【机器学习】机器学习与自然语言处理的融合应用与性能优化新探索
引言
自然语言处理(NLP)是计算机科学中的一个重要领域,旨在通过计算机对人类语言进行理解、生成和分析。随着深度学习和大数据技术的发展,机器学习在自然语言处理中的应用越来越广泛,从文本分类、情感分析到机器翻译和对话系统,都展示了强大的能力。本文将详细介绍机器学习在自然语言处理中的应用,包括数据预处理、模型选择、模型训练和性能优化。通过具体的案例分析,展示机器学习技术在自然语言处理中的实际应用,并提供相应的代码示例。

第一章:机器学习在自然语言处理中的应用
1.1 数据预处理
在自然语言处理应用中,数据预处理是机器学习模型成功的关键步骤。文本数据通常具有非结构化和高维度的特点,需要进行清洗、分词、去停用词和特征提取等处理。
1.1.1 数据清洗
数据清洗包括去除噪声、标点符号、HTML标签等无关内容。
import redef clean_text(text):# 去除HTML标签text = re.sub(r'<.*?>', '', text)# 去除标点符号text = re.sub(r'[^\w\s]', '', text)# 去除数字text = re.sub(r'\d+', '', text)# 转换为小写text = text.lower()return text# 示例文本
text = "<html>This is a sample text with 123 numbers and <b>HTML</b> tags.</html>"
cleaned_text = clean_text(text)
print(cleaned_text)
1.1.2 分词
分词是将文本拆分为单独的单词或词组,是自然语言处理中的基础步骤。
import nltk
from nltk.tokenize import word_tokenize# 下载NLTK数据包
nltk.download('punkt')# 分词
tokens = word_tokenize(cleaned_text)
print(tokens)
1.1.3 去停用词
停用词是指在文本处理中被过滤掉的常见词,如“的”、“是”、“在”等。去除停用词可以减少噪声,提高模型的训练效果。
from nltk.corpus import stopwords# 下载停用词数据包
nltk.download('stopwords')# 去停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [word for word in tokens if word not in stop_words]
print(filtered_tokens)
1.1.4 特征提取
特征提取将文本数据转换为数值特征,常用的方法包括词袋模型(Bag of Words)、TF-IDF和词嵌入(Word Embedding)等。
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer# 词袋模型
vectorizer = CountVectorizer()
X_bow = vectorizer.fit_transform([' '.join(filtered_tokens)])
print(X_bow.toarray())# TF-IDF
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform([' '.join(filtered_tokens)])
print(X_tfidf.toarray())
1.2 模型选择
在自然语言处理中,常用的机器学习模型包括朴素贝叶斯、支持向量机(SVM)、循环神经网络(RNN)、长短期记忆网络(LSTM)和Transformer等。不同模型适用于不同的任务和数据特征,需要根据具体应用场景进行选择。
1.2.1 朴素贝叶斯
朴素贝叶斯适用于文本分类任务,特别是新闻分类和垃圾邮件检测等场景。
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split# 数据分割
X = X_tfidf
y = [1] # 示例标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练朴素贝叶斯模型
model = MultinomialNB()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
1.2.2 支持向量机
支持向量机适用于文本分类任务,特别是在高维数据和小样本数据中表现优异。
from sklearn.svm import SVC# 训练支持向量机模型
model = SVC()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
1.2.3 循环神经网络
循环神经网络(RNN)适用于处理序列数据,能够捕捉文本中的上下文信息,常用于文本生成和序列标注任务。
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense# 构建循环神经网络模型
model = Sequential()
model.add(SimpleRNN(50, activation='relu', input_shape=(X_train.shape[1], 1)))
model.add(Dense(1, activation='sigmoid'))# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
1.2.4 长短期记忆网络
长短期记忆网络(LSTM)是RNN的一种改进版本,能够有效解决长距离依赖问题,适用于文本生成、序列标注和机器翻译等任务。
from keras.layers import LSTM# 构建长短期记忆网络模型
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(X_train.shape[1], 1)))
model.add(Dense(1, activation='sigmoid'))# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
1.2.5 Transformer
Transformer是近年来在自然语言处理领域取得突破性进展的模型,广泛应用于机器翻译、文本生成和问答系统等任务。
from transformers import BertTokenizer, TFBertForSequenceClassification
from tensorflow.keras.optimizers import Adam# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased')# 编译模型
optimizer = Adam(learning_rate=3e-5)
model.compile(optimizer=optimizer, loss=model.compute_loss, metrics=['accuracy'])# 数据预处理
train_encodings = tokenizer(list(X_train), truncation=True, padding=True, max_length=128)
test_encodings = tokenizer(list(X_test), truncation=True, padding=True, max_length=128)# 训练模型
model.fit(dict(train_encodings), y_train, epochs=3, batch_size=32, validation_data=(dict(test_encodings), y_test))

