【机器学习】机器学习重要方法——迁移学习:理论、方法与实践
文章目录
- 迁移学习:理论、方法与实践
- 引言
- 第一章 迁移学习的基本概念
- 1.1 什么是迁移学习
- 1.2 迁移学习的类型
- 1.3 迁移学习的优势
- 第二章 迁移学习的核心方法
- 2.1 特征重用(Feature Reuse)
- 2.2 微调(Fine-Tuning)
- 2.3 领域适应(Domain Adaptation)
- 第三章 迁移学习的应用实例
- 3.1 医疗影像分析
- 3.2 文本分类
- 3.3 工业故障检测
- 第四章 迁移学习的未来发展与挑战
- 4.1 领域差异与模型适应性
- 4.2 数据隐私与安全
- 4.3 跨领域迁移与多任务学习
- 结论
迁移学习:理论、方法与实践
引言
迁移学习(Transfer Learning)作为机器学习的一个重要分支,通过将一个领域或任务中学得的知识应用到另一个领域或任务中,可以在数据稀缺或训练资源有限的情况下显著提升模型性能。本文将深入探讨迁移学习的基本原理、核心方法及其在实际中的应用,并提供代码示例以帮助读者更好地理解和掌握这一技术。

第一章 迁移学习的基本概念
1.1 什么是迁移学习
迁移学习是一类机器学习方法,通过在源领域(source domain)或任务(source task)中学得的知识来帮助目标领域(target domain)或任务(target task)的学习。迁移学习的核心思想是利用已有的模型或知识,减少在目标任务中对大规模标注数据的依赖,提高学习效率和模型性能。
1.2 迁移学习的类型
迁移学习可以根据源任务和目标任务的关系进行分类,主要包括以下几种类型:
- 归纳迁移学习(Inductive Transfer Learning):源任务和目标任务不同,但源领域和目标领域可以相同或不同。
- 迁移学习(Transductive Transfer Learning):源领域和目标领域不同,但任务相同。
- 跨领域迁移学习(Cross-Domain Transfer Learning):源领域和目标领域不同,且任务也不同。
1.3 迁移学习的优势
迁移学习相比于传统机器学习方法具有以下优势:
- 减少标注数据需求:通过利用源任务中的知识,可以在目标任务中减少对大量标注数据的需求。
- 提高模型性能:在目标任务中数据稀缺或训练资源有限的情况下,迁移学习能够显著提升模型的泛化能力和预测准确性。
- 加快模型训练:通过迁移预训练模型的参数,可以减少模型训练时间和计算成本。
第二章 迁移学习的核心方法
2.1 特征重用(Feature Reuse)
特征重用是迁移学习的一种简单但有效的方法,通过直接使用源任务模型的特征提取层,将其应用到目标任务中进行特征提取,再在目标任务的数据上训练新的分类器或回归器。
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.applications import VGG16# 加载预训练的VGG16模型,不包括顶层分类器
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))# 冻结预训练模型的层
for layer in base_model.layers:layer.trainable = False# 构建新的分类器
model = models.Sequential([base_model,layers.Flatten(),layers.Dense(256, activation='relu'),layers.Dropout(0.5),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 加载并预处理CIFAR-10数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train = tf.image.resize(x_train, (224, 224)).numpy() / 255.0
x_test = tf.image.resize(x_test, (224, 224)).numpy() / 255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)# 训练模型
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test), batch_size=32)# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'测试准确率: {test_acc}')
2.2 微调(Fine-Tuning)
微调是迁移学习的一种常用方法,通过在目标任务的数据上继续训练预训练模型的部分或全部层,从而适应目标任务的特性。
# 解冻部分预训练模型的层
for layer in base_model.layers[-4:]:layer.trainable = True# 重新编译模型(使用较小的学习率)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-5), loss='categorical_crossentropy', metrics=['accuracy'])# 继续训练模型
model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test), batch_size=32)# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'微调后的测试准确率: {test_acc}')
2.3 领域适应(Domain Adaptation)
领域适应是迁移学习中的一种方法,通过调整源领域模型使其能够更好地适应目标领域的数据分布,从而提高在目标领域的预测性能。常见的领域适应方法包括对抗训练(Adversarial Training)和子空间对齐(Subspace Alignment)等。
from tensorflow.keras.datasets import mnist, usps
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input# 加载MNIST和USPS数据集
(mnist_train_images, mnist_train_labels), (mnist_test_images, mnist_test_labels) = mnist.load_data()
(usps_train_images, usps_train_labels), (usps_test_images, usps_test_labels) = usps.load_data()# 数据预处理
mnist_train_images = mnist_train_images.reshape(-1, 28*28).astype('float32') / 255
mnist_test_images = mnist_test_images.reshape(-1, 28*28).astype('float32') / 255
usps_train_images = usps_train_images.reshape(-1, 28*28).astype('float32') / 255
usps_test_images = usps_test_images.reshape(-1, 28*28).astype('float32') / 255mnist_train_labels = tf.keras.utils.to_categorical(mnist_train_labels, 10)
mnist_test_labels = tf.keras.utils.to_categorical(mnist_test_labels, 10)
usps_train_labels = tf.keras.utils.to_categorical(usps_train_labels, 10)
usps_test_labels = tf.keras.utils.to_categorical(usps_test_labels, 10)# 定义源领域模型
input_tensor = Input(shape=(28*28,))
x = Dense(256, activation='relu')(input_tensor)
x = Dense(256, activation='relu')(x)
output_tensor = Dense(10, activation='softmax')(x)source_model = Model(inputs=input_tensor, outputs=output_tensor)
source_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 在MNIST数据集上训练源领域模型
source_model.fit(mnist_train_images, mnist_train_labels, epochs=10, batch_size=128, validation_data=(mnist_test_images, mnist_test_labels))# 定义领域适应模型
feature_extractor = Model(inputs=source_model.input, outputs=source_model.layers[-2].output)
target_input = Input(shape=(28*28,))
target_features = feature_extractor(target_input)
target_output = Dense(10, activation='softmax')(target_features)
domain_adapt_model = Model(inputs=target_input, outputs=target_output)
domain_adapt_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 在USPS数据集上微调领域适应模型
domain_adapt_model.fit(usps_train_images, usps_train_labels, epochs=10, batch_size=128, validation_data=(usps_test_images, usps_test_labels))# 评估领域适应模型
test_loss, test_acc = domain_adapt_model.evaluate(usps_test_images, usps_test_labels)
print(f'领域适应模型在USPS测试集上的准确率: {test_acc}')

