【机器学习】初学者经典案例(随记)
| 🎈边走、边悟🎈迟早会好 |
一、概念
机器学习是一种利用数据来改进模型性能的计算方法,属于人工智能的一个分支。它旨在让计算机系统通过经验自动改进,而不需要明确编程。
类型
- 监督学习:使用带标签的数据进行训练,包括分类(如垃圾邮件检测)和回归(如房价预测)。
- 无监督学习:使用不带标签的数据进行训练,包括聚类(如客户细分)和降维(如主成分分析)。
- 强化学习:通过与环境的交互学习策略,以最大化累积奖励(如AlphaGo)。
二、 常见算法
2.1监督学习算法
- 线性回归:用于回归任务,假设目标变量与输入特征之间存在线性关系。
- 逻辑回归:用于二分类任务,输出一个介于0和1之间的概率。
- 决策树:树状结构的模型,易于理解和解释。
- 支持向量机(SVM):寻找能够最大化类间间隔的决策边界。
- K近邻(KNN):基于距离度量的简单算法,预测时考虑最近的K个邻居。
- 朴素贝叶斯:基于贝叶斯定理的分类算法,假设特征之间条件独立。
2.2无监督学习算法
- K均值聚类:将数据分成K个簇,使得簇内数据的相似度最大。
- 层次聚类:构建一个层次结构的聚类树,逐步合并或分割簇。
- 主成分分析(PCA):将高维数据投影到低维空间,保留数据的主要变异信息。
- 独立成分分析(ICA):类似于PCA,但假设数据成分相互独立。
2.3强化学习算法
- Q学习:基于状态-动作对的值函数,通过Q值迭代更新策略。
- 深度Q网络(DQN):结合深度学习的Q学习算法,用神经网络近似Q值。
- 策略梯度方法:直接优化策略,使得期望奖励最大化。
三.、模型评估
评估指标
分类:
- 准确率:正确预测的样本数占总样本数的比例。
- 精确率:预测为正类的样本中实际为正类的比例。
- 召回率:实际为正类的样本中被正确预测为正类的比例。
- F1分数:精确率和召回率的调和平均数。
- 混淆矩阵:总结预测结果的矩阵,显示真阳性、假阳性、真阴性和假阴性。
回归:
- 均方误差(MSE):预测值与真实值之差的平方和的平均数。
- 均方根误差(RMSE):MSE的平方根。
- 平均绝对误差(MAE):预测值与真实值之差的绝对值的平均数。
- R²:解释回归模型对数据变异的比例。
交叉验证
通过将数据集划分为若干子集,反复进行训练和验证,以评估模型的性能稳定性和泛化能力。
四、 优化技术
4.1 超参数优化
- 网格搜索:对所有可能的参数组合进行穷举搜索,找到最佳参数组合。
- 随机搜索:随机选择参数组合进行搜索,相对高效。
- 贝叶斯优化:利用贝叶斯推理逐步优化参数选择过程。
4.2 正则化
通过在损失函数中添加正则项,防止过拟合:
- L1正则化:加入参数的绝对值和(Lasso回归)。
- L2正则化:加入参数的平方和(Ridge回归)。
4.3 特征选择
选择对模型性能影响较大的特征,去除冗余或相关性高的特征。
五、 常见问题及解决方法
5.1 过拟合与欠拟合
- 过拟合:模型在训练集上表现良好,但在测试集上表现差。解决方法包括增加数据量、正则化、使用更简单的模型等。
- 欠拟合:模型在训练集上和测试集上都表现不佳。解决方法包括增加模型复杂度、添加更多特征等。
5.2 数据不平衡
当某一类样本数量远多于其他类时,模型可能偏向于预测多数类。解决方法包括重采样、调整分类阈值、使用加权损失函数等。
六、入门经典案例
1. 鸢尾花数据集分类(Iris Dataset Classification)
背景
鸢尾花数据集是机器学习领域中非常经典的数据集,由英国统计学家和生物学家Fisher在1936年提出。该数据集包含150个样本,每个样本有4个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。目标是根据这些特征将鸢尾花分为三类:山鸢尾(Setosa)、变色鸢尾(Versicolor)和维吉尼亚鸢尾(Virginica)。
过程
- 数据预处理:加载数据并进行基本的清洗和探索性数据分析(EDA)。
- 特征选择:选择合适的特征来进行分类。
- 数据划分:将数据集分为训练集和测试集,一般采用80/20或70/30的比例。
- 模型选择:选择合适的分类算法,如K近邻(KNN)、支持向量机(SVM)、决策树(Decision Tree)等。
- 模型训练:在训练集上训练模型。
- 模型评估:在测试集上评估模型的性能,常用的评估指标包括准确率、混淆矩阵、F1分数等。
- 模型优化:根据评估结果进行参数调优或选择其他模型。
详解
