Transformer常见面试题
目录
1.Transformer为何使用多头注意力机制?(为什么不使用一个头)
2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
5.在计算attention score的时候如何对padding做mask操作?编辑
6.为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
7.大概讲一下Transformer的Encoder模块?
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
9.简单介绍一下Transformer的位置编码?有什么意义和优缺点?
10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
11. 简单讲一下Transformer中的残差结构以及意义。
12. 为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
13.简答讲一下BatchNorm技术,以及它的优缺点。
14.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
15.Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)编辑
16.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
17.Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
18.简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
19. Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
20.引申一个关于bert问题,bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
21. 请简要介绍 Transformer 模型以及它与传统的神经网络架构(如 RNN 和 LSTM)之间的主要区别。
22. Transformer 模型中的自注意力机制是如何工作的?可以解释一下“缩放点积注意力”吗?
23. 在 Transformer 中,位置编码的作用是什么?为什么要引入位置编码?
24. 请解释 Transformer 的多头注意力是如何实现并同时处理不同的信息子空间的。
25. 在 Transformer 模型中,层归一化(Layer Normalization)和残差连接(Residual Connection)的目的是什么?
26. 为什么 Transformer 模型在处理序列数据方面比传统的 RNN 和 LSTM模型有效率得多?
27. 可以描述一下在 Transformer 模型训练中常用的优化方法和训练技巧吗?
28. 可以给出一些基于 Transformer 模型改进和变体的例子,以及它们的优点是什么吗?(如:BERT、GPT系列)
29.请讨论一下 Transformer 模型用于序列生成任务(如机器翻译、文本生成)时的输出序列是如何生成的。
30.在深度学习中,过拟合是一个常见问题。在实际工作中,你是如何防止 Transformer 模型过拟合的?
31.使用 Transformer 模型时可能会遇到的内存和计算问题有哪些?又是如何解决这些问题的?
32.Transformer 模型对于输入序列的长度有什么限制?如果要处理很长的序列,你会采取什么措施?
33.在某些情况下,Transformer 模型可能并不是最佳选择。可以讨论一下在什么类型的任务或场景中可能会偏好其他模型而不是 Transformer 吗?
34.Transformer 模型的解释性通常被认为是一个挑战,你是否有什么见解或方法来理解模型的决策过程?
35.最后,设想你需要在不同的硬件配置上部署 Transformer 模型。你会考虑哪些因素以及可能采用的优化策略
1.Transformer为何使用多头注意力机制?(为什么不使用一个头)
2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别)
3.Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
问题1参考:
首先,多头注意力允许模型同时关注不同位置和特征,这样可以捕捉更丰富的信息。比如说,一个头可以关注句子的语法结构,另一个头可以关注实体间的关系,这样就能综合考虑各种信息。其次,多头注意力可以增强模型的表达能力,让模型更好地理解复杂的数据关系。每个头可以学习不同的特征表示,这样模型就能更全面地分析输入数据。另外,多头注意力还有助于提高模型的稳定性。单一注意力可能会过度关注某些模式,导致不稳定性,而多头注意力可以降低每个头的负担,让模型更加健壮。最后,多头注意力还能提高计算效率,因为可以并行计算多个注意力分布,充分利用硬件资源。
总的来说,Transformer使用多头注意力机制的好处有很多,包括捕捉丰富信息、增强表达能力、提高稳定性和计算效率。这也是为什么多头注意力成为Transformer成功的关键组件。
问题2参考:
首先,使用不同的权重矩阵可以让模型学习到更多不同的信息。Query和Key分别表示了不同的语义信息,通过分别学习它们的权重矩阵,模型可以更好地区分不同类型的信息,提高了模型的表达能力。
其次,如果直接使用相同的数值进行自身的点乘,会导致模型难以区分Query和Key之间的关系。通过引入不同的权重矩阵,可以让模型更好地学习到Query和Key之间的语义关系,从而提高了模型的效果和准确性。
总的来说,使用不同的权重矩阵生成Query和Key在Transformer中是很重要的设计,可以让模型更好地学习到不同的信息并区分语义关系,从而提高了模型的性能和表现。
问题3参考:

4.为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解


总结来说,缩放的目的是为了保持Softmax函数梯度的稳定性,避免在高维空间中梯度消失或爆炸的问题,从而提高模型的训练效率和泛化能力。
5.在计算attention score的时候如何对padding做mask操作?

6.为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)


7.大概讲一下Transformer的Encoder模块?
Transformer模型的核心之一是其编码器(Encoder)模块,它负责将输入序列转换为连续的向量表示。以下是Transformer编码器模块的主要组成部分和工作流程:
·输入表示:编码器接收一个输入序列,通常是词汇表中的词嵌入(word embeddings)加上位置编码(positional encodings),以提供序列中单词的位置信息。
· 多头自注意力机制(Multi-Head Self-Attention):
编码器首先应用多头自注意力机制,允许模型在编码每个单词时同时考虑序列中的其他所有单词。
每个自注意力头独立地计算注意力分数,然后将所有头的输出合并起来,以获得全面的上下文信息。
缩放:自注意力机制中的点积被缩放(通常是除以键向量维度的平方根),以防止梯度消失或爆炸。
·掩码操作:如果输入序列包含填充(padding),编码器会使用掩码来防止模型在计算注意力分数时考虑填充部分。
前馈网络(Feed-Forward Neural Network):
在自注意力层之后,编码器包含一个前馈神经网络,通常是一个线性层后跟一个非线性激活函数(如ReLU)。
这个网络对自注意力层的输出进行进一步的非线性变换。
残差连接(Residual Connection):
在多头自注意力和前馈网络之后,编码器使用残差连接将原始输入添加到当前层的输出上。
这有助于避免深层网络中的梯度消失问题,并允许模型学习到恒等映射。
层归一化(Layer Normalization):
在残差连接之后,编码器使用层归一化来稳定训练过程。
归一化是在残差连接之前还是之后应用取决于具体的实现。
堆叠层:编码器通常由多个相同的层堆叠而成,每层都包含上述组件。每一层都会对输入序列进行进一步的编码,逐渐提取更深层次的语义信息。
输出:编码器的输出是一个连续的向量表示,捕捉了输入序列的丰富语义信息,这些信息可以被用于下游任务,如机器翻译、文本摘要等。
Transformer编码器的设计允许模型捕捉长距离依赖关系,并且由于其并行化的特性,它在处理长序列时非常高效。此外,编码器的模块化设计使得它可以轻松地扩展到更深的网络结构,以提高模型的容量和性能。
8.为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?


