【java基础】HashMap源码解析
文章目录
- 基础说明
- 构造器
- put方法(无扩容,无冲突)
- put方法(无冲突,有扩容)
- put方法(有冲突,无树化)
- put方法(有冲突,树化)
- remove方法(树退化)
- 常见方法
- 总结
基础说明
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
HashMap 是无序的,即不会记录插入的顺序。
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。
下面是HashMap的类图
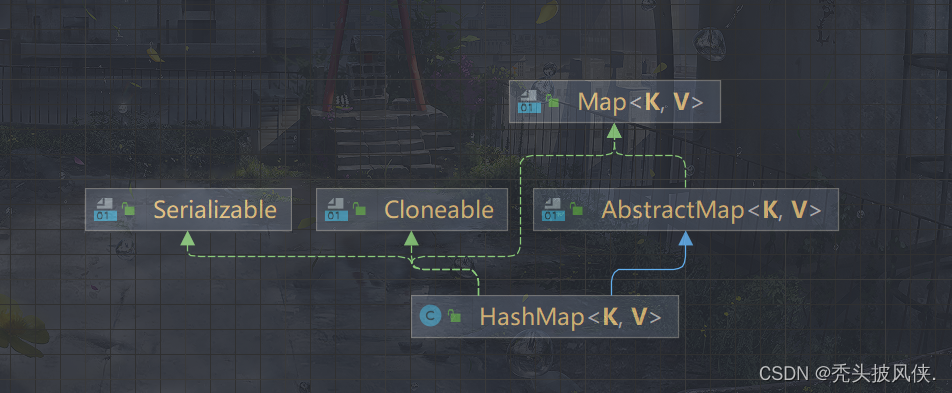
在HashMap里面,我们存储的每一个节点都是一个Node
/*** Basic hash bin node, used for most entries. (See below for* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)*/static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}}对于HashMap,这篇文章不会对hash算法还有红黑树的原理进行说明,这个是属于数据结构的知识!!!
在开始了解HashMap源码前,先对HashMap的几个重要成员属性进行说明
/*** The table, initialized on first use, and resized as* necessary. When allocated, length is always a power of two.* (We also tolerate length zero in some operations to allow* bootstrapping mechanics that are currently not needed.)*/transient Node<K,V>[] table;
table就是用来存储元素的
/*** The number of key-value mappings contained in this map.*/transient int size;
size表示元素个数
/*** The default initial capacity - MUST be a power of two.*/static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16/*** The maximum capacity, used if a higher value is implicitly specified* by either of the constructors with arguments.* MUST be a power of two <= 1<<30.*/static final int MAXIMUM_CAPACITY = 1 << 30;/*** The load factor used when none specified in constructor.*/static final float DEFAULT_LOAD_FACTOR = 0.75f;
上面几个是关于table容量的一些属性
/*** The bin count threshold for using a tree rather than list for a* bin. Bins are converted to trees when adding an element to a* bin with at least this many nodes. The value must be greater* than 2 and should be at least 8 to mesh with assumptions in* tree removal about conversion back to plain bins upon* shrinkage.*/static final int TREEIFY_THRESHOLD = 8;/*** The bin count threshold for untreeifying a (split) bin during a* resize operation. Should be less than TREEIFY_THRESHOLD, and at* most 6 to mesh with shrinkage detection under removal.*/static final int UNTREEIFY_THRESHOLD = 6;/*** The smallest table capacity for which bins may be treeified.* (Otherwise the table is resized if too many nodes in a bin.)* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts* between resizing and treeification thresholds.*/static final int MIN_TREEIFY_CAPACITY = 64;
上面这些是关于是否树形化的一些属性
构造器
在HashMap中有3个构造器,分别如下
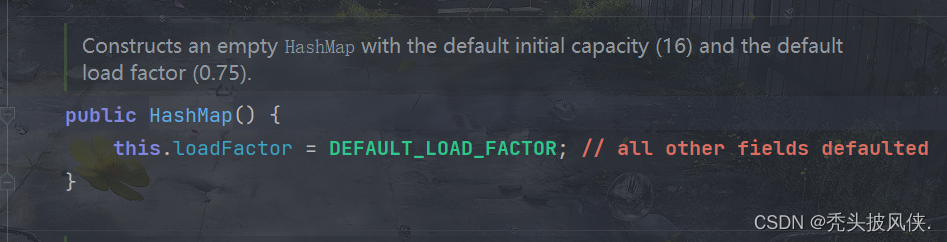
无参构造器
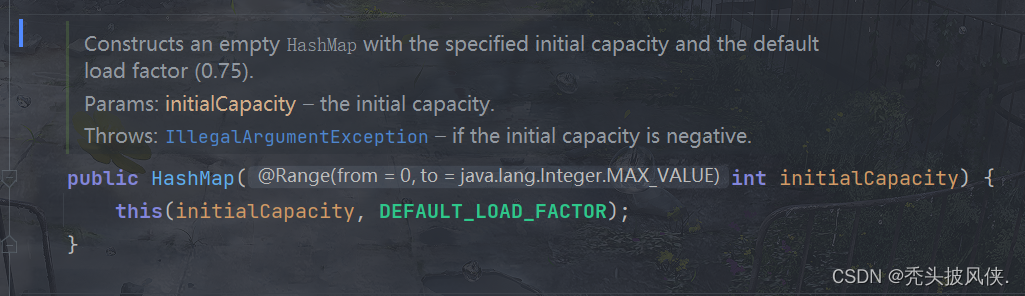
指定初始容量
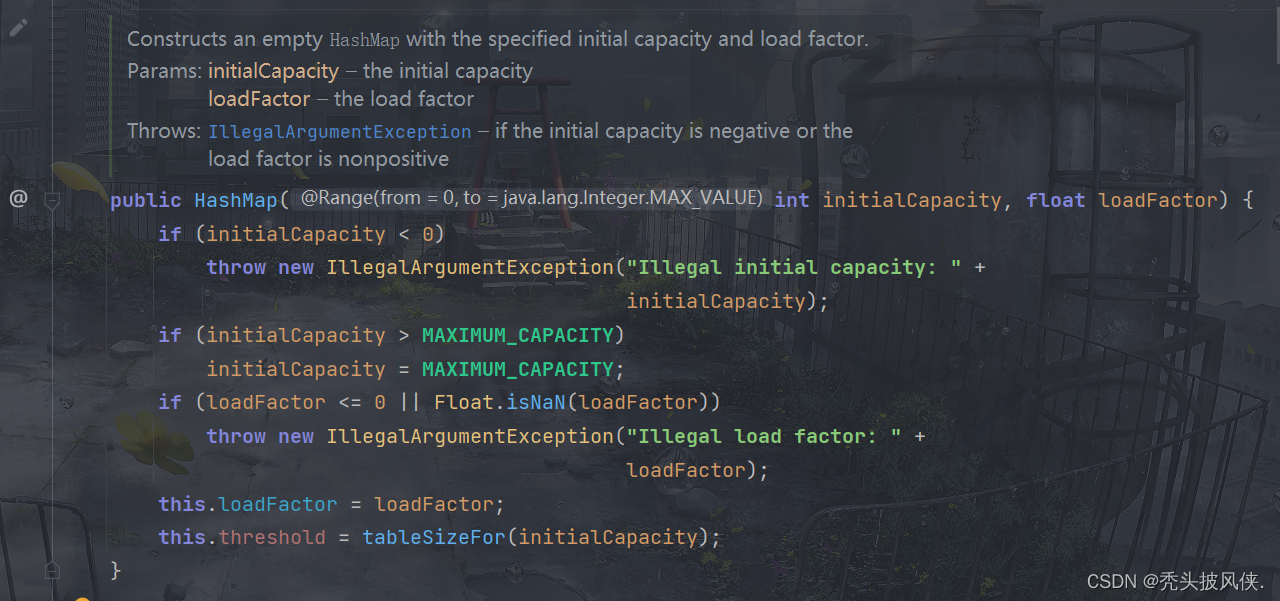
指定初始容量和负载因子
通过Map创建

对于HashMap,一般都是使用无参构造器。对于初始容量,默认值就是16,对于负载因子,默认值就是0.75。
负载因子的作用就是判断table是否需要扩容了,如果table的容量达到了 当前容量*负载因子,那么就会进行扩容
put方法(无扩容,无冲突)
现在我们就来开始debug,下面就是要进行debug的代码
public static void main(String[] args) {HashMap<Integer, String> hashMap = new HashMap<>();for (int i = 0; i < 20; i++) {hashMap.put(i, "100");}}
对于debug,我们主要是看过程,一定不要过分在意细节,不然就绕进去了。下面就开始debug了
首先看看创建HashMap后有什么
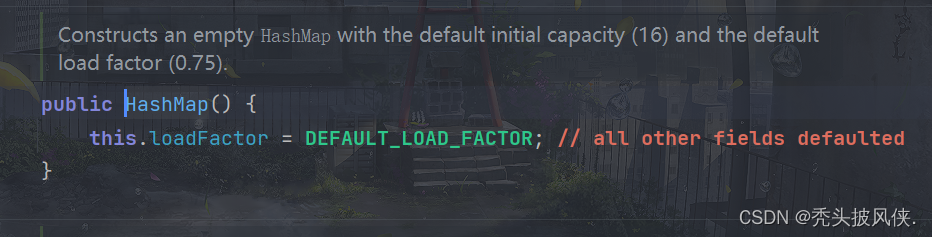
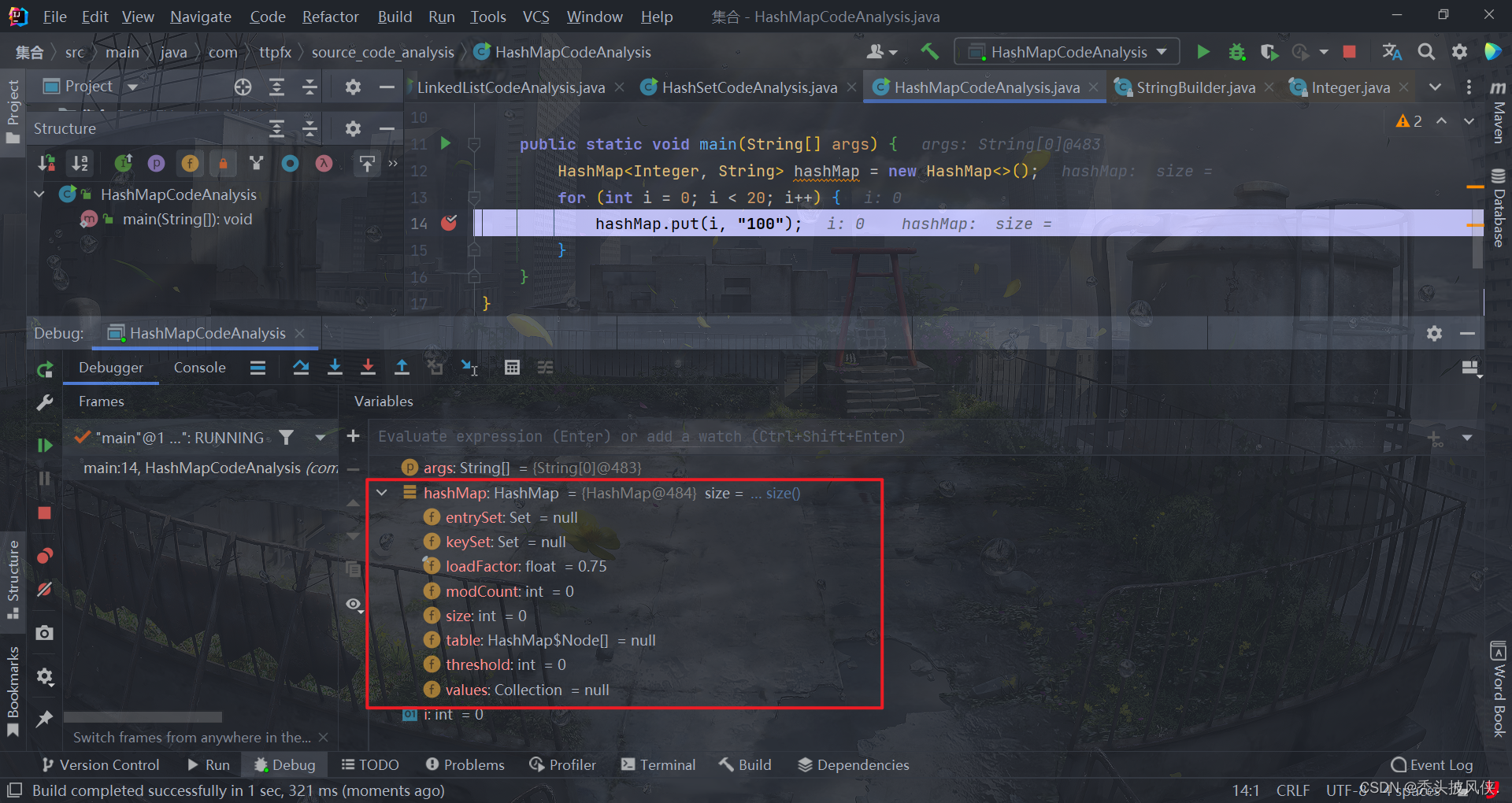
可以发现创建就是设置了一些负载因子
然后进入put方法

