【JVM基础篇】Java的四种垃圾回收算法介绍
文章目录
- 垃圾回收算法
- 垃圾回收算法的历史和分类
- 垃圾回收算法的评价标准
- 标记清除算法
- 优缺点
- 复制算法
- 优缺点
- 标记整理算法(标记压缩算法)
- 优缺点
- 分代垃圾回收算法(常用)
- JVM参数设置
- 使用Arthas查看内存分区
- 垃圾回收执行流程
- 分代GC算法内存为什么分年轻代、老年代
- 文章说明
垃圾回收算法
Java是如何实现垃圾回收的呢?简单来说,垃圾回收算法要做的有两件事:
- 找到内存中存活的对象
- 释放不再存活对象的内存,使得程序能再次利用这部分空间

垃圾回收算法的历史和分类
- 1960年John McCarthy发布了第一个GC算法:标记-清除算法。
- 1963年Marvin L. Minsky 发布了复制算法。
本质上后续所有的垃圾回收算法,都是在上述两种算法的基础上优化而来。

垃圾回收算法的评价标准
Java垃圾回收过程会通过单独的GC线程来完成,但是不管使用哪一种GC算法,都会有部分阶段需要停止所有的用户线程。这个过程被称之为Stop The World简称STW,如果STW时间过长(系统假死)则会影响用户的使用。
如下图,用户代码执行和垃圾回收执行让用户线程停止执行(STW)是交替执行的。

交替执行过程可以通过如下代码验证:
package chapter04.gc;import lombok.SneakyThrows;import java.util.LinkedList;
import java.util.List;/*** STW测试*/
public class StopWorldTest {public static void main(String[] args) {new PrintThread().start();new ObjectThread().start();}
}/*** 打印线程*/
class PrintThread extends Thread{@SneakyThrows@Overridepublic void run() {//记录开始时间long last = System.currentTimeMillis();while(true){long now = System.currentTimeMillis();// 如果不是垃圾回收影响,这里每次都应该是输出100System.out.println(now - last);last = now;Thread.sleep(100);}}
}/*** 创建对象线程*/
class ObjectThread extends Thread{@SneakyThrows@Overridepublic void run() {List<byte[]> bytes = new LinkedList<>();while(true){// 最多存放8g,然后删除强引用,垃圾回收时释放8gif(bytes.size() >= 80){// 清空集合,强引用去除,垃圾回收器就会去回收对象bytes.clear();}bytes.add(new byte[1024 * 1024 * 100]);Thread.sleep(10);}}
}
代码运行之前,设置如下JVM参数


所以判断GC算法是否优秀,可以从三个方面来考虑:
- 吞吐量
吞吐量指的是 CPU 用于执行用户代码的时间与 CPU 总执行时间的比值,即吞吐量 = 执行用户代码时间 /(执行用户代码时间 + GC时间)。吞吐量数值越高,垃圾回收的效率就越高。

- 最大暂停时间
最大暂停时间指的是所有在垃圾回收过程中的STW时间最大值。比如如下的图中,黄色部分的STW就是最大暂停时间,显而易见上面的图比下面的图拥有更少的最大暂停时间。最大暂停时间越短,用户使用系统时受到的影响就越短。

- 堆使用效率
不同垃圾回收算法,对堆内存的使用方式是不同的。比如标记清除算法,可以使用完整的堆内存。而复制算法会将堆内存一分为二,每次只能使用一半内存。从堆使用效率上来说,标记清除算法要优于复制算法。

上述三种评价标准:堆使用效率、吞吐量,以及最大暂停时间不可兼得。
一般来说,堆内存越大,回收对象就越多,最大暂停时间就越长。想要减少最大暂停时间,就要减少堆内存,少量多次,因为每次清理有一些准备工作,因此垃圾回收总时间会上升,吞吐量会降低。
没有一个垃圾回收算法能兼顾上述三点评价标准,所以不同的垃圾回收算法它的侧重点是不同的,适用于不同的应用场景(即垃圾回收算法没有好与坏,只有是否适合)
- 秒杀场景,购买只有很少的时间,最大暂停时间越短越好
- 有的场景,程序就在后台处理数据,暂停时间长一点无所谓,目标是吞吐量高一点
标记清除算法
标记清除算法的核心思想分为两个阶段:
- 标记阶段,将所有存活的对象进行标记。Java中使用可达性分析算法,从GC Root开始通过引用链遍历出所有存活对象。
- 清除阶段,从内存中删除没有被标记也就是非存活对象。
第一个阶段,从GC Root对象开始扫描,将对象A、B、C在引用链上的对象标记出来:

