大数据期末复习——hadoop、hive等基础知识
一、题型分析
1、Hadoop环境搭建
2、hadoop的三大组件
HDFS:NameNode,DataNode,SecondaryNameNode
YARN:ResourceManager,NodeManager (Yarn的工作原理)
MapReduce:Map,Reduce
3、大数据的特征:
4、hadoop特征:(重点hadoop可靠性)
5、Hive
数据库(OLTP)和数据仓库(OLAT)ETL:
UDF,UDTF,
数据表的分区,分桶
6、4个采集工具:DataX、Flume、Maxwell、kafka
二、考点涵盖
一、大数据基础知识文档
1、大数据需要解决的三个问题:数据采集、数据存储(hdfs)、数据计算(MapReduce)。
2、数据采集的4个工具:DataX、Flume、Maxwell、kafka
3、大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
4、1byte=8bit 1k=1024byte 1MB=1024K 1G=1024M 1T 1P
- 大数据特点:大量、高速、多样性、价值性
- 大数据的生态体系,指由大数据相关产业、技术和应用构成的复杂庞大的系统。
- 大数据生态体系:数据源+数据存储+数据处理+数据应用
(1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。Sqoop现已被DataX所替代。
(2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
(3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统。
(4)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
(5)Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
(6)Oozie:Oozie是一个管理Hadoop作业(job)的工作流程调度管理系统。
(7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
(8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务或Spark任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
(9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
二、Hadoop基础文档
1、hadoop特征(四高一低):高可靠性、高扩展性、高效性、高容错性、低成本、
写出六到七个高可靠性体现的方面(简答)
Hadoop的高可靠性体现在以下几个方面:
1.数据冗余和副本机制:Hadoop通过数据冗余和副本机制,在集群中存储数据的多个副本,以防止数据天失。当某个节点发生故障时,可以从其他副本中恢复数据,确保数据的可靠性,
2.心跳机制和节点健康检测:Hadoop集群中的节点会定期发送心跳信号给主节点,用于检测节点的健康状态。如果某个节点长时间未发送心跳信号,Hadoop会认为该节点故障,并进行相应的处理,保证集群的稳定性。
3.机架感知和数据本地性优化:Hadoop的机架感知功能可以根据节点所处的机架位置来优化数据的存储和任务调度,减少跨机架的数据传输,提高数据本地性和作业执行效率
4.自动故障转移和自我修复:Hadoop具有自动故障转移和自我修复机制,能够在节点或任务发生故障时自动转移任务或数据,并自动修复一些常见的问题,确保集群的连续性和稳定性,
5.赢可用性架构:Hadoop提供了高可用性的解决方案,如HDFS的NameNode HA(高可用性)机制和VARN的ResourceManager HA机制,确保即使在节点故障的情况下,集群仍能保持高可用性,不影响作业的执行。
6.数据完整性和一致性保证:Hadoop画过数据校验和一致性机制来保证数据的完整性和一致性。数据在存储和传输过程中会进行校验和验证,避免数据损坏或算改,保证数据的准确性,
7.监控和日志记录:Hadoop集群提供了丰富的监控和日志记录功能,可以实时监校集群的状态和性能指标,及时发现问题并进行处理,提高集群的稳定性和可靠性,
2、hadoop的三大组件
HDFS分布式文件系统 数据存储:NameNode什么叫元数据哪些是元数据管理什么;DateNode分块保存数据;SecondaryNameNode日志和日志合并,不能做热备份
YARN资源调度:ResourceManager资源调度管理;NodeManager管理单个节点;yarn工作原理
MapReduce计算:Map并行计算; Reduce合并

Yarn的工作原理(简答)
1.资源管理器(ResourceManager):YARN的核心组件之一,负责整个集群的资源管理。
ResourceManager接收作业提交请求,分配资源给不同的应用程序,并监控资源的使用情况。
2.节点管理器(NodeManager):每个集群节点上都运行一个NodeManager,负责管理该节点的资源,NodeManager会定期向ResourceManager报告节点的资源使用情况,并按收来自ResourceManager的资源分配指令。
3.应用程序主管(ApplicationMaster):每个应用程序在YARN中都有一个对应的ApplicationMaster,负责应用程序的管理和协调。ApplicationMaster与ResourceManager通信,请求资源分配,并监控应用程序的执行状态。
4.作业调度器(Scheduler):YARN的调度器负责决定如何分配集群资源给不同的应用程序。调度器根据资源请求、优先级和队列设置等因素来进行资源分配决策。
总体来说,YARN的工作原理是通过ResourceManager和NodeManager同工作,
每个应用程序的资源需求和执行过程,从而实现高效的集群资源管理和作业调度
- Map阶段并行处理输入数据。
- Reduce阶段对Map结果进行汇总。

