探索AudioLM:音频生成技术的未来
目录
2. AudioLM的基础理论
2.1. 音频生成的基本概念
2.2. 语言模型在音频生成中的应用
2.3. 深度学习在音频生成中的作用
3. AudioLM的架构与实现
3.1. AudioLM的基本架构
3.1.1 编码器
3.1.2 解码器
3.1.3 生成模块
3.2. 训练过程
3.2.1 数据预处理
3.2.2 损失函数
3.2.3 优化算法
4. AudioLM的技术优势
4.1. 高保真度音频生成
4.2. 多样性与灵活性
4.3. 自适应能力
5. AudioLM的应用场景
5.1. 虚拟助理
5.2. 内容创作
5.3. 无障碍技术
5.4. 教育与培训
5.5. 游戏与娱乐
6. AudioLM的挑战与未来发展
6.1. 数据需求
6.2. 实时生成
6.3. 跨语言音频生成
6.4. 语义理解与上下文感知
6.5. 隐私与安全
7. AudioLM与其他音频生成技术的比较
7.1. 传统方法
7.2. 基于深度学习的方法
7.3. AudioLM的独特之处
8. AudioLM的未来展望
8.1. 技术融合
8.2. 个性化生成
8.3. 新兴应用
8.4. 社会影响与伦理问题
9. 结论
音频生成技术已经成为人工智能领域的重要研究方向之一。在这个领域中,AudioLM作为一种新兴的技术,展现了其在生成高质量音频方面的巨大潜力。AudioLM的出现不仅改变了我们对音频生成的理解,还为未来的发展提供了新的方向。本文将深入探讨AudioLM的基础理论、架构与实现、技术优势、应用场景、面临的挑战以及未来的发展前景,并通过具体的案例分析和代码示例来加深对这一技术的理解。
2. AudioLM的基础理论
2.1. 音频生成的基本概念
音频生成技术的目标是利用算法生成与人类语音或其他自然声音相似的音频。传统的音频生成方法通常依赖于规则或统计模型,而近年来,深度学习技术的兴起为音频生成带来了新的可能性。
2.2. 语言模型在音频生成中的应用
语言模型在自然语言处理(NLP)中的应用非常广泛,它们通过学习大量文本数据来预测下一个单词或短语。在音频生成中,类似的模型被用来预测和生成连续的音频片段。
2.3. 深度学习在音频生成中的作用
深度学习特别适合处理复杂的时序数据,如音频信号。通过多层神经网络结构,深度学习模型能够自动提取音频信号中的特征,并基于这些特征生成高质量的音频。
3. AudioLM的架构与实现
3.1. AudioLM的基本架构
AudioLM基于深度学习技术,采用了多层神经网络结构。其核心组件包括编码器、解码器和生成模块。编码器负责将输入音频转换为中间表示,解码器则将这些中间表示转换回音频信号。
3.1.1 编码器
编码器的主要任务是将原始音频信号转换为更高层次的特征表示。这通常通过卷积神经网络(CNN)或递归神经网络(RNN)实现。
3.1.2 解码器
解码器的任务是将编码器生成的特征表示转换回音频信号。这一过程通常涉及反卷积(transposed convolution)或上采样(upsampling)技术。
3.1.3 生成模块
生成模块是AudioLM的核心组件,负责基于输入特征生成连续的音频片段。生成模块通常采用自回归模型(autoregressive models)或变分自编码器(VAE)等技术。
3.2. 训练过程
AudioLM的训练过程涉及大量的音频数据。模型通过对这些数据进行反复训练,学习音频的时序特性和频谱特征。训练过程中的关键在于如何有效地捕捉音频信号的复杂特性,以生成高保真度的音频。
3.2.1 数据预处理
在训练之前,音频数据需要经过预处理,包括去噪、归一化和分帧等步骤。这些预处理步骤有助于提高模型的训练效率和生成质量。
3.2.2 损失函数
损失函数是训练过程中的重要组成部分。常见的损失函数包括均方误差(MSE)、对抗性损失(adversarial loss)和感知损失(perceptual loss)等。
3.2.3 优化算法
优化算法用于最小化损失函数,使模型的参数逐渐收敛。常用的优化算法包括随机梯度下降(SGD)、Adam和RMSprop等。
import torch
import torch.nn as nn
import torch.optim as optimclass AudioEncoder(nn.Module):def __init__(self):super(AudioEncoder, self).__init__()self.conv1 = nn.Conv1d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=1)self.conv2 = nn.Conv1d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1)self.conv3 = nn.Conv1d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1)self.relu = nn.ReLU()def forward(self, x):x = self.relu(self.conv1(x))x = self.relu(self.conv2(x))x = self.relu(self.conv3(x))return xclass AudioDecoder(nn.Module):def __init__(self):super(AudioDecoder, self).__init__()self.deconv1 = nn.ConvTranspose1d(in_channels=64, out_channels=32, kernel_size=3, stride=2, padding=1, output_padding=1)self.deconv2 = nn.ConvTranspose1d(in_channels=32, out_channels=16, kernel_size=3, stride=2, padding=1, output_padding=1)self.deconv3 = nn.ConvTranspose1d(in_channels=16, out_channels=1, kernel_size=3, stride=2, padding=1, output_padding=1)self.relu = nn.ReLU()def forward(self, x):x = self.relu(self.deconv1(x))x = self.relu(self.deconv2(x))x = self.deconv3(x)return xclass AudioLM(nn.Module):def __init__(self):super(AudioLM, self).__init__()self.encoder = AudioEncoder()self.decoder = AudioDecoder()def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x# 示例训练代码