该方法首先会计算传入k的hash值,对于hash算法,这里不做说明,请参考数据结构,下面就是hash方法的内容
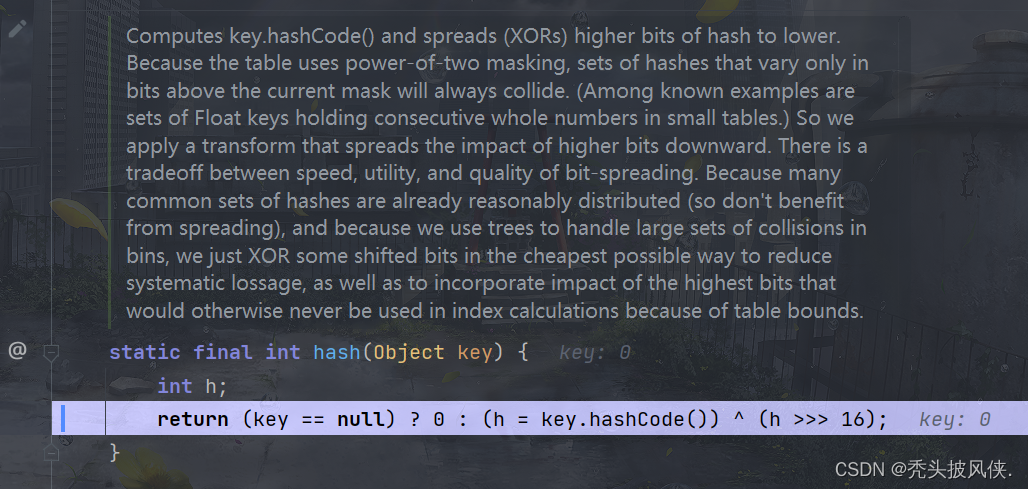
计算完hash后,进入putVal方法
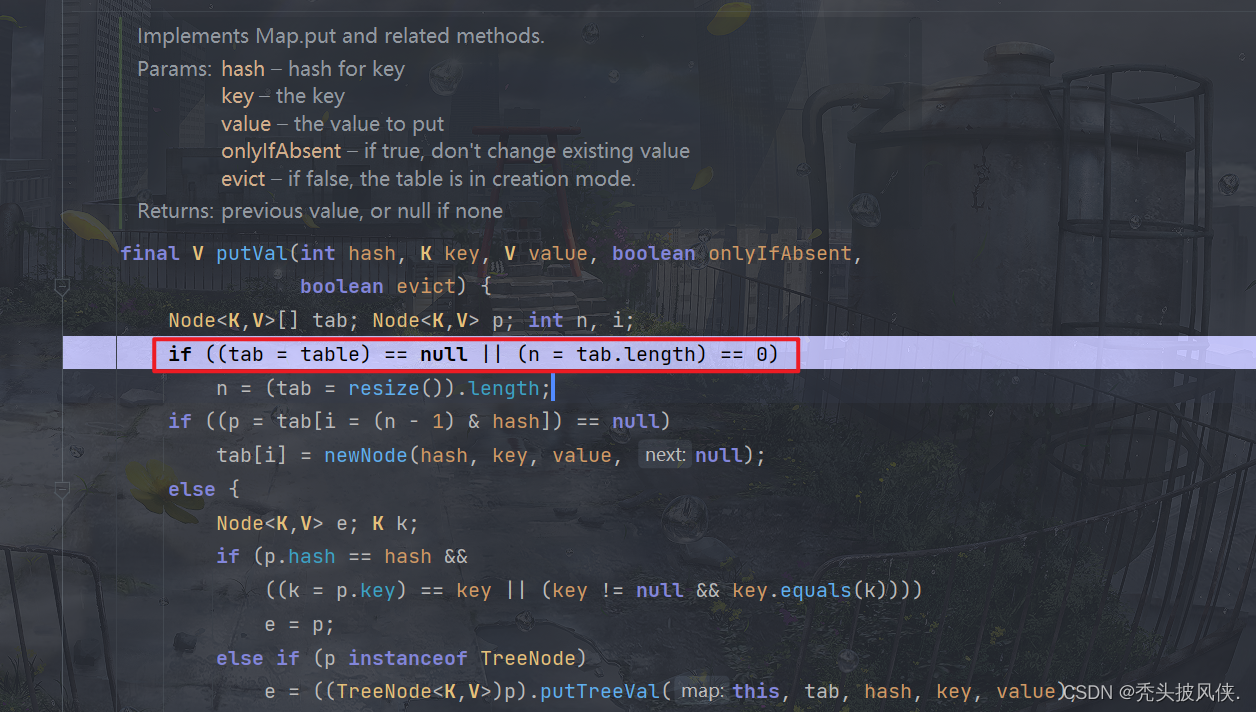
这个if就是判断当前table是否为null,显然是的,于是就进入到resize方法。resize方法内容很多,这里我不会说明每一条语句,挑重要的进行说明。在这之前,我们应当看一下该方法的注释
/*** Initializes or doubles table size. If null, allocates in* accord with initial capacity target held in field threshold.* Otherwise, because we are using power-of-two expansion, the* elements from each bin must either stay at same index, or move* with a power of two offset in the new table.** @return the table*/
开始debug
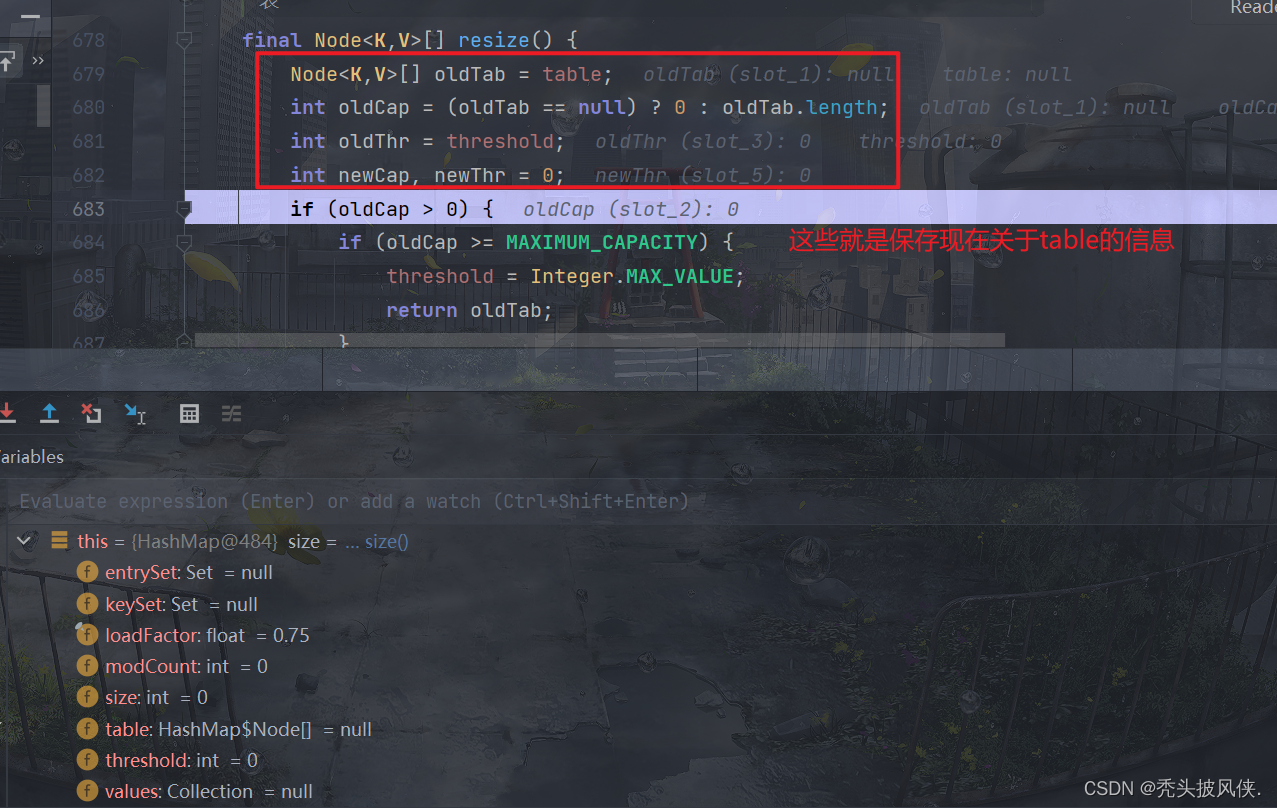
继续往下面走
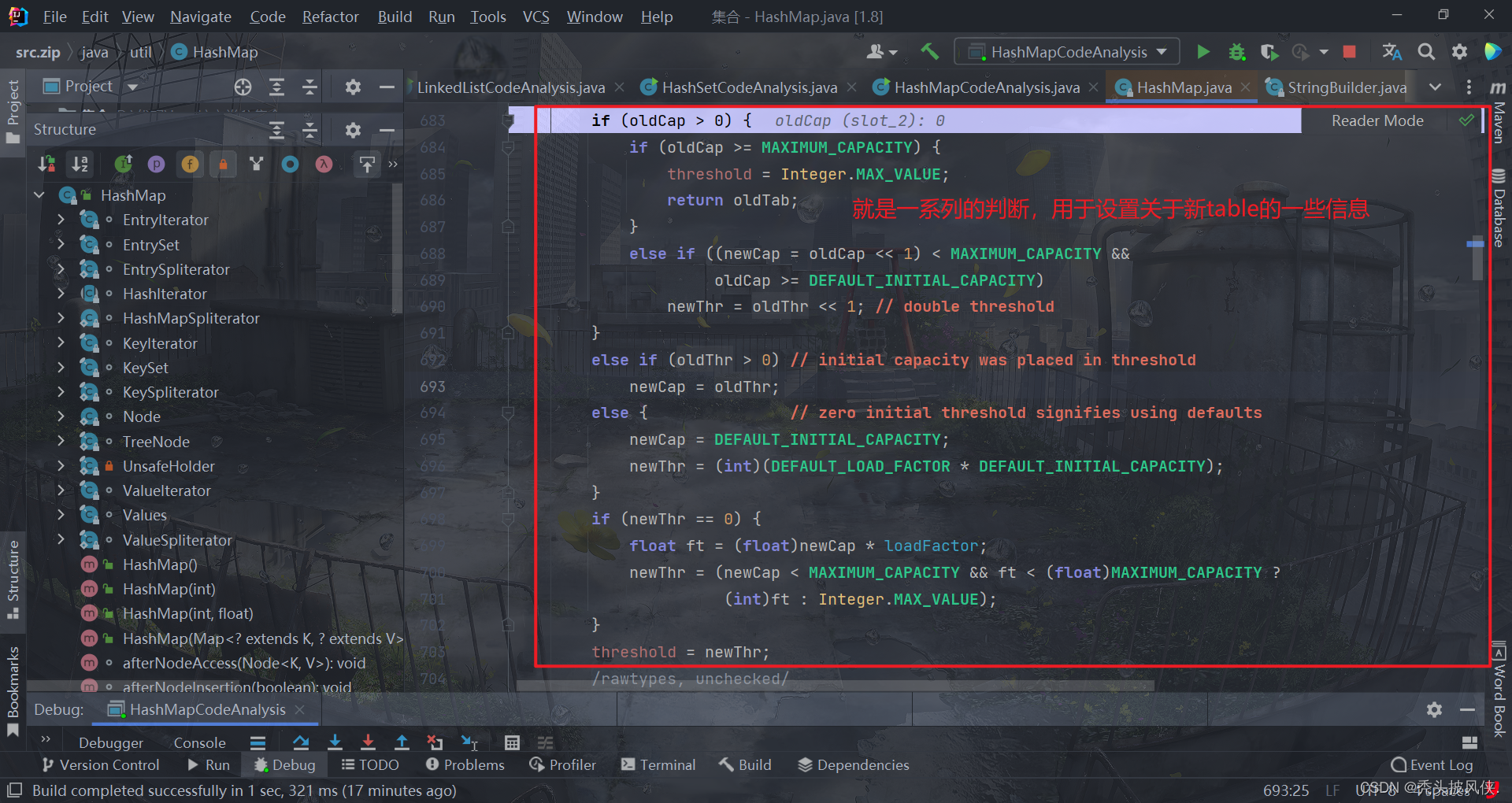
上面的判断完成后就开始真正创建数组了
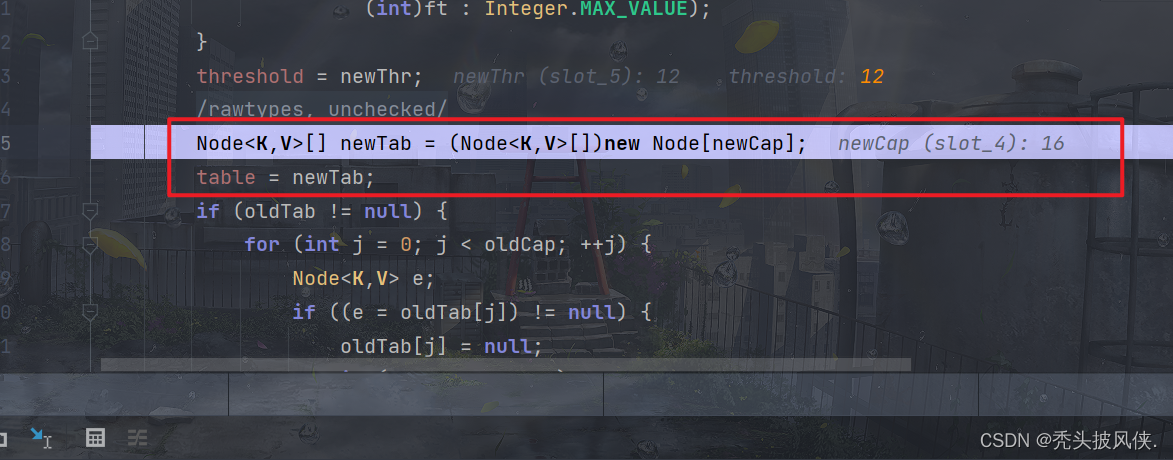
然后赋值,对于下面的if判断,其实就是将oldTab的值复制过来,由于oldTab为null,所以这个方法就结束了,这个方法结束之后,table就已经初始化了,大小为16
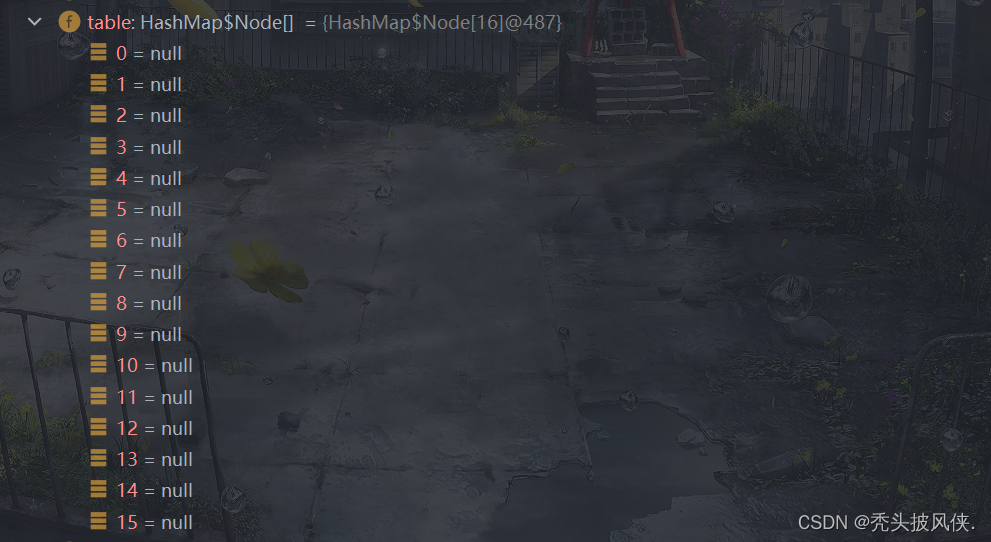
继续debug
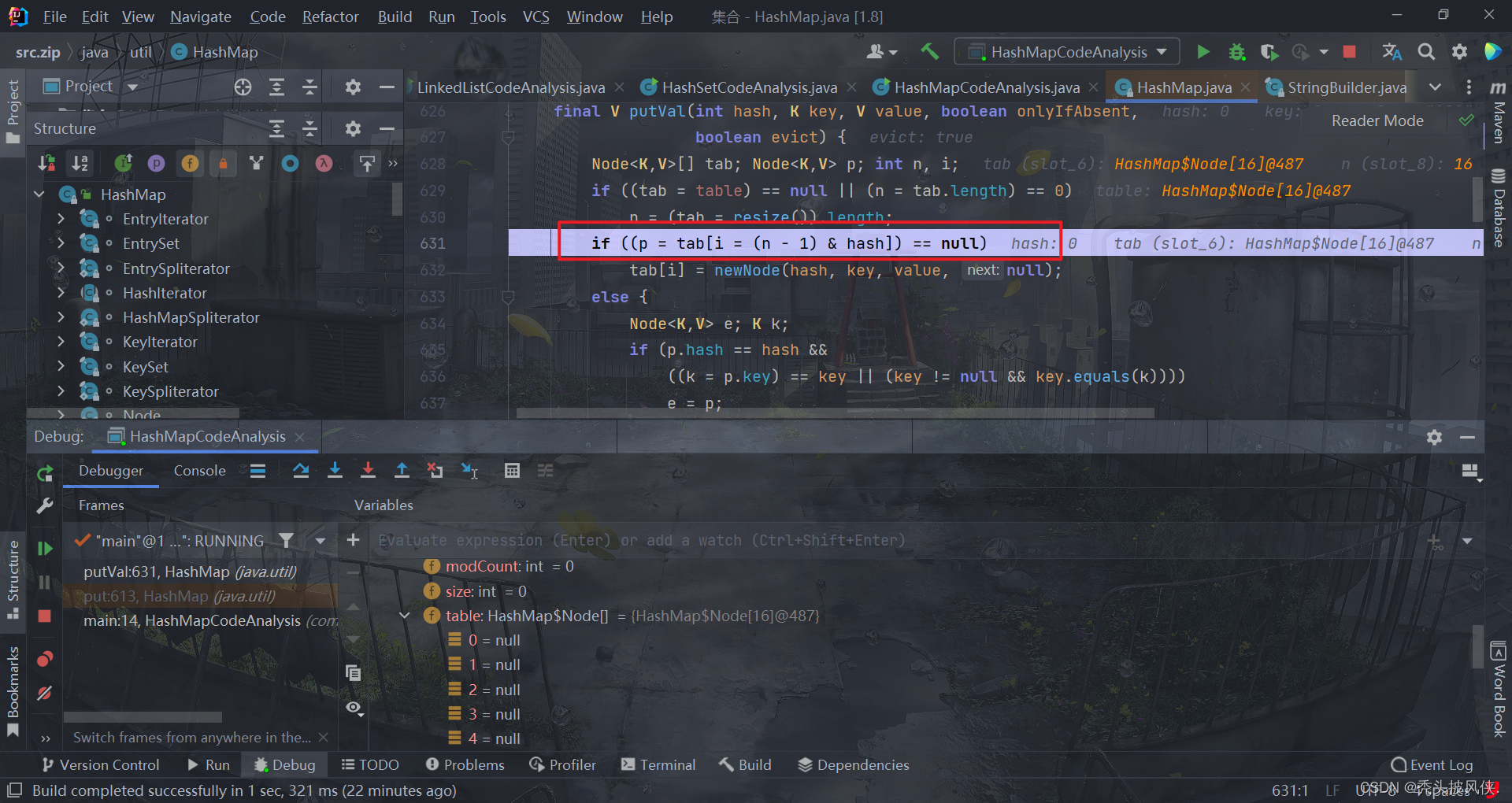
