【图解大数据技术】流式计算:Spark Streaming、Flink
【图解大数据技术】流式计算:Spark Streaming、Flink
- 批处理 VS 流式计算
- Spark Streaming
- Flink
- Flink简介
- Flink入门案例
- Streaming Dataflow
- Flink架构
- Flink任务调度与执行
- task slot 和 task
- EventTime、Windows、Watermarks
- EventTime
- Windows
- Watermarks
批处理 VS 流式计算
计算存储介质上的大规模数据,这类计算叫大数据批处理计算。数据是以批为单位进行计算,比如一天的访问日志、历史上所有的订单数据等。这些数据通常通过 HDFS 存储在磁盘上,使用 MapReduce 或者 Spark 这样的批处理大数据计算框架进行计算,一般完成一次计算需要花费几分钟到几小时的时间。
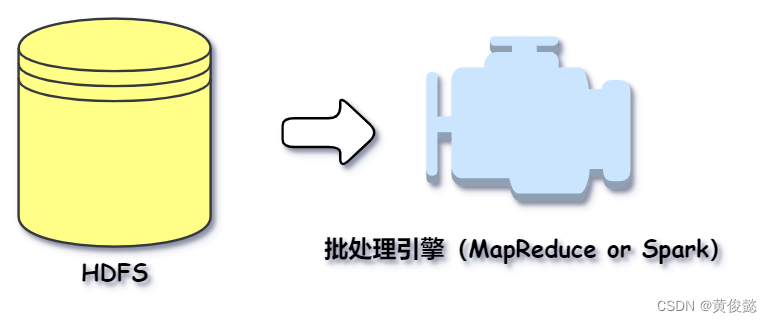
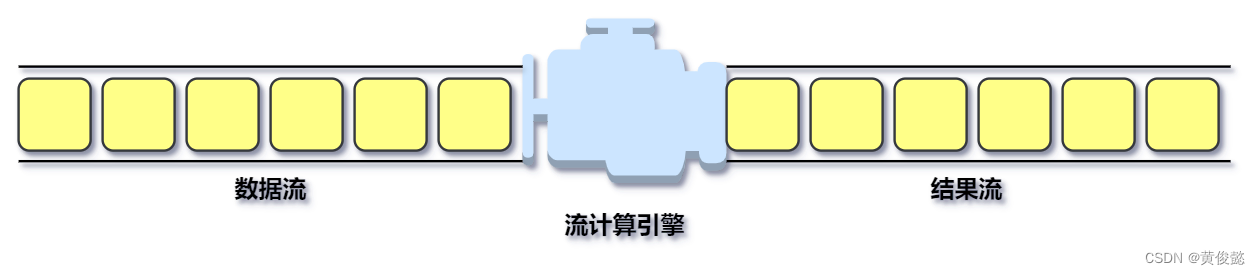
还有一种是针对实时产生的大规模数据进行即时计算处理,比如摄像头采集的实时视频数据、淘宝实时产生的订单数据等。实时处理最大的不同就是这类数据,是实时传输过来的针对这类大数据的实时处理系统也叫大数据流计算系统。
Spark Streaming