def train_model(model, dataloader, epochs=10):criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=0.001)for epoch in epochs:for batch in dataloader:inputs, targets = batchoutputs = model(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.item()}')# 假设我们有一个dataloader
# dataloader = ...# 初始化并训练模型
audio_model = AudioLM()
# train_model(audio_model, dataloader)
4. AudioLM的技术优势
4.1. 高保真度音频生成
与传统方法相比,AudioLM在音频生成的保真度上具有显著优势。通过深度神经网络,模型能够捕捉音频信号中的细微变化,从而生成与真实音频难以区分的高质量音频。
4.2. 多样性与灵活性
AudioLM不仅能够生成标准的人类语音,还能够生成各种类型的音频,包括音乐、环境音效等。这种多样性使得AudioLM在应用范围上具有很大的灵活性。
4.3. 自适应能力
通过不断更新和优化,AudioLM能够自适应不同的音频生成需求。例如,通过微调模型参数,可以针对特定的音频生成任务进行优化,从而提高生成效果。
5. AudioLM的应用场景
5.1. 虚拟助理
虚拟助理是AudioLM的一个重要应用场景。通过生成自然流畅的语音,虚拟助理能够与用户进行更自然的互动,提升用户体验。
5.2. 内容创作
在内容创作方面,AudioLM可以用于生成配音、背景音乐等,提高创作效率并降低成本。
5.3. 无障碍技术
对于视障人士,AudioLM可以生成描述性音频,帮助他们更好地理解视觉内容,提升无障碍体验。
5.4. 教育与培训
在教育和培训领域,AudioLM可以用于生成教学音频,提供个性化的学习体验。例如,通过生成不同语速和口音的音频,满足不同学习者的需求。
5.5. 游戏与娱乐
在游戏和娱乐行业,AudioLM可以用于生成游戏音效和角色对话,增强用户的沉浸感和互动体验。
6. AudioLM的挑战与未来发展
6.1. 数据需求
高质量音频生成需要大量的数据支持。然而,获取和处理这些数据既耗时又昂贵。如何高效地利用现有数据,并探索数据增强技术,是未来研究的重要方向。
6.2. 实时生成
虽然AudioLM在生成音频质量上有了显著提升,但在实时生成方面仍面临挑战。如何在保证生成质量的同时,提升生成速度,是亟待解决的问题。
6.3. 跨语言音频生成
目前,AudioLM在处理不同语言的音频生成方面还有待改进。未来,跨语言音频生成技术的进步将使得AudioLM在全球范围内的应用更加广泛。
6.4. 语义理解与上下文感知
生成高质量音频不仅需要技术上的突破,还需要在语义理解和上下文感知方面进行深入研究。通过引入更先进的自然语言处理技术,AudioLM可以实现更智能的音频生成。
6.5. 隐私与安全
在音频生成过程中,如何保护用户的隐私和数据安全也是一个重要的挑战。未来需要制定更严格的数据保护措施,确保用户信息不被滥用。
7. AudioLM与其他音频生成技术的比较
7.1. 传统方法
传统的音频生成方法,如基于规则的合成技术和统计模型,虽然在某些特定应用中表现良好,但在生成多样性和自然度方面存在局限。
7.2. 基于深度学习的方法
与传统方法相比,基于深度学习的音频生成技术,如WaveNet和Tacotron,展示了更强的生成能力。AudioLM作为这一领域的新成员,进一步推动了技术的发展。
7.3. AudioLM的独特之处
与其他深度学习模型相比,AudioLM在架构设计和生成质量上有着独特的优势。例如,AudioLM在编码器和解码器结构上的创新,使得其在生成高保真度音频方面表现出色。
8. AudioLM的未来展望
8.1. 技术融合
未来,AudioLM有望与其他先进技术融合,如计算机视觉和自然语言处理,提供更为全面的解决方案。例如,通过结合图像生成技术,可以开发出能够生成音频和视频的多模态模型。
8.2. 个性化生成
个性化生成是音频生成技术的一个重要发展方向。通过学习用户的偏好和需求,AudioLM可以生成更加符合用户期待的音频内容,提升用户满意度。
8.3. 新兴应用
随着技术的不断进步,AudioLM在新兴应用领域的潜力将逐步显现。例如,在虚拟现实(VR)和增强现实(AR)中,AudioLM可以提供更加逼真的音频体验,增强沉浸感。
8.4. 社会影响与伦理问题
音频生成技术的发展也带来了社会影响和伦理问题。如何防止生成的音频被滥用于恶意目的,如假新闻和虚假信息的传播,是需要重视的问题。未来需要制定相关的法规和政策,确保音频生成技术的健康发展。
9. 结论
AudioLM作为一种新兴的音频生成技术,展示了其在生成高质量音频方面的巨大潜力。虽然目前还存在一些挑战,但随着技术的不断发展和应用场景的扩展,AudioLM有望在未来的音频生成领域占据重要地位。通过不断优化模型结构、提升生成质量和速度,AudioLM将为我们带来更加丰富多样的音频体验,推动音频生成技术的发展。
相关文章:

