Keras实战之图像分类识别
文章目录
- 整体流程
- 数据加载与预处理
- 搭建网络模型
- 优化网络模型
- 学习率
- Drop-out操作
- 权重初始化方法对比
- 正则化
- 加载模型进行测试
实战:利用Keras框架搭建神经网络模型实现基本图像分类识别,使用自己的数据集进行训练测试。
问:为什么选择Keras?
答:使用Keras便捷快速。用起来简单,入门容易,上手快。没有tensorflow那么复杂的规范。
整体流程
- 读取数据
- 数据预处理
- 切分数据集(分为训练集和测试集)
- 搭建网络模型(初始化参数)
- 训练网络模型
- 评估测试模型(通过对比不同参数下损失函数不断优化模型)
- 保存模型到本地
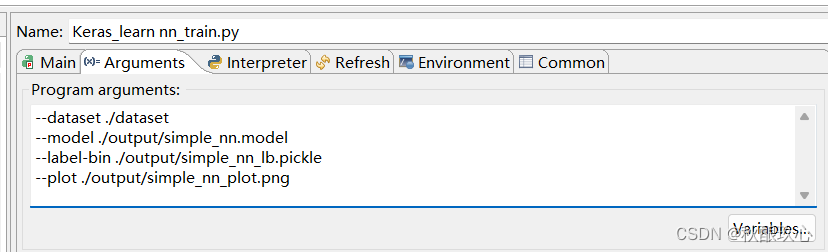
(1)手动配置参数,设置数据存储路径、模型保存路径、图片保存路径
# 输入参数,手动设置数据存储路径、模型保存路径、图片保存路径等
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,help="path to input dataset of images")
ap.add_argument("-m", "--model", required=True,help="path to output trained model")
ap.add_argument("-l", "--label-bin", required=True,help="path to output label binarizer")
ap.add_argument("-p", "--plot", required=True,help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
数据加载与预处理
# 拿到图像数据路径,方便后续读取
imagePaths = sorted(list(utils_paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# 数据洗牌前设置随机种子确保后面调参过程中训练数据集一样# 遍历读取数据
for imagePath in imagePaths:# 读取图像数据,由于使用神经网络,需要输入数据给定成一维image = cv2.imread(imagePath)# 而最初获取的图像数据是三维的,则需要将三维数据进行拉长image = cv2.resize(image, (32, 32)).flatten()data.append(image)# 读取标签,通过读取数据存储位置文件夹来判断图片标签label = imagePath.split(os.path.sep)[-2]labels.append(label)# scale图像数据,归一化
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)# 转换标签,one-hot格式
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
数据预处理:①通过数据除以255进行数据归一化;②对数据标签进行格式转换。
搭建网络模型
- 创建序列结构
model = Sequential()
- 添加全连接层
- 第一层全连接层Dense设计512个神经元,当前输入特征个数(输入神经元个数)为3072,设置激活函数为"relu";
- 第二层设计256个神经元;
- 第三层设计类别数个神经元(即3个),并作softmax操作得到最终分类类别。
# 第一层
model.add(Dense(512, input_shape=(3072,),activation="relu"))
# 第二层
model.add(Dense(256, activation="relu",))
# 第三层
model.add(Dense(len(lb.classes_), activation="softmax",))
- 初始化参数
# 学习率
INIT_LR = 0.01
# 迭代次数
EPOCHS = 200
- 训练网络模型
# 给定损失函数和评估方法
opt = SGD(lr=INIT_LR) # 指定优化器为梯度下降的优化器
model.compile(loss="categorical_crossentropy", optimizer=opt,metrics=["accuracy"])# 训练网络模型
H = model.fit(trainX, trainY, validation_data=(testX, testY),epochs=EPOCHS, batch_size=32)
- 测试网络模型
使用上面训练所得网络模型对测试集进行预测,并对比预测解国和数据集真实结果打印结果报告(包括准确率、recall、f1-score),并将损失函数以折线图的效果直观展示出来
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1), target_names=lb.classes_))
- 评估结果


