深度解析:机器学习如何助力GPT-5实现语言理解的飞跃
文章目录
- 文章前言
- 机器学习在GPT-5中的具体应用
- 模型训练与优化
- 机器翻译与跨语言交流:
- 情感分析与问答系统:
- 集成机器学习功能:
- 文本生成
- 语言理解
- 任务适应
- 机器学习对GPT-5性能的影响
- 存在的挑战及解决方案
- 技术细节与示例
文章前言

GPT-5是OpenAI公司开发的一种先进的自然语言处理模型,它是GPT(Generative Pre-trained Transformer)系列的最新成员。GPT-5代表了当前自然语言处理领域的最前沿技术,通过深度学习和机器学习技术,GPT-5能够在海量文本数据上进行预训练,学习并理解人类语言的复杂性和多样性。GPT-5拥有庞大的模型规模和超强的生成能力,能够生成连贯、流畅且富含信息的文本,广泛应用于文本生成、问答系统、机器翻译、文本摘要等自然语言处理任务中。GPT-5的出现不仅推动了人工智能技术的发展,也为各行各业带来了革命性的变革。
机器学习在GPT-5中发挥着至关重要的作用,为GPT-5赋予了强大的文本生成和语言理解能力。以下将详细解释机器学习在GPT-5中的应用、对性能的影响、存在的挑战及解决方案,并提供相关的技术细节和示例。
机器学习在GPT-5中的具体应用

模型训练与优化
- GPT-5采用了大规模的预训练数据,通过机器学习算法进行训练,使模型能够学习到人类语言的复杂性和多样性。
- GPT-5的模型规模预计将达到近百万亿参数的级别,远超GPT-4的10万亿参数,这得益于机器学习算法在处理大规模数据时的效率。
- GPT-5通过机器学习不断优化模型参数,使预测结果尽可能接近真实文本,从而提升模型的准确性和泛化能力。
示例伪代码:
# 假设我们有一个预训练模型GPT5Model和一个训练数据集train_data # 初始化GPT-5模型
gpt5_model = GPT5Model() # 定义损失函数和优化器
loss_function = ... # 具体的损失函数,如交叉熵损失
optimizer = ... # 具体的优化器,如Adam优化器 # 训练循环
for epoch in range(num_epochs): for batch in train_data: # 前向传播 outputs = gpt5_model(batch) # 计算损失 loss = loss_function(outputs, batch['targets']) # 反向传播和优化 loss.backward() optimizer.step() optimizer.zero_grad() # 保存训练好的模型
gpt5_model.save('gpt5_trained_model.pth')