Spark是一个批处理大数据计算引擎,而 Spark Steaming 则利用了 Spark 的分片和快速计算的特性,把实时传输过来的数据按时间范围进行分段,转成一个个的小批,再交给 Spark 去处理。因此 Spark Streaming 的原理是流转批,Spark Streaming 不是真正意义上的实时计算框架,它是一个准实时的计算框架。
Flink
Flink简介
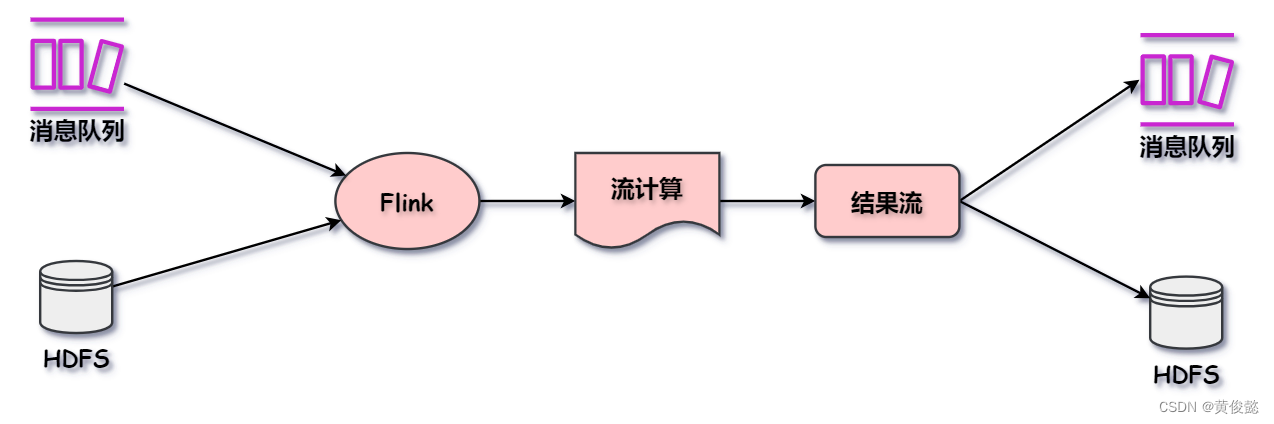
Flink 和 Spark Streaming 不一样,Flink 一开始设计就是为了做实时流式计算的。它可以监听消息队列获取数据流,也可以用于计算存储在 HDFS 等存储系统上的数据(Flink 把 这些静态数据当做数据流来进行处理)。
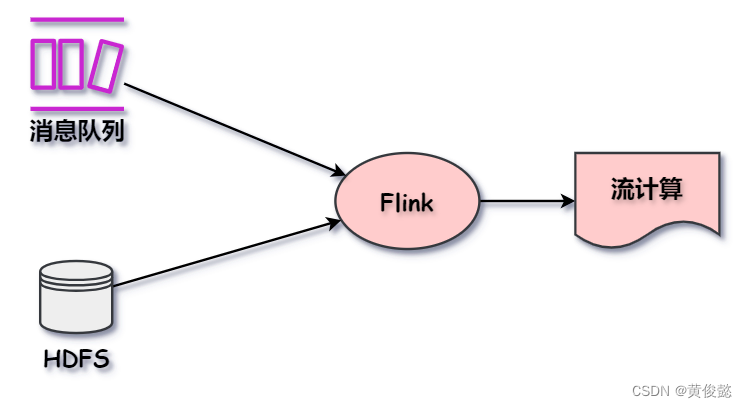
然后 Flink 计算后生成的结果流,也可以发送到其他存储系统。
Flink入门案例
public static void main(String[] args) throws Exception {// 初始化一个流执行环境final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 利用这个执行环境构建数据流 DataStream(source操作)DataStream<Person> flintstones = env.fromElements(new Person("Fred", 35),new Person("Wilma", 35),new Person("Pebbles", 2));// 