动手学深度学习(Pytorch版)代码实践 -计算机视觉-48全连接卷积神经网络(FCN)
48全连接卷积神经网络(FCN)

1.构造函数
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
import matplotlib.pyplot as plt
import liliPytorch as lp
from d2l import torch as d2l# 构造模型
pretrained_net = torchvision.models.resnet18(pretrained=True)
# print(list(pretrained_net.children())[-3:]) # ResNet-18模型的最后几层
"""
[Sequential((0): BasicBlock((conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(downsample): Sequential((0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True))
), AdaptiveAvgPool2d(output_size=(1, 1)), Linear(in_features=512, out_features=1000, bias=True)]
"""# 创建一个全卷积网络net。 它复制了ResNet-18中大部分的预训练层,
# 除了最后的全局平均汇聚层和最接近输出的全连接层。
net = nn.Sequential(*list(pretrained_net.children())[:-2])# ResNet-18中
"""
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape:\t', X.shape)
# Sequential output shape: torch.Size([1, 64, 24, 24])
# Sequential output shape: torch.Size([1, 64, 24, 24])
# Sequential output shape: torch.Size([1, 128, 12, 12])
# Sequential output shape: torch.Size([1, 256, 6, 6])
# Sequential output shape: torch.Size([1, 512, 3, 3])
前向传播将输入的高和宽减小至原来的 1/32
"""
# 使用1 X 1 卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。
# 最后需要将特征图的高度和宽度增加32倍,从而将其变回输入图像的高和宽。
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes, num_classes,kernel_size=64, padding=16, stride=32))
# print(list(net.children())[-2:])
"""
[Conv2d(512, 21, kernel_size=(1, 1), stride=(1, 1)),
ConvTranspose2d(21, 21, kernel_size=(64, 64), stride=(32, 32), padding=(16, 16))]
"""
2.双线性插值
# 初始化转置卷积层
# 在图像处理中,我们有时需要将图像放大,即上采样(upsampling)
# 双线性插值(bilinear interpolation) 是常用的上采样方法之一,
# 它也经常用于初始化转置卷积层
# 双线性插值的上采样可以通过转置卷积层实现,内核由以下bilinear_kernel函数构造。
def bilinear_kernel(in_channels, out_channels, kernel_size):factor = (kernel_size + 1) // 2 # 计算中心因子,用于确定卷积核的中心位置if kernel_size % 2 == 1: # 确定卷积核的中心位置# 如果卷积核大小是奇数center = factor - 1else:# 如果卷积核大小是偶数center = factor - 0.5# 生成坐标网格,用于计算每个位置的双线性内核值og = (torch.arange(kernel_size).reshape(-1, 1), # 列向量torch.arange(kernel_size).reshape(1, -1)) # 行向量# 计算双线性内核值,基于当前位置与中心位置的距离并归一化filt = (1 - torch.abs(og[0] - center) / factor) * \(1 - torch.abs(og[1] - center) / factor)# 初始化权重张量weight = torch.zeros((in_channels, out_channels, kernel_size, kernel_size))# 填充权重张量,将计算好的双线性内核值赋值给权重张量weight[range(in_channels), range(out_channels), :, :] = filt# 返回生成的双线性卷积核权重张量return weight# 定义转置卷积层 (n + 4 - 2 - 2 ) * 2
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2,bias=False)
# 将双线性卷积核权重复制到转置卷积层的权重
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4))img = torchvision.transforms.ToTensor()(d2l.Image.open('../limuPytorch/images/catdog.jpg'))
"""
d2l.Image.open('../limuPytorch/images/catdog.jpg') 首先被执行,返回一个 PIL.Image 对象。
然后,torchvision.transforms.ToTensor() 创建一个 ToTensor 对象。
最后,ToTensor 对象被调用(通过 () 运算符),将 PIL.Image 对象作为参数传递给 ToTensor 的 __call__ 方法,
转换为 PyTorch 张量。
"""
X = img.unsqueeze(0) # 添加一个新的维度,形成形状为 (1, C, H, W) 的张量 X,
Y = conv_trans(X)
out_img = Y[0].permute(1, 2, 0).detach()print('input image shape:', img.permute(1, 2, 0).shape)
