算法-二叉树常见问题详解
文章目录
- 1. 二叉树的三种遍历方式的实质
- 2. 二叉树的序列化与反序列化
- 3. 根据前序中序反序列创建二叉树
- 4. 二叉树的路径问题
- 5. LCA公共祖先问题
- 6. 二叉搜索树的LCA问题
- 7. 验证搜索二叉树
- 8. 修建搜索二叉树
- 9. 二叉树打家劫舍问题
1. 二叉树的三种遍历方式的实质
这个相信大家都不会陌生, 但是大家学习这个知识点的时候, 往往并不会在意这三种遍历的顺序到底有什么意义(一般都只会打印一下值即可), 而且对这个是怎么来的也不是很清晰, 下面我们通过代码的注释仔细解释一下
public static void dfs(TreeNode node){//递归的终止条件(其实也就是深度优先搜索)//即当递归(其实也就是搜索到空节点的时候, 就直接结束(返回),但是该函数无返回信息)if(node == null){return;}//下面是第一次来到该节点的时机(对应直接对节点进行操作,前序)System.out.println(node.val);//往左子树搜索dfs(node.left);//下面是第二次来到该节点的时机(左子树搜索完毕之后进行操作,中序)System.out.println(node.val);//往右子树搜索dfs(node.right);//下面是第三次来到该节点的时机(左右子树都搜索完毕进行操作,后序)System.out.println(node.val);}
我们现在创建一颗树, 树的结构是[1,2,3,4,null], 看一下上面的代码的结果
public static void main(String[] args) {TreeNode node1 = new TreeNode(1);TreeNode node2 = new TreeNode(2);TreeNode node3 = new TreeNode(3);TreeNode node4 = new TreeNode(4);node1.left = node2;node1.right = node3;node2.left = node4;dfs(node1);}运行结果是 1 2 4 4 4 2 2 1 3 3 3 1
我们仔细研究一下上面的打印结果
把每一个数字
第一次出现的结果提取出来也就是
1 2 4 3(前序)
第二次出现的结果提取出来也就是
4 2 1 3(中序)
第三次出现的结果提取出来也就是
4 2 3 1(后序)
上述的结果其实正式对应二叉树中的递归序
也就是几大遍历顺序的实质
下面我们做题的时候要时刻分析我们的遍历顺序!
2. 二叉树的序列化与反序列化
对于一个树状存储的数据来说我们需要将其序列化转换为文本文件(字符串)便于存储与传输,然后在通过反序列化的方式将其还原出来, 值得一提的是, 反序列化只能操作前序或者后序或者层序的字符串,而不能操作中序的字符串, 原因是中序的字符串是不唯一的,比如下面这一行代码
public static void main(String[] args) {//第一棵树TreeNode node1 = new TreeNode(1);TreeNode node2 = new TreeNode(1);node1.left = node2;//第二棵树node1.right = node2;}
第一颗树的序列化结果是 " # 1 # 1 # "
第二棵树的序列化结果也是 " # 1 # 1 # "
但是二者不是同一棵树, 所以中序的序列化是有问题的
首先展示的我们序列化的代码(前序举例子)
//创建一个拼接字符的static StringBuilder sp = new StringBuilder();//序列化的过程其实就是前序遍历输出结果的时候进行拼接即可public static String creatStringUsePreOrder(TreeNode node){//递归终止条件if(node == null){sp.append("#,");return sp.toString();}sp.append(node.val + ",");//递归的返回值其实没有被接收(//实质上只有最高层级的结果被调用者接收了)creatStringUsePreOrder(node.left);creatStringUsePreOrder(node.right);return sp.toString();}
序列化的过程是比较简单的,其实就是前序遍历加上字符串的拼接, 那如何将字符串还原为一颗二叉树呢, 下面是我们的实现(已经用split方法去除连接的","而转化为一个String[]数组)
//定义一个下标遍历字符串(思考为什么定义到外侧)private static int index = 0;public static TreeNode creatTreeUsePreString(String[] s){//递归终止条件if(s[index++].equals("#")){return null;}//递归创建二叉树//(前序遍历的方案, 树的连接其实是从底部连接的, 逐级返回)TreeNode root = new TreeNode(Integer.parseInt(s[index++]));root.left = creatTreeUsePreString(s);root.right = creatTreeUsePreString(s);return root;}
上述代码我们从递归的角度解释, 该函数的作用就是(创建一个二叉树), 那创建一颗二叉树需要创建出左子树, 也需要创建出一颗右子树, 所以出现了子问题的反复调用, 我们只需要把这个函数想象为一个"黑匣子"…
3. 根据前序中序反序列创建二叉树
