昇思25天学习打卡营第7天|网络构建
昇思25天学习打卡营第7天|网络构建
- 前言
- 函数式自动微分
- 函数与计算图
- 微分函数与梯度计算
- Stop Gradient
- Auxiliary data
- 神经网络梯度计算
- 个人任务打卡(读者请忽略)
- 个人理解与总结
前言
非常感谢华为昇思大模型平台和CSDN邀请体验昇思大模型!从今天起,笔者将以打卡的方式,将原文搬运和个人思考结合,分享25天的学习内容与成果。为了提升文章质量和阅读体验,笔者会将思考部分放在最后,供大家探索讨论。同时也欢迎各位领取算力,免费体验昇思大模型!
函数式自动微分
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。下面我们使用一个简单的单层线性变换模型进行介绍。
%%capture captured_output
# 实验环境已经预装了mindspore==2.3.0rc1,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.3.0rc1
import numpy as np
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor, Parameter
函数与计算图
计算图是用图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。

在这个模型中, x x x为输入, y y y为正确值, w w w和 b b b是我们需要优化的参数。
x = ops.ones(5, mindspore.float32) # input tensor, 生成5*5的全1矩阵,其元素类型均为float32
y = ops.zeros(3, mindspore.float32) # expected output,生成3*3的全0矩阵,其元素类型均为float32
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # weight, 生成5*3的随机矩阵,其元素类型均为float32
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # bias,生成3*1的随机矩阵,其元素类型均为float32
我们根据计算图描述的计算过程,构造计算函数。
其中,binary_cross_entropy_with_logits 是一个损失函数,计算预测值和目标值之间的二值交叉熵损失。
def function(x, y, w, b):z = ops.matmul(x, w) + b #z=x矩阵相乘w + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))#使用二值交叉熵损失计算z和y之间的损失return loss
执行计算函数,可以获得计算的loss值。
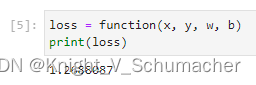
loss = function(x, y, w, b)
print(loss)
微分函数与梯度计算
为了优化模型参数,需要求参数对loss的导数: ∂ loss ∂ w \frac{\partial \operatorname{loss}}{\partial w} ∂w∂loss和 ∂ loss ∂ b \frac{\partial \operatorname{loss}}{\partial b} ∂b∂loss,此时我们调用mindspore.grad函数,来获得function的微分函数。
这里使用了grad函数的两个入参,分别为:
fn:待求导的函数。grad_position:指定求导输入位置的索引。
由于我们对 w w w和 b b b求导,因此配置其在function入参对应的位置(2, 3)。
使用
grad获得微分函数是一种函数变换,即输入为函数,输出也为函数。
grad_fn = mindspore.grad(function, (2, 3))#计算待求导的函数中w和b的梯度值
执行微分函数,即可获得 w w w、 b b b对应的梯度。
grads = grad_fn(x, y, w, b)
print(grads)

Stop Gradient
通常情况下,求导时会求loss对参数的导数,因此函数的输出只有loss一项。当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
这里我们将function改为同时输出loss和z的function_with_logits,获得微分函数并执行。
def function_with_logits(x, y, w, b):z = ops.matmul(x, w) + b #z=x矩阵相乘w + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))#使用二值交叉熵损失计算z和y之间的损失return loss, z
grad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)

可以看到求得 w w w、 b b b对应的梯度值发生了变化。此时如果想要屏蔽掉z对梯度的影响,即仍只求参数对loss的导数,可以使用ops.stop_gradient接口,将梯度在此处截断。我们将function实现加入stop_gradient,并执行。
def function_stop_gradient(x, y, w, b):z = ops.matmul(x, w) + b #z=x矩阵相乘w + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))#使用二值交叉熵损失计算z和y之间的损失return loss, ops.stop_gradient(z)
grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)

