[Information Sciences 2023]用于假新闻检测的相似性感知多模态提示学习
推荐的一个视频:p-tuning
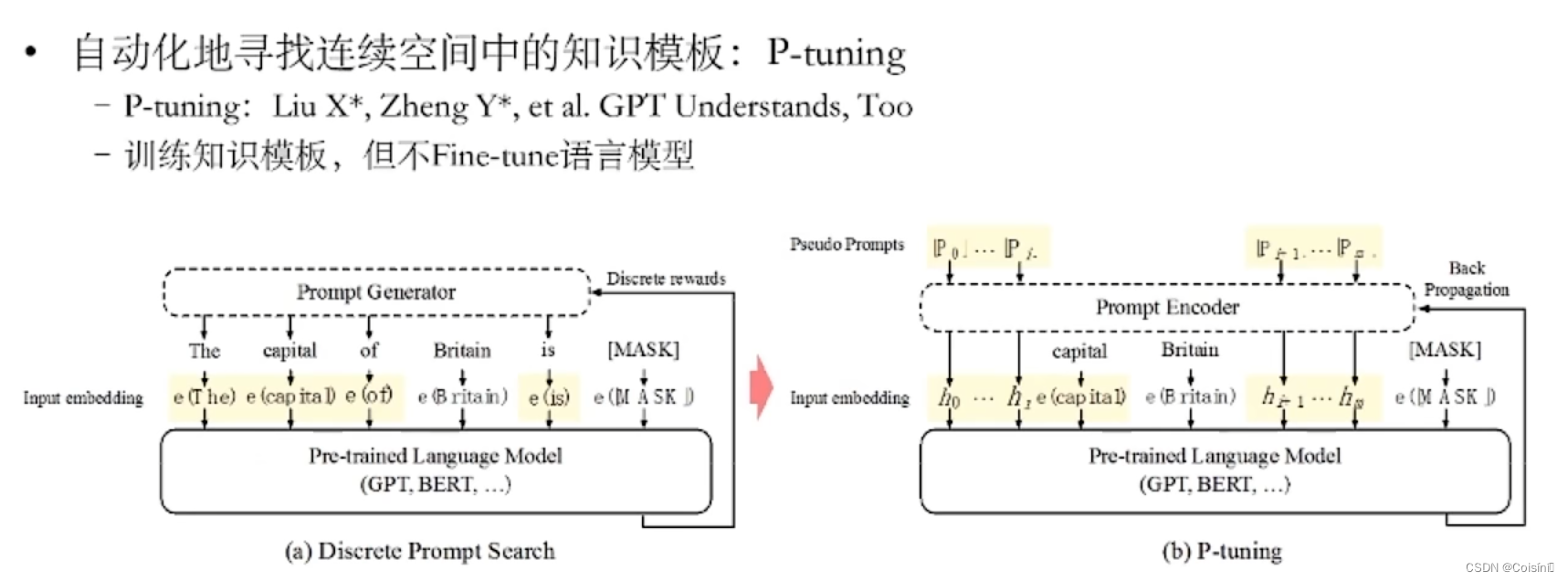
P-tunning直接使用连续空间搜索
做法就是直接将在自然语言中存在的词直接替换成可以直接训练的输入向量。本身的Pretrained LLMs 可以Fine-Tuning也可以不做。
这篇论文也解释了为什么很少在其他领域结合知识图谱的原因:就是因为大模型本身就是一个很好的KG,作者在视频中讲到利用P-tuning的方法完全可以在WikiData上实现60%的准确率,也就说可以完全通过大模型形成60%的WikiData中三元组表示内容。而且随着模型规模的上升,这个精度也会继续增加。

【使用Fine-tunning的方法,BERT的性能表现要高于GPT;而基于P-tunning的方法,GPT的性能表现高于BERT】
通讯作者简介:
青岛科技大学-王宜敏教授主页
摘要
假新闻检测的标准范式依赖于利用文本信息来建模新闻的真实性。然而,网络假新闻的微妙本质使得仅仅依靠文本信息进行揭穿具有挑战性。近年来针对多模态假新闻检测的研究表明了该方法与纯文本检测方法同样具有优越的性能,从而建立了检测假新闻的新范式。然而,这种范例可能需要大量的训练实例或更新整套预训练的模型参数。此外,现有的多模态方法通常集成跨模态特征,而不考虑来自不相关语义表示的可能引入的噪声。此外,现有的多模态方法通常集成跨模态特征,而不考虑来自不相关语义表示的潜在噪声引入。为了解决这些问题,本文提出了相似性感知多模态提示学习(SAMPLE)框架。将提示学习融入多模式假新闻检测中,我们使用三个带有软语言器的提示模板来检测假新闻。 此外,我们引入了一种相似性感知融合方法,该方法自适应地融合多模态表示的强度,以减轻来自不相关的跨模态特征的噪声注入。评估结果表明,SAMPLE 的性能优于之前的工作,在两个多模态基准数据集上获得了更高的 F1 和准确度分数,无论数据丰富还是少样本设置都证明了其在现实场景中的可行性。
Introduction
社交媒体的日益普及极大地影响了信息传播和消费的方式。 虽然社交媒体平台为人们寻找和分享信息提供了有效的方式,但假新闻的传播给国际社会造成了巨大伤害。 为了减轻在线假新闻的影响,学术界和工业界开发了各种技术。 早期研究[29,4]主要集中于分析假新闻的文本内容。然而,假新闻可以采取多种形式,仅依靠文本信息来验证其真实性需要专业知识,这可能非常耗时。 例如,图 1 显示了两个新闻片段,这对仅通过文本信息来识别其真实性提出了挑战。 因此,最近开发了多模态假新闻检测(FND)技术来利用图像和文本信息,展示了通过跨模态分析提供的互补优势的良好性能。
多模态 FND 旨在结合图像和文本的特征来自动识别虚假新闻帖子。 传统的深度学习方法,例如卷积神经网络 (CNN)、循环神经网络 (RNN) 和 Transformer,在假新闻的文本和图像表示建模方面取得了重大进展。然而,这些方法通常受到依赖大量注释数据来实现令人满意的性能的限制。 最近,人们对利用大型预训练模型进行 FND 越来越感兴趣。许多研究[42,2]使用预训练的语言模型(例如 BERT [10])和预训练的视觉模型(例如 ResNet [16])分别对新闻帖子的文本和图像特征进行编码。然而,预训练模型通常是在不特定于任何特定领域的大型、未经精炼的语料库上进行训练的。 尽管预训练模型可以利用外部知识来识别虚假帖子,但 FND 系统的有效性高度依赖于其焦点领域 [19]。
微调是使预训练模型适应不同下游任务的常用技术。 在最近的研究中,BERT 的变体,包括原始的预训练模型,已经专门针对 FND 进行了微调 [7]。 然而,由于需要大量标记实例来训练额外的分类器,FND 的微调通常会在资源匮乏的情况下带来困难 [5]。 传统的预训练语言模型采用完形填空式的目标进行训练,其中涉及预测屏蔽词以了解其分布,而微调的目的是直接识别目标标签。 因此,预训练模型需要大量标记数据来针对特定任务进行微调。 同时,由于预训练模型的大小,微调、更新单个任务的所有模型参数给现实世界的 FND 带来了挑战 [27]。 提示学习是一种旨在通过向输入添加附加信息并在调整过程中使用完形填空式任务来更好地利用预训练知识的方法,从而更有效地应用预训练信息[37]。此外,提示学习对于现实世界的 FND 场景尤其重要,因为在现实世界中,手动标记的假新闻数据很少。 它使预先训练的模型即使在标记数据有限的资源匮乏的环境中也能获得有竞争力的性能[5]。 然而,当前基于提示的 FND 方法[19]主要考虑文本信息,对假新闻帖子中跨模态特征的分析尚不成熟。