其实该问题就是给我们一个两个数组(无重复数据), 一个是前序遍历的结果, 一个是中序遍历的结果, 然后让我们创建出一颗完整的二叉树, 我们这个问题给定的两个数组, 可以是前序加中序, 也可以是中序加后序, 但是不可以是前序加后序(创建不出唯一的二叉树), 例子自己想…, 比如下面这个例子
TreeNode node1 = new TreeNode(1);
TreeNode node2 = new TreeNode(2);//第一颗树
node1.left = node2;
//第二颗树
node1.right = node2
下面我们分析一下如何创建一个二叉树(前序加上中序)
假设有一个函数 func, 这个函数的功能就是创建二叉树, 那么该函数的参数应该就是(传入数据的所有信息)
> func(int[] pre,int l1,int r1,int[] in,int l2,int r2)我们假设数组的长度都是5, 那么我们创建二叉树的过程一定是从前序的结果开始的, 首先我们new出来根节点, 然后找到根节点在中序数组中所处的位置, 也就是在这个左侧就是我们的左树的部分(我们可以知道节点的规模), 右侧就是右树, 也就是说我们可以知道每一个元素在中序的位置然后控制左右边界的位置, 最终完成二叉树的创建, 由于这个过程相对抽象, 我们下面举一个例子方便大家理解
下面是我们的代码实现(用HashMap加速查询的过程)

/*** 从前序跟中序构建一颗完整的二叉树* 用的是一个封装的构建函数来构建 f(pre,l1,r1,in,l1,r1)*/public TreeNode buildTree(int[] preorder, int[] inorder) {if (preorder == null || inorder == null || preorder.length != inorder.length) return null;//构建出来一张表加快构建二叉树的过程HashMap<Integer, Integer> map = new HashMap<>();for (int i = 0; i < inorder.length; ++i) {map.put(inorder[i], i);}return creatTree(preorder, 0, preorder.length - 1, inorder, 0, inorder.length, map);}private TreeNode creatTree(int[] pre, int l1, int r1, int[] in, int l2, int r2, HashMap<Integer, Integer> map) {//递归的终止条件if (l1 > r1) {return null;}if (r1 == l1) {return new TreeNode(pre[r1]);}//借助HashMap加快查找的过程int k = map.get(pre[l1]);TreeNode node = new TreeNode(pre[l1]);node.left = creatTree(pre, l1 + 1, l1 + k - l2, in, l2, k, map);node.right = creatTree(pre, l1 + k - l2 + 1, r1, in, k + 1, r2, map);return node;}
从递归的角度来说, 创建二叉树的这个函数相当于就是一个"黑盒", 我们要相信它可以根据我们给定的参数创建出一颗完整的树, 然后我们需要去创建我们的左子树, 创建右子树(就出现了子问题复现的情况), 所以出现了递归
后序加上中序其实是同理的
4. 二叉树的路径问题
该问题涉及到回溯这一算法的概念, 其实递归的过程天然就带着回溯, 那我们为什么要用回溯呢, 是因为在该类问题当中, 我们用一个stack收集节点的时候, 如果该节点的左右深度优先搜索完毕之后, 我们需要把该节点弹出, 进行其他深度路径的搜索, 其实回溯的实际也正式我们该节点的搜索任务结束的时机, 从内存的角度来看, 也是该函数栈帧弹栈的时机
/*** 二叉树的所有路径* 1. 返回值是void类型 2. 遍历的顺序我们采用的是前序遍历的顺序* 3. 中途会进行节点的弹出其实也就是回溯的思路(回溯和递归是不分家的)*/private List<String> binaryTreePathsRes = new ArrayList<>();private ArrayDeque<Integer> stack = new ArrayDeque<>();public List<String> binaryTreePaths(TreeNode root) {binaryTreePathsFunc(root);return binaryTreePathsRes;}private void binaryTreePathsFunc(TreeNode node) {//递归的终止条件if (node == null) return;stack.add(node.val);//证明递归到了叶子节点该收获了, 不能在null节点处收获if (node.left == null && node.right == null) {StringBuilder sp = new StringBuilder();Iterator<Integer> it = stack.iterator();while (it.hasNext()) sp.append(it.next() + "->");sp.delete(sp.lastIndexOf("-"), sp.lastIndexOf(">") + 1);binaryTreePathsRes.add(sp.toString());stack.removeLast();}//下面就是深度优先搜索的过程binaryTreePathsFunc(node.left);binaryTreePathsFunc(node.right);stack.removeLast();}还有一个搜索和为targerSum的路径然后返回, 其实是一样的思路, 定义一个全局变量sum, 每次遍历到的时候进行 sum += root.val , 搜索完毕之后进行回溯操作, sum -= root.val, 思路其实是一样的