这条语句就是判断指定通过hash算出来的索引位置是否已经存放了值,显然没有,所以就会将其设置到指定位置
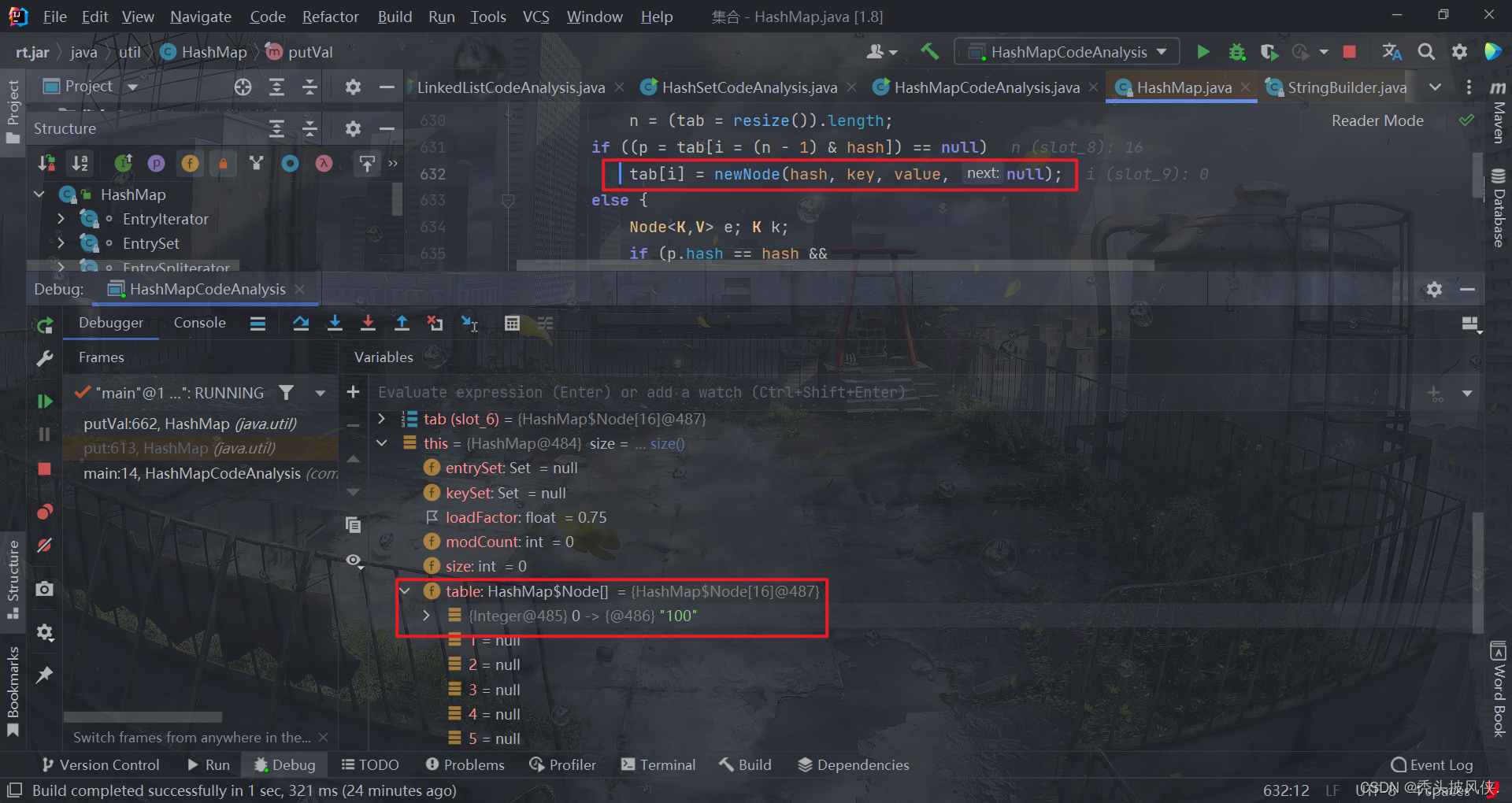
继续往下面走,可以看见一个if语句
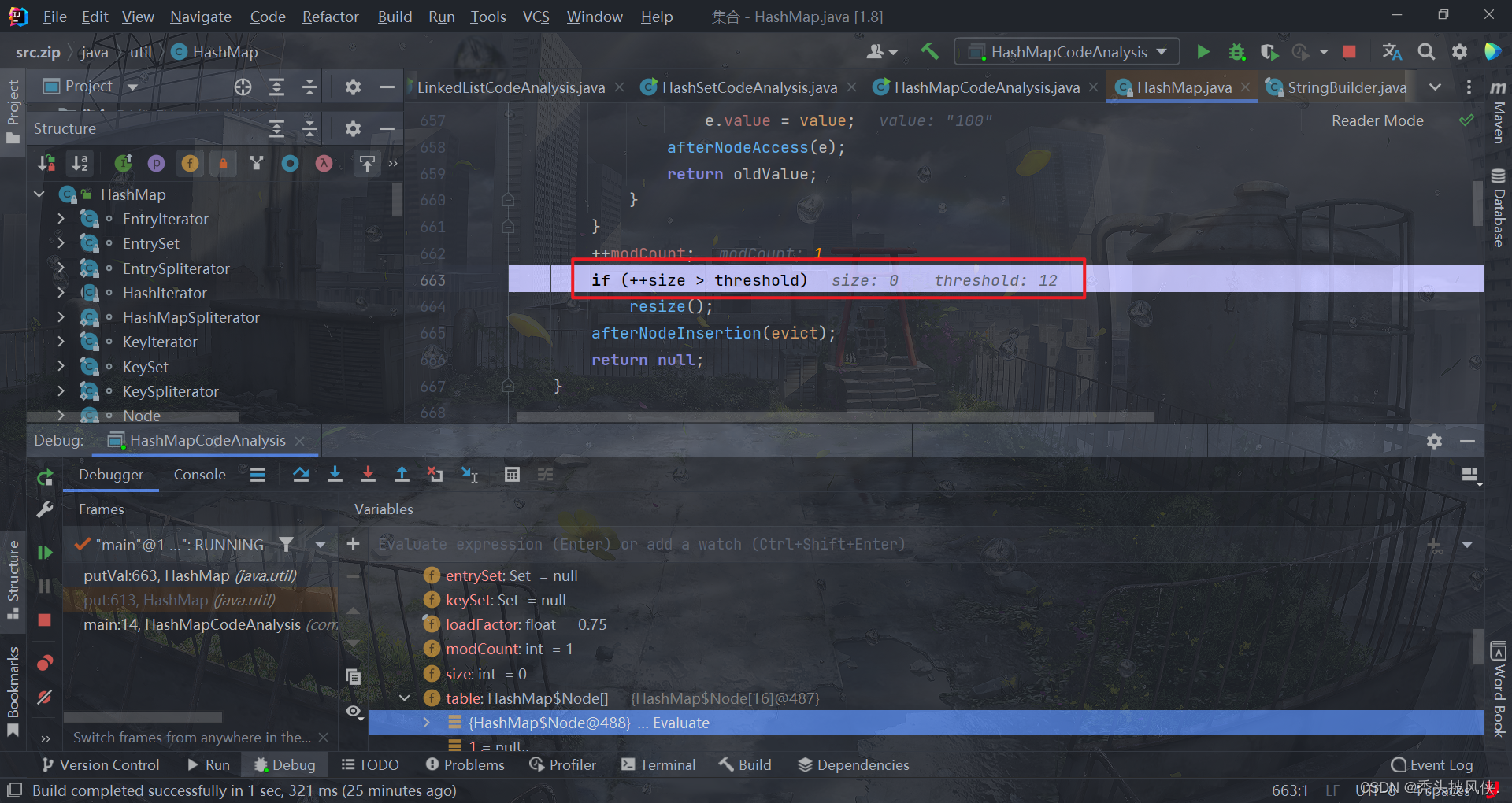
这个就是用来判断是否需要扩容的,threshold就是当前容量*负载因子,这里的threshold就是12
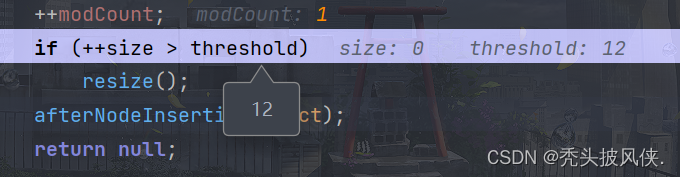
继续往下走,方法结束
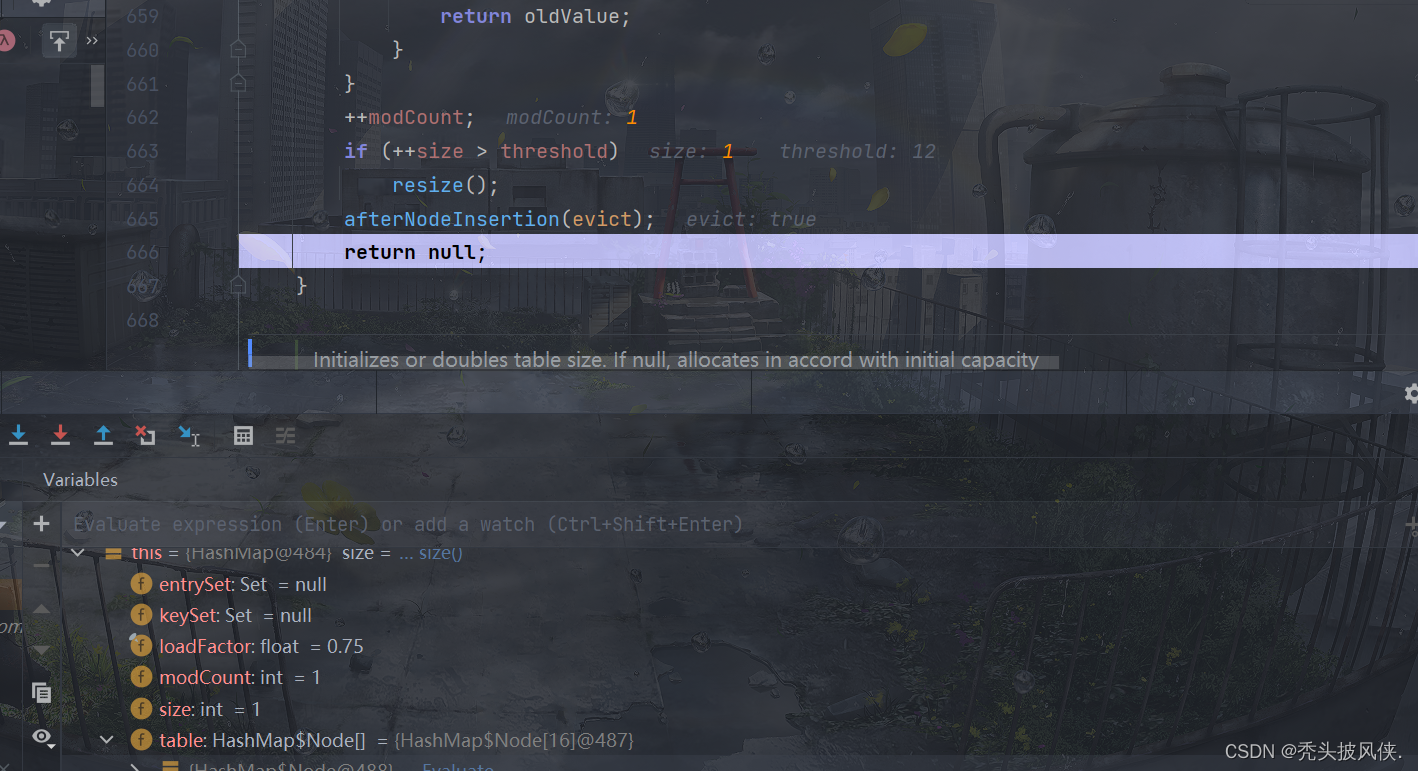
下面就是添加完一个元素后的HashMap信息
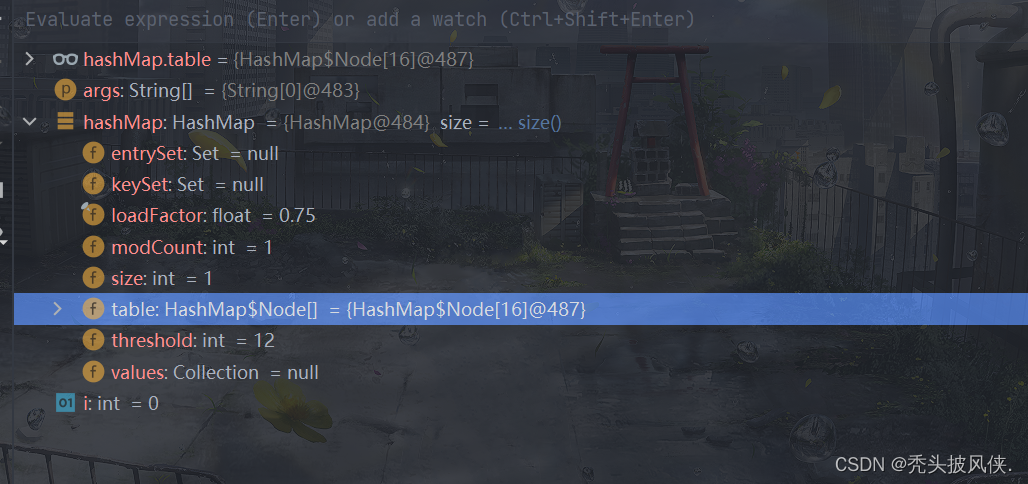
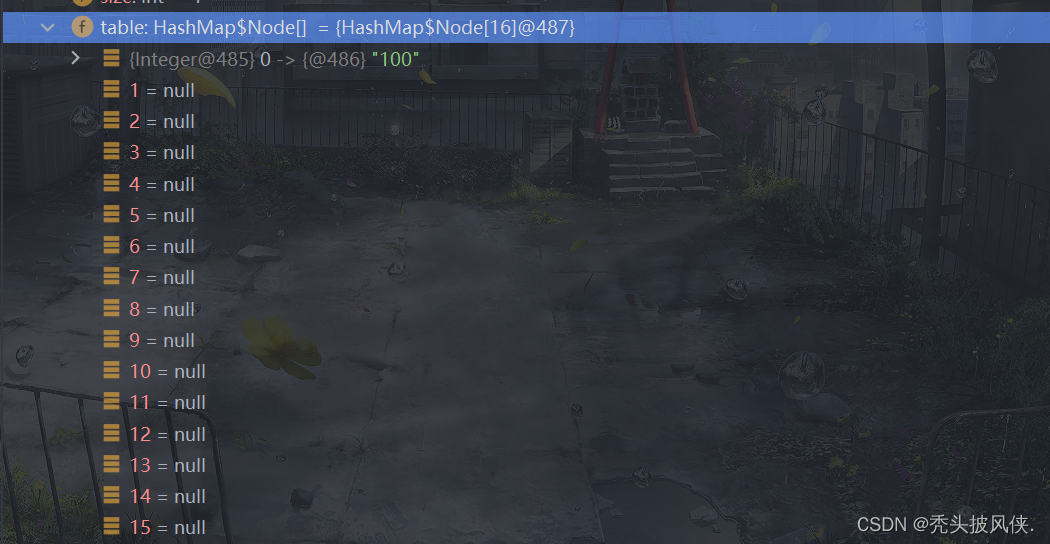
put方法(无冲突,有扩容)
我们通过上面的学习应该知道了当table数组使用3/4的时候就会扩容了,下面来具体看一下流程
public static void main(String[] args) {HashMap<Integer, String> hashMap = new HashMap<>();for (int i = 0; i < 20; i++) {hashMap.put(i, "100");}}
还是这个代码,我们使用条件debug,看看i==12的时候是如何进行扩容的
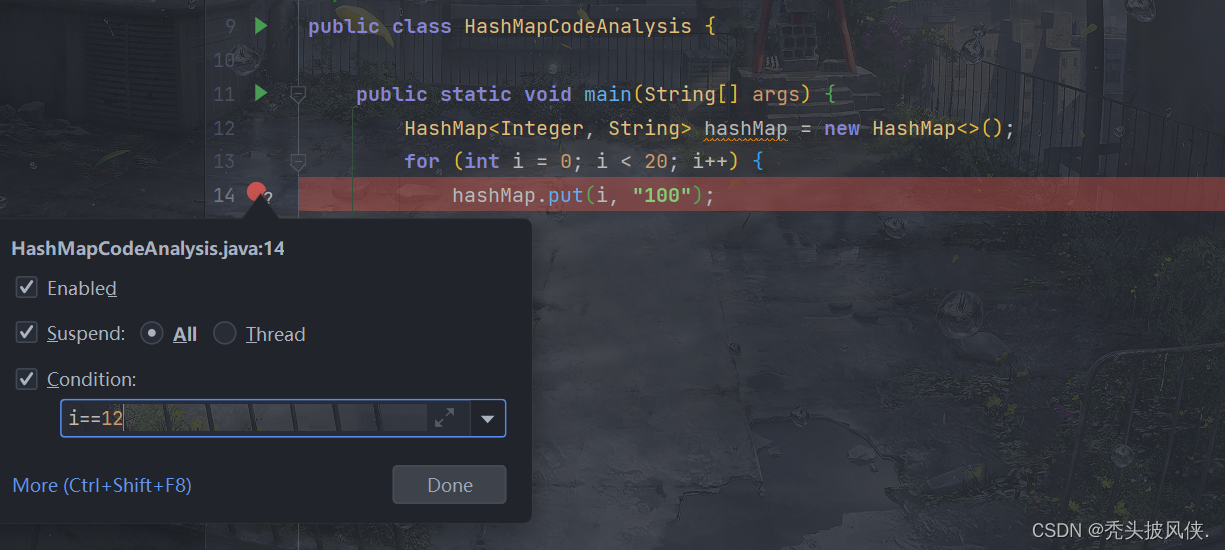
由于大部分内容都是和一般情况一样的,所以我就直接跳到关键部分
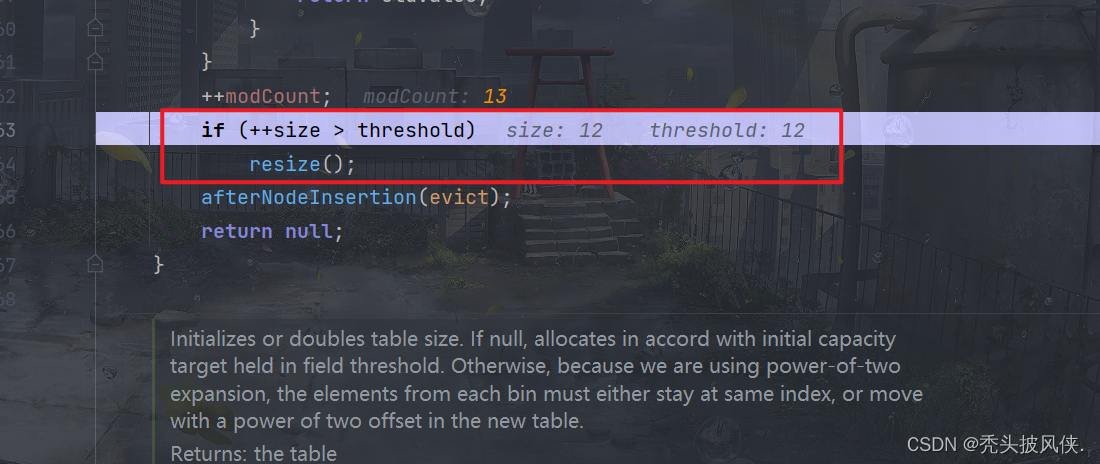
当i=12的时候,++size会>threshold,所以会执行resize方法。resize方法前面部分也是一样的,我也是直接跳到关键部分
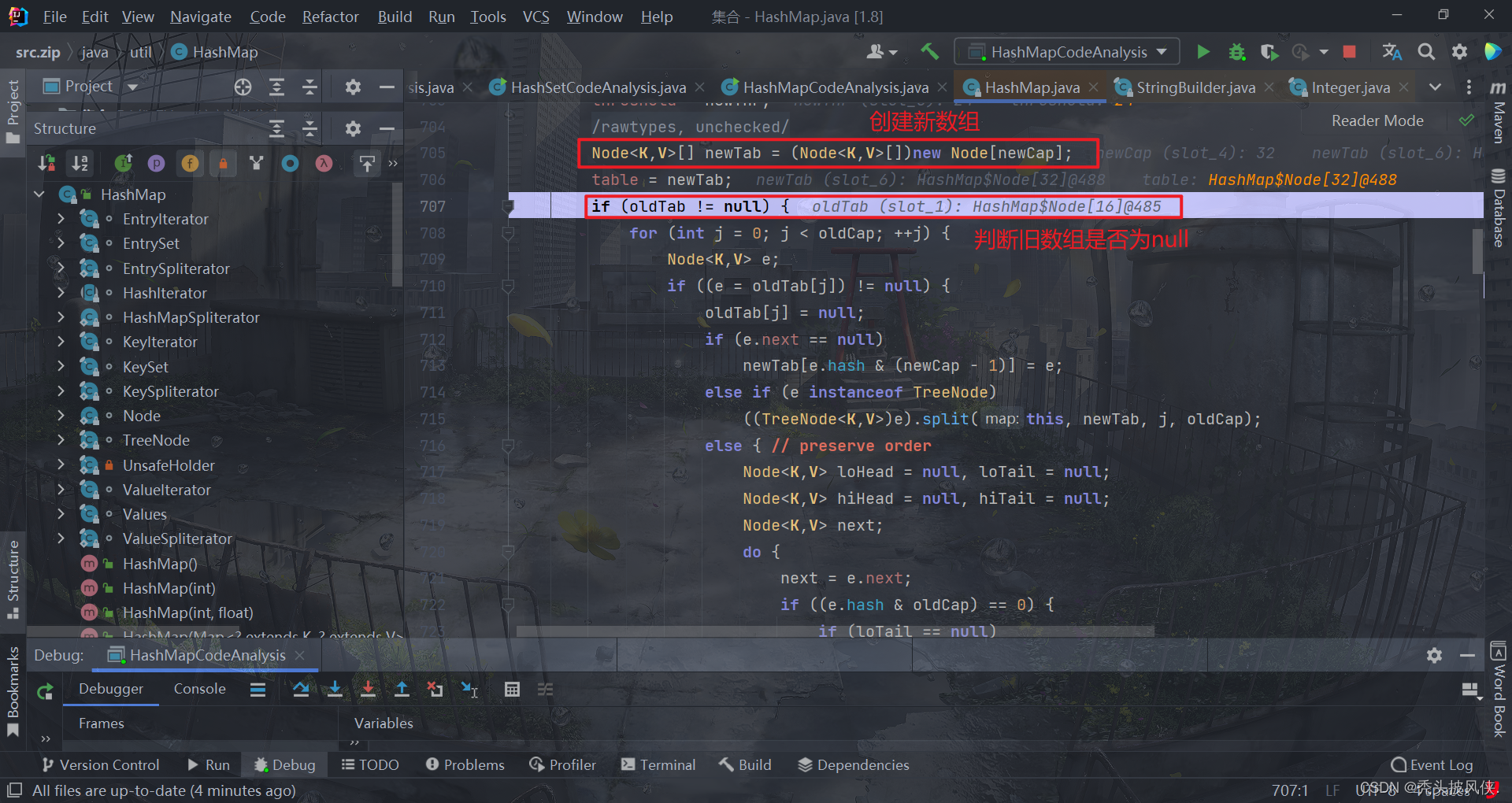