机器翻译与跨语言交流:
- GPT-5具备强大的机器翻译能力,能够实现多种语言间的互译,为跨语言交流提供便利。
- 机器学习算法使得GPT-5在翻译过程中能够准确捕捉语言的语义和上下文信息,确保翻译结果的准确性和流畅性。
示例伪代码:
# 假设我们有一个加载好的GPT-5翻译模型gpt5_translator # 加载GPT-5翻译模型
gpt5_translator = load_translator('gpt5_translator_model.pth') # 输入待翻译的文本和源语言、目标语言
source_text = "你好,世界!"
source_lang = 'zh'
target_lang = 'en' # 使用GPT-5翻译模型进行翻译
translated_text = gpt5_translator.translate(source_text, source_lang, target_lang) # 打印翻译结果
print(translated_text)
情感分析与问答系统:
- GPT-5可以应用于情感分析任务,通过机器学习算法识别文本中的情感倾向和情绪表达。
- 在问答系统方面,GPT-5可以理解用户的问题或需求,并给出相应的回答或建议。这种能力同样依赖于机器学习算法对语言理解和处理的能力。
示例伪代码:
# 假设我们有一个加载好的GPT-5情感分析模型gpt5_sentiment_analyzer和一个问答模型gpt5_qa_model # 加载情感分析模型
gpt5_sentiment_analyzer = load_model('gpt5_sentiment_analyzer_model.pth') # 输入待分析的文本
text_to_analyze = "这部电影太棒了!" # 使用GPT-5情感分析模型进行分析
sentiment = gpt5_sentiment_analyzer.analyze_sentiment(text_to_analyze) # 打印情感分析结果
print(sentiment) # 输出可能是 "positive" 或其他情感标签 # 加载问答模型
gpt5_qa_model = load_model('gpt5_qa_model.pth') # 输入问题和上下文
question = "这部电影的导演是谁?"
context = "这部电影是由张艺谋执导的..." # 使用GPT-5问答模型回答问题
answer = gpt5_qa_model.answer_question(question, context) # 打印回答结果
print(answer)
集成机器学习功能:
- GPT-5集成了机器学习功能,使得AI能够从用户的反馈和数据中不断学习和改进,提供更好的服务。
- 用户可以给GPT-5提供正面或负面的评价,或者指定一些优化目标或约束条件,让GPT-5根据这些信息来调整自己的行为和输出。
文本生成
GPT-5通过机器学习技术,特别是深度学习中的自然语言处理(NLP)技术,能够生成高质量的文本内容。它可以根据输入的文本或主题,自动编写文章、新闻、小说等,具有与人类相似的写作风格和语言表达能力。
示例代码:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch # 加载模型和分词器
model_name = "gpt2-medium" # 假设我们使用GPT-2的medium版本作为示例
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name) # 输入文本
input_text = "今天天气真好,"
input_ids = tokenizer.encode(input_text, return_tensors='pt') # 生成文本
generated = model.generate(input_ids, max_length=50, pad_token_id=tokenizer.eos_token_id) # 将生成的ID转换为文本
output_text = tokenizer.decode(generated[0], skip_special_tokens=True)
print(output_text)
语言理解
GPT-5还能够理解并解释自然语言文本的含义。它可以通过学习大量的文本数据,掌握语言的语法、语义和上下文信息,从而实现对文本内容的深入理解。
示例代码:
# 假设我们有一个预训练的GPT模型和一个分类头
# (注意:GPT本身不直接用于分类,但我们可以添加额外的层) # ...(加载模型和分词器的代码与上面相同)... # 假设的文本分类函数(这里只是一个示意,GPT本身不提供分类功能)
def classify_text(text, model, tokenizer, classifier_head): input_ids = tokenizer.encode(text, return_tensors='pt') with torch.no_grad(): gpt_output = model(input_ids)[0] # 获取GPT模型的最后一层输出 # 假设classifier_head是一个预训练的分类头模型 class_logits = classifier_head(gpt_output[:, 0, :]) # 取第一个token的输出进行分类 predicted_class = torch.argmax(class_logits, dim=-1).item() return predicted_class # 示例文本
text_to_classify = "我喜欢看电影"
predicted_class = classify_text(text_to_classify, model, tokenizer, classifier_head)
print(f"预测的类别是:{predicted_class}")
任务适应
GPT-5具备自适应学习能力,能够根据不同的任务需求调整自身的参数和模型结构。这使得GPT-5能够应用于各种自然语言处理任务,如问答系统、情感分析、机器翻译等。
示例代码:
from transformers import Trainer, TrainingArguments
