如何使用uer做多分类任务
如何使用uer做多分类任务
语料集下载

找到这里点击即可
里面是这有json文件的

因此我们对此要做一些处理,将其转为tsv格式
# -*- coding: utf-8 -*-
import json
import csv
import chardet# 检测文件编码
def detect_encoding(file_path):with open(file_path, 'rb') as f:raw_data = f.read()return chardet.detect(raw_data)['encoding']# 输入文件名
input_file = './datasets/iflytek/train.json'
# 输出文件名
output_file = './datasets/iflytek/train.tsv'# 检测输入文件的编码格式
file_encoding = detect_encoding(input_file)# 打开输入的 JSON 文件和输出的 TSV 文件
with open(input_file, 'r', encoding=file_encoding) as json_file, open(output_file, 'w', newline='', encoding='utf-8') as tsv_file:# 准备 TSV 写入器tsv_writer = csv.writer(tsv_file, delimiter='\t')# 写入表头(列表['label', 'label_des', 'sentence']中要注意根据json文件中的键值做更换)tsv_writer.writerow(['label', 'label_des', 'sentence'])# 逐行读取 JSON 文件for line in json_file:try:# 解析每一行的 JSON 数据json_data = json.loads(line.strip())# 写入到 TSV 文件中,(列表['label', 'label_des', 'sentence']中要注意根据json文件中的键值做更换)tsv_writer.writerow([json_data['label'], json_data['label_des'], json_data['sentence']])except json.JSONDecodeError as e:print(f"无法解析的行: {line.strip()}")print(f"错误信息: {e}")print(f"JSON 文件已成功转换为 TSV 文件,输入文件编码: {file_encoding}")接着呢要把所有tsv文件的sentence表头名改成text_a,不然运行uer框架会报错,原因请看源代码逻辑
def read_dataset(args, path):dataset, columns = [], {}with open(path, mode="r", encoding="utf-8") as f:for line_id, line in enumerate(f):if line_id == 0:for i, column_name in enumerate(line.rstrip("\r\n").split("\t")):columns[column_name] = icontinueline = line.rstrip("\r\n").split("\t")tgt = int(line[columns["label"]])if args.soft_targets and "logits" in columns.keys():soft_tgt = [float(value) for value in line[columns["logits"]].split(" ")]if "text_b" not in columns: # Sentence classification.text_a = line[columns["text_a"]]src = args.tokenizer.convert_tokens_to_ids([CLS_TOKEN] + args.tokenizer.tokenize(text_a) + [SEP_TOKEN])seg = [1] * len(src)else: # Sentence-pair classification.text_a, text_b = line[columns["text_a"]], line[columns["text_b"]]src_a = args.tokenizer.convert_tokens_to_ids([CLS_TOKEN] + args.tokenizer.tokenize(text_a) + [SEP_TOKEN])src_b = args.tokenizer.convert_tokens_to_ids(args.tokenizer.tokenize(text_b) + [SEP_TOKEN])src = src_a + src_bseg = [1] * len(src_a) + [2] * len(src_b)if len(src) > args.seq_length:src = src[: args.seq_length]seg = seg[: args.seq_length]if len(src) < args.seq_length:PAD_ID = args.tokenizer.convert_tokens_to_ids([PAD_TOKEN])[0]src += [PAD_ID] * (args.seq_length - len(src))seg += [0] * (args.seq_length - len(seg))if args.soft_targets and "logits" in columns.keys():dataset.append((src, tgt, seg, soft_tgt))else:dataset.append((src, tgt, seg))return dataset
这里规定好了表头名只有label,text_a,text_b
搞完之后进入训练代码,我的显存只有16G,因此
python finetune/run_classifier.py --pretrained_model_path models/cluecorpussmall_roberta_wwm_large_seq512_model.bin --vocab_path models/google_zh_vocab.txt --config_path models/bert/large_config.json --train_path datasets/iflytek/train.tsv --dev_path datasets/iflytek/dev.tsv --output_model_path models/iflytek_classifier_model.bin --epochs_num 3 --batch_size 16 --seq_length 128