# 示例代码(以KNN为例)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 模型训练
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)# 模型预测
y_pred = knn.predict(X_test)# 模型评估
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))
2. 房价预测(Housing Price Prediction)
背景
房价预测是回归问题的经典案例之一,通常使用波士顿房价数据集。该数据集包含506个数据点,每个数据点有13个特征(如房间数量、房龄、犯罪率等),目标是预测房屋的中位数价格。
过程
- 数据预处理:加载数据,处理缺失值和异常值,进行EDA。
- 特征工程:选择重要特征,并进行特征缩放。
- 数据划分:将数据集分为训练集和测试集。
- 模型选择:选择回归模型,如线性回归(Linear Regression)、随机森林回归(Random Forest Regression)等。
- 模型训练:在训练集上训练模型。
- 模型评估:在测试集上评估模型性能,常用评估指标包括均方误差(MSE)、均方根误差(RMSE)等。
- 模型优化:根据评估结果进行参数调优或选择其他模型。
详解
# 示例代码(以线性回归为例)
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 加载数据
boston = load_boston()
X = boston.data
y = boston.target# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 模型训练
lr = LinearRegression()
lr.fit(X_train, y_train)# 模型预测
y_pred = lr.predict(X_test)# 模型评估
mse = mean_squared_error(y_test, y_pred)
rmse = mse ** 0.5
print("MSE:", mse)
print("RMSE:", rmse)
3. 手写数字识别(Digit Recognition)
背景
手写数字识别是计算机视觉中的经典问题,通常使用MNIST数据集。该数据集包含60000个训练样本和10000个测试样本,每个样本是28x28像素的灰度图像,代表手写的数字0-9。
过程
- 数据预处理:加载数据,并进行基本的图像处理。
- 特征工程:将图像数据展平或进行特征提取。
- 数据划分:将数据集分为训练集和测试集。
- 模型选择:选择分类模型,如卷积神经网络(CNN)、支持向量机(SVM)等。
- 模型训练:在训练集上训练模型。
- 模型评估:在测试集上评估模型性能,常用评估指标包括准确率、混淆矩阵等。
- 模型优化:根据评估结果进行参数调优或选择其他模型。
详解
# 示例代码(以简单的多层感知机为例)
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.utils import to_categorical# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()# 数据预处理
X_train = X_train.reshape(-1, 28*28).astype('float32') / 255.0
X_test = X_test.reshape(-1, 28*28).astype('float32') / 255.0
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)# 构建模型
model = Sequential([Flatten(input_shape=(28*28,)),Dense(128, activation='relu'),Dense(64, activation='relu'),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_split=0.2)# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("Loss:", loss)
print("Accuracy:", accuracy)
🌟感谢支持 听忆.-CSDN博客