图 1. 两个假新闻片段及其原始报道。
与直接输出类别分布的微调模型相比,提示学习与语言建模目标保持一致,通过在原始文本输入之前添加补充信息来生成与 FND 相关的特定答案词。 **如图1左侧的新闻片段所示,通过在原文前引入提示(例如,“这是一条新闻。前总统和违法者巴拉克·奥巴马……” ),这种方法的目的是检索提示文本的屏蔽标记。**然而,离散提示的局限性在于它需要嵌入模板词以与自然语言词的嵌入保持一致。 为了解决这个问题,连续提示[35]通过直接在预训练模型的连续空间中执行提示来消除离散提示的约束,例如“< soft > < soft >…< soft > < mask >,Former president and breaker of laws, Barack Obama…” ,其中每个 < soft > 可以与随机初始化的可训练向量相关联。此外,混合提示[19]不是利用完全可学习的提示模板,而是将可训练向量合并到离散提示模板中(例如:“< soft > This is a piece of < mask > news < soft >. Former president and breaker of laws, Barack Obama…”)并展示了比单独使用每种提示类型更优越的性能。
以前的多模态 FND 方法 [26,41] 旨在通过直接融合多模态表示来提高性能。 然而,仅仅结合图像和文本特征并不能保证信息的可靠性,因为新闻文章的真实性并不完全与图文相关性相关。 在这种情况下,文本和图像特征之间的相关性往往较弱,导致多模态表示出现噪声。 因此,多模态 FND 模型掌握不同模态之间的语义相关性并自适应地结合多模态特征进行准确分类至关重要。
语义相似度的方法大概率来自于SAFE模型。
本文提出了一种用于 FND 的相似性感知多模态提示学习(SAMPLE)框架。 三种流行的提示学习方法(离散提示(DP)、连续提示(CP)和混合提示(MP))被系统地集成到用于 FND 任务的软言语器中。 此外,应用预训练模型对比语言-图像预训练(CLIP)[36]来提取文本和图像特征,用于生成多模态表示。 为了解决文本和图像之间语义表示不相关的问题,该框架计算了它们特征之间的语义相似度。 为了调整聚合多模态表示的强度,语义相似性被进一步归一化。 为了评估所提出的 SAMPLE 框架的性能,使用了两个特定领域的可公开访问的数据集:PolitiFact 和 GossipCop [39])。 我们将 SAMPLE 与现有的 FND 方法以及标准微调方法进行比较,在少样本和数据丰富的场景下模拟真实世界的 FND 设置。 实验结果表明,无论数据丰富还是少样本场景,SAMPLE 在宏观 f1 和准确性指标方面都显著优于传统的深度学习和微调方法。
本文的贡献是:
- 我们提出了一个名为 SAMPLE 的框架,它自适应地将 CLIP 模型生成的多模态特征与预先训练的语言模型的文本表示融合在一起,以帮助快速学习来检测假新闻。
- 所提出的框架通过使用预训练 CLIP 模型生成的标准化余弦相似度来调整融合多模态特征的强度,从而缓解了不相关的跨模态语义问题。
- SAMPLE 在两个基准多模式假新闻检测数据集上进行了评估,在资源匮乏和数据丰富的场景中都优于以前的方法。
Related work
假新闻被描述为“通过新闻媒体或互联网以真实新闻为幌子传播以获取政治或经济利益的虚假信息”[30]。 此外,最近的许多研究旨在将虚假内容与类似概念区分开来,例如错误信息[20]和虚假信息[43]。 在这种情况下,错误信息是由于失误或认知偏见而产生的虚假信息,而虚假信息是故意捏造的,在这两种情况下,其形式并不限于新闻媒体。
单模态虚假新闻检测
对单模态 FND 的早期研究通常使用手工特征来识别帖子文本或图像中的异常情况。 传统的图像篡改检测方法[8]可以有效地检测新闻图像的篡改行为。 这些方法从假新闻中学习图像取证、语义、统计和上下文特征。 假新闻的特点通常是违反常识的语义不一致[24],以及图像质量差[14]。 在文本模式中,之前的研究 [32] 设计了一个模块化工具 MedOSINT 来识别与 Covid-19 相关的假新闻。 王等人[45]提出了一种双层次压缩学习框架,其中包括多种数据增强策略和 FND 的三个对比学习任务。 Khullar 和 Singh [23] 建立了一个联邦学习框架来对假新闻进行分类并维护数据隐私。 虽然单模态 FND 是检测假新闻的可靠基线,但 FND 中各模态的相关性和一致性尚未确定。
多模态虚假新闻检测
先前多模态假新闻检测(FND)的研究通常集中在两种方法:设计复杂网络或利用预先训练的模型作为特征提取器。周等人 [46]提出了SAFE模型,该模型使用Image2Sentence模型将图像转换为文本标题,并扩展Text-CNN模型以从新闻描述中提取文本特征。为了检测假新闻,该模型使用稍微修改的余弦相似性度量来计算文本和视觉信息之间的相关性,然后将其输入分类器。 Meel 和 Vishwakarma [31] 结合了分层注意力网络、图像字幕和取证分析来检测多模式假新闻。
最近,许多研究选择利用预先训练的模型来提取 FND 中的文本和视觉特征。 例如,CAFE [9]采用 BERT 和 ResNet-34 作为分别编码文本和视觉特征的预训练模型。 同样,周等人 [47]提出了FND-CLIP模型,该模型同时使用基于ResNet的编码器、基于BERT的编码器和两个成对的CLIP编码器从图像和文本中提取特征表示。 华等人[18]建立了一种基于 BERT 的反向翻译文本和整个图像多模态模型,具有对比学习和数据增强功能。 静等人[22]设计了一个渐进融合网络来捕获每种模态在不同级别的特征表示,并实现了一个混合器来建立模态之间的连接。
此外,一些研究发现,微调预训练模型也可以产生有竞争力的性能,而不仅仅是将它们用作特征提取器。 例如,Ro-CT-BERT [7] 用专业短语扩展了词汇量,并采用了对抗性训练中激烈的 softmax 损失来提高模型的鲁棒性。 尽管传统的多模态 FND 方法以准确检测假新闻而闻名,但它们通常需要大量人工注释的数据才能有效地训练模型。 此外,虽然在早期阶段检测假新闻可以最大限度地减少其有害影响[40],但 FND 方法仍然受到人工注释数据可用性的限制。
针对于虚假新闻检测的提示学习
近年来,提示学习已成为自然语言处理(NLP)的新范式,并在各种 NLP 任务中表现出与标准微调相当的性能。 例如,朱等人 [48]开发了PLST框架,该框架在短文本分类任务中结合了文本输入和来自开放知识图的外部知识。 韩等人[15]提出了PTR模型,该模型是为多类文本分类而设计的,并使用包含多个子提示的逻辑规则构造提示。 基于提示的模型也被用来帮助假新闻检测(FND)。 例如,El Vaigh 等人 [11] 利用 DistilGPT-2 的基于提示的模型结合多任务学习来检测 MediaEval-2021 中与冠状病毒相关的假新闻。 江等人[19]提出了KPL,通过整合外部知识来检测假新闻。 然而,KPL 依赖于人为设计的提示和语言器,这可能非常耗时且可能不可靠。 此外,它没有解决新闻帖子多模态表示的融合如何增强假新闻检测。
Methodology
所提出的方法旨在利用文本和图像来识别新闻文章的真实性。 多模态 FND 的主要目标是为给定的包含 n n n个单词的文本输入 x = [ w 1 , w 2 , . . . , w n ] x = [\mathcal{w}_1,\mathcal{w}_2,...,\mathcal{w}_n] x=[w1,w2,...,wn]以及 m m m个图像 i = [ i 1 , i 2 , . . . , i m ] i = [i_1,i_2,...,i_m] i=[i1,i2,...,im]的新闻文章分配标准二元分类标签 y ∈ { 0 , 1 } y \in\{0,1\} y∈{0,1},其中 0 代表真实新闻,1 代表假新闻。为了识别与给定新闻文章文本相对应的最相关图像,使用预先训练的 CLIP 模型分别对文本和图像表示进行编码。 在此过程中,仅保留与文本表示具有最高余弦相似度的图像,而丢弃其余图像。这里说明了含有多个图像的帖子的处理方法
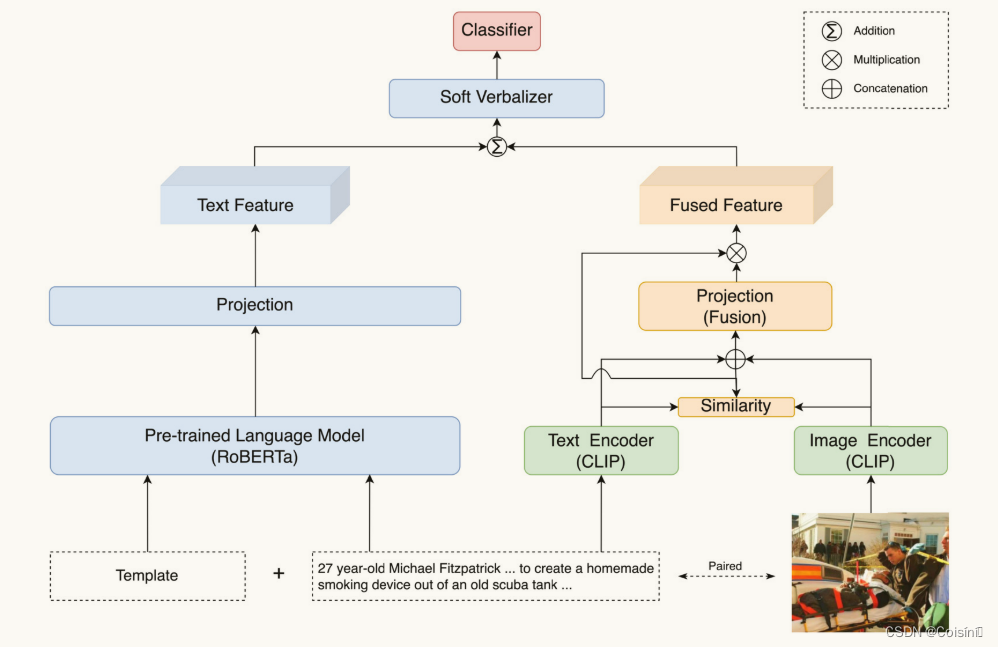
图 2. 用于假新闻检测SAMPLE的整体结构。
离散提示
在本节中,我们利用离散提示[38],它主要对应于自然语言短语并自动搜索离散空间中描述的模板。 此外,我们引入了一个称为连续提示的扩展版本[35],它使用包含预训练语言模型词汇中不存在的伪标记的提示。 我们还采用了混合提示,结合了 FND 的离散提示和连续提示。 最后,我们标准化文本和图像之间的语义相似性来调整融合的多模态表示。 图 2 说明了所提出的 SAMPLE 的整体结构。
我们利用手动构建的离散模板作为提示机制。 为了使模型能够检索被屏蔽的单词,文本输入最初在提示学习阶段被屏蔽。 离散提示涉及通过有限的、人为设计的模板故意扭曲文本输入,并用掩码替换单个关键字。 我们研究了五个不同的离散模板,因为模板的选择可能会对语言模型的性能产生重大影响,如附录 A 所示。离散模板 d t dt dt="This is a news piece with < mask > information"是一个人为设计的模板。接下来,我们通过预训练的语言模型计算与 FND 任务的目标相关的屏蔽词的表示。 为了实现这一点,我们将任意模板 d t dt dt 与初始输入 x x x 连接起来以生成提示, x d = [ d t ; x ] x_d=[dt;x] xd=[dt;x]。随后,计算 x d x_d xd的隐藏状态:

其中, h i d t ( i ∈ [ 1 , m ] ) h^{dt}_i(i\in[1,m]) hidt(i∈[1,m])和 h m a s k d t h^{dt}_{mask} hmaskdt分别是长度为m和< mask >离散模板标记的隐藏向量。 h j x ( j ∈ [ 1 , n ] ) h^x_j(j\in[1,n]) hjx(j∈[1,n])是长度为n的输入文本的隐藏向量, P L M ( ) PLM() PLM()是屏蔽语言模型的输出。
其中, h i d t ( i ∈ [ 1 , m ] ) h^{dt}_i(i\in[1,m]) hidt(i∈[1,m])和 h m a s k d t h^{dt}_{mask} hmaskdt分别是长度为m和< mask >离散模板标记的隐藏向量。 h j x ( j ∈ [ 1 , n ] ) h^x_j(j\in[1,n]) hjx(j∈[1,n])是长度为n的输入文本的隐藏向量, P L M ( ) PLM() PLM()是屏蔽语言模型的输出。
连续提示
尽管离散提示自然地继承了任务描述的可解释性,但它受到在自然语言中嵌入模板词的要求的限制。 此外,离散提示可能不是最理想的,因为预训练的语言模型可能已经从完全不同的上下文中学习了目标知识。 这种手动设计的约束也可以应用于言语生成器,因为手动言语生成器通常基于有限的信息来确定预测。例如,标准语言描述器映射$ fake ⟶ {counterfeit, sham, …, falsify}$,这意味着在推断过程中,只有预测那些与token相关的词才会被认为是正确的,而不管对其他相关词的预测,如“unreal”或“untrue”,这些也具有有用的信息。
为了解决上述问题,通过用连续模板替换可训练标记来重新格式化离散模板 s t st st=“ < s o f t 1 > , < s o f t 2 > , . . . , < s o f t t > , < m a s k > <soft_1>,<soft_2>,...,<soft_t>,<mask> <soft1>,<soft2>,...,<softt>,<mask>”,其中每一个 < s o f t > < soft > <soft>与随机初始化的可训练向量相关联。(三种初始化方法的比较如附录 B 所示。实验结果表明,随机初始化实现了可比的性能,验证损失的收敛速度比其他方法稍快。)

其中, h k s t ( k ∈ [ 1 , t ] ) h^{st}_k(k\in[1,t]) hkst(k∈[1,t])和 h m a s k s t h^{st}_{mask} hmaskst分别是长度为 t t t的隐藏向量和连续模板的 m a s k mask mask标记。
混合提示
最近的研究表明,与单独使用它们相比,采用混合连续和离散模板的混合提示表现出更优越的性能[15]。在此基础上,我们将可训练tokens合并到离散提示模板中。 具体来说,我们在混合模板的开头和结尾插入了两个可训练的tokens, h h e a d m t h^{mt}_{head} hheadmt和 h t a i l m t h^{mt}_{tail} htailmt,表示为
mt = “$<h^{mt}{head}>This\space is\space a\space piece\space of<h^{mt}{mask}>\space news.<h^{mt}_{tail}> $”。
与离散提示类似,新的混合提示 x m = [ m t ; x ] x_m=[mt;x] xm=[mt;x]。 然后我们计算其隐藏状态如下:

其中, h i m t ( i ∈ [ 1 , m ] ) h^{mt}_i(i\in[1,m]) himt(i∈[1,m])和 h m a s k m t h^{mt}_{mask} hmaskmt分别是长度为 m m m的隐藏向量和混合模板的 m a s k mask mask标记。
相似性感知的多模态特征融合
根据之前的研究[47],从预训练模型中提取的文本和图像特征表现出很大的语义差距。 因此,多模态特征的直接融合无法捕获内在的语义相关性。单模态预训练模型,例如 BERT 和 ViT-B-32,倾向于关注琐碎的线索,而不是提取语义上有意义的信息。 BERT 可以更好地从文本输入中学习情感特征,而 ViT-B-32 可以捕获图像中的噪声模式。 因此,即使文本和图像在语义上相关,单模态特征的直接融合也可能会将噪声注入多模态表示中。 相比之下,预先训练的 CLIP 模型利用大量图像-文本对数据集来捕获情感特征或噪声模式之外的语义相关性。
为了有效地整合图像和文本特征,应用预训练的CLIP模型来独立提取这些特征。 CLIP 模型由用于文本编码的文本 Transformer 组成,并采用 Vision Transformer (ViT-B-32) 作为图像编码器。 为了降低编码器提供的粗略特征的维数并消除冗余信息,我们利用单独的投影头 P t x t P_{txt} Ptxt和 P i m g P_{img} Pimg来处理文本和图像特征。每个投影头具有两组全连接层 (FC),后面是批量归一化、修正线性单元 (ReLU) 激活函数和一个 dropout 层。接下来,我们测量 P t x t P_{txt} Ptxt和 P i m g P_{img} Pimg之间的余弦相似度 s i m sim sim来修正融合特征 f f u s e d f_{fused} ffused的强度:

在实验过程中,我们注意到某些新闻帖子,无论其真实性如何,都没有表现出明确的跨模态语义关系。 因此,连接单模态特征以生成融合特征可能会引入噪声,特别是在相似度较低的情况下。 为了解决这个问题,我们应用标准化和 Sigmoid 函数将相似度值限制在 [0 −1] 范围内。标准化涉及在训练期间计算平均值和标准差,从 s i m sim sim中减去运行平均值,然后将结果除以运行标准差。然后可以使用标准化相似度来调整最终跨模式表示的强度 m f u s e d m_{fused} mfused:

软言语器
为了恢复提示模板中的屏蔽单词,使用软语言器将标签映射到其相应的单词。 在本研究中,我们利用 WARP [13] 来识别连续嵌入空间中的最佳提示,其中预先训练的语言模型通过进行搜索来预测屏蔽标记。 我们在上述三种模板类型中使用软语言来比较不同的提示方法。为了确定提示和言语嵌入的最佳参数 θ = { θ P , θ V } \theta=\{\theta^P,\theta^V\} θ={θP,θV},我们首先使用残差连接将掩码语言模型的输出向量添加到调整后的跨模态表示中。 然后将组合输出输入 FC 层:

其中 x ′ x' x′是上面的提示模板之一相连接的输入序列。分类概率 p ( y ∣ x ′ ) p(y|x') p(y∣x′)可以计算为:

其中的C是类别的集合, θ y V \theta^V_y θyV是真实标签的嵌入, θ i V \theta^V_i θiV是预测标签词的嵌入。最后,交叉熵损失可以最小化为:

Experiment
我们在资源匮乏和数据丰富的场景中在两个基准 FND 数据集上评估了我们提出的方法。 本节的第一部分概述了基准多模式 FND 数据集,包括其统计数据。 在第二部分中,我们解释了数据丰富和少样本设置的实现细节。 最后,我们对我们提出的方法以及基线模型进行了详细的讨论和分析。
数据
我们使用两个可公开访问的数据集来检测虚假信息,即 PolitiFact 和 GossipCop,它们分别包含政治新闻和名人八卦,并包含在 FakeNewsNet 项目中 [39]。 使用提供的数据爬行脚本,我们从 PolitiFact 检索了 1,056 条新闻,从 GossipCop 检索了 22,140 条新闻。为了减少冗余,对于具有多个图像的新闻,我们仅根据文本和图像的余弦相似度保留最相关的图像。 没有图像或图像 URL 无效的新闻将被排除。 结果数据集统计数据如表 1 所示。