由于我们的table没有发生冲突,在这个循环里面 e.next==null 永远成立
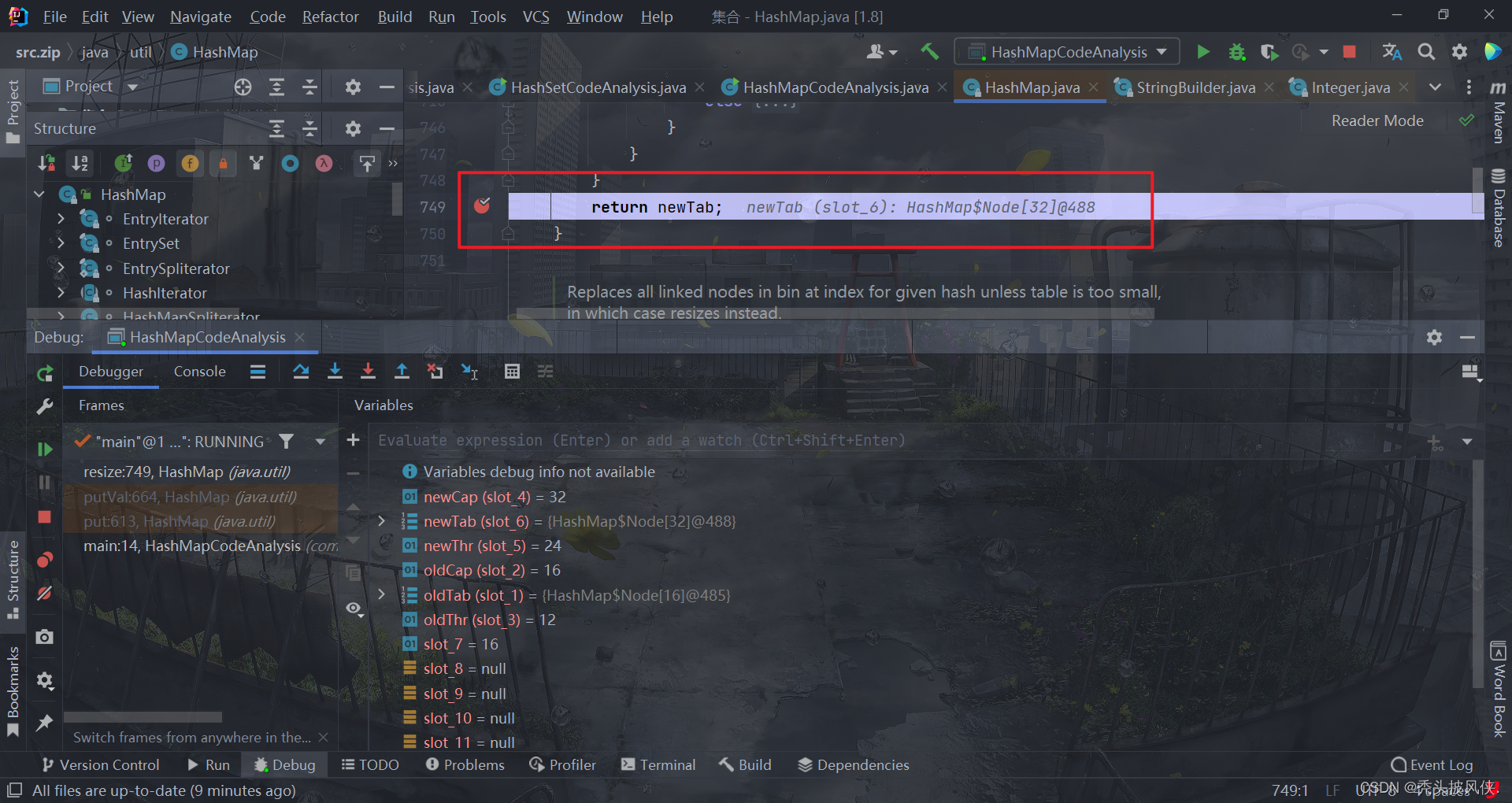
复制完成之后就会返回新table,大小为32,threshold会更新为24
对于一般情况下的扩容,下面的条件基本都会成立,也就是threshold和容量都会翻倍