这里可以看到只有61.49的正确率,其实是因为显存还不够,训练不了那么大的,标准的参数应该设置为batch_size=32 seq_length=256
有能力的可以更改参数进行训练
接着来预测
python inference/run_classifier_infer.py --load_model_path models/iflytek_classifier_model.bin --vocab_path models/google_zh_vocab.txt --config_path models/bert/large_config.json --test_path datasets/iflytek/test.tsv --prediction_path datasets/iflytek/prediction.tsv --seq_length 256 --labels_num 119

最后自行查看预测效果
相关文章:
如何使用uer做多分类任务
如何使用uer做多分类任务 语料集下载 找到这里点击即可 里面是这有json文件的 因此我们对此要做一些处理,将其转为tsv格式 # -*- coding: utf-8 -*- import json import csv import chardet# 检测文件编码 def detect_encoding(file_path):with open(file_path,…...

【HICE】转发服务器实验
1.在本地主机上操作 2.在客户端操作设置主机的IP地址为dns 3.测试,客户机是否能ping通...

MATLAB-分类CPO-RF-Adaboost冠豪猪优化器(CPO)优化RF随机森林结合Adaboost分类预测(二分类及多分类)
MATLAB-分类CPO-RF-Adaboost冠豪猪优化器(CPO)优化RF随机森林结合Adaboost分类预测(二分类及多分类) 分类CPO-RF-Adaboost冠豪猪优化器(CPO)优化RF随机森林结合Adaboost分类预测(二分类及多分类…...
绝区贰--及时优化降低 LLM 成本和延迟
前言 大型语言模型 (LLM) 为各行各业带来了变革性功能,让用户能够利用尖端的自然语言处理技术处理各种应用。然而,这些强大的 AI 系统的便利性是有代价的 — 确实如此。随着 LLM 变得越来越普及,其计算成本和延迟可能会迅速增加,…...

JDBC【封装工具类、SQL注入问题】
day54 JDBC 封装工具类01 创建配置文件 DBConfig.properties driverNamecom.mysql.cj.jdbc.Driver urljdbc:mysql://localhost:3306/qnz01?characterEncodingutf8&serverTimezoneUTC usernameroot passwordroot新建配置文件,不用写后缀名 创建工具类 将变…...
Windows打开redis以及Springboot整合redis
目录 前言Windows系统打开redisSpringboot整合redis依赖实体类yml配置文件config配置各个数据存储类型分别说明记录string数据写入redis,并查询通过命令行查询 list插入数据到redis中从redis中读取命令读取数据 hash向redis中逐个添加map键值对获取key对应的map中所…...

