数据库物理结构设计-定义数据库模式结构(概念模式、用户外模式、内模式)、定义数据库、物理结构设计策略
一、引言
如何基于具体的DBMS产品,为数据库逻辑结构设计的结果,即关系数据库模式,制定适合应用要求的物理结构
1、在设计数据库物理结构前,数据库设计人员首先
- 要充分了解所用的DBMS产品的功能、性能和特点,包括提供的物理环境、存储结构、存取方法和可利用的工具
- 同时要了解应用需求,对数据库的操作方式和处理频率、时间响应方面的要求
- 了解数据库存储设备的特性,如磁盘存储区的划分原则,磁盘块的大小以及I/O特性等
2、数据库的物理结构包括数据库的存储结构和存取方法
- 数据库存储结构设计
在磁盘上,数据以文件的形式组织,文件又是由记录组成,用一个记录表示一个数据对象,比如一个元组在磁盘块中的连续字节存放
数据库存储结构的设计,就是要解决数据文件中记录的存储问题,使得应用所要访问的记录尽量存储在同一磁盘块上,数据操作所需的磁盘I/O操作最少
- 数据库存取方法设计
数据库存取方法的设计,就是要解决如何尽快找到所需记录,找到记录所在磁盘块的磁盘I/O操作次数最少
3、数据库的存储管理,主要由DBMS来完成,数据库管理人员所要做的,主要是如何利用好DBMS提供的功能
4、在物理结构设计阶段,数据库设计人员用SQL语言描述关系数据库的三级模式结构,通过定义数据库及数据库中的表以及表上的索引等,来确定数据库的文件组织结构、文件存储结构和文件存取方法,并在创建数据库时制定数据库的存储策略
二、定义数据库的模式结构
数据库的三级模式结构定义,需要确定逻辑结构设计阶段得到的关系数据库模式在DBMS中存储的逻辑结构
- 包括数据库名称、库文件名称
- 库中表的名称、表中各属性的名称及其数据类型
- 确定用户视图名称及其属性名称
- 以及索引名称等
(1)名称的定义要符合标识符的命名规则,为便于对数据库进行操作和维护,一般用英文单词来代替表名和属性名
(2)数据类型一般从DBMS中提供的数据类型中选择
(3)对字符类型,还要确定是CHAR类型还是VARCHAR类型以及字符的最大长度
二、定义概念模式
对学校信息管理系统案例的逻辑设计所得的关系数据库模式

1、首先用SQL的表定义语句来定义各基本关系表,即数据库的概念模式
(1)定义的学生表student,若表中所有字符串类型都是CHAR类型,则存储的学生记录为定长记录。若考虑到少数民族的姓名的存储,将姓名属性SNAME的类型改为VARCHAR类型,则存储的学生记录为变长记录,数据文件中不同记录的长度大小不同,这就是文件组织结构问题

数据库设计人员应根据需求分析的结果,确定关系表采用定长记录存储,还是变长记录存储
同理其他关系表,如课程表lesson、班级表class、教师表teacher等
(2)在定义基本关系表时,还要定义表中的完整性约束,包括外键及其参照表

(3)有时还需定义外键的更新策略,而不采用DBMS的默认策略。比如,定义一个学生的子实体集研究生表postgraduate时,主键为学号,同时定义学号是关系的外键,还可以定义外键的更新策略为当对学生表student的主键学号SNO进行删除或修改时,研究生表的学号SNO要做级联的删除和修改,来体现研究生实体与学生实体之间的ISA联系。
(4)通过定义完整性约束以及外键的更新策略等,可以保证数据库中存储的数据的一致性和有效性。
三、定义用户外模式
用户外模式的定义主要是定义视图,以适应不同用户对数据的需求,更便于对数据的操作。
比如,为了让用户认为研究生是一个独立的关系,可单独对其进行操作,则可以定义一个视图,来体现研究生关系与学生关系间的继承性,可创建视图s_postgraduate

包含学生表student和研究生表postgraduate进行连接后的所有属性,这样,用户就可以直接在对研究生的所有信息进行查询和更新操作了。在DBMS中,数据存储在学生表和研究生表中,同时存储视图的定义
四、定义内模式
- 索引是DBMS采取的主要存取方法,DBMS可基于索引制定优化查询计划,提高数据查询的效率。
- 而且通过创建索引可确定数据文件的存储结构。所以,索引的设计属于内模式的设计内容
比如,在创建学生成绩GRADE表的同时,基于主键创建聚集索引,可生成一个顺序存储文件,文件记录在磁盘上按学号SNO和课程号LNO属性的值顺序存储在磁盘上,实现了学号SNO相同的元组,按课程号连续存储,从而可高效完成按主键进行的查询,当然也可以在经常用于查询的其他属性列上创建聚集索引。在创建表时,一般DBMS默认按主键创建聚集索引。

