YOLOv10改进 | Conv篇 | RCS-OSA替换C2f实现暴力涨点(减少通道的空间对象注意力机制)
一、本文介绍
本文给大家带来的改进机制是RCS-YOLO提出的RCS-OSA模块,其全称是"Reduced Channel Spatial Object Attention",意即"减少通道的空间对象注意力"。这个模块的主要功能是通过减少特征图的通道数量,同时关注空间维度上的重要特征,来提高模型的处理效率和检测精度。亲测在小目标检测和大尺度目标检测的数据集上都有大幅度的涨点效果(mAP直接涨了大概有0.6左右)。同时本文对RCS-OSA模块的框架原理进行了详细的分析,不光让大家会添加到自己的模型在写论文的时候也能够有一定的参照,最后本文会手把手教你添加RCS-OSA模块到网络结构中。
专栏回顾:YOLOv10改进系列专栏——本专栏持续复习各种顶会内容——科研必备
目录
一、本文介绍
二、RCS-OSA模块原理
2.1 RCS-OSA的基本原理
2.2 RCS
2.3 RCS模块
2.4 OSA
2.5 特征级联
三、RCS-OSA核心代码
四、手把手教你添加RCS-OSA模块
4.1 RCS-OSA添加步骤
4.1.1 步骤一
4.1.2 步骤二
4.1.3 步骤三
4.2 RCS-OSA的yaml文件和训练截图
4.2.1 RCS-OSA的yaml版本一(推荐)
4.2.2 RCS-OSA的yaml版本二
4.2.3 训练代码
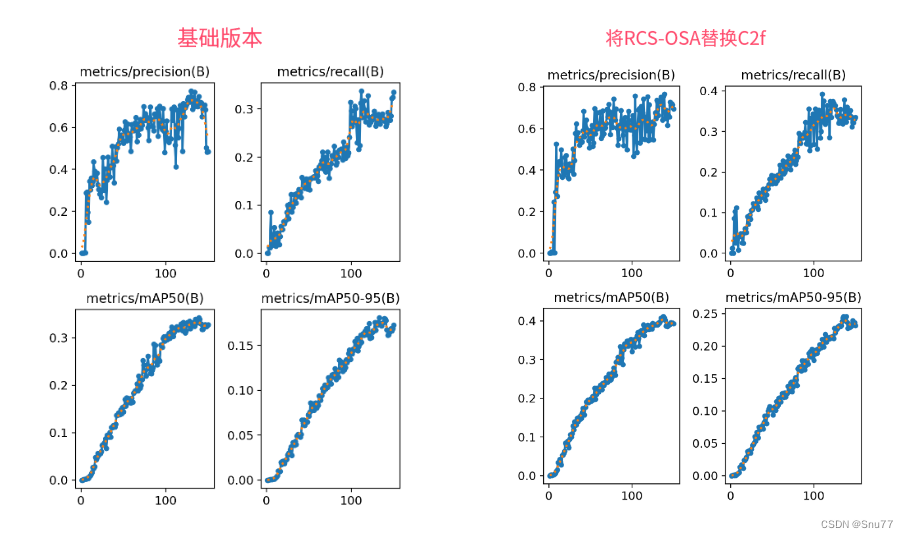
4.2.4 RCS-OSA的训练过程截图
五、本文总结
二、RCS-OSA模块原理