第二个阶段,将没有标记的对象清理掉,所以对象D就被清理掉了。

优缺点
优点:实现简单,只需要在第一阶段给每个对象维护标志位(在引用链上,标记为1),第二阶段删除标记值为0的对象即可。
缺点:
- 碎片化问题:由于内存是连续的,所以在对象被删除之后,内存中会出现很多细小的可用内存单元。如果我们需要的是一个比较大的空间,很有可能这些内存单元的大小过小无法进行分配。如下图,红色部分已经被清理掉了,总共回收了9个字节,但是每个都是一个小碎片,无法为5个字节的对象分配空间。

- 分配速度慢。由于内存碎片的存在,需要维护一个空闲链表,极有可能发生每次需要遍历到链表的最后才能获得合适的内存空间。我们需要用一个链表来维护,哪些空间可以分配对象,很有可能需要遍历这个链表到最后,才能发现这块空间足够我们去创建一个对象。如下图,遍历到最后才发现有足够的空间分配3个字节的对象了。如果链表很长,遍历也会花费较长的时间。

复制算法
复制算法的核心思想是:
- 准备两块空间From空间和To空间,每次在对象分配阶段,只能使用其中一块空间(From空间)。
对象A首先分配在From空间:

- 在垃圾回收GC阶段,将From中的存活对象复制到To空间。
在垃圾回收阶段,如果对象A存活,就将其复制到To空间。然后将From空间直接清空。

- 将两块空间的From和To名字互换,下次依然在From空间上创建对象。

完整的复制算法的例子:
1、将堆内存分割成两块From空间 To空间,对象分配阶段,创建对象。

2、GC阶段开始,将GC Root搬运到To空间

3、将GC Root关联的对象,搬运到To空间

4、清理From空间,并把名称互换

优缺点
优点:
- 吞吐量高,复制算法只需要遍历一次存活对象复制到To空间即可,比
标记-整理算法少了一次遍历的过程,因而性能较好;但是性能不如标记-清除算法,因为标记清除算法不需要进行对象的移动 - 不会发生碎片化,复制算法在复制之后就会将对象按顺序放入To空间中,所以对象以外的区域都是可用空间,不存在碎片化内存空间。
缺点:
- 内存使用效率低,每次只能让一半的内存空间来给创建对象使用。
标记整理算法(标记压缩算法)
标记整理算法是对标记清理算法中容易产生内存碎片问题的一种解决方案。
核心思想分为两个阶段:
- 标记阶段,将所有存活的对象进行标记。Java中使用可达性分析算法,从GC Root开始通过引用链遍历出所有存活对象。
- 整理阶段,将存活对象移动到堆的一端。清理掉存活对象的内存空间。

优缺点
优点:
- 内存使用效率高,整个堆内存都可以使用,不像复制算法只能使用半个堆内存
- 不会发生碎片化,在整理阶段可以将对象往内存的一侧进行移动,剩下的空间都是可以分配对象的有效空间
缺点:
- 整理阶段的效率不高,需要遍历多次对象,还需要移动对象。整理算法有很多种,比如Lisp2整理算法需要对整个堆中的对象搜索3次,整体性能不佳。可以通过Two-Finger、表格算法、ImmixGC等高效的整理算法优化此阶段的性能。
分代垃圾回收算法(常用)
现代优秀的垃圾回收算法,会将上述描述的垃圾回收算法组合进行使用,其中应用最广的就是分代垃圾回收算法(Generational GC)。分代垃圾回收将整个内存区域划分为两块大区:年轻代、老年代:

- Eden区:对象刚被创建出来的时候放到的地方
- 幸存者区-S0、幸存者区-S1:用来实现复制算法
可以通过arthas来验证下内存划分的情况:
- 在JDK8中,添加
-XX:+UseSerialGC参数使用分代回收的垃圾回收器,运行程序。 - 在arthas中使用memory命令查看内存,显示出三个区域的内存情况。

- Eden + survivor 这两块区域组成了年轻代。
- tenured_gen指的是晋升区域,其实就是老年代。
JVM参数设置
可以设置的虚拟机参数如下
| 参数名 | 参数含义 | 示例 |
|---|---|---|
| -Xms | 设置堆的最小和初始大小,必须是1024倍数且大于1MB | 比如初始大小6MB的写法: -Xms6291456 -Xms6144k -Xms6m |
| -Xmx | 设置最大堆的大小,必须是1024倍数且大于2MB | 比如最大堆80 MB的写法: -Xmx83886080 -Xmx81920k -Xmx80m |
| -Xmn | 新生代的大小 | 新生代256 MB的写法: -Xmn256m -Xmn262144k -Xmn268435456 |
| -XX:SurvivorRatio | 伊甸园区和幸存区的比例,默认为8:如新生代有1g内存,则伊甸园区800MB,S0和S1各100MB | 比例调整为4的写法:-XX:SurvivorRatio=4 |
| -XX:+PrintGCDetailsverbose:gc | 打印GC日志 | 无 |
老年代大小不需要设置,因为新生代设置完之后,老年代的大小就确定了(总的堆内存-新生代内存)
注:如果使用其他版本的JDK,或者使用其他回收器,上面的部分参数可能就不会生效
使用Arthas查看内存分区
代码:
package chapter04.gc;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;/*** 垃圾回收器案例1*/
//-XX:+UseSerialGC -Xms60m -Xmn20m -Xmx60m -XX:SurvivorRatio=3 -XX:+PrintGCDetails
public class GcDemo0 {public static void main(String[] args) throws IOException {List<Object> list = new ArrayList<>();int count = 0;while (true){System.in.read();System.out.println(++count);//每次添加1m的数据list.add(new byte[1024 * 1024 * 1]);}}
}
使用arthas的memory展示出来的效果:

heap展示的是可用堆。
垃圾回收执行流程
1、分代回收时,创建出来的对象,首先会被放入Eden伊甸园区。

2、随着对象在Eden区越来越多,如果Eden区满,新创建的对象已经无法放入,就会触发年轻代的GC,称为Minor GC或者Young GC。Minor GC会把需要eden中和From需要回收的对象回收,把没有回收的对象放入To区(算法使用的是复制算法)。Minor GC结束之后**,**Eden区会被清空,后面创建的对象又可以放到Eden区。

3、接下来,S0会变成To区,S1变成From区。当eden区满时再往里放入对象,依然会发生Minor GC。

此时会回收eden区和S1(from)中的对象,并把eden和from区中存活的对象放入S0。
注意:每次Minor GC中都会为对象记录他的年龄,初始值为0,每次GC完加1。

4、如果Minor GC后对象的年龄达到阈值(最大15,默认值和垃圾回收器有关),对象就会被晋升至老年代。


5、当老年代中空间不足,无法放入新的对象时,先尝试minor gc(为啥?**因为young满了之后,部分对象年龄没有到15,也被放在了老年区,**minor gc可以清理young区来放新对象)。如果空间还是不足,就会触发Full GC(停顿时间较长),Full GC会对整个堆进行垃圾回收。如果Full GC依然无法回收掉老年代的对象,那么当对象继续放入老年代时,就会抛出Out Of Memory异常。

下图中的程序为什么会出现OutOfMemory?