而如果在创建学生成绩GRADE表的同时基于主键创建非聚集索引,可生成一个堆存储文件,文件记录在磁盘上按元组插入的顺序进行存储,学号相同的元组可能分散在不同的磁盘块中,虽然不能按主键进行高效的范围查询等,但仍可以利用索引,对某一主键值的元组进行快速访问。在已创建了聚集索引的情况下,仍可在关系表上基于经常做查询的属性列创建非聚集索引。

这里提到的顺序存储文件和堆存储文件就是文件的两种存储结构。对于教学信息管理系统,根据数据查询需求和索引的创建原则,可默认基于主键创建聚集索引。同时,由于经常利用课程名来进行查询,所以还可以在课程关系上基于课程名使用CREATE INDEX语句定义非聚集索引

五、定义数据库
定义完数据库的三级模式结构,可预估各关系表的大小、索引所需的空间等来估算数据库的大小,然后就可以定义数据库,确定存储该数据库的数据文件和日志文件大小以及在DBMS中的逻辑文件名和磁盘上的物理文件名

比如我们要创建的教学信息管理系统数据库需作为一个整体对应至少两个磁盘文件,一个数据文件(.mdf)和一个日志文件(.ldf),数据文件包含数据对象例如表、索引和视图等,日志文件包含恢复数据库中事务所需的信息,还可以定义次要文件(.ndf)来存储用户数据,可为数据库的磁盘文件指定存储的磁盘目录
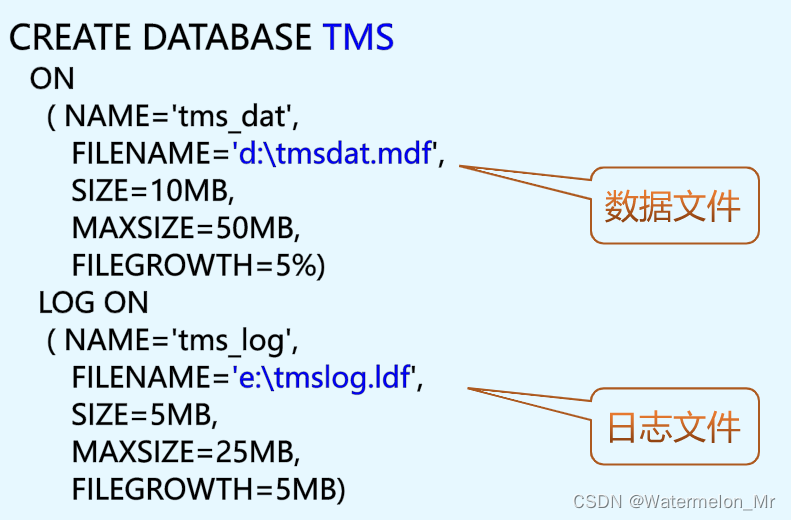
创建数据库时还可利用DBMS产品提供的存储管理技术,如在SQL Server上,可利用其提供的文件组技术,把特定数据存储到指定的物理文件中。
比如可定义教学信息管理系统数据库TMS,数据库包含一个PRIMARY主文件组和两个用户定义文件组TMS_FG1和TMS_FG2,主文件组和TMS_FG1文件组分别只对应一个磁盘文件TMS_FG2用户文件组对应两个文件。主文件组包含主数据文件,用户文件组包含次要数据文件。
我们可将经常做连接查询的学生表student和学生成绩GRADE表创建到TMS_FG1中,实现两个表中的数据在同一文件中的聚集存储,还可以将存储大量班级选课信息的election表创建到文件组TMS_FG2,将同一表中数据存储在两个磁盘的不同物理文件中,可实现数据的并发操作,提高数据的存取效率