论文地址:官方论文地址
代码地址:官方代码地址

2.1 RCS-OSA的基本原理
RCSOSA(RCS-One-Shot Aggregation)是RCS-YOLO中提出的一种结构,我们可以将主要原理概括如下:
1. RCS(Reparameterized Convolution based on channel Shuffle): 结合了通道混洗,通过重参数化卷积来增强网络的特征提取能力。
2. RCS模块: 在训练阶段,利用多分支结构学习丰富的特征表示;在推理阶段,通过结构化重参数化简化为单一分支,减少内存消耗。
3. OSA(One-Shot Aggregation): 一次性聚合多个特征级联,减少网络计算负担,提高计算效率。
4. 特征级联: RCS-OSA模块通过堆叠RCS,确保特征的复用并加强不同层之间的信息流动。
2.2 RCS
RCS(基于通道Shuffle的重参数化卷积)是RCS-YOLO的核心组成部分,旨在训练阶段通过多分支结构学习丰富的特征信息,并在推理阶段通过简化为单分支结构来减少内存消耗,实现快速推理。此外,RCS利用通道分割和通道Shuffle操作来降低计算复杂性,同时保持通道间的信息交换,这样在推理阶段相比普通的3×3卷积可以减少一半的计算复杂度。通过结构重参数化,RCS能够在训练阶段从输入特征中学习深层表示,并在推理阶段实现快速推理,同时减少内存消耗。
2.3 RCS模块
RCS(基于通道Shuffle的重参数化卷积)模块中,结构在训练阶段使用多个分支,包括1x1和3x3的卷积,以及一个直接的连接(Identity),用于学习丰富的特征表示。在推理阶段,结构被重参数化成一个单一的3x3卷积,以减少计算复杂性和内存消耗,同时保持训练阶段学到的特征表达能力。这与RCS的设计理念紧密相连,即在不牺牲性能的情况下提高计算效率。
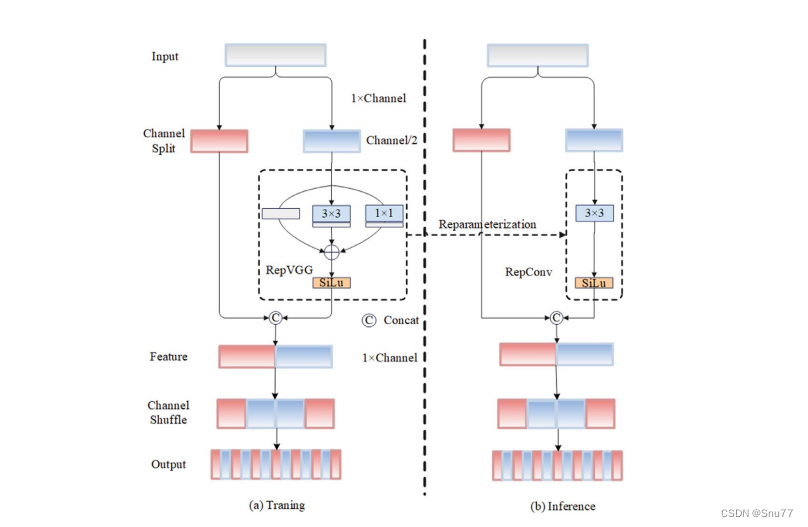
上图为大家展示了RCS的结构,分为训练阶段(a部分)和推理阶段(b部分)。在训练阶段,输入通过通道分割,一部分输入经过RepVGG块,另一部分保持不变。然后通过1x1卷积和3x3卷积处理RepVGG块的输出,与另一部分输入进行通道Shuffle和连接。在推理阶段,原来的多分支结构被简化为一个单一的3x3 RepConv块。这种设计允许在训练时学习复杂特征,在推理时减少计算复杂度。黑色边框的矩形代表特定的模块操作,渐变色的矩形代表张量的特定特征,矩形的宽度代表张量的通道数。