第三章 迁移学习的应用实例
3.1 医疗影像分析
在医疗影像分析任务中,迁移学习通过利用在大规模自然图像数据集上预训练的模型,可以显著提高在小规模医疗影像数据集上的分类或检测性能。以下是一个在胸部X光片数据集上使用迁移学习进行肺炎检测的示例。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import InceptionV3# 加载预训练的InceptionV3模型
base_model = InceptionV3(weights='imagenet', include_top=False, input_shape=(224, 224, 3))# 冻结预训练模型的层
for layer in base_model.layers:layer.trainable = False# 构建新的分类器
model = models.Sequential([base_model,layers.GlobalAveragePooling2D(),layers.Dense(256, activation='relu'),layers.Dropout(0.5),layers.Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 数据预处理
train_datagen = ImageDataGenerator(rescale=0.5, validation_split=0.2)
train_generator = train_datagen.flow_from_directory('chest_xray/train',target_size=(224, 224),batch_size=32,class_mode='binary',subset='training'
)
validation_generator = train_datagen.flow_from_directory('chest_xray/train',target_size=(224, 224),batch_size=32,class_mode='binary',subset='validation'
)# 训练模型
model.fit(train_generator, epochs=10, validation_data=validation_generator)# 评估模型
test_datagen = ImageDataGenerator(rescale=0.5)
test_generator = test_datagen.flow_from_directory('chest_xray/test',target_size=(224, 224),batch_size=32,class_mode='binary'
)
test_loss, test_acc = model.evaluate(test_generator)
print(f'迁移学习模型在胸部X光片测试集上的准确率: {test_acc}')
3.2 文本分类
在文本分类任务中,迁移学习通过使用在大规模文本语料库上预训练的语言模型,可以显著提高在特定领域或任务上的分类性能。以下是一个使用BERT预训练模型进行IMDB情感分析的示例。
from transformers import BertTokenizer, TFBertForSequenceClassification
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import SparseCategoricalCrossentropy# 加载BERT预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)# 编译模型
model.compile(optimizer=Adam(learning_rate=3e-5), loss=SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])# 加载IMDB数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.imdb.load_data(num_words=10000)# 数据预处理
maxlen = 100
x_train = pad_sequences(x_train, maxlen=maxlen)
x_test = pad_sequences(x_test, maxlen=maxlen)# 将数据转换为BERT输入格式
def encode_data(texts, labels):input_ids = []attention_masks = []for text in texts:encoded = tokenizer.encode_plus(text,add_special_tokens=True,max_length=maxlen,pad_to_max_length=True,return_attention_mask=True,return_tensors='tf')input_ids.append(encoded['input_ids'])attention_masks.append(encoded['attention_mask'])return {'input_ids': tf.concat(input_ids, axis=0),'attention_mask': tf.concat(attention_masks, axis=0)}, tf.convert_to_tensor(labels)train_data, train_labels = encode_data(x_train, y_train)
test_data, test_labels = encode_data(x_test, y_test)# 训练模型
model.fit(train_data, train_labels, epochs=3, batch_size=32, validation_data=(test_data, test_labels))# 评估模型
test_loss, test_acc = model.evaluate(test_data, test_labels)
print(f'迁移学习模型在IMDB测试集上的准确率: {test_acc}')
3.3 工业故障检测
在工业故障检测任务中,迁移学习通过利用在大规模工业数据上预训练的模型,可以显著提高在特定设备或场景下的故障检测性能。以下是一个使用迁移学习进行工业设备故障检测的示例。
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import load_model# 加载预训练的故障检测模型
base_model = load_model('pretrained_fault_detection_model.h5')# 冻结预训练模型的层
for layer in base_model.layers[:-2]:layer.trainable = False# 构建新的分类器
model = models.Sequential([base_model,layers.Dense(64, activation='relu'),layers.Dropout(0.5),layers.Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 加载并预处理工业设备数据集
data = pd.read_csv('industrial_equipment_data.csv')
X = data.drop(columns=['fault'])
y = data['fault']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))# 评估模型
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f'迁移学习模型在工业设备故障检测测试集上的准确率: {test_acc}')