# input image shape: torch.Size([561, 728, 3])
plt.imshow(img.permute(1, 2, 0))
plt.show()
print('output image shape:', out_img.shape)
# output image shape: torch.Size([1122, 1456, 3])
# 图片放大了两倍
plt.imshow(out_img)
plt.show()
3.模型训练
# 37微调章节的代码
def train_batch_ch13(net, X, y, loss, trainer, devices):"""使用多GPU训练一个小批量数据。参数:net: 神经网络模型。X: 输入数据,张量或张量列表。y: 标签数据。loss: 损失函数。trainer: 优化器。devices: GPU设备列表。返回:train_loss_sum: 当前批次的训练损失和。train_acc_sum: 当前批次的训练准确度和。"""# 如果输入数据X是列表类型if isinstance(X, list):# 将列表中的每个张量移动到第一个GPU设备X = [x.to(devices[0]) for x in X]else:X = X.to(devices[0])# 如果X不是列表,直接将X移动到第一个GPU设备y = y.to(devices[0])# 将标签数据y移动到第一个GPU设备net.train() # 设置网络为训练模式trainer.zero_grad()# 梯度清零pred = net(X) # 前向传播,计算预测值l = loss(pred, y) # 计算损失l.sum().backward()# 反向传播,计算梯度trainer.step() # 更新模型参数train_loss_sum = l.sum()# 计算当前批次的总损失train_acc_sum = d2l.accuracy(pred, y)# 计算当前批次的总准确度return train_loss_sum, train_acc_sum# 返回训练损失和与准确度和def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices=d2l.try_all_gpus()):"""训练模型在多GPU参数:net: 神经网络模型。train_iter: 训练数据集的迭代器。test_iter: 测试数据集的迭代器。loss: 损失函数。trainer: 优化器。num_epochs: 训练的轮数。devices: GPU设备列表,默认使用所有可用的GPU。"""# 初始化计时器和训练批次数timer, num_batches = d2l.Timer(), len(train_iter)# 初始化动画器,用于实时绘制训练和测试指标animator = lp.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],legend=['train loss', 'train acc', 'test acc'])# 将模型封装成 DataParallel 模式以支持多GPU训练,并将其移动到第一个GPU设备net = nn.DataParallel(net, device_ids=devices).to(devices[0])# 训练循环,遍历每个epochfor epoch in range(num_epochs):# 初始化指标累加器,metric[0]表示总损失,metric[1]表示总准确度,# metric[2]表示样本数量,metric[3]表示标签数量metric = lp.Accumulator(4)# 遍历训练数据集for i, (features, labels) in enumerate(train_iter):timer.start() # 开始计时# 训练一个小批量数据,并获取损失和准确度l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)metric.add(l, acc, labels.shape[0], labels.numel()) # 更新指标累加器timer.stop() # 停止计时# 每训练完五分之一的批次或者是最后一个批次时,更新动画器if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[3], None))test_acc = d2l.evaluate_accuracy_gpu(net, test_iter) # 在测试数据集上评估模型准确度animator.add(epoch + 1, (None, None, test_acc))# 更新动画器# 打印最终的训练损失、训练准确度和测试准确度print(f'loss {metric[0] / metric[2]:.3f}, train acc 'f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')# 打印每秒处理的样本数和使用的GPU设备信息print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on 'f'{str(devices)}')# 全卷积网络用双线性插值的上采样初始化转置卷积层
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W)
# 读取数据集
batch_size, crop_size = 32, (320, 480)
train_iter, test_iter = lp.load_data_voc(batch_size, crop_size) # 46语义分割和数据集代码
# 损失函数
def loss(inputs, targets):return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
# loss 0.443, train acc 0.863, test acc 0.848
# 254.0 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
plt.show()
相关文章:
动手学深度学习(Pytorch版)代码实践 -计算机视觉-48全连接卷积神经网络(FCN)
48全连接卷积神经网络(FCN) 1.构造函数 import torch import torchvision from torch import nn from torch.nn import functional as F import matplotlib.pyplot as plt import liliPytorch as lp from d2l import torch as d2l# 构造模型 pretrained…...

