PHP爬虫类的并发与多线程处理技巧

PHP爬虫类的并发与多线程处理技巧
引言:
随着互联网的快速发展,大量的数据信息存储在各种网站上,获取这些数据已经成为很多业务场景下的需求。而爬虫作为一种自动化获取网络信息的工具,被广泛应用于数据采集、搜索引擎、舆情分析等领域。本文将介绍一种基于PHP的爬虫类的并发与多线程处理技巧,并通过代码示例来说明其实现方式。
一、爬虫类的基本结构
在实现爬虫类的并发与多线程处理前,我们先来看一下一个基本的爬虫类的结构。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
|
上述代码中,我们首先定义一个Crawler类,通过构造函数传入一个起始URL。在crawl()方法中,我们首先获取起始页面的内容,然后解析页面内容,提取需要的信息。之后,我们可以对获取到的信息进行处理,比如存储到数据库中。最后,我们获取页面中的链接,并递归抓取其他页面。
二、并发处理
通常情况下,爬虫需要处理大量的URL,而网络请求的IO操作非常耗时。如果我们采用顺序执行的方式,一个请求完毕后再请求下一个,会极大地降低我们的抓取效率。为了提高并发处理能力,我们可以采用PHP的多进程扩展来实现。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
上述代码中,我们首先定义了一个ConcurrentCrawler类,通过构造函数传入一组需要抓取的URL。在crawl()方法中,我们使用了多进程的方式来进行并发处理。通过使用pcntl_fork()函数,在每个子进程中处理一部分URL,而父进程负责管理子进程。最后,通过pcntl_wait()函数等待所有子进程的结束。
三、多线程处理
除了使用多进程进行并发处理,我们还可以利用PHP的Thread扩展实现多线程处理。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
上述代码中,我们首先定义了一个MultithreadCrawler类,继承自Thread类,并重写了run()方法作为线程的主体逻辑。在Executor类中,我们通过循环创建多个线程,并启动它们执行。最后,通过join()方法等待所有线程的结束。
结语:
通过对PHP爬虫类的并发与多线程处理技巧的介绍,我们可以发现并发处理和多线程处理都能够大大提高爬虫的抓取效率。不过,在实际开发过程中,我们需要根据具体的情况选择合适的处理方式。同时,为了保证多线程或多进程的安全性,我们还需要在处理过程中进行适当的同步操作。
相关文章:
PHP爬虫类的并发与多线程处理技巧
PHP爬虫类的并发与多线程处理技巧 引言: 随着互联网的快速发展,大量的数据信息存储在各种网站上,获取这些数据已经成为很多业务场景下的需求。而爬虫作为一种自动化获取网络信息的工具,被广泛应用于数据采集、搜索引擎、舆情分析…...

用Python将PowerPoint演示文稿转换到图片和SVG
PowerPoint演示文稿作为展示创意、分享知识和表达观点的重要工具,被广泛应用于教育、商务汇报及个人项目展示等领域。然而,面对不同的分享场景与接收者需求,有时需要我们将PPT内容以图片形式保存与传播。这样能够避免软件兼容性的限制&#x…...

机电公司管理小程序的设计
管理员账户功能包括:系统首页,个人中心,用户管理,管理员管理,客户管理,公告管理,考勤管理,请假管理 微信端账号功能包括:系统首页,公告,机电零件&…...
)
SQL中的子查询和CTE(with ....as..)
第一次看到with as 这种类似于python中读文件的写法还是挺疑惑的,其实它是CTE,功能和子查询很类似但又有不同点,在实际应用场景中具有着独特作用。 子查询 子查询是在主查询中的嵌套查询,可以出现在SELECT、FROM、WHERE等子句中…...

Cesium 基本概念:创建实体和相机控制
基本概念 Entity // 创建一个实体 const entity_1 viewer.entities.add({position: new Cesium.Cartesian3(0, 0, 10000000),point: {pixelSize: 10,color: Cesium.Color.BLUE} });// 通过经纬度创建实体 const position Cesium.Cartesian3.fromDegrees(180.0, 0.0); // 创…...
vue使用scrollreveal和animejs实现页面滑动到指定位置后再开始执行动画效果
效果图 效果链接:http://website.livequeen.top 介绍 一、Scrollreveal ScrollReveal 是一个 JavaScript 库,用于在元素进入/离开视口时轻松实现动画效果。 ScrollReveal 官网链接:ScrollReveal 二、animejs animejs是一个好用的动画库…...

在Ubuntu 16.04上安装和配置GitLab的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 GitLab CE(Community Edition)是一个开源应用程序,主要用于托管 Git 仓库,并提供额…...