第四章 迁移学习的未来发展与挑战
4.1 领域差异与模型适应性
迁移学习的一个主要挑战是源领域和目标领域之间的差异。研究如何设计更加灵活和适应性的模型,使其能够在不同领域间有效迁移,是一个重要的研究方向。
4.2 数据隐私与安全
在迁移学习中,源领域数据的隐私和安全问题需要特别关注。研究如何在保证数据隐私和安全的前提下进行有效的迁移学习,是一个关键的研究课题。
4.3 跨领域迁移与多任务学习
跨领域迁移学习和多任务学习是迁移学习的两个重要方向。研究如何在多个任务和领域间共享知识,提升模型的泛化能力和适应性,是迁移学习的一个重要研究方向。
结论
迁移学习作为一种有效的机器学习方法,通过将已学得的知识从一个任务或领域应用到另一个任务或领域,在数据稀缺或训练资源有限的情况下尤其有效。本文详细介绍了迁移学习的基本概念、核心方法及其在实际中的应用,并提供了具体的代码示例,帮助读者深入理解和掌握这一技术。希望本文能够为您进一步探索和应用迁移学习提供有价值的参考。

相关文章:
【机器学习】机器学习重要方法——迁移学习:理论、方法与实践
文章目录 迁移学习:理论、方法与实践引言第一章 迁移学习的基本概念1.1 什么是迁移学习1.2 迁移学习的类型1.3 迁移学习的优势 第二章 迁移学习的核心方法2.1 特征重用(Feature Reuse)2.2 微调(Fine-Tuning)2.3 领域适…...

uniapp, [TypeError] “Failed to fetch dynamically imported module“ 报错解决思路
文章目录 1. 背景2. 报错3. 解决思路4. 思考参考1. 背景 最近基于uniapp开发一款设备参数调试的APP软件,在使用第三方插件的过程中,出现下面的报错。 2. 报错 [plugin:vite:import-analysis] Cannot find module ‘D:/leaning/uniapp/demo/jk-uts-udp示例/uni_modules/uts-…...

四川省高等职业学校大数据技术专业建设暨专业质量监测研讨活动顺利开展
6月21日,省教育评估院在四川邮电职业技术学院组织开展全省高等职业学校大数据技术专业建设暨专业质量监测研讨活动。省教育评估院副院长赖长春,四川邮电职业技术学院党委副书记、校长冯远洪,四川邮电职业技术学院党委委员、副校长程德杰等出席…...