from your_custom_dataset import YourCustomDataset # 假设你有一个自定义的数据集类 # ...(加载模型和分词器的代码与上面相同)... # 定义训练参数
training_args = TrainingArguments( output_dir='./results', # 输出目录 num_train_epochs=3, # 训练轮次 per_device_train_batch_size=16, # 批量大小 warmup_steps=500, # 学习率预热步数 weight_decay=0.01, # 权重衰减 logging_dir='./logs', # TensorBoard日志目录 logging_steps=10,
) # 加载数据集
train_dataset = YourCustomDataset(tokenizer=tokenizer, mode='train')
eval_dataset = YourCustomDataset(tokenizer=tokenizer, mode='eval') # 初始化Trainer
trainer = Trainer( model=model, # 模型 args=training_args, # 训练参数 train_dataset=train_dataset, # 训练数据集 eval_dataset=eval_dataset, # 评估数据集 # ... 其他可选参数 ...
) # 开始训练
trainer.train()
机器学习对GPT-5性能的影响
机器学习对GPT-5性能的影响是多方面的,从提升模型的准确性、泛化能力,到优化计算效率等方面都起到了关键作用。以下是详细的分析:
-
提升准确性:
- GPT-5通过大量的文本数据训练,能够学习到更多的语言知识和模式,从而提升其生成文本和理解语言的准确性。
- 斯坦福大学的研究发现,虽然使用AI生成的数据训练模型会导致性能下降,即所谓的“模型自噬障碍”(MAD),但这是因为模型未能得到“新鲜的数据”,即人类标注的数据。这强调了真实数据在提升模型准确性中的重要性。
- GPT-5的训练数据预计将达到近百万亿参数的级别,远超GPT-4的10万亿参数,这将使GPT-5能够处理更复杂的任务,生成更精确和流畅的文本。
-
提高泛化能力:
- GPT-5经过充分的机器学习训练,能够处理各种复杂的自然语言场景,具备较强的泛化能力。它的多模态能力将支持视频、音频等其他媒体形式的输入和输出,进一步扩大了其应用场景。GPT-5的更新还包括长期记忆和增强上下文意识,这将使模型能够处理需要长期记忆和连贯性的任务,如写长篇小说或进行深入对话,进一步提高了其泛化能力。
-
优化计算效率:
- GPT-5采用了先进的分布式计算技术和轻量级模型,这些技术能够在保持高性能的同时,降低对计算资源的需求,提高计算效率。尽管GPT-5的算力集群更庞大,训练成本更高,但通过这些优化技术,可以在一定程度上缓解成本问题。
-
数据依赖与解决方案:
- GPT-5的性能高度依赖于训练数据的质量和数量。为了解决这个问题,需要采用高质量、多样化的训练数据,并对数据进行预处理和过滤。
- 牛津、剑桥等机构的研究人员发现,如果在训练时大量使用AI内容,会引发模型崩溃。因此,为模型的训练准备由人类生产的真实数据变得尤为重要。
-
挑战与未来方向:
- 数据安全和隐私问题是GPT-5面临的重要挑战之一。由于GPT-5需要大量的数据进行训练和优化,因此确保数据的安全性和隐私性至关重要。
- 偏见和误导问题也是GPT-5需要解决的问题。GPT-5生成的内容受训练数据的影响,如果这些数据中存在偏见或误导,那么生成的内容也可能存在类似问题。
- 未来的研究将探索如何更好地利用机器学习技术来提升GPT-5的性能,并解决上述挑战。例如,通过改进数据预处理和过滤技术来提高数据质量,或者通过引入新的算法和技术来减少偏见和误导问题。
存在的挑战及解决方案
数据依赖:GPT-5的性能高度依赖于训练数据的质量和数量。如果训练数据存在偏见或误导信息,将会影响GPT-5生成文本的质量。为了解决这个问题,需要采用高质量、多样化的训练数据,并对数据进行预处理和过滤。
计算资源:GPT-5的训练和推理过程需要大量的计算资源。为了解决这个问题,可以采用分布式计算、并行计算等技术手段,提高模型的训练和推理速度。
版权问题:GPT-5生成的文本可能存在版权问题。为了避免这种情况的发生,需要在使用GPT-5时遵守相关的法律法规和伦理标准,确保生成的内容不侵犯他人的知识产权。
技术细节与示例
GPT-5采用了Transformer架构作为其基础模型,该架构由多个自注意力机制和全连接层组成。通过堆叠多个Transformer层,GPT-5能够学习到更深层次的语言特征。以下是一个简化的GPT-5模型架构示意图(注意,由于GPT-5的复杂性,这里仅展示一个概念性的示例):
Input -> [ Embedding Layer ] -> [ Transformer Layer 1 ] -> ... -> [ Transformer Layer N ] -> [ Output Layer ]
其中,Embedding Layer用于将输入文本转换为模型可以处理的向量表示;Transformer Layer是模型的核心部分,负责学习文本中的语言特征;Output Layer则根据任务需求输出相应的结果。
由于GPT-5的复杂性和专业性,直接提供代码示例可能不太合适。但读者可以通过查阅相关的深度学习框架(如TensorFlow、PyTorch等)和NLP库(如Hugging Face的Transformers库)来了解如何构建和训练类似的模型。这些框架和库提供了丰富的API和工具,可以帮助读者更好地理解机器学习在GPT-5中的应用和实现过程。
–
相关文章:
深度解析:机器学习如何助力GPT-5实现语言理解的飞跃
文章目录 文章前言机器学习在GPT-5中的具体应用模型训练与优化机器翻译与跨语言交流:情感分析与问答系统:集成机器学习功能:文本生成语言理解任务适应 机器学习对GPT-5性能的影响存在的挑战及解决方案技术细节与示例 文章前言 GPT-5是OpenAI公…...
Springcloud-消息总线-Bus
1.消息总线在微服务中的应用 BUS- 消息总线-将消息变更发送给所有的服务节点。 在微服务架构的系统中,通常我们会使用消息代理来构建一个Topic,让所有 服务节点监听这个主题,当生产者向topic中发送变更时,这个主题产生的消息会被…...