实施细节
采用 HuggingFace 库中预训练的 RoBERTa 作为快速学习的主要模块。 应用来自预训练 CLIP (ViT-B-32) 模型的文本和图像编码器来提取各自的特征。 隐藏层投影层的大小设置为768,dropout率为0.6。 我们使用 AdamW 优化器来优化模型参数,学习率为 3e−5,衰减参数为 1e−3,这两个参数都是根据经验确定的。 该模型经过 20 个 epoch 的训练,我们选择能够产生最佳验证性能的模型检查点来进行测试。 我们在少样本和数据丰富的设置中评估该方法。
在少样本设置中,我们的模型是使用从数据集中随机抽样的少量实例( n n n)进行训练的。具体地说,我们考虑 n ∈ [ 2 , 4 , 8 , 16 , 100 ] n∈[2,4,8,16,100] n∈[2,4,8,16,100] 。其余实例用于测试。此外,还会创建与训练集大小相同的验证集用于模型选择。PolitiFact 数据集包含数量有限的新闻条目。 为了解决这一限制,我们采用了一种称为 PolitiFact 100-shot 设置的特定配置。 在此配置中,我们分配 100 个实例用于训练,50 个实例用于开发目的。 由于训练集和验证集质量对模型性能的显着影响,我们使用不同的随机种子重复上述数据采样方法五次。然后,我们计算平均分数(排除最高和最低分数),以评估模型在少样本设置中的性能。 对于训练集和验证集,我们确保训练阶段标记实例的平衡分布。
在数据丰富的情况下,两个数据集被分为三部分,即训练集、验证集和测试集,分割比例为8:1:1。 为了评估所提出模型的稳定性,我们使用不同的随机种子重复上述数据采样过程五次。 我们报告平均分数,计算为从五次运行中去除最高和最低分数后的分数平均值。
基线模型
我们将所提出的 SAMPLE 模型与之前在 FND 数据集上实现了最先进性能的几个模型进行了比较。 具体来说,我们的比较涉及单模态方法 (1-2)、多模态方法 (3-6) 和标准微调方法 (7)。 为了初始化单词嵌入,我们利用在 60 亿个单词的语料库上训练的预训练 100 维 GloVe 嵌入 [34]。
- (1) LDA-HAN [21]:该模型将潜在狄利克雷分配(LDA)[3]主题分布纳入分层注意力网络中。
- (2) T-BERT [2]:这种基于特征的方法使用级联三重 BERT 模型来预测假新闻。
- (3) SAFE [46]:该模型将图像转换为其文本描述,并利用文本和视觉信息之间的相关性来检测假新闻。
- (4) RIVF[44]:该模型利用VGG和BERT模型对图像和文本特征进行编码。 它将缩放点积注意力机制应用于融合的多模态特征来捕获文本和图像之间的关系。
- (5) SpotFake[42]:该模型使用预训练的图像模型VGG和BERT来提取各自的图像和文本特征,将它们连接起来以对假新闻进行分类。
- (6) CAFE [9]:该模型使用模糊感知多模态方法来自适应聚合单模态特征和相关性。
- (7) FT-RoBERTa:这是预训练语言模型 RoBERTa 的标准、微调版本。
结果
表2.基线和多模态提示学习框架之间的整体宏观 F1 和准确性。 D-SAMPLE、C-SAMPLE 和 M-SAMPLE 分别表示所提出的 SAMPLE 框架中的离散提示、连续提示和混合提示。
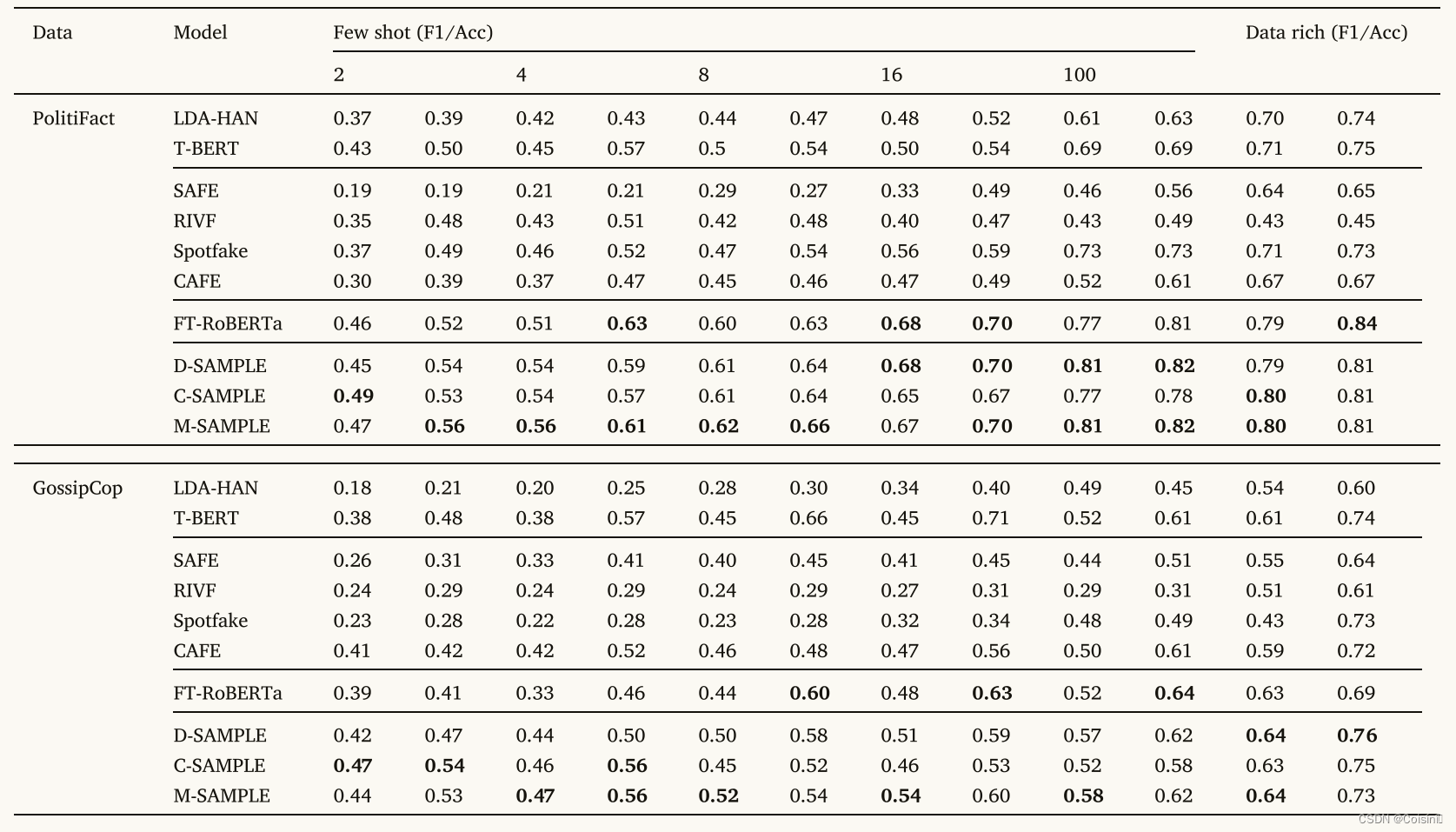
表 2 显示了将所提出的 SAMPLE 框架与微调方法、多模态和单模态 FND 方法进行比较的总体结果。
与微调相比。 首先,我们通过评估各自的 F1 分数来研究标准微调 RoBERTa (FT-RoBERTa) 和提议的 SAMPLE 的性能。我们计算 M-SAMPLE 的平均改进(即 ( 0.44 − 0.39 ) + . . . ( 0.58 − 0.52 ) 5 × 2 + ( 0.47 − 0.46 ) + . . . ( 0.81 − 0.77 ) 5 × 2 \frac{(0.44−0.39)+...(0.58−0.52) }{5×2}+ \frac{(0.47−0.46)+...(0.81−0.77)}{ 5×2 } 5×2(0.44−0.39)+...(0.58−0.52)+5×2(0.47−0.46)+...(0.81−0.77)),C-SAMPLE 和 D-SAMPLE 优于 FT-RoBERTa,发现所有 SAMPLE 方法分别优于 FT-RoBERTa 0.05、0.024 和 0.035。随着训练样本数量的减少,这种改进更加显着,凸显了在资源匮乏的场景下即时学习的优越性。
然而,在数据丰富的情况下,改进变得更小,其中 F1 的平均改进分别为 0.005、0.005 和 0.01,这表明 FT-RoBERTa 在训练数据充足时能够实现可比的性能。 SAMPLE 方法和 FT-RoBETRa 之间的准确性比较与上述观察结果一致,证明了所提出的方法在利用 PLM 信息方面的优越性,特别是在训练数据稀缺的情况下。 然而,在数据丰富的环境中,标准微调方法仍然可以作为可靠的基线。
与多模态方法进行比较。 我们与之前的多模态 FND 方法相比评估了 SAMPLE 的性能。 我们的结果表明,无论是多模态还是单模态方法,SAMPLE 的 F1 和准确度得分在所有设置中都优于以前的方法。 例如,在 PolitiFact 数据集上进行评估时,与 CAFE 相比,M-SAMPLE 在 100 个样本设置中实现了高达 0.29 秒的显着改进。 这一改进主要归功于 CLIP 模型的学习方法,它利用大量的图像文本对来学习多模态语义的提取。 相反,CAFE 常用的预训练模型(如 BERT 和 ResNet-34)可能无法有效捕获以异构特征分布为特征的单模态特征。
不同提示模板的分析。 结果表明,混合提示 (M-SAMPLE) 优于 C-SAMPLE 和 D-SAMPLE,F1 的平均改进分别为 0.04 和 0.02。 这一发现表明,连续提示不如离散和混合提示方法。 具体来说,C-SAMPLE 的使用可能无法提供足够的先验人类知识来帮助语言表达者从连续空间中捕获标签词。
总体而言,实验结果表明,无论采用少镜头还是数据丰富的设置,所提出的 SAMPLE 方法在多模态 FND 任务中都表现出优越的性能。
分析
本小节在少样本和数据丰富的设置中对所提出的 SAMPLE 方法进行了全面分析。 首先,评估图像模态的重要性。 接下来,给出了所提出的模型在各种数据设置下的标准差。 消融研究进一步检查了 SAMPLE 的关键组成部分。 最后,我们可视化并比较不同基线模型生成的嵌入。
图像模态的影响
将图像和文本特征之间的语义相似性集成到 SAMPLE 中的多模态表示中,可以自动调整跨多种模态的相关性。 然而,该方法不允许直接测量图像模态的有效性。
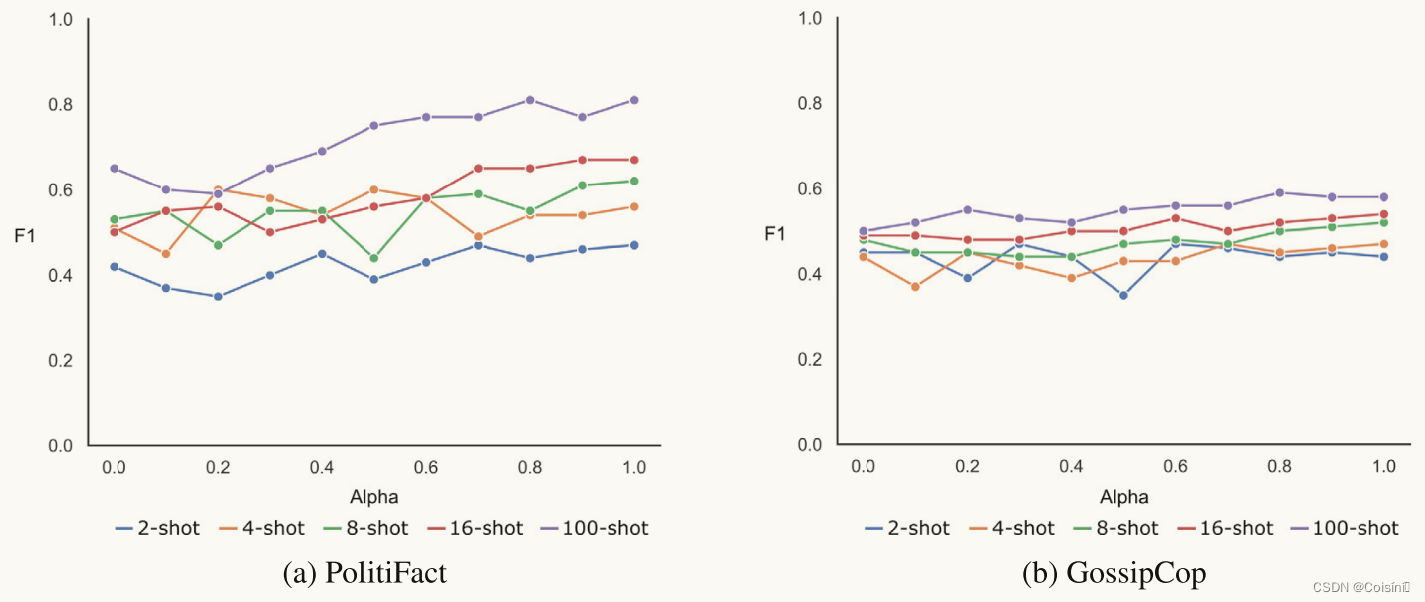
图 3. 所提出框架中图像模态的重要性。
为了理解视觉模态对模型推理的影响,我们引入了一个可调节参数,参数 α \alpha α,来调节视觉模态在少样本训练过程中的参与程度。准确地说,融合的多模态特征乘以 α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1]。将 α \alpha α设置为0会消除视觉模态的贡献,而将 α \alpha α设置为1则充分利用图像和文本两个模态。在这个实验中,我们应用了M-SAMPLE,它实现了最高的F1。 根据图 3 所示的结果,随着 α \alpha α的增加,M-SAMPLE 获得了更高的 F1,这表明视觉模态的参与可以增强模型性能。然而,我们也观察到包含视觉模态会导致 F1 下降的情况,特别是当训练样本数量相对较小时,例如在 2-shot、4-shot 和 8-shot 设置中。 这表明,当与其他模态的相关性有限时,视觉模态特征的存在可能会对少样本设置中的整体性能产生不利影响。
稳定性测试
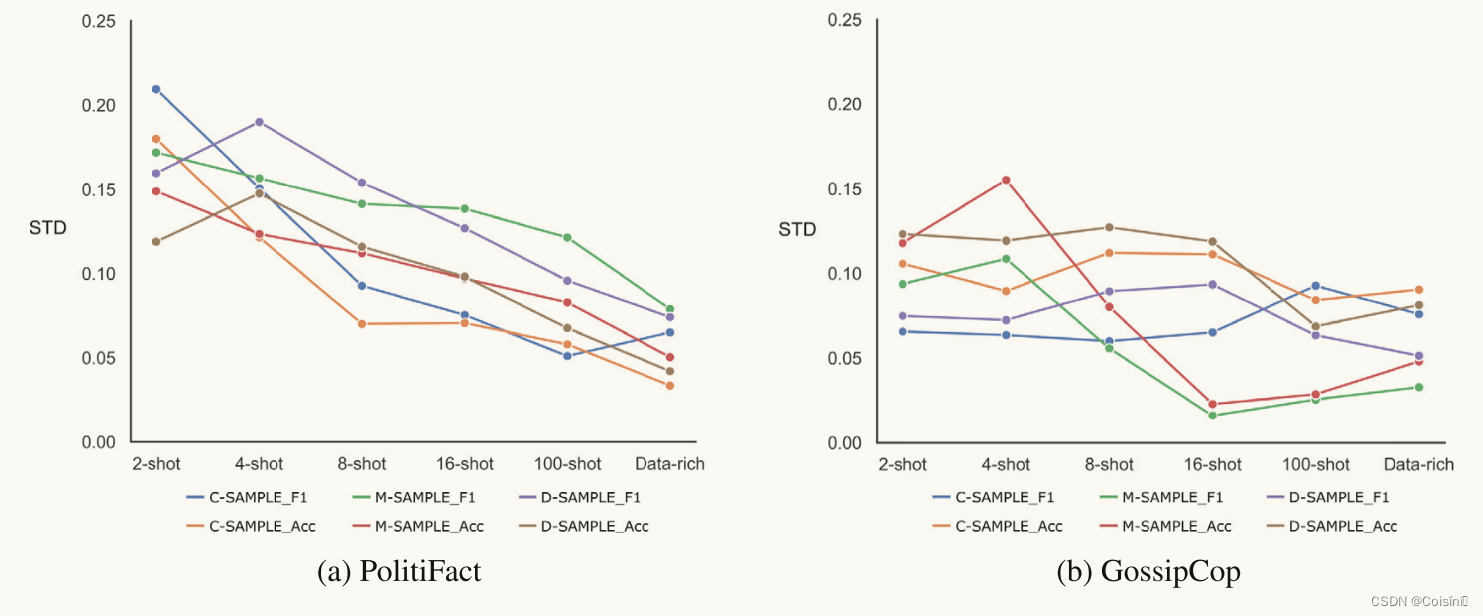
图 4. 所提出框架中 F1 的标准差和准确度。
在本研究中,我们通过测量少样本和数据丰富设置中 F1 的标准差和准确性来评估 SAMPLE 模型的稳定性。 如图 4 所示,我们展示了对每个样本模型进行的上述五次实验的平均标准差。 我们观察到标准差随着训练样本数量的增加而减小,特别是在 PolitiFact 数据集中,如图 4a 所示。 此外,GossipCop 数据集比 PolitiFact 数据集相对更不稳定,如图 4b 所示。 这可能归因于 GossipCop 中语义的复杂性,这也导致所有模型的 F1 分数和准确性较低。
多模态融合策略
附录C:CLIP 与预训练单模态模型进行特征提取的比较
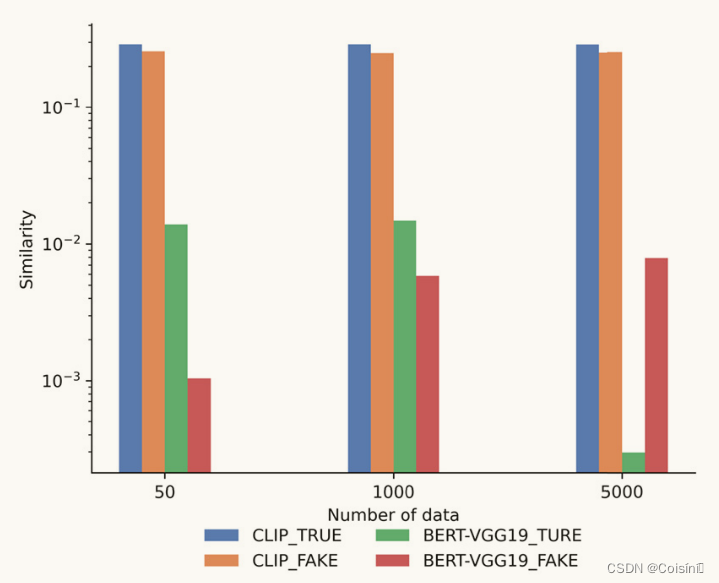
图 7. 预训练模型之间的对数尺度语义相似度比较。
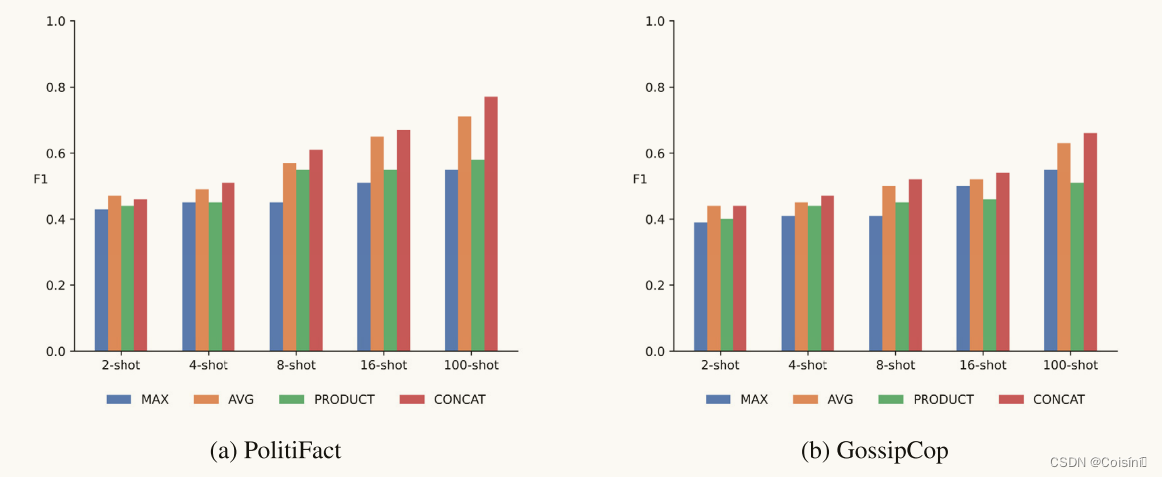
图 5. 不同多模态融合策略的比较。
如图5所示,我们使用M-SAMPLE来评估各种多模态融合方法对模型性能的影响。 具体来说,比较了四种基于规则的融合策略 [1] 的 F1 分数。 利用基于规则的融合策略背后的动机植根于 CLIP 模型在单模态特征之间生成有效时间对齐的能力 [47],如附录 C 所示。具体来说,符号“MAX”表示使用 最大池化层。 类似地,“AVG”表示通过平均池化层进行融合。 另一方面,“PRODUCT”表示多模态特征是通过所有单模态特征的元素乘积形成的。 最后,“CONCAT”意味着将单模态特征串联起来以创建多模态特征。 结果表明,在少样本设置中,与其他融合策略相比,两个单模态特征的串联可以产生更好的 F1 分数。
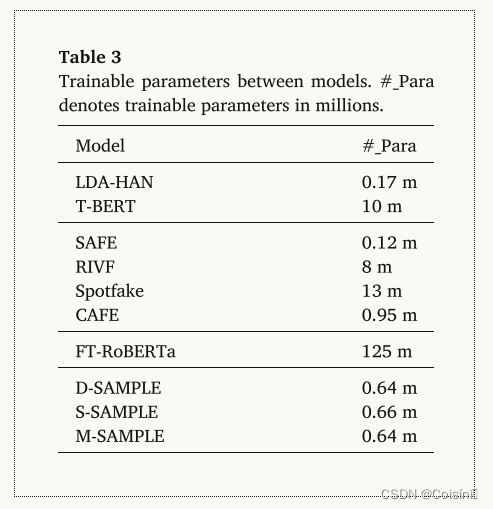
可训练参数比较
我们比较了基线和 SAMPLE 之间的可训练参数数量,如表 3 所示。SAMPLE 框架中的可训练参数相当小,大部分来自语言器和模板。 相比之下,当对整个模型进行完全微调时,FT-RoBERTa 具有最多数量的可训练参数。 因此,与微调相比,即时学习需要更低的计算成本,同时仍能获得与其他深度学习方法相当的结果。
消融实验
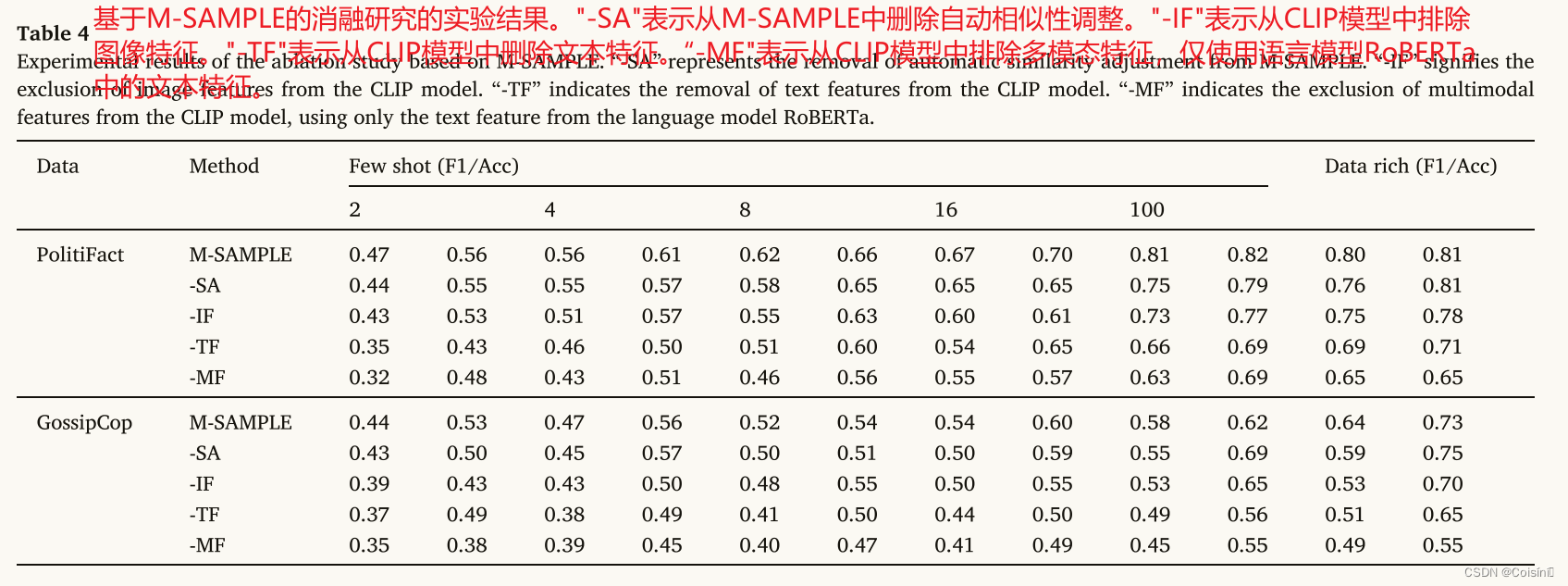
我们通过评估 SAMPLE 框架在各种部分配置下的性能来检查 SAMPLE 框架中关键组件的影响。 我们采用 M-SAMPLE,在每次测试中删除不同的组件,并从头开始训练框架。 表 4 中的结果表明,当在大多数测试设置中移除 M-SAMPLE 的任何组件时,M-SAMPLE 的性能会下降。 这表明了 SAMPLE 中每个单独关键模块的有效性。 具体来说,我们发现当删除自动相似性调整“-SA”时,性能略有下降。 这一观察结果凸显了在多模态特征融合中标准化语义相似性的重要性。 这样做有助于减少假新闻分类中的不相关信息,同时还可以减轻不同模态的多模态特征带来的噪音。
此外,与在框架内删除图像特征(“-IF”)相比,从 CLIP 中删除文本特征(“-TF”)通常会导致 F1 分数和准确性较低。 我们的研究结果表明,虽然图像模态被证明在 FND 中很有价值,如图 3 所示,但值得注意的是,文本特征在提示学习过程中仍然至关重要。 这主要是由于提示学习的训练目标,其重点是从模板中恢复屏蔽标记。 该目标主要与从预训练模型中提取的文本特征保持一致并利用。 从不同的预训练模型 RoBERTa 和 CLIP 中提取两个文本特征,为分类器提供了更加多样化和更具表现力的文本信息。 另一方面,图像特征的主要作用是最小化不同模态之间的差异可能产生的噪声。
当从 CLIP 模型获得的融合多模态特征(“-MF”)被删除时,所提出的框架归结为提示学习方法的普通版本,该方法利用预先训练的语言模型来直接预测 FND。 分析结果表明,即使是基本的提示学习方法也可以优于仅依赖文本特征的单模态方法。 这一观察结果强调了 FND 中提示学习的优越性。
T-SNE可视化