MySQL使用LIKE索引是否失效的验证
1、简单的示例展示 在MySQL中,LIKE查询可以通过一些方法来使得LIKE查询能够使用索引。以下是一些可以使用的方法: 使用前导通配符(%),但确保它紧跟着一个固定的字符。 避免使用后置通配符(%)&…...
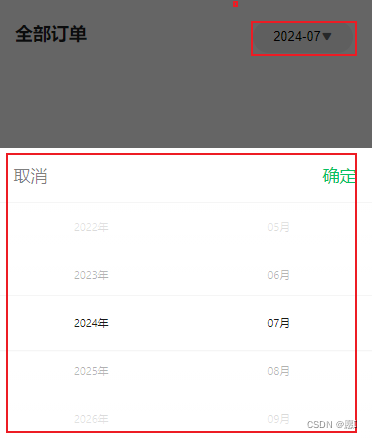
封装日历uniapp,只显示年月不显示日
默认展示最新日期 子组件 <template><view class"date-picker"><picker mode"date" fields"month" change"onDateChange" :value"selectedDate"><view class"picker">{{ selectedDate…...
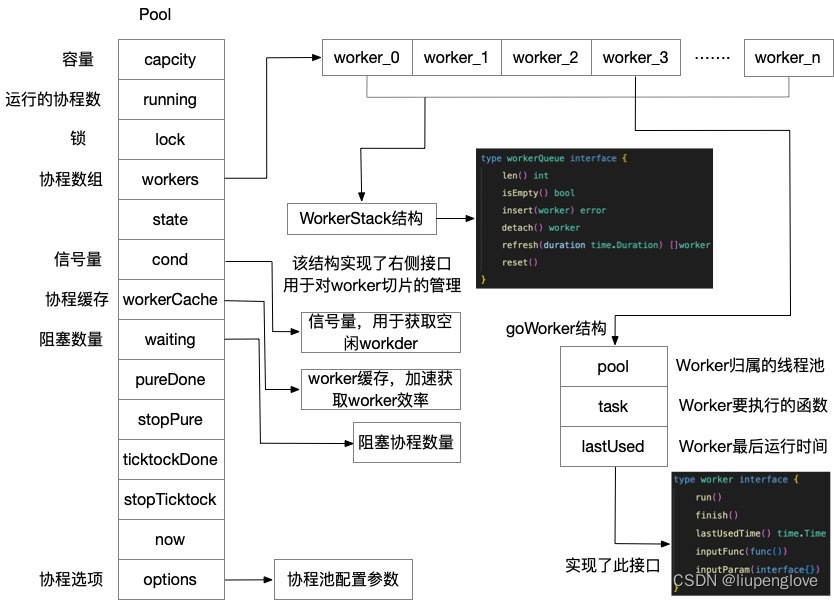
golang线程池ants-实现架构
1、总体架构 ants协程池,在使用上有多种方式(使用方式参考这篇文章:golang线程池ants-四种使用方法),但是在实现的核心就一个,如下架构图: 总的来说,就是三个数据结构: Pool、WorkerStack、goW…...
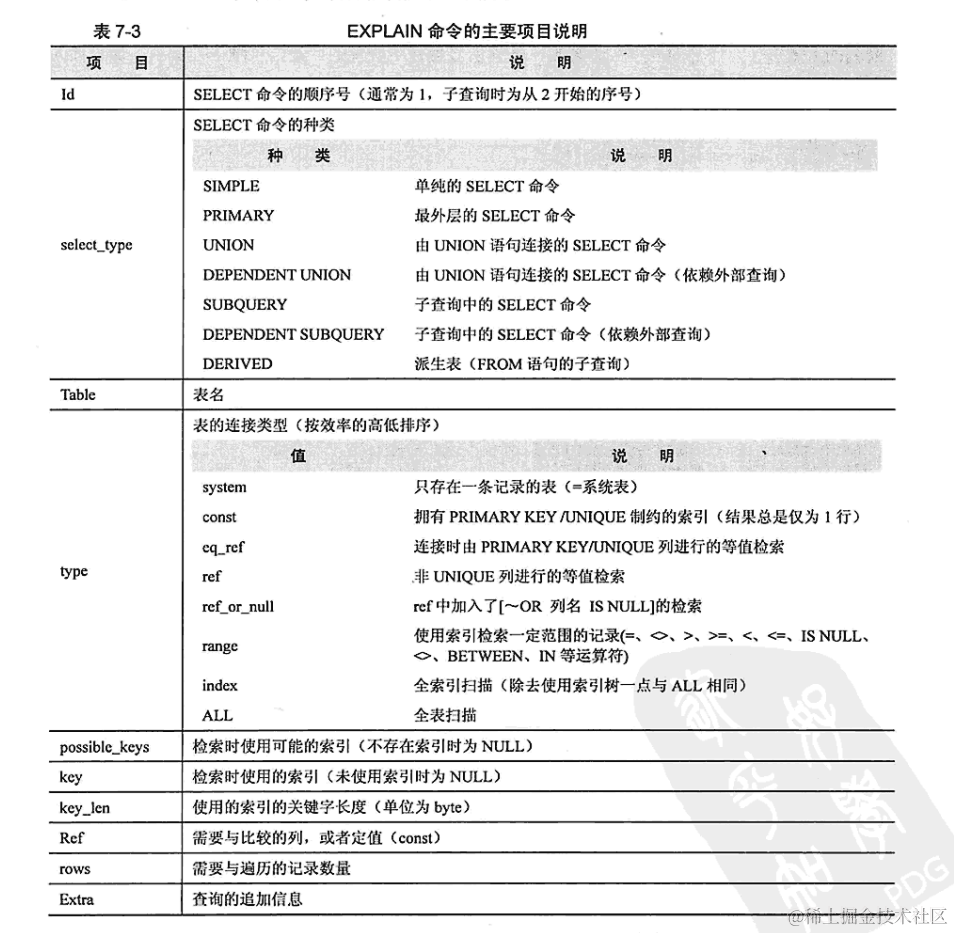
Mysql面试合集
概念 是一个开源的关系型数据库。 数据库事务及其特性 事务:是一系列的数据库操作,是数据库应用的基本逻辑单位。 事务特性: (1)原子性:即不可分割性,事务要么全部被执行,要么就…...
: 构建变体与自定义任务)
Android Gradle 开发与应用 (五): 构建变体与自定义任务
目录 1. 概述 2. 构建变体 2.1 构建变体的概念 2.2 构建类型 2.3 产品风味 2.4 构建变体的使用 3. 自定义任务 3.1 自定义任务的概念 3.2 创建自定义任务 3.3 配置任务依赖 3.4 任务类型 3.5 动态任务 3.6 自定义任务执行顺序 4. 案例 4.1 多渠道打包 4.2 自动…...