9.简单介绍一下Transformer的位置编码?有什么意义和优缺点?


10.你还了解哪些关于位置编码的技术,各自的优缺点是什么?
以下是一些常见的位置编码技术及其优缺点:


11. 简单讲一下Transformer中的残差结构以及意义。


12. 为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?


13.简答讲一下BatchNorm技术,以及它的优缺点。



14.简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?


15.Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)


16.Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)


17.Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?


18.简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?


19. Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?



20.引申一个关于bert问题,bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?


21. 请简要介绍 Transformer 模型以及它与传统的神经网络架构(如 RNN 和 LSTM)之间的主要区别。
Transformer模型是一种基于自注意力机制的神经网络架构,它在自然语言处理(NLP)领域取得了显著的成果。以下是Transformer模型的简要介绍以及与传统神经网络架构(如RNN和LSTM)的主要区别:
Transformer模型简介:
-
自注意力机制:Transformer模型的核心是自注意力机制,它允许模型在处理序列时同时考虑序列中的所有位置,而不是像传统序列模型那样按顺序处理。
-
并行化处理:由于自注意力机制不依赖于序列中元素的前后顺序,Transformer可以高效地并行化计算,这与传统的RNN和LSTM不同,后者需要按顺序逐步处理序列。
-
编码器-解码器结构:Transformer模型通常由编码器(Encoder)和解码器(Decoder)组成,编码器处理输入序列,解码器生成输出序列。
-
多头注意力:Transformer模型使用多头自注意力机制,允许模型同时从不同的表示子空间捕捉信息。
-
位置编码:Transformer模型通过位置编码向自注意力机制提供序列中每个元素的位置信息,以保持序列的顺序性。
-
前馈网络:在自注意力层之后,Transformer模型使用前馈网络进一步处理信息。
-
残差连接和层归一化:每个子层的输出通过残差连接和层归一化处理,以帮助梯度流动并稳定训练。
与传统神经网络架构的区别:
-
处理顺序:RNN和LSTM按顺序处理序列,而Transformer并行处理整个序列。
-
梯度流动:由于循环结构,RNN和LSTM可能面临梯度消失或爆炸的问题,而Transformer通过残差连接和层归一化缓解了这些问题。
-
长距离依赖:LSTM设计有门控机制来捕捉长距离依赖,而Transformer通过自注意力机制直接捕捉序列中的长距离关系。
-
计算效率:Transformer由于其并行化能力,在处理长序列时通常比RNN和LSTM更高效。
-
模型复杂性:Transformer模型通常比RNN和LSTM更复杂,需要更多的参数和计算资源。
-
适用性:虽然Transformer在很多NLP任务中表现出色,但RNN和LSTM在某些特定任务(如语音识别)中可能仍然有优势。
-
灵活性:Transformer模型由于其自注意力机制,在处理不同长度的序列时更加灵活。
Transformer模型的这些特性使其成为许多NLP任务的首选架构,尤其是在需要处理长序列和大量并行计算资源可用的情况下。在面试中,可以强调Transformer模型的这些优势,以及它如何改变了自然语言处理领域的模型设计和任务解决方案。同时,也可以讨论在不同应用场景下选择合适模型架构的重要性。
22. Transformer 模型中的自注意力机制是如何工作的?可以解释一下“缩放点积注意力”吗?