图 6. 在分类器之前从 M-SAMPLE、D-SAMPLE、C-SAMPLE、RoBERTa、CAFE、SPOTFAKE、T-BERT 和 LDA-HAN 在 2-PolitiFact 测试集上学习的特征的 T-SNE 可视化2-shot设置。
如图 6 所示,在 2-shot 设置的 PolitiFact 测试集上分析了分类器之前学习到的特征。假新闻和真实新闻的降维特征表示由红点和蓝点表示。 从图 6a、图 6b 和图 6c 中,我们注意到与 D-SAMPLE 和 C-SAMPLE 相比,M-SAMPLE 的边界似乎更加清晰。 这表明 M-SAMPLE 中学习到的特征表示更具辨别力。 虽然 FT-RoBERTa 在 F1 和准确度方面表现出相当的性能,但它确实在 2-shot 设置中显示了一些明显的错误分类实例。 此外,与 SAMPLE 相比,FT-RoBERTa 中学习到的特征表示往往更稀疏,如图 6d 所示。 这意味着在少样本场景中,多模态特征和即时学习方法的组合优于标准微调方法。 我们还可视化了 CAFE 和 SPOTFAKE 的特征表示,如图 6e 和图 6f 所示。 分析表明,与即时学习和微调方法相比,错误分类实例的数量明显更高。 此外,我们的研究结果表明,T-BERT 和 LDA-HAN 等单峰方法表现出最多的错误分类实例。 这表明,与仅依赖文本特征相比,结合多模态特征可以捕获更具表现力的信息,如图 6g 和图 6h 所示。
Discussion
所提出的 SAMPLE 框架将多个提示学习模板与软语言器集成在一起,以便能够在少量样本和数据丰富的环境中自动检测假新闻。 首先,本节首先分析我们的方法与现有研究之间的关系。 接下来,我们详细阐述所提出的 SAMPLE 方法如何对 FND 领域产生积极影响并为实际应用提供支持。 最后,本文讨论了我们方法的局限性,并概述了未来工作的潜在途径。
与前人作品的联系和比较
无论是在少量样本还是数据丰富的场景中,SAMPLE 在检测假新闻方面都表现出了令人满意的性能。 当将SAMPLE与FND领域的其他方法进行比较时,传统方法可以分为三类:(1)仅基于文本或图像特征的单模态方法[6,8]; (2)通过预训练模型或深度学习表示来同化文本和视觉特征的多模态方法[44]; (3)标准微调方法,使用特定任务的数据微调预先训练的单峰模型[33]。
在本研究中,SAMPLE 包含 (2) 和 (3) 的混合方法。 然而,由于它利用了提示学习算法,因此它与标准微调方法不同。 尽管微调有可能实现最佳性能,但它会消耗大量内存。 这是因为微调会更新整套模型参数,以满足特定任务的目标。 相比之下,提示学习利用自然语言提示来查询语言模型,保持了与预训练类似的目标,同时显示出可比较的性能,特别是在有限的训练实例中。 通过将标准微调的结果与SAMPLE的结果进行比较,实验结果证实了上述推理,如表2所示。
先前的多模态方法,例如 CAFE 和 SAFE,依赖于外部跨模态模块来对齐和测量不同的单模态特征。 然而,此类外部模块需要足够数量的训练实例来捕获跨模态相关性,这通常会导致性能不足,特别是在少数样本设置中。 我们的新颖提案引入了一种相似性感知的多模态特征融合方法,该方法利用了 CLIP 的预训练策略。 CLIP 利用大量图像-文本对来学习多模态语义的集成。 此外,跨模态特征相关性的标准化结合了 Sigmoid 函数来确定文本和图像输入之间的语义相似性。 进行了消融研究,以研究我们在少样本设置中的方法,如表 4 所示。结果清楚地表明少样本性能的显着改善,这归因于提示学习和所提出的相似性感知多模态融合过程的结合。
对未来研究的贡献
我们引入了一种新颖的 FND 框架 SAMPLE,用于通过提示学习来识别假新闻。 尽管提示学习在众多分类任务中表现出了高性能,但不同提示策略与多模态特征的集成仍有待探索。 本文提出了一种有前途的方法,该方法取得了令人印象深刻且稳健的结果,并且可以作为多模式 FND 未来研究的重要基线。
传统的多模态 FND 系统通常需要大量的训练数据才能达到令人满意的性能水平。 然而,在现实环境中获取带注释的数据具有挑战性。 本文证明 SAMPLE 提供了可比较的结果,特别是在少数样本场景中,表明其在现实情况下检测假新闻的能力。 此外,所提出的将相似性感知多模态特征与提示学习相融合的方法对于未来类似性质的分类任务具有潜力。
局限性和未来的工作
本研究有几个局限性。 首先,SAMPLE 主要关注研究软语言表达器的效果,该语言器旨在自动从词汇表中识别适当的标签词。 然而,在低数据条件下优化更广泛词汇量的软语言器仍然是一个相当大的挑战。 这表明需要额外的自适应修改来提高整体性能。 其次,新提出的基于相似性感知策略的多模态融合方法,旨在减少相关性较弱的跨模态特征中的噪声注入。 它没有明确考虑不相关的跨模态关系。 第三,仍然需要进一步探索包含不同模式的多模态FND 方法,例如新闻实体和社交网络。
多项研究表明,语言表达者的选择对表现有很大影响。 手动语言器[38]尤其依赖于特定于任务的先验知识,并且需要大量的劳动来识别代表类别的标签词。 另一方面,尽管软语言器[12]旨在简化这一过程,但在低数据环境中针对大词汇量有效优化它仍然具有挑战性。 此外,知识丰富的提示调整方法[17]利用外部知识库来扩大标签词的覆盖范围,并减少与手动语言器相关的偏差。 研究不同言语者的影响将是我们未来工作的一部分。 此外,整合新闻实体、主题和社交网络等其他模式有可能在未来进一步扩展多模态融合方法。
Conclusion
本文提出了一种新颖的相似性感知多模态 FND 框架,名为 SAMPLE,它利用提示学习。 为了缓解数据不足的问题,SAMPLE 对原始输入文本结合了三种流行的提示模板:离散提示、连续提示和混合提示。 采用预训练的语言模型 RoBERTa 从提示中获取文本特征。 此外,使用预训练的 CLIP 模型来获取输入文本、图像及其语义相似度。 为了解决语义差距并改善图像和文本模态之间的协作,我们引入了一种相似性感知的多模态特征融合方法,该方法应用标准化和 Sigmoid 函数来调整最终跨模态表示的强度。 最后,将多模态特征输入全连接层来投影并获得与特定新闻类别相对应的词分布。
我们在两个基准数据集上进行了多模态 FND 实验来评估所提出的方法。 SAMPLE 的性能与单模态、多模态和标准微调方法进行了广泛的比较。 我们的实验结果表明,无论是少量样本还是数据丰富的设置,SAMPLE 的性能都优于以前的方法。 此外,我们的结果表明,尽管图像模态提供了有意义的信息,但不相关的跨模态特征会对 FND 性能产生负面影响,特别是当训练实例数量有限时。 此外,我们方法的每个组成部分,特别是标准化的多模态特征融合模块,有助于来自预训练模型的单模态特征更有效地协作,挖掘 FND 的关键特征。
我们评估了来自各种预训练模型的文本和图像特征之间的语义相似性。 具体来说,我们应用 BERT 模型和 VGG-19 从每个训练样本中提取特征。 随后,计算平均相似度分数,以评估真实新闻和假新闻之间的语义相似度。 类似地,我们使用 CLIP 文本转换器和视觉转换器来提取单峰特征并计算它们的语义相似度。 我们还增加了样本数量来观察语义相似度的任何变化。 最后,为了准确地表示单峰模型之间的微小差异,我们对轴上的值进行对数缩放。
我们的实验结果表明,与从单模态模型获得的文本和图像特征相比,从 CLIP 模型提取的文本和图像特征表现出更高的一致性,如图 7 所示。这可以归因于 CLIP 通过联合训练和学习多模态表示的能力。 它利用对比损失函数,有助于区分相关对和不相关对。 结果,无论样本数量多少,真实新闻(CLIP_TRUE)的语义相似度始终高于假新闻(CLIP_FAKE)。 相比之下,BERT-VGG19组合分别从文本和图像中提取特征,这可能会在特征提取过程中引入更多噪声。
附录A:离散模板的提示工程
为了评估各种模板对性能的影响,我们创建了离散模板,如表 5 所示。由于即时工程涉及的时间和成本,我们在本文中将我们的研究限制为仅五个离散模板。 随后,我们选择获得最高 F1 分数的离散模板作为我们实验中的最终模板。