put方法(有冲突,无树化)
上面我们都是介绍的无hash冲突的情况,现在就来debug下出现hash冲突的情况
public class FixHashCat {@Overridepublic int hashCode() {return 12345678;}
}
上面的FixHashCat重写了hashCode,使之成为固定值,这样方便debug
public static void main(String[] args) {HashMap<FixHashCat, String> hashMap = new HashMap<>();hashMap.put(new FixHashCat(), "1");hashMap.put(new FixHashCat(), "2");}
上面的第二个put肯定就会产生hash冲突,下面就来看一下流程吧
对于重复的步骤我就跳过了,现在还是会进入putVal方法
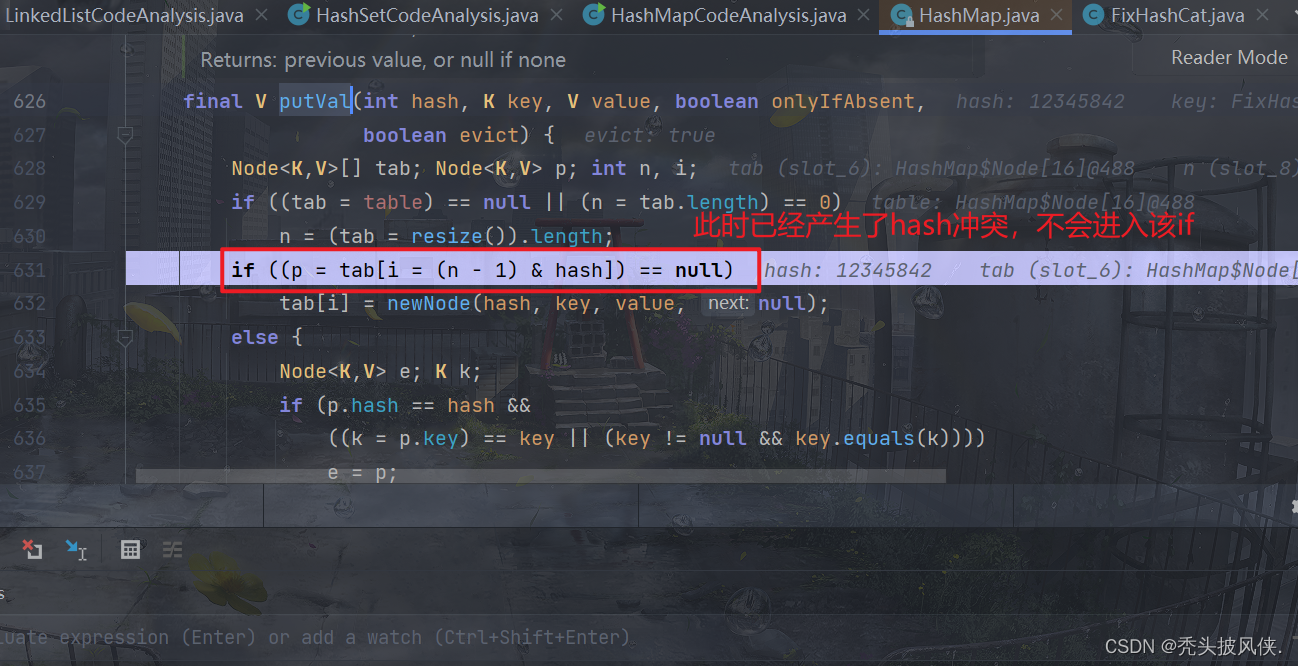
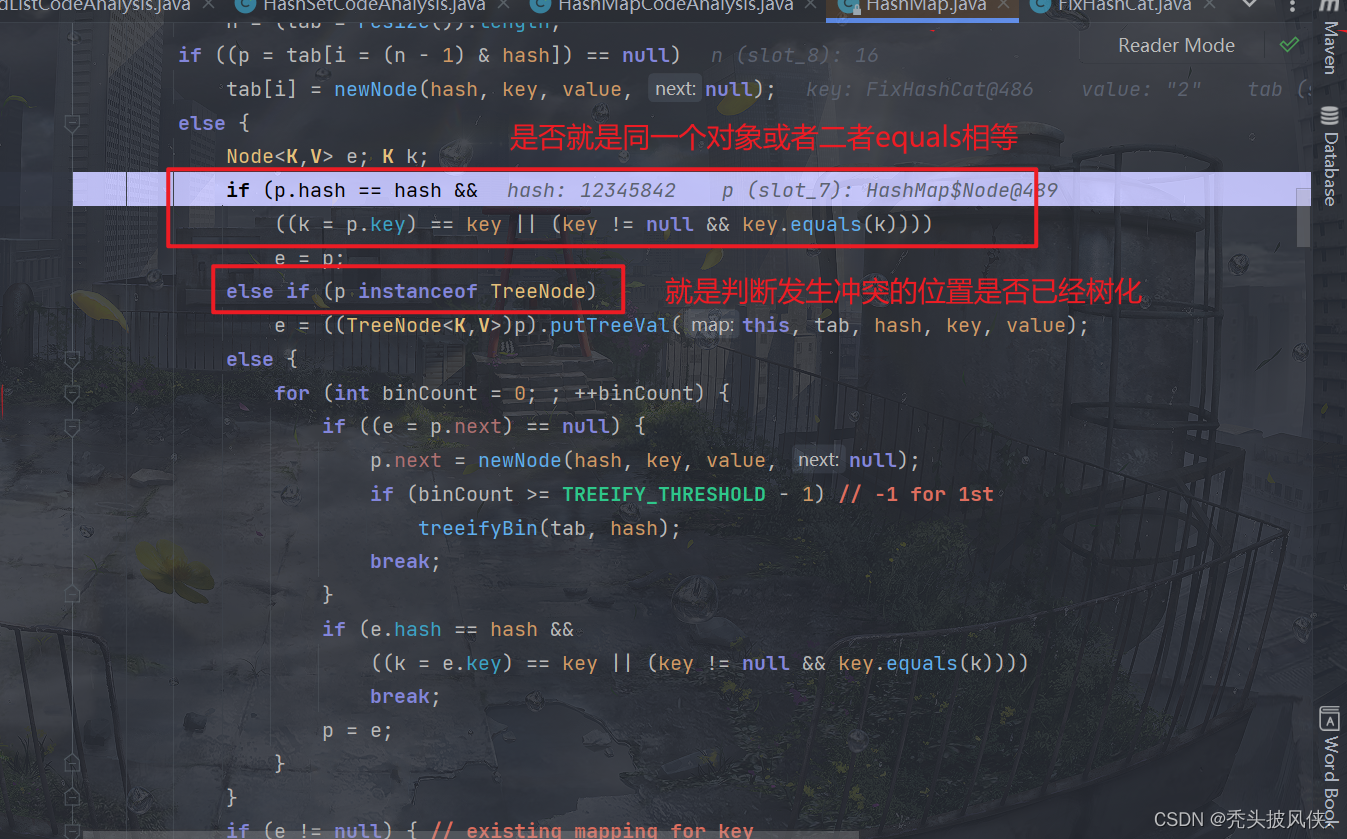
由于我们没有重写equals方法,当前也没有树化,所以会进行如else语句
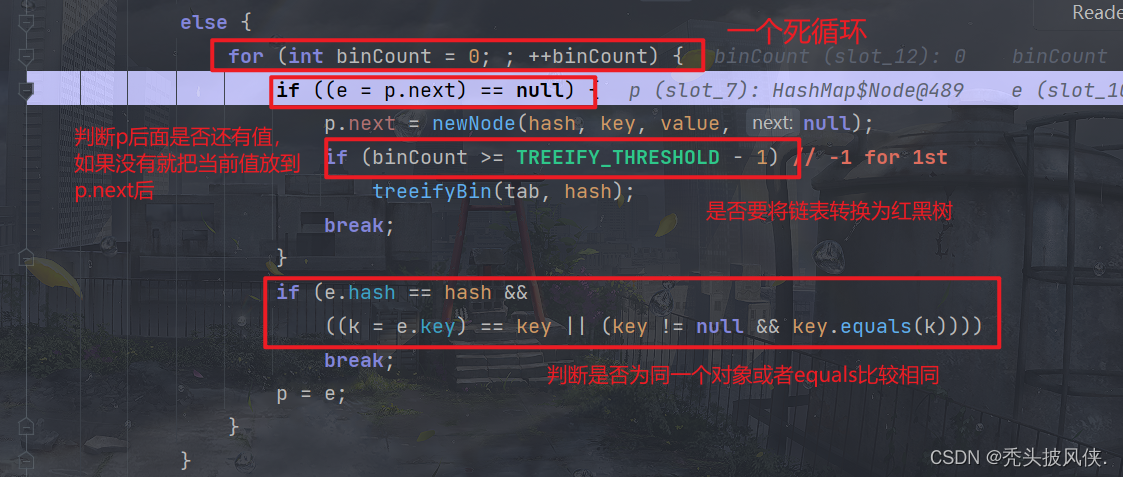
对于是否树化,链表的数量要大于等于7才行,加上新加入的那个,bitCount又是从0开始的,也就是当链表个数达到9个就会进行树化
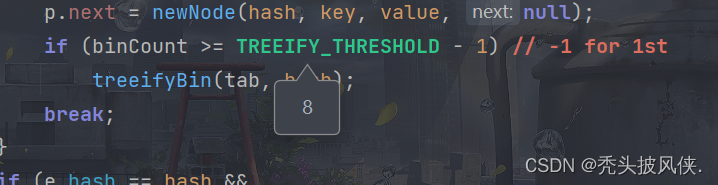
由于我们添加后链表长度都才为2,所以显然不会树化,继续执行,将当前元素添加到指定索引的链表末尾。继续往下执行,还可以发现一个if
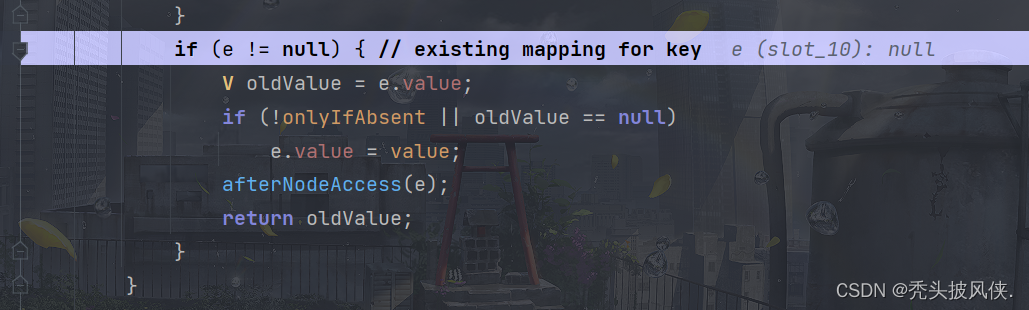
我们指定map里面key是唯一的,如果添加2个相同的key,那么前面个key的值就会被覆盖,这里的if就是用来完成这个事情的。继续debug
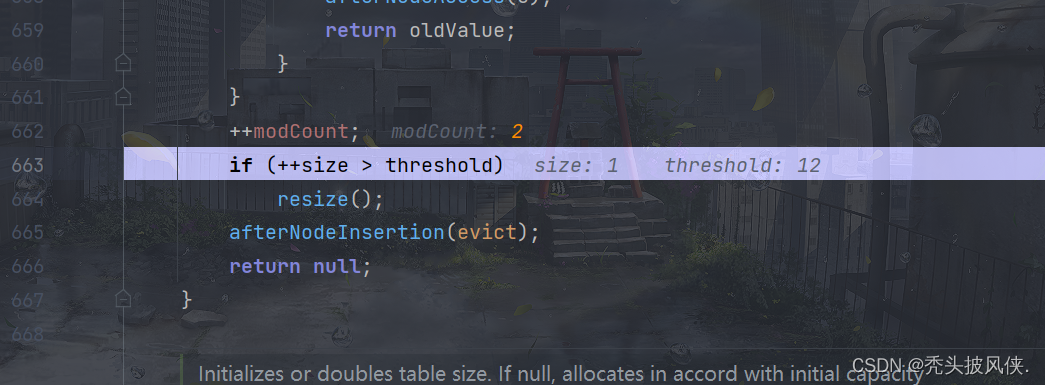
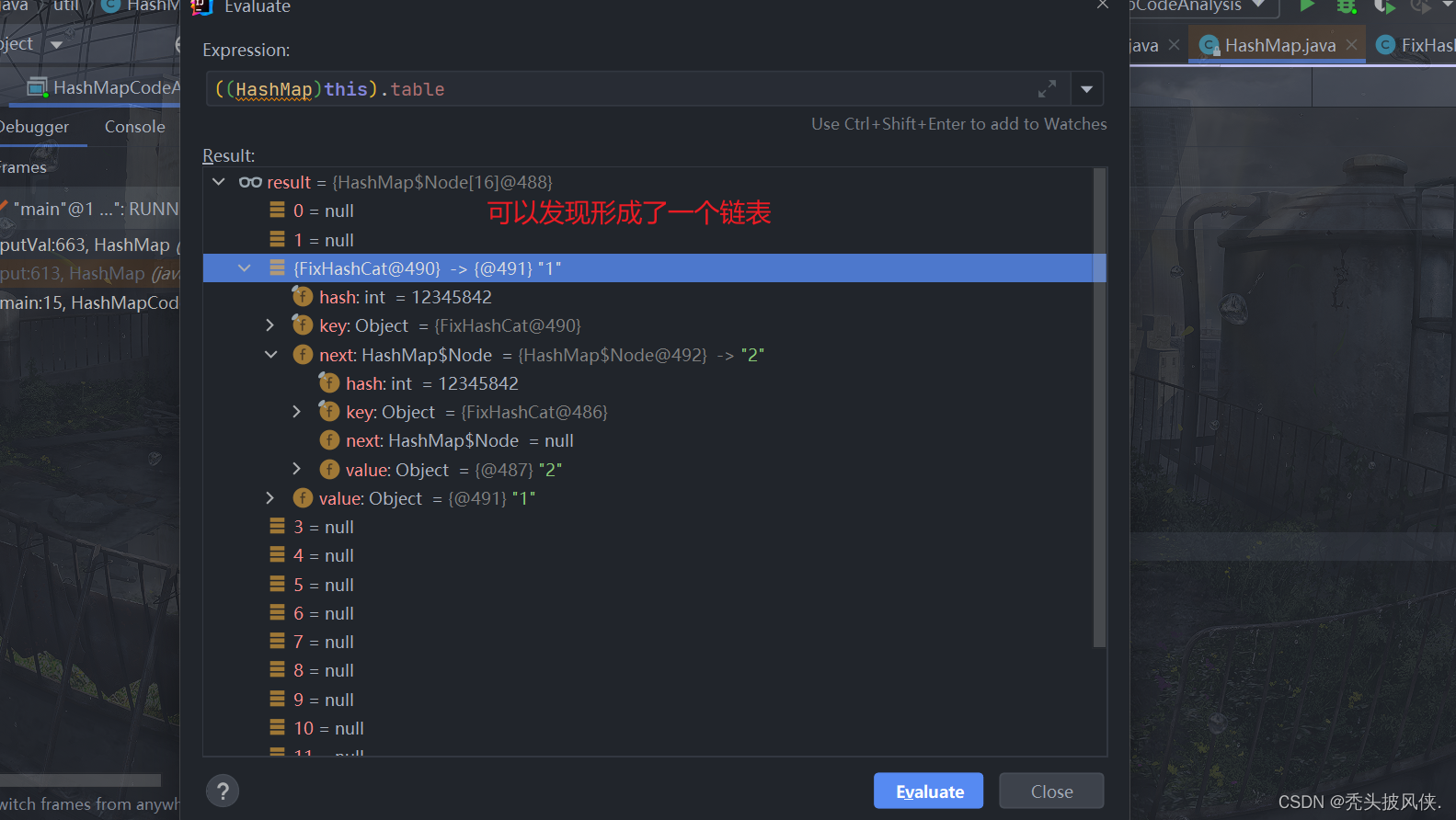
执行到这里,debug也就基本结束了,最后来看看table的结构
put方法(有冲突,树化)
上面看见了当链表个数达到9个的时候会进行树化,链表变换为红黑树,下面就来debug这个过程
public static void main(String[] args) {HashMap<FixHashCat, String> hashMap = new HashMap<>();for (int i = 0; i < 8; i++) {hashMap.put(new FixHashCat(), i + "");}hashMap.put(new FixHashCat(), "8");}
我使用上面代码进行debug,查看hashMap.put(new FixHashCat(), “8”)这条语句添加时候的情况
前面相同的部分我就跳过了,直接从树化部分开始
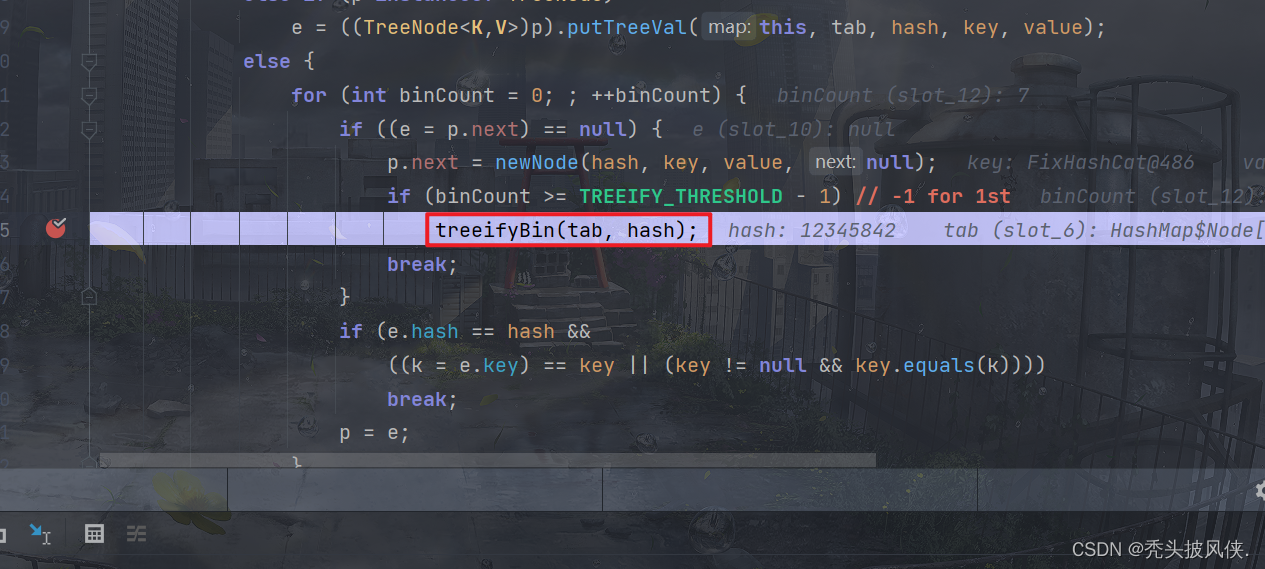
进入到treeifyBin,结果由于table容量太小(这里是16),于是会重设table大小,并不会树化。
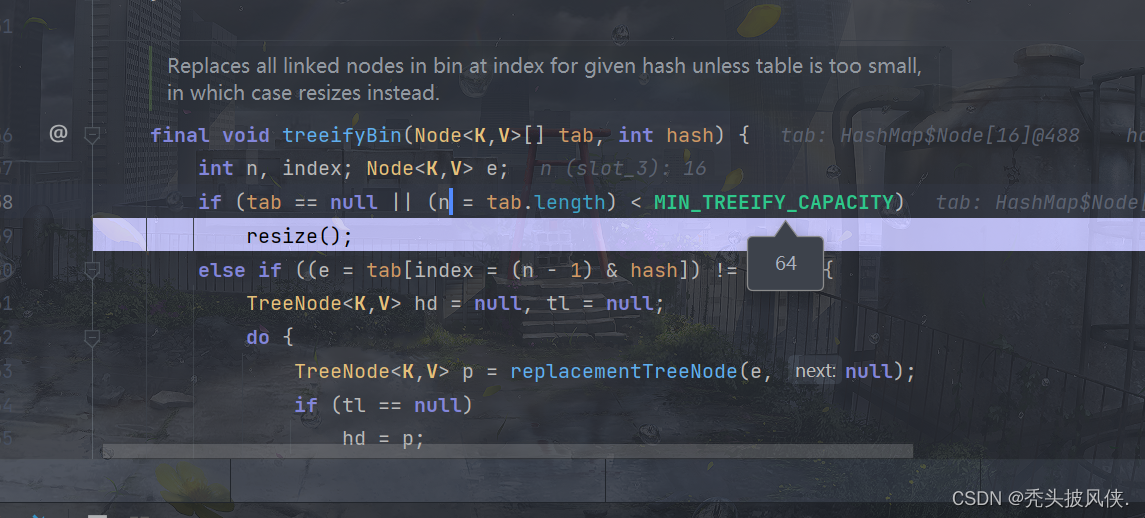
为了看到树化的过程,我在创建HashMap的时候指定初始容量
public static void main(String[] args) {HashMap<FixHashCat, String> hashMap = new HashMap<>(128);for (int i = 0; i < 8; i++) {hashMap.put(new FixHashCat(), i + "");}hashMap.put(new FixHashCat(), "9");}
还是debug到treeifyBin
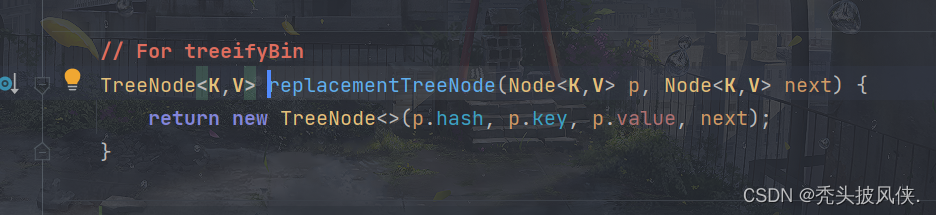
简单看一下replacementTreeNode,代码很简单,如下
对于do-while里面的内容我并不关心,直接跳到if语句
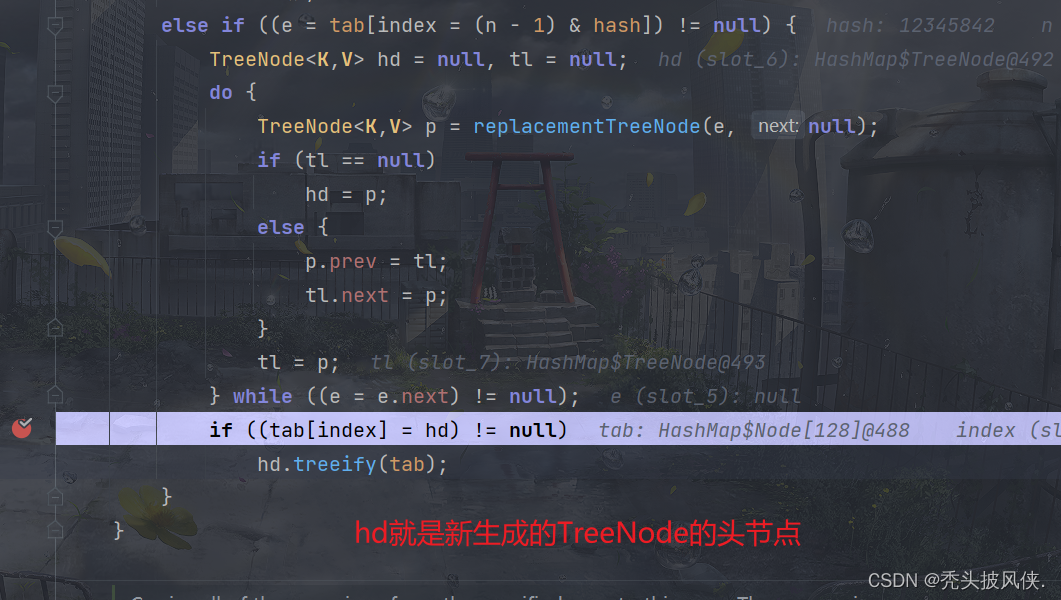
可以看一下hd的内容
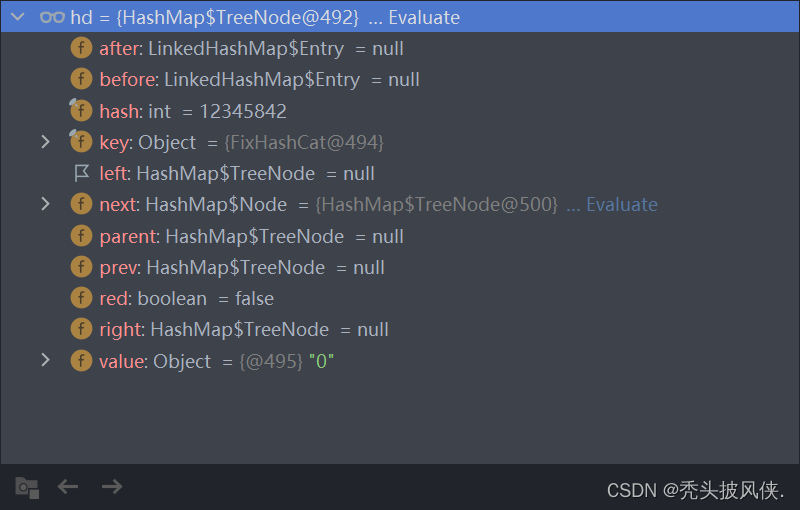
下面就是执行treeify方法
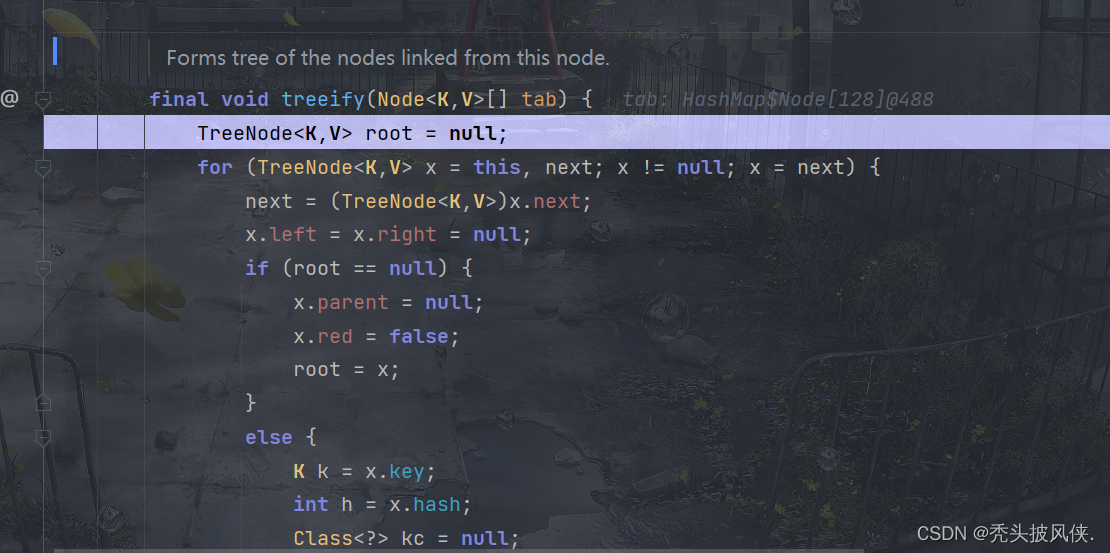
对于这个方法,完全就是属于数据结构了,这里不进行说明,大家可以自行查看源代码。现在我直接看看执行完该方法后产生的树
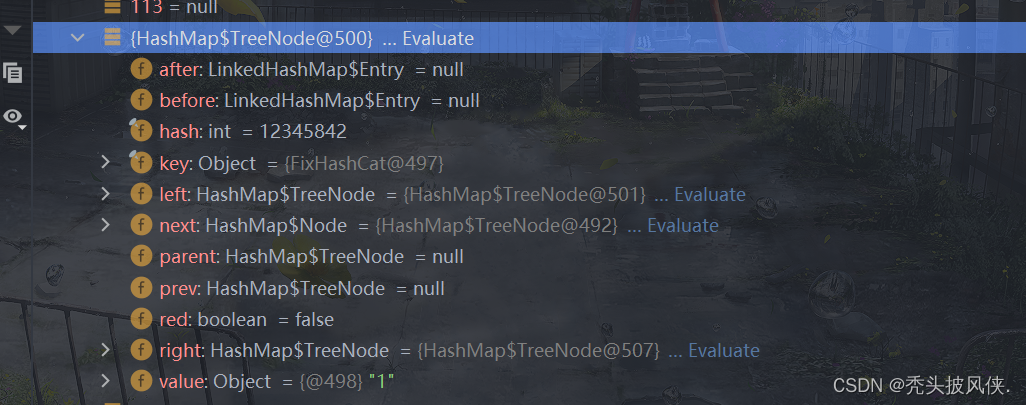
可以发现树节点就是通过TreeNode来存储的,用于快速查找。
现在关于树化的debug就结束了,现在我想对上面提到的TreeNode进行一下说明