2.4 OSA
OSA(One-Shot Aggregation)是一个关键的模块,旨在提高网络在处理密集连接时的效率。OSA模块通过表示具有多个感受野的多样化特征,并在最后的特征映射中仅聚合一次所有特征,从而克服了DenseNet中密集连接的低效率问题。
OSA模块的使用有两个主要目的:
1. 提高特征表示的多样性:OSA通过聚合具有不同感受野的特征来增加网络对于不同尺度的敏感性,这有助于提升模型对不同大小目标的检测能力。
2. 提高效率:通过在网络的最后一部分只进行一次特征聚合,OSA减少了重复的特征计算和存储需求,从而提高了网络的计算和能源效率。
在RCS-YOLO中,OSA模块被进一步与RCS(基于通道Shuffle的重参数化卷积)相结合,形成RCS-OSA模块。这种结合不仅保持了低成本的内存消耗,而且还实现了语义信息的有效提取,对于构建轻量级和大规模的对象检测器尤为重要。
下面我将为大家展示RCS-OSA(One-Shot Aggregation of RCS)的结构。
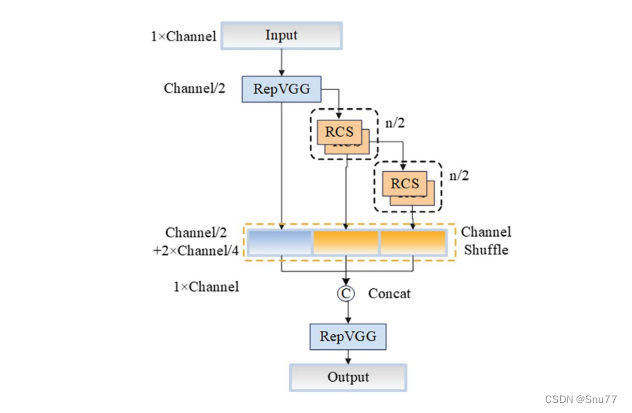
在RCS-OSA模块中,输入被分为两部分,一部分直接通过,另一部分通过堆叠的RCS模块进行处理。处理后的特征和直接通过的特征在通道混洗(Channel Shuffle)后合并。这种结构设计用于增强模型的特征提取和利用效率,是RCS-YOLO架构中的一个关键组成部分旨在通过一次性聚合来提高模型处理特征的能力,同时保持计算效率。
2.5 特征级联
特征级联(feature cascade)是一种技术,通过在网络的一次性聚合(one-shot aggregate)路径上维持有限数量的特征级联来实现的。在RCS-YOLO中,特别是在RCS-OSA(RCS-Based One-Shot Aggregation)模块中,只保留了三个特征级联。
特征级联的目的是为了减轻网络计算负担并降低内存占用。这种方法可以有效地聚合不同层次的特征,提高模型的语义信息提取能力,同时避免了过度复杂化网络结构所带来的低效率和高资源消耗。
下面为大家提供的图像展示的是RCS-YOLO的整体架构,其中包括RCS-OSA模块。RCS-OSA在模型中用于堆叠RCS模块,以确保特征的复用并加强不同层之间的信息流动。图中显示的多层RCS-OSA模块的排列和组合反映了它们如何一起工作以优化特征传递和提高检测性能。