可以看到,求得 w w w、 b b b对应的梯度值与初始function求得的梯度值一致。
Auxiliary data
Auxiliary data意为辅助数据,是函数除第一个输出项外的其他输出。通常我们会将函数的loss设置为函数的第一个输出,其他的输出即为辅助数据。
grad和value_and_grad提供has_aux参数,当其设置为True时,可以自动实现前文手动添加stop_gradient的功能,满足返回辅助数据的同时不影响梯度计算的效果。
下面仍使用function_with_logits,配置has_aux=True,并执行。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)
grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)

可以看到,求得 w w w、 b b b对应的梯度值与初始function求得的梯度值一致,同时z能够作为微分函数的输出返回。
神经网络梯度计算
前述章节主要根据计算图对应的函数介绍了MindSpore的函数式自动微分,但我们的神经网络构造是继承自面向对象编程范式的nn.Cell。接下来我们通过Cell构造同样的神经网络,利用函数式自动微分来实现反向传播。
首先我们继承nn.Cell构造单层线性变换神经网络。这里我们直接使用前文的 w w w、 b b b作为模型参数,使用mindspore.Parameter进行包装后,作为内部属性,并在construct内实现相同的Tensor操作。
# Define model
class Network(nn.Cell):def __init__(self):super().__init__()self.w = wself.b = bdef construct(self, x):z = ops.matmul(x, self.w) + self.b #z=x矩阵相乘w + breturn z
接下来我们实例化模型和损失函数。
# Instantiate model
model = Network() #实例化模型
# Instantiate loss function
loss_fn = nn.BCEWithLogitsLoss() #计算二元交叉熵损失函数
完成后,由于需要使用函数式自动微分,需要将神经网络和损失函数的调用封装为一个前向计算函数。
# Define forward function
def forward_fn(x, y):# 定义前向推理z = model(x)loss = loss_fn(z, y)return loss
完成后,我们使用value_and_grad接口获得微分函数,用于计算梯度。
由于使用Cell封装神经网络模型,模型参数为Cell的内部属性,此时我们不需要使用grad_position指定对函数输入求导,因此将其配置为None。对模型参数求导时,我们使用weights参数,使用model.trainable_params()方法从Cell中取出可以求导的参数。
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())#获得微分函数,从cell取出可以求导的参数
loss, grads = grad_fn(x, y)
print(grads)

执行微分函数,可以看到梯度值和前文function求得的梯度值一致。
个人任务打卡(读者请忽略)

个人理解与总结
本章节主要介绍了昇思大模型中函数式自动微分的主要功能,包括函数与计算图、微分函数与梯度计算、停止梯度计算(Stop Gradient)、辅助数据(Auxiliary data)和神经网络梯度计算及它们对搭建深度神经网络模型的作用。该章节通过搭建简单的深度学习模型(y=w*x+b),通过计算预测值和目标值之间的二值交叉熵损失计算loss;使用mindspore.grad计算梯度,使用ops.stop_gradient停止梯度计算,最后使用Cell搭建深度神经网络,使用model.trainable_params()计算可求导的参数。综上所述,昇思大模型为深度神经网络中梯度和损失的计算提供了基础且便捷的解决方案。
相关文章:
昇思25天学习打卡营第7天|网络构建
昇思25天学习打卡营第7天|网络构建 前言函数式自动微分函数与计算图微分函数与梯度计算Stop GradientAuxiliary data神经网络梯度计算 个人任务打卡(读者请忽略)个人理解与总结 前言 非常感谢华为昇思大模型平台和CSDN邀请体验昇思大模型!从今…...
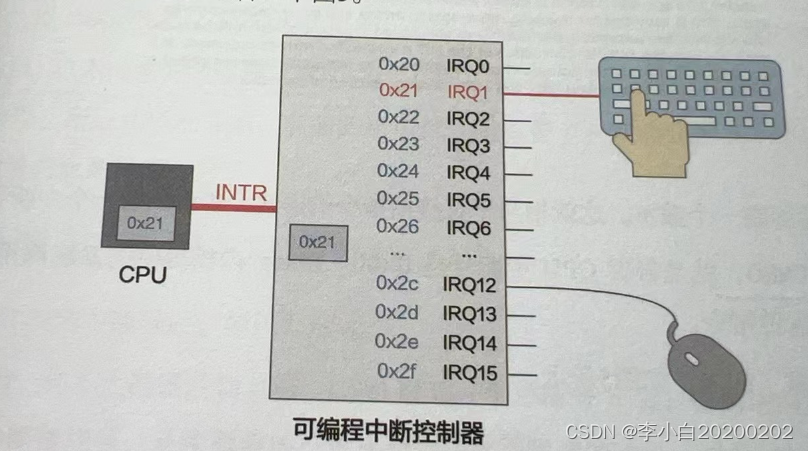
扩展阅读:什么是中断
如果用一句话概括操作系统的原理,那就是:整个操作系统就是一个中断驱动的死循环,用最简单的代码解释如下: while(true){doNothing(); } 其他所有事情都是由操作系统提前注册的中断机制和其对应的中断处理函数完成的。我们点击一下鼠标,敲击一下键盘,执行一个程序,…...