附录B:连续模板的不同初始化方法的比较
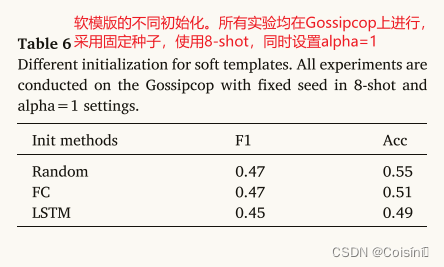
该研究比较了连续模板中<𝑠𝑜𝑓𝑡>标记的三种初始化方法,如表6所示。“随机”初始化方法即随机初始化<𝑠𝑜𝑓𝑡>标记。“FC”方法用另一个可训练矩阵重新参数化 <𝑠𝑜𝑓𝑡 > 标记,并通过 FC 层向前传播它[25]。“LSTM”方法通过 LSTM 层提供 < 𝑠𝑜𝑓𝑡 > token,并将输出用作可训练向量 [28]。尽管三种初始化方法在 F1 和精度方面的表现略有不同,但研究还观察到,与“随机”初始化相比,“FC”和“LSTM”初始化导致验证损失较晚收敛。 这是由于需要额外的训练来获得 < 𝑠𝑜𝑓𝑡 > 向量。
相关文章:
[Information Sciences 2023]用于假新闻检测的相似性感知多模态提示学习
推荐的一个视频:p-tuning P-tunning直接使用连续空间搜索 做法就是直接将在自然语言中存在的词直接替换成可以直接训练的输入向量。本身的Pretrained LLMs 可以Fine-Tuning也可以不做。 这篇论文也解释了为什么很少在其他领域结合知识图谱的原因:就是因…...