23. 在 Transformer 中,位置编码的作用是什么?为什么要引入位置编码?
在Transformer模型中,位置编码(Positional Encoding)的作用是向模型提供序列中每个元素(如单词或字符)的位置信息。这是必要的,因为Transformer的自注意力机制本身并不包含处理序列顺序的能力,即它不具备像循环神经网络(RNN)或长短期记忆网络(LSTM)那样的固有序列处理能力。以下是引入位置编码的原因和作用:
-
序列顺序性:自然语言中的单词顺序对于理解句子的意义至关重要。位置编码使得Transformer能够捕捉和理解序列中的顺序信息。
-
模型输入:位置编码通常与词嵌入(Word Embedding)相加,形成模型的最终输入表示,这样每个元素的表示就包含了位置信息。
-
捕捉长距离依赖:位置编码有助于模型捕捉序列中元素之间的长距离依赖关系,这对于语言模型尤其重要。
-
灵活性:位置编码允许Transformer模型处理可变长度的序列,因为编码是针对每个位置独立定义的。
-
实现方式:在原始的Transformer模型中,位置编码是通过正弦和余弦函数的组合来实现的,每个位置的编码都是唯一的,并且编码的模式随着位置的增加而周期性变化。
-
并行处理:引入位置编码后,Transformer模型可以并行处理序列中的所有元素,这是其相比RNN和LSTM的一个重要优势。
-
改善模型性能:位置编码有助于改善模型在特定任务上的性能,尤其是在需要模型理解单词顺序的任务中。
-
泛化能力:位置编码增强了模型对序列数据的泛化能力,使其能够更好地处理在训练数据中未出现过的序列模式。
在面试中,可以强调位置编码在Transformer模型中的重要性,以及它是如何使模型能够有效处理序列数据的。同时,也可以讨论位置编码的不同实现方式,例如学习型位置编码或相对位置编码,以及它们如何影响模型的性能和应用。
24. 请解释 Transformer 的多头注意力是如何实现并同时处理不同的信息子空间的。
Transformer 模型中的多头注意力(Multi-Head Attention)是一种强大的机制,它允许模型同时从多个不同的信息子空间捕捉信息。以下是多头注意力的实现方式和它如何处理不同信息子空间的解释:
多头注意力的实现:
-
分割表示:首先,模型将输入序列分割成多个“头”,每个头处理序列的一部分信息。这是通过将输入序列的特征维度分割成多个子空间来实现的。
-
线性变换:对于每个头,模型使用不同的线性变换(即不同的权重矩阵)来生成查询(Q)、键(K)和值(V)。这意味着每个头都会得到自己的Q、K和V表示。
-
并行自注意力:每个头独立地计算自注意力,即每个头使用自己的Q、K和V来计算注意力输出。由于每个头的权重矩阵不同,它们可以学习到不同的表示。
-
缩放点积:在每个头中,使用缩放点积注意力机制来计算注意力权重和加权的值向量。
-
拼接和合并:所有头的输出(即加权的值向量)被拼接在一起,形成一个较长的向量。然后,使用另一个线性变换来合并这些信息,得到最终的多头注意力输出。
-
残差连接和层归一化:多头注意力的输出通常会通过残差连接和层归一化处理,以帮助梯度流动并稳定训练。
多头注意力处理不同信息子空间:
-
多样性:每个头可以学习到序列的不同方面,例如,一个头可能专注于捕捉句法信息,而另一个头可能专注于捕捉语义信息。
-
并行处理:多头注意力允许模型并行地从多个子空间中提取特征,这提高了模型的计算效率。
-
灵活性:通过使用不同的线性变换,每个头可以适应不同的表示需求,增加了模型的灵活性。
-
信息整合:通过拼接和合并步骤,模型将从不同子空间中提取的信息整合到一起,形成一个综合的表示。
-
捕获复杂模式:多头注意力使模型能够捕获更复杂的模式和关系,因为每个头可以专注于不同类型的依赖和特征。
-
提高性能:多头注意力已被证明可以提高Transformer模型在各种NLP任务上的性能,包括机器翻译、文本摘要和问答系统。
在面试中,可以讨论多头注意力如何增强Transformer模型的表示能力,以及它如何使模型能够同时从多个角度理解输入数据。同时,也可以探讨多头注意力在实际应用中的效果和潜在的改进方向。
25. 在 Transformer 模型中,层归一化(Layer Normalization)和残差连接(Residual Connection)的目的是什么?
在Transformer模型中,层归一化(Layer Normalization,LN)和残差连接(Residual Connection)是两个关键组件,它们共同帮助模型更有效地训练和泛化。以下是它们各自的目的和作用:
层归一化(Layer Normalization):
-
稳定性:层归一化通过对每个样本的激活输出进行归一化,减少训练过程中的内部协变量偏移,从而提高模型的稳定性。
-
加速收敛:归一化有助于加快模型的收敛速度,因为它减少了不同层激活输出的方差。
-
减少依赖:与传统的批归一化(Batch Normalization)不同,层归一化不依赖于批次的大小,这使得模型在处理不同长度的序列时更加灵活。
-
改善梯度流:层归一化有助于改善深层网络中的梯度流动,减少梯度消失或爆炸的问题。
-
正则化效果:层归一化具有一定的正则化效果,可以减少模型对输入数据的敏感性,从而提高泛化能力。
残差连接(Residual Connection):
-
梯度流动:残差连接通过在每个子层的输入和输出之间添加直接连接,帮助梯度在深层网络中更有效地流动。
-
缓解退化问题:在深层网络中,如果没有残差连接,可能会遇到梯度消失导致的退化问题,即较深层的特征逐渐失去表达能力。残差连接缓解了这一问题。
-
网络深度:残差连接使得模型可以设计得更深,而不必担心深层网络带来的训练困难。
-
提高表达能力:残差连接允许模型学习到恒等映射,即直接传递输入到输出的映射,这增加了模型的表达能力。
-
简化训练:残差连接简化了模型的训练过程,因为它允许每个子层专注于学习输入和输出之间的残差,而不是整个映射。
-
与层归一化配合:残差连接通常与层归一化一起使用,以进一步稳定训练过程。
26. 为什么 Transformer 模型在处理序列数据方面比传统的 RNN 和 LSTM模型有效率得多?
Transformer模型在处理序列数据方面之所以比传统的RNN(循环神经网络)和LSTM(长短期记忆网络)有效率得多,主要归功于以下几个方面:
-
并行化能力:
- RNN和LSTM由于其递归性质,必须按顺序逐步处理序列中的每个元素,这限制了它们并行化的能力。
- Transformer模型使用的自注意力机制允许模型同时处理序列中的所有元素,从而可以充分利用并行计算资源。
-
避免梯度消失/爆炸问题:
- RNN和LSTM可能会遇到梯度消失或爆炸的问题,特别是当处理长序列时,这会导致训练困难。
- Transformer通过残差连接和层归一化技术缓解了这一问题,使得模型能够稳定地训练深层网络。
-
处理长距离依赖:
- RNN和LSTM虽然理论上能够捕捉长距离依赖,但在实践中,它们可能难以学习超过一定距离的依赖关系。
- Transformer的自注意力机制可以直接计算序列中任意两个元素之间的关系,有效地捕捉长距离依赖。
-
计算效率:
- RNN和LSTM在处理长序列时需要线性增长的时间复杂度,因为它们需要逐步处理序列。
- Transformer的自注意力虽然在理论上具有二次方的时间复杂度,但通过优化(如使用稀疏注意力模式)和现代硬件加速,实际上可以非常高效地处理长序列。
-
灵活性和通用性:
- Transformer模型的架构更加灵活,易于适配不同的任务和模型大小,而RNN和LSTM可能需要针对特定任务进行调整。
- Transformer模型已经成为许多NLP任务的基础架构,显示出其通用性。
-
更好的泛化能力:
- 由于Transformer模型能够更好地捕捉序列的全局特征,它通常能够在多种任务上实现更好的泛化能力。
-
模型容量:
- Transformer模型通常具有更大的模型容量,可以存储和处理更多的信息,这有助于提高模型的性能。
-
先进的优化技术:
- 随着研究的发展,针对Transformer模型的优化技术(如AdamW优化器、学习率预热和衰减策略)不断进步,进一步提高了模型的训练效率。
在面试中,可以强调Transformer模型的这些优势,并讨论它们如何使Transformer在处理序列数据方面比RNN和LSTM更加高效。同时,也可以探讨在特定应用场景下选择合适模型架构的重要性。
27. 可以描述一下在 Transformer 模型训练中常用的优化方法和训练技巧吗?
Transformer模型的训练是一个复杂的过程,涉及到多个优化方法和训练技巧,以确保模型能够有效地学习并泛化到新的数据上。以下是一些常用的优化方法和训练技巧:
-
Adam优化器:
- Adam(自适应矩估计)优化器是一种流行的选择,它结合了动量(Momentum)和RMSprop的优点,能够适应不同参数的更新速率。
-
学习率预热:
- 在训练初期,逐渐增加学习率,从较小的值预热到设定的目标学习率,有助于稳定训练初期的损失下降。
-
学习率衰减:
- 随着训练的进行,逐渐减小学习率,例如使用余弦退火或阶梯衰减策略,以保证收敛的稳定性。
-
权重衰减(L2正则化):
- 在优化过程中添加权重衰减,有助于减少模型的过拟合。
-
残差连接:
- 残差连接帮助梯度在深层网络中流动,缓解梯度消失问题,允许训练更深的网络。
-
层归一化:
- 层归一化通过对每个子层的输出进行归一化,提高了模型的稳定性,并有助于梯度的流动。
-
dropout:
- 在适当的位置添加dropout层,可以作为正则化手段,减少模型对训练数据的过拟合。
-
标签平滑:
- 在分类任务中,使用标签平滑技术可以防止模型过于自信,提高模型的泛化能力。
-
梯度裁剪:
- 在训练过程中,对梯度的大小进行裁剪,以防止梯度爆炸问题。
-
使用适当的批量大小:
- 批量大小对模型的训练效率和性能有显著影响,需要根据具体任务和硬件资源来调整。
-
数据增强:
- 对于某些任务,如机器翻译或文本摘要,可以使用数据增强技术,例如同义词替换或句子重组,来增加数据多样性。
-
早停法(Early Stopping):
- 在验证集上的性能不再提升时停止训练,以避免过拟合。
-
模型蒸馏:
- 通过知识蒸馏技术,将大型复杂模型的知识迁移到小型模型中,以提高小型模型的性能。
-
使用预训练模型:
- 在特定任务上微调预训练的Transformer模型,可以利用预训练模型已经学习到的知识。
-
多任务学习:
- 通过同时训练模型在多个任务上,可以提高模型的泛化能力和效率。
-
混合精度训练:
- 使用混合精度(如FP16)进行训练,可以在保持模型性能的同时减少内存使用和加速训练。
这些优化方法和训练技巧可以根据具体任务和数据集的需求进行调整和组合。在面试中,可以讨论这些技巧如何帮助提高Transformer模型的训练效率和性能,以及在实际应用中如何选择和调整这些技巧。
28. 可以给出一些基于 Transformer 模型改进和变体的例子,以及它们的优点是什么吗?(如:BERT、GPT系列)