探索AudioLM:音频生成技术的未来
目录 2. AudioLM的基础理论 2.1. 音频生成的基本概念 2.2. 语言模型在音频生成中的应用 2.3. 深度学习在音频生成中的作用 3. AudioLM的架构与实现 3.1. AudioLM的基本架构 3.1.1 编码器 3.1.2 解码器 3.1.3 生成模块 3.2. 训练过程 3.2.1 数据预处理 3.2.2 损失函…...

计算机视觉:深入了解图像分类、目标检测和图像分割的核心技术
计算机视觉是什么? 计算机视觉是一门致力于让计算机“看懂”图像和视频的技术,它旨在通过模拟人类视觉系统来理解和解释数字化视觉信息。这一领域涉及图像的获取、处理、分析和理解,最终用于从视觉数据中提取有用信息并做出决策。计算机视觉的…...

Django 安装 Zinnia 后出现故障
在Django中安装和配置Zinnia时遇到故障可能有多种原因,通常包括版本兼容性、依赖关系或配置问题。这里提供一些常见的解决方法和调试步骤,帮助大家解决问题。 首先,确保您安装的Zinnia版本与Django版本兼容。查看Zinnia的官方文档或GitHub页…...
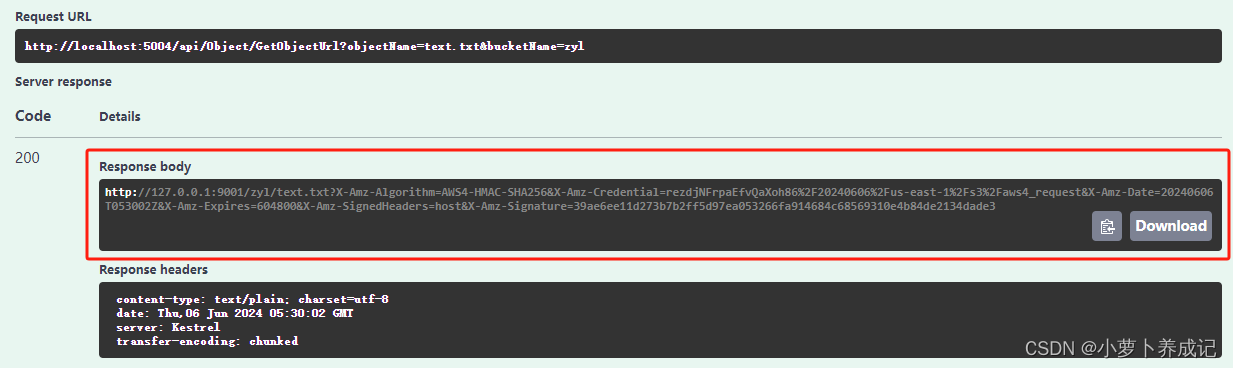
.net 8 集成 MinIO文件存储服务,实现bucket管理,以及文件对象的基本操作
