【CUDA】 Trust基本特性介绍及性能分析
Trust简介
Thrust 是一个实现了众多基本并行算法的 C++ 模板库,类似于 C++ 的标准模板库(standard template library, STL)。该库自动包含在 CUDA 工具箱中。这是一个模板库,仅仅由一些头文件组成。在使用该库的某个功能时,包含需要的头文件即可。该库中的所有类型与函数都在命名空间thrust中定义,所以都以thrust::开头。用命名空间的目的是避免名称冲突。例如,Thrust中的thrust::sort和STL 中的 std::sort 就不会发生名称冲突。
数据结构
Thrust 中的数据结构主要是矢量容器(vector container),类似于 STL中的std::vector。在 Thrust 中,有两种矢量:
(1)一种是存储于主机的矢量 thrust::host_vector<typename>。
(2)一种是存储于设备的矢量 thrust::device_vector<typename>。这里的 typename 可以是任何数据类型。例如,下面的语句定义了一个设备矢量x,元素类型为双精度浮点数(全部初始化为0),长度为10:
thrust::device_vector<double>x(10,0);
要使用这两种矢量,需要分别包含如下头文件:
#incldue <thrust/host vector.h>
#incldue <thrust/device vector.h>
算法
Thrust 提供了5类常用算法,包括
(1)变换(transformation)。
(2)归约(reduction)。
(3)前缀和(prefxsum)。
(4)排序(sorting)与搜索(searching)。
(5)选择性复制、替换、移除、分区等重排(reordering)操作。
除了 thrust::copy,Thrust 算法的参数必须都来自于主机矢量或都来自于设备矢量。否则,编译器会报错。
实例分析
在了解 Thrust 库更多的细节之前,我们先分析Code1所示的程序,这个程序展示了Thrust库的一些显著特点。
Code1
#include <iostream>
#include <cstdio>
#include <ctime>
#include <cmath>#include <cuda_runtime.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/generate.h>
#include <thrust/sort.h>
#include <cstdlib>int main()
{thrust::host_vector<int> h_vec(1 << 24);thrust::device_vector<int> d_vec = h_vec;thrust::generate(h_vec.begin(), h_vec.end(), rand);thrust::sort(d_vec.begin(), d_vec.end());thrust::copy(d_vec.begin(), d_vec.end(), h_vec.begin());return 0;
}
Code1分配了两个向量容器:host_vector与 device_vector。host_vector位于主机端,device_vector位于GPU设备端。Thrust 的向量容器与C++ STL中的向量容器类似,host_vector与 device_vector 是通用的容器(即可以存储任何数据类型),可以动态调整大小。如Code1所示,容器可以自动分配和释放内存空间并且简化主机端和设备端之间的数据交换。
程序在向量容器上执行时,使用了generate、sort和copy算法。采用了STL中的迭代器进行遍历。在这个例子中,迭代器h_vec.beginO和h_vec.end()分别指向容器的第一个元素和最后一个元素的后一个位置(与STL一致左闭右开)。通过计算h_vec.end() – h_vec.beginO,我们可以得到容器的大小。
注意,在执行排序算法的时候,Thrust 会建议启动一个或多个CUDA kernel,但编程人员并不需要进行相关配置,因为Thrust的接口已经将这些细节抽象化了。对于性能敏感变量(比如 Thrust 库的网格和块大小)的选择,内存管理的细节,甚至排序算法的选择都留给具体实现的人自行决定。
迭代器和内存空间
虽然向量迭代器类似于数组的指针,但它们还包含了一些额外的信息。注意,我们不需要指定在 device_vector 元素上操作的sort算法,也不用暗示复制操作是从设备内存端到主机内存端。在Thrust库中,每个范围的内存空间可以通过迭代器参数自动推断,并调度合适的算法进行执行。
另外,关于内存空间,Thrust 的迭代器对大量信息进行隐式编码,这些信息可以用来指导进程调度。比如,Code1中sort的例子,它对基本的整型数据类型进行比较操作。在这个例子中,Thrust库中采用高度优化的基数排序(radix sort)算法,要比基于数据之间比较的排序算法(例如归并排序算法速度快很多。需要注意的是,这个调度过程并不会造成性能或存储开销:迭代器对元数据编码只存在于编译阶段并且它的调度策略已经确定。实际上,Thrust的静态调度策略可以利用迭代器类型的任何信息。
互操作性
Thrust库完全由CUDA C/C++实现,并且保持了与CUDA 生态系统其余部分的互操作性。互操作性是一个重要特性,因为没有一个单一的语言或库能够很好地解决所有问题。例如,尽管Thrust 算法在内部使用了像共享存储器的CUDA特性,但是并没有为用户提供机制通过 Thrust库直接使用共享存储器。因此,有时候应用程序需要直接访问CUDAC,实现一些特定的算法。Thrust和CUDA C之间的互操作性允许程序员只修改少量外围代码,就能用CUDA kerel函数替换Thrust kerel函数,反之亦然。
将Thrust转换成CUDA C很简单,类似于用标准C代码使用C++STL。外部库通过从向量中抽取“原始”指针,可以访问驻留在Thrust容器中的数据。Code2中的代码示例说明了使用原始指针转换,得到指向device_vector内容的整型指针。
Code2
//Thrust 与 CUDA C/C++的互操作//Thrust dev To CUDA kernel