总结:RCS-YOLO主要由RCS-OSA(蓝色模块)和RepVGG(橙色模块)构成。这里的n代表堆叠RCS模块的数量。n_cls代表检测到的对象中的类别数量。图中的IDetect是从YOLOv7中借鉴过来的,表示使用二维卷积神经网络的检测层。这个架构通过堆叠的RCS模块和RepVGG模块,以及两种类型的检测层,实现了对象检测的任务。
三、RCS-OSA核心代码
在这里说一下这个原文是RCS-YOLO我们只是用其中的RCS-OSA模块来替换我们YOLOv8中的C2f模块,但是在RCS-YOLO中还有一个RepVGG模块(大家在下面的代码中可以看到),这个模块可以替换Conv,但是如果都替换的话我觉得那就是RCS-YOLO了没啥区别了,所以我下面的改进和这篇文章只用了RCS-OSA模块来替换C2f,如果你对RCS-YOLO感兴趣的话,我后面也会提高RCS-YOLO的yaml文件供大家参考。
import torch.nn as nn
import torch
import torch.nn.functional as F
import numpy as np
import math# build RepVGG block
# -----------------------------
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):result = nn.Sequential()result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,kernel_size=kernel_size, stride=stride, padding=padding, groups=groups,bias=False))result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))return resultclass SEBlock(nn.Module):def __init__(self, input_channels):super(SEBlock, self).__init__()internal_neurons = input_channels // 8self.down = nn.Conv2d(in_channels=input_channels, out_channels=internal_neurons, kernel_size=1, stride=1,bias=True)self.up = nn.Conv2d(in_channels=internal_neurons, out_channels=input_channels, kernel_size=1, stride=1,bias=True)self.input_channels = input_channelsdef forward(self, inputs):x = F.avg_pool2d(inputs, kernel_size=inputs.size(3))x = self.down(x)x = F.relu(x)x = self.up(x)x = torch.sigmoid(x)x = x.view(-1, self.input_channels, 1, 1)return inputs * xclass RepVGG(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=3,stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):super(RepVGG, self).__init__()self.deploy = deployself.groups = groupsself.in_channels = in_channelspadding_11 = padding - kernel_size // 2self.nonlinearity = nn.SiLU()# self.nonlinearity = nn.ReLU()if use_se:self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)else:self.se = nn.Identity()if deploy:self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True,padding_mode=padding_mode)else:self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else Noneself.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, groups=groups)self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,padding=padding_11, groups=groups)# print('RepVGG Block, identity = ', self.rbr_identity)def get_equivalent_kernel_bias(self):kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasiddef _pad_1x1_to_3x3_tensor(self, kernel1x1):if kernel1x1 is None:return 0else:return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])def _fuse_bn_tensor(self, branch):if branch is None:return 0, 0if isinstance(branch, nn.Sequential):kernel = branch.conv.weightrunning_mean = branch.bn.running_meanrunning_var = branch.bn.running_vargamma = branch.bn.weightbeta = branch.bn.biaseps = branch.bn.epselse:assert isinstance(branch, nn.BatchNorm2d)if not hasattr(self, 'id_tensor'):input_dim = self.in_channels // self.groupskernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)for i in range(self.in_channels):kernel_value[i, i % input_dim, 1, 1] = 1self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)kernel = self.id_tensorrunning_mean = branch.running_meanrunning_var = branch.running_vargamma = branch.weightbeta = branch.biaseps = branch.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta - running_mean * gamma / stddef forward(self, inputs):if hasattr(self, 'rbr_reparam'):return self.nonlinearity(self.se(self.rbr_reparam(inputs)))if self.rbr_identity is None:id_out = 0else:id_out = self.rbr_identity(inputs)return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))def fusevggforward(self, x):return self.nonlinearity(self.rbr_dense(x))# RepVGG block end
# -----------------------------class SR(nn.Module):# Shuffle RepVGGdef __init__(self, c1, c2):super().__init__()c1_ = int(c1 // 2)c2_ = int(c2 // 2)self.repconv = RepVGG(c1_, c2_)def forward(self, x):x1, x2 = x.chunk(2, dim=1)out = torch.cat((x1, self.repconv(x2)), dim=1)out = self.channel_shuffle(out, 2)return outdef channel_shuffle(self, x, groups):batchsize, num_channels, height, width = x.data.size()channels_per_group = num_channels // groupsx = x.view(batchsize, groups, channels_per_group, height, width)x = torch.transpose(x, 1, 2).contiguous()x = x.view(batchsize, -1, height, width)return xdef make_divisible(x, divisor):# Returns nearest x divisible by divisorif isinstance(divisor, torch.Tensor):divisor = int(divisor.max()) # to intreturn math.ceil(x / divisor) * divisorclass RCSOSA(nn.Module):# VoVNet with Res Shuffle RepVGGdef __init__(self, c1, c2, n=1, se=False, e=0.5, stackrep=True):super().__init__()n_ = n // 2c_ = make_divisible(int(c1 * e), 8)# self.conv1 = Conv(c1, c_)self.conv1 = RepVGG(c1, c_)self.conv3 = RepVGG(int(c_ * 3), c2)self.sr1 = nn.Sequential(*[SR(c_, c_) for _ in range(n_)])self.sr2 = nn.Sequential(*[SR(c_, c_) for _ in range(n_)])self.se = Noneif se:self.se = SEBlock(c2)def forward(self, x):x1 = self.conv1(x)x2 = self.sr1(x1)x3 = self.sr2(x2)x = torch.cat((x1, x2, x3), 1)return self.conv3(x) if self.se is None else self.se(self.conv3(x))if __name__ == '__main__':m = RCSOSA(256, 256)im = torch.randn(2, 256, 13, 13)y = m(im)print(y.shape)四、手把手教你添加RCS-OSA模块
4.1 RCS-OSA添加步骤
4.1.1 步骤一
首先我们找到如下的目录'ultralytics/nn/modules',然后在这个目录下创建一个py文件,名字为RCSOSA即可,然后将RCS-OSA的核心代码复制进去。
4.1.2 步骤二
之后我们找到'ultralytics/nn/tasks.py'文件,在其中注册我们的RCS-OSA模块。
首先我们需要在文件的开头导入我们的RCS-OSA模块,如下图所示->