29.请讨论一下 Transformer 模型用于序列生成任务(如机器翻译、文本生成)时的输出序列是如何生成的。
Transformer模型在序列生成任务,如机器翻译或文本生成中,通常采用解码器(Decoder)部分来生成输出序列。以下是生成输出序列的一般步骤:
-
初始化:
- 序列生成通常从一个特殊的起始标记(如"")开始。
-
输入嵌入:
- 起始标记首先被转换为对应的嵌入向量,然后与位置编码相结合,形成初始的输入表示。
-
解码器自注意力:
- 在每个解码步骤中,解码器首先使用自注意力机制处理当前步骤的输入,同时应用掩码以保持自回归特性。
-
编码器-解码器注意力:
- 接着,解码器使用编码器的输出作为键和值,通过注意力机制获取编码器的上下文信息。
-
前馈网络:
- 将自注意力和编码器-解码器注意力的输出合并后,解码器使用前馈网络进一步处理信息。
-
输出层:
- 最后,解码器的输出通过一个线性层,并应用Softmax激活函数,生成下一个词的概率分布。
-
选择下一个词:
- 根据概率分布,选择概率最高的词作为下一个词的预测。
-
序列生成:
- 将预测的词添加到已生成的序列中,并将其转换为嵌入向量,与新的位置编码相结合,作为下一个解码步骤的输入。
-
迭代过程:
- 重复步骤3到8,直到生成特定的结束标记(如"")或达到最大序列长度。
-
掩码和自回归特性:
- 在整个过程中,解码器的自注意力使用掩码来确保自回归特性,即在生成当前词时只能看到之前已经生成的词。
-
束搜索(Beam Search):
- 为了生成更高质量的序列,通常会使用束搜索策略,它扩展了多个候选序列,并选择概率最高的序列作为最终输出。
-
避免信息泄露:
- 在生成过程中,需要确保未来信息不会影响当前词的生成,这通常通过适当的掩码和自回归策略来实现。
Transformer模型的这种序列生成方式使其在机器翻译、文本摘要、对话生成等任务中表现出色。在面试中,可以讨论这些步骤如何协同工作,以及它们如何影响序列生成的质量和效率。同时,也可以探讨束搜索和其他高级解码策略如何帮助生成更准确的输出序列。
30.在深度学习中,过拟合是一个常见问题。在实际工作中,你是如何防止 Transformer 模型过拟合的?