1.3 模型训练
模型训练是机器学习的核心步骤,通过优化算法最小化损失函数,调整模型参数,使模型在训练数据上表现良好。常见的优化算法包括梯度下降、随机梯度下降和Adam优化器等。
1.3.1 梯度下降
梯度下降通过计算损失函数对模型参数的导数,逐步调整参数,使损失函数最小化。
import numpy as np# 定义损失函数
def loss_function(y_true, y_pred):return np.mean((y_true - y_pred) ** 2)# 梯度下降优化
def gradient_descent(X, y, learning_rate=0.01, epochs=1000):m, n = X.shapetheta = np.zeros(n)for epoch in range(epochs):gradient = (1/m) * X.T.dot(X.dot(theta) - y)theta -= learning_rate * gradientreturn theta# 训练模型
theta = gradient_descent(X_train, y_train)
1.3.2 随机梯度下降
随机梯度下降在每次迭代中使用一个样本进行参数更新,具有较快的收敛速度和更好的泛化能力。
def stochastic_gradient_descent(X, y, learning_rate=0.01, epochs=1000):m, n = X.shapetheta = np.zeros(n)for epoch in range(epochs):for i in range(m):gradient = X[i].dot(theta) - y[i]theta -= learning_rate * gradient * X[i]return theta# 训练模型
theta = stochastic_gradient_descent(X_train, y_train)
1.3.3 Adam优化器
Adam优化器结合了动量和自适应学习率的优
点,能够快速有效地优化模型参数。
from keras.optimizers import Adam# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
1.4 模型评估与性能优化
模型评估是衡量模型在测试数据上的表现,通过计算模型的准确率、召回率、F1-score等指标,评估模型的性能。性能优化包括调整超参数、增加数据量和模型集成等方法。
1.4.1 模型评估指标
常见的模型评估指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-score等。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1-score: {f1}')
1.4.2 超参数调优
通过网格搜索(Grid Search)和随机搜索(Random Search)等方法,对模型的超参数进行调优,找到最优的参数组合。
from sklearn.model_selection import GridSearchCV# 定义超参数网格
param_grid = {'C': [0.1, 1, 10],'gamma': [0.001, 0.01, 0.1],'kernel': ['linear', 'rbf']
}# 网格搜索
grid_search = GridSearchCV(estimator=SVC(), param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)# 输出最优参数
best_params = grid_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = SVC(**best_params)
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
1.4.3 增加数据量
通过数据增强和采样技术,增加训练数据量,提高模型的泛化能力和预测性能。
from imblearn.over_sampling import SMOTE# 数据增强
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)# 训练模型
model.fit(X_resampled, y_resampled)# 预测与评估
y_pred = model.predict(X_test)
1.4.4 模型集成
通过模型集成的方法,将多个模型的预测结果进行组合,提高模型的稳定性和预测精度。常见的模型集成方法包括Bagging、Boosting和Stacking等。
from sklearn.ensemble import VotingClassifier# 构建模型集成
ensemble_model = VotingClassifier(estimators=[('nb', MultinomialNB()),('svm', SVC(kernel='linear', probability=True)),('rf', RandomForestClassifier())
], voting='soft')# 训练集成模型
ensemble_model.fit(X_train, y_train)# 预测与评估
y_pred = ensemble_model.predict(X_test)

