从数据仓库到数据湖(下):热门的数据湖开源框架
文章目录
- 一、前言
- 二、Delta Lake
- 三、Apache Hudi
- 四、Apache Iceberg
- 五、Apache Paimon
- 六、对比
- 七、笔者观点
- 八、总结
- 九、参考资料
一、前言
在上一篇从数据仓库到数据湖(上):数据湖导论文章中,我们简单讲述了数据湖的起源、使用原因及其本质。本篇文章将着重介绍市面上热门的数据湖开源框架,并分享笔者对当前数据湖技术的理解和看法。
截至目前,在数据湖领域,Delta Lake、Apache Iceberg 和 Apache Hudi 无疑是三大热门开源框架。此外,Apache Paimon 最初是 Flink 的子项目,后来独立发展成为一个独立的框架,可以说是后起之秀。
二、Delta Lake
由于 Apache Spark 在商业化上取得巨大成功,由其背后的商业公司 Databricks 推出的 Delta Lake 也显得格外亮眼。Delta Lake 是一个流批一体的数据湖存储层,支持更新、删除和合并操作。
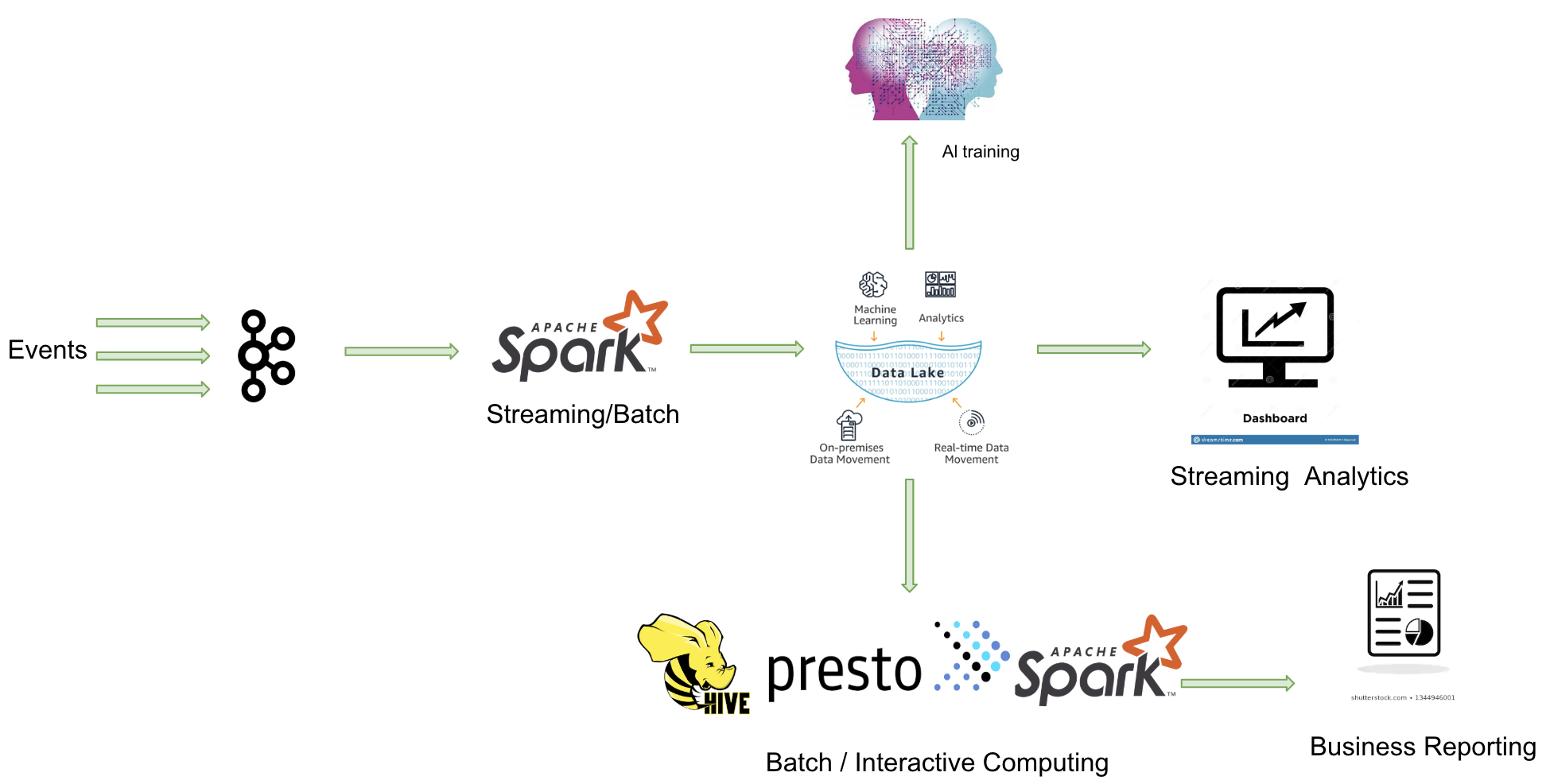
主要特点:
- 由于出自 Databricks,Delta Lake 与 Spark 的所有数据写入方式完全兼容,包括基于 DataFrame 的批处理、流处理,以及 SQL 的 Insert、Insert Overwrite 等操作(开源版本暂不支持 SQL 写入,EMR 已做支持)。
- 在数据写入方面,Delta Lake 与 Spark 强绑定;在查询方面,开源 Delta Lake 目前支持 Spark 和 Presto,但处理 delta log 需要使用 Spark。
核心能力:

三、Apache Hudi
Apache Hudi 是 Uber 公司开源的数据湖架构,用于管理存储在 HDFS 上的数据。其设计目标如其名所示,即 Hadoop Upserts Deletes and Incrementals。Hudi 提供了“COW vs MOR”两种数据模型,以适应不同的业务需求。此外,Hudi 还提供了丰富的插件生态,可以方便地与其他大数据组件集成。

核心能力:

四、Apache Iceberg
Apache Iceberg 是一种用于跟踪超大规模表的新格式,专门为对象存储(如 S3)而设计。尽管社区关注度暂时不如 Delta Lake,功能也不如 Hudi 丰富,但 Iceberg 是一个野心勃勃的项目,具有高度抽象和优雅的设计,为成为一个通用的数据湖方案奠定了良好基础。
Iceberg 为大数据带来了 SQL 表的可靠性和简单性,同时让 Spark、Trino、Flink、Presto 和 Hive 等引擎能够同时安全地使用相同的表。
五、Apache Paimon
Apache Paimon 是一种湖泊格式,可以使用 Flink 和 Spark 构建实时湖屋架构,用于流和批处理操作。Paimon 创新地结合了湖泊格式和 LSM(日志结构合并树)结构,将实时流更新引入湖泊架构。
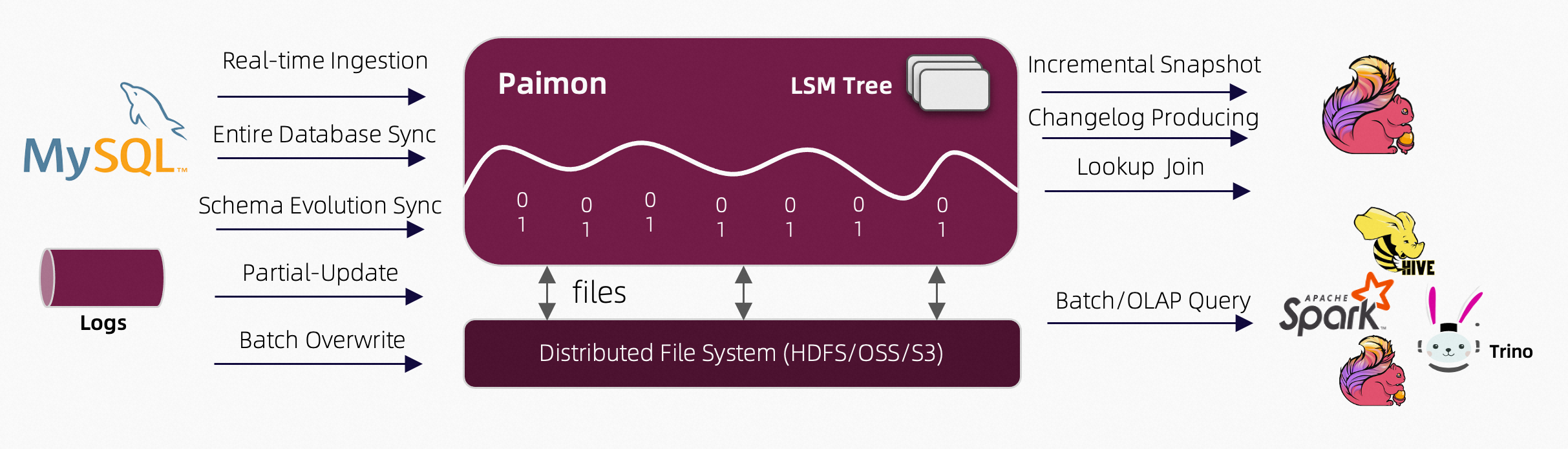
核心能力:
- 实时更新:
- 主键表支持大规模更新,具有高性能,通常通过 Flink 流实现。
- 支持定义合并引擎,灵活更新记录。可重复保存最后一行,部分更新,或聚合记录。