在实际工作中,通常需要结合多种策略来防止过拟合。在面试中,可以讨论这些策略在具体项目中的应用,以及如何根据任务和数据的特性选择和调整这些策略。同时,也可以分享在实际工作中遇到的过拟合问题和解决方案。
31.使用 Transformer 模型时可能会遇到的内存和计算问题有哪些?又是如何解决这些问题的?
使用Transformer模型时可能会遇到的内存和计算问题主要包括:
-
内存消耗大:
- Transformer模型由于其自注意力机制,内存消耗与输入序列的长度成平方关系,导致处理长序列时内存占用很大。
-
计算复杂度:
- 自注意力层的计算复杂度为O(N^2),其中N是序列长度,这使得模型在长序列上的训练和推理变得计算密集。
-
GPU内存限制:
- 当模型和数据集较大时,可能会超出单个GPU的内存限制,导致无法训练或需要分割数据和模型。
-
训练时间长:
- 由于模型参数多和计算量大,Transformer模型的训练可能需要较长的时间。
-
数据传输瓶颈:
- 在分布式训练中,数据传输可能成为瓶颈,特别是当模型需要跨多个设备进行训练时。
为了解决这些问题,可以采取以下措施:
-
模型剪枝:
- 移除模型中不重要的权重或神经元,减少模型大小和计算需求。
-
量化:
- 将模型的权重和激活从32位浮点数降低到更低位数,以减少内存占用和加速计算。
-
使用稀疏注意力:
- 通过限制自注意力的范围或使用稀疏模式来减少计算量。
-
模型并行:
- 在多个GPU上分布模型的不同部分,以减少单个GPU的内存负担。
-
数据并行:
- 将数据分割在多个GPU上并行处理,以提高训练效率。
-
梯度累积:
- 在小批量上累积梯度并在多个迭代后更新,以减少内存占用。
-
使用更高效的注意力机制:
- 如相对位置编码或Transformer-XL中的循环机制,以减少内存和计算需求。
-
优化算法:
- 使用混合精度训练或更高效的优化算法来减少内存占用和加速训练。
-
知识蒸馏:
- 将大型复杂模型的知识迁移到小型模型中,以减少计算和内存需求。
-
使用外存:
- 当GPU内存不足时,可以使用外存(如硬盘或SSD)作为扩展内存。
-
模型压缩:
- 通过技术如权重共享、低秩分解等减少模型大小。
-
动态序列长度:
- 在训练时使用动态序列长度,避免对所有序列使用最大长度。
-
异步计算:
- 使用异步计算技术来隐藏数据传输和计算的延迟。
-
模型分片:
- 将模型的不同部分分布到不同的设备上,以减少单个设备的内存压力。
通过这些方法,可以在一定程度上缓解Transformer模型在内存和计算上的限制,使其能够更高效地应用于实际问题。在面试中,可以讨论这些解决方案在具体项目中的应用,以及如何根据实际情况选择和实施这些策略。
32.Transformer 模型对于输入序列的长度有什么限制?如果要处理很长的序列,你会采取什么措施?
Transformer模型对于输入序列的长度确实存在一些限制,主要由于以下几个方面:
-
内存限制:由于自注意力机制的内存消耗与序列长度的平方成正比,非常长的序列会导致内存需求急剧增加。
-
计算复杂度:自注意力层的时间复杂度也是O(N^2),其中N是序列长度,这意味着处理长序列需要更多的计算资源。
-
GPU容量:单个GPU的内存有限,当序列长度增加时,可能会超出GPU的内存容量。
-
梯度消失/爆炸:尽管Transformer通过层归一化和残差连接缓解了这个问题,但过长的序列仍可能导致梯度难以有效传播。
-
优化挑战:长序列可能导致优化过程变慢,因为模型需要更多时间来处理每个批次的数据。
要处理很长的序列,可以采取以下措施:
-
序列分割:将长序列分割成多个较小的块,分别处理后再进行整合。
-
稀疏注意力机制:使用如相对位置编码或可学习的位置编码,减少自注意力计算的复杂度。
-
层次化注意力:采用层次化的注意力结构,先在较小的局部窗口内计算注意力,再在更大范围合并信息。
-
Transformer-XL:使用Transformer-XL或其变体,它支持跨序列的信息流动,可以处理超出单个序列长度的长期依赖。
-
内存和计算优化:使用模型剪枝、量化、知识蒸馏等技术减少模型大小和计算需求。
-
分布式训练:在多个GPU或TPU上并行训练模型,分散内存和计算压力。
-
优化算法:使用更高效的优化算法,如AdamW,以及利用混合精度训练减少内存占用。
-
渐进式训练:从较短的序列开始训练,逐渐增加序列长度,让模型逐步适应长序列。
-
外存使用:当GPU内存不足时,可以考虑使用外存作为补充,但这会引入额外的数据传输时间。
-
模型并行:在多个设备上分布模型的不同部分,以减少单个设备的内存压力。
-
动态序列长度:在训练时使用动态序列长度,避免对所有序列使用最大长度。
-
有效的数据结构:使用有效的数据结构来存储和访问长序列数据,减少内存占用。
通过这些措施,可以在处理长序列时减少Transformer模型的限制。在面试中,可以讨论这些策略在具体项目中的应用,以及如何根据项目需求和资源限制选择和实施这些策略。
33.在某些情况下,Transformer 模型可能并不是最佳选择。可以讨论一下在什么类型的任务或场景中可能会偏好其他模型而不是 Transformer 吗?
尽管Transformer模型在许多序列处理任务中表现出色,但在某些任务或场景中,可能会有其他模型更加适合。以下是一些可能偏好使用其他模型而不是Transformer的情况:
-
长序列处理:
- 对于极长序列的任务,如某些类型的时间序列预测或信号处理,Transformer的O(N^2)复杂度可能变得不可行。在这种情况下,循环神经网络(RNN)或其变体(如LSTM或GRU)可能更合适。
-
生成任务的多样性:
- 在需要生成多样化序列的任务中,例如创意写作或音乐生成,基于RNN的模型可能更优,因为它们能够逐步构建序列,每一步都可能产生新的创意。
-
实时或低延迟应用:
- 对于需要实时响应的应用,如语音识别或实时翻译,Transformer的自注意力机制可能因为其高计算复杂度而导致延迟。在这种情况下,卷积神经网络(CNN)或RNN可能更加高效。
-
数据集较小的任务:
- 当可用数据量较小时,Transformer可能无法充分学习并泛化。相比之下,更简单的模型或具有更好泛化能力的模型可能更适合。
-
任务特定结构:
- 对于具有明显结构的任务,如树结构的句法分析,其他模型(如树形LSTM或图神经网络)可能更自然地适应这些结构。
-
计算资源受限:
- 在计算资源受限的环境中,如移动设备或嵌入式系统,Transformer的大模型尺寸和高内存需求可能不现实。轻量级的模型或更高效的架构可能更受偏好。
-
特定领域的任务:
- 在特定领域,如生物信息学或化学信息学,可能存在特定类型的数据和任务需求,这些需求可能更适合用领域特定的模型来处理。
-
需要长短期记忆的任务:
- 对于需要同时考虑长期和短期信息的任务,LSTM或GRU可能更擅长捕捉这些依赖关系。
-
任务的可解释性:
- 如果任务需要模型的决策过程具有高度的可解释性,一些更简单的模型或具有明确规则的模型可能更受青睐。
-
特定类型的注意力机制:
- 对于某些任务,可能需要特定类型的注意力机制,如硬注意力或基于规则的注意力,这些可能不容易用标准Transformer实现。
在实际工作中,选择模型应基于任务的具体需求、数据的特性、计算资源的可用性以及性能要求。在面试中,可以讨论这些因素如何影响模型选择,以及在面对不同任务时如何权衡各种模型的优缺点。同时,也可以探讨如何根据特定场景调整或改进Transformer模型,使其更适应这些任务。
34.Transformer 模型的解释性通常被认为是一个挑战,你是否有什么见解或方法来理解模型的决策过程?
Transformer模型的解释性确实是一个挑战,主要由于其高度复杂的内部表示和非线性变换。然而,研究人员已经开发了一些方法来提高模型的可解释性,并理解其决策过程:
-
注意力可视化:
- 通过可视化Transformer模型中的注意力权重,可以了解模型在做出预测时关注输入序列的哪些部分。
-
梯度分析:
- 使用梯度方法,如Integrated Gradients或Gradient-weighted Class Activation Mapping (Grad-CAM),来识别对模型输出贡献最大的输入特征。
-
特征消融研究:
- 通过逐个或成组地移除输入特征,并观察模型性能的变化,可以了解每个特征的重要性。
-
注意力头分析:
- 分析模型中不同注意力头的作用,了解它们分别关注输入数据的哪些方面。
-
局部解释:
- 使用局部解释方法,如LIME或SHAP,为特定预测提供解释。
-
规则提取:
- 从训练好的Transformer模型中提取规则或模式,尽管这对于深度学习模型来说可能具有挑战性。
-
模型简化:
- 使用更简单的模型作为代理,来近似Transformer的行为,并提供更直观的解释。
-
对比解释:
- 通过比较模型在不同输入下的行为,来理解模型的决策边界。
-
中间层表示分析:
- 检查Transformer模型中间层的激活,以了解模型在不同层次上如何表示和处理信息。
-
行为克隆:
- 通过训练一个辅助模型来模仿Transformer的行为,可能有助于揭示主模型的决策过程。
-
对抗样本分析:
- 通过分析对抗样本,即在输入中引入小的、有针对性的扰动,来观察模型预测的变化,这可以揭示模型的敏感性和潜在弱点。
-
模型卡片和文档:
- 创建模型卡片和详细的文档,记录模型的设计、训练过程和预期用途,以提供透明度。
-
交互式工具:
- 开发交互式工具和平台,允许用户探索模型的行为,并提供即时反馈。
-
模型验证和测试:
- 对模型进行广泛的验证和测试,以确保其决策过程的合理性和一致性。
提高Transformer模型的解释性是一个活跃的研究领域,涉及到机器学习、认知科学和人机交互等多个学科。在面试中,可以讨论这些方法的应用和效果,以及在实际工作中如何平衡模型性能和可解释性。同时,也可以探讨在特定应用中解释性的重要性,以及如何向非技术利益相关者传达模型的决策过程。
35.最后,设想你需要在不同的硬件配置上部署 Transformer 模型。你会考虑哪些因素以及可能采用的优化策略?
在不同的硬件配置上部署Transformer模型时,需要考虑多种因素,并可能采用一系列优化策略来确保模型的高效运行。以下是一些关键因素和相应的优化策略:
考虑的因素:
- 硬件类型:CPU、GPU、TPU或专用硬件如ASIC等。
- 内存限制:可用的RAM或VRAM大小,影响模型大小和批量大小。
- 计算能力:硬件的浮点运算性能。
- 能耗限制:移动设备或嵌入式系统可能对能耗有特定要求。
- 延迟要求:实时应用可能对延迟有严格要求。
- 吞吐量需求:需要处理的数据量和速度。
- 模型大小:Transformer模型的参数数量。
- 数据传输:数据在不同硬件组件间的传输速度和带宽。
可能采用的优化策略:
-
模型剪枝:
- 移除不重要的权重或神经元以减少模型大小。
-
量化:
- 降低模型权重和激活的精度,减少内存占用和加速推理。
-
知识蒸馏:
- 将大型模型的知识迁移到小型模型中。
-
模型并行:
- 在多个GPU或TPU上分布模型的不同部分。
-
数据并行:
- 将数据分割在多个设备上并行处理。
-
混合精度训练:
- 使用FP16或更低精度进行计算以减少内存占用和加速训练。
-
动态序列长度:
- 根据硬件限制调整输入序列的长度。
-
分块处理:
- 将长序列分割成小块分别处理。
-
优化算法:
- 使用高效的优化算法和学习率调度策略。
-
使用高效的库:
- 利用针对特定硬件优化的深度学习框架和库。
-
异构计算:
- 结合使用不同类型的硬件,如CPU和GPU。
-
模型蒸馏:
- 将多个模型的知识合并到一个更小的模型中。
-
硬件特定的优化:
- 针对特定硬件(如TPU)的优化。
-
资源调度:
- 智能地调度计算资源以优化能耗和性能。
-
模型微调:
- 在特定硬件上微调模型参数以获得最佳性能。
-
使用模型服务器:
- 使用模型服务器进行模型管理和版本控制。
在面试中,可以讨论这些因素和策略在具体项目中的应用,以及如何根据硬件环境和应用需求选择和调整优化策略。同时,也可以探讨在不同硬件上部署模型时遇到的挑战和解决方案。
相关文章:
Transformer常见面试题
目录 1.Transformer为何使用多头注意力机制?(为什么不使用一个头) 2.Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘? (注意和第一个问题的区别) 3.Transf…...