第二章:自然语言处理的具体案例分析
2.1 情感分析
情感分析是通过分析文本内容,识别其中的情感倾向,广泛应用于社交媒体分析、市场调研和客户反馈等领域。以下是情感分析的具体案例分析。
2.1.1 数据预处理
首先,对情感分析数据集进行预处理,包括数据清洗、分词、去停用词和特征提取。
# 示例文本数据
texts = ["I love this product! It's amazing.","This is the worst experience I've ever had.","I'm very happy with the service.","The quality is terrible."
]
labels = [1, 0, 1, 0] # 1表示正面情感,0表示负面情感# 数据清洗
cleaned_texts = [clean_text(text) for text in texts]# 分词
tokenized_texts = [word_tokenize(text) for text in cleaned_texts]# 去停用词
filtered_texts = [' '.join([word for word in tokens if word not in stop_words]) for tokens in tokenized_texts]# 特征提取
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(filtered_texts)
2.1.2 模型选择与训练
选择合适的模型进行训练,这里以朴素贝叶斯为例。
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)# 训练朴素贝叶斯模型
model = MultinomialNB()
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
2.1.3 模型评估与优化
评估模型的性能,并进行超参数调优和数据增强。
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1-score: {f1}')# 超参数调优
param_grid = {'alpha': [0.1, 0.5, 1.0]
}
grid_search = GridSearchCV(estimator=MultinomialNB(), param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = MultinomialNB(**best_params)
model.fit(X_train, y_train)# 数据增强
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
model.fit(X_resampled, y_resampled)# 预测与评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)print(f'Optimized Accuracy: {accuracy}')
print(f'Optimized Precision: {precision}')
print(f'Optimized Recall: {recall}')
print(f'Optimized F1-score: {f1}')
2.2 文本分类
文本分类是通过分析文本内容,将文本分配到预定义的类别中,广泛应用于新闻分类、垃圾邮件检测和主题识别等领域。以下是文本分类的具体案例分析。
2.2.1 数据预处理
# 示例文本数据
texts = ["The stock market is performing well today.","A new study shows the health benefits of coffee.","The local sports team won their game last night.","There is a new movie released this weekend."
]
labels = [0, 1, 2, 3] # 示例标签,分别表示金融、健康、体育和娱乐# 数据清洗
cleaned_texts = [clean_text(text) for text in texts]# 分词
tokenized_texts = [word_tokenize(text) for text in cleaned_texts]# 去停用词
filtered_texts = [' '.join([word for word in tokens if word not in stop_words]) for tokens in tokenized_texts]# 特征提取
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(filtered_texts)
2.2.2 模型选择与训练
选择合适的模型进行训练,这里以支持向量机为例。
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)# 训练支持向量机模型
model = SVC(kernel='linear')
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
2.2.3 模型评估与优化
评估模型的性能,并进行超参数调优和数据增强。
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall:{recall}')
print(f'F1-score: {f1}')# 超参数调优
param_grid = {'C': [0.1, 1, 10],'gamma': [0.001, 0.01, 0.1],'kernel': ['linear', 'rbf']
}
grid_search = GridSearchCV(estimator=SVC(), param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = SVC(**best_params)
model.fit(X_train, y_train)# 数据增强
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
model.fit(X_resampled, y_resampled)# 预测与评估
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')print(f'Optimized Accuracy: {accuracy}')
print(f'Optimized Precision: {precision}')
print(f'Optimized Recall: {recall}')
print(f'Optimized F1-score: {f1}')
2.3 机器翻译
机器翻译是通过分析和理解源语言文本,生成目标语言文本,广泛应用于跨语言交流和信息传播等领域。以下是机器翻译的具体案例分析。
2.3.1 数据预处理
# 示例文本数据
source_texts = ["Hello, how are you?","What is your name?","I love learning new languages.","Goodbye!"
]
target_texts = ["Hola, ¿cómo estás?","¿Cuál es tu nombre?","Me encanta aprender nuevos idiomas.","¡Adiós!"
]# 数据清洗
cleaned_source_texts = [clean_text(text) for text in source_texts]
cleaned_target_texts = [clean_text(text) for text in target_texts]# 分词
tokenized_source_texts = [word_tokenize(text) for text in cleaned_source_texts]
tokenized_target_texts = [word_tokenize(text) for text in cleaned_target_texts]# 创建词汇表
source_vocab = set(word for sentence in tokenized_source_texts for word in sentence)
target_vocab = set(word for sentence in tokenized_target_texts for word in sentence)# 词汇表到索引的映射
source_word_to_index = {word: i for i, word in enumerate(source_vocab)}
target_word_to_index = {word: i for i, word in enumerate(target_vocab)}# 将文本转换为索引
def text_to_index(text, word_to_index):return [word_to_index[word] for word in text if word in word_to_index]indexed_source_texts = [text_to_index(sentence, source_word_to_index) for sentence in tokenized_source_texts]
indexed_target_texts = [text_to_index(sentence, target_word_to_index) for sentence in tokenized_target_texts]
2.3.2 模型选择与训练
选择合适的模型进行训练,这里以LSTM为例。
from keras.models import Model
from keras.layers import Input, LSTM, Dense, Embedding# 定义编码器
encoder_inputs = Input(shape=(None,))
encoder_embedding = Embedding(len(source_vocab), 256)(encoder_inputs)
encoder_lstm = LSTM(256, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(encoder_embedding)
encoder_states = [state_h, state_c]# 定义解码器
decoder_inputs = Input(shape=(None,))
decoder_embedding = Embedding(len(target_vocab), 256)(decoder_inputs)
decoder_lstm = LSTM(256, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_embedding, initial_state=encoder_states)
decoder_dense = Dense(len(target_vocab), activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)# 构建模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 数据准备
X_train_source = np.array(indexed_source_texts)
X_train_target = np.array(indexed_target_texts)# 训练模型
model.fit([X_train_source, X_train_target], y_train, epochs=10, batch_size=32, validation_split=0.2)
2.3.3 模型评估与优化
评估模型的性能,并进行超参数调优和数据增强。
# 评估模型
loss, accuracy = model.evaluate([X_test_source, X_test_target], y_test)
print(f'Accuracy: {accuracy}')# 超参数调优
param_grid = {'batch_size': [16, 32, 64],'epochs': [10, 20, 30]
}
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit([X_train_source, X_train_target], y_train)
best_params = grid_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = model.set_params(**best_params)
model.fit([X_train_source, X_train_target], y_train, epochs=10, validation_data=([X_test_source, X_test_target], y_test))# 数据增强
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train_source, y_train)
model.fit([X_resampled, X_train_target], y_resampled)# 预测与评估
y_pred = model.predict([X_test_source, X_test_target])