一、准备工作 1、本地部署MinIO服务 2、创建MinIO的Access Key 3、创建.net 项目 4、下载MinIO sdk 5、相关文档 二、编写MinIO工具类 三、管理存储桶 1、MyBucket类 (1)判断bucket是否存在 (2)新建bucket (…...
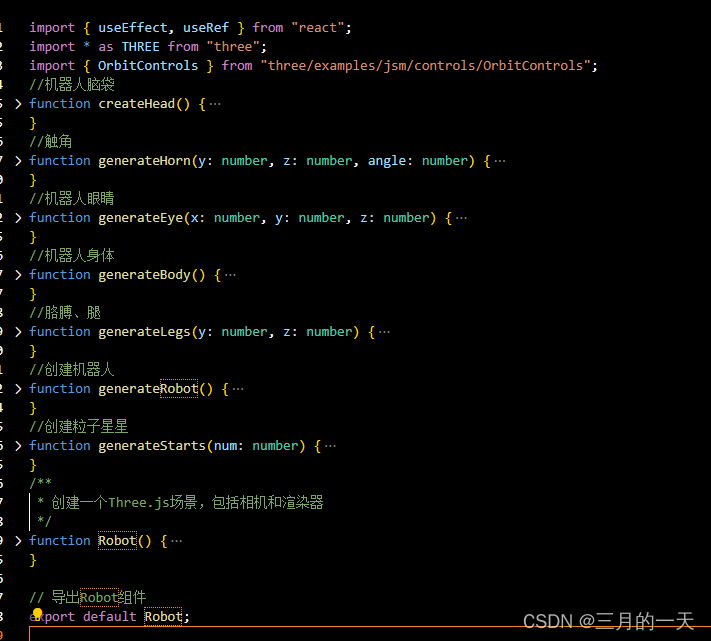
Three.js机器人与星系动态场景:实现3D渲染与交互式控制
内容摘要:使用Three.js库构建了一个交互式的3D场景。组件中创建了一个机器人模型,包括头部、眼睛、触角、身体和四肢,以及两个相同的机器人实例以实现动态效果。场景中还加入了粒子效果,模拟星系环境,增强了视觉效果。…...
Android系统集成和使用FFmpeg
文章目录 前言FFmpeg源码下载交叉编译NDK下载x264编译源码下载编译 FFmpeg编译脚本 AOSP继承FFmpeg 前言 原生AOSP中并未继承FFmpeg,所以要想在android上使用,需要自己编译集成。 FFmpeg源码下载 git clone https://git.ffmpeg.org/ffmpeg.git目前最新…...
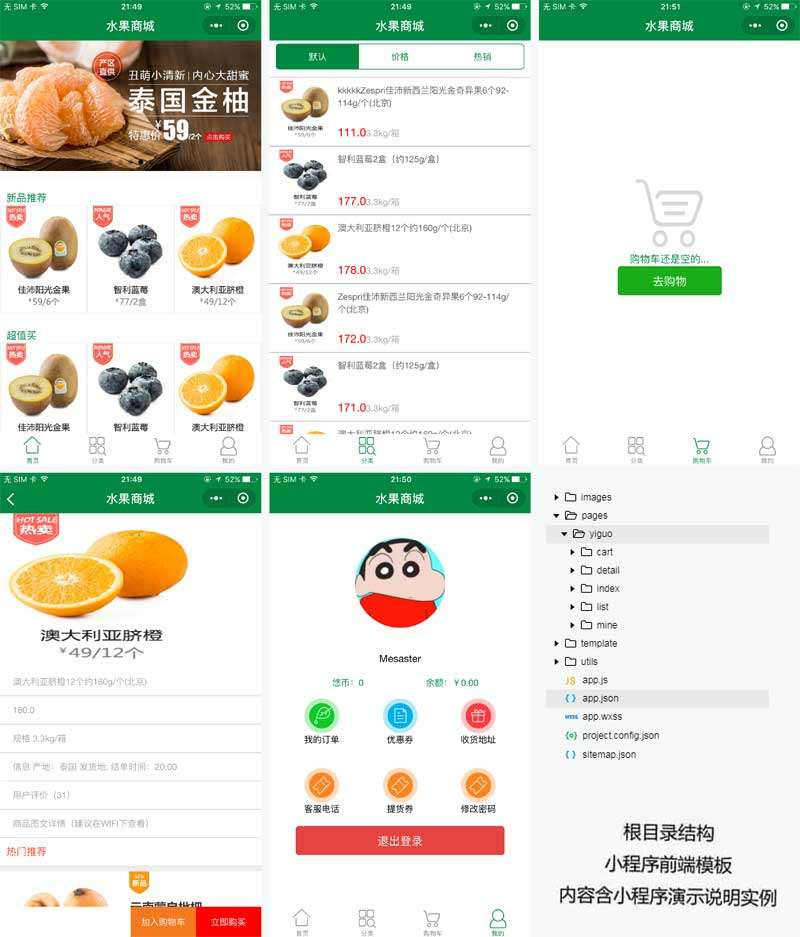
水果商城外卖微信小程序模板
手机微信水果外卖,水果电商,水果商城网页小程序模板。包含:主页、列表页、详情页、购物车、个人中心。 水果商城外卖小程序模板...