执行各种数据转换操作(transformation)DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {@Overridepublic boolean filter(Person person) throws Exception {return person.age >= 18;}});// 打印结果(sink类型操作)adults.print();// 执行env.execute();}
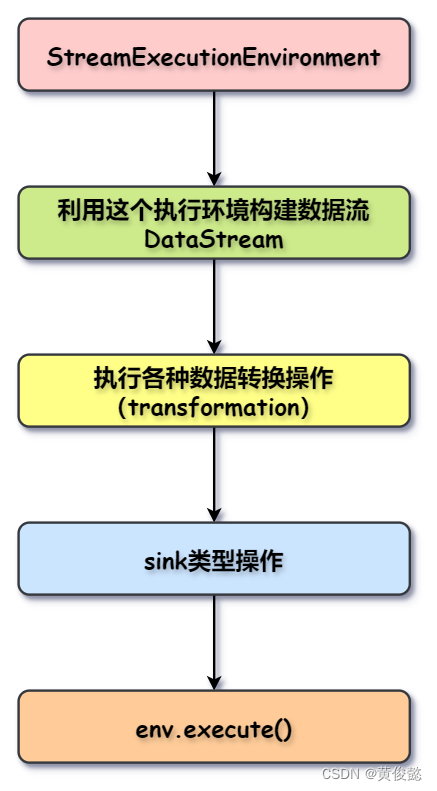
首先构建一个执行环境env,然后通过执行环境env构建数据流DataStream(这就是source操作),然对这个数据流进行各种转换操作(transformation),最后跟上一个sink类型操作(类似是Spark的action操作),然后调用env的execute()启动计算。
上面是流计算的例子,如果要进行批计算,则要构建ExecutionEnvironment类型的执行环境,然后使用ExecutionEnvironment执行环境构建一个DataSet。
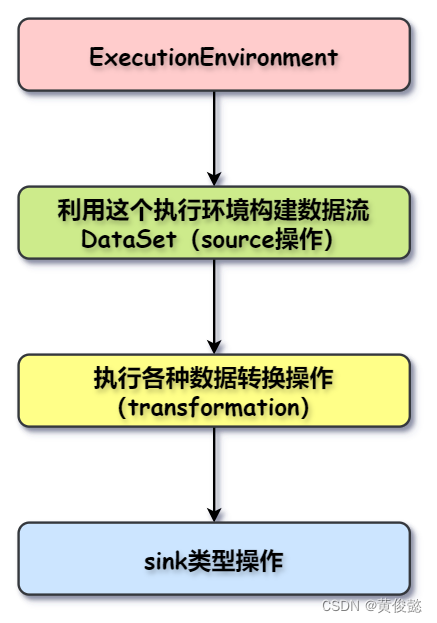
Streaming Dataflow
Flink程序代码会被映射为Streaming Dataflow(类似于DAG)。一个Streaming Dataflow是由一组Stream(流)和Operator(算子)组成,并且始于一个或多个Source Operator,结束于一个或多个Sink Operator,中间有一个或多个Transformation Operator。
Source Operator:
DataStream<Person> flintstones = env.fromElements(new Person("Fred", 35),new Person("Wilma", 35),new Person("Pebbles", 2));
Transformation Operator:
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {@Overridepublic boolean filter(Person person) throws Exception {return person.age >= 18;}});
Sink Operator:
adults.print();
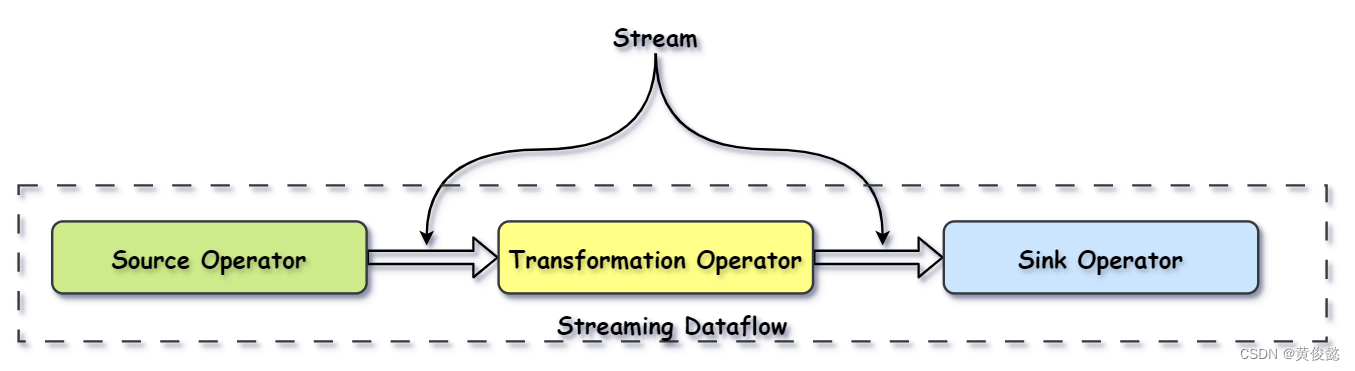
由于Flink是分布式并行的,因此在程序执行期间,一个Stream流会有多个Stream Partition(流分区),一个Operator也会有多个Operator Subtask(算子子任务)。
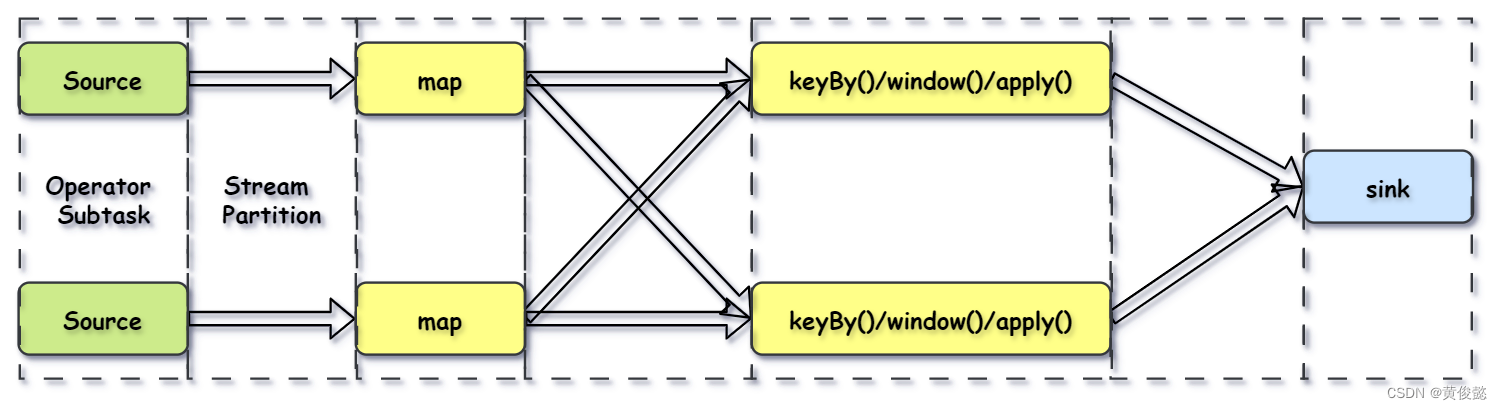
两个 operator 之间传递的时候有两种模式:
- One to One 模式:像Source到map这种传递模式,不会改变数据的分区特性。
- Redistributing (重新分配)模式:像map到keyBy这种传递模式,会根据key的hashcode进行重写分区,改变分区特性的。
Flink还会进行优化,将紧密度高的算子结合成一个Operator Chain(算子链)。
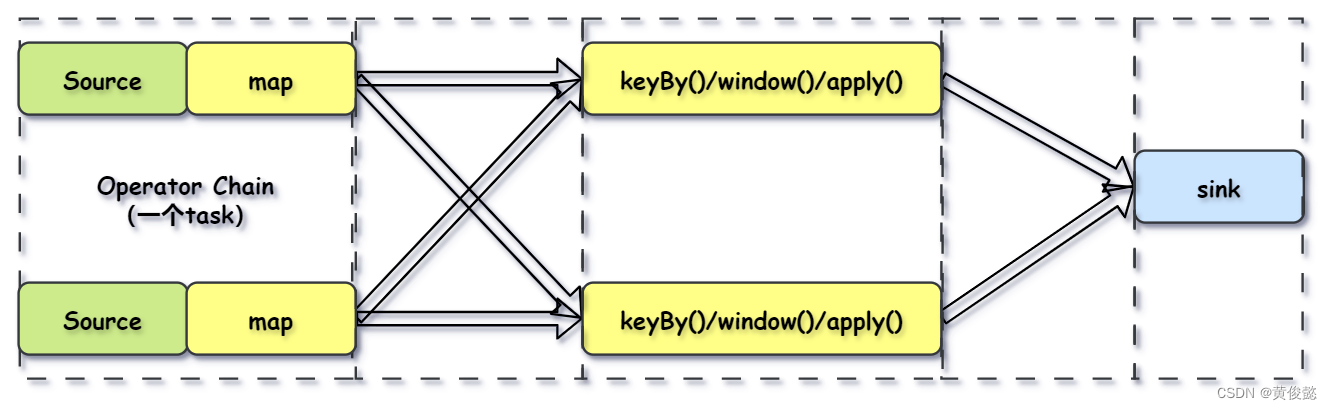