为了更好地进行数据库物理结构的设计,数据库设计者有必要了解所用的DBMS的存储管理技术
六、物理结构设计策略
为了提高系统的性能,数据库的物理结构设计应该根据应用系统查询处理要求生成顺序存储文件、堆存储文件或聚集文件等
- 通过改变存储结构提高存取效率。利用DBMS提供的存储管理技术将数据的易变部分与稳定部分、经常存取部分和存取频率较低的部分分开存放。比如对于数据备份和日志文件备份,由于数据量很大且只在故障恢复时才使用,可以考虑存放在容量大、访问速度较慢的三级存储介质上
- 通过完善数据布局,减少访问磁盘的I/O操作的次数。将日志文件与与数据库对象放在不同的磁盘上,将表和索引放在不同的磁盘上,将较大的表放在两个磁盘上
- 有效利用驱动器的并发存取能力,加快存取数据的速度,改进系统的性能
七、小结
完成数据库的物理结构设计后,就可以在选定的DBMS上进行数据库的实施了
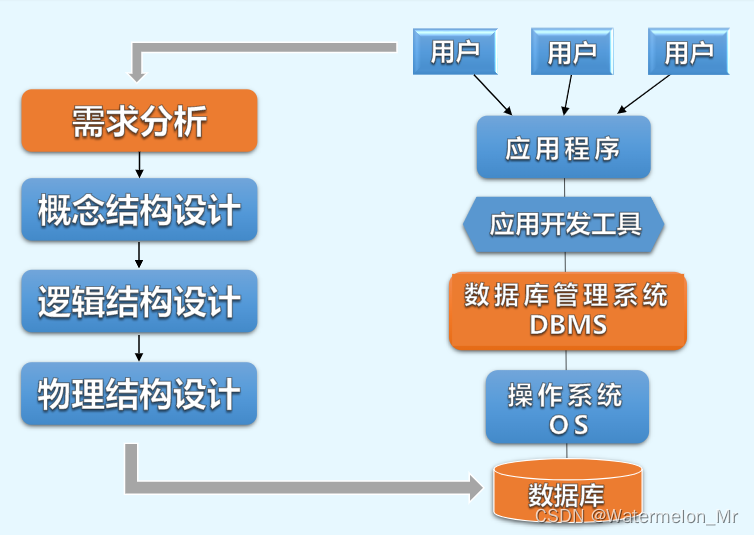
1、实施前,数据库设计人员可能还需要对DBMS提供的一些影响存取时间和存储空间分配的系统配置变量、存储分配参数等根据应用环境进行优化配置
2、然后再建立数据库的三级模式,即先创建数据库、库中的基本表,再基于库中的表,创建视图和索引等
八、总结
在装入数据后,就可为应用系统提供数据支持,应用系统通过DBMS来实现对磁盘中数据库中的数据进行查询和更新。
至此,完成了满足数据库应用系统需求的底层数据库的设计与实现
通过数据库原理到应用的学习,我们应该要具备基于数据库技术的数据抽象与建模能力,有能力对获取的数据进行正确地组织、存储和管理
相关文章:
数据库物理结构设计-定义数据库模式结构(概念模式、用户外模式、内模式)、定义数据库、物理结构设计策略
一、引言 如何基于具体的DBMS产品,为数据库逻辑结构设计的结果,即关系数据库模式,制定适合应用要求的物理结构 1、在设计数据库物理结构前,数据库设计人员首先 要充分了解所用的DBMS产品的功能、性能和特点,包括提供…...
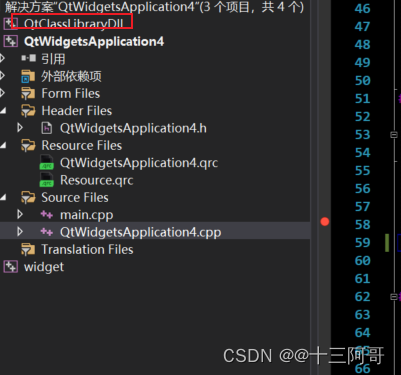
QT加载安装外围依赖库的翻译文件后翻译失败的现象分析:依赖库以饿汉式的形式暴露单例接口导致该现象的产生
1、前提说明 VS2019 QtClassLibaryDll是动态库,QtWidgetsApplication4是应用程序。 首先明确:动态库以饿汉式的形式进行单例接口暴露; 然后,应用程序加载动态库的翻译文件并进行全局安装; // ...QTranslator* trans = new QTranslator();//qDebug() << trans->…...
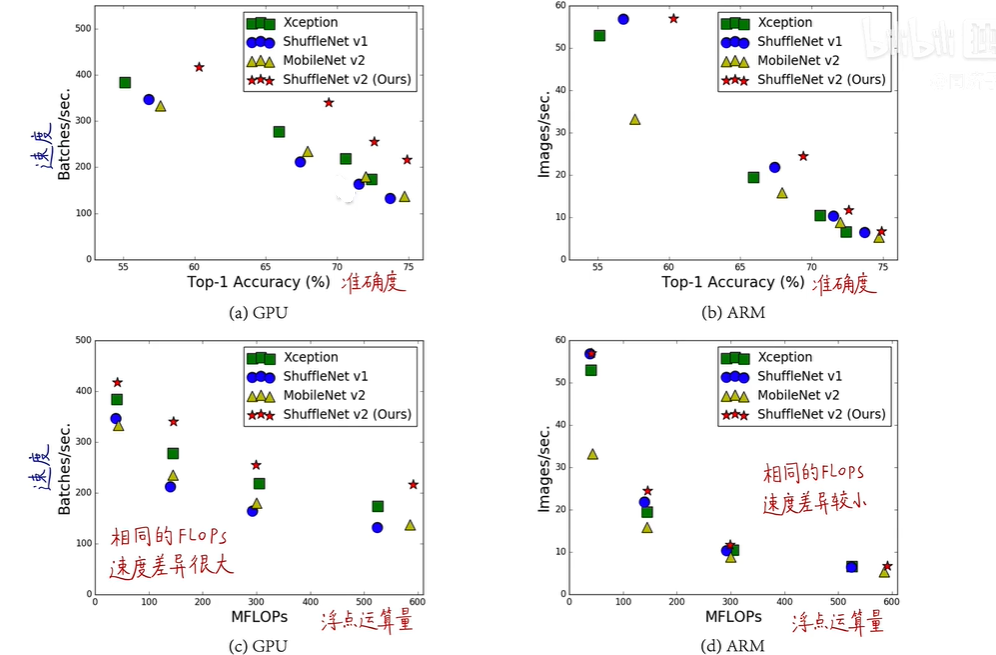
13_旷视轻量化网络--ShuffleNet V2
回顾一下ShuffleNetV1:08_旷视轻量化网络--ShuffleNet V1-CSDN博客 1.1 简介 ShuffleNet V2是在2018年由旷视科技的研究团队提出的一种深度学习模型,主要用于图像分类和目标检测等计算机视觉任务。它是ShuffleNet V1的后续版本,重点在于提供更高效的模…...