自定义vue3 hooks
文章目录 hooks目录结构demo hooks 当页面内有很多的功能,js代码太多,不好维护,可以每个功能都有写一个js或者ts,这样的话,代码易读,并且容易维护,组合式setup写法与此结合👍&#…...
《昇思25天学习打卡营第21天 | 昇思MindSporePix2Pix实现图像转换》
21天 本节学习了通过Pix2Pix实现图像转换。 Pix2Pix是基于条件生成对抗网络(cGAN)实现的一种深度学习图像转换模型。可以实现语义/标签到真实图片、灰度图到彩色图、航空图到地图、白天到黑夜、线稿图到实物图的转换。Pix2Pix是将cGAN应用于有监督的图…...
【文档+源码+调试讲解】科研经费管理系统
目 录 目 录 摘 要 ABSTRACT 1 绪论 1.1 课题背景 1.2 研究现状 1.3 研究内容 2 系统开发环境 2.1 vue技术 2.2 JAVA技术 2.3 MYSQL数据库 2.4 B/S结构 2.5 SSM框架技术 3 系统分析 3.1 可行性分析 3.1.1 技术可行性 3.1.2 操作可行性 3.1.3 经济可行性 3.1…...

linux 下 rm 为什么要这么写?
下面代码中的rm 为什么要写成/bin/rm? 大文件清理,高宿主含量样本可节约>90%空间/bin/rm -rf temp/qc/*contam* temp/qc/*unmatched* temp/qc/*.fqls -l temp/qc/ 这是一个很好的问题,观察很仔细, 也带着了自己的思考。 rm是 Linux 下的一个危险…...

【Spring Boot】Spring AOP中的环绕通知
目录 一、什么是AOP?二、AOP 的环绕通知2.1 切点以及切点表达式2.2 连接点2.3 通知(Advice)2.4 切面(Aspect)2.5 不同通知类型的区别2.5.1 正常情况下2.5.2异常情况下 2.6 统一管理切点PointCut 一、什么是AOP? Aspect Oriented Programmingÿ…...
docker部署前端,配置域名和ssl
之前使用80端口部署前端项目后,可以使用IP端口号在公网访问到部署的项目。 进行ICP域名备案后,可以通过域名解析将IP套壳,访问域名直接访问到部署的项目~ 如果使用http协议可以很容易实现这个需求,对nginx.conf文件进行修改&#…...
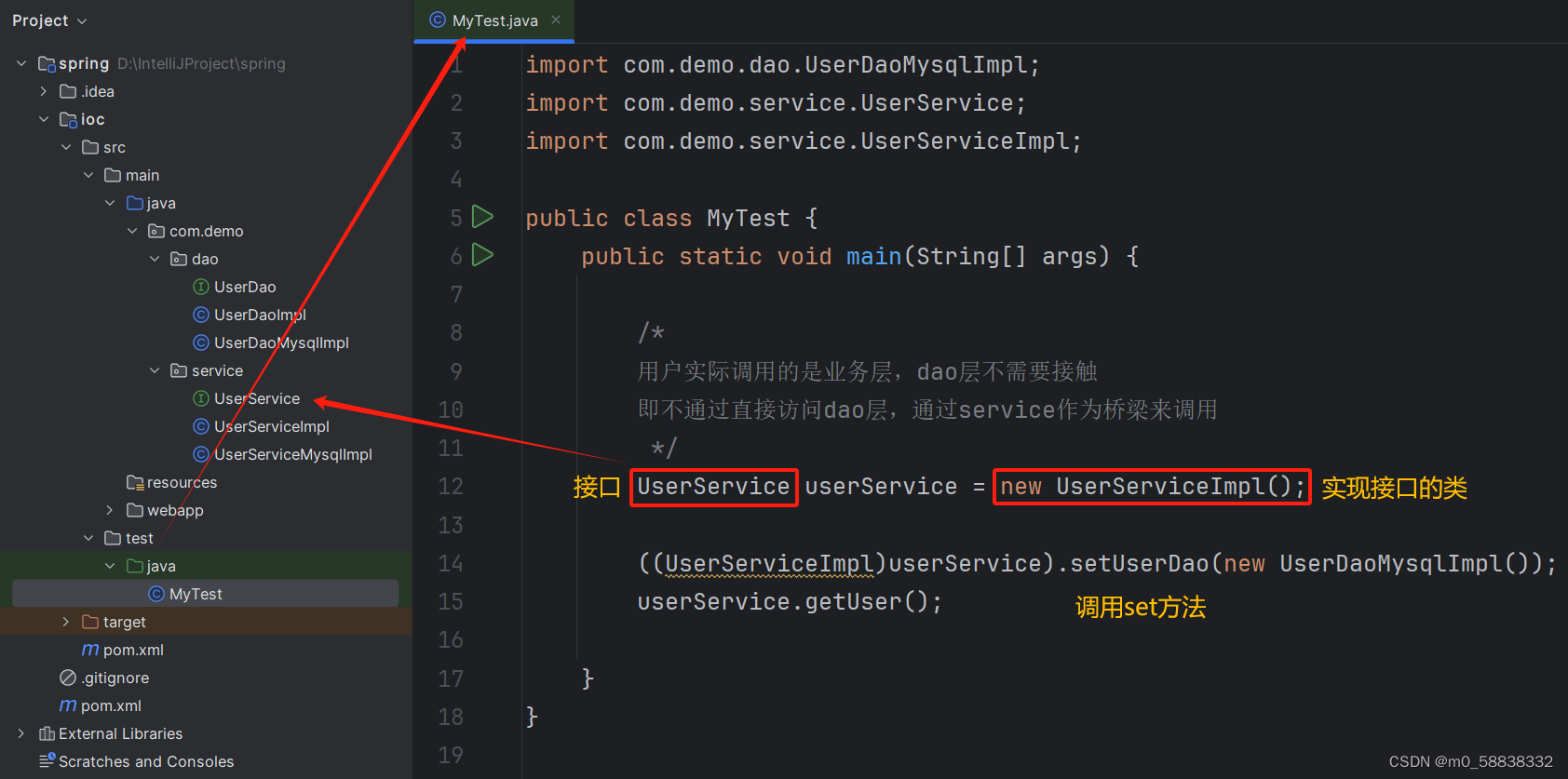
初学Spring之 IOC 控制反转
Spring 是一个轻量级的控制反转(IOC)和面向切面编程(AOP)的框架 导入 jar 包:spring-webmvc、spring-jdbc <dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc&…...