4.1.3 步骤三
我们找到parse_model这个方法,可以用搜索也可以自己手动找,大概在六百多行吧。 我们找到如下的地方,然后将RCS-OSA添加进去即可

到此我们就注册成功了,可以修改yaml文件中输入RCSOSA使用这个模块了。
4.2 RCS-OSA的yaml文件和训练截图
下面推荐几个版本的yaml文件给大家,大家可以复制进行训练,但是组合用很多具体那种最有效果都不一定,针对不同的数据集效果也不一样,我不可每一种都做实验,所以我下面推荐了几种我自己认为可能有效果的配合方式,你也可以自己进行组合。
4.2.1 RCS-OSA的yaml版本一(推荐)
此版本训练信息:YOLOv10n-RCSOSA summary: 469 layers, 5883858 parameters, 5883842 gradients, 20.7 GFLOPs
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov10n.yaml' will call yolov10.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, RCS-OSA, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, RCS-OSA, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, RCS-OSA, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, RCS-OSA, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSA, [1024]] # 10# YOLOv10.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, RCS-OSA, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, RCS-OSA, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, RCS-OSA, [512]] # 19 (P4/16-medium)- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
4.2.2 RCS-OSA的yaml版本二
此版本训练信息:YOLOv10n-RCSOSA-2 summary: 458 layers, 7814866 parameters, 7814850 gradients, 22.2 GFLOPs
此版本为将C2fCIB也替换为RCSOSA
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv10 object detection model. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov10n.yaml' will call yolov10.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, RCSOSA, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, RCSOSA, [256, True]]- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16- [-1, 6, RCSOSA, [512, True]]- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32- [-1, 3, RCSOSA, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 1, PSA, [1024]] # 10# YOLOv10.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, RCSOSA, [512]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, RCSOSA, [256]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 3, RCSOSA, [512]] # 19 (P4/16-medium)- [-1, 1, SCDown, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 3, RCSOSA, [1024]] # 22 (P5/32-large)- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
4.2.3 训练代码
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('ultralytics/cfg/models/v8/yolov8-C2f-FasterBlock.yaml')# model.load('yolov8n.pt') # loading pretrain weightsmodel.train(data=r'替换数据集yaml文件地址',# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, posecache=False,imgsz=640,epochs=150,single_cls=False, # 是否是单类别检测batch=4,close_mosaic=10,workers=0,device='0',optimizer='SGD', # using SGD# resume='', # 如过想续训就设置last.pt的地址amp=False, # 如果出现训练损失为Nan可以关闭ampproject='runs/train',name='exp',)4.2.4 RCS-OSA的训练过程截图
下面是添加了RCS-OSA的训练截图。
大家可以看下面的运行结果和添加的位置所以不存在我发的代码不全或者运行不了的问题大家有问题也可以在评论区评论我看到都会为大家解答(我知道的)。

五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:
相关文章:
YOLOv10改进 | Conv篇 | RCS-OSA替换C2f实现暴力涨点(减少通道的空间对象注意力机制)
一、本文介绍 本文给大家带来的改进机制是RCS-YOLO提出的RCS-OSA模块,其全称是"Reduced Channel Spatial Object Attention",意即"减少通道的空间对象注意力"。这个模块的主要功能是通过减少特征图的通道数量,同时关注空…...