【Python游戏】猫和老鼠
本文收录于 《一起学Python趣味编程》专栏,从零基础开始,分享一些Python编程知识,欢迎关注,谢谢! 文章目录 一、前言二、代码示例三、知识点梳理四、总结一、前言 本文介绍如何使用Python的海龟画图工具turtle,开发猫和老鼠游戏。 什么是Python? Python是由荷兰人吉多范…...

【无标题】c# WEBAPI 读写表到Redis
//c# WEBAPI 读写表到Redis using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Net.Http; using System.Web.Http; using Newtonsoft.Json; using StackExchange.Redis; using System.Data; using System.Web; namespace …...
)
【剑指Offer系列】53-0到n中缺失的数字(index)
给定一个包含 [0, n] 中 n 个数的数组 nums ,找出 [0, n] 这个范围内没有出现在数组中的那个数。 示例 1: 输入:nums [3,0,1] 输出:2 解释:n 3,因为有 3 个数字,所以所有的数字都在范围 [0,3]…...

docker compose部署zabbix7.0官方方法快速搭建
环境介绍: 系统:centos7 官方文档:https://www.zabbix.com/documentation/current/zh/manual/installation/containers docker镜像加速 vi /etc/docker/daemon.json{"registry-mirrors": ["https://docker.1panel.live&quo…...
?)
分库分表之后如何设计主键ID(分布式ID)?
文章目录 1、数据库的自增序列步长方案2、分表键结合自增序列3、UUID4、雪花算法5、redis的incr方案总结 在进行数据库的分库分表操作后,必然要面临的一个问题就是主键id如何生成,一定是需要一个全局的id来支持,所以分库分表之后,…...
秋招突击——6/28、6.29——复习{数位DP——度的数量}——新作{}
文章目录 引言复习数位DP——度的数量个人实现参考实现 总结 引言 头一次产生了那么强烈的动摇,对于未来没有任何的感觉的,不知道将会往哪里走,不知道怎么办。可能还是因为实习吧,再加上最近复习也没有什么进展,并不知…...

Spring Boot中使用Thymeleaf进行页面渲染
Spring Boot中使用Thymeleaf进行页面渲染 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何在Spring Boot应用中使用Thymeleaf模板引擎进行页面…...

恢复策略(下)-事务故障后的数据库恢复、系统故障后的数据库恢复(检查点技术)、介质故障后的数据库恢复
一、数据库恢复-事务故障 系统通过对事物进行UNDO操作和REDO操作可实现故障后的数据库状态恢复 1、对于发生事务故障后的数据库恢复 恢复机制在不影响其他事务运行的情况下,强行回滚夭折事务,对该事务进行UNDO操作,来撤销该事务已对数据库…...