就是p instanceof TreeNode,这个在上面提到过,现在大家应该可以看懂了,树化之后的节点就是TreeNode,如果是TreeNode,那么就要将其添加到树,而不是链表尾部。
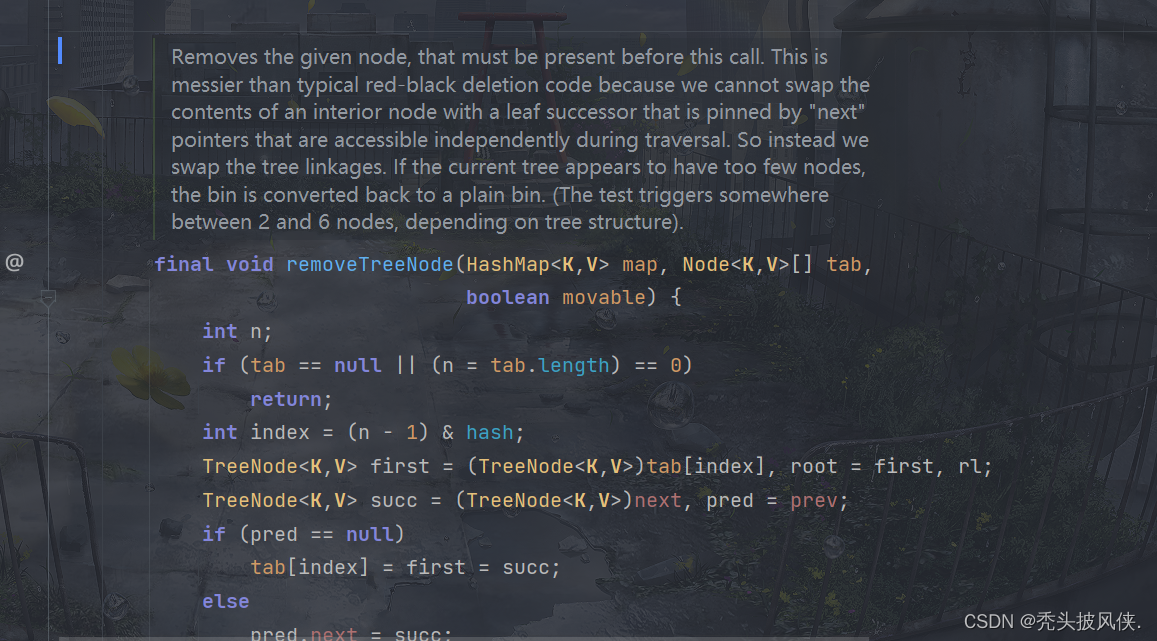
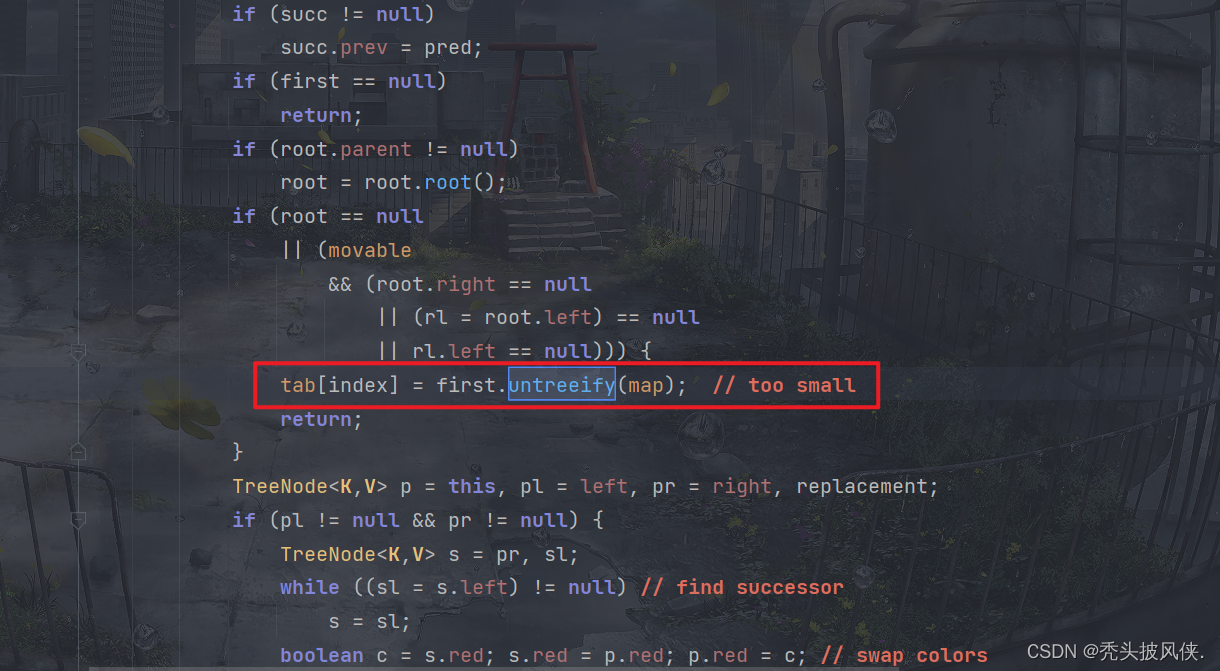
remove方法(树退化)
对于HashMap,不仅仅会将链表变化为树,当树的元素个数小于某个阈值时,树也会退化为链表
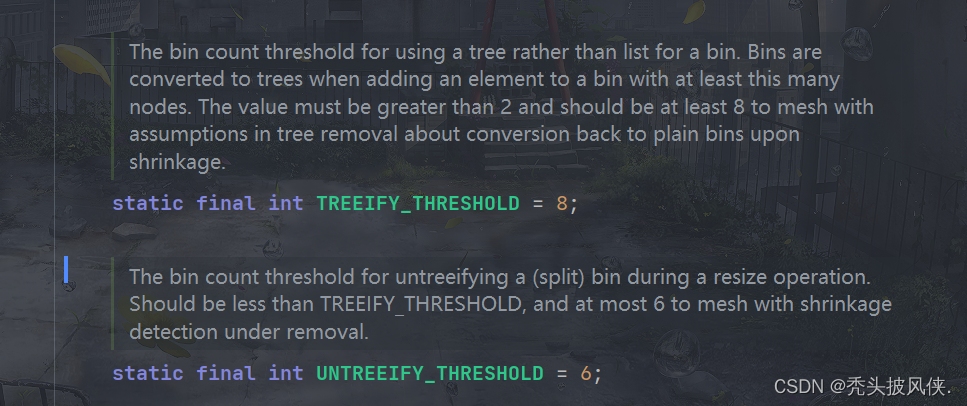
上面分别是树化和退化的阈值。
当我们删除元素的时候可能就会进行退化,树变成链表
常见方法
在这里介绍一些HashMap里面经常使用到的方法
| 方法名称 | 作用 |
|---|---|
| entrySet() | 返回所有元素的set集合(k-v形式) |
| getOrDefault(Object key, V defaultValue) | 返回指定key对于的value,如果不存在就返回defaultValue |
| keySet() | 返回所有的key |
| values() | 返回所有的value |
| forEach | 遍历集合元素 |
| containsKey(Object key) | 是否包含指定key |
| containsValue(Object value) | 是否包含指定value |
总结
HashMap使用K-V的形式存储数据,Map的扩容机制是按照2倍进行的,当达到阈值时就会扩容。当hash冲突严重时,链表会转换为红黑树,当树元素个数很少时,又会退化为链表。
相关文章:
【java基础】HashMap源码解析
文章目录基础说明构造器put方法(无扩容,无冲突)put方法(无冲突,有扩容)put方法(有冲突,无树化)put方法(有冲突,树化)remove方法&#…...