从上图可以看到,Full GC无法回收掉老年代的对象,那么当对象继续放入老年代时,就会抛出Out Of Memory异常。
【测试代码】
//-XX:+UseSerialGC -Xms60m -Xmn20m -Xmx60m -XX:SurvivorRatio=3 -XX:+PrintGCDetails
public class GcDemo0 {public static void main(String[] args) throws IOException {List<Object> list = new ArrayList<>();int count = 0;while (true){System.in.read();System.out.println(++count);//每次添加1m的数据list.add(new byte[1024 * 1024 * 1]);}}
}
结果如下:

老年代已经满了,而且垃圾回收无法回收掉对象,如果还想往里面放就发生了OutOfMemoryError。

分代GC算法内存为什么分年轻代、老年代
为什么分代GC算法要把堆分成年轻代和老年代?首先我们要知道堆内存中对象的特性:
- 系统中的大部分对象,都是创建出来之后很快就不再使用可以被回收,比如用户获取订单数据,订单数据返回给用户之后就可以释放了。
- 老年代中会存放长期存活的对象,比如Spring的大部分bean对象,在程序启动之后就不会被回收了。
- 在虚拟机的默认设置中,新生代大小要远小于老年代的大小。
分代GC算法将堆分成年轻代和老年代主要原因有:
- 可以通过调整年轻代和老年代的比例来适应不同类型的应用程序,提高内存的利用率和性能。
- 新生代和老年代使用不同的垃圾回收算法,新生代一般选择
复制算法;老年代可以选择标记-清除和标记-整理算法,由程序员来选择灵活度较高。 - 分代的设计中允许只回收新生代(minor gc),如果能满足对象分配的要求就不需要对整个堆进行回收(full gc),STW时间就会减少。(尽可能做minor gc,少做full gc,尽量降低垃圾回收对程序运行的影响)
文章说明
该文章是本人学习 黑马程序员 的学习笔记,文章中大部分内容来源于 黑马程序员 的视频黑马程序员JVM虚拟机入门到实战全套视频教程,java大厂面试必会的jvm一套搞定(丰富的实战案例及最热面试题),也有部分内容来自于自己的思考,发布文章是想帮助其他学习的人更方便地整理自己的笔记或者直接通过文章学习相关知识,如有侵权请联系删除,最后对 黑马程序员 的优质课程表示感谢。
相关文章:
【JVM基础篇】Java的四种垃圾回收算法介绍
文章目录 垃圾回收算法垃圾回收算法的历史和分类垃圾回收算法的评价标准标记清除算法优缺点 复制算法优缺点 标记整理算法(标记压缩算法)优缺点 分代垃圾回收算法(常用)JVM参数设置使用Arthas查看内存分区垃圾回收执行流程分代GC算…...
Kodcloud可道云安装与一键发布上线实现远程访问详细教程
文章目录 1.前言2. Kodcloud网站搭建2.1. Kodcloud下载和安装2.2 Kodcloud网页测试 3. cpolar内网穿透的安装和注册4. 本地网页发布4.1 Cpolar云端设置4.2 Cpolar本地设置 5. 公网访问测试6.结语 1.前言 本文主要为大家介绍一款国人自研的在线Web文件管理器可道云,…...

python杨辉三角的两种书写方式
第一种(设置二维列表设置每个元素为0进行替换元素) 代码演示: n eval(input("请输入想要的行数")) lst[[0 for j in range(n)] for i in range(n)] # lst2[[0]*n]*n for i in range(n):for j in range(i1):if j0 or ji:lst[i][j…...

【CSS in Depth 2精译】2.5 无单位的数值与行高
当前内容所在位置 第一章 层叠、优先级与继承第二章 相对单位 2.1 相对单位的威力2.2 em 与 rem2.3 告别像素思维2.4 视口的相对单位2.5 无单位的数值与行高 ✔️2.6 自定义属性2.7 本章小结 2.5 无单位的数值与行高 有些属性允许使用无单位的数值(unitless value…...

【人脸识别、Python实现】PyQt5人脸识别管理系统
PyQt5人脸识别管理系统 项目描述主要功能效果展示获取源码 项目描述 接的一个基于宿舍管理系统与人脸识别的小单子。然后我把它优化了一些,现在开源一下。有需要的小伙伴自取,点个免费的关注就行 主要功能 1、录入学生基本信息、录入人脸 2、主页面展…...

软设之观察者模式
设计模式中,观察者模式的意图是:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。 比如说,有一个新闻网站,订阅的用户众多,假如说管理员发布了一…...

deep learning 环境配置
1 NVIDIA驱动安装 ref link: https://blog.csdn.net/weixin_37926734/article/details/123033286 2 cuda安装 ref link: https://blog.csdn.net/qq_63379469/article/details/123319269 进去网站 https://developer.nvidia.com/cuda-toolkit-archive 选择想要安装的cuda版…...