git 命令学习之branch 和 tag 操作
引言 在项目一个迭代过程结束之时,或是一个版本发布之后,我们要进行 新版本的开发,这时就需要对原来的项目代码进行封存,以及新项目代码的开始,这时就需要用到 branch 和 tag 操作。下面简单说说对这两个操作的理解。…...

如何理解 IEEE 754 单精度浮点型能表示的最小绝对值、最大绝对值
文章目录 解答最小绝对值最大绝对值总结 细节理解1. 为什么非规格化数的指数偏移量为126(而不是127)?规格化数与非规格化数非规格化数的指数偏移量非规格化数的尾数非规格化数的值示例 解答 IEEE 754单精度浮点数使用32位来表示一个数值&…...
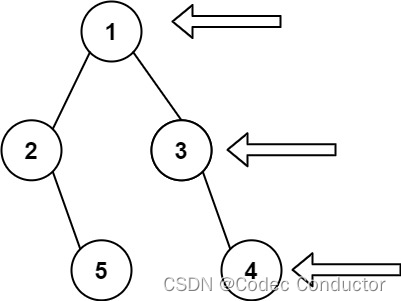
LeetCode 算法:二叉树的右视图 c++
原题链接🔗:二叉树的右视图 难度:中等⭐️⭐️ 题目 给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。 示例 1: 输入: [1,2,3,null,5,null,4…...

Java 并发编程常见问题
1、线程状态它们之间是如何扭转的? 1、谈谈对于多线程的理解? 1、对于多核CPU,多线程可以提升CPU的利用率; 2、对于多IO操作的程序,多线程可以提升系统的整体性能及吞吐量; 3、使用多线程在一些场景下可…...