- 支持定义变更日志生成器,在合并引擎的更新中产生正确和完整的变更日志,简化流分析。
- 大规模数据处理:
- 附加表(无主键)提供大规模批处理和流处理能力,并自动进行小文件合并。
- 支持通过 z 顺序排序进行数据压缩,以优化文件布局,并使用 minmax 等索引提供快速查询。
- 数据湖功能:
- 可伸缩元数据:支持存储 Petabyte 级别的大数据集和大量分区。
- 支持 ACID 事务、时间旅行和模式演化。
六、对比
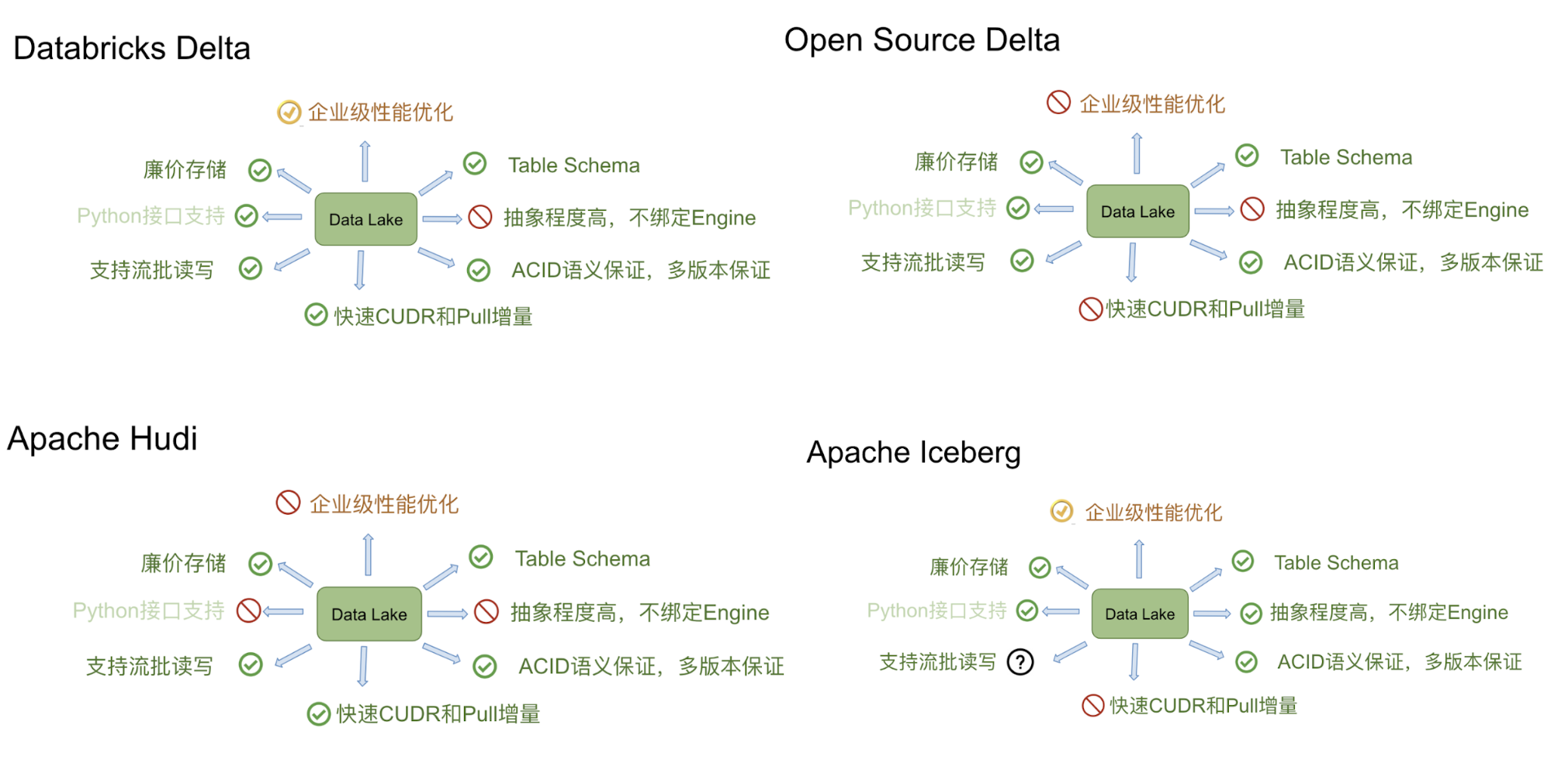
Delta、Iceberg、Hudi 和 Hive 四者的差异可以用建房子的比喻来说明。由于开源的 Delta 是 Databricks 闭源 Delta 的简化版本,主要提供 table format 的技术标准,而闭源版本的 Delta 基于这个标准实现了诸多优化,因此我们主要用闭源的 Delta 来做对比。
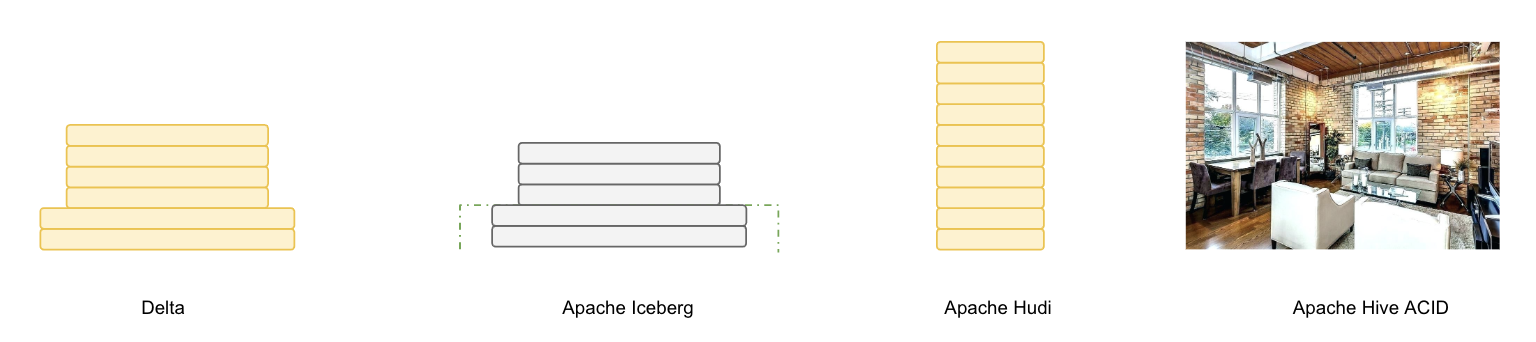
Delta 的房子基础相对结实,功能楼层也建得比较高,但这个房子可以说是 Databricks 的,本质上是为了更好地壮大 Spark 生态。在 Delta 上,其他计算引擎难以替代 Spark 的位置,尤其是在写入路径方面。Iceberg 的建筑基础非常扎实,扩展到新的计算引擎或文件系统都很方便,但目前功能楼层相对低一点,最缺的功能是 upsert 和 compaction。Iceberg 社区正在优先推动这两个功能的实现。Hudi 的情况不同,它的建筑基础设计不如 Iceberg 结实。