深入解析三大跨平台开发框架:Flutter、React Native 和 uniapp
深入解析三大跨平台开发框架:Flutter、React Native 和 uniapp 在移动开发中,跨平台开发框架已经成为开发者的首选工具。本篇将深入解析三大主流跨平台开发框架:Flutter、React Native 和 uniapp。下面将详细探讨它们的原理、优势和劣势。 …...

【吊打面试官系列-MyBatis面试题】#{}和${}的区别是什么?
大家好,我是锋哥。今天分享关于 【#{}和${}的区别是什么?】面试题,希望对大家有帮助; #{}和${}的区别是什么? #{} 是预编译处理,${}是字符串替换。 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网…...

解决HTTP 400 Bad Request错误的方法
解决HTTP 400 Bad Request错误的方法 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在进行网络通信时,HTTP 400 Bad Request错误是相对常见的问题…...

Html的表单标签。(Java程序员需要掌握的前端)
表单标签 2.5.1 表单 2.5.1.1 介绍 那表单呢,在我们日常的上网的过程中,基本上每天都会遇到。比如,我们经常在访问网站时,出现的登录页面、注册页面、个人信息提交页面,其实都是一个一个的表单 。 当我们在这些表单中录入数据之后…...
 下String的内存释放)
Arduino (esp ) 下String的内存释放
在个人的开源项目 GitHub - StarCompute/tftziku: 这是一个通过单片机在各种屏幕上显示中文的解决方案 中为了方便快速检索使用了string,于是这个string在esp8266中占了40多k,原本以为当string设置为""的时候这个40k就可以回收,结果发觉不行…...

图灵虚拟机配置
导入虚拟机 点击新建,选择虚拟硬盘文件 环境机器.vmdk 配置网络...
】)
【SQL常用日期函数(一)】
SQL 常用日期函数-基于impala 引擎 当前日期(YYYY-MM-DD) SELECT CURRENT_DATE(); -- 2024-06-30昨天 SELECT CURRENT_DATE(); -- 2024-06-30 SELECT CAST( DAYS_ADD(TO_DATE( CURRENT_DATE() ), -1 ) AS VARCHAR(10) ); -- 2024-06-29 SELECT CAST( …...
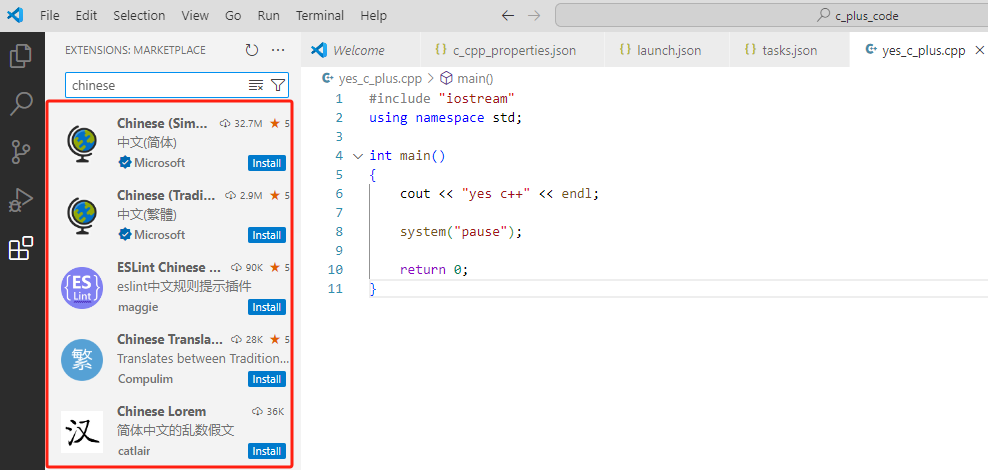
C++操作系列(二):VSCode安装和配置C++开发环境
1. VSCode下载 进入VSCode的官网网页:Download Visual Studio Code - Mac, Linux, Windows 下载相应的版本: 2. 安装VSCode 安装到指定位置: 一路下一步,直至安装完成: 3. 安装C插件 3.1. 安装C/C 点击扩展图标&…...