网络基础:静态路由
静态路由是一种由网络管理员手动配置的路由方式,用于在网络设备(如路由器或交换机)之间传递数据包。与动态路由不同,静态路由不会根据网络状态的变化自动调整。 不同厂商的网络设备在静态路由的配置上有些许差异;下面…...
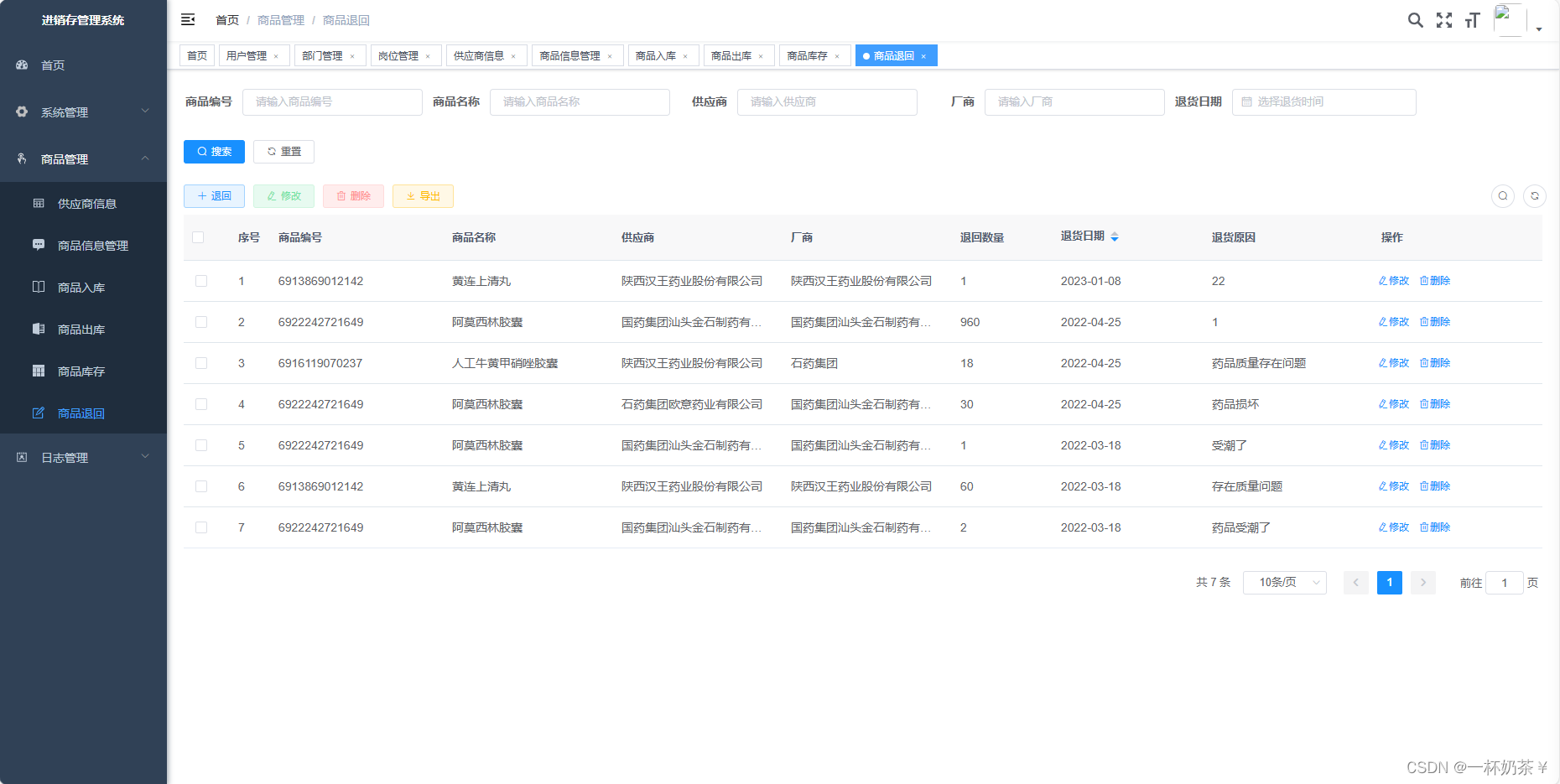
库存管理系统基于spingboot vue的前后端分离仓库库存管理系统java项目java课程设计java毕业设计
文章目录 库存管理系统一、项目演示二、项目介绍三、部分功能截图四、部分代码展示五、底部获取项目源码(9.9¥带走) 库存管理系统 一、项目演示 库存管理系统 二、项目介绍 基于spingboot和vue前后端分离的库存管理系统 功能模块ÿ…...
【ArcGIS AddIn插件】【可用于全国水旱灾害风险普查】全网最强洪水淹没分析插件-基于8邻域种子搜索算法-有源淹没分析算法