例如,要接入 Flink 作为 Sink,需要从底向上重新设计房子,把接口抽象出来,并且考虑不影响其他功能。尽管如此,Hudi 的功能楼层还是比较完善的,提供的 upsert 和 compaction 功能直接命中用户的痛点。Hive 看起来像是一栋豪宅,绝大部分功能都有,但作为数据湖有点像靠着豪宅的一堵墙建房子,显得相对笨重。此外,正如 Netflix 的分析,细看这栋豪宅的墙面其实有一些问题。
七、笔者观点
虽然上述四款热门开源框架都宣称自己是数据湖解决方案,但根据我的了解和使用体验,这几款产品均不能完全满足数据湖所应具备的能力。
在前一篇文章中,笔者提到数据湖的本质是由数据存储架构和数据处理工具组成的解决方案。然而,这四款开源框架均沿用了传统数据库建表的思想,对数据有较强的 schema 约束,这与数据湖原始定义中的集成各类非结构化数据的要求相悖。
通过对这几款产品的使用和体验,我认为目前热门的数据湖技术均依赖于分布式文件系统的存储能力。它们的功能介于分布式文件系统与普通数据库之间,继承了文件系统中数据文件和目录对用户直观可见,以及数据库对数据使用表结构的管理、元数据管理和事务管理的优点,可以被称为一种数据管理中间件的开源产品。
这些产品的使用并不需要安装部署任何软件,也不需要启动额外的服务和端口,只需增加一个 jar 包,以插件的形式嵌入到计算引擎中,从而实现对分布式文件系统中数据的读写和各种数据管理功能。它们为计算引擎提供了一种数据组织和管理方式,但并非真正意义上的数据湖。
真正意义上的数据湖应该具备数据抽取 (ETL)、元数据管理、数据分析三大功能,如下图所示:

八、总结
数据湖就像其他新兴技术一样,在刚出现时往往受到广泛关注,成为热门话题。然而,很多新兴技术词汇大多是作为一个泛化的理论概念,但往往具有很大的吸引力,其实际应用还存在诸多挑战和局限性。
根据对当前几款热门开源框架(如Delta Lake、Apache Iceberg、Apache Hudi、Hive-ACID)的使用体验,这些产品均无法完全满足数据湖应具备的能力。数据湖的本质是由数据存储架构和数据处理工具组成的解决方案,但上述框架在设计上仍然沿用了传统数据库的schema约束,与数据湖集成各类非结构化数据的初衷相悖。
总体来说,数据湖等新兴技术在理论上提供了一个理想的解决方案,但在实际应用中,仍需不断发展和完善,以满足企业对数据存储、管理和分析的需求。这一过程需要时间和技术的积累,才能真正实现理论与实践的统一。
九、参考资料
- 从数据库到数据仓库:数据仓库导论
- 从数据仓库到数据湖(上):数据湖导论
- 深度对比 Delta、Iceberg 和 Hudi 三大开源数据湖方案
- Hidi
- Delta Lake
- Iceberg
- Paimon
相关文章:
从数据仓库到数据湖(下):热门的数据湖开源框架
文章目录 一、前言二、Delta Lake三、Apache Hudi四、Apache Iceberg五、Apache Paimon六、对比七、笔者观点八、总结九、参考资料 一、前言 在上一篇从数据仓库到数据湖(上):数据湖导论文章中,我们简单讲述了数据湖的起源、使用原因及其本质。本篇文章…...