【java12】java12新特性之File的mismatch方法
Java12引入了一个新的方法 mismatch,它属于java.nio.file.Files类。此方法用于比较两个文件的内容,并返回第一个不匹配字节的位置。如果两个文件完全相同,则返回-1。 Files.mismatch 方法声明 public static long mismatch(Path path1, Pat…...
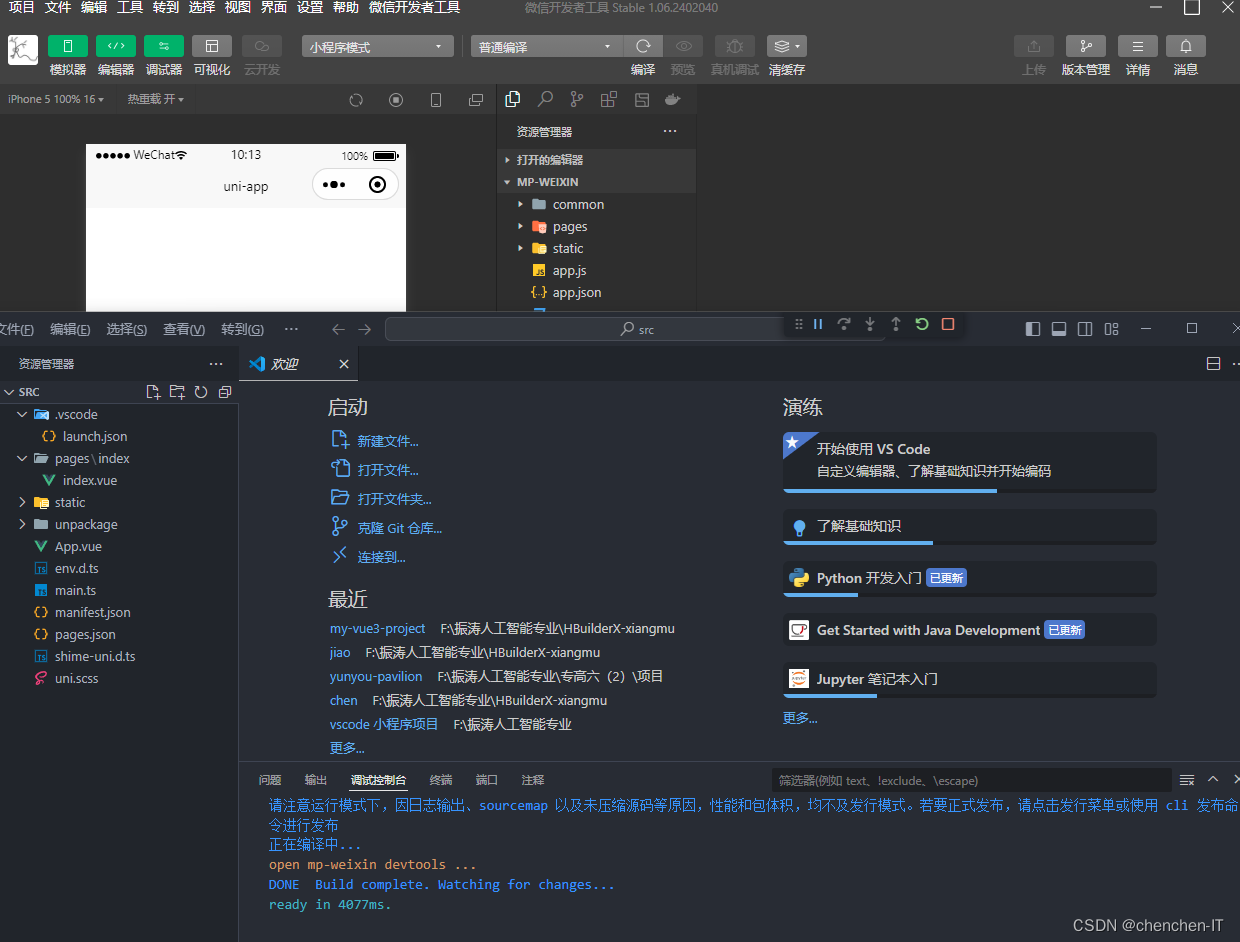
uni-app (通过HBuilderX 和 VS Code 开发)详细连接过程教学。