thrust::device_vector<int> d_vec(1 << 24);thrust::device_vector<int> dev_Y;reduction1<int> << <gridDim, threads, threads.x * sizeof(double) >> > (thrust::raw_pointer_cast(d_vec.data()),temp,thrust::raw_pointer_cast(dev_Y.data()));//CUDA dev To Thrust devint* h_test = (int*)malloc((1 << 24) * sizeof(int));int* d_test;cudaMemcpy(d_test, h_test, (1 << 24) * sizeof(int),cudaMemcpyHostToDevice)thrust::device_ptr<int> dev_ptr = thrust::device_pointer_cast(d_test);thrust::sort(dev_ptr, dev_ptr + (1 << 24));在Code2中,函数raw_pointer_cast()接受设备向量d_vec的元素0的地址(.data()与STL类似)作为参数,并且返回原始C指针raw_ptr。这个指针可用于调用CUDA C API函数(如cudaMemset()函数),或者作为参数传递到CUDA C kerel函数中(reduction1函数)。
将 Thrust 算法应用到原始C指针也很简单。一旦原始指针经过 device_ptr 的包装,它便能作为普通的 Thrust迭代器。
Code2中,C指针raw_ptr 指向设备内存中由函数cudaMalloc()分配的一片内存。通过 device_pointer_cast()函数,它可以转换为指向设备向量的设备指针。转换后的指针提供了一些内存空间信息,以便Thrust库调用适当的算法实现,并且为从主机端访问设备存储器提供了方便的机制。在这个例子中,这些信息指明dev_ptr指向设备内存中的向量并且元素类型是整型。
Thrust的原生CUDA C的互操作性保证Thrust总是能作为CUDA C的很好补充,Thrust和CUDA C的结合使用通常比单独使用CUDA C或者Thrust效果好。事实上,即使能够完全使用 Thrust 函数编写完整的并行程序,但是在某些特定领域内直接使用CUDA C实现函数功能会取得更好的结果。原生CUDA C的抽象层次允许程序员能够细粒度地控制计算资源到特定问题的精确映射。在这个层次上编程给开发者提供了实现特定算法的灵活性。互操作性也有利于迭代开发策略:(1)使用Thrust库快速开发出并行应用的原型:(2)确定程序热点;(3)使用CUDA C实现特定算法并作必要优化。
Thrust性能分析
Code
耗时测试代码
#include <iostream>
#include <cstdio>
#include <ctime>
#include <cmath>#include <cuda_runtime.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/generate.h>
#include <thrust/sort.h>
#include <cstdlib>#include "helper_cuda.h"
#include "error.cuh"using namespace std;const int FORTIME = 50;template<typename T> __global__
void reduction1(T* X, uint32_t n, T* Y) {extern __shared__ uint8_t shared_mem[];T* partial_sum = reinterpret_cast<T*>(shared_mem);uint32_t tx = threadIdx.x;uint32_t i = blockIdx.x * blockDim.x + threadIdx.x;partial_sum[tx] = i < n ? X[i] : 0;__syncthreads();for (uint32_t stride = 1; stride < blockDim.x; stride <<= 1) {if (tx % (2 * stride) == 0)partial_sum[tx] += tx + stride < n ? partial_sum[tx + stride] : 0;__syncthreads();}if (tx == 0) Y[blockIdx.x] = partial_sum[0];
}template<typename T>
void rand_array(T* array, size_t len) {for (int i = 0; i < len; ++i) {array[i] = ((T)rand()) / RAND_MAX;}
}int main(int argc, char* argv[])
{thrust::host_vector<int> h_vec(1 << 24);cout <<"Test Mem :\t" << (1 << 24) * sizeof(int) / 1024 / 1024 << "MB" << endl;thrust::host_vector<int> h_vec1(5);thrust::generate(h_vec1.begin(), h_vec1.end(), rand);h_vec1[0] = 0;h_vec1[4] = 4;cout << "h_vec1[4] = \t" << h_vec1[4] << endl << "h_vec1.end() - 1 = \t" << *(h_vec1.end() - 1) << endl;thrust::generate(h_vec.begin(), h_vec.end(), rand);thrust::device_vector<int> d_vec(1 << 24);cudaEvent_t start, stop;float elapsed_time;checkCudaErrors(cudaEventCreate(&start));checkCudaErrors(cudaEventCreate(&stop));checkCudaErrors(cudaEventRecord(start));for (int i = 0; i < FORTIME; i++)d_vec = h_vec;checkCudaErrors(cudaEventRecord(stop));checkCudaErrors(cudaEventSynchronize(stop));checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));std::cout << "thrust HostToDevice elapsed_time:" << elapsed_time / FORTIME << std::endl;thrust::sort(d_vec.begin(), d_vec.end());checkCudaErrors(cudaEventRecord(start));for (int i = 0; i < FORTIME; i++)thrust::copy(d_vec.begin(), d_vec.end(), h_vec.begin());checkCudaErrors(cudaEventRecord(stop));checkCudaErrors(cudaEventSynchronize(stop));checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));std::cout << "thrust Copy DeviceToHost elapsed_time:" << elapsed_time / FORTIME << std::endl;checkCudaErrors(cudaEventRecord(start));for (int i = 0; i < FORTIME; i++)h_vec = d_vec;checkCudaErrors(cudaEventRecord(stop));checkCudaErrors(cudaEventSynchronize(stop));checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));std::cout << "thrust DeviceToHost elapsed_time:" << elapsed_time / FORTIME << std::endl;//-------------------------------------------------------int* h_test = (int*)malloc((1 << 24) * sizeof(int));int* d_test;if (h_test == nullptr)return -1;rand_array(h_test, 1 << 24);checkCudaErrors(cudaMalloc((void**)&d_test, (1 << 24) * sizeof(int) ));checkCudaErrors(cudaEventRecord(start));for (int i = 0; i < FORTIME; i++)checkCudaErrors(cudaMemcpy(d_test, h_test, (1 << 24) * sizeof(int),cudaMemcpyHostToDevice));checkCudaErrors(cudaEventRecord(stop));checkCudaErrors(cudaEventSynchronize(stop));checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));std::cout << "cudaMemcpy HostToDevice elapsed_time:" << elapsed_time / FORTIME << std::endl;checkCudaErrors(cudaEventRecord(start));for (int i = 0; i < FORTIME; i++)checkCudaErrors(cudaMemcpy(h_test, d_test, (1 << 24) * sizeof(int), cudaMemcpyDeviceToHost));checkCudaErrors(cudaEventRecord(stop));checkCudaErrors(cudaEventSynchronize(stop));checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));std::cout << "cudaMemcpy DeviceToHost elapsed_time:" << elapsed_time / FORTIME << std::endl;//Thrust 与 CUDA C/C++的互操作thrust::device_ptr<int> dev_ptr = thrust::device_pointer_cast(d_test);thrust::sort(dev_ptr, dev_ptr + (1 << 24));thrust::device_vector<int> dev_Y;dim3 threads(1024);dim3 gridDim;uint32_t temp = 1 << 24; int sumTime = 0;do {gridDim = dim3((temp + threads.x - 1) / threads.x);d_vec = dev_Y;dev_Y.resize(gridDim.x);checkCudaErrors(cudaEventRecord(start));reduction1<int> << <gridDim, threads, threads.x * sizeof(double) >> > (thrust::raw_pointer_cast(d_vec.data()),temp,thrust::raw_pointer_cast(dev_Y.data()));checkCudaErrors(cudaEventRecord(stop));checkCudaErrors(cudaEventSynchronize(stop));checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));sumTime += elapsed_time;temp = gridDim.x;} while (temp > 1);free(h_test);cudaFree(d_test);return 0;
}
具体代码参考Code
可见Thrust的HostToDev、DevToHost和copy()耗时与CUDA C相似。
Reduction函数耗时分析:

Thrust虽然方便但是相对于固定优化的CUDA C耗时更长。其它Reduction函数请参考:【CUDA】 归约 Reduction
参考文献:
1、大规模并行处理器编程实战(第2版)
2、CUDA C 编程:基础与实践
相关文章:
【CUDA】 Trust基本特性介绍及性能分析
Trust简介 Thrust 是一个实现了众多基本并行算法的 C 模板库,类似于 C 的标准模板库(standard template library, STL)。该库自动包含在 CUDA 工具箱中。这是一个模板库,仅仅由一些头文件组成。在使用该库的某个功能时,包含需要的头文件即可。该库中的所有类型与函数都在命名空…...

颈肩肌筋膜炎中医治疗
颈肩肌筋膜炎,又称颈肩肌纤维织炎或肌肉风湿症,是一种涉及筋膜、肌肉、肌腱和韧带等软组织的无菌性炎症。以下将分别从症状和治疗两方面进行详细介绍。 一、颈肩肌筋膜炎的症状 颈肩肌筋膜炎的主要症状包括: 1、肩背部疼痛:患者…...

Java 通配符 在短信发送之中 通配符参数动态获取解决方案
目录 1、通配符应用场景 2、实现方案分析 2.1、可能针对不同模板中核定参数硬编码到程序之中写死 2.2、通配置模板之中动态获得对应的参数 3、通过正则表达式验证与替换参数${}参考示例 4、参考文章 1、通配符应用场景 我们在使用通配符场景,主要是应用于短信…...

Mybatis-Plus中LambdaQueryWrapper
基本用法 import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper; // 假设有一个 User 实体类 LambdaQueryWrapper<User> queryWrapper new LambdaQueryWrapper<>(); // 添加查询条件 queryWrapper.eq(User::getName, "John&quo…...

C++ 入门05:类和对象
往期回顾: C 入门02:控制结构和循环-CSDN博客C 入门03:函数与作用域-CSDN博客C 入门04:数组与字符串-CSDN博客 一、前言 在前面文章的学习中,我们了解了 C 的基本结构、变量、输入输出、控制结构、循环、函数、作用域…...

4G LTE教程
整体架构 物理层(第 1 层) 物理层通过空中接口传输来自 MAC 传输信道的所有信息。负责 RRC 层的链路自适应 (AMC)、功率控制、小区搜索(用于初始同步和切换目的)和其他测量(LTE 系统内部和系统之间)。 介…...

C++:哈希表
哈希表概念 哈希表可以简单理解为:把数据转化为数组的下标,然后用数组的下标对应的值来表示这个数据。如果我们想要搜索这个数据,直接计算出这个数据的下标,然后就可以直接访问数组对应的位置,所以可以用O(1)的复杂度…...

自己动手写一个滑动验证码组件(后端为Spring Boot项目)
近期参加的项目,主管丢给我一个任务,说要支持滑动验证码。我身为50岁的软件攻城狮,当时正背着双手,好像一个受训的保安似的,中规中矩地参加每日站会,心想滑动验证码在今时今日已经是标配了,司空…...

keepalive脑裂
keepalive脑裂 调度器的高可用 vip地址主备之间的切换,主在工作时,p地址只在主上,主停止工作,ip飘移到备服务器。 在主备的优先级不变的情况下,主恢复工作,vip会飘回到主服务器。 1、配优先级 2、配置…...

STM32Cubemx配置生成 Keil AC6支持代码
文章目录 一、前言二、AC 6配置2.1 ARM ComPiler 选择AC62.2 AC6 UTF-8的编译命令会报错 三、STM32Cubemx 配置3.1 找到stm32cubemx的模板位置3.2 替换文件内核文件3.3 修改 cmsis_os.c文件3.4 修改本地 四、编译对比 一、前言 使用keil ARM compiler V5的时候,编译…...

