怎么用JavaScript写爬虫
随着互联网技术的不断发展,爬虫(web crawler)已经成为当前最热门的爬取信息方式之一。通过爬虫技术,我们可以轻松地获取互联网上的数据,并用于数据分析、挖掘、建模等多个领域。而javascript语言则因其强大的前端开发工具而获得越来越大的关注。那么,如何使用javascript写一个爬虫呢?接下来,本文将为您详细讲解。
一、什么是爬虫?
爬虫是指一种自动化程序,通过模拟浏览器的行为,访问网络中的各种网站,从中提取信息的一种程序。爬虫可以生成对网站的请求,并得到对应的响应,然后从响应中提取所需的信息。在互联网中,很多网站都会提供API接口,但是一些网站并没有提供这样的接口,我们就需要使用爬虫来抓取所需的数据。
二、JavaScript爬虫的原理及优势
- 原理
JavaScript爬虫的原理非常简单,其主要利用浏览器提供的Window对象,通过XMLHttpRequest或者Fetch函数模拟请求网页的行为,接着用Document对象进行DOM操作,从而获取页面DOM树,进而提取网页上的有用信息。
- 优势
与其他编程语言相比,JavaScript爬虫的优势在于:
(1)便于学习和使用
JavaScript语言的语法非常简洁明了,并且在前端开发中应用广泛,其一些方法和技术,在网页爬虫中也适用。
(2)能够实现动态爬取
某些网站有反爬虫的机制,对于非动态请求,页面可能会返回拒绝访问的提示信息。使用JavaScript可以模拟浏览器行为,对于一些动态网站爬取比较容易。
(3)应用广泛
JavaScript可以运行在多个终端设备上, 应用场景广泛。
三、使用JavaScript写爬虫的流程
要编写 JavaScript 爬虫用来获取网页数据,需要按照以下流程:
- 发送请求:爬虫首先会生成一个 URL,发送 HTTP 请求到这个 URL,以获取要爬取的网页内容。可以使用 Ajax,fetch等方法完成。
- 获取 HTML 内容:页面资源已经被下载下来,此时,我们需要将 HTML 内数据解析,解析后得到 DOM,使我们可以从中各种数据后续操作。
- 解析数据:了解页面数据所需要爬取的数据,以及这些数据出现在页面的位置和数据类型。可能需要借助外部库,例如 jQuery, cheerio,htmlparser2 等库,他们能够快速解析页面数据。
- 保存数据:需要使用File System 保存我们爬下来的信息。
下面我们通过一个例子来解释上述过程。
四、通过例子学习JavaScript爬虫的写法
在我们的例子中,我们将使用 Node.js 和jQuery, cheerio。以下是我们将要爬的网站:http://www.example.com
- 安装Node.js
如果未安装Node.js,需要先下载Node.js最新版本。运行以下命令来验证 Node.js 是否安装成功。
| 1 |
|
如果成功安装,会在命令行显示Node.js的版本号。
- 创建目录和文件
在本地创建一个新目录并且在该目录下使用终端创建一个 JavaScript 文件。例如,我们创建一个目录名为crawler,在该目录下创建一个名为crawler.js 的文件。
- 安装jQuery和cheerio
我们在 Node.js 中使用轻量级的jQuery替代原生js操作DOM(document),使用cheerio模块进行DOM操作。运行以下命令安装 jQuery 轻量级库和 cheerio 模块。
| 1 2 |
|
- 编写JavaScript爬虫代码
在crawler.js文件中,我们编写以下代码。
创建了一个 JavaScript 文件,导入了两个库cheerio和jQuery,它们可以让我们更方便地操作HTML内容。接着,创建express库并构建服务器。我们检索网站,并问 cheerio 模块将HTML内容加载到变量中,随后在HTML内容中查找我们感兴趣的元素,并将其输出到控制台中。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
代码分析:
通过request库的get方法请求http://www.example.com网站的HTML内容,$变量是cheerio的实例,通过此实例,使用$()进行操作DOM的方法和操作HTML的方法,以此在BODY标签中检索 H1 标签。使用res.json方法将我们的 HTML内容输出到控制台中。
注意事项:
- 爬虫需要获取的网站内容必须是可以公开的,如果涉及到基础认证,爬虫是无法自动获取到数据。
- 爬虫的速度需要适当,最好不要过快,否则服务器端可能认为您是异常访问。
五、总结
本文介绍了如何使用JavaScript编写爬虫以及优势和原理。JavaScript爬虫的优点在于其便于学习和使用,并可以实现动态爬取。对于动态网站爬取来说,使用 JavaScript 是非常方便和简单的,因为它具有跨平台的优势和广泛的应用。如果您想要获取互联网上的数据并用于数据分析、挖掘、建模等多个领域,JavaScript爬虫是一种不错的选择。
相关文章:

怎么用JavaScript写爬虫
随着互联网技术的不断发展,爬虫(web crawler)已经成为当前最热门的爬取信息方式之一。通过爬虫技术,我们可以轻松地获取互联网上的数据,并用于数据分析、挖掘、建模等多个领域。而javascript语言则因其强大的前端开发工…...

Leetcode 3203. Find Minimum Diameter After Merging Two Trees
Leetcode 3203. Find Minimum Diameter After Merging Two Trees 1. 解题思路2. 代码实现 题目链接:3203. Find Minimum Diameter After Merging Two Trees 1. 解题思路 这一题的话算是一个拓扑树的题目?总之就是从树的叶子节点不断向上遍历ÿ…...
:循环群的两道例题)
【抽代复习笔记】24-群(十八):循环群的两道例题
例1:证明: (1)三次交错群A3是循环群,它与(Z3,)同构,其中Z3 {[0],[1],[2]}; (2)G {1,i,-1,-i},G上的代数运算是数的乘法,则G是一个循环群&…...

Linux常见操作问题
1、登录刚创建的用户,无法操作。 注:etc/passwd文件是Linux操作系统中存储用户账户信息的文本文件,包含了系统中所有用户的基本信息,比如用户名、用户ID、用户组ID、用户家目录路径。 注:etc: 这个目录存放所有的系统…...

鲁工小装载机-前后桥传动轴油封更换记录
鲁工装载机 因前后桥大量漏齿轮油,故拆开查看、更换油封 一: 如图圈起来的地方是螺丝和钢板相别,用200的焊接电流用电焊机点开一个豁口后拆除螺丝。 转轴是拆除传动轴后的样子。 这就是拆下来的样子,这玩意插上边那图&…...

商城自动化测试实战 —— 登录+滑块验证
hello大家好,我是你们的小编! 本商城测试项目采取PO模型和数据分离式架构,采用pytestseleniumjenkins结合的方式进行脚本编写与运行,项目架构如下: 1、创建项目名称:code_shopping,创建所需项目…...

8.计算机视觉—增广和迁移
目录 1.数据增广数据增强数据增强的操作代码实现2.微调 迁移学习 Transfer learning(重要的技术)网络结构微调:当目标数据集比源数据集小得多时,微调有助于提高模型的泛化能力。训练固定一些层总结代码实现1.数据增广 CES上的真实故事 有一家做智能售货机的公司,发现他们…...

【Matlab】-- BP反向传播算法
文章目录 文章目录 00 写在前面01 BP算法介绍02 基于Matlab的BP算法03 代码解释 00 写在前面 BP算法可以结合鲸鱼算法、飞蛾扑火算法、粒子群算法、灰狼算法、蝙蝠算法等等各种优化算法一起,进行回归预测或者分类预测。 01 BP算法介绍 BP(Backpropag…...

【Python】 数据分析中的常见统计量:众数
那年夏天我和你躲在 这一大片宁静的海 直到后来我们都还在 对这个世界充满期待 今年冬天你已经不在 我的心空出了一块 很高兴遇见你 让我终究明白 回忆比真实精彩 🎵 王心凌《那年夏天宁静的海》 众数(Mode)是统计学中另…...

Karabiner-Elements 设置mac键盘
软件下载地址: Karabiner-Elements 修改键盘位置,但是重启后,就消失了。 {"description": "New Rule (change left_shiftcaps_lock to page_down, right_shiftcaps_lock to left_commandmission_control)","manip…...