使用 HBuilderX 创建 uni-app 项目 并编译到微信开发者工具。 uni-app 支持两种方式创建项目: 通过 HBuilderX 创建 通过命令行创建 首先我们需要先下载HBuilderX 下载链接地址:DCloud - HBuilder、HBuilderX、uni-app、uniapp、5、5plus、mui、wap2…...
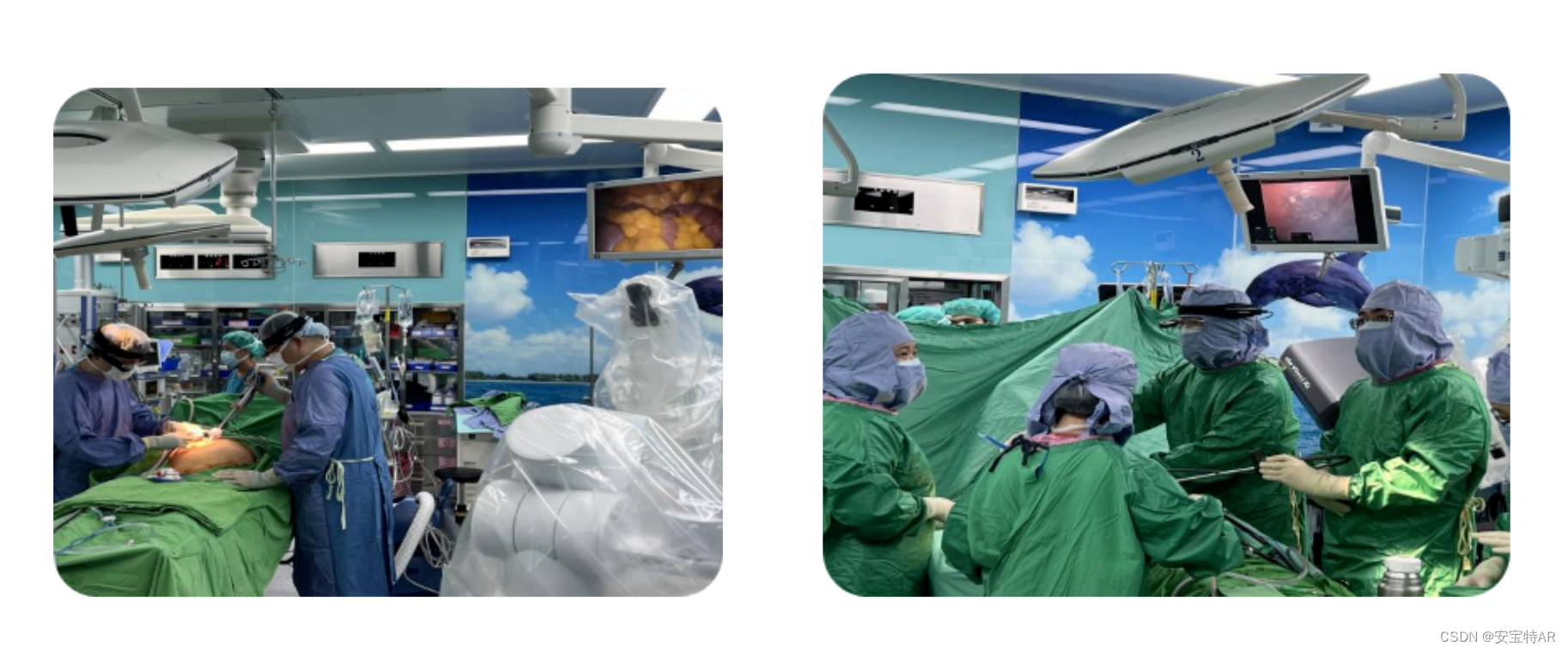
安宝特方案 | AR术者培养:AR眼镜如何帮助医生从“看”到“做”?
每一种新药品的上市都需要通过大量的临床试验,而每一种新的手术工具在普及使用之前也需要经过反复的实践和验证。医疗器械公司都面临着这样的挑战:如何促使保守谨慎的医生从仅仅观察新工具在手术中的应用,转变为在实际手术中实操这项工具。安…...