| 🎈众口难调🎈从心就好 |
相关文章:
【机器学习】初学者经典案例(随记)
🎈边走、边悟🎈迟早会好 一、概念 机器学习是一种利用数据来改进模型性能的计算方法,属于人工智能的一个分支。它旨在让计算机系统通过经验自动改进,而不需要明确编程。 类型 监督学习:使用带标签的数据进行训练&…...

进阶版智能家居系统Demo[C#]:整合AI和自动化
引言 在基础智能家居系统的基础上,我们将引入更多高级功能,包括AI驱动的自动化控制、数据分析和预测。这些进阶功能将使智能家居系统更加智能和高效。 目录 高级智能家居功能概述使用C#和AI实现智能家居自动化实现智能照明系统的高级功能 自动调节亮度…...

IC后端设计中的shrink系数设置方法
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧? 拾陆楼知识星球入口 在一些成熟的工艺节点通过shrink的方式(光照过程中缩小特征尺寸比例)得到了半节点,比如40nm从45nm shrink得到,28nm从32nm shrink得到,由于半节点的性能更优异,成本又低,漏电等不利因素也可以…...

在NVIDIA Jetson平台离线部署大模型
在NVIDIA Jetson平台离线部署大模型,开启离线具身智能新纪元。 本项目提供一种将LMDeploy移植到NVIDIA Jetson系列边缘计算卡的方法,并在Jetson计算卡上运行InternLM系列大模型,为离线具身智能提供可能。 最新新闻🎉 [2024/3/1…...

51单片机嵌入式开发:8、 STC89C52RC 操作LCD1602原理
STC89C52RC 操作LCD1602原理 1 LCD1602概述1.1 LCD1602介绍1.2 LCD1602引脚说明1.3 LCD1602指令介绍 2 LCD1602外围电路2.1 LCD1602接线方法2.2 LCD1602电路原理 3 LCD1602软件操作3.1 LCD1602显示3.2 LCD1602 protues仿真 4 总结 1 LCD1602概述 1.1 LCD1602介绍 LCD1602是一种…...

数字化时代的供应链管理综合解决方案
目录 引言背景与意义供应链管理综合解决方案的目标 📄供应链管理系统主要功能系统优势 📄物流管理系统主要功能系统优势 📄订单管理系统主要功能应用场景 📄仓储管理系统系统亮点主要功能系统优势 📄商城管理系统主要功…...

CentOS 安装 annie/lux,以及 annie/lux 的使用
annie 介绍 如果第一次听到 annie 想必都会觉得陌生,annie 被大家称为视频下载神器,annie 作者介绍说可以下载抖音、哔哩哔哩、优酷、爱奇艺、芒果TV、YouTube、Tumblr、Vimeo 等平台的视频。 githup:https://github.com/pingf/annie 支持…...

拥抱UniHttp,规范Http接口对接之旅
前言 如果你项目里还在用传统的编程式Http客户端比如HttpClient、Okhttp去直接对接第三方Http接口, 那么你项目一定充斥着大量的对接逻辑和代码, 并且针对不同的对接渠道方需要每次封装一次调用的简化, 一旦封装不好系统将会变得难以维护&am…...

Python 给存入 Redis 的键值对设置过期时间
Redis 是一种内存中的数据存储系统,与许多传统数据库相比,它具有一些优势,其中之一就是可以设置数据的过期时间。通过 Redis 的过期时间设置,可以为存储在 Redis 中的数据设置一个特定的生存时间。一旦数据到达过期时间࿰…...