【前端】面试八股文——输入URL到页面展示的过程
【前端】面试八股文——输入URL到页面展示的过程 1. DNS解析 当用户在浏览器中输入URL并按下回车时,首先需要将域名转换为IP地址,这个过程称为DNS(域名系统)解析。具体步骤如下: 浏览器缓存:浏览器首先检…...
什么是应用安全态势管理 (ASPM):综合指南
软件开发在不断发展,应用程序安全也必须随之发展。 传统的应用程序安全解决方案无法跟上当今开发人员的工作方式或攻击者的工作方式。 我们需要一种新的应用程序安全方法,而ASPM在该方法中发挥着关键作用。 什么是 ASPM? 应用程序安全…...
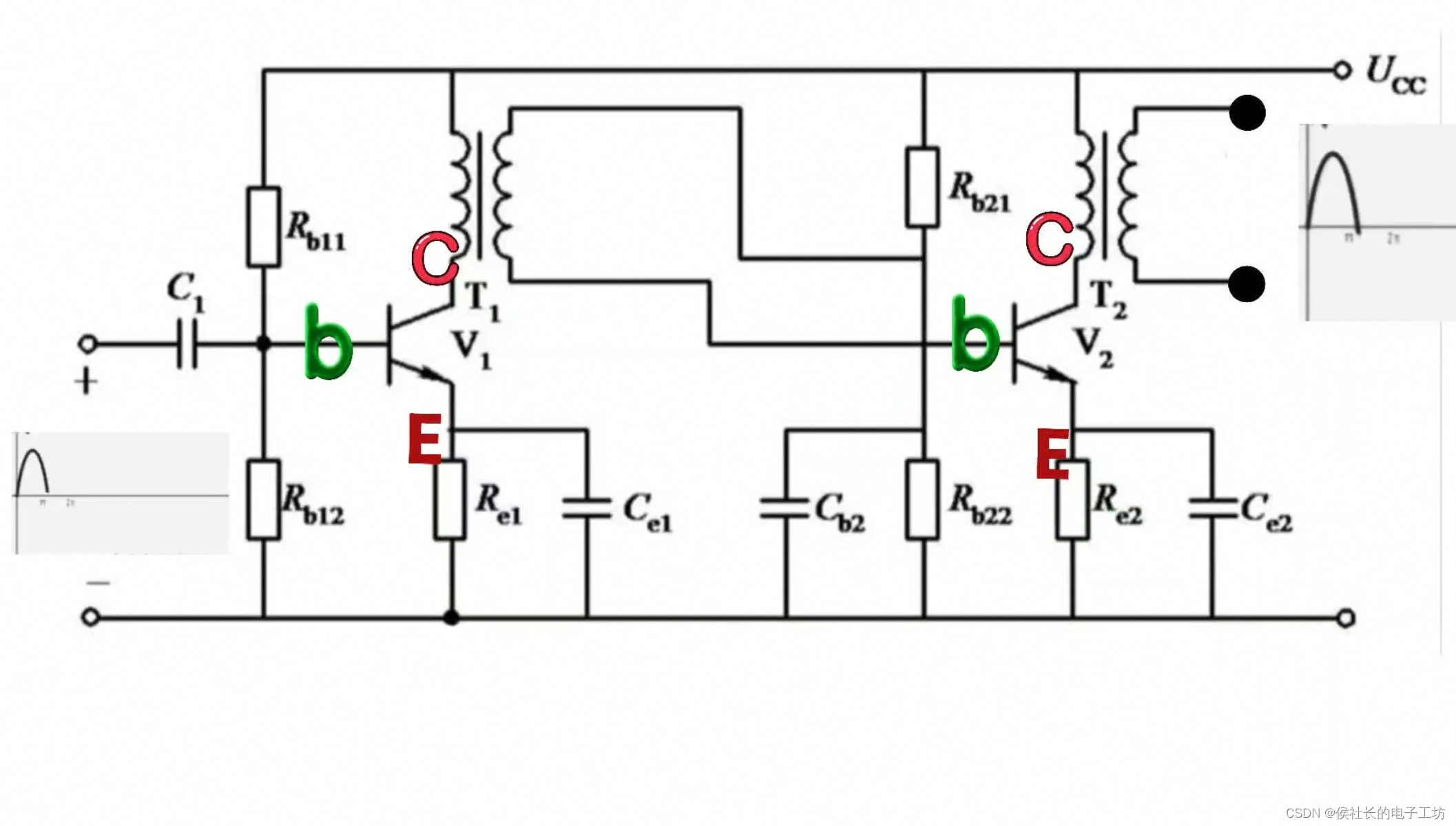
认识100种电路之耦合电路
在电子电路的世界中,耦合电路宛如一座精巧的桥梁,连接着各个功能模块,发挥着至关重要的作用。 【为什么电路需要耦合】 在复杂的电子系统中,不同的电路模块往往需要协同工作,以实现特定的功能。然而,这些模…...

