Deepspeed : AttributeError: ‘DummyOptim‘ object has no attribute ‘step‘
题意:尝试在一个名为 DummyOptim 的对象上调用 .step() 方法,但是这个对象并没有定义这个方法
问题背景:
I want to use deepspeed for training LLMs along with Huggingface Trainer. But when I use deepspeed along with trainer I get error "AttributeError: 'DummyOptim' object has no attribute 'step'". Below is my code
尝试结合使用 DeepSpeed 和 Hugging Face 的 Trainer API 来训练大型语言模型(LLMs)时遇到 "AttributeError: 'DummyOptim' object has no attribute 'step'" 这个错误,下面是我的代码:
import argparse
import numpy as np
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLMfrom trl import DPOTrainer, DPOConfig
def preprocess_data(item):return {'prompt': 'Instruct: ' + item['prompt'] + '\n','chosen': 'Output: ' + item['chosen'],'rejected': 'Output: ' + item['rejected']} def main():parser = argparse.ArgumentParser()parser.add_argument("--epochs", type=int, default=1)parser.add_argument("--beta", type=float, default=0.1)parser.add_argument("--batch_size", type=int, default=4)parser.add_argument("--lr", type=float, default=1e-6)parser.add_argument("--seed", type=int, default=2003)parser.add_argument("--model_name", type=str, default="EleutherAI/pythia-14m")parser.add_argument("--dataset_name", type=str, default="jondurbin/truthy-dpo-v0.1")parser.add_argument("--local_rank", type=int, default=0)args = parser.parse_args()# Determine device based on local_rankdevice = torch.device("cuda", args.local_rank) if torch.cuda.is_available() else torch.device("cpu")tokenizer = AutoTokenizer.from_pretrained(args.model_name)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(args.model_name).to(device)ref_model = AutoModelForCausalLM.from_pretrained(args.model_name).to(device)dataset = load_dataset(args.dataset_name, split="train")dataset = dataset.map(preprocess_data)# Split the dataset into training and validation setsdataset = dataset.train_test_split(test_size=0.1, seed=args.seed)train_dataset = dataset['train']val_dataset = dataset['test']training_args = DPOConfig(learning_rate=args.lr,num_train_epochs=args.epochs,per_device_train_batch_size=args.batch_size,logging_steps=10,remove_unused_columns=False,max_length=1024,max_prompt_length=512,deepspeed="ds_config.json" )# Verify and print embedding dimensions before finetuningprint("Base model embedding dimension:", model.config.hidden_size)model.train()ref_model.eval()dpo_trainer = DPOTrainer(model,ref_model,beta=args.beta,train_dataset=train_dataset,eval_dataset=val_dataset,tokenizer=tokenizer,args=training_args,)dpo_trainer.train()# Evaluateevaluation_results = dpo_trainer.evaluate()print("Evaluation Results:", evaluation_results)save_model_name = 'finetuned_model'model.save_pretrained(save_model_name)if __name__ == "__main__":main()The config file used is the below one 使用的配置文件是下面的这个:
{
"zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},"overlap_comm": true,"contiguous_gradients": true,"sub_group_size": 1e9,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_16bit_weights_on_model_save": true},
"bf16": {"enabled": "auto"
},
"fp16": {"enabled": "auto","loss_scale": 0,"initial_scale_power": 32,"loss_scale_window": 1000,"hysteresis": 2,"min_loss_scale": 1
},"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false,
"flops_profiler": {"enabled": false,"detailed": false
},
"optimizer": {"type": "Lamb","params": {"lr": "auto","betas": [0.9, 0.999],"eps": "auto","weight_decay": "auto"}
},
"zero_allow_untested_optimizer": true
}The code works with out deepspeed. I have torch=2.3.1, deepspeed =0.14.5, trl=0.9.4 and CUDA Version: 12.5.
在没有使用 DeepSpeed 的情况下,代码可以正常工作。当前的软件版本配置为:PyTorch 2.3.1,DeepSpeed 0.14.5,TRL 0.9.4,以及 CUDA 版本 12.5。
Appreciate any hint on this ! 非常感谢您在这方面的任何提示!
问题解决:
from accelerate.utils import DistributedTypetraining_args.distributed_state.distributed_type = DistributedType.DEEPSPEEDadding this solves the issue 添加这个解决了问题

相关文章:
Deepspeed : AttributeError: ‘DummyOptim‘ object has no attribute ‘step‘
题意:尝试在一个名为 DummyOptim 的对象上调用 .step() 方法,但是这个对象并没有定义这个方法 问题背景: I want to use deepspeed for training LLMs along with Huggingface Trainer. But when I use deepspeed along with trainer I get …...

【Python123题库】#查询省会 #字典的属性、方法与应用
禁止转载,原文:https://blog.csdn.net/qq_45801887/article/details/140081665 参考教程:B站视频讲解——https://space.bilibili.com/3546616042621301 有帮助麻烦点个赞 ~ ~ Python123题库 查询省会字典的属性、方法与应用 查询省会 类型…...