Perl基础入门指南:从零开始掌握Perl编程
Perl是一种功能强大且灵活的编程语言,广泛应用于系统管理、Web开发、网络编程和文本处理等领域。如果你是编程新手或者想学习一种新的编程语言,Perl是一个不错的选择。本文将带你了解Perl的基础知识,并通过简单的示例代码帮助你快速入门。 什…...

Mybatis SQL注解使用场景
MyBatis 提供了几种常用的注解,主要用于简化 XML 映射文件的编写,使得 SQL 查询和操作可以直接在 Java 接口中定义。下面列出了主要的注解以及它们在被调用时的写法示例: 1. Select Select 注解用于执行查询操作,并将查询结果映…...

Dataset for Stable Diffusion
1.Dataset for Stable Diffusion 笔记来源: 1.Flickr8k数据集处理 2.处理Flickr8k数据集 3.Github:pytorch-stable-diffusion 4.Flickr 8k Dataset 5.dataset_flickr8k.json 1.1 Dataset 采用Flicker8k数据集,该数据集有两个文件ÿ…...

近期matlab学习笔记,学习是一个记录,反复的过程
近期matlab学习笔记,学习是一个记录,反复的过程 matlab的mlx文件在运行的时候,不需要在文件夹路径下,也能运行,但是需要调用子函数时,就需要在文件所在路径下运行 那就先运行子函数,把路径换过来…...

Elasticsearch7.5.2 常用rest api与elasticsearch库
目录 一、rest api 1. 新建索引 2. 删除索引 3. 插入单条数据 4. 更新单条数据 5. 删除单条数据 6. 查询数据 二、python elasticsearch库 1. 新建索引 一、rest api 1. 新建索引 请求方式:PUT 请求URL:http://ip/(your_index_nam…...
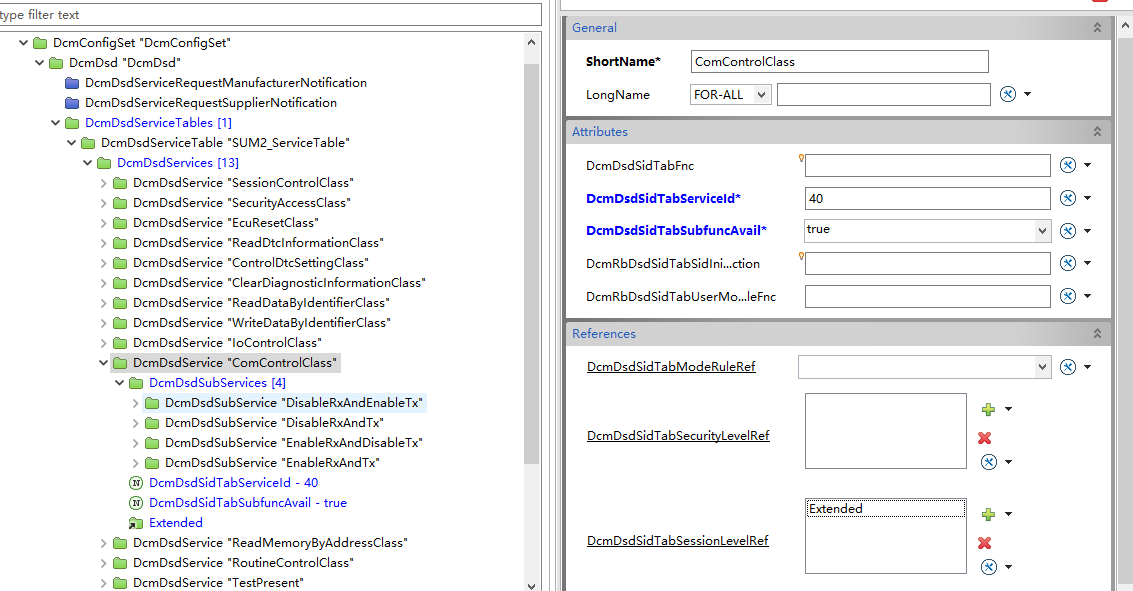
Autosar Dcm配置-0x28服务ComControl-基于ETAS软件
文章目录 前言DcmDcmDsdDcmDspBswMBswMModeRequestPortBswMModeConditionBswMLogicalExpressionBswMActionBswMActionListBswMRule总结前言 0x28服务主要用来控制非诊断报文的通讯,一般在刷写预编程过程中,用来禁止APP的通信报文,可以减少总线负载率,提高刷写成功率。本文…...