09磁盘管理
一、磁盘管理 1.磁盘基础知识 (1)磁盘接口类型 个人电脑, 硬盘接口分为IDE类型和SATA类型 服务器版分为SCSI类型和SAS类型 (2)磁盘命名方式 windows中硬盘命名方式是c,d,e盘 linux中硬盘命名方式为 系统…...

Node.js Stream
Node.js Stream Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,它允许开发者使用 JavaScript 编写服务器端代码。Node.js 的一个核心特性是其对流(Stream)的处理能力。流是一种在 Node.js 中处理读/写文件、网络通信或任何端到端…...

简化嵌入式Linux开发:在Ubuntu上安装和配置交叉编译环境的高效方法
在嵌入式Linux开发中,我们通常需要在Ubuntu上安装交叉编译工具链,并配置相关文件。编译过程中,如果遇到依赖库问题,还需要手动查找并编译开源源码。这些步骤较为繁琐,为了简化操作,我们可以尝试以下方案&am…...

Photoshop批量处理图片分辨率
整理一些文件的时候,发现需要处理大量图片的尺寸和分辨率。如果一张一张的处理就会很慢,搜了下,Photoshop提供自动批量处理的方法。在此记录一下。 一、说说批量处理图片 1.打开PS软件并导入图片,我用的是比较老的版本cs4&#…...

TCP协议的三次握手和四次挥手(面试)
三次握手 首先可以简单的回答: 1、第一次握手:客户端给服务器发送一个 SYN 报文。 2、第二次握手:服务器收到 SYN 报文之后,会应答一个 SYNACK 报文。 3、第三次握手:客户端收到 SYNACK 报文之后…...

css看见彩虹,吃定彩虹
css彩虹 .f111 {width: 200px;height: 200px;border-radius: 50%;box-shadow: 0 0 0 5px inset red, 0 0 0 10px inset orange, 0 0 0 15px inset yellow, 0 0 0 20px inset lime, 0 0 0 25px inset aqua, 0 0 0 30px inset blue, 0 0 0 35px inset magenta;clip-path: polygo…...

springboot在线教育平台-计算机毕业设计源码68562
摘要 在数字化时代,随着信息技术的飞速发展,在线教育已成为教育领域的重要趋势。为了满足广大学习者对于灵活、高效学习方式的需求,基于Spring Boot的在线教育平台应运而生。Spring Boot以其快速开发、简便部署以及良好的可扩展性,…...
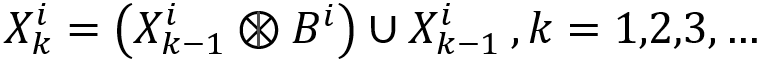
形态学图像处理
1 工具 1.1 灰度腐蚀和膨胀 当平坦结构元b的原点是(x,y)时,它在(x,y)处对图像f的灰度腐蚀定义为,图像f与b重合区域中的最小值。结构元b在位置(x,y)处对图像f的腐蚀写为: 类似地,当b的反射的原点是(x,y)时,平坦结构元…...

安泰电压放大器的选型方案是什么
电压放大器是一种常见的电路元件,广泛应用于各种电子设备中。在选择电压放大器的时候,我们需要考虑一系列因素,以确保选型方案能够满足实际需求。下面安泰电子将详细介绍电压放大器选型的主要考虑因素,包括应用需求、技术性能、成…...

ARMV8安全特性:Pointer Authentication
文章目录 前言一、Introduction二、Problem Definition三、Pointer Authentication3.1 Instructions3.2 Cryptography3.3 Key Management 四、Sample Use Cases4.1 Software Stack Protection4.2 Control Flow Integrity (CFI)4.3 Binding Pointers to Addresses 五、Security …...

MySQL和Redis更新一致性问题
1. 先更新数据库,再更新缓存 适用场景:适用于对数据一致性要求不是特别高,且缓存更新失败对 系统影响较小的场景。例如,某些非关键数据的缓存更新。 风险:如果缓存更新失败,会导致数据库和缓存数据不一致。…...