数据建设实践之大数据平台(一)
大数据组件版本信息 zookeeper-3.5.7hadoop-3.3.5mysql-5.7.28apache-hive-3.1.3spark-3.3.1dataxapache-dolphinscheduler-3.1.9大数据技术架构 大数据组件部署规划 node101node102node103node104node105datax datax datax ZK ZK ZK RM RM NM...

【MIT 6.5840/6.824】Lab1 MapReduce
MapReduce MapReduce思想实现思路感受 6.5840/6.824 Lab与笔记汇总 本文对应的Lab版本为MIT6.5840-Spring2024的Lab1 本博客只提供思路,不会公开任何代码 本lab耗时约6h,码量约500行 MapReduce思想 MapReduce的思想属于是比较简单的,分为两…...

如何在 C 语言中进行选择排序?
🍅关注博主🎗️ 带你畅游技术世界,不错过每一次成长机会! 📙C 语言百万年薪修炼课程 通俗易懂,深入浅出,匠心打磨,死磕细节,6年迭代,看过的人都说好。 文章目…...

开源浏览器引擎对比与适用场景:WebKit、Chrome、Gecko
WebKit与Chrome的Blink引擎对比 起源与关系: WebKit最初由苹果公司开发,用于Safari浏览器。后来,WebKit逐渐成为一个独立的开源项目,被多个浏览器厂商采用。Blink是Google基于WebKit项目分支出来的一个浏览器引擎,用于…...
DNF客户端使用
客户端使用 1、下载客户端2、配置网关连接到服务器2.1 网关设置参数:2.2 点击连接网关2.3 点击“参数设置内容立即生效” 3、使用网关生成登陆器3.1 登陆器参数设置3.2 点击增加3.3 复制网关的通信密钥,点击生成登陆器 4、复制替换相关文件4.1 复制登陆器到客户端文…...

打包时提示:Missing Gradle Project Information.或者在加载gradle时出错
1.Android打包弹出错误提示框:missing gradle project information. please check if the IDE successfully synchronized its state with the Gradble project model. 2.加载gradle出错:修复报错后 File -> Sync Project with Gradle Files...

基于前馈神经网络 FNN 实现股票单变量时间序列预测(PyTorch版)
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对…...

Scikit Learn - 建模手册(02)--- 数据表示、估算器
Scikit Learn - 数据表示 文章目录 一、说明二、数据表格2.1 数据作为特征矩阵2.2 数据作为目标数组 三、什么是 Estimator API四、Estimator API 的使用五、指导原则六、使用 Estimator API 的步骤七、监督学习示例八、无监督学习示例 一、说明 众所周知,机器学习…...

【鸿蒙学习笔记】通过用户首选项实现数据持久化
官方文档:通过用户首选项实现数据持久化 目录标题 使用场景第1步:源码第2步:启动模拟器第3步:启动entry第6步:操作样例2 使用场景 Preferences会将该数据缓存在内存中,当用户读取的时候,能够快…...

LabVIEW航空发动机试验器数据监测分析
1. 概述 为了适应航空发动机试验器的智能化发展,本文基于图形化编程工具LabVIEW为平台,结合航空发动机试验器原有的软硬件设备,设计开发了一套数据监测分析功能模块。主要阐述了数据监测分析功能设计中的设计思路和主要功能,以及…...

快速上手:前后端分离开发(Vue+Element+Spring Boot+MyBatis+MySQL)
文章目录 前言项目简介环境准备第一步:初始化前端项目登录页面任务管理页面 第二步:初始化后端项目数据库配置数据库表结构实体类和Mapper服务层和控制器 第三步:连接前后端总结 🎉欢迎来到架构设计专栏~探索Java中的静态变量与实…...
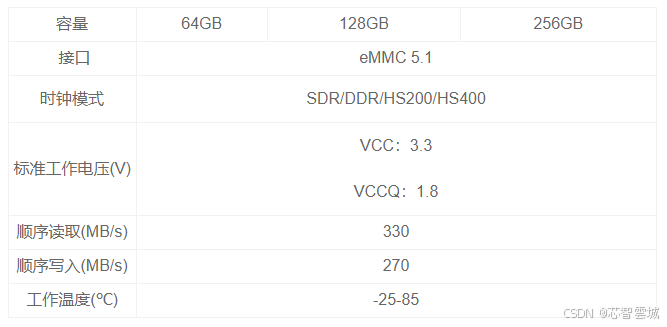
产品推荐| 长江存储eMMC嵌入式储存 YMTC EC230
产品详情 EC230是基于长江存储晶栈Xtacking3.0三维闪存架构打造的新一代eMMC 5.1嵌入式存储产品。EC230的最大顺序读取速度达330MB/s,支持动态SLC缓存,为终端设备提供稳定高性能;支持自动后台/自动节能等操作,减少设备延迟&#…...