最近有很多GIS小伙伴咨询我关于基于8邻域种子搜索算法的有源淹没分析插件的使用方法及原理,咱们通过这篇文章给大家详细介绍下这款插件的运行机制。 一、插件类型及适用版本 本插件属于ArcGIS AddIn工具条插件,基于ArcGIS Engine10.2.2的开发环境开发的&…...
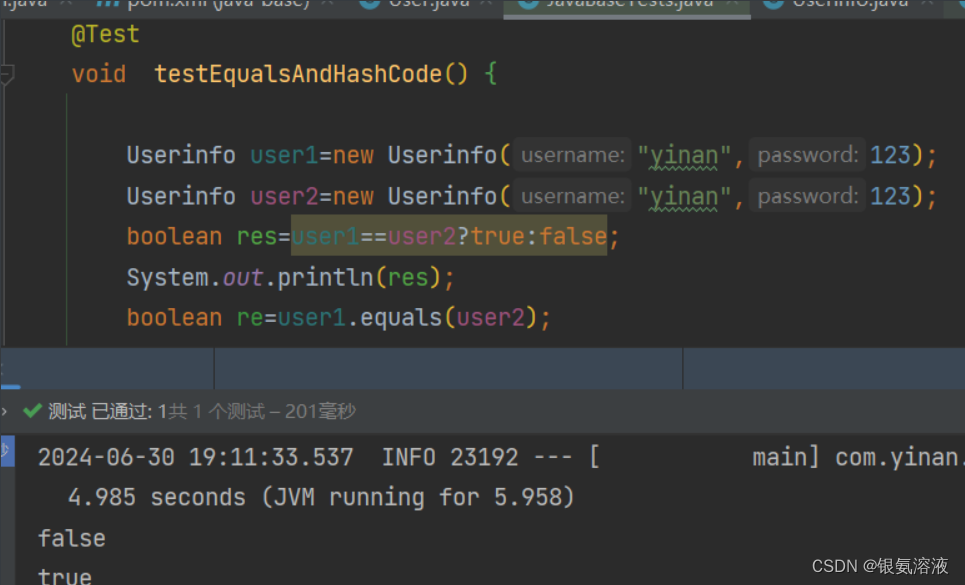
==和equals的区别(面试题)
和equals有什么区别 对于基本数据类型,比较的是值是否相等,对于引用类型则是比较的地址是否相等;对于equals来说,基本数据类型没有equals方法,对于引用类型equals比较的是引用对象是否相同 那针对以上结论,…...
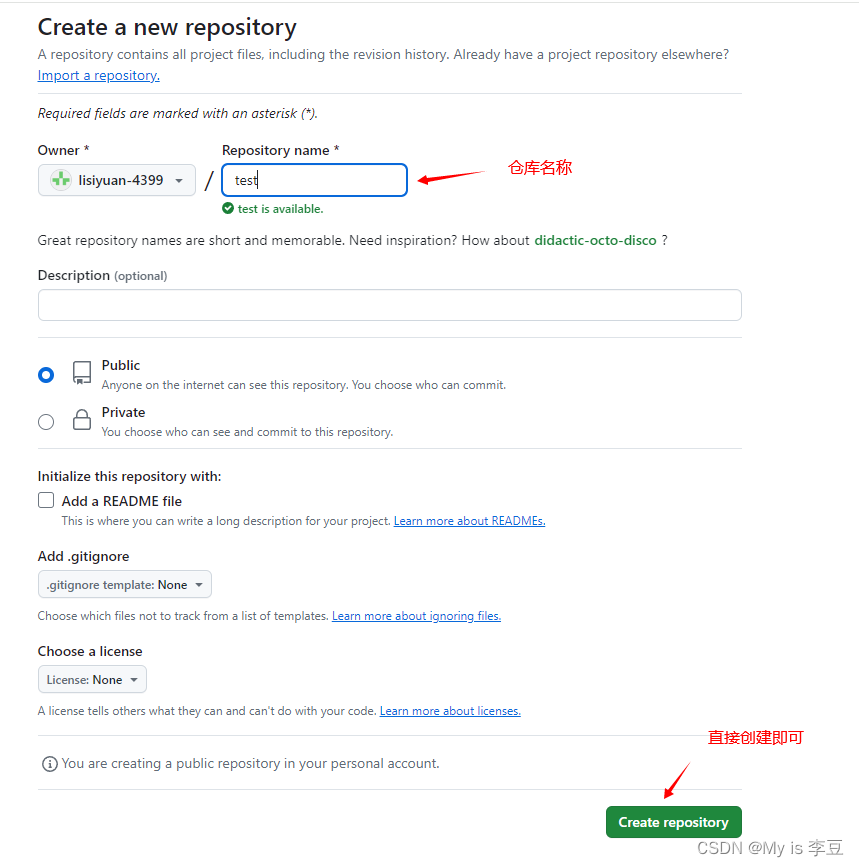
本地项目上传到GitHub上(李豆)
本地项目上传到GitHub上(李豆) 准备工作: 本地需要有 git 也需要有一个 GitHub 账号 首先需要在 GitHub 新建一个空仓库 在想要上传项目的文件夹中使用 Git 命令操作 初始化: git init与 github 仓库进行链接 :git remote add origin …...