(19)夹钳(用于送货)
文章目录 前言 1 常见的抓手参数 2 参数说明 前言 Copter 支持许多不同的抓取器,这对送货应用和落瓶很有用。 按照下面的链接(或侧边栏),根据你的设置了解配置信息。 Electro Permanent Magnet v3 (EPMv3)Electro Permanent M…...

安装lap和cython_bbox失败了很多次!!!终于被我发现了!
先说 lap 试了很多种方式,pip install lap / conda install -c conda-forge lap … 全失败了后面发现 lap 不支持 python > 3.9 的版本使用 pip install lapx 成功! cython_bbox 更难了 一直提示缺少MicroSoft C 14.0 … 大家有需要自行下载&#x…...

GX Works3实战:基于TCP+SLMP协议与三菱FX5U的工业互联配置详解
1. 从零开始搭建FX5U通信环境 第一次接触三菱FX5U系列PLC时,我被它小巧的机身和强大的性能惊艳到了。这款PLC虽然体积只有传统Q系列的一半大小,但处理能力却提升了两倍以上。不过在实际项目中,最让我头疼的就是通信配置问题——特别是从老项…...

2026年热门抠图软件怎么选?好用的抠图工具实测对比与推荐指南
抠图的需求无处不在——做小红书封面、制作电商商品图、处理证件照、视频背景分离——但市面上的抠图工具繁杂多样,究竟哪个才是真正好用的?我们在2026年对市场上主流的抠图软件进行了全面实测,从操作体验、AI识别精度、输出质量、使用成本等…...

智能字幕革命:Open-Lyrics如何用AI重新定义音频内容处理
智能字幕革命:Open-Lyrics如何用AI重新定义音频内容处理 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。 项…...

ComfyUI Segment Anything 终极指南:一键实现精准AI图像分割
ComfyUI Segment Anything 终极指南:一键实现精准AI图像分割 【免费下载链接】comfyui_segment_anything Based on GroundingDino and SAM, use semantic strings to segment any element in an image. The comfyui version of sd-webui-segment-anything. 项目地…...

告别论文 “双杀” 困局:okbiye 如何用一套闭环方案,破解重复率与 AIGC 检测双重难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT降重复率 - Okbiye智能写作https://www.okbiye.com/reduceAIGC 当你对着导师的红笔批注,第三次修改论文时,有没有想过一个问题:为什么你改了又改的句子,重…...

告别MobaXterm!VSCode Remote-SSH + SFTP插件,实现本地与Linux服务器的无缝代码同步
VSCode全栈远程开发:SSH连接、代码同步与Python环境管理一体化实战 远程开发已成为现代工作流的重要组成部分,但传统工具链的割裂体验让许多开发者头疼。本文将展示如何用VSCode构建完整的远程开发环境,从SSH连接到代码同步,再到P…...
)
告别卡顿!用WebRTC-Streamer在浏览器里丝滑播放海康/大华监控(附完整代码)
告别卡顿!用WebRTC-Streamer在浏览器里丝滑播放海康/大华监控(附完整代码) 监控视频的实时查看一直是许多开发者和运维人员头疼的问题。传统的解决方案如Flash早已被淘汰,而基于FLV.js的方案又常常面临延迟高、卡顿、标签页切换暂…...

JiYuTrainer高效实用指南:3步解锁极域电子教室控制,恢复电脑操作自由
JiYuTrainer高效实用指南:3步解锁极域电子教室控制,恢复电脑操作自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 还在为课堂上被老师全屏控制电脑而烦…...

别再傻傻串联了!聊聊数字电路里移位器的三种实现:从简单开关到桶形和对数结构
数字电路设计中的移位器架构选择:从基础实现到性能优化 在数字电路设计中,移位操作是最基础却又最容易被低估的功能之一。许多刚入行的工程师往往会采用最简单的串联移位结构,直到项目遇到性能瓶颈才开始思考优化方案。实际上,移…...

对比直接使用厂商API体验Taotoken在计费透明度上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API体验Taotoken在计费透明度上的优势 在集成大模型能力到实际业务的过程中,除了模型的性能和稳定性&…...