比如Source操作和map操作可以结合成一个Operator Chain,结合成Operator Chain后就在一个task中由一个thread完成。
Flink架构
Flink任务调度与执行
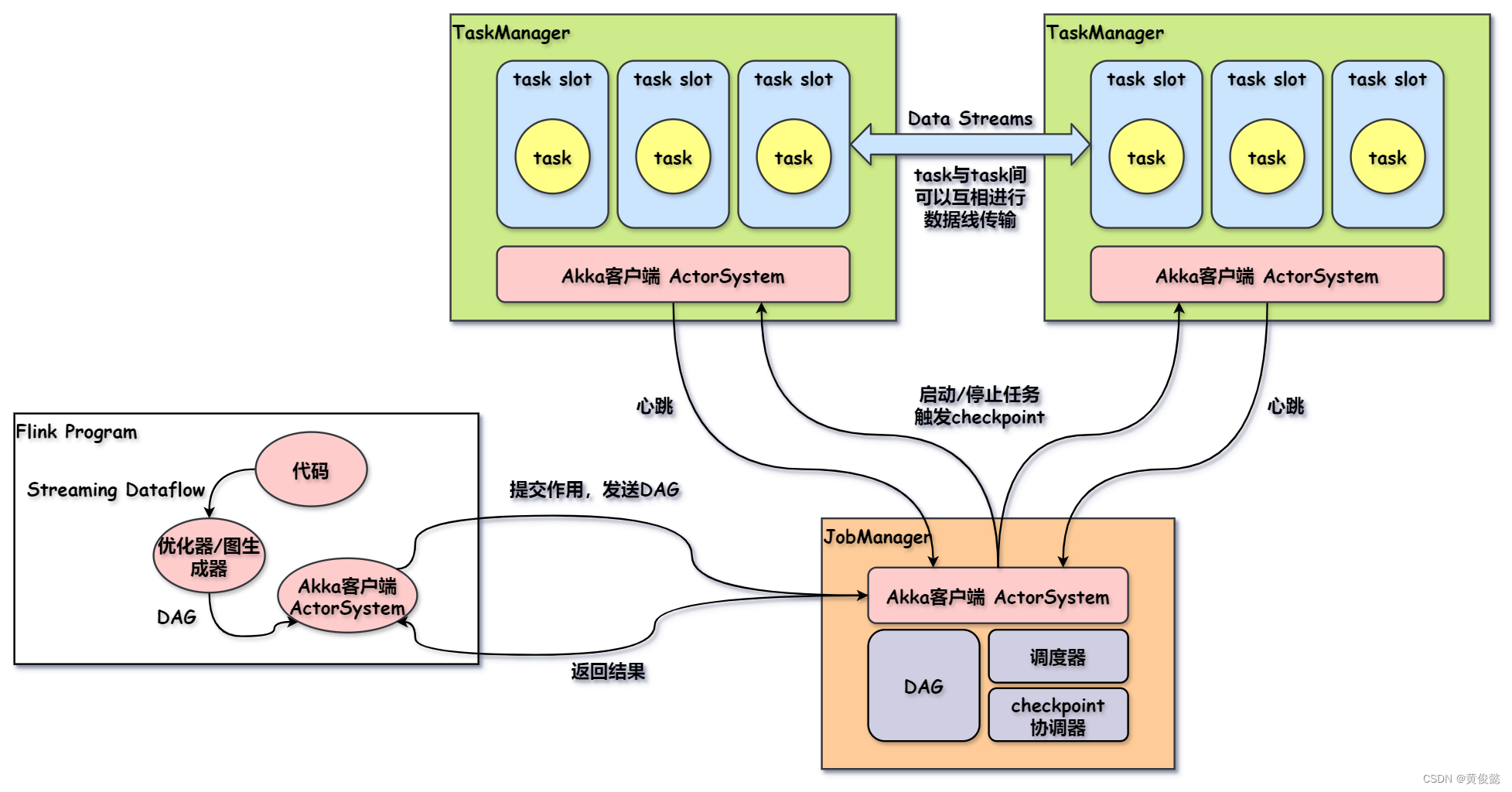
- 我们的代码会被Flink解析成一个DAG图,当我们调用env.execute()方法后,该DAG图就会被打包通过Akka客户端发送到JobManager。
- JobManager会通过调度器,把task调度到TaskManager上执行。
- TaskManager接收到task后,task将会在一个task slot中执行。
task slot 和 task
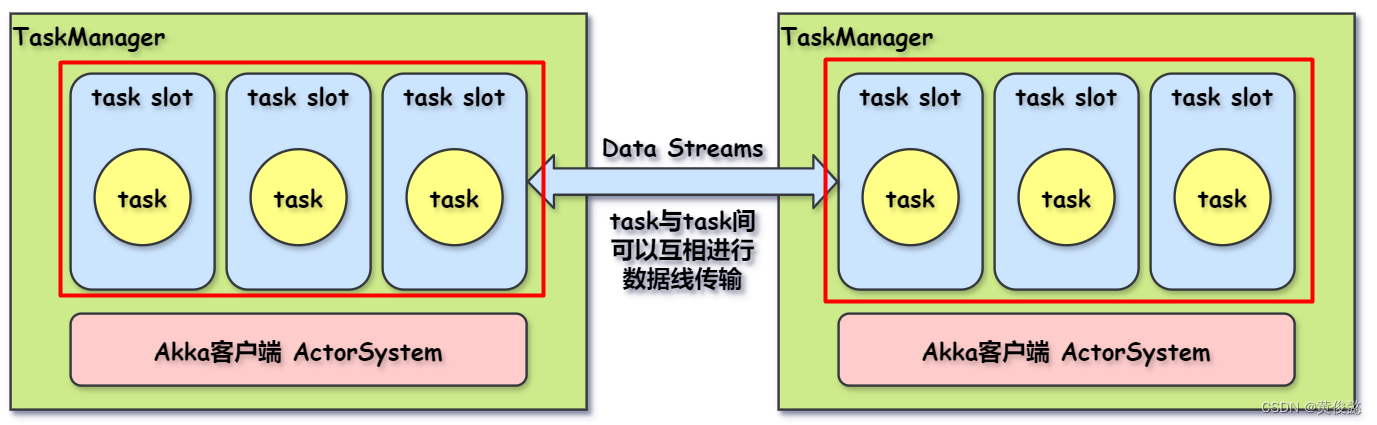
我们看到在TaskManager上有一个个的task slot被划分出来,task slot的数量是在TaskManager创建之初就设置好的。每个task(正确来说应该是subtask)都会调度到一个task slot上执行。task slot的作用主要是进行内存隔离,比如TaskManager设置了3个task slot的数量,那么每个task slot占用TaskManager三分之一的内存,task在task slot执行时,task与task之间将不会有内存资源竞争的情况发生。
EventTime、Windows、Watermarks
由于Flink处理的是流式计算,数据是以流的形式源源不断的流过来的,也就是说数据是没有边界的,但是对数据的计算必须在一个范围内进行,比如实时统计高速公路过去一个小时里的车流量。