STM32的SPI通信
1 SPI协议简介 SPI(Serial Peripheral Interface)协议是由摩托罗拉公司提出的通信协议,即串行外围设备接口,是一种高速全双工的通信总线。它被广泛地使用在ADC、LCD等设备与MCU间,使用于对通信速率要求较高的场合。 …...

机器学习引领教育革命:智能教育的新时代
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀目录 📒1. 引言📙2. 机器学习在教育中的应用🌞个性化学习🌙评估与反馈的智能化⭐教学资源的优…...

6月29日,每日信息差
第一、位于四川省绵阳市的中广核质子治疗装备制造基地正式通过竣工验收,为全球装机数量和治疗患者数量最多的国际领先质子治疗系统全面国产化奠定了坚实基础。质子治疗作为目前全球最尖端的肿瘤放射治疗技术之一,与传统放疗技术相比,质子治疗…...

SpringCloud中复制模块然后粘贴,文件图标缺少蓝色方块
再maven中点击+号,把当前pom文件交给maven管理即可...
JS乌龟吃鸡游戏
代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>乌龟游戏</title><script type"text/javascript">function move(obj){//乌龟图片高度var wuGui_height 67;…...

第十节:学习ConfigurationProperties类来配置pojo实体类参数(自学Spring boot 3.x的第二天)
大家好,我是网创有方 。这节记录下如何使用ConfigurationProperties来实现自动注入配置值。。实现将配置文件里的application.properties的参数赋值给实体类并且打印出来。 第一步:新建一个实体类WechatConfig package cn.wcyf.wcai.config;import org…...

如何学习Node.js
Node.js是一个开源、跨平台的JavaScript运行环境,它允许你在服务器端使用JavaScript。以下是一些步骤和资源,可以帮助你开始学习Node.js: ### 1. 基础知识 首先,确保你熟悉JavaScript语言的基础。Node.js是基于JavaScript的&…...

云计算基础知识
前言: 随着ICT技术的高速发展,企业架构对计算、存储、网络资源的需求更高,急需一种新的架构来承载业务,以获得持续,高速,高效的发展,云计算应运而生。 云计算背景 信息大爆炸时代:…...
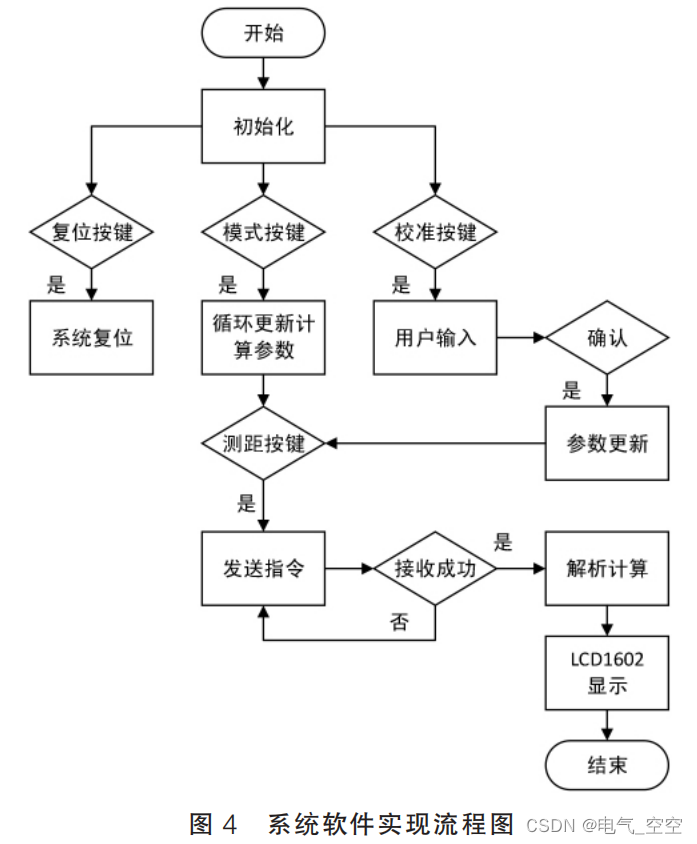
基于单片机光纤测距系统的设计与实现
摘要 : 光纤由于其频带宽 、 损耗低及抗干扰能力强等优点已被广泛地应用在通信 、 电子及电力方面 , 是我们生产生活中必不可少的媒介。 在实际的光纤实验 、 安装 、 运营和维护工作中 , 一种精准 、 轻便和易操作的光纤测距系统显得尤为重…...

python项目实战——人生重开模拟器
文章目录 1.菜单栏的编写2.玩家确定颜值、体质、智力、家境3.生成性别4.设定角色出生点5.各个年龄段的变化5.1 幼年阶段5.2 青年阶段5.3中年阶段5.4 晚年阶段 6.整体代码 人生重开模拟器是一款文字类小游戏. 玩家可根据提示输入角色的初始属性之后, 就可以开启不同的人生经历. …...