平安养老险厦门分公司:提升金融服务,发挥金融力量
为向社会公众普及金融保险知识,传递消费者权益保护理念,平安养老保险股份有限公司厦门分公司(以下简称“分公司”)积极开展“78保险公众宣传日”系列教育宣传活动。分公司紧扣“保险,让每一步前行更有底气”主题&#…...
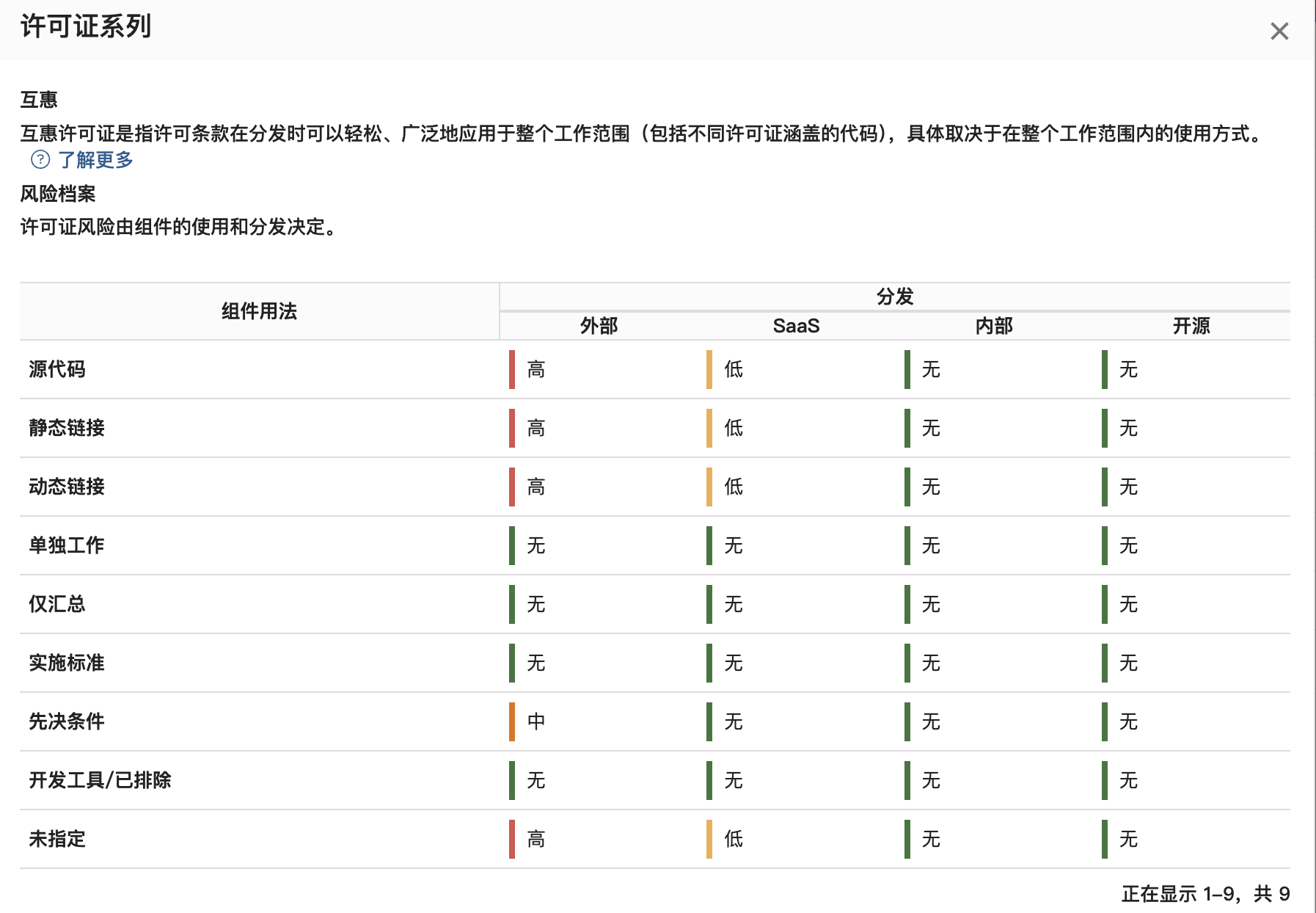
【开源合规】开源许可证风险场景详细解读
文章目录 前言关于BlackDuck许可证风险对比图弱互惠型许可证举个例子具体示例LGPL系列LGPL-2.0-onlyLGPL-2.0-or-laterLGPL-2.1-onlyLGPL-2.1-or-laterLGPL-3.0-onlyLGPL-3.0-or-laterMPL系列MPL-1.0MPL-1.1MPL-2.0EPL系列EPL-1.0EPL-2.0互惠型许可证GPL系列GPL-1.0GPL-2.0GPL-…...