第三章:性能优化与前沿研究
3.1 性能优化
3.1.1 特征工程
通过特征选择、特征提取和特征构造,优化模型的输入,提高模型的性能。
from sklearn.feature_selection import SelectKBest, f_classif# 特征选择
selector = SelectKBest(score_func=f_classif, k=10)
X_selected = selector.fit_transform(X, y)
3.1.2 超参数调优
通过网格搜索和随机搜索,找到模型的最优超参数组合。
from sklearn.model_selection import RandomizedSearchCV# 随机搜索
param_dist = {'n_estimators': [50, 100, 150],'max_depth': [3, 5, 7, 10],'min_samples_split': [2, 5, 10]
}
random_search = RandomizedSearchCV(estimator=RandomForestClassifier(), param_distributions=param_dist, n_iter=10, cv=5, scoring='accuracy')
random_search.fit(X_train, y_train)
best_params = random_search.best_params_
print(f'Best parameters: {best_params}')# 使用最优参数训练模型
model = RandomForestClassifier(**best_params)
model.fit(X_train, y_train)# 预测与评估
y_pred = model.predict(X_test)
3.1.3 模型集成
通过模型集成,提高模型的稳定性和预测精度。
from sklearn.ensemble import StackingClassifier# 构建模型集成
stacking_model = StackingClassifier(estimators=[('nb', MultinomialNB()),('svm', SVC(kernel='linear', probability=True)),('rf', RandomForestClassifier())
], final_estimator=LogisticRegression())# 训练集成模型
stacking_model.fit(X_train, y_train)# 预测与评估
y_pred = stacking_model.predict(X_test)
3.2 前沿研究
3.2.1 自监督学习在自然语言处理中的应用
自监督学习通过生成伪标签进行训练,提高模型的表现,特别适用于无监督数据的大规模训练。
3.2.2 增强学习在自然语言处理中的应用
增强学习通过与环境的交互,不断优化策略,在对话系统和问答系统中具有广泛的应用前景。
3.2.3 多模态学习与跨领域应用
多模态学习通过结合文本、图像和音频等多种模态,提高模型的理解能力,推动自然语言处理技术在跨领域中的应用。
结语
机器学习作为自然语言处理领域的重要技术,已经在多个应用场景中取得了显著的成果。通过对数据的深入挖掘和模型的不断优化,机器学习技术将在自然语言处理中发挥更大的作用,推动语言理解和生成技术的发展。