如何知道docker谁占用的显卡的显存?
文章目录 python环境安装nvidia-htop查看pid加一个追踪总结一下【找到容器创建时间】使用说明示例 再总结一下【用PID找到容器创建时间,从而找到谁创建的】使用说明示例 python环境安装nvidia-htop nvidia-htop是一个看详细的工具。 pip3 install nvidia-htop查看…...
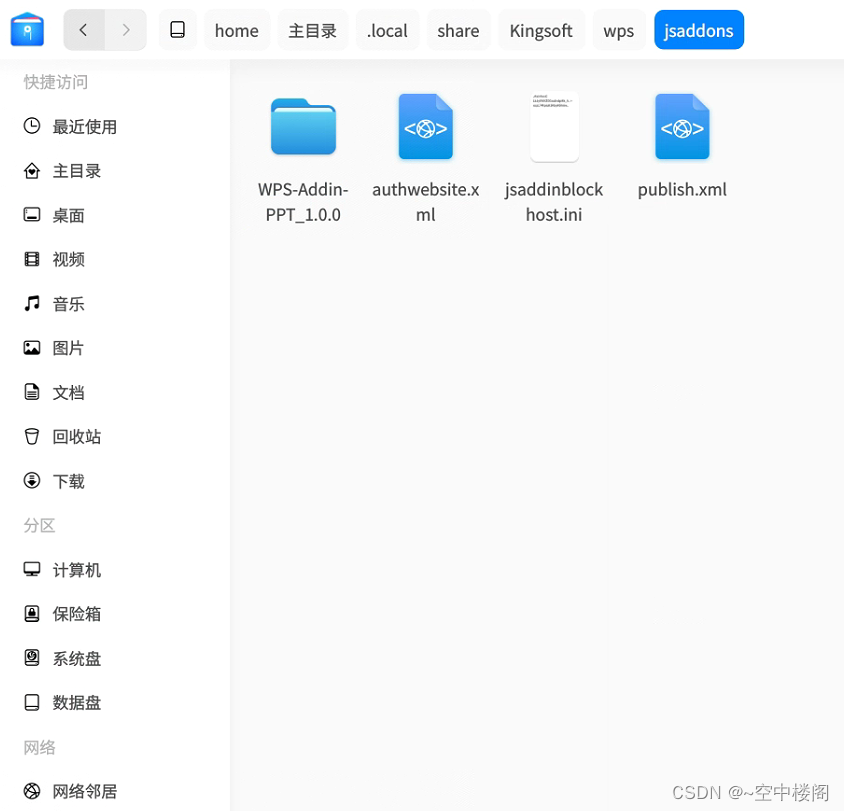
wps linux node.js 加载项开发,和离线部署方案
环境准备 windwos 安装node.js 安装VSCode 安装wps linux 安装node.js 安装VSCode 安装wps 通过npm 安装wpsjs SDK 使用npm安装wpsjs npm install -g wpsjs 创建一个项目 wpsjs create WPS-Addin-PPT 创建项目会让你选择2个东西: 1:选择你的文…...
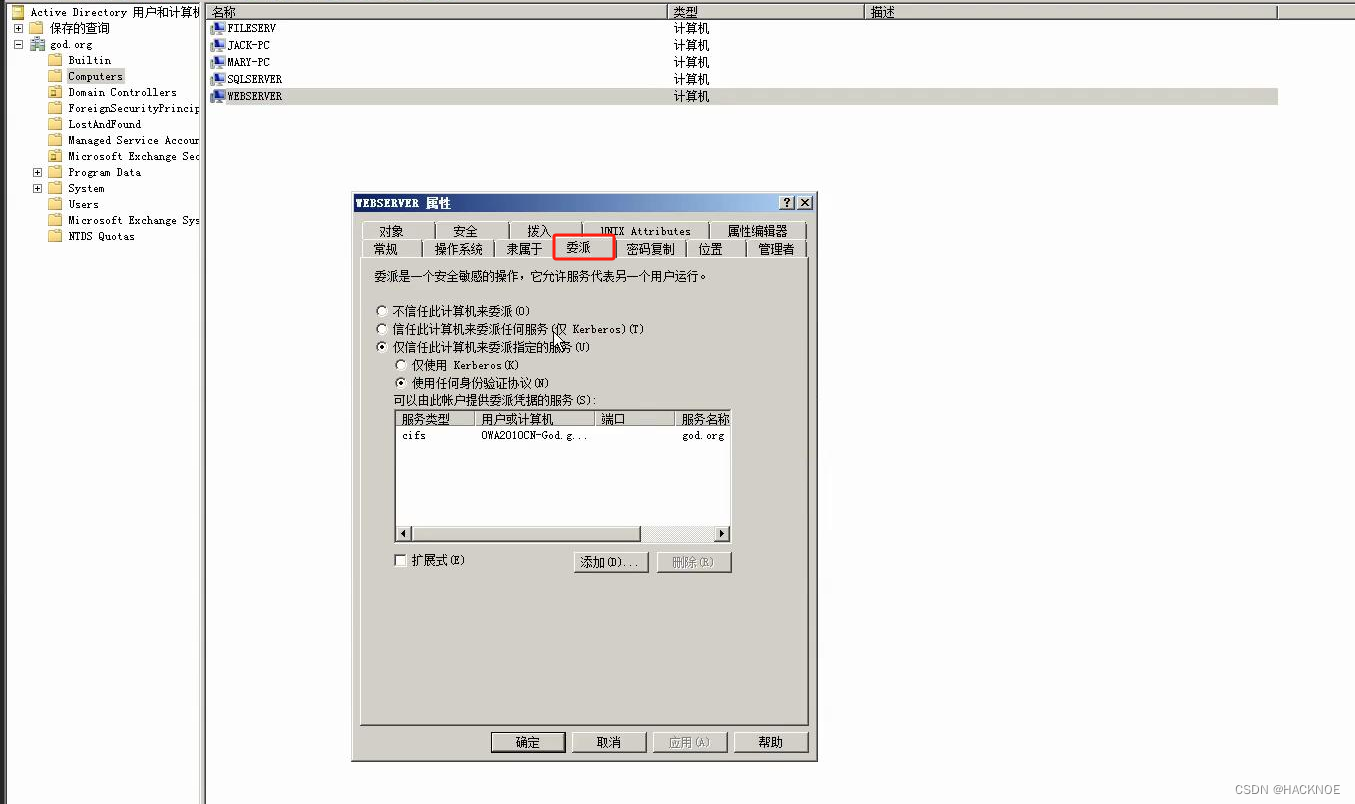
红队内网攻防渗透:内网渗透之内网对抗:横向移动篇Kerberos委派安全非约束系约束系RBCD资源系Spooler利用
红队内网攻防渗透 1. 内网横向移动1.1 委派安全知识点1.1.1 域委派分类1.1.2 非约束委派1.1.2.1 利用场景1.1.2.2 复现配置:1.1.2.3 利用思路1:诱使域管理员访问机器1.1.2.3.1 利用过程:主动通讯1.1.2.3.2 利用过程:钓鱼1.1.2.4 利用思路2:强制结合打印机漏洞1.1.2.5 利用…...