rpc的仅有通信的功能,在网断的情况下,比网通情况下,内存增长会是什么原因
RPC(Remote Procedure Call,远程过程调用)主要负责在分布式系统中透明地调用远程服务,就像调用本地函数一样。它封装了网络通信的细节,使得开发者可以专注于业务逻辑而非底层通信协议。RPC通信通常包括序列化、网络传输…...

从零开始:如何设计一个现代化聊天系统
写在前面: 此博客内容已经同步到我的博客网站,如需要获得更优的阅读体验请前往https://mainjaylai.github.io/Blog/blog/system/chat-system 在当今数字化时代,聊天系统已成为我们日常生活和工作中不可或缺的一部分。从个人交流到团队协作,从客户服务到社交网络,聊天应用…...

香橙派OrangePi AIpro初体验:当小白拿到一块开发板第一时间会做什么?
文章目录 香橙派OrangePi AIpro初体验:当小白拿到一块高性能AI开发板第一时间会做什么前言一、香橙派OrangePi AIpro概述1.简介2.引脚图开箱图片 二、使用体验1.基础操作2.软件工具分析 三、香橙派OrangePi AIpro.测试Demo1.测试Demo1:录音和播音(USB接口…...
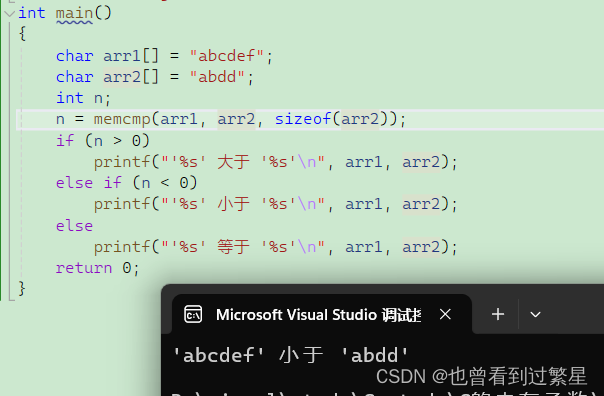
【C语言内存函数】
目录 1.memcpy 使用 模拟实现 2.memmove 使用 模拟实现 3.memset 使用 4.memcmp 使用 1.memcpy 使用 void * memcpy ( void * destination, const void * source, size_t num );目的地址 源地址 字节数 destination:指向要复制内…...
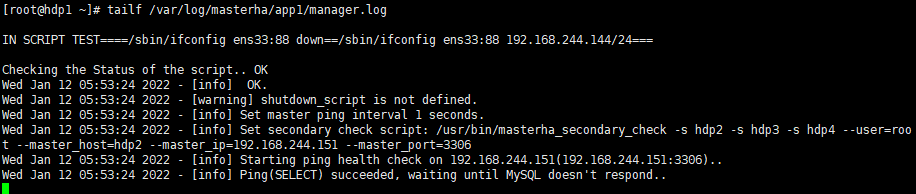
Mysql部署MHA高可用
部署前准备: mysql-8.0.27下载地址:https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-8.0.27-1.el7.x86_64.rpm-bundle.tar mha-manager下载地址:https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-mana…...
【算法学习】射线法判断点在多边形内外(C#)以及确定内外两点连线与边界的交点
1.前言: 在GIS开发中,经常会遇到确定一个坐标点是否在一块区域的内部这一问题。 如果这个问题不是一个单纯的数学问题,例如:在判断DEM、二维图像像素点、3D点云点等含有自身特征信息的这些点是否在一个区域范围内部的时候&#x…...

SQL语句(DML)
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增删改等操作 DML-添加数据 insert into employee(id, workno, name, gender, age, idcard) values (1,1,Itcast,男,10,123456789012345678);select *…...

uniapp小程序打开地图导航
uniapp uni.getLocation({type: gcj02, //返回可以用于uni.openLocation的经纬度success: function (res) {const latitude res.latitude;const longitude res.longitude;uni.openLocation({latitude: latitude,longitude: longitude,success: function () {console.log(suc…...
webstorm格式化或保存时 vue3引入的组件被删除了
解决办法 保存时设置 格式化设置...

Java时间转换
一、线程不安全 Date date new Date(); SimpleDateFormat dateFormat new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String prefix dateFormat.format(date);二、线程安全,建议使用 String t1 LocalDateTime.now().format(DateTimeFormatter.ofPattern("y…...

Spring Boot与WebFlux的实战案例
Spring Boot与WebFlux的实战案例 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将探讨如何利用Spring Boot和WebFlux构建响应式应用的实战…...

vue3引入本地静态资源图片
一、单张图片引入 import imgXX from /assets/images/xx.png二、多张图片引入 说明:import.meta.url 是一个 ESM 的原生功能,会暴露当前模块的 URL。将它与原生的 URL 构造器 组合使用 注意:填写自己项目图片存放的路径 /** vite的特殊性…...

POE是什么?
POE 一般指 Power over Ethernet(以太网供电)。 通俗理解 用 一根网线(RJ45) 同时做两件事: 传数据(上网、通信) 给设备供电(不用单独再接电源适配器) 常见场景:IP 摄像头、无线 AP、部分 Orange Dongle / 底座,实验室用 PoE 交换机或 PoE 适配器 给 Dongle 供电…...

容器镜像深度分析:Quaid工具的设计原理与DevOps实践
1. 项目概述:Quaid,一个为现代开发者打造的容器镜像分析利器如果你和我一样,日常工作中需要频繁地处理Docker镜像,无论是进行安全审计、优化镜像体积,还是单纯地想搞清楚一个镜像里到底“藏”了什么,那你一…...

跨境电商团队如何用Taotoken调用AI模型批量生成多语言商品描述
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 跨境电商团队如何用Taotoken调用AI模型批量生成多语言商品描述 对于跨境电商运营团队而言,为海量商品生成不同语言版本…...

别再照搬教科书了!聊聊西门子温度模块里那个‘奇怪’的热电偶采样电路
西门子温度模块热电偶采样电路的设计玄机:为何打破教科书常规? 第一次拆解西门子S7-1200系列温度模块时,我的目光被热电偶输入电路牢牢钉住了——这个电路竟然没有按照教科书上的经典差分放大结构来设计!更令人困惑的是࿰…...

Open3D内存检测终极指南:LeakSanitizer的完整应用教程
Open3D内存检测终极指南:LeakSanitizer的完整应用教程 【免费下载链接】Open3D Open3D: A Modern Library for 3D Data Processing 项目地址: https://gitcode.com/gh_mirrors/op/Open3D Open3D作为现代3D数据处理库,在处理大规模点云、网格等数据…...

JSON Lint for PHP:如何构建企业级JSON数据验证解决方案?
JSON Lint for PHP:如何构建企业级JSON数据验证解决方案? 【免费下载链接】jsonlint JSON Lint for PHP 项目地址: https://gitcode.com/gh_mirrors/jso/jsonlint 在现代Web开发和API设计中,JSON数据验证是确保系统稳定性的关键环节。…...

百度网盘直链解析终极指南:5分钟告别限速下载的完整教程
百度网盘直链解析终极指南:5分钟告别限速下载的完整教程 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘那令人崩溃的下载速度而烦恼吗?…...

Habitat-Lab具身AI仿真平台:从核心概念到实战部署全解析
1. 项目概述:从零开始理解Habitat-Lab 如果你正在研究具身智能,或者对如何让AI在三维物理世界里“学会做事”感到好奇,那你大概率已经听说过Habitat-Lab这个名字。它不是一个游戏引擎,也不是一个单纯的机器人仿真器,而…...
)
电商内容自动化秘籍:构建商品知识库,小白也能轻松掌握大模型自动化(收藏版)
文章指出,电商内容自动化应首先建立商品知识库,而非直接接入模型或Agent。强调商品知识库是自动化稳定性的基础,缺乏统一认知将导致结果混乱。文章详细介绍了知识库应包含的基础字段、用户决策信息、信任证据和转化表达等要素,并阐…...

WorkBuddy+PPT Master组合,AI-PPT 的效率革命
用 AI 做 PPT,10 分钟出了 30 页,漂亮得不行。大家好,我是小虎。可下载到本地,双击打开,傻眼了。所有文字都是图片,一个都改不了。想改个标题?没办法。想调个字号?没办法。想加一页&…...