那么就需要给源源不断流过来的数据划分边界,我们可以根据时间段或数据量来划分边界。
如果要按照时间段来划分边界,那么是通过时间字段进行划分。
EventTime

Flink有三种类型的时间:
- Event Time
- Ingestion Time
- Processing Time
一般用的较多的时Event Time,因为Event Time是固定不变的,不管什么时候计算,都会得到相同的输出结果。
Windows
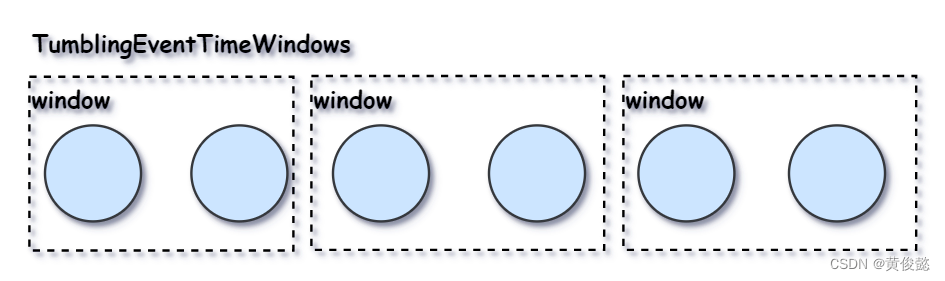
有了时间字段后,就可以根据时间划分时间窗,比如下面就是划分1分钟为一个时间窗,然后就可以对时间窗内的数据做计算。
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
TumblingEventTimeWindows是滚动时间窗:
还有SlidingEventTimeWindows滑动时间窗:
// 没10秒计算前1分钟窗口内的数据
.window(SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10)))
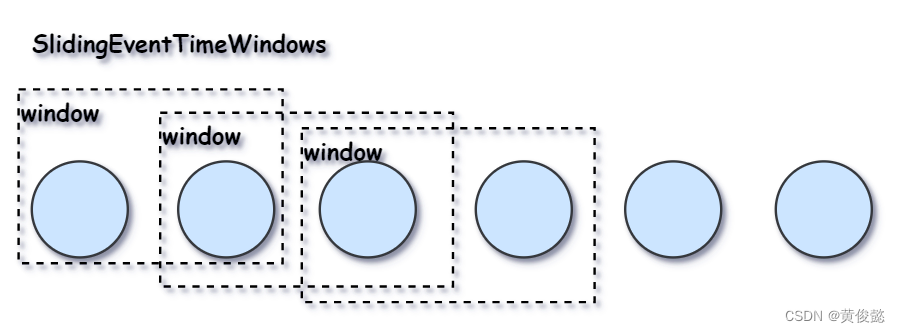
以及EventTimeSessionWindows会话时间窗:
// 间隔超过5s的话,下一达到的事件在新的窗口内计算,否则在同一窗口内计算
.window(EventTimeSessionWindows.withGap(Time.seconds(5)))上面设置的会话时间窗表示如果两个事件间的间隔超过5秒,那么后一个事件就会在新的窗口中计算;如果两个事件间隔没有超过5秒,那么就在同一窗口内计算。
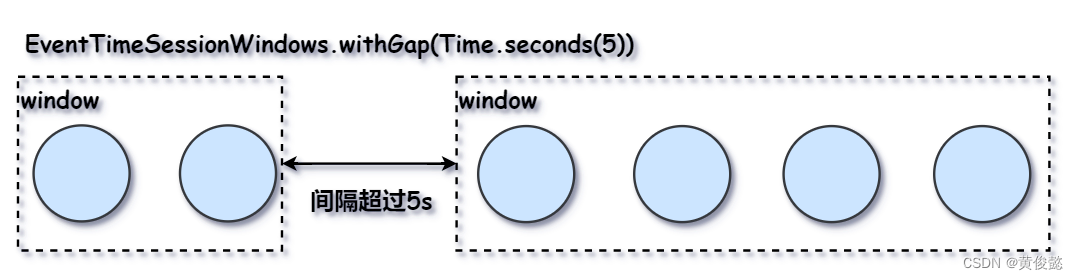
Watermarks
但是事件流并不一定是有序的,它有可能是无序,有可能早发生的事件反而比晚发生的事件更晚到达。这时Flink需要等待较早发生的事件都到达了,才能进行一个时间窗的计算。
但是Flink无法得知什么时候边界内的所有事件都达到,因此必须有一种机制控制Flink什么时候停止等待。
这时候就要使用watermarks ,Flink接收到每一条数据时,会使用watermark生成器根据EventTime计算出一个watermark然后插入到数据中。当我们设置watermark的延迟时长是t时,那么watermark就等于当前所有达到数据中的EventTime中的最大值(maxEventTime)减去时间t,代表EventTime在 maxEventTime - t 之前的数据都已达到,结束时间为 maxEventTime - t 的时间窗可以进行计算。
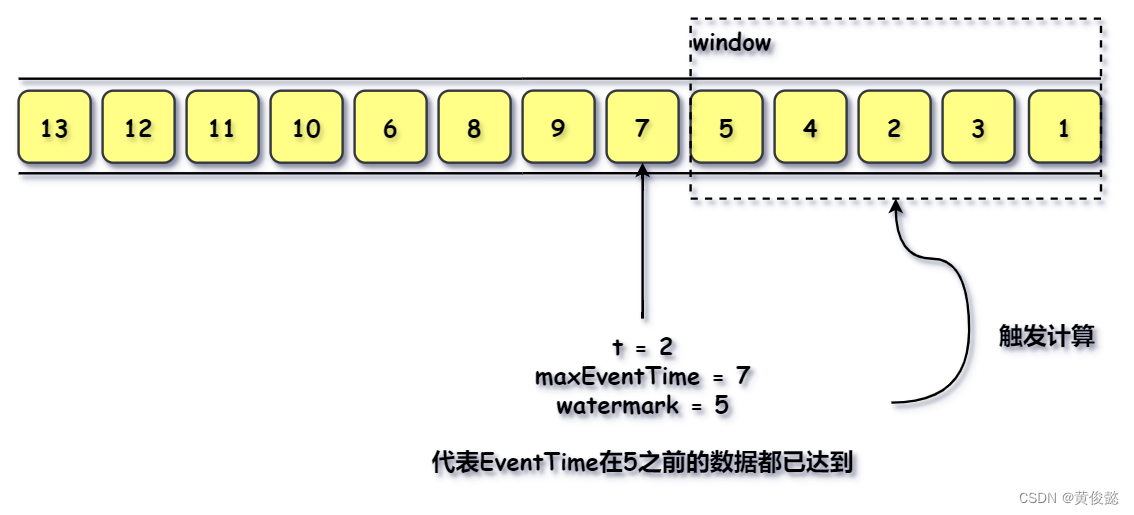
比如上面的例子,我们设置wartemark的延时时间t为2,那么当EventTime为7的事件到达时,该事件的watermark就是5(maxEventTime = 7, t = 2, watermark = maxEventTime - t = 7 - 2 = 5),那么表示Flink认定EventTime在5或5之前的时间都已经达到了,那么如果有一个窗口的结束时间为5的话,该窗口就会触发计算。
watermarks的使用:
DataStream<Event> stream = ...;WatermarkStrategy<Event> strategy = WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(20)).withTimestampAssigner((event, timestamp) -> event.timestamp);DataStream<Event> withTimestampsAndWatermarks =stream.assignTimestampsAndWatermarks(strategy);
当然,使用了watermarks之后,也不一定就能保证百分之一百准确。当我们把延时时间t设置的较短时,就能获取更低的延迟,但是准确性也相对下降;而如果我们把t设的较大,那么延迟就更大,但是准确性就想对较高。
相关文章:
【图解大数据技术】流式计算:Spark Streaming、Flink
【图解大数据技术】流式计算:Spark Streaming、Flink 批处理 VS 流式计算Spark StreamingFlinkFlink简介Flink入门案例Streaming Dataflow Flink架构Flink任务调度与执行task slot 和 task EventTime、Windows、WatermarksEventTimeWindowsWatermarks 批处理 VS 流式…...