js 接收回调函数 转换为promise
下面是一个示例代码,展示如何编写一个接收回调函数并将其转换为 Promise 的 JavaScript 函数: // 定义一个接收回调函数并转换为 Promise 的函数 function convertCallbackToPromise(callbackFunction) {// 返回一个新的 Promise 对象return new Promis…...

Python 面试【★★★】
欢迎莅临我的博客 💝💝💝,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...
计算机网络(物理层)
物理层 物理层最核心的工作内容就是解决比特流在线路上传输的问题 基本概念 何为物理层?笼统的讲,就是传输比特流的。 可以着重看一下物理层主要任务的特性 传输媒体 传输媒体举例: 引导型传输媒体 引导型传输媒体指的是信号通过某种…...

OpenGL-ES 学习(6)---- 立方体绘制
目录 立方体绘制基本原理立方体的顶点坐标和绘制顺序立方体颜色和着色器实现效果和参考代码 立方体绘制基本原理 一个立方体是由8个顶点组成,共6个面,所以绘制立方体本质上就是绘制这6个面共12个三角形 顶点的坐标体系如下图所示,三维坐标…...

《数据结构与算法基础 by王卓老师》学习笔记——类C语言有关操作补充
1.元素类型说明 2.数组定义 3.C语言的内存动态分配 4..C中的参数传递 5.传值方式 6.传地址方式 例子...

高频面试题基本总结回顾2(含笔试高频算法整理)
干货分享,感谢您的阅读! (暂存篇---后续会删除,完整版和持续更新见高频面试题基本总结回顾(含笔试高频算法整理)) 备注:引用请标注出处,同时存在的问题请在相关博客留言…...
》)
《深入浅出MySQL:数据库开发、优化与管理维护(第3版)》
深入浅出MySQL sql执行流程第一步:通过连接器进行连接第二步:解析器解析 SQL第三步:执行SQL 行记录存储格式行溢出日志数据库三大范式第一范式第二范式第三范式 索引索引分类B树索引BTree vs Hash需要索引1、字段需要频繁的查询操作2、字段用…...
VBA技术资料MF171:创建指定工作表数的工作簿
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。“VBA语言専攻”提供的教程一共九套,分为初级、中级、高级三大部分,教程是对VBA的系统讲解&#…...
【效率提升】新一代效率工具平台utools
下载地址:utools uTools这款软件,是一款功能强大且高度可定制的效率神器,使用快捷键alt space(空格) 随时调用,支持调用系统应用、用户安装应用和市场插件等。 utools可以调用系统设置和内置应用,这样可以方便快捷的…...