在linux中安装docker
文章目录 1、安装依赖2、安装docker的下载源3、安装docker4、设置Docker服务开机自启 1、安装依赖 sudo yum install -y yum-utils2、安装docker的下载源 sudo yum-config-manager \--add-repo \https://download.docker.com/linux/centos/docker-ce.repohttps://download.do…...
【JVM-04】线上CPU100%
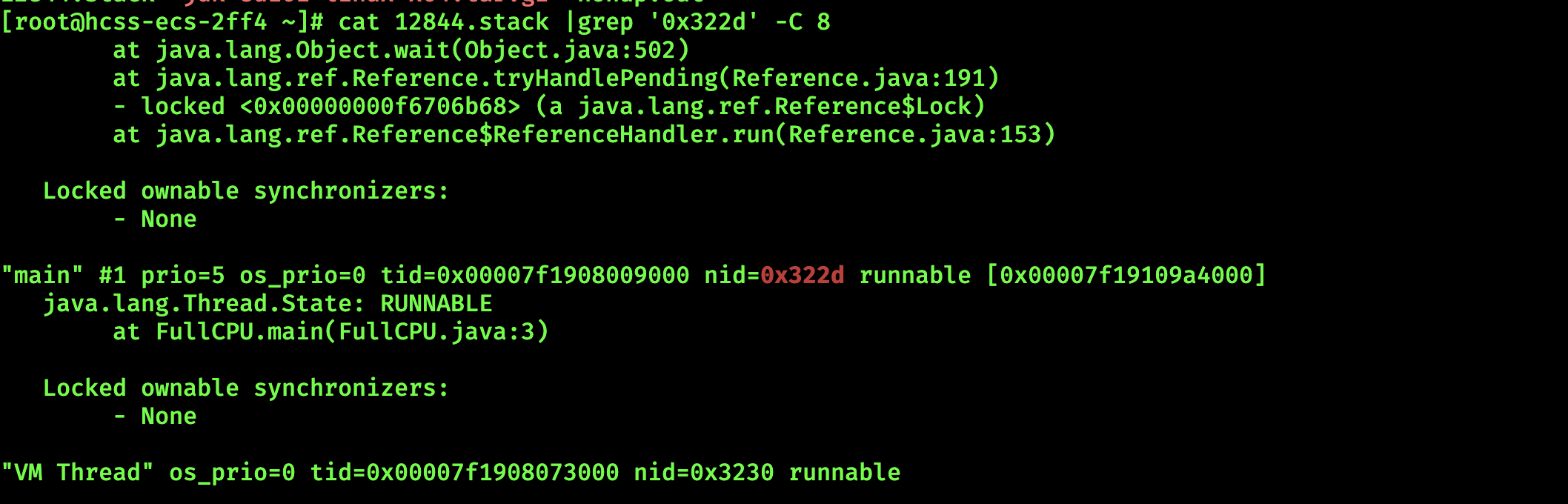
【JVM-04】线上CPU100% 1. 如何排查2. 再举一个例子 1. 如何排查 ⼀般CPU100%疯狂GC,都是死循环的锅,那怎么排查呢?先进服务器,⽤top -c 命令找出当前进程的运⾏列表按⼀下 P 可以按照CPU使⽤率进⾏排序显示Java进程 PID 为 2609…...

try catch 解决大问题
项目开发中遇到一个棘手的bug,react前端项目独自运行时一切正常,但是把项目集成到使用wujie的大平台微前端项目中之后,突然有个地方无故报错,导致程序运行停止,后续的方法不再执行。报错如下: DOMExceptio…...

手动解析Collection
即将被解析的json {"collection": {"templates": [{"data": [{"name": "plantCode","value": "MSHG_KFXHS02"}, {"name": "details","value": [{"plantMedicament…...

list模拟实现【C++】
文章目录 全部的实现代码放在了文章末尾准备工作包含头文件定义命名空间类的成员变量为什么节点类是用struct而不是class呢?为什么要写get_head_node? 迭代器迭代器在list类里的实例化和重命名普通迭代器operator->()的作用是什么? const迭代器反向迭…...

nginx正向代理、反向代理、负载均衡
nginx.conf nginx首要处理静态页面 反向代理 动态请求 全局模块 work processes 1; 设置成服务器内核数的两倍(一般不不超过8个超过8个反而会降低性能一般4个 1-2个也可以) netstat -antp | grep 80 查端口号 *1、events块:* 配置影响ngi…...

matlab 有倾斜的椭圆函数图像绘制
matlab 有倾斜的椭圆函数图像绘制 有倾斜的椭圆函数图像绘制xy交叉项引入斜线负向斜线成分正向斜线成分 x^2 y^2 xy 1 (负向)绘制结果 x^2 y^2 - xy 1 (正向)绘制结果 有倾斜的椭圆函数图像绘制 为了确定椭圆的长轴和短轴的…...

PTK是如何加密WLAN单播数据帧的?
1. References WLAN 4-Way Handshake如何生成PTK?-CSDN博客 2. 概述 在Wi-Fi网络中,单播、组播和广播帧的加密算法是由AP决定的。其中单播帧的加密使用PTK密钥,其PTK的密钥结构如下图所示: PTK的组成如上图所示,由K…...