c++【入门】三数的乘积
限制 时间限制 : 1 秒 内存限制 : 128 MB 题目 你已经学了一些程序的输入,这次,你需要在没有老师的任何帮助下完成这次的任务啦。这次任务,我们要读入三个整数,并且计算它们的乘积。 这是一个非常简单的题目,意在…...
:增加简单实用的事件机制)
C++实现简化版Qt的QObject(4):增加简单实用的事件机制
前面的文章已经实现了许多QObject的功能了: C实现一个简单的Qt信号槽机制 C实现简化版Qt信号槽机制(2):增加内存安全保障 C实现简化版Qt的QObject(3):增加父子关系、属性系统 但是,…...
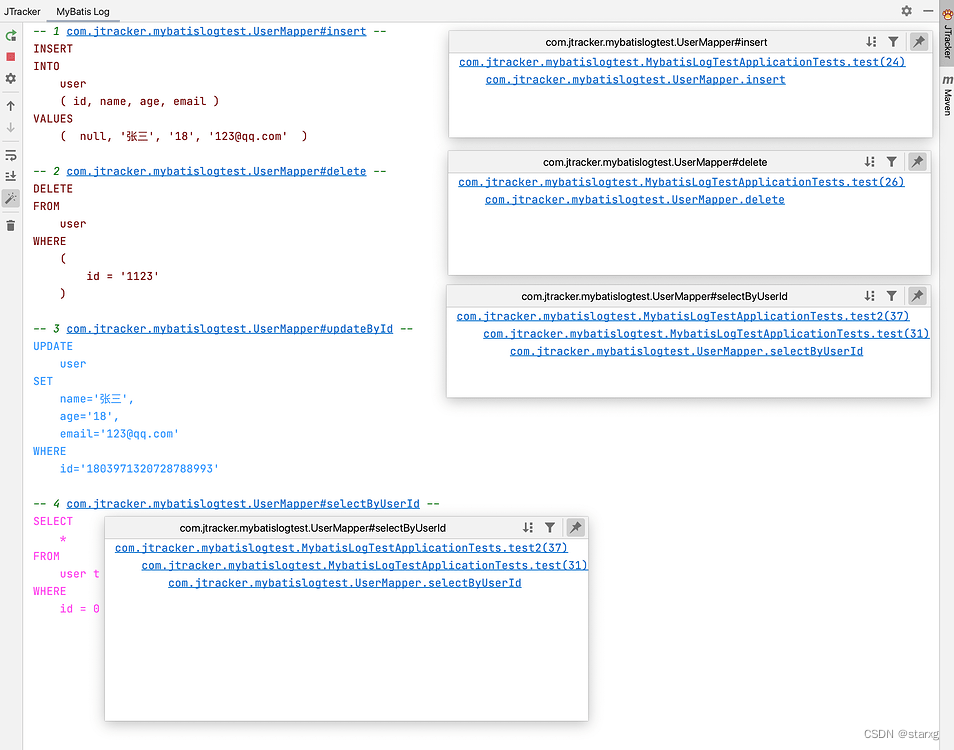
JTracker IDEA 中最好的 MyBatis 日志格式化插件
前言 如果你使用 MyBatis ORM 框架,那么你应该用过 MyBatis Log 格式化插件,它可以让我们的程序输出的日志更人性化。 但是有一个问题,通常我们只能看到格式化后的效果,没办法知道这个 SQL 是谁执行的以及调用的链路。 如下图所…...