三、Hive全部文档
1、数据库(OLTP)和数据仓库(OLAT)ETL 区别:(简答)
数据库主要用于事务处理,即联机事务处理OLTP(On-Line Transaction Processing),也就是我们常用的面向业务的增删改查操作。OLTP要求实时性高,但处理数据量不是很大。
数据仓库主要用于数据分析,即联机分析处理OLAP(On-Line Analytical Processing),供上层决策,常见于一些查询性的统计数据。OLAP实时性要求不高,但处理的数据量很大。
2、

【课后作业】
1、简述数据库与数据仓库的区别。
2、简述OLTP的OLAP。

3、什么是ETL,ETL在数据处理过程中所起的作用是什么?
建立 OLAP 应用之前,我们要想办法把各个独立系统的数据抽取出来,经过一定的转换
和过滤,存放到一个集中的地方,成为数据仓库。这个抽取,转换,加载的过程叫 ETL(Extract
Transform,Load),目的是将企业中分散、零乱、标准不统一的数据整合到一起。
ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的
新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持 ETL 的正常和稳定。ETL
4、下面不是数据仓库特征的是(C)稳定性
A.主题性 B.集成性 C.实时性 D.时变性
5、关于hive描述,以下说法错误的是( D)
A.Hive本身不存储数据,Hive中每张表的数据存储在HDFS。
B.Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)。
C. Hive解析器(SQLParser)将SQL字符串转换成抽象语法树(AST)。
D.Hive仓库存储了数据库、表名、表的拥有者、列/分区字段、表的类型。
【课后作业】
4、Hive底层的计算由分布式计算框架实现,下列哪些计算引擎hive不支持( D)
A.MapReduce B.Tez C.Spark D.Flink
5、Hive默认在HDFS的工作目录配置在哪个参数配置文件中( B)
A. hive-default.xml B.hive-site.xml C.hive-log4j2.properties D.hive-env.sh
【课后作业】
4、下列HQL操作是属于反序列化的是( D)
A.INSERT B.ALERT C.DROP D.SELECT
5、下列存储格式不属于列式存储的是( A)
A. TEXTFILE B. ORC C. PARQUET D. RCFILE
【课后作业】
4、下列语句中,能够按照课程求平均值的是(D)
A.select 课程,avg( 成绩) 平均分 from 表
B. select 课程,分数,avg( 成绩) 平均分 from 表 group by 课程
C. select 课程, max( 成绩) 平均分 from 表 group by 课程
D. select 课程, sum( 成绩)/count(*) 平均分 from 表 group by 课程
5、Hive函数类别不包括(D)
A.一进一出 B. 多进一出 C. 一进多出 D. 多进多出
【课后作业】
- 简述UDF、UDAF、UDTF函数的区别。
UDF一进一出
UDAF多进一出
UDTF一进多出
3、函数substr('abcde',2,2)的的执行结果是(B)
A.ab B. bc C. cd D. de
4、下列关于窗口函数的说法错误的是( D)
A. partition by 分组类似group by,基于每一行数据所在的组进行计算并返回结果。
B. 窗口函数和聚合函数相似,窗口函数的输入也是多行记录。
C. order by 不仅在窗口内排序,还在窗口内从当前行到之前所有行的聚合。
D. 窗口若包含order by,则默认值为rows between 第一行 and 当前行。
【课后作业】
1、简述分区的原理和作用。
2、简述分桶的原理和作用。
3、简述动态分区和静态分区的区别和使用场景。
4、下列参数设置中,可以避免动态分区过多导致的性能问题( B)
A. hive.exec.max.dynamic.partitions
B. hive.exec.max.dynamic.partitions.pernode
C. hive.exec.max.created.files
D. hive.error.on.empty.partition
5、下列关于分区的说法错误的是( A)
A. Hive动态分区的分区字段必须是表的列
B. Hive分区通过设置虚拟列来进行动态分区,可以更加灵活地根据查询结果插入相应的分区。
C. Hive动态分区可以提高数据插入和查询的效率,同时也可能导致分区目录过多降低查询性能。
D.可以设置hive. exec. default. partition. name参数来处理分区字段值为空的情况。通过设置默认分区名,可以将分区字段值为空的数据插入到默认分区目录。
四、yarn文档
Yarn的工作原理
- mysql常用语句
MySQL初级篇——常用SQL语句(大总结)_查询薪资表中比java最高工资高的所有员工职位名称和薪资;-CSDN博客
MySQL常用SQL语句大全_数据库建表语句-CSDN博客
相关文章:
大数据期末复习——hadoop、hive等基础知识
一、题型分析 1、Hadoop环境搭建 2、hadoop的三大组件 HDFS:NameNode,DataNode,SecondaryNameNode YARN:ResourceManager,NodeManager (Yarn的工作原理) MapReduce:Map࿰…...