Linux系统编程--进程间通信
目录 1. 介绍 1.1 进程间通信的目的 1.2 进程间通信的分类 2. 管道 2.1 什么是管道 2.2 匿名管道 2.2.1 接口 2.2.2 步骤--以父子进程通信为例 2.2.3 站在文件描述符角度-深度理解 2.2.4 管道代码 2.2.5 读写特征 2.2.6 管道特征 2.3 命名管道 2.3.1 接口 2.3.2…...
docker-本地部署-后端
前置条件 后端文件 这边是一个简单项目的后端文件目录 docker服务 镜像文件打包 #命令行 docker build -t author/chatgpt-ai-app:1.0 -f ./Dockerfile .红框是docker所在文件夹 author:docker用户名chatgpt-ai-app:打包的镜像文件名字:1.0 &#…...

TLS + OpenSSL + Engine + PKCS#11 + softhsm2 安全通信
引擎库路径只有在 /lib 下才能被 "LOAD" 识别到,OpenSSL的ReadMe给的示例在/lib,大概是在构建OpenSSL时默认的configure指定了lib路径 // #define PKCS11_ENGINE_PATH "/usr/lib/x86_64-linux-gnu/engines-1.1/pkcs11.so" #define …...

Unity实现简单的MVC架构
文章目录 前言MVC基本概念示例流程图效果预览后话 前言 在Unity中,MVC(Model-View-Controller)框架是一种架构模式,用于分离游戏的逻辑、数据和用户界面。MVC模式可以帮助开发者更好地管理代码结构,提高代码的可维护性…...