启动完 kubelet 日志显示 failed to get azure cloud in GetVolumeLimits, plugin.host: 1
查看 kubelet 日志组件命令 journalctl -xefu kubelet 文字描述问题 Jul 09 07:45:17 node01 kubelet[1344]: I0709 07:45:17.410786 1344 operation_generator.go:568] MountVolume.SetUp succeeded for volume "default-token-mfzqf" (UniqueName: "ku…...
C语言基础and数据结构
C语言程序和程序设计概述 程序:可以连续执行的一条条指令的集合 开发过程:C源程序(.c文件) --> 目标程序(.obj二进制文件,目标文件) --> 可执行文件(.exe文件) -->结果 在任何机器上可以运行C源程序生成的 .exe 文件 没有安装C语言集成开发环境,不能编译C语言程…...

【超万卡GPU集群关键技术深度分析 2024】_构建10万卡gpu集群的技术挑战
文末有福利! 1. 集群高能效计算技术 随着大模型从千亿参数的自然语言模型向万亿参数的多模态模型升级演进,超万卡集群吸需全面提升底层计算能力。 具体而言,包括增强单芯片能力、提升超节点计算能力、基于 DPU (Data Processing Unit) 实现…...

RuntimeError: CUDA error: invalid device ordinal
RuntimeError: CUDA error: invalid device ordinal 报错分析:可能原因1:设置CUDA_VISIBLE_DEVICES的问题解决办法: 可能原因2:硬件或驱动原因解决方法: 参考资料 报错分析: 如果你在运行代码时报错&#…...

如何在Qt中添加文本
在Qt中添加文本通常涉及到使用几种不同的Qt控件,具体取决于你想要在何处以及以何种方式显示文本。以下是一些常见的方法: 1. 使用QLabel显示文本 QLabel是Qt中用于显示文本或图片的简单控件。你可以通过构造函数或setText()方法设置其显示的文本。 #i…...

解决打印PDF文本不清楚的处理办法
之前打印PDF格式的电子书,不清晰,影响看书的心情,有时看到打印的书的质量,根本不想看,今天在打印一本页数不多,但PDF格式的书感觉也不太清楚,我想应该有办法解决,我使用的是解决福昕…...

【Cesium开发实战】火灾疏散功能的实现,可设置火源点、疏散路径、疏散人数
Cesium有很多很强大的功能,可以在地球上实现很多炫酷的3D效果。今天给大家分享一个可自定义的火灾疏散人群的功能。 1.话不多说,先展示 火灾疏散模拟 2.设计思路 根据项目需求要求,可设置火源点、绘制逃生路线、可设置逃生人数。所以点击火…...

imx6ull/linux应用编程学习(16)emqx ,mqtt创建连接mqtt.fx
在很多项目中都需要自己的私人服务器,以保证数据的隐私性,这里我用的是emqx。 1.进入emqx官网 EMQX:用于物联网、车联网和工业物联网的企业级 MQTT 平台 点击试用cloud 申请成功后可得:(右边的忽略) 进入…...

Debezium系列之:验证mysql、mariadb等兼容mysql协议数据库账号权限
Debezium系列之:验证mysql、mariadb等兼容mysql协议数据库账号权限 一、数据库需要开启binlog二、创建账号和账号需要赋予的权限三、账号具有权限查看日志信息四、验证账号权限五、验证账号能否执行show master status六、验证数据库是否开启binlog一、数据库需要开启binlog …...

Vue.js学习笔记(五)抽奖组件封装——转盘抽奖
基于VUE2转盘组件的开发 文章目录 基于VUE2转盘组件的开发前言一、开发步骤1.组件布局2.布局样式3.数据准备 二、最后效果总结 前言 因为之前的转盘功能是图片做的,每次活动更新都要重做UI和前端,为了解决这一问题进行动态配置转盘组件开发,…...

使用pip或conda离线下载安装包,使用pip或conda安装离线安装包
使用pip或conda离线下载安装包,使用pip或conda安装离线安装包 一、使用pip离线下载安装包1. 在有网络的机器上下载包和依赖2. 传输离线安装包 二、在目标机器上离线安装pip包三、使用conda离线下载安装包1. 在有网络的机器上下载conda包2. 传输conda包或环境包3. 在…...

产品访问分析
1、DWD产品访问明细 1.1、用户产品权限数据 --用户产品权限数据INSERT OVERWRITE TABLE temp_lms.dm_lms_platform_usergroup_app_tmpselect 仓储司南 as pro_name,CCSN as pro_code,c.user_name as user_name,d.account_name …...