实现异步的8种方式,你知道几个?
一、前言 在编程中,有时候我们需要处理一些费时的操作,比如网络请求、文件读写、数据库操作等等,这些操作会阻塞线程,等待结果返回。为了避免阻塞线程、提高程序的并发处理能力,我们常常采用异步编程。 异步编程是一种…...
二叉树的三种遍历
二叉树的遍历可以有:先序遍历、中序遍历、后序遍历先序遍历:根、左子树,右子树中序遍历:左子树、根、右子树后序遍历:左子树、右子树、根下面是我画图理解三种遍历:二叉树里都是分为左子树和右子树。分治思…...

我,30岁程序员被裁了,千万别干全栈
大家好,这里是程序员晚枫,今天是读者投稿。下面开始我们的正文。👇 关注博主👉程序员晚枫 很久了,今天给大家分享一下我从事程序员后,30岁被裁的经历,希望帮到有需要的人。 1、我被裁了 大家好…...
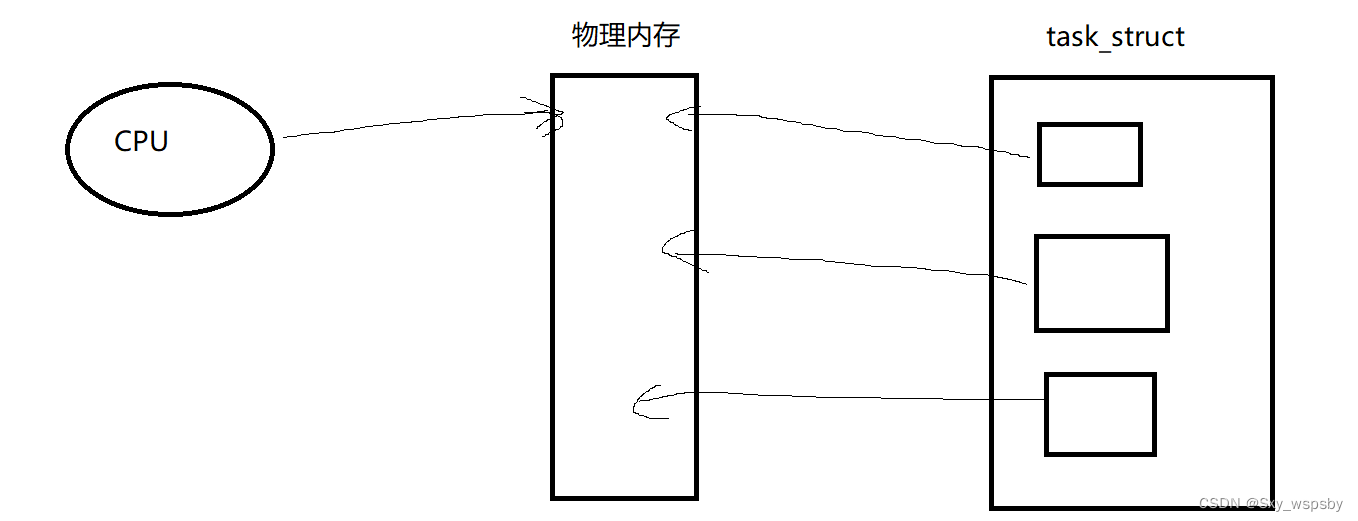
【linux】:进程地址空间
文章目录 前言一、进程地址空间总结前言 本篇文章接着上一篇文章继续讲解进程,主要讲述了进程在运行过程中是如何在内存中被读取的以及为什么要有虚拟地址的存在,CPU在运行过程中是拿到程序的虚拟地址还是真实的物理内存。 一、进程地址空间 下面我们先…...
【保姆级】JMeter Mqtt 压测配置
忽然有个紧急任务要对某个服务做MQTT做压测,紧急实操下JMeter,这里记录下非专业测试员的测试过程、(▽`),欢迎👏大家检查指点( ̄∇ ̄)/下载⏬工具JMeter官方下载地址https://jmeter.apache.org/do…...