物联网工业级网关解决方案 工业4G路由器助力智慧生活
随着科技的飞速发展,无线通信技术正逐步改变我们的工作与生活。在这个智能互联的时代,一款高性能、稳定可靠的工业4G路由器成为了众多行业不可或缺的装备。工业4G路由器以其卓越的性能和多样化的功能,助力我们步入智慧新纪元。 一、快速转化&…...

IoTDB Committer+Ratis PMC Member:“两全其美”的秘诀是?
IoTDB & Ratis 双向深耕! 还记得一年前我们采访过拥有 IoTDB 核心研发 Ratis Committer “双重身份”的社区成员宋子阳吗?(点此阅读) 我们高兴地发现,一年后,他在两个项目都更进一步,已成为…...

【链表】- 移除链表元素
1. 对应力扣题目连接 移除链表元素 2. 实现案例代码 public class RemoveLinkedListElements {public static void main(String[] args) {// 示例 1ListNode head1 new ListNode(1, new ListNode(2, new ListNode(6, new ListNode(3, new ListNode(4, new ListNode(5, new …...
云原生之使用Docker部署RabbitMQ消息中间件
云原生之使用Docker部署RabbitMQ消息中间件 一、RabbitMQ介绍1.1 RabbitMQ简介1.2 RabbitMQ特点1.3 RabbitMQ使用场景 二、检查Docker环境2.1 检查Docker版本2.2 检查操作系统版本2.3 检查Docker状态 三、下载RabbitMQ镜像四、部署RabbitMQ服务4.1创建挂载目录4.2 运行RabbitMQ…...
opengl箱子的显示
VS环境配置: /JMC /ifcOutput "Debug\" /GS /analyze- /W3 /Zc:wchar_t /I"D:\Template\glfwtemplate\glfwtemplate\assimp" /I"D:\Template\glfwtemplate\glfwtemplate\glm" /I"D:\Template\glfwtemplate\glfwtemplate\LearnOp…...