20240628每日前端---------解决vue项目滥用watch
主题 滥用watch。 名字解释 watch 例子 先看一个代码例子: <template>{{ dataList }} </template><script setup lang"ts"> import { ref, watch } from "vue";const dataList ref([]); const props defineProps([&q…...
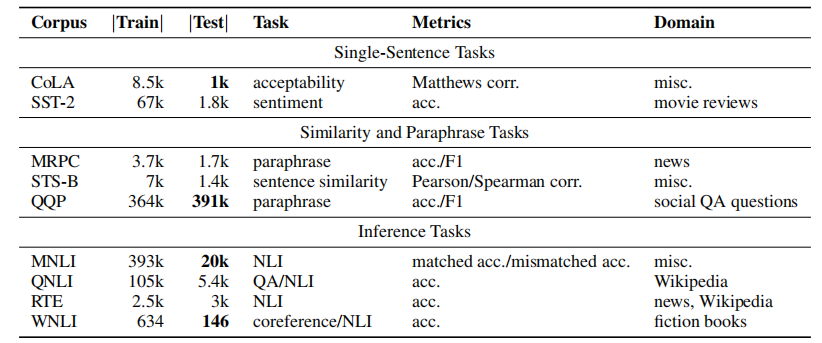
【LLM 评估】GLUE benchmark:NLU 的多任务 benchmark
论文:GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding ⭐⭐⭐⭐ arXiv:1804.07461, ICLR 2019 Site: https://gluebenchmark.com/ 文章目录 一、论文速读二、GLUE 任务列表2.1 CoLA(Corpus of Linguistic Accep…...
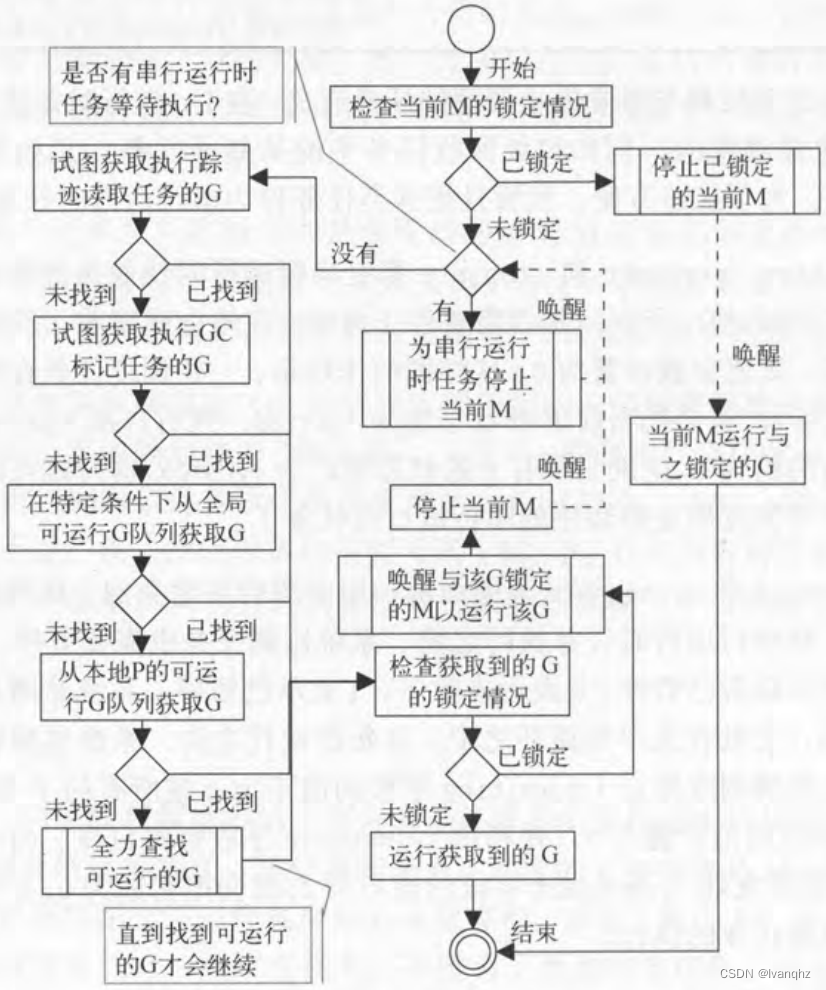
Go线程调度器
基本结构 字段gcwaiting、stopwait和stopnoted都是串行运行时任务执行前后的辅助协调手段 gcwaiting字段的值用于表示是否需要停止调度 在停止调度前,该值会被设置为1在恢复调度之前,该值会被设置为0这样做的作用是,一些调度任务在执行时只…...
使用 fvm 管理 Flutter 版本
文章目录 Github官网fvm 安装Mac/Linux 环境Windows 环境 fvm 环境变量fvm 基本命令 Github https://github.com/leoafarias/fvmhttps://github.com/flutter/flutter 官网 https://fvm.app/ fvm 安装 Mac/Linux 环境 Install.sh curl -fsSL https://fvm.app/install.sh …...