Django之登录权限系统
本文参考链接django之auth模块(用户认证) - chchcharlie、 - 博客园 (cnblogs.com) 执行完迁移命令,会自动生成admin表,迁移命令如下: python manage.py makemigrations python manage.py migrate 相关模块 from django.contrib …...

rust way step 1
install rust CARGO_HOME D:\rust\.cargo RUSTUP_HOME D:\rust\.rustup [dependencies] ferris-says "0.2" vscode 安装rust 插件 use ferris_says::say; // from the previous step use std::io::{stdout, BufWriter};fn main() {let stdout stdout();let m…...

视觉语言模型导论:这篇论文能成为你进军VLM的第一步
近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。 这些模型之前基本都局限于文本输入,但现在也正在具备处理视觉输入的能力。如果…...

3个步骤解决Mac Boot Camp驱动部署难题:Brigadier自动化方案详解
3个步骤解决Mac Boot Camp驱动部署难题:Brigadier自动化方案详解 【免费下载链接】brigadier Fetch and install Boot Camp ESDs with ease. 项目地址: https://gitcode.com/gh_mirrors/bri/brigadier 还在为Mac电脑安装Windows系统后的驱动问题而烦恼吗&…...

Sumi-e风格出图模糊、缺骨法、无气韵?手把手修复4类典型失败案例,含可复用的--s 800+ --style raw进阶参数包
更多请点击: https://intelliparadigm.com 第一章:Sumi-e风格在Midjourney中的本质困境与美学断层 水墨精神与扩散模型的结构性冲突 Sumi-e(日本水墨画)的核心在于“留白即墨、飞白见气、一笔三变”,其审美依赖于笔触…...

Poppins字体终极指南:免费开源的多语言几何无衬线字体完全解析
Poppins字体终极指南:免费开源的多语言几何无衬线字体完全解析 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 如果你正在寻找一款既现代又专业的免费字体ÿ…...

通用汽车IT部门裁员600人,为AI人才腾空间,软件团队变革进行时
通用汽车IT部门裁员600人,AI人才成新宠 通用汽车证实已对其IT部门进行裁员,约600名领薪员工(占比10%以上)被裁,目的是清除专业知识不再适用的员工,为具有AI背景的人员腾出空间。公司表示这是面向未来做好准…...

大数据量存储终极指南:10个高效数据分片技巧
大数据量存储终极指南:10个高效数据分片技巧 【免费下载链接】til :memo: Today I Learned 项目地址: https://gitcode.com/gh_mirrors/ti/til 在当今数据爆炸的时代,高效处理和存储海量数据已成为企业技术架构的核心挑战。数据分片作为一种关键的…...

高校vs中小学气象站:核心区别
绝大多数普通校园气象站仅适合中小学可视化科普展示,数据精度低、无原始数据导出、无开放接口、参数单一,完全无法满足高校教学科研需求。中小学设备:侧重外观展示、简单数据观看、趣味科普,精度普通、数据封闭、无科研溯源能力&a…...

AI教材编写利器!低查重AI写教材工具,快速生成30万字专业教材!
在开始编写教材之前,选择合适的工具真的是一个“非常纠结”的过程!如果用常见的办公软件来写,功能太简单,框架设计和格式处理都得自己手动来搞;而要是尝试那些专业的编写工具,又会觉得操作太复杂࿰…...

利用GPU指纹技术进行位置验证
大家读完觉得有帮助记得关注和点赞!!!摘要对GPU芯片进行强有力的监管,对于防范先进AI模型被未经授权开发和滥用至关重要。目前的芯片位置监控方法,依赖于存储在芯片内部的加密密钥所支持的“基于ping的协议”。然而&am…...

Tinke完整技术指南:NDS游戏资源提取与逆向工程深度解析
Tinke完整技术指南:NDS游戏资源提取与逆向工程深度解析 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke Tinke是一款专业的任天堂DS(NDS)游戏资源提取与逆向工程…...
)
STM32CubeMX实战:用高级定时器TIM1实现带刹车功能的互补PWM输出(F4系列)
STM32CubeMX实战:用高级定时器TIM1实现带刹车功能的互补PWM输出(F4系列) 在电机控制、电源管理等工业应用中,硬件级的保护机制往往比软件响应更加可靠。STM32F4系列的高级定时器TIM1提供的互补PWM输出与刹车功能,正是为…...