF 文件虽为“便携式文档格式”,但其内部结构高度异构——文本可能嵌入在图形路径中、字体被子集化或完全缺失、字符编码映射断裂,甚至存在跨…...

Lumi Diary:基于OpenClaw Skill的本地AI记忆伴侣设计与实践
1. 项目概述:一个住在你设备里的记忆精灵如果你和我一样,对把生活点滴交给云端总有点不放心,但又渴望有一个能懂你、能帮你把碎片记忆编织成故事的伙伴,那么 Lumi Diary 的出现,可能正是时候。这不是又一个需要你手动打…...