nginx上传文件限制
默认限制 Nginx 限制文件大小可以通过 client_max_body_size 指令来设置,该指令通常在 http、server 或 location 块中设置,如果不设置,默认上传大小为1M。 修改上传文件限制 要修改Nginx的文件上传大小限制,你需要编辑Nginx的配…...

76. 最小覆盖子串(困难)
76. 最小覆盖子串 1. 题目描述2.详细题解3.代码实现3.1 Python3.2 Java 1. 题目描述 题目中转:76. 最小覆盖子串 2.详细题解 在s中寻找一个最短的子串,使之包含t中的所有字符,t中可能存在多个相同字符,寻找的子串也应至少含有…...

K8S 集群节点扩容
环境说明: 主机名IP地址CPU/内存角色K8S版本Docker版本k8s231192.168.99.2312C4Gmaster1.23.1720.10.24k8s232192.168.99.2322C4Gwoker1.23.1720.10.24k8s233(需上线)192.168.99.2332C4Gwoker1.23.1720.10.24 当现有集群中的节点资源不够用&…...
AI大模型技术在音乐创造的应用前景
大模型技术在音乐创作领域具有广阔的应用前景,可以为音乐家、作曲家和音乐爱好者提供以下方面的帮助。北京木奇移动技术有限公司,专业的软件外包开发公司,欢迎交流合作。 音乐创作辅助:大模型可以帮助音乐家和作曲家生成旋律、和声…...
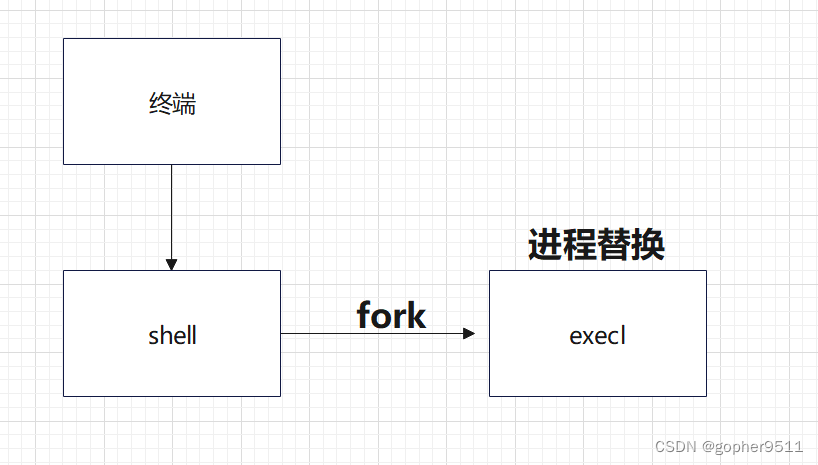
Linux多进程和多线程(一)-进程的概念和创建
进程 进程的概念进程的特点如下进程和程序的区别LINUX进程管理 getpid()getppid() 进程的地址空间虚拟地址和物理地址进程状态管理进程相关命令 ps toppstreekill 进程的创建 并发和并行fork() 父子进程执行不同的任务创建多个进程 进程的退出 exit()和_exit() exit()函数让当…...