什么是客户体验自动化?
客户体验自动化是近年来在企业界备受关注的一个概念。那么,究竟什么是客户体验自动化呢?本文将为您详细解析这一话题,帮助您更好地理解并应用客户体验自动化。 我们要先明确什么是客户体验。客户体验是指客户在使用产品或服务过程中的感受和体…...

高效除氟:探索CH-87up树脂在氟化工废水处理中的应用
摘要 本研究旨在评估Tulsimer CH-87up树脂针对经钙镁预处理后的氟化工废水的深度处理效果。实验结果显示,CH-87up树脂能显著降低废水中的氟离子浓度,从43.4mg/L降至0.34mg/L,远低于行业排放标准的5mg/L。此外,该树脂表现出卓越的…...

【Git】LFS
什么是lfs Git 是分布式 版本控制系统,这意味着在克隆过程中会将仓库的整个历史记录传输到客户端。对于包涵大文件(尤其是经常被修改的大文件)的项目,初始克隆需要大量时间,因为客户端会下载每个文件的每个版本**。Gi…...

隐式转换的魔法:Scala中隐式转换的深度解析
隐式转换的魔法:Scala中隐式转换的深度解析 在Scala编程语言的丰富特性中,隐式转换是一个强大而微妙的工具。它允许开发者在不改变现有代码的情况下,扩展或修改类的行为。本文将深入探讨Scala中隐式转换的工作原理,并通过详细的代…...

外贸企业选择什么网络?
随着全球化的深入发展,越来越多的国内企业将市场拓展到海外。为了确保外贸业务的顺利进行,企业需要建立一个稳定、安全且高速的网络。那么,外贸企业应该选择哪种网络呢?本文将为您详细介绍。 外贸企业应选择什么网络? …...

Redis 7.x 系列【14】数据类型之流(Stream)
有道无术,术尚可求,有术无道,止于术。 本系列Redis 版本 7.2.5 源码地址:https://gitee.com/pearl-organization/study-redis-demo 文章目录 1. 概述2. 常用命令2.1 XADD2.2 XRANGE2.3 XREVRANGE2.4 XDEL2.5 XLEN2.6 XREAD2.7 XG…...
opengl函数加载和错误处理)
(四)opengl函数加载和错误处理
#include <glad/glad.h>//glad必须在glfw头文件之前包含 #include <GLFW/glfw3.h> #include <iostream>void frameBufferSizeCallbakc(GLFWwindow* window, int width, int height) {glViewport(0, 0, width, height);std::cout << width << &qu…...

RuoYi-Vue3不启动后端服务如何登陆?
RuoYi-Vue3不启动后端服务如何登陆?RuoYi-Vue3使用的前端技术栈 是:Vue3 + Element Plus + Vite。 github开源地址:https://github.com/yangzongzhuan/RuoYi-Vue3 前后的分离在线演示项目地址:https://vue.ruoyi.vip/ 这种方式是用若依提供的在线后端接口,可以在此基础上修…...

Typora(跨平台 Markdown 编辑器 )正版值得购买吗
Typora 是一款桌面 Markdown 编辑器,作为国人开发的优秀软件,一直深受用户的喜爱。 实时预览格式 Typora 是一款适配 Windows / macOS / Linux 平台的 Markdown 编辑器,编辑实时预览标记格式,所见即所得,轻巧而强大…...
springboot个人证书管理系统-计算机毕业设计源码16679
摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了个人证书管理系统的开发全过程。通过分析个人证书管理系统管理的不足,创建了一个计算机管理个人证书管理系统的方案。文章介绍了个人证书管理系统的系…...