Jmeter插件管理器,websocket协议,Jmeter连接数据库,测试报告的查看
目录 1、Jmeter插件管理器 1、Jmeter插件管理器用处:Jmeter发展并产生大量优秀的插件,比如取样器、性能监控的插件工具等。但要安装这些优秀的插件,需要先安装插件管理器。 2、插件的下载,从Availabale Plugins中选择ÿ…...
)
Android中ViewModel+LiveData+DataBinding的配合使用(kotlin)
Android 中 ViewModel、LiveData 和 Data Binding 的配合使用(Kotlin) 摘要 本文将介绍如何在 Android 开发中结合使用 ViewModel、LiveData 和 Data Binding 进行数据绑定和状态更新。我们将详细探讨这三者之间的关系,并展示如何在 Kotlin…...

Elasticsearch 避免常见查询错误和陷阱
Elasticsearch 作为一款强大的搜索引擎和分析工具,已经被广泛应用于各种场景中。然而,在使用 Elasticsearch 进行查询时,如果不注意一些常见的错误和陷阱,可能会导致查询效率低下、结果不准确甚至系统性能下降。本文旨在总结一些常…...
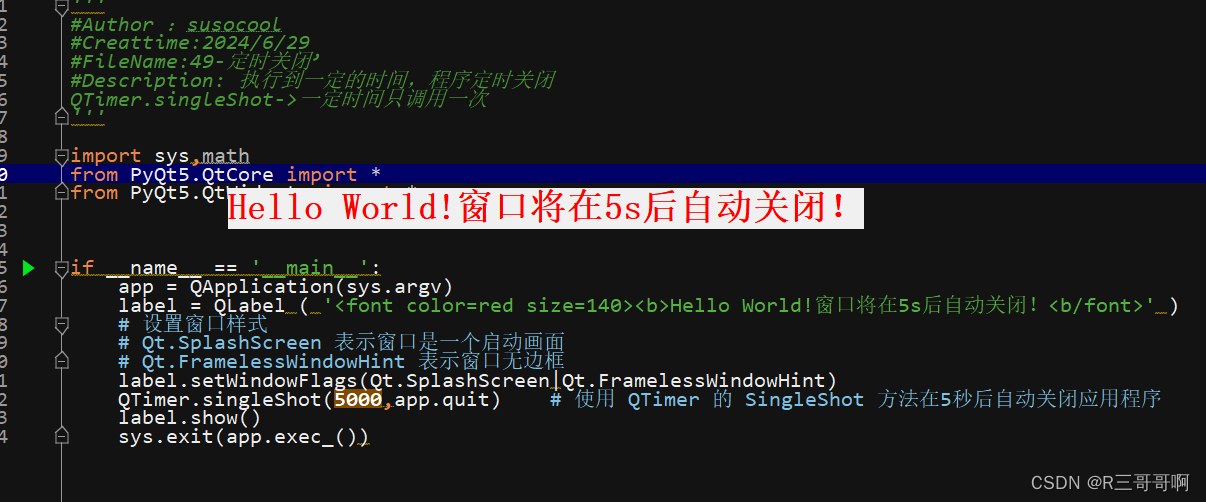
【PyQt】20-QTimer(动态显示时间、定时关闭)
QTimer 前言一、QTimer介绍二、动态时间展示2.1 代码2.2 运行结果 三、定时关闭3.1 介绍他的两种用法1、使用函数或Lambda表达式2、带有定时器类型(高级) 3.2 代码3.3 运行结果 总结 前言 好久没学习了。 一、QTimer介绍 pyqt里面的多线程可以有两种实…...
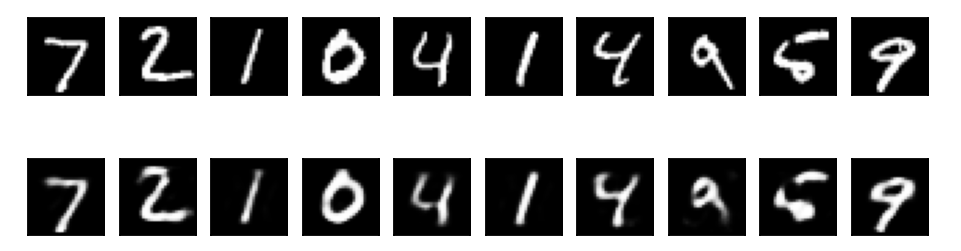
[深度学习] 自编码器Autoencoder
自编码器(Autoencoder)是一种无监督学习算法,主要用于数据的降维、特征提取和数据重建。自编码器由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。其基本思想是将输入数据映射…...