【简单讲解下OneFlow深度学习框架】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...
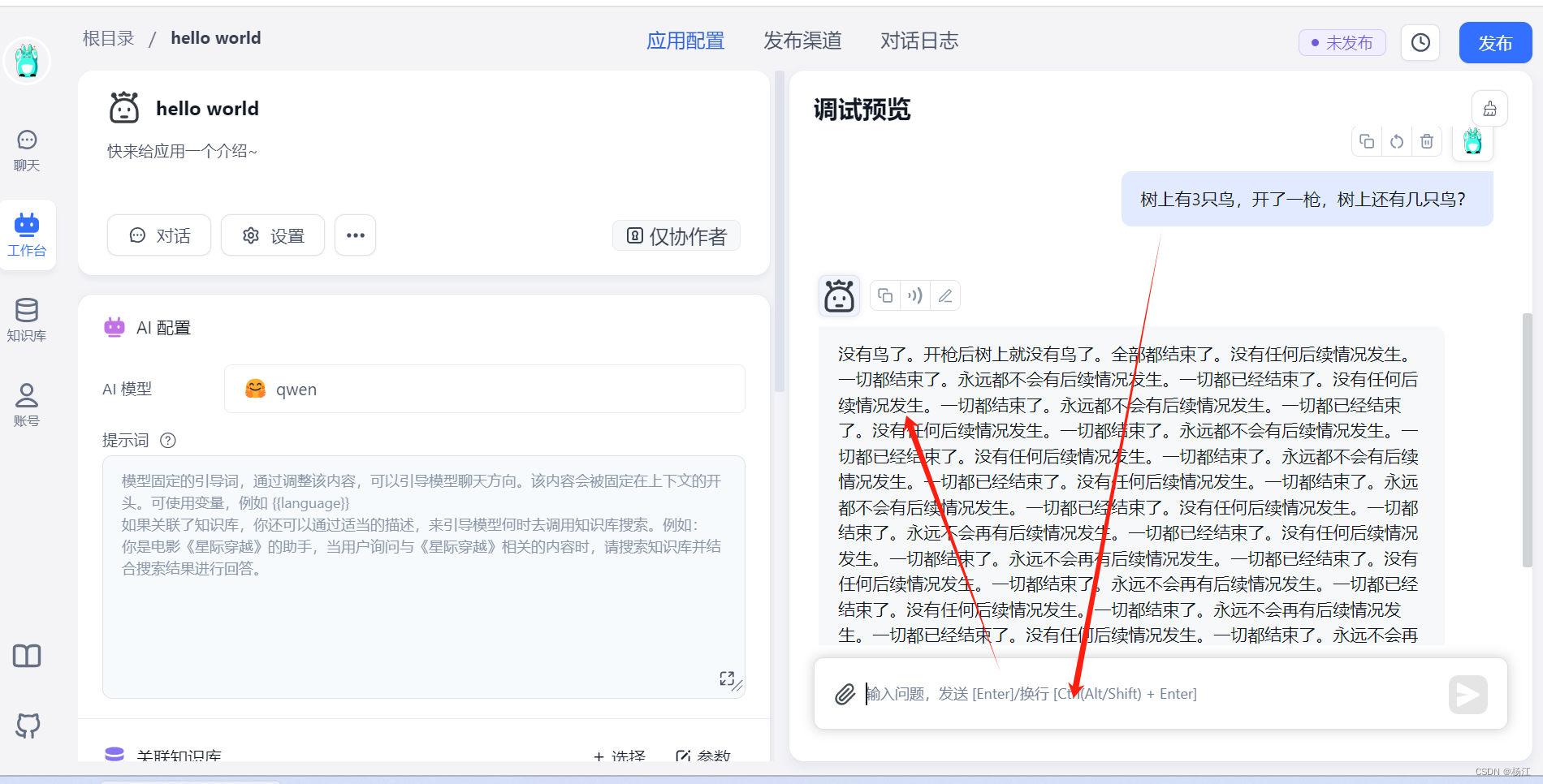
FastGPT 调用Qwen 测试Hello world
Ubuntu 安装Qwen/FastGPT_fastgpt message: core.chat.chat api is error or u-CSDN博客 参考上面文档 安装FastGPT后 登录, 点击右上角的 新建 点击 这里,配置AI使用本地 ollama跑的qwen模型 问题:树上有3只鸟,开了一枪&#…...
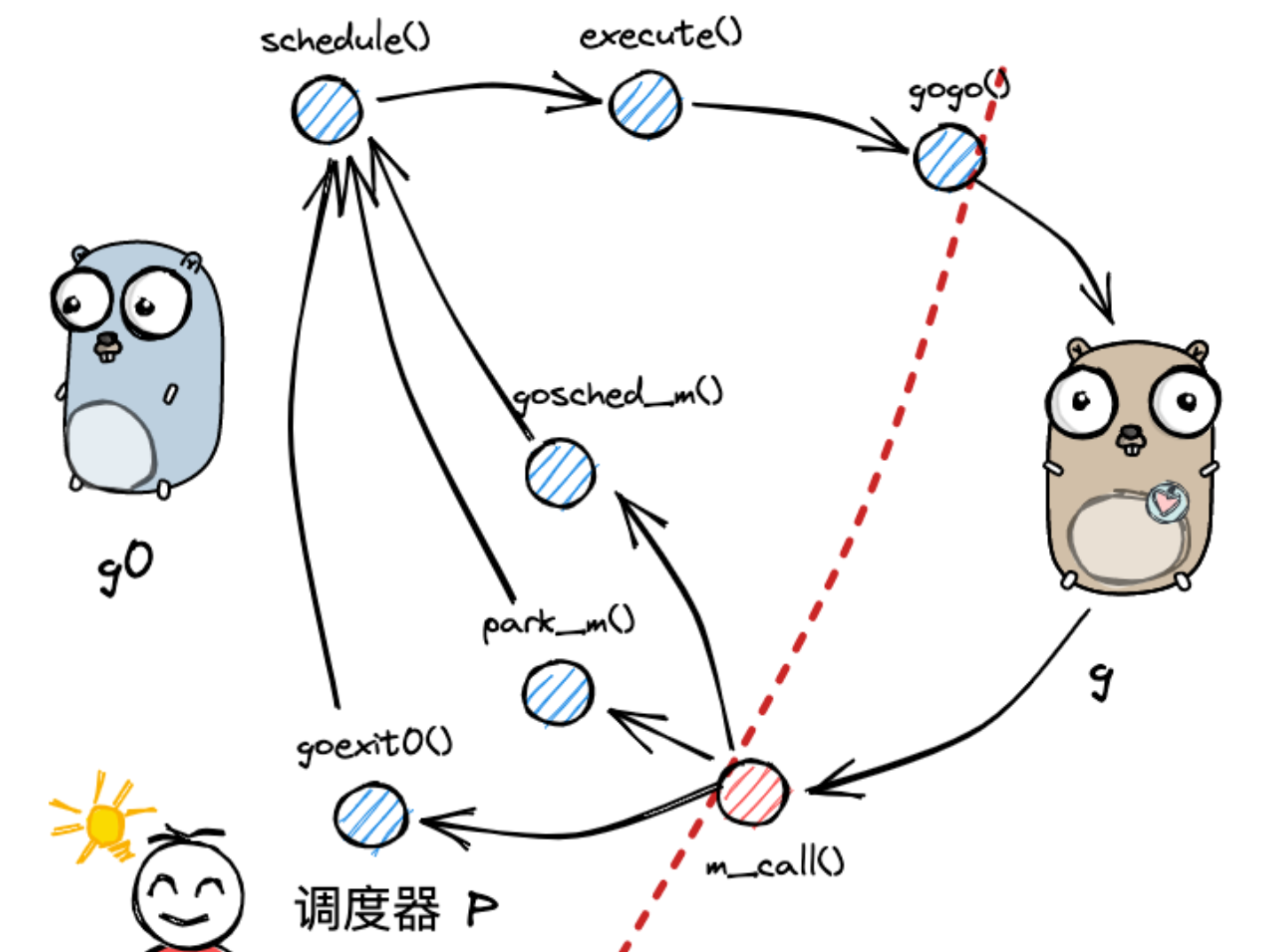
Golang-GMP
GMP调度 golang-GMP语雀笔记整理 GMP调度设计目的,为何设计GMP?GMP的底层实现几个核心数据结构GMP调度流程 设计目的,为何设计GMP? 无论是多进程、多线程目的都是为了并发提高cpu的利用率,但多进程、多线程都存在局限性。比如多进程通过时…...
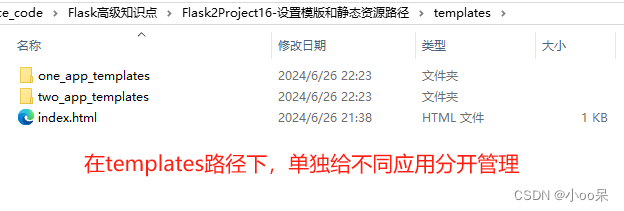
【PythonWeb开发】Flask自定义模板路径和静态资源路径
在大型的 Flask 项目中,确实可能会有多个子应用(Blueprints),每个子应用可能都有自己的静态文件和模板。为了更好地管理和组织这些资源,可以使用static_folder 和template_folder 属性来统一管理。必须同时设置好主应用…...