Mybatis实现流程
一,UserDAO 接口定义 首先,定义 UserDAO接口,包含 getList()方法,定义类型为List<User>: package dao;import model.User; import java.util.List;public interface UserDAO {List<User> getList(); }二,…...
)
简单的springboot整合activiti5-serviceImpl部分(1)
简单的springboot整合activiti5.22.0-serviceImpl部分(1) 原来的流程serviceImpl部分代码过多,所以此处单独记录一下,此处记录的是serviceImpl第一部分代码 package cn.git.workflow.service.impl;import cn.git.cache.api.BaseCacheApi; import cn.gi…...

snat、dnat和firewalld
目录 概述 SNAT源地址转换 DANT目的地址转换 抓包 firewalld 端口管理 概述 snat :源地址转换 内网——外网 内网ip转换成可以访问外网的ip 也就是内网的多个主机可以只有一个有效的公网ip地址访问外部网络 DNAT:目的地址转发 外部用户&#…...

[数据集][目标检测]鸡蛋缺陷检测数据集VOC+YOLO格式2918张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2918 标注数量(xml文件个数):2918 标注数量(txt文件个数):2918 标注…...

前后端防重复提交
数据重复提交是一个大忌,会带来无效数据,应该在前端和后端都建议检测防范。 前端一般是按钮按下触发数据提交,如果用户鼠标操作习惯不好,或者鼠标或系统设置问题会导致鼠标连击,如果前端不做相关处理,可能会…...
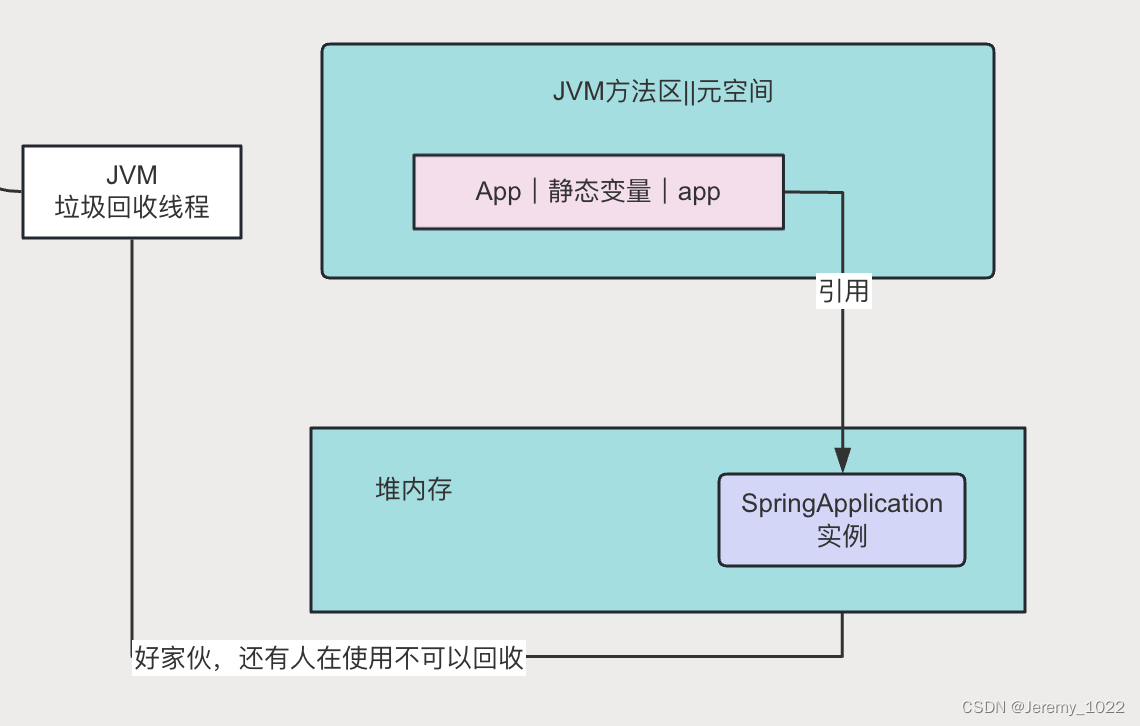
JVM专题八:JVM如何判断可回收对象
在JVM专题七:JVM垃圾回收机制中提到JVM的垃圾回收机制是一个自动化的后台进程,它通过周期性地检查和回收不可达的对象(垃圾),帮助管理内存资源,确保应用程序的高效运行。今天就让我们来看看JVM到底是怎么定…...

binary_cross_entropy_with_logits函数的参数设定
binary_cross_entropy_with_logits 该函数参数: logits (Tensor) - 输入预测值。其数据类型为float16或float32。 label (Tensor) - 输入目标值,shape与 logits 相同。数据类型为float16或float32。 weight (Tensor,可选) - 指定每个批次二…...