读-改-写操作
1 什么是读-改-写操作 “读-改-写”(Read-Modify-Write,简称RMW)是一种常见的操作模式,它通常用于需要更新数据的场景。 这个模式包含三个基本步骤: 1.读(Read):首先读取当前的数据…...
海外仓系统应用教程:解决了小型海外仓哪些问题
大型海外仓通过对海外仓WMS系统的使用,大大提升了业务流程的效率和利润率。这也给很多小型海外仓造成了误区,觉得海外仓系统就是为大型海外仓设计的。其实小型海外仓对海外仓系统的需求同样强烈,现在也有很多专门转对中小型海外仓设计的WMS系…...
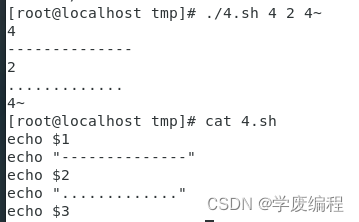
shell 脚本编程
简介: 用户通过shell向计算机发送指令的计算机通过shell给用户返回指令的执行结果 通过shell编程可以达到的效果 提高工作效率可以实现自动化 需要学习的内容: linuxshell的语法规范 编写shell的流程 第一步:用vi/vim创建一个.sh的文件…...
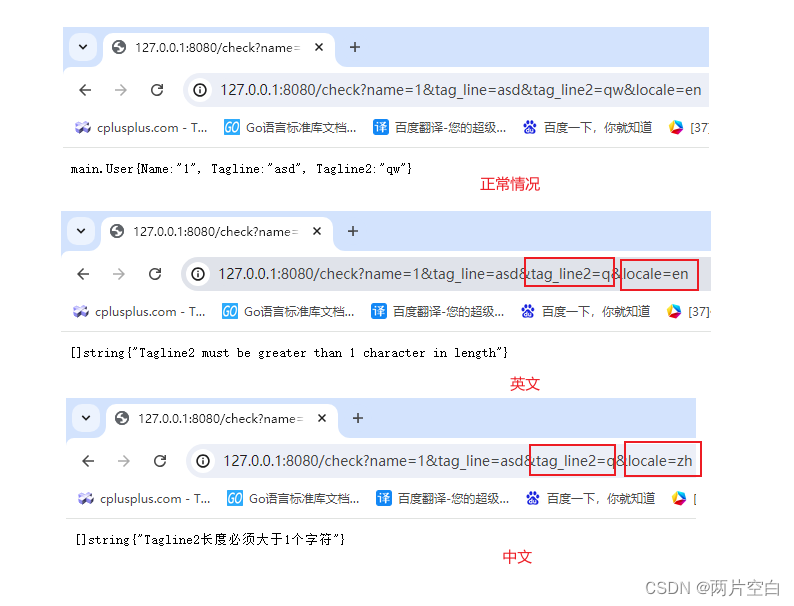
gin参数验证
一. 结构体验证 用gin框架的数据验证,可以不用解析数据,减少if else。如下面的代码,如果需要增加判断条件,就需要增加if或者if else。 type MyApi struct {a intb string }func checkMyApi(val *MyApi) bool {if val.a 0 {retur…...
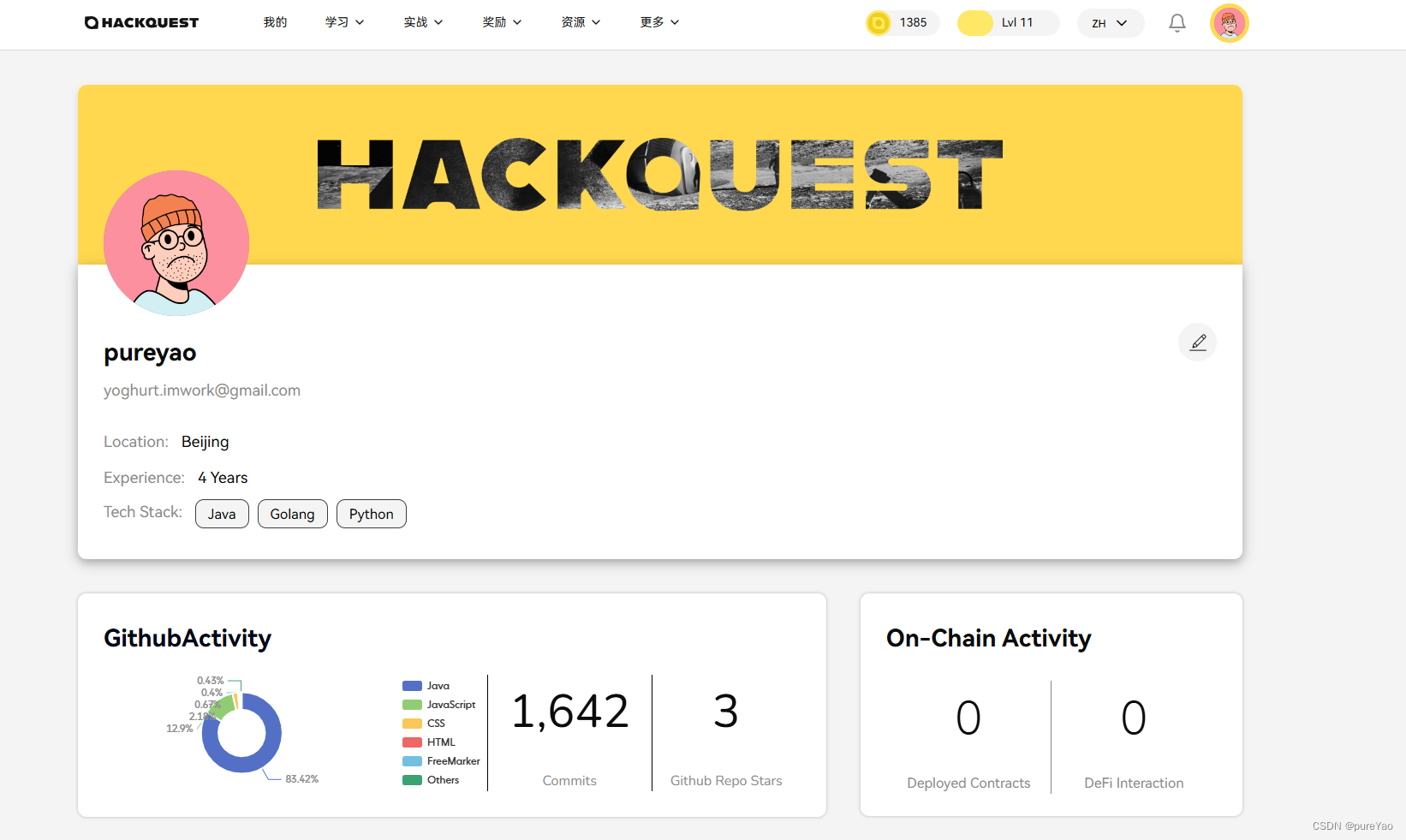
【web3】分享一个web入门学习平台-HackQuest
前言 一直想进入web3行业,但是没有什么途径,偶然在电鸭平台看到HackQuest的共学营,发现真的不错,并且还接触到了黑客松这种形式。 链接地址:HackQuest 平台功能 学习路径:平台有完整的学习路径ÿ…...