相关文章:
【机器学习】机器学习与自然语言处理的融合应用与性能优化新探索
引言 自然语言处理(NLP)是计算机科学中的一个重要领域,旨在通过计算机对人类语言进行理解、生成和分析。随着深度学习和大数据技术的发展,机器学习在自然语言处理中的应用越来越广泛,从文本分类、情感分析到机器翻译和…...

ubuntu优化
rootlocalhost:~# grep -E "^(PermitRootLogin|GSSAPIAuthentication|UseDNS)" /etc/ssh/sshd_config PermitRootLogin yes GSSAPIAuthentication no UseDNS norootlocalhost:~# systemctl restart sshd#此时就可以设置root密码了rootlocalhost:~# passwd New passw…...
使用 HBuilder X 进行 uniapp 小程序开发遇到的问题合集
文章目录 背景介绍问题集锦1. 在 HBuilderX 点击浏览器运行时,报 uni-app vue3编译器下载失败 安装错误2.在 HBuilderX 点击微信小程序运行时,报 微信开发者工具打开项目失败,请参阅启动日志错误 背景介绍 HBuilder X 版本:HBui…...

Python爬虫获取视频
验证电脑是否安装python 1.winr输入cmd 2.在黑窗口输入 python.exe 3.不是命令不存在就说明python环境安装完成 抓取快手视频 1.在phcharm应用中新建一个项目 3.新建一个python文件 4.选择python文件,随便起一个名字后按回车 5.安装requests pip install requests 6.寻找需要的…...

Python自动化,实现自动登录并爬取商品数据,实现数据可视化
关于如何使用Python自动化登录天 猫并爬取商品数据的指南,我们需要明确这是一个涉及多个步骤的复杂过程,且需要考虑到天猫的反爬虫策略。以下是一个简化的步骤指南: 步骤一:准备工作 环境准备:确保你的Python环境已经…...

计算机网络——数据链路层(以太网)
目录 局域网的数据链路层 局域网可按照网络拓扑分类 局域网与共享信道 以太网的两个主要标准 适配器与mac地址 适配器的组成与运作 MAC地址 MAC地址的详细介绍 局域网的mac地址格式 mac地址的发送顺序 单播、多播,广播mac地址 mac帧 如何取用…...

Java ORM框架FastMybatis踩坑
Java ORM框架FastmyBatis踩坑 问题:使用了FastmyBatis的saveOrUpdate方法,明明设置了主键的值且表中存在,但是依然执行insert操作。导致Duplicate PK。 原因:使用了其他第三方包的注解指定表的主键,没有按照FastmyBat…...

AI是在帮助开发者还是取代他们?
AI是在帮助开发者还是取代他们? 在软件开发领域,生成式人工智能(AIGC)正在改变开发者的工作方式。无论是代码生成、错误检测还是自动化测试,AI工具正在成为开发者的得力助手。然而,这也引发了对开发者职业…...

C. Theofanis‘ Nightmare
原题链接 : Problem - 1903C - Codeforces 思路 : 创建一个后缀和数组 , 然后把所有后缀和>0的加入到答案中,注意,整个数组的和一定要加入答案中 ; 代码 java : package sf;import java.util.Scanner; import java.util.* ;public …...