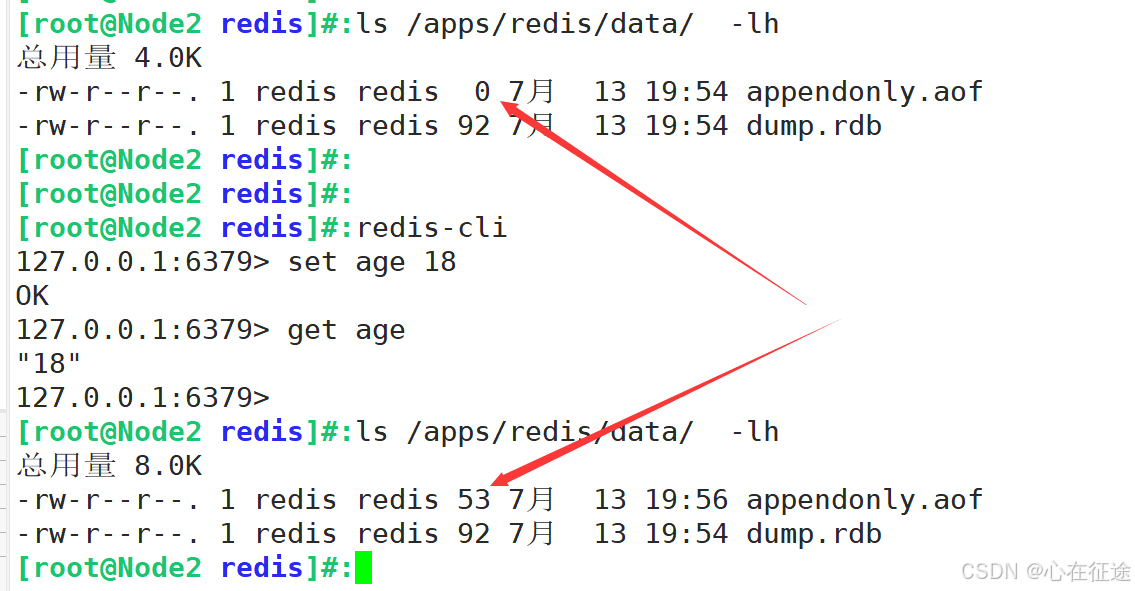
Redis持久化RDB,AOF
目 录 CONFIG动态修改配置 慢查询 持久化 在上一篇主要对redis的了解入门,安装,以及基础配置,多实例的实现:redis的安装看我上一篇: Redis安装部署与使用,多实例 redis是挡在MySQL前面的,运行在内存…...
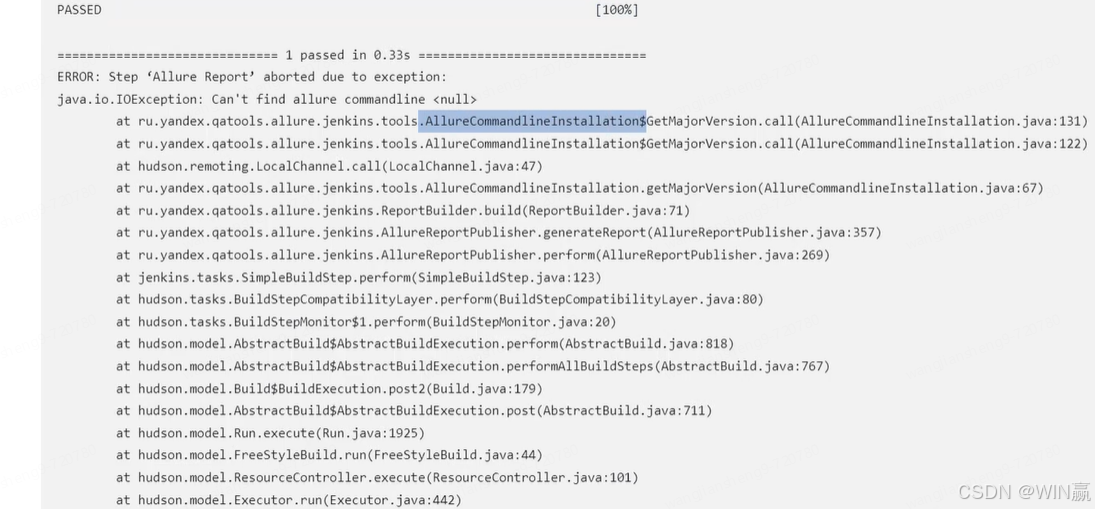
【持续集成_03课_Linux部署Sonar+Gogs+Jenkins】
一、通过虚拟机搭建Linux环境-CnetOS 1、安装virtualbox,和Vmware是一样的,只是box更轻量级 1)需要注意内存选择,4G 2、启动完成后,需要获取服务器IP地址 命令 ip add 服务器IP地址 通过本地的工具,进…...

阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月
阿波罗登月,不可能:读心术与影子叙事 ——不是向全世界展示登月,而是向全世界注射登月 Jianbing Zhu 1^{1}1 1^{1}1 ECT-OS-JiuHuaShan 文明实验室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20373157 Email: ect-os-jiuhuashanzoho…...

LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 [特殊字符]
LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 🎯 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为复盘找不到关键点而烦恼吗?想提升棋力却…...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...

基于CNN的食双星光变曲线自动化参数初估模型EBOP MAVEN
1. 项目概述与核心价值在恒星天体物理领域,食双星系统一直扮演着“宇宙实验室”的关键角色。通过分析两颗恒星相互绕转时周期性相互遮挡产生的光变曲线,我们可以像解谜一样,精确反演出恒星的质量、半径、轨道倾角等基本物理参数。这些参数是构…...

使用libusb-win32驱动复活老旧USB硬件:以Elektor Magic Eye为例
1. 项目概述:让老硬件在新时代焕发新生手头有一台十多年前的《Elektor》杂志上刊登的“Magic Eye EM84”复古VFD显示屏项目,想把它接到Windows 10电脑上当个酷炫的CPU占用率显示器,却发现官方提供的“AVR309”USB驱动在新系统上彻底罢工了。这…...

Windows键盘重映射终极指南:如何使用SharpKeys专业解决方案告别误触烦恼
Windows键盘重映射终极指南:如何使用SharpKeys专业解决方案告别误触烦恼 【免费下载链接】sharpkeys SharpKeys is a utility that manages a Registry key that allows Windows to remap one key to any other key. 项目地址: https://gitcode.com/gh_mirrors/sh…...

为什么选择Espresso?5大优势让快递管理变得前所未有的简单[特殊字符]
为什么选择Espresso?5大优势让快递管理变得前所未有的简单🚀 【免费下载链接】Espresso 🚚 Espresso is an express delivery tracking app designed with Material Design style, built on MVP(Model-View-Presenter) architecture with RxJ…...

如何免费激活VMware Workstation Pro 17:完整密钥获取与安装指南
如何免费激活VMware Workstation Pro 17:完整密钥获取与安装指南 【免费下载链接】VMware-Workstation-Pro-17-Licence-Keys Free VMware Workstation Pro 17 full license keys. Weve meticulously organized thousands of keys, catering to all major versions o…...

从红宝石到光纤:固体激光器家族里,谁才是工业加工界的‘六边形战士’?
从红宝石到光纤:固体激光器家族里,谁才是工业加工界的‘六边形战士’? 在金属切割车间里,激光束正以毫米级精度划过不锈钢板;精密电子产线上,纳米级激光打标机为电路板刻印追溯码;汽车焊接工段…...