Sectigo或RapidSSL DV通配符SSL证书哪个性价比更高?
在当前的网络安全领域,选择一款合适的SSL证书对于保护网站和用户数据至关重要。Sectigo和RapidSSL作为市场上知名的SSL证书提供商,以其高性价比和快速的服务响应而受到市场的青睐。本文将对Sectigo和RapidSSL DV通配符证书进行深入对比,帮助用…...
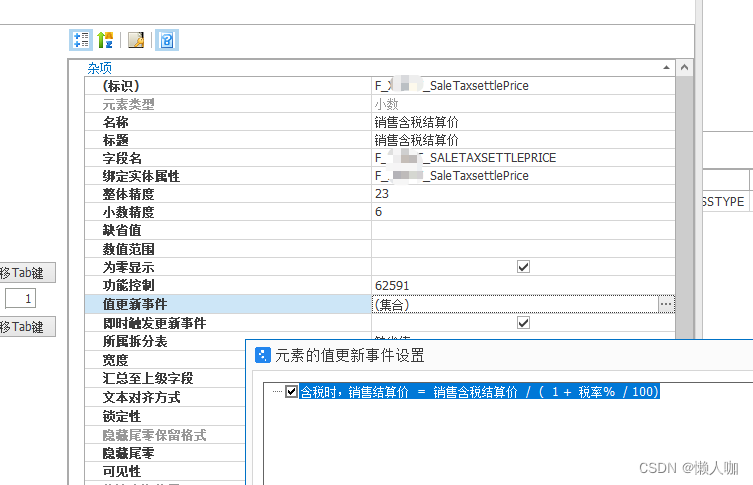
金蝶云星空字段之间连续触发值更新
文章目录 金蝶云星空字段之间连续触发值更新场景说明具体需求:解决方案 金蝶云星空字段之间连续触发值更新 场景说明 字段A配置了字段B的计算公式,字段B配置了自动C的计算公式,修改A的时候,触发了B的重算,但是C触发不…...
Python 获取字典中的值(八种方法)
Python 字典(dictionary)是一种可变容器模型,可以存储任意数量的任意类型的数据。字典通常用于存储键值对,每个元素由一个键(key)和一个值(value)组成,键和值之间用冒号分隔。 以下是 Python 字典取值的几…...