从损失函数图像中可看出,模型出现明显过拟合现象,故而该初始参数所构建的模型效果较差,需要通过调参优化模型。
优化网络模型
学习率
对比学习率为0.01和0.001的损失函数图像。

train_loss与val_loss之间差异仍然存在,但是可看出学习率越大,过拟合现象越明显。
Drop-out操作
Dropout操作:在搭建网络模型中,通过设置一0到1范围内的参数从而防止过拟合。

权重初始化方法对比
(1)RandomNormal随机高斯初始化
kernel_initializer =initializers.random_normal(mean=0.0,stddev=0.05)
model.add(Dense(512, input_shape=(3072,),activation="relu",kernel_initializer =initializers.random_normal(mean=0.0,stddev=0.05)))
model.add(Dense(256, activation="relu",kernel_initializer =initializers.random_normal(mean=0.0,stddev=0.05)))
model.add(Dense(len(lb.classes_), activation="softmax",kernel_initializer =initializers.random_normal(mean=0.0,stddev=0.05)))

图中可看出,添加RandomNormal初始化后,过拟合现象减弱了一丢丢。
(2)TruncatedNormal截断
kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None)
相比于正常高斯分布截断了两边,只取小于2倍stddev的值
model.add(Dense(512, input_shape=(3072,), activation="relu" ,kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05)))
model.add(Dense(256, activation="relu",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05)))
model.add(Dense(len(lb.classes_), activation="softmax",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05)))

对比stddev取不同值时的loss函数图可得,TruncatedNormal中stddev值越小,过拟合风险越低,模型效果越好。TruncatedNormal消除过拟合的效果RandomNormal好。
正则化
kernel_regularizer=regularizers.l2(0.01)
正则化后,损失函数loss = 初始loss + aR(W)。正则化惩罚W,让稳定的W减少过拟合。
model.add(Dense(512, input_shape=(3072,), activation="relu" ,kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None),kernel_regularizer=regularizers.l2(0.01)))
model.add(Dense(256, activation="relu",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None),kernel_regularizer=regularizers.l2(0.01)))
model.add(Dense(len(lb.classes_), activation="softmax",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None),kernel_regularizer=regularizers.l2(0.01)))
对比正则化前后取迭代150到200的loss波动图,可发现正则化后虽然开始时loss值较大,但后期过拟合现象有明显减弱

再对比正则化参数l2 = 0.01和0.05的结果可得,l2越大,W的惩罚力度越大,过拟合风险越小

加载模型进行测试
# 导入所需工具包
from keras.models import load_model
import argparse
import pickle
import cv2# 设置输入参数
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,help="path to input image we are going to classify")
ap.add_argument("-m", "--model", required=True,help="path to trained Keras model")
ap.add_argument("-l", "--label-bin", required=True,help="path to label binarizer")
ap.add_argument("-w", "--width", type=int, default=28,help="target spatial dimension width")
ap.add_argument("-e", "--height", type=int, default=28,help="target spatial dimension height")
ap.add_argument("-f", "--flatten", type=int, default=-1,help="whether or not we should flatten the image")
args = vars(ap.parse_args())# 加载测试数据并进行相同预处理操作
image = cv2.imread(args["image"])
output = image.copy()
image = cv2.resize(image, (args["width"], args["height"]))# scale the pixel values to [0, 1]
image = image.astype("float") / 255.0# 对图像进行拉平操作
image = image.flatten()
image = image.reshape((1, image.shape[0]))# 读取模型和标签
print("[INFO] loading network and label binarizer...")
model = load_model(args["model"])
lb = pickle.loads(open(args["label_bin"], "rb").read())# 预测
preds = model.predict(image)# 得到预测结果以及其对应的标签
i = preds.argmax(axis=1)[0]
label = lb.classes_[i]# 在图像中把结果画出来
text = "{}: {:.2f}%".format(label, preds[0][i] * 100)
cv2.putText(output, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7,(0, 0, 255), 2)# 绘图
cv2.imshow("Image", output)
cv2.waitKey(0)
分类结果:



通过预测结果可得:该模型在预测猫上存在较大误差,在预测熊猫上较为准确。或许改进增加迭代次数可进一步优化模型。
相关文章:
Keras实战之图像分类识别
文章目录 整体流程数据加载与预处理搭建网络模型优化网络模型学习率Drop-out操作权重初始化方法对比正则化加载模型进行测试 实战:利用Keras框架搭建神经网络模型实现基本图像分类识别,使用自己的数据集进行训练测试。 问:为什么选择Keras&am…...

Celery,一个实时处理的 Python 分布式系统
大家好!我是爱摸鱼的小鸿,关注我,收看每期的编程干货。 一个简单的库,也许能够开启我们的智慧之门, 一个普通的方法,也许能在危急时刻挽救我们于水深火热, 一个新颖的思维方式,也许能…...

源码编译安装 LAMP
源码编译安装 LAMP Apache 网站服务基础Apache 简介安装 httpd 服务器 httpd 服务器的基本配置Web 站点的部署过程httpd.conf 配置文件 构建虚拟 Web 主机基于域名的虚拟主机基于IP 地址、基于端口的虚拟主机 MySQL 的编译安装构建 PHP 运行环境安装PHP软件包设置 LAMP 组件环境…...
PostgreSQL的pg_filedump工具
PostgreSQL的pg_filedump工具 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777pg_filedump 是一个工具&#x…...

Java语言+后端+前端Vue,ElementUI 数字化产科管理平台 产科电子病历系统源码
Java语言后端前端Vue,ElementUI 数字化产科管理平台 产科电子病历系统源码 Java开发的数字化产科管理系统,已在多家医院实施,支持直接部署。系统涵盖孕产全程,包括门诊、住院、统计和移动服务,整合高危管理、智能提醒、档案追踪等…...

Linux 服务器环境搭建
一、安装 JDK 官网下载地址:https://www.oracle.com/java/technologies/downloads # 创建目录 mkdir /usr/local/java/# 解压 tar -zxvf jdk-8u333-linux-x64.tar.gz -C /usr/local/java/# 配置环境变量 vim /etc/profileexport export JAVA_HOME/usr/local/java/…...
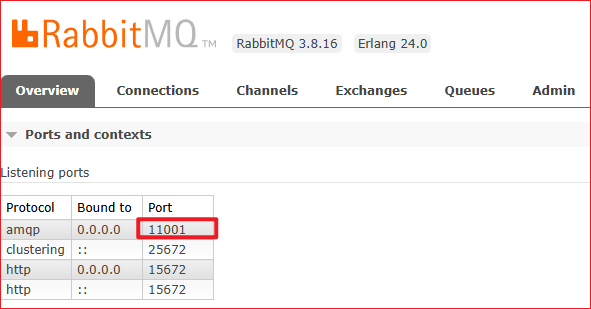
RabbitMQ 更改服务端口号
需求 windows环境下,将RabbitMQ默认的端口号 5672 改为 11001 实现 本机RabbitMQ版本为3.8.16,找到配置文件位置,路径为:C:\Users\%USERNAME%\AppData\Roaming\RabbitMQ\advanced.config 配置文件默认内容为空 填写修改端口号…...

16:9横屏短视频素材库有哪些?横屏短视频素材网站分享
在这个视觉内容至关重要的时代,16:9横屏视频因其宽广的画面和优越的观赏体验,已经成为无数创作者和营销专家的首选格式。但要创造出吸引人的横屏视频,高质量的视频素材库是不可或缺的。不管你是资深视频制作人还是刚入行的新手,下…...