Linux——vim的配置文件+异常处理
vim的配置文件: [rootserver ~]# vim /etc/vimrc # 输入以下内容 set nu # 永久设置行号 shell [rootserver ~]# vim /etc/vimrc 或者 vim ~/.vimrc set hlsearch "高亮度反白 set backspace2 "可随时用退格键删除 set autoindent…...
node mySql 实现数据的导入导出,以及导入批量插入的sql语句
node 实现导出, 在导出excel中包含图片(附件) node 实现导出, 在导出excel中包含图片(附件)-CSDN博客https://blog.csdn.net/snows_l/article/details/139999392?spm1001.2014.3001.5502 一、效果 如图: 二、导入 …...
Webpack: 底层配置逻辑
概述 Webpack 5 提供了非常强大、灵活的模块打包功能,配合其成熟生态下数量庞大的插件、Loader 资源,已经能够满足大多数前端项目的工程化需求,但代价则是日益复杂、晦涩的使用方法,开发者通常需要根据项目环境、资源类型、编译目…...

数字图像处理期末复习题1
个人名片: 🎓作者简介:嵌入式领域优质创作者🌐个人主页:妄北y 📞个人QQ:2061314755 💌个人邮箱:[mailto:2061314755qq.com] 📱个人微信:Vir2025WB…...
poi-tl 生成 word 文件(插入文字、图片、表格、图表)
文章说明 本篇文章主要通过代码案例的方式,展示 poi-tl 生成 docx 文件的一些常用操作,主要涵盖以下内容 : 插入文本字符(含样式、超链接)插入图片插入表格引入标签(通过可选文字的方式,这种方…...
centos上部署Ollama平台,实现语言大模型本地部署
网上有很多大模型,很多都是远程在线调用ChatGPT的api来实现的,自己本地是没有大模型的,这里和大家分享一个大模型平台,可以实现本地快速部署大模型。 Ollama是一个开源项目,它提供了一个平台和工具集,用于部…...

Java学习 - Redis Redigo简单介绍
Redigo 驱动下载 go get github.com/garyburd/redigo/redis获取redis服务器连接 c, err : redis.Dial("tcp", "127.0.0.1:6379")if err ! nil {panic(err) }defer c.Close()命令使用 v, err : c.Do("SET","hello","world&quo…...
【鸿蒙学习笔记】ArkTS组件 Blank
官方文档:Blank 目录标题...

如何使用Spring Boot进行单元测试
如何使用Spring Boot进行单元测试 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何在Spring Boot项目中进行单元测试,确保代码质量…...

2024steam夏促商店打不开、steam活动加载不了解决方法一览
今年的夏促终于开始了!目前可以看到很多精品小游戏在促销列表内,活动正式开启后还不知道又会是怎样的一幅场景。因为每年夏促都会有不少刚高考完的新手加入,遇到常见的steam商店打不开、活动页面不加载等问题不知道怎么解决。所以这里给大家准备了几种常…...

IPC进程通信:QNX
引言 在现代操作系统中,进程间通信(IPC)机制是实现进程间数据交换和同步的关键技术。IPC允许多个进程共享信息和资源,从而协同工作完成复杂任务。在QNX Neutrino系统中,IPC尤为重要,因为QNX主要面向实时系…...

OpenCV学习之cv2.imshow()函数
OpenCV学习之cv2.imshow()函数 一、简介 cv2.imshow 是 OpenCV 库中用于显示图像的基本函数之一。在图像处理和计算机视觉的过程中,使用该函数可以快速预览处理后的图像,便于调试和结果展示。 二、基本语法 cv2.imshow(WindowName, Imgmat)三、参数说…...
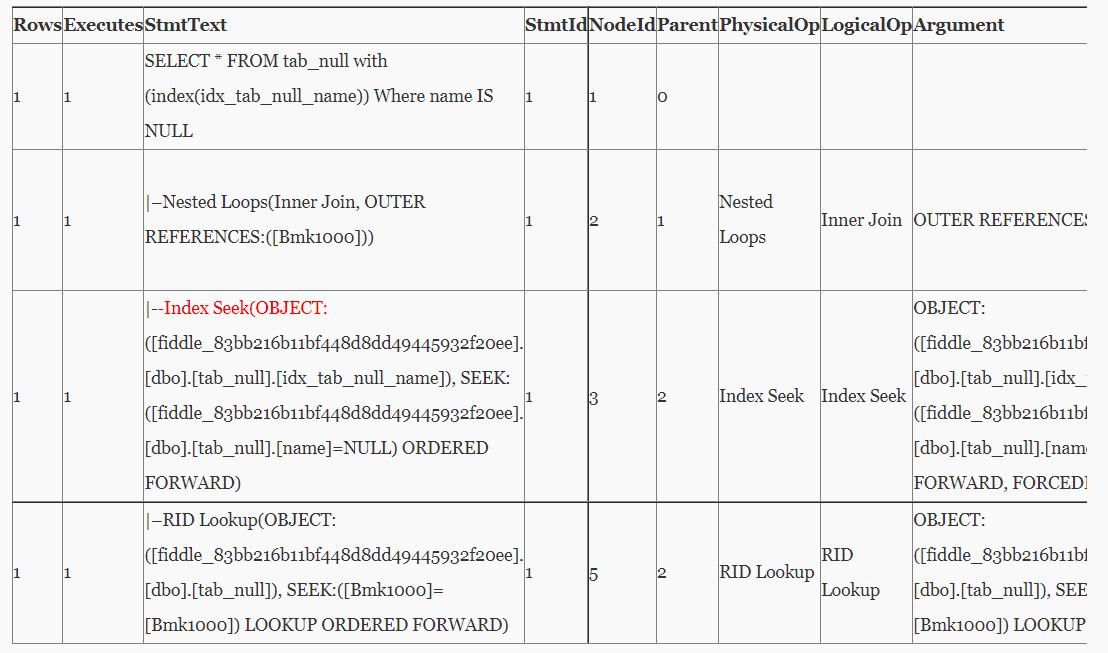
Oracle、MySQL、PostGreSQL、SQL Server-空值
Oracle、MySQL、PostGreSQL、SQL Server-null value 最近几年数据库市场百花齐放,在做跨数据库迁移的数据库选型时,除了性能、稳定、安全、运维、功能、可扩展外,像开发中对于值的处理往往容易被人忽视, 之前写过一篇关于PG区别O…...