Day49
Day49 代理模式proxy 概念: 代理(Proxy)是一种设计模式,提供了对目标对象另外的访问方式,即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能. 代理模式分为静态代理和动态代理…...
)
保姆级教程:用斐讯N1盒子刷Armbian 5.77,打造你的专属Debian服务器(附解决负载过高问题)
斐讯N1盒子改造指南:从电视盒子到高性能家庭服务器的蜕变 在智能家居和个性化网络需求日益增长的今天,拥有一台24小时运行的家庭服务器成为许多技术爱好者的刚需。而斐讯N1盒子凭借其出色的硬件配置和极低的功耗,成为了DIY玩家眼中的"宝…...

WebToEpub:5分钟快速制作专业EPUB电子书的完整指南
WebToEpub:5分钟快速制作专业EPUB电子书的完整指南 【免费下载链接】WebToEpub A simple Chrome (and Firefox) Extension that converts Web Novels (and other web pages) into an EPUB. 项目地址: https://gitcode.com/gh_mirrors/we/WebToEpub 还在为在线…...

AI学术研究技能包:从论文导读到实验设计的全流程自动化助手
1. 项目概述:一个为AI研究助手打造的学术技能包如果你正在用Claude Code、ChatGPT/Codex CLI或者Gemini CLI这类AI编程助手做研究,大概率遇到过这样的场景:想让AI帮你读篇论文,它却只能泛泛而谈;想让AI设计个实验&…...

明日方舟游戏资源库:一站式高清素材解决方案
明日方舟游戏资源库:一站式高清素材解决方案 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 还在为创作明日方舟同人内容却找不到高质量素材而烦恼吗?想要开发明…...
背锅了!TongWeb7/6负载均衡后获取真实IP的两种实战方案)
别再让request.getRemoteAddr()背锅了!TongWeb7/6负载均衡后获取真实IP的两种实战方案
负载均衡环境下TongWeb获取真实客户端IP的工程实践 在分布式架构盛行的今天,负载均衡已成为高可用系统的标配组件。但当流量经过多层代理后,后端服务获取的客户端IP往往会"失真"——这不仅是TongWeb特有的问题,而是所有Java Web容…...
)
NotebookLM深度适配语言学研究全流程(附Linguistic Annotation Pipeline v2.1实测报告)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM语言学研究辅助的范式变革 从静态语料库到动态知识图谱的跃迁 NotebookLM 不再将语言学材料视为孤立文本,而是通过语义锚点(Semantic Anchors)自动识别术…...

从RunwayML转投Pika Labs?我对比了5个关键场景后的真实体验
从RunwayML转投Pika Labs?5个关键场景下的深度对比与选型指南 当AI视频生成工具如雨后春笋般涌现,创作者们面临的最大挑战不再是技术获取,而是如何在众多选项中做出明智选择。RunwayML作为行业先驱积累了稳定用户群,而Pika Labs凭…...
)
手把手教你给STM32H743的0.96寸OLED屏移植STemWin(裸机+FreeRTOS双版本)
STM32H743与0.96寸OLED的STemWin深度移植实战:裸机与RTOS双环境解析 在嵌入式图形界面开发领域,STemWin作为ST官方推出的图形库解决方案,以其高效的渲染性能和丰富的控件资源,成为STM32开发者构建人机界面的首选。本文将聚焦STM32…...

抖音无水印视频下载终极指南:5分钟快速上手douyin-downloader
抖音无水印视频下载终极指南:5分钟快速上手douyin-downloader 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

Code-Captain:一体化开发工作流自动化工具的设计与实践
1. 项目概述:一个为开发者打造的“全能副驾”最近在 GitHub 上看到一个挺有意思的项目,叫devobsessed/code-captain。光看这个名字,你可能会联想到“代码船长”或者“开发指挥官”之类的形象。没错,这个项目的核心定位,…...