小时候的子弹击中了现在的我-hive进阶:案例解析(第18天)
系列文章目录 一、Hive表操作 二、数据导入和导出 三、分区表 四、官方文档(了解) 五、分桶表(熟悉) 六、复杂类型(熟悉) 七、Hive乱码解决(操作。可以不做,不影响) 八、…...

电影票房预测管理系统设计
电影票房预测管理系统的开发涉及多个层面的设计,包括但不限于数据收集、数据分析、预测模型构建、用户界面设计和系统集成。以下是一个基本的系统设计框架: 1. 数据收集模块:这是整个系统的基础。需要收集的数据可能包括历史票房数据、上映电…...

正则表达式与Pyhton
一、正则表达式的规则 1、支持普通字符匹配 2、元字符,一个符号匹配一堆字符 \d 匹配数字 \w 匹配数字、字母、下划线 \D \d的取反,除了数字全部匹配 \W \w的取反 [abc] 匹配字母a、b、c [^abc] [abc]的取反…...

我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 我的Claude Code不再被封号,Taotoken提供了稳定可靠的替代方案 作为一名频繁使用Claude Code进行代码生成和审查的个人…...

PowerInfer:基于热点神经元预测的LLM高性能推理引擎部署指南
1. 项目概述:当推理速度成为AI落地的瓶颈最近在折腾本地大模型推理的朋友,估计都绕不开一个核心痛点:速度。模型效果再好,生成一句话要等上十几秒,那种“卡顿感”足以劝退绝大多数想把它集成到实际应用里的开发者。我自…...

如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解
如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...

CFD工程师必看:TVD格式选型指南——从SUPERBEE到UMIST,哪个才是你的菜?
CFD工程师必看:TVD格式选型实战指南——从工程场景到最优解 在计算流体力学(CFD)的世界里,TVD格式就像赛车手的轮胎选择——没有绝对的好坏,只有场景的适配。当你在汽车外气动分析中遇到激波振荡,或在燃烧模拟中面临虚假扩散时&am…...

构建个人技能库:用GitHub+Markdown打造开发者的第二大脑
1. 项目概述:从“我的Copaw技能”看个人技能库的构建与管理最近在GitHub上看到一个挺有意思的项目,叫“my-copaw-skill”。这个项目名本身就很有故事感,“Copaw”这个词,我猜是“Code”和“Paw”(爪子)的结…...

ViewTurbo:基于响应式依赖追踪的前端渲染优化方案
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 ViewTurbo。这名字听起来就带点“涡轮增压”的劲儿,事实上,它也确实是一个旨在为视图渲染“加速”的工具。简单来说,ViewTurbo 的核心目标,是解决在复杂前端…...

大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核?!
【大学正在悄悄 “僵尸化”,AI正在毁掉高等教育内核】快速阅读:大学正面临一场名为“僵尸化”的危机。当学生和教授都开始将 AI 用于替代思考、替代教学、甚至替代沟通时,高等教育正在从知识的殿堂退化为一种由算法驱动的、高度标准化的凭证工…...

儿童语音合成不能只靠“可爱”!ElevenLabs底层音素建模缺陷与3种年龄适配性补偿方案,一线教育科技团队内部流出
更多请点击: https://intelliparadigm.com 第一章:儿童语音合成不能只靠“可爱”!ElevenLabs底层音素建模缺陷与3种年龄适配性补偿方案,一线教育科技团队内部流出 ElevenLabs 的 TTS 模型虽在成人语音自然度上表现优异࿰…...

从刺绣到互动:用导电绣线与微控制器打造光控可穿戴艺术
1. 项目概述与核心价值最近在捣鼓一个特别有意思的玩意儿:把会发光的电子元件“绣”到衣服上,让它不仅能穿,还能跟你互动。这个光控发光琵琶鱼刺绣项目,就是一个绝佳的入门案例。它完美地融合了传统手工艺(刺绣&#x…...

从零制作LED智能面具:三种方案详解与避坑指南
1. 项目概述:三种不同段位的LED化妆面具制作如果你对闪烁的灯光和可穿戴电子设备着迷,一直想亲手做一个能在派对或演出中吸引眼球的智能面具,但又觉得无从下手,那这个项目就是为你准备的。我花了几个周末的时间,从最简…...