python pip详解1
一、简介 pip是python的一个软件包管理工具,同yum,apt作用一致,pip有两种使用方式:pip模块和pip命令,示例如下: python -m pip install package pip install package二、命令行详解 python -m pip --hel…...
Linux常用命令大全(超详细!!!)
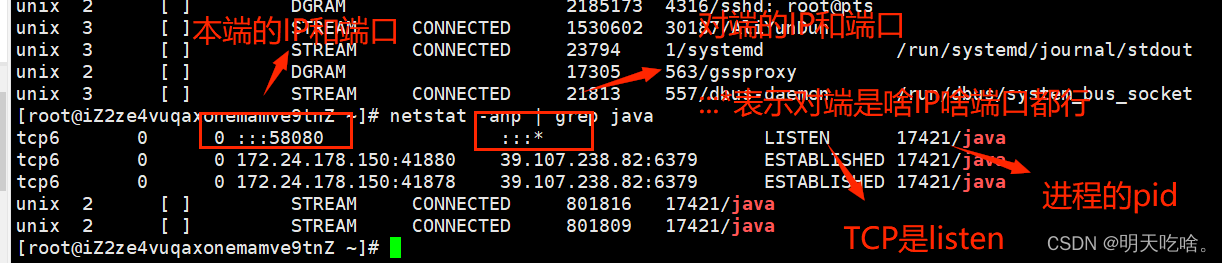
文章目录 1.Linux是什么1.1 关于Linux我们主要学习什么1.1 学习Linux常见命令的前置知识 2. Linux常见命令2.1 ls命令2.2 cd命令2.3 pwd命令2.4 touch命令2.5 cat命令2.6 echo命令2.7 vim命令2.8 mkdir 命令2.9 rm命令2.10 cp命令2.11 mv命令2.12 grep命令2.13 ps命令2.14 nets…...

TDD测试驱动开发
为什么需要TDD? 传统开发方式,带来大量的低质量代码,而代码质量带来的问题: 1.在缺陷的泥潭中挣扎 开发长时间投入在缺陷的修复中,修复完依赖测试做长时间的回归测试 2.维护困难,开发缓慢 比如重复代码&am…...

huggingface镜像站
huggingface下载太慢,大模型文件太大。用huggingface_hub镜像。 pip install -U huggingface_hub pip install huggingface-cli export HF_ENDPOINThttps://hf-mirror.com huggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat --loc…...

Java中如何实现数据库连接池优化?
Java中如何实现数据库连接池优化? 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨在Java应用程序中如何实现数据库连接池优化&am…...

002 SpringMVC入门项目搭建
文章目录 HelloController.javaspringmvc.xmlweb.xmlpom.xmlhello.jsp http://localhost:8080/showView http://localhost:8080/showData HelloController.java package com.springmvc.controller;import org.springframework.stereotype.Controller; import org.springframewo…...

别再手动算位宽了!Vivado FIR IP核的位宽计算逻辑与配置避坑指南
Vivado FIR IP核位宽计算实战:从黑盒解析到精准配置 在FPGA数字信号处理领域,FIR滤波器作为基础构建模块,其性能表现直接影响整个系统的信号处理质量。而位宽配置这个看似简单的参数,往往成为项目后期调试阶段的"隐形杀手&qu…...

终极指南:如何使用Autoclick实现Mac自动点击900次/秒
终极指南:如何使用Autoclick实现Mac自动点击900次/秒 【免费下载链接】Autoclick A simple Mac app that simulates mouse clicks 项目地址: https://gitcode.com/gh_mirrors/au/Autoclick 你是否厌倦了重复性的鼠标点击工作?无论是游戏中的重复操…...

如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南
如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼…...

轻量级监控系统Monikhao:自托管部署与核心架构解析
1. 项目概述:一个轻量级、可自托管的监控解决方案最近在折腾个人服务器和家庭网络监控时,发现了一个挺有意思的项目:khaodius/monikhao。乍一看这个名字,可能会觉得有点陌生,但如果你对自建监控系统有需求,…...

DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具
DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的免费开源工具,专为PC游戏玩家设计,能够智能管理、…...

终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼
终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中疯狂上跳的枪口而…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕
m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容日益丰富的今天…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...

Cursor编辑器状态快照插件开发:一键保存与恢复工作区
1. 项目概述:一个专为开发者设计的“后悔药”如果你是一名重度使用 Cursor 编辑器的开发者,那么你一定经历过这样的场景:在沉浸式编码时,为了快速定位或修改,你可能会频繁地使用CtrlClick跳转到函数定义,或…...