对话AI原生 | 千帆AppBuilder重构企业AI原生应用开发体验
人工智能和大模型正在引领当前最重要的科技创新趋势。在过去的一年中,行业关注点已从大模型研发转向实际应用,正成为推动创新和转型的关键力量。百度智能云千帆AppBuilder作为基于大模型的企业级AI原生应用开发工作台,支持应用的快速开发和发…...

CF253C Text Editor 题解
思路 既然要求最少步数,那我们可以用bfs 如果鼠标的位置比上一行的行末位置大,如果按上的话,移到上一行的行末。如果鼠标的位置比下一行的行末位置大,如果按下的话,移到下一行的行末。 注意当鼠标位置超过当前行最大…...

Spring Boot 创建定时任务
在现代应用程序开发中,定时任务是一个常见的需求。Spring Boot作为一个强大的框架,提供了简单易用的定时任务调度功能。本文将详细介绍如何在Spring Boot中创建和管理定时任务,并提供完整的代码示例。 1. 什么是定时任务 定时任务是指在预定…...

Vue使用Echarts(入门级)
最终效果: npm install echarts --save // 先安装echarts<template><!-- 创建一个dom区域用于挂载echarts图表 --><div id"chart" style"width: 600px;height:500px;"/> </template> <script> import * as ech…...
)
2025届秋招提前批信息汇总(计算机类)
私企篇 深信服 链接:https://app.mokahr.com/campus_apply/sangfor/27944#/home内推码:NTAHRFS截止时间:6月21日 TP-LINK 链接:https://hr.tp-link.com.cn/jobList?jobId107&jobDirection0&workPlace0¤tPa…...
)
Scala Collection(集合)
Scala Collection(集合) Scala集合库是Scala语言的核心特性之一,它提供了一套丰富的数据结构来存储、管理和操作数据。Scala集合分为可变(mutable)和不可变(immutable)两种类型,每种类型都有其特定的用途和优势。本文将详细介绍Scala集合库的基本概念、常用集合类型以及…...

Go 语言 UUID 库 google/uuid 源码解析:UUID version4 的实现
google/uuid 库地址 本文将解析 googl/uuid 库中 UUID 变体10版本4的实现。 版本 4 的 UUID 采取完全随机的方式实现,简单来说就是将 UUID 中的 122 位全部随机填充(剩余的 6 位作标记位)。版本 4 的 UUID 存在一定的重复风险,但…...

开发个人Go-ChatGPT--6 OpenUI
开发个人Go-ChatGPT–6 OpenUI Open-webui Open WebUI 是一种可扩展、功能丰富且用户友好的自托管 WebUI,旨在完全离线运行。它支持各种 LLM 运行器,包括 Ollama 和 OpenAI 兼容的 API。 功能 由于总所周知的原由,OpenAI 的接口需要密钥才…...

Spring中的工厂模式详解及应用示例
1. Spring中的BeanFactory BeanFactory是一个接口,表示它是一个工厂,负责生产和管理bean。在Spring中,BeanFactory是IOC容器的核心接口,定义了管理Bean的通用方法,如 getBean 和 containsBean。 BeanFactory与IOC容器…...

Electron 简单搭建项目
准备工作 全局安装 node npm创建文件夹,并执行 npm init安装 electron npm i electron --save-dev在 package.json 配置文件中的scripts字段下增加一条start命令: {"scripts": {"start": "electron ."} }由于配置中的入…...
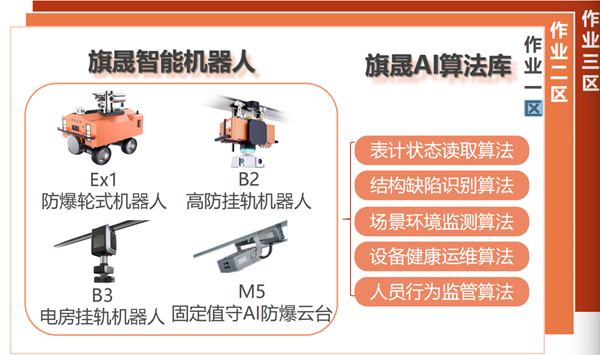
旗晟智能巡检机器人:开启工业运维的智能化新篇章
在当今快速发展的工业领域,安全、效率和成本控制是企业运营的核心。旗晟科技以创新为驱动,推出了一站式的工业级智能巡检机器人数字化全景运维解决方案,为石油、天然气、化工、电力等高危行业提供了一个全新的运维模式。 一、面对挑战&#x…...

vue3的常用 Composition API有哪些?
Vue.js 3.0 引入了 Composition API,作为一种新的组织组件逻辑的方式,相比于传统的 Options API,Composition API 提供了更灵活、更可复用的代码组织方式。 以下是 Vue 3.0 中常用的 Composition API:setup() 函数: s…...
)
深度优先算法-DFS(算法篇)
算法之深度优先算法 深度优先算法(DFS) 概念: 深度优先算法(DFS)跟BFS算法一样是用于遍历图的算法,但是DFS并不像BFS算法一样,它搜索出来的路径不具有最短性,并且dfs算法类似于枚举,因此DFS算法一般用于求出问题的所…...