【C++BFS】690. 员工的重要性
本文涉及知识点 CBFS算法 LeetCode690. 员工的重要性 你有一个保存员工信息的数据结构,它包含了员工唯一的 id ,重要度和直系下属的 id 。 给定一个员工数组 employees,其中: employees[i].id 是第 i 个员工的 ID。 employees[…...

视频调整帧率、分辨率+音画同步
# python data_utils/pre_video/multi_fps_crop_sync.pyimport cv2 import os from tqdm import tqdm import subprocess# 加载人脸检测模型 face_cascade cv2.CascadeClassifier(cv2.data.haarcascades haarcascade_frontalface_default.xml)def contains_face(frame):gray …...

【深度学习】关于模型加速
模型转为半精度的会加快推理速度吗 将模型转为半精度(通常指16位浮点数,即FP16)确实可以加快推理速度,同时还能减少显存(GPU内存)的使用。以下是一些关键点: 加快推理速度的原因 减少计算量&a…...

Python中time模块用法示例详解
前言 仅供个人学习用,如果对各位朋友有参考价值,给个赞或者收藏吧 ^_^ 一、time模块介绍 time模块是Python中处理时间相关操作的核心工具,提供了时间获取、格式化、转换、延迟以及计时等多种功能。 总的来说time模块中时间可以有3种格式&…...

解决POST请求中文乱码问题
解决POST请求中文乱码问题 1、乱码原因2、解决方法3、具体步骤 💖The Begin💖点点关注,收藏不迷路💖 在Web开发中,处理POST请求时经常遇到中文乱码问题,这主要是由于服务器在接收到POST请求的数据后&#x…...

Axure-黑马
Axure-黑马 编辑时间2024/7/12 来源:B站黑马程序员 需求其他根据:visio,墨刀 Axure介绍 Axure RP是美国Axure Software Solution给公司出品的一款快速原型大的软件,一般来说使用者会称他为Axure 应用场景 拉投资使用 给项目团…...

Centos解决服务器时间不准的问题
CentOS 系统时间老是自己变化可能有以下几个原因: 硬件时钟问题:服务器的硬件时钟可能出现故障或不准确。 时区设置错误:如果时区设置不正确,可能导致显示的时间与实际期望的时间不符。 系统服务异常:与时间同步相关…...

摸鱼大数据——Kafka——Kafka的shell命令使用
Kafka本质上就是一个消息队列的中间件的产品,主要负责消息数据的传递。也就说学习Kafka 也就是学习如何使用Kafka生产数据,以及如何使用Kafka来消费数据 topics操作 注意: 创建topic不指定分区数和副本数,默认都是1个 分区数可以后期通过alter增大,但是…...

在 Linux/Debian/Ubuntu 上使用 Brasero 刻录光盘
在 Ubuntu 系统中,Brasero 是一个非常方便的光盘刻录工具。无论是创建数据光盘、音频光盘还是刻录光盘镜像文件,Brasero 都能轻松胜任。本文将介绍如何在 Ubuntu 上安装和使用 Brasero 进行光盘刻录。 安装 Brasero 在大多数 Ubuntu 版本中,…...