在Java中,创建一个实现了Callable接口的类可以提供强大的灵活性,特别是当你需要在多线程环境中执行任务并获取返回结果时。
在Java中,创建一个实现了Callable接口的类可以提供强大的灵活性,特别是当你需要在多线程环境中执行任务并获取返回结果时。以下是一个简单的案例,演示了如何创建一个实现了Callable接口的类,并在线程池中执行它。 首先࿰…...

Vuforia AR篇(八)— AR塔防上篇
目录 前言一、设置Vuforia AR环境1. 添加AR Camera2. 设置目标图像 二、创建塔防游戏基础1. 导入素材2. 搭建场景3. 创建敌人4. 创建脚本 前言 在增强现实(AR)技术快速发展的今天,Vuforia作为一个强大的AR开发平台,为开发者提供了…...
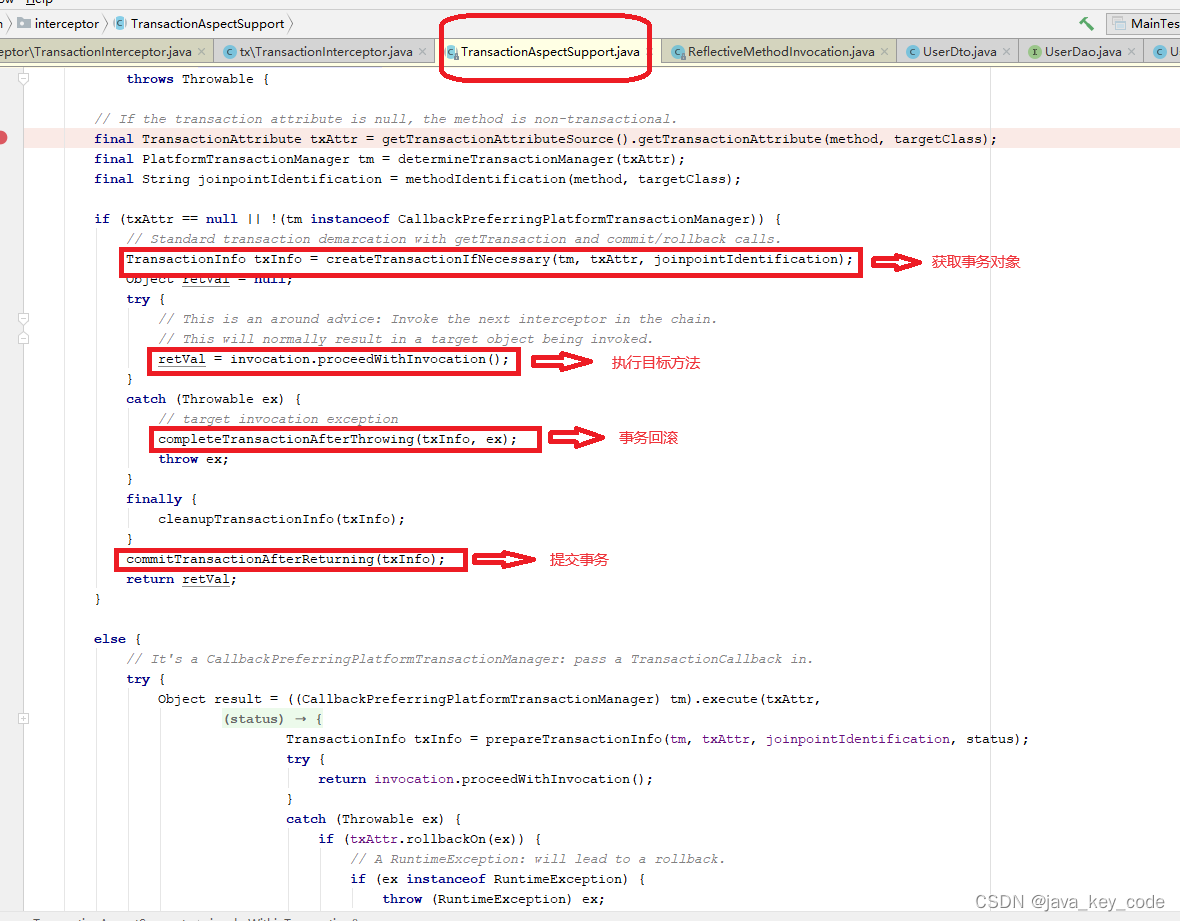
Spring AOP源码篇四之 数据库事务
了解了Spring AOP执行过程,再看Spring事务源码其实非常简单。 首先从简单使用开始, 演示Spring事务使用过程 Xml配置: <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema…...
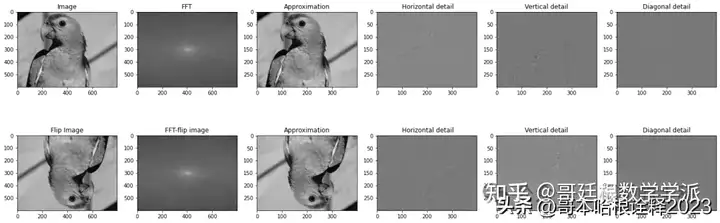
小波与傅里叶变换的对比(Python)
直接上代码,理论可以去知乎看。 #Import necessary libraries %matplotlib inline import numpy as np import matplotlib.pyplot as plt import seaborn as snsimport pywt from scipy.ndimage import gaussian_filter1d from scipy.signal import chirp import m…...