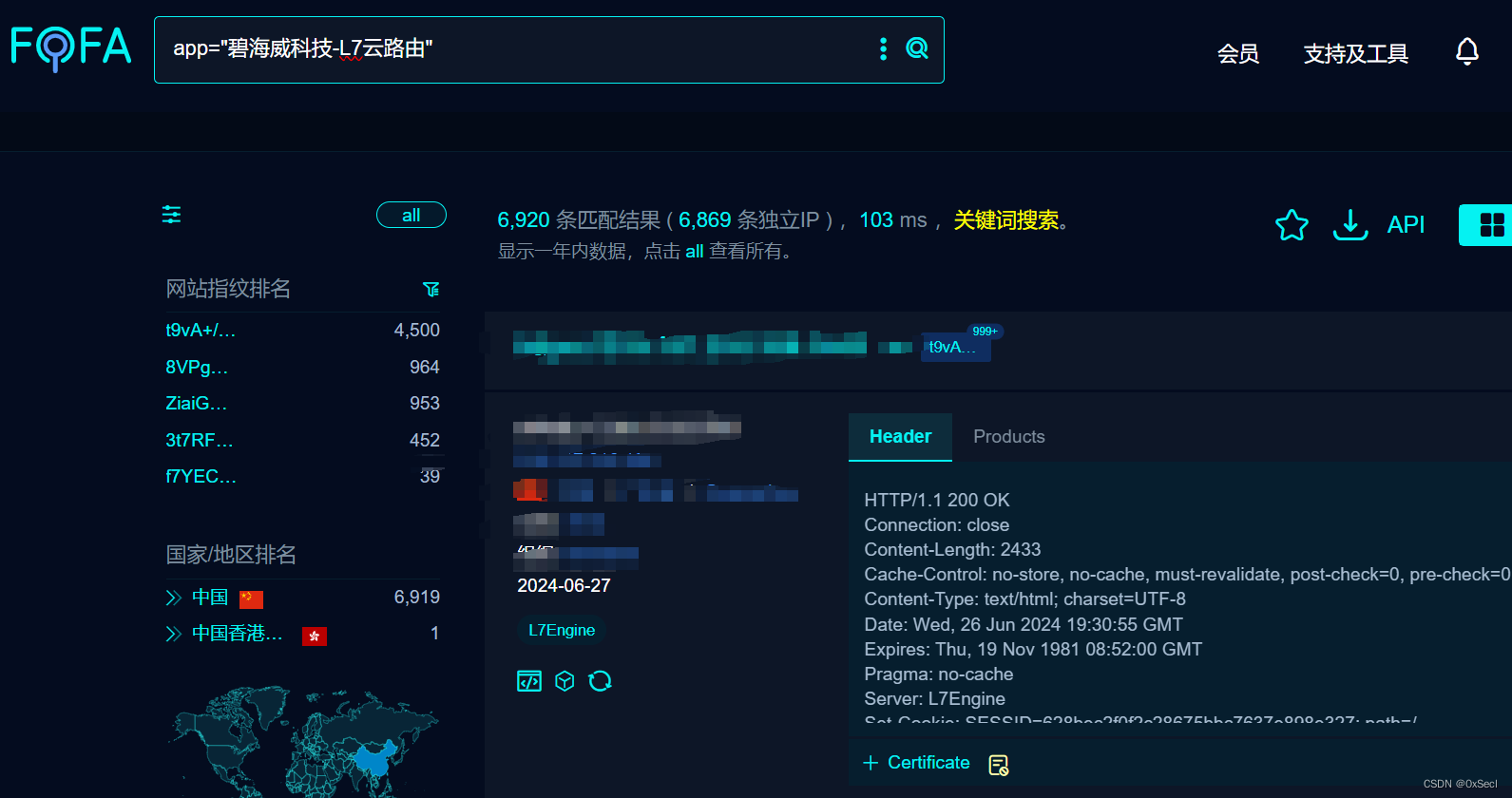
碧海威L7云路由无线运营版 confirm.php/jumper.php 命令注入漏洞复现(XVE-2024-15716)
0x01 产品简介 碧海威L7网络设备是 北京智慧云巅科技有限公司下的产品,基于国产化ARM硬件平台,采用软硬一体协同设计方案,释放出产品最大效能,具有高性能,高扩展,产品性能强劲,具备万兆吞吐能力,支持上万用户同时在线等高性能。其采用简单清晰的可视化WEB管理界面,支持…...
redis实战-添加商户缓存
为什么要使用缓存 言简意赅:速度快,好用缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低用户访问并发量带来的服务器读写压力实际开发中,企业的数据量,少…...