熊猫烧香是什么?
熊猫烧香(Worm.WhBoy.cw)是一种由李俊制作的电脑病毒,于2006年底至2007年初在互联网上大规模爆发。这个病毒因其感染后的系统可执行文件图标会变成熊猫举着三根香的模样而得名。熊猫烧香病毒具有自动传播、自动感染硬盘的能力,以及…...

使用Vue3和Tailwind CSS快速搭建响应式布局
### 第一部分:初始化Vue3项目并安装Tailwind CSS 首先,在你的开发环境中打开终端,然后通过Vue CLI来创建一个新的Vue3项目。输入如下命令: vue create my-vue-app 按照提示选择Vue3的相关选项,创建完毕后࿰…...
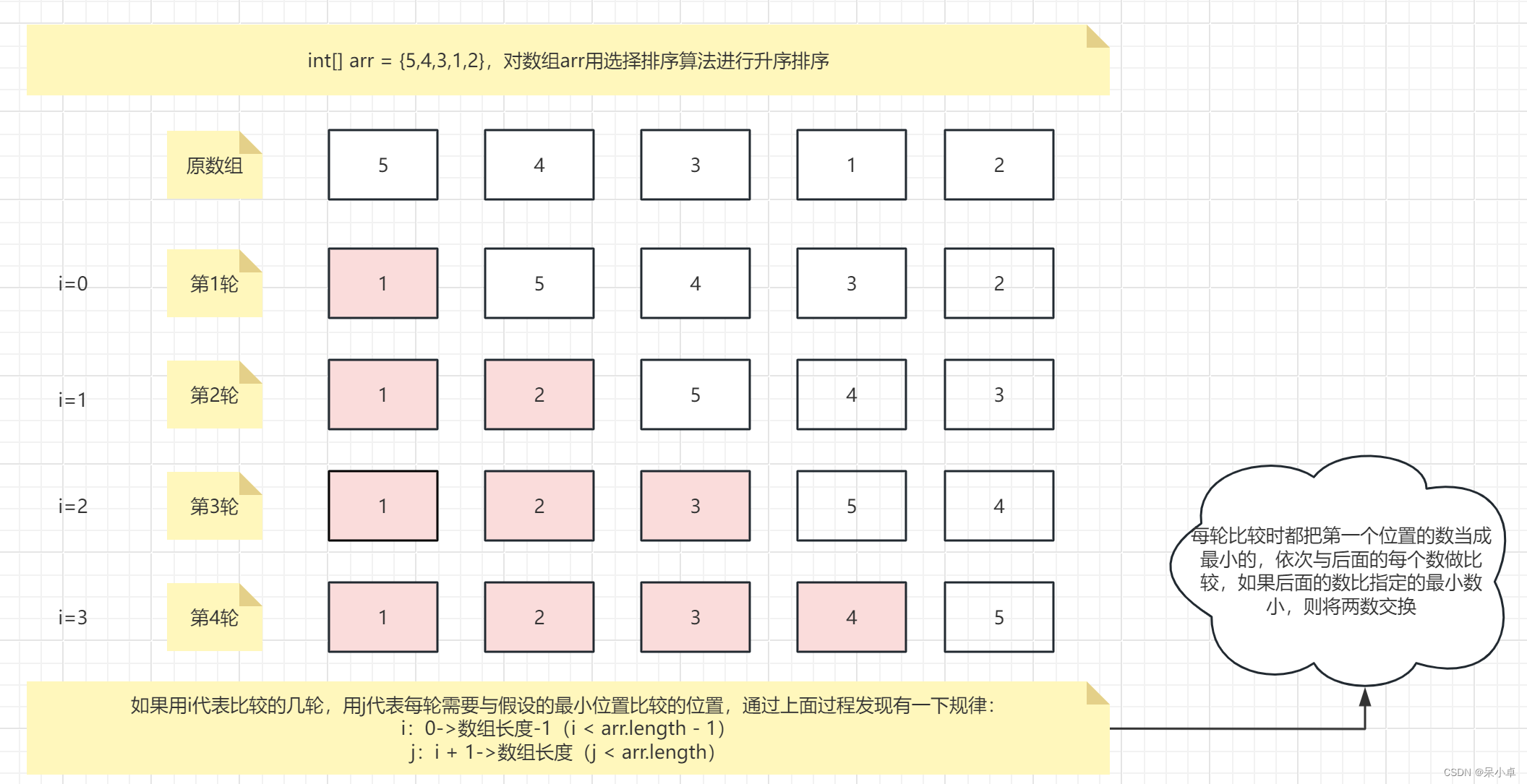
J019_选择排序
一、排序算法 排序过程和排序原理如下图所示: 二、代码实现 package com.itheima.sort;import java.util.Arrays;public class SelectSort {public static void main(String[] args) {int[] arr {5, 4, 3, 1, 2};//选择排序for (int i 0; i < arr.length - 1…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