模型微调、智能体、知识库之间的区别
使用开源模型微调和使用知识库与智能体(agent)的区别主要体现在工作原理、应用场景和实现目标上。以下是对这三者的详细对比: 开源模型微调 定义: 微调是对预训练模型(例如BERT、GPT等)进行额外训练&…...
七日世界Once Human跳ping、延迟高、丢包怎么办?
七日世界是一款开放世界为轴点的生存射击游戏,玩家将进入一个荒诞、荒芜的末日世界,在这里与好友一起对抗可怖的怪物和神秘物质星尘的入侵,给这个星球留下最后的希望,共筑一片安全的领地。不过有部分玩家在游玩七日世界的时候&…...
机器人控制系列教程之关节空间运动控制器搭建(1)
机器人位置控制类型 机器人位置控制分为两种类型: 关节空间运动控制—在这种情况下,机器人的位置输入被指定为一组关节角度或位置的向量,这被称为机器人的关节配置,记作q。控制器跟踪一个参考配置,记作 q r e f q_{re…...

[linux]sed命令基础入门详解
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...

编程统计公司内部资料查阅使用数据,优化资料分类存储方式。提升职场员工工作查阅办事效率。
构建一个公司内部资料查阅使用统计与资料分类存储优化的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在中大型企业中,内部资料(制度、流程文档、技术手册、项目档案)数量庞大&a…...

Vircadia Native Core:开源虚拟世界服务器核心架构与部署实战
1. 项目概述:一个开源虚拟世界的“引擎心脏”如果你对构建一个属于自己的、去中心化的虚拟世界(Metaverse)感兴趣,或者你正在寻找一个能支撑起大规模、高自由度社交与协作应用的底层平台,那么Vircadia Native Core绝对…...

告别手动框选!用SUSTechPOINTS的V键批量标注,5分钟搞定一帧点云
解锁SUSTechPOINTS的V键批量标注:点云处理效率革命 在自动驾驶与机器人研发领域,点云标注是构建高精度感知模型的基础环节,但传统逐帧手动标注方式往往成为项目进度的瓶颈。我曾参与过一个城市级点云数据集标注项目,团队最初采用常…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...

自主智能体框架构建指南:从LLM工具调用到多任务规划系统
1. 项目概述:一个能“开疆拓土”的智能体框架最近在开源社区里,一个名为njbrake/agent-of-empires的项目引起了我的注意。光看这个名字,就充满了野心和想象力——“帝国的代理人”。这可不是一个简单的脚本工具,而是一个旨在构建能…...
从零构建大语言模型:Transformer架构、训练技巧与实战指南
1. 项目概述:从零构建你自己的大语言模型最近几年,大语言模型(LLM)的热度居高不下,从ChatGPT到Claude,再到国内外的各种开源模型,它们展现出的理解和生成能力让人惊叹。但你是否也和我一样&…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...
CircuitPython与NeoPixel实战:从硬件连接到动态灯光效果
1. 项目概述:用Python点亮你的硬件创意如果你玩过Arduino,可能会觉得C/C的语法和库管理有点门槛;如果你熟悉Python,又觉得它和硬件之间隔着一层纱。那么,当Raspberry Pi Pico这块性价比极高的微控制器,遇上…...