QT之嵌入外部第三方软件到本窗体中
一、前言 使用QT开发,有时需要调用一些外部程序,但是单独打开一个外部窗口有的场合很不合适,最好是嵌入到开发的QT程序界面中。还有就是自己开发的n个程序,一个主程序托n个子程序,为了方便管理将各个程序独立…...
解决GET请求中文乱码问题
解决GET请求中文乱码问题 1、乱码的根本原因2、解决方法方法一:修改Tomcat配置(推荐)方法二:使用URLEncoder和URLDecoder(不推荐用于GET请求乱码)方法三:String类编解码(不直接解决乱…...

弥合人类与人工智能的知识差距:AlphaZero 中的概念发现和迁移(1)
文章目录 一、摘要二、简介三、相关工作3.1 基于概念的解释3.2 强化学习中生成解释3.3 国际象棋与人工智能 四、什么是概念?五、发掘概念5.1 挖掘概念向量5.1.1 静态概念的概念约束5.1.2 动态概念的概念约束 5.2 过滤概念 一、摘要 人工智能(AIÿ…...

cpp的cbp
.cbp 文件是 Code::Blocks 的项目文件。Code::Blocks 是一个开源的跨平台集成开发环境(IDE),主要用于 C、C 以及 Fortran 编程。.cbp 文件包含有关项目的所有配置信息,包括文件路径、编译选项、链接器设置等。 以下是 .cbp 文件的…...

jQuery 选择器
jQuery 选择器 jQuery 是一个快速、小巧且功能丰富的 JavaScript 库。它使得 HTML 文档遍历和操作、事件处理、动画和 AJAX 等操作更加简单,适用于各种浏览器。jQuery 的核心特性之一是其强大的选择器引擎,它允许开发者通过 CSS 选择器语法轻松地选取和操作 DOM 元素。本文将…...
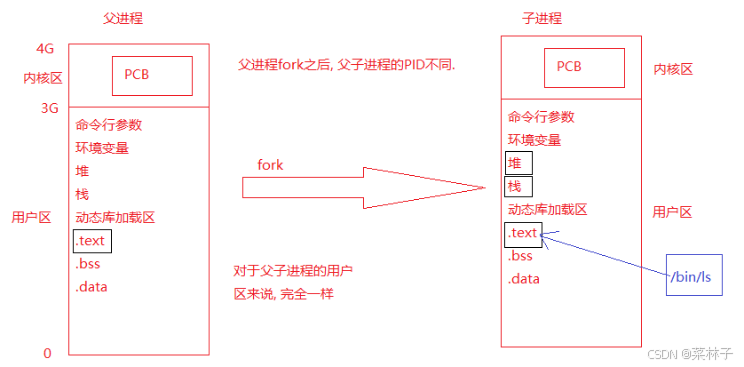
Linux系统编程-进程控制相关操作详解
进程(Process)是计算机科学中一个基本的概念,特别是在操作系统领域中非常重要。它指的是在系统中正在运行的一个程序的实例。每个进程都是系统资源分配的基本单位,是程序执行时的一个实例。以下是关于进程的详细解释: …...

分布式I/O从站的认知
为什么需要分布式I/O从站? 当PLC与控制机构距离过远时,远距离会带来信号干扰,分布式I/O从站只需要一个网络线缆连接。 ET200分布式I/O从站家族 体积紧凑、功能强大。 ET200SP ET200M ET200S ET200iSP ET200 AL ET200pro ET200 eco PN 通讯协议…...
【python】PyQt5顶层窗口相关操作API原理剖析,企业级应用实战分享
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...
流程图编辑框架LogicFlow-vue-ts和js
LogicFlow官网https://site.logic-flow.cn/LogicFlow 是一款流程图编辑框架,提供了一系列流程图交互、编辑所必需的功能和灵活的节点自定义、插件等拓展机制。LogicFlow支持前端研发自定义开发各种逻辑编排场景,如流程图、ER图、BPMN流程等。在工作审批配…...
goaccess分析json格式日志
一.安装使用yum安装,yum install goaccess 二.主要介绍格式问题 1.nginx日志格式如下: log_format main escapejson {"time_local":"$time_local", "remote_addr":"$remote_addr", "r…...