Linux-sqlplus安装
1.下载安装包 下载入口:安装包 下载对应版本: oracle-instantclient-sqlplus-21.14.0.0.0-1.x86_64.rpm oracle-instantclient-basic-21.14.0.0.0-1.x86_64.rpm oracle-instantclient-devel-21.14.0.0.0-1.x86_64.rpm 2.安装 [rootpromethues-01 tmp…...

LeetCode 算法:课程表 c++
原题链接🔗:课程表 难度:中等⭐️⭐️ 题目 你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。 在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i]…...

前端面试题30(闭包和作用域链的关系)
闭包和作用域链在JavaScript中是紧密相关的两个概念,理解它们之间的关系对于深入掌握JavaScript的执行机制至关重要。 作用域链 作用域链是一个链接列表,它包含了当前执行上下文的所有父级执行上下文的变量对象。每当函数被调用时,JavaScri…...
A股本周在3000点以下继续筑底,本周依然继续探底?
夜已深,市场传来了3个浓烈的消息,炸锅了,恐有大事发生,马上告诉所有人: 消息面: 1、中国经济周刊首席评论员钮文新称:不要等中小投资者都彻底希望,销户离场了,才发现该…...

Javadoc介绍
Javadoc 是用于生成 Java 代码文档的工具。它利用特定的注释格式,将 Java 源代码中的注释提取出来,并生成 HTML 文档。Javadoc 注释通常位于类、接口、构造函数、方法和字段的声明之前,以 /** 开始,以 */ 结束。以下是 Javadoc 注释的一些主要元素和使用方法: 基本语法 …...