C++模块化之内部类
目录 1.引言 2.内部类的访问控制 3.优缺点分析 4.实际运用 4.1.实现复杂数据结构 4.2.封装细节实现 4.3.事件处理和回调 4.4.模板元编程辅助类 4.5. 访问控制和封装 4.6. 代码组织和模块化 5.总结 1.引言 在C中,内部类(Nested Classÿ…...

k8s-第九节-命名空间
命名空间 如果一个集群中部署了多个应用,所有应用都在一起,就不太好管理,也可以导致名字冲突等。 我们可以使用 namespace 把应用划分到不同的命名空间,跟代码里的 namespace 是一个概念,只是为了划分空间。 # 创建命…...

【AI大模型新型智算中心技术体系深度分析 2024】
文末有福利! ChatGPT 系 列 大 模 型 的 发 布, 不 仅 引 爆 全 球 科 技 圈, 更 加 夯 实 了 人 工 智 能(Artificial Intelligence, AI)在未来改变人类生产生活方式、引发社会文明和竞争力代际跃迁的战略性地位。当…...

王道计算机数据结构+插入排序、冒泡排序、希尔排序、快速排序、简单选择排序
本内容是基于王道计算机数据结构的插入排序、冒泡排序、希尔排序、快速排序、简单选择排序整理。 文章目录 插入排序算法性能代码 冒泡排序算法性能代码 希尔排序算法性能代码 快速排序算法性能代码 简单选择排序算法性能代码 插入排序 算法 算法思想:每次将一个…...
---多线程上篇)
python爬虫学习(三十三天)---多线程上篇
hello,小伙伴们!我是喔的嘛呀。今天我们来学习多线程方面的知识。 目录 一、了解多线程 (1)大概描述 (2)多线程爬虫的优势 (3)多线程爬虫的实现方式 (4)…...
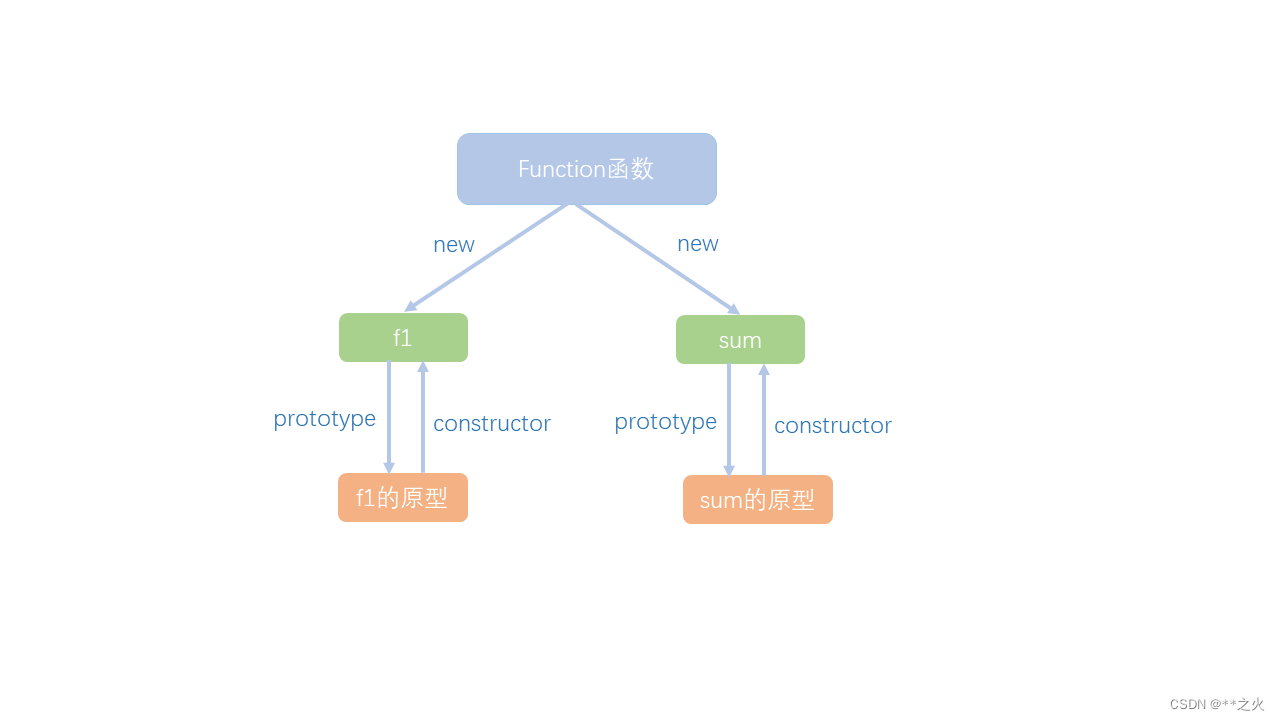
JavaScript 原型链那些事
在讲原型之前我们先来了解一下函数。 在JS中,函数的本质就是对象,它与其他对象不同的是,创建它的构造函数与创建其他对象的构造函数不一样。那产生函数对象的构造函数是什么呢?是一个叫做Function的特殊函数,通过newFu…...