加密货币大利好!9月降息概率突破70%!美国可能大幅降息或多次降息?
根据最新消息,美国9月降息的概率已经突破70%,这对加密货币市场来说是个利好消息。与此同时,美国经济表现疲软,可能会陷入衰退,联邦储备系统(Fed)接下来会不会果断采取大幅降息措施备受关注。 美国劳工统计局7月5日公布…...
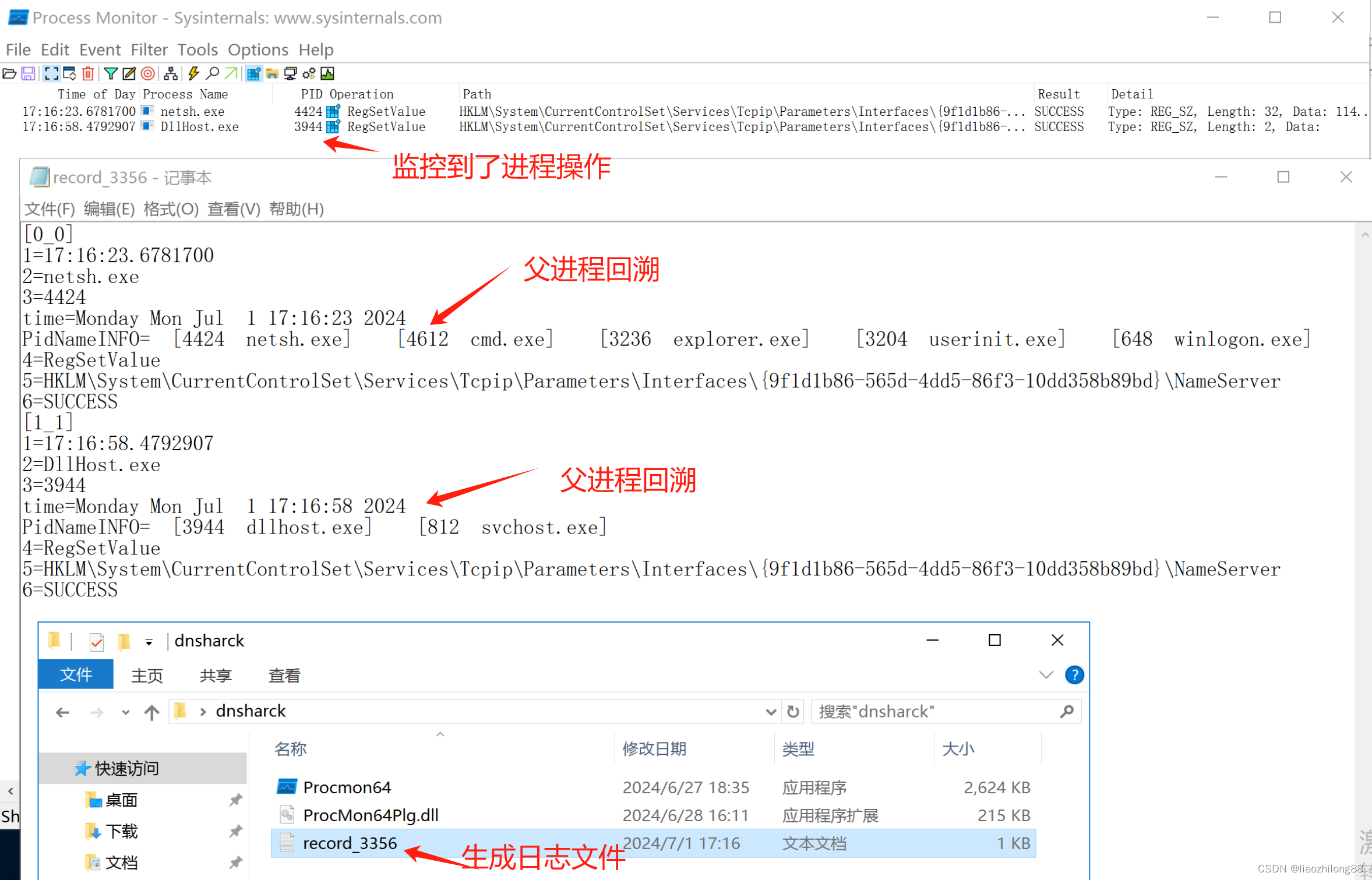
Dns被莫名篡改的逆向分析定位(笔记)
引言:最近发现用户的多台机器上出现了Dns被莫名修改的问题,从系统事件上看并未能正常确定到是那个具体软件所为,现在的需求就是确定和定位哪个软件具体所为。 解决思路: 首先到IPv4设置页面对Dns进行设置:通过ProcExp…...