【算法】代码随想录之链表(更新中)
文章目录 前言 一、移除链表元素(LeetCode--203) 前言 跟随代码随想录,学习链表相关的算法题目,记录学习过程中的tips。 一、移除链表元素(LeetCode--203) 【1】题目描述: 【2】解决思想&am…...

react 18中,使用useRef 获取其他组件的dom并操作节点,flushSync强制同步更新useState
React 不允许组件访问其他组件的 DOM 节点。甚至自己的子组件也不行!这是故意的。Refs 是一种脱围机制,应该谨慎使用。手动操作 另一个 组件的 DOM 节点会使你的代码更加脆弱。 相反,想要 暴露其 DOM 节点的组件必须选择该行为。一个组件可以…...

Jupyter Notebook基础:用IPython实现动态编程
Jupyter Notebook基础:用IPython实现动态编程 1. 引言 Jupyter Notebook是一个基于Web的交互式计算环境,允许用户创建和共享包含实时代码、方程式、可视化和文本叙述的文档。它广泛应用于数据清洗与转换、数值模拟、统计建模、机器学习以及其他数据科学…...

Python 爬虫:使用打码平台来识别各种验证码:
本课程使用的是 超级鹰 打码平台, 没有账户的请自行注册! 超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大 使用打码平台来攻破验证码难题, 是很简单容易的, 但是要钱! 案例代码及测…...

理解算法复杂度:空间复杂度详解
引言 在计算机科学中,算法复杂度是衡量算法效率的重要指标。时间复杂度和空间复杂度是算法复杂度的两个主要方面。在这篇博客中,我们将深入探讨空间复杂度,了解其定义、常见类型以及如何进行分析。空间复杂度是衡量算法在执行过程中所需内存…...

浅析Kafka Streams消息流式处理流程及原理
以下结合案例:统计消息中单词出现次数,来测试并说明kafka消息流式处理的执行流程 Maven依赖 <dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusio…...

QGroundControl的总体架构,模块化设计和主要组件的功能。
QGroundControl 总体架构详细描述 QGroundControl (QGC) 作为一个开源地面控制站软件,其设计原则是模块化、高扩展性和高可维护性。 总体架构 QGroundControl 由多个层次构成,每个层次负责不同的功能。这种分层结构确保了系统的高内聚性和低耦合性。 …...

TV Bro:解锁智能电视上网的终极遥控器浏览器方案
TV Bro:解锁智能电视上网的终极遥控器浏览器方案 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 想象一下,坐在舒适的沙发上,手握电视…...
)
从零训练潮州话语音克隆模型:ElevenLabs Fine-tuning实战(附1782条标注语料清洗脚本)
更多请点击: https://codechina.net 第一章:从零训练潮州话语音克隆模型:ElevenLabs Fine-tuning实战(附1782条标注语料清洗脚本) 语料准备与质量校验 潮州话语音克隆对数据一致性要求极高。我们采集并人工标注了178…...
)
告别低速串口:用STM32的FSMC总线驱动FPGA,实现高速数据交换的完整流程(基于STM32F407)
STM32与FPGA的高速数据通道:基于FSMC总线的实战设计指南 在嵌入式系统开发中,数据吞吐量常常成为制约系统性能的关键瓶颈。当STM32微控制器需要与FPGA进行大数据量交互时——无论是实时图像处理、高速数据采集还是复杂算法加速——传统的串行通信接口如…...

LiveSplit终极指南:为速度跑者量身定制的精准计时神器
LiveSplit终极指南:为速度跑者量身定制的精准计时神器 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款专为速度跑者打造的轻量级、高度可定制的计…...

长期使用Taotoken Token Plan套餐对项目研发成本的控制效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐对项目研发成本的控制效果 在项目研发中,大模型API调用成本是预算管理的重要一环。对…...
)
JS 异步 从零讲(大白话 + 真实场景 + 可运行案例)
按顺序:回调函数 → Promise → async/await,工作最常用,直接上手。1. 回调函数(最原始,缺点:回调地狱)2. Promise(解决回调地狱,链式调用)new Promise((reso…...
)
别再新建空文件了!手把手教你用CodeBlocks创建可调试的C/C++工程(避坑中文路径)
别再新建空文件了!手把手教你用CodeBlocks创建可调试的C/C工程(避坑中文路径) 刚接触编程的新手常常会遇到这样的困惑:明明按照教程写好了代码,设置了断点,按下F7却毫无反应。这种挫败感往往源于一个被多数…...

Hotkey Detective:3分钟找出Windows热键冲突元凶,重获键盘控制权
Hotkey Detective:3分钟找出Windows热键冲突元凶,重获键盘控制权 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-de…...

英雄联盟Akari助手:免费开源的游戏效率工具完整指南
英雄联盟Akari助手:免费开源的游戏效率工具完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁琐的操作和…...

避开这些坑,你的蓝桥杯单片机程序也能拿高分:EEPROM存储与电压比较逻辑详解
蓝桥杯单片机高分秘籍:EEPROM存储与电压比较逻辑的深度优化 在蓝桥杯单片机竞赛中,能够完成基本功能只是及格线,真正决定成绩高低的是对细节的掌控和边界条件的处理。许多参赛者在EEPROM数据存储和复杂电压比较逻辑这两个关键环节频频失分&am…...