C语言数据结构初阶(4)----带头双向循环链表
我们先来看看带头双向循环链表的结构:看到这里我们可能会产生一个想法:这个链表看起来好复杂的样子,是不是它的增删改查比单链表更难写呢?嘿嘿,还真的不是这样的,双向链表的增删改查是很好写的哦࿰…...

原生javascript手写一个丝滑的轮播图
通过本文,你将学到: htmlcssjs 没错,就是html,css,js,现在是框架盛行的时代,所以很少会有人在意原生三件套,通过本文实现一个丝滑的轮播图,带你重温html,css和js基础知识。 为什么选用轮播图做示例&…...
【Linux】进程优先级(进程优先级 Linux下优先级 用top命令更改已存在进程的nice 其他概念 进程切换)
文章目录进程优先级Linux下优先级用top命令更改已存在进程的nice:其他概念进程切换进程优先级 我们作为使用者一般不关心优先级,它跟我们的调度器有很大的关系,调度器是为了跟均衡的调度进程。 什么叫做优先级? 优先级和权限是两…...
2016年chatGPT之父Altman与马斯克的深度对话(值得一看)
2016年9月,现今OpenAI CEO,ChatGPT之父,时任创投公司Y Combinator的总裁Sam Altman在特斯拉加州弗里蒙特工厂采访了埃隆马斯克。马斯克阐述了创建OpenAI的初衷,以及就他而言,对于未来最为重要的五件事。这是OpenAI的两…...

基于vscode开发vue3项目的详细步骤教程 3 前端路由vue-router
1、Vue下载安装步骤的详细教程(亲测有效) 1_水w的博客-CSDN博客 2、Vue下载安装步骤的详细教程(亲测有效) 2 安装与创建默认项目_水w的博客-CSDN博客 3、基于vscode开发vue项目的详细步骤教程_水w的博客-CSDN博客 4、基于vscode开发vue项目的详细步骤教程 2 第三方图标库FontAw…...

【C语言】每日刷题 —— 牛客语法篇(5)
前言 大家好,继续更新专栏 c_牛客,不出意外的话每天更新十道题,难度也是从易到难,自己复习的同时也希望能帮助到大家,题目答案会根据我所学到的知识提供最优解。 🏡个人主页:悲伤的猪大肠9的博…...
操作系统(2.1)--进程的描述与控制
目录 一、前驱图和程序执行 1.前驱图 2.程序顺序执行 2.1 程序的顺序执行 2.2 程序顺序执行时的特征 3. 程序并发执行 3.1程序的并发执行 3.2 程序并发执行时的特征 一、前驱图和程序执行 1.前驱图 前趋图:是一个有向无循环图,用于描述进程之间执行的前后…...

JAVA查看动态代理类
JAVA查看代理类 1. 代理类 class 生成 System.setProperty // jdk8及之前的设置System.setProperty("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");// or System.getProperties().put("sun.misc.ProxyGenerator.saveGenerated…...

Chapter2 : SpringBoot配置
尚硅谷SpringBoot顶尖教程 1. 全局配置文件 SpringBoot使用一个全局的配置文件 application.properties 或者 application.yml ,该配置文件放在src/main/resources目录或者类路径/config目录下面, 可以用来修改SpringBoot自动配置的默认值。 yml是YA…...

手撕单链表练习
Topic 1:LeetCode——203. 移除链表元素203. 移除链表元素 - 力扣(LeetCode)移除链表中的数字6操作很简单,我们只需要把2的指向地址修改就好了,原来的指向地址是6现在改为3这个思路是完全正确的,但是在链表…...

Kubuntu安装教程
文章目录Kubuntu介绍下载Kubuntu在VMware虚拟机中安装Kubuntu1. 点击“创建新的虚拟机”2. 选择“自定义(高级)”3. 按照下图所示进行设置设置网络4. 点击“自定义硬件”5. 开启虚拟机6. 进入安装界面,选择中文,之后点击“安装Kub…...
[蓝桥杯] 树状数组与线段树问题(C/C++)
文章目录 一、动态求连续区间和 1、1 题目描述 1、2 题解关键思路与解答 二、数星星 2、1 题目描述 2、2 题解关键思路与解答 三、数列区间最大值 3、1 题目描述 3、2 题解关键思路与解答 标题:树状数组与线段树问题 作者:Ggggggtm 寄语:与其…...

Matlab-Loma Prieta 地震分析
此示例说明如何将带时间戳的地震数据存储在时间表中以及如何使用时间表函数来分析和可视化数据。 加载地震数据 示例文件quake.mat包含 1989 年 10 月 17 日圣克鲁斯山脉 Loma Prieta 地震的 200 Hz 数据。这些数据由加州大学圣克鲁斯分校查尔斯F里希特地震实验室的 Joel Yelli…...

Spring Boot全局异常处理
使用注解方式处理全局异常使用 ControllerAdvice (RestControllerAdvice) 配合 ExceptionHandler适用于返回数据的请求(一般是RESTful接口规范下的JSON报文)package com.example.exception;import org.slf4j.Logger; import org.s…...

LangGraph大模型脚手架实战:揭秘6种爆款智能体设计模式,玩转生产级Agent开发!
最近Herness大火,我就在反思,我们在日常进行智能体开发的过程中,是否也在做类似的事,我们用过claude code sdk、codex sdk、copilot cli等通用agent做封装,也用过dify或者coze搭工作流,也用过langchain做过…...

2026最权威的六大降AI率工具解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于学术创作以及报告撰写的场景当中,内容重复率超出标准限度常常是创作者所面临的…...

怪物猎人世界终极叠加层工具:HunterPie 5分钟快速上手指南
怪物猎人世界终极叠加层工具:HunterPie 5分钟快速上手指南 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/HunterPi…...

STM32H750调试KSZ8863翻车实录:从F4经验到H7的坑,硬件配置避雷指南
STM32H7与KSZ8863实战避坑指南:从F4经验到H7的硬件设计差异 调试以太网PHY芯片KSZ8863时,许多工程师会带着STM32F4的成功经验直接迁移到STM32H7平台,结果往往遭遇意想不到的硬件兼容性问题。本文将深入剖析两个平台在RMII接口设计上的关键差…...

从Kaggle竞赛到实战:基于XGBoost的Otto多分类产品识别系统构建
1. 从Kaggle竞赛到真实业务场景的跨越 第一次接触Otto数据集是在2015年的Kaggle竞赛上,当时只觉得这是个典型的多分类问题。直到去年为某跨境电商平台搭建商品自动分类系统时,我才真正理解这个案例的实战价值——90%的参赛者只关注模型精度,而…...

碧蓝航线脚本补丁Perseus:原生库的无偏移皮肤解锁技术实现
碧蓝航线脚本补丁Perseus:原生库的无偏移皮肤解锁技术实现 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 在移动游戏修改领域,实现版本兼容性一直是技术挑战的核心。Perseus项目通…...

OpenClaw 汉化版 Windows 一键安装指南|零基础 5 分钟部署 告别命令行
前言 在本地部署 AI 智能体时,英文界面晦涩、命令行操作复杂、环境配置繁琐,是很多零基础用户的三大痛点。OpenClaw 汉化中文版专为国内用户优化,采用全中文图形化界面 免环境配置 一键部署设计,全程无任何命令行操作ÿ…...

【AI原生多任务学习实战白皮书】:SITS 2026官方未公开的5大优化范式与3类典型失效场景复盘
更多请点击: https://intelliparadigm.com 第一章:AI原生多任务学习:SITS 2026多目标优化实战技巧 在 SITS 2026 挑战赛中,AI 原生多任务学习(MTL)不再仅依赖共享特征表示,而是通过任务感知梯…...

Python 爬虫反爬突破:流量指纹伪装规避流量监测
前言 在爬虫反爬对抗体系中,IP 封禁、UA 伪造、验证码拦截属于表层防护,而流量指纹监测是现阶段大中型互联网平台、资讯门户、电商业务系统采用的高阶反爬手段。服务端与网关防火墙会基于全网流量行为、报文特征、连接握手规则、请求时序模型、协议栈特…...

最新OpenClaw 2.7.1 Windows 环境快速部署教程
Windows 一键部署 OpenClaw v2.7.1 教程|5 分钟搭建本地 AI 智能体 在开源 AI 工具持续更新的当下,OpenClaw(小龙虾)凭借本地运行、零代码操控、自动化执行等特点,成为广受用户欢迎的本地 AI 智能体,GitHu…...