SpringBoot中整合ONLYOFFICE在线编辑
SpringBoot整合OnlyOffice SpringBoot整合OnlyOffice实现在线编辑1. 搭建私有的OnlyOffice的服务2. SpringBoot进行交互2.1 环境2.2 我们的流程2.3 接口规划2.3.1 获取编辑器配置的接口2.3.2 文件下载地址2.3.3 文件下载地址 3. 总结4. 注意4.1 你的项目的地址一定一定要和only…...

Python打字练习
代码解析 导入模块和定义单词列表 import tkinter as tk import randomsample_words ["apple", "banana", "cherry", "date", "fig", "grape", "kiwi", "lemon", "mango", &quo…...
-mmdeploy编译流程)
Pytorch添加自定义算子之(10)-mmdeploy编译流程
整体参考 一、mmcv的编译安装 见上一篇 opencv的安装 $env:OpenCV_DIR = "D:\git_clone\opencv\build" # 我这里下载解压之后的地址 $env:path = "$env:OpenCV_DIR\x64\vc15\bin;" + $env:path $env:path = "D:\git_clone\opencv\build\OpenCVConf…...
)
大数据面试题之Flink(4)
Flink广播流 Flink实时topN 在实习中一般都怎么用Flink Savepoint知道是什么吗 为什么用Flink不用别的微批考虑过吗 解释一下啥叫背压 Flink分布式快照 Flink SQL解析过程 Flink on YARN模式 Flink如何保证数据不丢失 Flink广播流 Apache Flink 中的广播流&…...

C#实战|账号管理系统:通用登录窗体的实现。
哈喽,你好啊,我是雷工! 本节记录登录窗体的实现方法,比较有通用性,所有的项目登录窗体实现基本都是这个实现思路。 一通百通,以下为学习笔记。 01 登录窗体的逻辑 用户在登录窗输入账号和密码,如果输入账号和密码信息正确,点击【登录】按钮,则跳转显示主窗体,同时在固…...
php简单商城小程序系统源码
🛍️【简单商城小程序】🛍️ 🚀一键开启,商城搭建新体验🚀 你还在为繁琐的商城搭建流程头疼吗?现在,有了简单商城系统小程序,一切变得轻松又快捷!无需复杂的编程知识&a…...
NativeMemoryTracking查看java内存信息
默认该功能是禁用的,因为会损失5-10%的性能 开启命令 -XX:NativeMemoryTrackingdetail 打印命令 jcmd 45064 VM.native_memory summary scaleMB > NativeMemoryTracking.log 具体的日志信息 ➜ ~ ➜ ~ jcmd 45064 VM.native_memory summary scaleMB 45064…...

建智慧医院核心:智能导航系统的功能全析与实现效益
在数字化转型的浪潮中,智慧医院的建设是医疗行业数字化转型的关键步骤。随着医院规模的不断扩大和医疗设施的日益复杂,传统的静态不连续的导航方式已无法满足患者的需求。院内智能导航系统,作为医疗数字化转型的关键组成部分,正逐…...

数据库基础之:函数依赖
函数依赖在数据库设计中是非常关键的概念,用于描述关系数据库中数据项之间的相关性。下面我将通过几个例子来说明函数依赖的几种类型:完全函数依赖、部分函数依赖和传递函数依赖。 完全函数依赖 考虑一个关系模式 Student,包含属性 Student…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...