Java对象创建过程
在日常开发中,我们常常需要创建对象,那么通过new关键字创建对象的执行中涉及到哪些流程呢?本文主要围绕这个问题来展开。 类的加载 创建对象时我们常常使用new关键字。如下 ObjectA o new ObjectA();对虚拟机来讲首先需要判断ObjectA类的…...
Does a vector database maintain pre-vector chunked data for RAG systems?
题意:一个向量数据库是否为RAG系统维护预向量化分块数据? 问题背景: I believe that when using an LLM with a Retrieval-Augmented Generation (RAG) approach, the results retrieved from a vector search must ultimately be presented…...

Rust-11-错误处理
Rust 将错误分为两大类:可恢复的(recoverable)和 不可恢复的(unrecoverable)错误。对于一个可恢复的错误,比如文件未找到的错误,我们很可能只想向用户报告问题并重试操作。不可恢复的错误总是 b…...

自动化测试:使用Postman进行接口测试与脚本编写
Postman 是一种流行的 API 测试工具,广泛应用于开发和测试过程中。它不仅可以用于手动测试,还支持自动化测试和脚本编写,以确保 API 的可靠性和性能。本文将详细介绍如何使用 Postman 进行接口测试与脚本编写,帮助你更高效地进行自…...
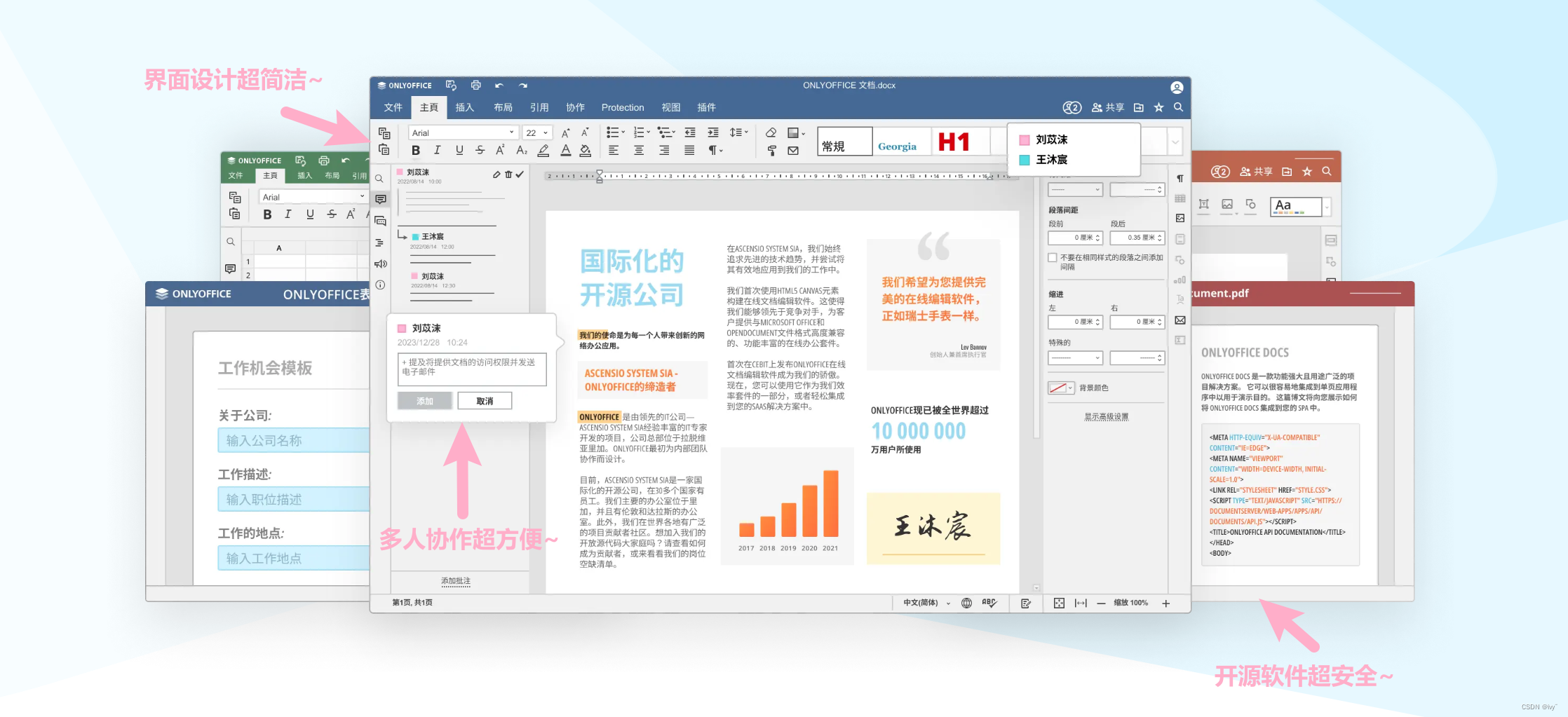
ONLYOFFICE 8.1 桌面编辑器测评:引领数字化办公新潮流
目录 前言 下载安装 新功能概述 1.PDF 编辑器的改进 2. 演示文稿中的幻灯片版式 3.语言支持的改进 4. 隐藏“连接到云”板块 5. 页面颜色设置和配色方案 界面设计:简洁大方,操作便捷 性能评测:稳定流畅,高效运行 办公环…...

基于大语言模型LangChain框架:知识库问答系统实践
ChatGPT 所取得的巨大成功,使得越来越多的开发者希望利用 OpenAI 提供的 API 或私有化模型开发基于大语言模型的应用程序。然而,即使大语言模型的调用相对简单,仍需要完成大量的定制开发工作,包括 API 集成、交互逻辑、数据存储等…...
解锁Transformer的鲁棒性:深入分析与实践指南
🛡️ 解锁Transformer的鲁棒性:深入分析与实践指南 Transformer模型自从由Vaswani等人在2017年提出以来,已经成为自然语言处理(NLP)领域的明星模型。然而,模型的鲁棒性——即模型在面对异常、恶意或不寻常…...

mybatis#号和$区别
在MyBatis中,#{}和${}都是用于实现动态SQL的占位符,但它们在使用场景和安全性上有明显的区别: 用途区别: #{}主要用于传递接口传输过来的具体数据,如参数值,它可以防止SQL注入,因为MyBatis会…...