C# Application.DoEvents()的作用
文章目录 1、详解 Application.DoEvents()2、示例处理用户事件响应系统事件控制台输出游戏和多媒体应用与操作系统的交互 3、注意事项总结 Application.DoEvents() 是 .NET 框架中的一个方法,它主要用于处理消息队列中的事件。在 Windows 应用程序中,当一…...
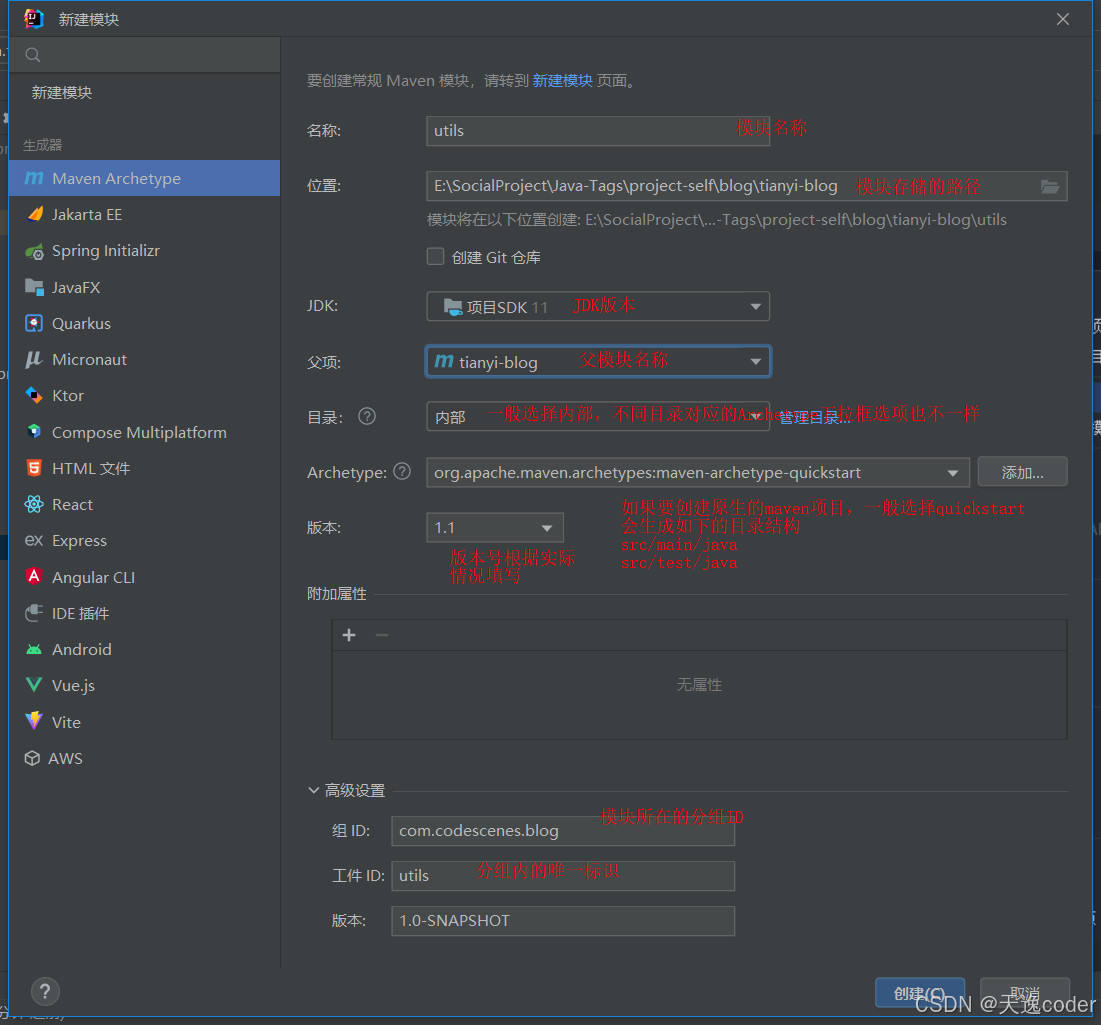
IDEA如何创建原生maven子模块
文件 -> 新建 -> 新模块 -> Maven ArcheTypeMaven ArcheType界面中的输入框介绍 名称:子模块的名称位置:子模块存放的路径名创建Git仓库:子模块不单独作为一个git仓库,无需勾选JDK:JDK版本号父项:…...

LCD EMC 辐射 测试随想
最近做几个产品过认证。 有带2.8寸 MCU8080接口的小屏(320 X 240),也有RGB接口的10.1寸的大屏(800*600). 以下为个人随想,不知道是否正确,仅作记录。 测试发现辐射的核心问题还是在于时钟及其倍频所产生的尖峰。 记得读…...