Oracle 视图、存储过程、函数、序列、索引、同义词、触发器
优质博文:IT-BLOG-CN 一、视图 从表中抽出的逻辑上相关的数据集合,视图是一种虚表,视图是建立在已有表的基础之上,视图赖以建立的这些表称为基表。向视图提供数据的是 SELECT语句,可以将视图理解为存储起来的SELECT语…...
网站被浏览器提示“不安全”的解决办法
在互联网时代,网站的安全性直接关系到用户体验和品牌形象。当用户访问网站时,如果浏览器出现“您与此网站之间建立的连接不安全”的警告,这不仅会吓跑潜在客户,还可能对网站的SEO排名造成等负面影响。 浏览器发出的“不安全”警告…...
)
树莓派物联网实战:避开TCP连接OneNet的3个常见坑(鉴权、脚本、心跳)
树莓派物联网实战:避开TCP连接OneNet的3个常见坑(鉴权、脚本、心跳) 在物联网项目开发中,树莓派作为边缘计算设备与云平台对接是常见需求。OneNet作为国内主流物联网平台,其TCP透传协议因其简单高效备受开发者青睐。然…...

从字典扩容到高位进位加法:图解Redis SCAN命令的底层遍历原理
从字典扩容到高位进位加法:图解Redis SCAN命令的底层遍历原理 Redis的SCAN命令是开发者工具箱中不可或缺的利器,尤其当面对海量键值对的遍历需求时。与简单粗暴的KEYS命令不同,SCAN通过精妙的高位进位加法算法和渐进式处理策略,在…...

自动化技能备份库的安全分析与工程实践指南
1. 项目概述与核心定位最近在整理一些自动化工具和脚本时,我又翻出了这个叫openclaw/skills的仓库。这其实是一个挺有意思的“数字档案馆”,它的主要作用是把一个特定平台上的“技能”(Skills)给备份下来。简单来说,你…...

AI代理如何通过MCP协议安全自动化DeFi期权价差交易
1. 项目概述:为AI交易员打造的DeFi期权交易接口如果你正在探索如何让AI智能体(比如OpenClaw或Bankr)在Base链上的Callput协议进行自动化期权交易,那么你很可能已经发现,现有的工具要么过于复杂,要么需要大量…...

ExifToolGUI终极指南:告别繁琐,用图形界面批量管理照片元数据
ExifToolGUI终极指南:告别繁琐,用图形界面批量管理照片元数据 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你是否曾面对成百上千张照片,想要批量修改拍摄时间、统一添…...

构建个人知识记忆桥梁:从数据抽取到智能检索的工程实践
1. 项目概述:一个连接记忆与未来的桥梁最近在开源社区里,我注意到一个挺有意思的项目,叫leninejunior/engrene-memory-bridge。光看这个名字,就透着一股子“连接”和“记忆”的味道。作为一个长期在数据工程和知识管理领域摸爬滚打…...

建议科技部与教育部聘请耿同学做学术打假工作
目前,学术界和社会公众正在热议的有一个核心话题:学术打假。“耿同学”(B站科普博主“耿同学讲故事”)近期在学术打假领域的表现确实堪称“降维打击”。作为一名退学博士,他仅凭个人力量和一些开源AI工具,在…...
技术:原理、优化与应用)
光学邻近校正(OPC)技术:原理、优化与应用
1. 光学邻近校正技术概述在半导体制造的光刻工艺中,光学邻近效应(Optical Proximity Effect)是影响图案转移精度的主要挑战之一。当特征尺寸缩小到45nm及以下节点时,光衍射和光阻化学反应导致的图案失真变得尤为显著。具体表现为&…...

GPT-5级能力提前落地,ChatGPT 2026新增9大生产级功能,含RAG++动态知识图谱、零样本工作流编排、联邦学习微调接口——错过本轮升级将落后至少18个月
更多请点击: https://intelliparadigm.com 第一章:GPT-5级能力提前落地的技术本质与产业影响 当前,所谓“GPT-5级能力”并非依赖单一巨型模型发布,而是通过模型蒸馏、多专家协同推理(MoE)、实时知识注入与…...

开源首发:DocCenter — 本地 HTML 工作台,治好 AI 时代的文档散落病
Tags:Python aiohttp 开源项目 AI工具 前端工程 全栈 工具分享 一、痛点:AI 时代的文档散落病 (对比传统文档管理 vs AI 生成文档的区别,说明为什么 VSCode/Notion 都不合适) 二、技术选型:为什么是单 Pyth…...