若依-前后端分离项目学习
★★★★★省流 直接看第一集和最后一集★★★★★ 第一天(6.24) 具体参考视频 b站 楠哥教你学Java 【【开源项目学习】若依前后端分离版,通俗易懂,快速上手】 https://www.bilibili.com/video/BV1HT4y1d7oA/?shar…...

使用adb shell getprop命令获取Android设备的属性
常用属性获取: adb shell getprop ro.build.version.emui —查询EMUI版本 adb shell getprop ro.product.brand —查询手机品牌 adb shell getprop ro.product.name --查询设备名称 adb shell getprop ro.serialno —查询设备序列号 获取手机系统信息( CPU,厂商…...

测试驱动开发与持续集成实践指南
测试驱动开发与持续集成实践指南 引言 测试驱动开发(TDD)和持续集成(CI)是现代软件开发中的重要实践。TDD强调先写测试再实现功能,CI确保代码的持续质量和快速反馈。本文将深入探讨TDD的方法论和CI的实践经验。 一、测…...

如何为你的智能体项目配置 Taotoken 作为 OpenAI 兼容后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为你的智能体项目配置 Taotoken 作为 OpenAI 兼容后端 基础教程类,面向希望将 Taotoken 作为大模型服务提供商接入…...

django-stubs模型类型检查实战:告别运行时错误的终极指南
django-stubs模型类型检查实战:告别运行时错误的终极指南 【免费下载链接】django-stubs PEP-484 stubs for Django 项目地址: https://gitcode.com/gh_mirrors/dj/django-stubs 在Django开发中,模型定义是核心环节,但传统开发模式下&…...

Office RibbonX Editor:打造个性化Office界面的终极工具
Office RibbonX Editor:打造个性化Office界面的终极工具 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...
)
分析梳理--分子动力学模拟的常规步骤八(Gromacs)
作者,Evil Genius 每一个组学内容都很多啊,都需要花费大量的时间学习,学习的最好阶段就是学生阶段,你的导师就是你的伯乐,像我这种社会底层人员,纯纯没事干,学了有没有用真的不知道。 这一篇我们继续分子动力学,上一步我们处理配体分子得到符合Gromacs的出入文件 这里…...

Flutter项目构建提速:告别‘gradle assembleDebug’卡顿的实战配置指南
1. 为什么Flutter项目构建会卡在gradle assembleDebug? 每次看到Android Studio卡在"Running Gradle task assembleDebug..."这个界面,我都忍不住想砸键盘。作为一个踩过无数坑的老Flutter开发者,我完全理解这种痛苦。其实这个问题…...

Infinity Router:构建统一流量网关的架构设计与生产实践
1. 项目概述:一个面向未来的路由聚合器 最近在折腾一个很有意思的项目,叫“Infinity Router”。这名字听起来挺唬人的,但说白了,它就是一个 路由聚合器 。不过,它和我们平时在项目里用的那些路由库(比如 …...

硬件工程师的‘第一板’:从最小系统设计到PCB Layout的STM32实战指南
STM32最小系统设计实战:从原理到PCB的工程化思维 作为一名硬件工程师,第一次独立完成PCB设计时的忐忑至今记忆犹新。那块承载着STM32最小系统的绿色电路板,不仅是我职业生涯的"第一板",更是一次从理论到实践的完整跨越。…...

基本面分析建模——用Excel构建财务筛选系统
价值投资就像相亲——你得设定条件,才能筛选出合适的对象。ROE是"赚钱能力",净利润增长率是"成长潜力",资产负债率是"家底厚不厚"。财报就像企业的"体检报告",而Excel就是你的"红娘系统"。记住,股东的钱生钱能力,才是…...

告别卡顿!用MobaXterm+PyCharm专业版,在实验室服务器上丝滑跑Python的保姆级教程
实验室服务器远程开发终极指南:MobaXterm与PyCharm专业版的高效协作方案 当你的Python脚本在本地笔记本上跑得比蜗牛还慢,而实验室那台128核的服务器却在"闲置"时,这种资源错配简直让人抓狂。作为一名常年与远程服务器打交道的算法…...