SQL游标的基本使用方法与示例
SQL游标的基本使用方法与示例 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们来探讨SQL游标的基本使用方法及示例。在数据库编程中,游标是一…...

还不知道工业以太网和现场总线区别???
工业以太网 工业以太网是一种专为工业环境设计的网络通信技术,它基于标准的以太网技术,但针对工业应用进行了优化。工业以太网能够适应高温、低温、防尘等恶劣工业环境,采用TCP/IP协议,与IEEE 802.3标准兼容,并在应用层…...
量化交易 - 策略回测
策略回测 1、什么是策略回测?2、策略回测的作用3、策略回测系统概述3.1策略回测中相关的指标介绍3.2量化交易策略的资金容量3.3 完整的策略回测系统包含哪些内容 1、什么是策略回测? 策略回测,也称之为策略回溯测试,是指利用交易…...

Java--选择排序
思想 从左向右遍历数组,让每个数组元素依次作为基准,将基准数组扫描一次,若有元素比基准小则标记这个元素,若后续元素存在比此元素更小的,则标记更小的元素,遍历完此次数组之后,交换基准和标记数…...

Python基础之模块和包
文章目录 1 模块和包1.1 模块和包1.1.1 模块1.1.2 包1.1.3 简单使用 1.2 import 语句1.2.1 import1.2.2 from … import 语句1.2.3 from … import * 语句 1.4 深入模块1.4.1 模块符号表1.4.2 __name__属性1.4.3 dir() 函数1.4.4 作用域 1.5 常用内置模块 1 模块和包 1.1 模块…...
基于SpringBoot漫画网站系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,…...