Django学习第六天
启动项目命令 python manage.py runserver 取消模态框功能 js实现列表数据删除 第二种实现思路 使用jquery修改模态框标题 编辑页面拿到数据库数据显示默认数据功能实现 想要去数据库中获取数据时:对象/字典 三种不同的数据类型 使用Ajax传入数据实现表单编辑&…...

docker部署mycat,连接上面一篇的一主二从mysql
一、docker下载mycat镜像 查看安装结果 这个名称太长,在安装容器时不方便操作,设置标签为mycat docker tag longhronshens/mycat-docker mycat 二、安装容器 先安装一个,主要目的是获得配置文件 docker run -it -d --name mycat -p 8066:…...

VUE2拖拽组件:vue-draggable-resizable-gorkys
vue-draggable-resizable-gorkys组件基于vue-draggable-resizable进行二次开发, 用于可调整大小和可拖动元素的组件并支持冲突检测、元素吸附、元素对齐、辅助线 安装: npm install --save vue-draggable-resizable-gorkys 全局引用: import Vue from vue import vdr fro…...

容器:stack
以下是关于stack容器的一些总结: stack容器比较简单,主要包括: 1、构造函数:stack [staName] 2、添加、删除元素: push() 、pop() 3、获取栈顶元素:top() 4、获取栈的大小:size() 5、判断栈是否为空&#x…...
跨平台Ribbon UI组件QtitanRibbon全新发布v6.7.0——支持Qt 6.6.3
没有Microsoft在其办公解决方案中提供的界面,就无法想象现代应用程序,这个概念称为Ribbon UI,目前它是使应用程序与时俱进的主要属性。QtitanRibbon是一款遵循Microsoft Ribbon UI Paradigm for Qt技术的Ribbon UI组件,QtitanRibb…...
 深入探索Python-Pandas库的核心数据结构:DataFrame全面解析)
(6) 深入探索Python-Pandas库的核心数据结构:DataFrame全面解析
目录 前言1. DataFrame 简介2. DataFrame的特点3. DataFrame的创建3.1 使用字典创建DataFrame3.2 使用列表的列表(或元组)创建DataFrame3.3 使用NumPy数组创建DataFrame3.4 使用Series构成的字典创建DataFrame3.5 使用字典构成的字典创建DataFrame 4. 从…...
在 Azure 云中开始使用适用于 Ubuntu 的 Grafana
介绍 Grafana 是一款开源工具,可用于可视化和分析数据。它特别适合跟踪计算机系统的运行情况。在构建微服务或其他类型的应用程序时,您可能需要分析日志数据、轻松可视化数据或设置特殊警报以接收有关系统中发生的某些事件的通知。 这就是为什么你可能…...

1.Python学习笔记
一、环境配置 1.Python解释器 把程序员用编程语言编写的程序,翻译成计算机可以执行的机器语言 安装: 双击Python3.7.0-选择自定义安装【Customize installation】-勾选配置环境变量 如果没有勾选配置环境变量,输入python就会提示找不到命令…...

中英双语介绍百老汇著名歌剧:《猫》(Cats)和《剧院魅影》(The Phantom of the Opera)
中文版 百老汇著名歌剧 百老汇(Broadway)是世界著名的剧院区,位于美国纽约市曼哈顿。这里汇集了许多著名的音乐剧和歌剧,吸引了全球各地的观众。以下是两部百老汇的经典音乐剧:《猫》和《剧院魅影》的详细介绍。 1.…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

如何在macOS上免费解锁QQ音乐加密文件:完整指南
如何在macOS上免费解锁QQ音乐加密文件:完整指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...