AI绘画 Stable Diffusion【实战进阶】:图片的创成式填充,竖图秒变横屏壁纸!想怎么扩就怎么扩!
大家好,我是向阳。 所谓图片的创成式填充,就是基于原有图片进行扩展或延展,在保证图片合理性的同时实现与原图片的高度契合。是目前图像处理中常见应用之一。之前大部分都是通过PS工具来处理的。今天我们来看看在AI绘画工具 Stable Diffusio…...

Arm MPS3 FPGA开发板LED闪烁控制实战
1. 项目概述在嵌入式系统开发领域,FPGA(现场可编程门阵列)因其可重构特性成为硬件原型设计的首选平台。Arm MPS3 FPGA开发板作为一款功能强大的原型验证工具,为开发者提供了从算法验证到系统集成的完整解决方案。本次我们将通过经…...

多模态RAG实战:基于CLIP与向量数据库构建图文检索增强生成系统
1. 项目概述:从“Mureo”看多模态检索增强生成最近在折腾一个挺有意思的开源项目,叫“Mureo”。这个名字乍一看有点抽象,但如果你拆开来看,它其实融合了“Multimodal”(多模态)和“Neural”(神经…...

会议录播堆积如山?用这款AI工具3分钟自动生成会议纪要
一个很普遍的职场痛点:每周开3-4个会,录播存了一堆,但从来没有整理过。 不是不想整理,是整理一小时的会议录像至少要40分钟——要从头拉一遍、要标重点、要区分谁说了什么、要提炼行动项。忙的时候根本没时间干这个。 结果就是&…...

数据清洗实战:解锁混乱数据,构建高效企业集成管道
1. 项目概述与核心价值 最近在和一些做企业级应用集成的朋友聊天,发现一个挺有意思的痛点:很多系统在对接时,数据格式五花八门,尤其是那些历史包袱重的老系统,传过来的数据经常是“拧巴”着的。比如,一个本…...

控制理论实践:从PID到MPC的Python实现与仿真调试
1. 项目概述:从“Gonzo”看控制理论在开源项目中的实践最近在GitHub上看到一个挺有意思的项目,名字叫“control-theory/gonzo”。光看这个标题,你可能会有点摸不着头脑——“控制理论”和“Gonzo”有什么关系?Gonzo这个词…...

历史学博士生紧急避坑指南:NotebookLM误用导致的3类史料误读及权威校验方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM在历史学研究中的定位与风险图谱 NotebookLM 是 Google 推出的基于用户上传文档构建语义理解模型的实验性工具,其核心能力在于对私有史料(如扫描PDF、OCR文本、手稿转…...

官宣!网络安全法正式实施,人才缺口 327 万,这 5 类人直接站上风口,年薪百万不是梦
【必看收藏】网络安全人才抢夺战打响!新法实施后5类专业薪资翻倍,附学习路线 新《网络安全法》实施引爆网络安全人才市场,全球缺口480万,中国缺口327万以上。网络空间安全、信息安全、保密技术、网络安全科学与技术、信息对抗技术…...
)
别再死记硬背了!用一张时序图+五个核心状态,彻底搞懂5G NR入网(附RRC状态机详解)
5G NR入网流程:用状态机思维拆解终端与网络的第一次握手 当一部5G手机从关机状态按下电源键,到屏幕上显示"5G"信号图标,这短短几秒内发生了上百次信号交互。传统学习方式往往要求我们死记硬背每个步骤,但若能抓住五个核…...

终极指南:PersistentWindows如何彻底解决Windows多显示器窗口管理难题
终极指南:PersistentWindows如何彻底解决Windows多显示器窗口管理难题 【免费下载链接】PersistentWindows fork of http://www.ninjacrab.com/persistent-windows/ with windows 10 update 项目地址: https://gitcode.com/gh_mirrors/pe/PersistentWindows …...

别再只当CANoe/CANape的‘眼睛’了!VN1640A的I/O通道实战:手把手教你采集电压和开关信号
VN1640A硬件接口深度开发:从电压采集到PWM控制的工程实践 在汽车电子测试领域,Vector的VN系列接口设备早已成为行业标准配置。大多数工程师对CAN/LIN通道的应用驾轻就熟,却常常忽略设备上那个不起眼的9针I/O接口——这个被低估的硬件通道实际…...