基于Arduino与TSL2561的光照度测量系统:从硬件连接到软件调试
1. 项目概述:从园艺需求到嵌入式光测量方案最近在折腾一个园艺相关的项目,需要量化评估不同覆盖材料(比如遮阳网、塑料薄膜)对光线透射率的影响。说白了,就是想精确知道,盖上一层材料后,底下还能…...

Forge模组开发效率提升:Gradle插件自动化构建与热部署实践
1. 项目概述:一个为Forge模组开发者准备的“瑞士军刀”如果你是一名Minecraft Forge模组的开发者,或者你正打算踏入这个充满创造力的领域,那么你大概率经历过这样的场景:为了测试一个简单的功能改动,你需要反复地执行g…...

Python自动化股票分析工具:从数据采集到可视化报告全流程实战
1. 项目概述:一个面向个人投资者的自动化股票分析工具如果你和我一样,是个对A股市场有点兴趣,但又没时间天天盯盘的上班族,那你肯定也经历过这种纠结:早上开盘前想看看心仪的几只股票有没有什么异动,结果一…...

Python数据聚合抓取工具:从配置化引擎到实战避坑指南
1. 项目概述:一个多功能的“聚合爪”工具最近在GitHub上闲逛,发现了一个名字挺有意思的项目:al1enjesus/polyclawster。这个名字拆开看,“poly”代表多,“clawster”听起来像是“claw”(爪子)和…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

Pro Trinket:Arduino UNO的紧凑型替代方案与双模编程实战
1. Pro Trinket:当Arduino遇上“口袋工程学”如果你和我一样,在创客圈子里摸爬滚打多年,肯定经历过这样的场景:一个基于Arduino UNO的酷炫原型在面包板上运行得风生水起,但当你试图把它塞进一个精致的3D打印外壳&#…...

基于xclaude-plugin框架的Claude自定义插件开发实战指南
1. 项目概述:Claude插件生态的“瑞士军刀”如果你最近在深度使用Claude,尤其是Claude Desktop应用,那你大概率已经感受到了插件生态的潜力与混乱。官方插件商店虽然方便,但总有些特定需求找不到现成的解决方案,或者找到…...

容器镜像深度解析与生产级部署实战指南
1. 项目概述:从容器镜像名到高效部署实践的深度解析最近在梳理内部容器镜像仓库时,一个名为containers/ramalama的镜像引起了我的注意。这个名字乍一看有些无厘头,甚至带点戏谑,但在容器化部署的实践中,这类看似随意的…...

雷达目标检测与成像算法实时实现【附代码】
✨ 长期致力于阵列雷达、多输入多输出、现场可编程门阵列、目标检测定位、高分辨成像研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)相控阵和差波束目…...