微通道液冷散热:六类强化结构深度解析
🎓作者简介:科技自媒体优质创作者 🌐个人主页:莱歌数字-CSDN博客 💌公众号:莱歌数字(B站同名) 📱个人微信:yanshanYH 211、985硕士,从业16年 从…...

ChatGPT写论文被判AI怎么办?降AI率完整应对攻略+工具推荐!
ChatGPT写论文被判AI怎么办?降AI率完整应对攻略工具推荐! ChatGPT 是 2022 年起最早被广泛使用的大模型,现在依然是不少留学生、研究生写英文论文/中文论文的首选。但它写出来的论文在 AIGC 检测平台(Turnitin、知网英文模块、维普…...

突破音频平台限制:基于Go+Qt5的喜马拉雅下载器技术解析
突破音频平台限制:基于GoQt5的喜马拉雅下载器技术解析 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 在数字化学习与娱…...

正点原子阿尔法开发板uboot编译避坑指南:从源码到SD卡启动的完整流程
正点原子阿尔法开发板uboot编译全流程实战:从环境搭建到SD卡启动的深度解析 第一次接触正点原子阿尔法开发板时,最令人头疼的莫过于uboot的编译和烧录过程。那些看似简单的命令背后,隐藏着无数新手容易踩中的"暗坑"——从文件格式的…...

边缘计算实战:基于 Linux Netns 与标准海事网关抵御局域网横向攻击的物理隔离架构
摘要:扁平化局域网极易遭受 ARP 欺骗与黑客横向攻击。本文记录了在标准工业级海事网关上基于 Linux netns 构建网络物理与逻辑隔离防线的实操复盘。 导语:在实操一个远洋船载网络的安全重构项目时,我们面临一个极其严峻的威胁模型࿱…...

3分钟快速解锁网易云音乐NCM格式:ncmdump音频解密工具完全指南
3分钟快速解锁网易云音乐NCM格式:ncmdump音频解密工具完全指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在特定客户端播放,无法在其他设…...
)
嵌入式开发实战:手把手教你用U-Boot命令调试i.MX6ULL开发板(含网络/EMMC操作)
嵌入式开发实战:i.MX6ULL开发板U-Boot调试全攻略 1. 从零开始的硬件调试环境搭建 拿到i.MX6ULL开发板的第一件事,就是建立可靠的调试环境。不同于桌面开发,嵌入式系统往往需要通过串口与开发板交互。这里推荐使用USB转TTL模块连接开发板的调试…...

CANN Ascend C SetStride API
SetStride 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

智能水表、血糖仪、工业HMI:STM32L152ZET6的超低功耗MCU应用版图
STM32L152ZET6:带LCD驱动的超低功耗Cortex-M3旗舰MCU 在电池供电的工业仪表、医疗设备和消费电子产品中,微控制器的功耗与集成度往往是决定产品可行性的关键因素。STM32L152ZET6是意法半导体STM32 L1系列中的高端型号,采用2020mm的LQFP-144封…...

【信息科学与工程学】【人工智能】【知识工程】企业知识库管理与评估-第四篇-市场篇
一、企业价格知识管理参数体系 1.1、价格知识管理参数列表 内部交易价格参数 参数名称 参数定义 计算公式 计量单位 数据来源 部门间转移定价准确率 内部转移定价的准确程度 准确转移定价次数 / 总转移定价次数 100% % 财务系统、转移定价记录 成本中心计价合规率…...