Maxwell 磁芯损耗模型怎么选?Power Ferrite vs B-P Curve
🔖 开篇一句话总结 Power Ferrite:用斯坦梅茨公式算损耗,简单高效,适合标准铁氧体材料快速估算。 B-P Curve:直接用实测数据点插值,精度更高,适合非标准材料或追求极致仿真的场景。 一、底层逻辑有什么不一样? 🔹 Power Ferrite:公式拟合的 “标准模板” 它基于经…...

你的脑洞,值得被“电”亮!TimechoAI 有奖反馈征集令!
五月初,我们“官宣”了将时序大模型“上云”的智能服务平台:TimechoAI,无门槛体验,注册即能试用全部功能!体验过 TimechoAI 的你,心里一定有点想法吧?是惊喜?是建议?还是…...

JMeter登录Cookie提取与传递全链路实战指南
1. 为什么“提取登录Cookie”是接口测试里最常卡壳的一步做JMeter接口测试的人,十有八九在登录环节栽过跟头——明明登录请求返回了200,Header里也明明白白写着Set-Cookie: JSESSIONIDabc123; Path/; HttpOnly,可后续所有带权限的接口全报401…...

Richard Socher创业公司获6.5亿美元融资,欲让AI自动化研发引领底层范式转移
Richard Socher创业公司获巨额融资一家创业公司获得了GV(Alphabet旗下VC)和Greycroft共同领投的6.5亿美元早期融资,NVIDIA和AMD也参与本轮融资,它的估值达到了46.5亿美元。这家公司的创始人是Richard Socher,他是AI领域…...

英特尔N150处理器深度解析:从N100升级看嵌入式一体机效能进化
1. 从N100到N150:一次务实且精准的效能升级在嵌入式与一体机领域,选择一颗合适的处理器,往往意味着在性能、功耗、成本和扩展性之间找到那个微妙的平衡点。过去几年,英特尔的N100处理器凭借其出色的能效比,成为了众多办…...

AI时代如何精准识人?大客户销售话术与沟通,AI赋能销售成交铁军的专业销售技巧成交赢单培训老师
读懂这个人,比说服他更重要 AI时代销售影响力 在大客户销售与高效沟通中,我们最大的误区不是话术不够好,而是压根就没读懂对方是谁。AI时代给了我们一把新的钥匙——用三个维度拆解每一个人,让影响力真正落地。 目录 销售沟通的本…...

1688代采系统开发避坑指南:经验之谈
做跨境代购系统三年了,技术栈换过一次。今天把当初的技术选型过程和踩坑经验整理出来。多页面架构(MPA)的选择:没有用 React/Vue SPA 做租户端前台的首页和商品页,而是传统的多页面(HTML JS jQuery&#…...

JMeter精准控制1 QPS的底层原理与三种实战方案
1. 这不是“设个线程数”就能搞定的事很多人第一次用Jmeter做压测,看到“我要每秒发1个请求”,第一反应是:开1个线程,Ramp-up时间设为1秒,循环次数设无限——结果一跑起来,发现TPS忽高忽低,有时…...

AI执行层临界点:推理确定性、能力切片与可信Agent的工程落地
1. 项目概述:这不是一份新闻简报,而是一份AI产业周度“技术脉搏图”“Last Week in AI”这个标题乍看像一份科技媒体的常规栏目,但真正拆开来看——它根本不是给普通读者看的“资讯摘要”,而是一份面向AI工程师、算法研究员、技术…...

如何快速掌握文档扫描优化:ScanTailor完整指南
如何快速掌握文档扫描优化:ScanTailor完整指南 【免费下载链接】scantailor 项目地址: https://gitcode.com/gh_mirrors/sc/scantailor 你是否曾为扫描文档的歪斜、污渍和模糊而烦恼?ScanTailor就是你的救星!这款强大的开源工具能智能…...