Python 面试【★★★★★】
欢迎莅临我的博客 💝💝💝,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

C# StringBuilder
以下是一些基本的 StringBuilder 使用方法:创建 StringBuilder 实例:追加字符串:插入字符串:删除字符串:替换字符串:清空 StringBuilder:转换 StringBuilder 为字符串:使用容量&…...
4个文章生成器免费版分享,让文章创作更轻松便捷
在当今这个信息飞速传播的时代,文章创作的重要性愈发凸显。无论是从事内容创作的专业人士,还是偶尔需要撰写文章的普通大众,都希望能更高效地完成文章创作任务。而在实际操作中,我们常常会遇到思路卡顿、没有创作灵感的问题。今天…...

从MHC到MCC:PIC32项目迁移实战指南与问题排查
1. 项目概述:从MHC到MCC的迁移之路如果你是一位长期使用Microchip PIC32系列微控制器的嵌入式开发者,那么“MPLAB Harmony配置器(MHC)”这个名字你一定不陌生。它曾经是Harmony框架下图形化配置工具的核心,帮助我们快速…...
动态适配(含开源声学适配器))
维吾尔语AI语音最后一公里难题:ElevenLabs+Kaldi联合方案实现方言变体(伊犁/喀什/和田)动态适配(含开源声学适配器)
更多请点击: https://intelliparadigm.com 第一章:维吾尔语AI语音最后一公里难题的本质剖析 维吾尔语AI语音系统在实验室环境中已能实现较高识别准确率,但落地至真实场景时仍面临显著性能衰减——这一“最后一公里”并非技术迭代的自然延迟&…...
)
GPT-Image 2 对标竞争者研发?——理性看待“对手传闻”的技术路径(2026 观察)
深度观察:OpenAI 是否在暗中加速 GPT-Image 2 对标竞争者研发?——理性看待“对手传闻”的技术路径(2026 观察)“竞争对手是否在秘密被研发?”“OpenAI 背后是不是在悄悄做某种 GPT-Image 2 的替代方案?”这…...

Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析
Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析 【免费下载链接】webdav-provider An Android app that can expose WebDAV storage to other apps through Androids Storage Access Framework (SAF) 项目地址: https://gitcode.com/gh_mirrors/we/we…...

Spectator:云原生可观测性数据采集库的设计与实战
1. 项目概述:从“观众”到“洞察者”的转变在分布式系统和微服务架构成为主流的今天,我们每天面对的不再是单一的、庞大的单体应用,而是由数十甚至上百个服务节点组成的复杂网络。每个服务都在持续地产生日志、指标和追踪数据,这些…...

QtScrcpy:将手机屏幕变成电脑扩展屏的终极解决方案
QtScrcpy:将手机屏幕变成电脑扩展屏的终极解决方案 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy …...

基于大语言模型的智能购物助手:从架构设计到工程实现
1. 项目概述:当AI遇上电商,一个“懂你”的购物助手如何炼成最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“KudoAI/amazongpt”。光看名字,你大概能猜到它和亚马逊(Amazon)以及GPT有关。没…...

SAP屏幕导航:从SET到LEAVE,实战解析六大跳转策略
1. SAP屏幕导航的核心逻辑 在SAP ABAP开发中,屏幕导航就像是在迷宫中寻找出口。想象你手里有六把不同的钥匙(六种跳转策略),每把钥匙对应不同的门锁(业务场景)。选错钥匙要么打不开门,要么可能把…...

装机解惑:Bios中的Secure Boot与CSM,为何相爱相杀?
1. Secure Boot与CSM:现代PC的引导之争 刚装好的新电脑突然黑屏,这种经历估计不少DIY玩家都遇到过。上周我就帮朋友处理了这么个案例:他为了省钱继续用老显卡GTX650ti,结果在新配的13代酷睿主机上死活点不亮屏幕。这背后其实是UEF…...
)
别再死记PRBS7/15了!用Python+NumPy手搓一个可配置的PRBS码生成器(附完整代码)
用Python构建可配置PRBS生成器:从LFSR原理到信号仿真实战 在数字通信和高速电路设计中,工程师们经常需要生成特定的测试信号来验证系统性能。伪随机二进制序列(PRBS)因其近似真实数据流的特性,成为信号完整性测试的黄金…...