【Linux】IP地址与主机名
文章目录 1.IP地址2.特殊IP地址3.主机名4.域名解析 1.IP地址 每一台联网的电脑都会有一个地址,用于和其它计算机进行通讯 IP地址主要有2个版本,V4版本和V6版本 IPv4版本的地址格式是:a.b.c.d,其中abcd表示0~255的数字,如192.168.…...

ros2--colcon
colcon ros2的编译工具,用于编译ros2项目; 需要在工作空间,也就是src上一级目录colcon build; 很明显colcon作为构建工具,通过调用CMake、Python setuptools完成构建。 小鱼文档 构建参数 --packages-select 仅构…...

PyCharm 2023.3.2 关闭时一直显示正在关闭项目
文章目录 一、问题描述二、问题原因三、解决方法 一、问题描述 PyCharm 2023.3.2 关闭时一直显示正在关闭项目 二、问题原因 因为PyCharm还没有加载完索引导致的 三、解决方法 方法一: 先使用任务管理器强制关闭,下次关闭时注意要等待PyCharm加载完索…...

VS2022 git拉取/推送代码错误
第一步:打开VS2022 第二步:工具->选项->源代码管理->Git 全局设置 第三步:加密网络提供程序设置为:OpenSSL 完结:...

【Vue】vue3中使用swipe竖直方向上滚动
安装 npm install swipe使用 import swiper/css; import swiper/css/mousewheel; import { Swiper, SwiperSlide } from swiper/vue; import { Mousewheel } from swiper/modules;containerHeight 是容器的高度,一定要设置竖直方向上滚动高度,不然会非…...

搭建基于 ChatGPT 的问答系统
搭建基于 ChatGPT 的问答系统 📣1.简介📣2.模型,范式和 token📣3.检查输入-分类📣4.检查输入-监督📣5.思维链推理📣6.提示链📣7.检查输入📣8.评估(端到端系统…...
)
【数字对调】信息学奥赛一本通C语言解法(题号2070)
自留or欢迎大佬纠错【题目描述】输入一个三位数,要求把这个数的百位数与个位数对调,输出对调后的数。【输入】三位数。【输出】如题述结果。【输入样例】123【输出样例】321#include<stdio.h> int main(){int a;scanf("%d",&a);int …...
)
Python(while循环)
目录 1.while 循环的基本概念 1.1 语法格式 1.2 最简单的示例 1.3 while 与 for 的对比 2. 代码执行顺序详解 3. 无限循环及其控制 3.1 无限循环的基本写法 3.2 避免无限循环的常见错误 4. break、continue 与 else 4.1 break:提前终止整个循环 4.2 cont…...

BiliBiliToolPro:解放双手的B站自动化神器,让你的账号管理从未如此轻松
BiliBiliToolPro:解放双手的B站自动化神器,让你的账号管理从未如此轻松 【免费下载链接】BiliBiliToolPro B 站(bilibili)自动任务工具,支持docker、青龙、k8s等多种部署方式。全面拥抱AI。敏感肌也能用。 项目地址:…...

USER.md 渐进式沉淀实战:Hermes Agent 用户画像构建的 4 阶段演进路径
1. USER.md 不是静态配置,而是用户认知的渐进式快照 大多数人第一次打开 USER.md 文件时,会下意识把它当成一个“填空题”:姓名、职位、技术栈、常用工具……填完就提交,以为完成了人格初始化。我试过三次——第一次在内部 PoC 项目里,第二次在客户交付现场,第三次是在给…...

WLED与xLights打造音乐同步LED灯光秀:从硬件连接到创意编排
1. 项目概述:从独立闪烁到交响乐章如果你玩过像NeoPixel这类可单独寻址的LED灯带,肯定体验过那种让灯光随心所欲流动的快感。但不知道你有没有想过,把这些闪烁的光点从简单的循环动画,升级成一场能与音乐节拍精准共舞、充满叙事感…...

从标签页混乱到高效工作流:Tabee如何彻底改变我的浏览器体验
从标签页混乱到高效工作流:Tabee如何彻底改变我的浏览器体验 【免费下载链接】chrome-tab-modifier Take control of your tabs 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-tab-modifier 你是否曾经在几十个标签页中迷失方向?每个标签页…...

终极科学文库PDF解密完整指南:永久解除CAJViewer限制的3步方案
终极科学文库PDF解密完整指南:永久解除CAJViewer限制的3步方案 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效期限制。 项目…...

C语言入门实战:从开发环境搭建到核心语法精讲
1. 从零开始:为什么是C语言,以及我们该如何开始如果你对编程世界充满好奇,或者想从最坚实的地基开始构建你的技术大厦,那么选择C语言作为起点,绝对是一个明智且充满挑战的决定。这不是一个轻松的选择,但它的…...

QMC音频解密实战指南:如何高效解锁QQ音乐加密文件
QMC音频解密实战指南:如何高效解锁QQ音乐加密文件 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 还在为QQ音乐下载的加密音频文件无法在其他播放器中使用而困扰…...

还在对着学校格式手册掉头发?Paperxie 帮你一键搞定毕业论文排版
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 改完论文正文,本以为能松口气,结果学校的格式手册又把你打回原形。字体字号、页眉页…...