Mysql----表的约束
提示:以下是本篇文章正文内容,下面案例可供参考 一、表的约束 表的约束:表中一定要有约束,通过约束让插入表中的数据是符合预期的。它的本质是通过技术手段,让程序员插入正确的数据,约束的最终目标是保证…...
-virtual sequence实战:中断与异常场景构建)
I2C虚拟项目笔记(二)-virtual sequence实战:中断与异常场景构建
1. 为什么需要模拟中断与异常场景? 在实际的I2C总线通信中,各种异常情况时有发生。比如从设备突然掉电导致无应答(NACK),或者主设备在发送数据时遭遇干扰导致传输中断。这些场景如果不在验证阶段充分覆盖,…...

【knife4j】接口分组配置;登录拦截器放行;登录拦截器配置token;给全局异常处理类添加注解;解决上传文件不显示文件域;参数扁平化;@Parameter
Parameter Parameter 是用来为 API 接口参数添加元数据(描述信息)的注解,这些信息最终会生成到 OpenAPI 规范的文档中,供 Knife4j/Swagger UI 等工具展示 简单来说:它让 API 的使用者能清楚地知道每个参数的含义、是…...

153.YOLOv8 从数据集下载到 ONNX 部署
摘要 目标检测是计算机视觉领域的核心任务之一,YOLO系列算法凭借其单阶段检测架构和实时推理能力,成为工业界部署的首选方案。本文从零开始,系统讲解YOLOv8的完整使用流程,涵盖环境搭建、数据集构建、模型训练、评估与部署全链路。所有代码均基于Ultralytics官方库,提供可…...

2025届最火的十大AI写作平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在这个信息呈现爆炸态势的时代当中,内容创作已然变成了个人以及企业所具备的核心…...

百度网盘Mac版终极加速方案:免费解锁SVIP级下载体验
百度网盘Mac版终极加速方案:免费解锁SVIP级下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的蜗牛下载速度而烦…...

基于Circuit Playground Express与MakeCode的互动拳套制作指南
1. 项目概述与核心思路如果你和我一样,既是《宇宙小子》的粉丝,又对把动画里的酷炫装备带到现实世界充满兴趣,那这个项目绝对能让你玩上一整天。今天要做的,是主角之一石榴那对标志性的拳套——不过,我们给它加上了一点…...

心智网络与图神经网络:从Awesome清单到脑科学AI实战
1. 项目概述:当“心智网络”遇见“Awesome”清单如果你对认知科学、人工智能的交叉领域感兴趣,或者正在寻找一个能帮你快速切入“心智网络”研究的导航图,那么你很可能已经听说过或正在寻找mind-network/Awesome-Mind-Network这个项目。简单来…...
)
STM32F407驱动0.96寸OLED屏:除了SPI,你还可以试试这几种通信方式(I2C/8080对比)
STM32F407驱动0.96寸OLED屏:SPI、I2C与8080接口的深度技术选型指南 当你在STM32F407VET6核心板上连接0.96寸OLED模块时,第一个技术决策往往就是通信接口的选择。这个看似简单的选择实际上会影响整个项目的硬件设计复杂度、软件维护成本以及最终显示性能。…...

VSCode调试STM32实战:解决Cortex-Debug插件配置JLink/OpenOCD时最常见的5个报错
VSCode调试STM32实战:破解Cortex-Debug插件五大经典报错 当你在深夜赶工STM32项目,按下F5期待调试器顺利启动时,终端却弹出鲜红的错误信息——这种挫败感每个嵌入式开发者都深有体会。本文不重复那些基础配置教程,而是直击VSCode…...

避开4D毫米波雷达性能坑:详解AWR2243天线通道失配原因与校准策略
避开4D毫米波雷达性能坑:详解AWR2243天线通道失配原因与校准策略 在自动驾驶与高级驾驶辅助系统(ADAS)领域,4D毫米波雷达正逐渐成为环境感知的核心传感器。德州仪器(TI)的AWR2243级联方案凭借其192个虚拟通…...