从-15dBm到+16dBm:STC8G信标FM射频放大链路实测与优化
1. 从零开始的FM信标信号放大实战 去年我在做一个野外定位项目时,遇到了一个棘手的问题:用STC8G微控制器生成的FM信标信号,在空旷地带的有效传输距离还不到50米。当时测得的初始输出功率只有-15dBm左右,这个强度连穿过一片小树林都…...

oh-my-opencode:AI编程操作系统,智能体编排与哈希锚定编辑实战
1. 项目概述:一个为AI编程而生的“操作系统”如果你和我一样,在过去一年里深度使用过Claude Code、Cursor或者各种开源的AI编程工具,那你一定经历过这种痛苦:模型选型让人眼花缭乱,配置流程复杂到让人想放弃࿰…...

AIAgent系统崩溃前的7个征兆:基于SITS2026容错框架的实时预警与自愈方案
更多请点击: https://intelliparadigm.com 第一章:SITS2026容错框架的理论根基与演进脉络 SITS2026(Self-Integrating Tolerance System 2026)并非凭空而生,其设计深度植根于分布式系统可靠性理论、形式化验证方法论与…...

3406硬核量化总结:黄大年茶思屋34期5题全解 重塑华为全球全栈技术霸权战略
华夏之光永存・硬核总结:黄大年茶思屋5题全解对华为战略的决定性价值 一、华为核心战略:全栈自主可控,构建端边云网芯一体化技术霸权 华为的核心战略是根技术全自研、全链路闭环、全场景覆盖,以芯片为底座、网络为联接、操作系统为中枢、AI为引擎、云为载体、行业应用为出…...

AI API智能调度中继服务:多账号管理与高可用架构实践
1. 项目概述:一个高性能的AI API智能调度中转站如果你手头有多个Claude、Gemini或者OpenAI的账号,并且经常在不同的开发工具(比如Claude Code CLI、各种SDK)之间切换使用,那你肯定体会过那种管理上的繁琐。每次调用都得…...

构建可信AI系统:从黑箱到透明决策的工程实践
1. 项目概述:当AI开始“思考”自己是谁最近和几个做AI安全的朋友聊天,大家不约而同地提到了一个越来越棘手的问题:我们怎么知道一个AI系统在“想”什么?或者说,我们怎么判断它给出的答案、做出的决策,是“可…...

GEE筛选行政区的两种野路子:手绘个圈圈或者随便点个点,就能搞定研究区边界
GEE自定义研究区边界:交互式绘图与动态筛选实战指南 当研究区域无法用标准行政区划描述时,传统GIS工作流程往往陷入数据准备的泥潭。本文介绍两种Google Earth Engine(GEE)中高效定义不规则边界的创新方法,特别适合生态…...

0301国产光刻机突围全景:双工件台+纳米级精密运动控制 1. 双工件台工作逻辑
国产光刻机突围全景:双工件台纳米级精密运动控制 第三卷 双工件台纳米级精密运动控制(A级 中期集中攻坚) 1. 双工件台工作逻辑(喂饭级实操版带量化参数企业单字脱敏) 一、核心定义:先搞懂“双工件台”的本质…...

别再只会用默认蓝色了!MATLAB scatter函数调色全攻略,从单色到渐变一次搞定
MATLAB散点图色彩艺术:从基础调色到数据驱动的视觉叙事 科研图表的美学价值往往被低估——直到你看到那些配色糟糕的论文插图。MATLAB的scatter函数远不止是绘制点集的工具,当掌握其色彩控制逻辑后,它能成为数据故事讲述的视觉利器。本文将彻…...

洛谷 P1333:瑞瑞的木棍 ← 欧拉回路 + 并查集
【题目来源】 https://www.luogu.com.cn/problem/P1333 【题目描述】 瑞瑞有一堆的玩具木棍,每根木棍的两端分别被染上了某种颜色,现在他突然有了一个想法,想要把这些木棍连在一起拼成一条线,并且使得木棍与木棍相接触的两端颜色…...