5. LCA公共祖先问题
其实就是求两个节点p,q在一颗二叉树的最近的公共祖先, 也是著名的LCA问题(该问题本身是很复杂的,我们先弄一个入门题), 我们知道, p,q对于一颗树来说, 他们可能在一支上(此时q或者是p就是最近的公共祖先), 又或者是分属于两颗不同的树, 此时树的根节点就是最近的公共祖先, 我们现在创建, 其实也就是dfs对左右子树进行深度优先搜索的思路)

其实代码是很简单的
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if(root == null || root == q || root == p){return root;}//往左边搜索TreeNode ln = lowestCommonAncestor(root.left,p,q);//往右边搜索TreeNode rn = lowestCommonAncestor(root.right,q,p);if(ln == null && rn == null) return null;if(ln != null && rn != null) return root;return ln == null ? rn : ln;}
}
其实就是一个简单的搜索的逻辑
总结一下本节, 我们递归要如何想到, 我们要把这个方法当成一个黑盒子, 然后确定返回值, 终止条件等等, 另外递归的过程其实就是深度优先搜索, 搜索和递归是不分家的, 还有搜索跟回溯是不分家的
6. 二叉搜索树的LCA问题
常规树的LCA解决之后, 二叉搜索树的LCA问题其实也被包括在里面了, 但是是否有一个更好的思路来解决二叉搜索树的最近公共祖先呢?
我们都知道, 对于二叉搜索树来说, 左侧的所侧节点都小于当前节点, 右侧都大于
所以我们可以把问题抽象为下面这个问题, 记作当前的节点为cur
cur == p || cur == q : cur就是我们要找到的祖先节点
cur > Math.max(p,q) : cur = cur.left (向左侧移动)
cur < Math.min(p,q) : cur = cur.right (向右侧移动)
Math.min(p,q) < cur < Math.max(p,q) 此时 cur就是最近公共祖先
翻译为实现代码如下
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {return p.val > q.val ? lca(root,q,p) : lca(root,p,q);}//该方法默认的p为较小的值, q为较大的值public TreeNode lca(TreeNode root,TreeNode p,TreeNode q){while(p != root && q != root){if(root.val > p.val && root.val < q.val){return root;}root = root.val > q.val ? root.left : root.right;}return root;}
}
7. 验证搜索二叉树
这个问题如何想到递归呢, 首先二叉搜索树的左子树也是一个二叉搜索树, 右子树也是一个二叉搜索树, 递归的终点其实就是叶子节点, 对于任何一个树, 左子树的最大值, 一定要小于中间节点的值, 右侧子树的最小值一定要大于中间节点的值, 而对于任意一个树, 如何找到最大最小值呢, 其实就是左子树一直向右侧扎, 右子树一直向左侧扎, 代码实现如下
class Solution {public boolean isValidBST(TreeNode root) {//递归的终止条件if(root == null) return true;if(root.left == null && root.right == null) return true;//寻找左侧最大, 右侧最小(设置一个前驱节点)TreeNode curl = root.left;TreeNode prel = null;TreeNode curr = root.right;TreeNode prer = null;while(curl != null){prel = curl;curl = curl.right;}while(curr != null){prer = curr;curr = curr.left;}if(prel == null){if(root.val >= prer.val) return false;}if(prer == null){if(root.val <= prel.val) return false;}if(prel != null && prer != null){if(root.val <= prel.val || root.val >= prer.val) return false;}return isValidBST(root.left) && isValidBST(root.right);}
}
遍历方式其实就是后续遍历, 收集到左右子树的信息然后返回
8. 修建搜索二叉树

这个题的意思就是上面描述的这样, 分析的思路如下
/*** 修剪二叉搜索树* 问题分析 : 如果当前节点的值小于左边界, 那么我们当前节点及其左边都不会被保留* 如果当前节点的值大于右边界, 那么我们当前节点及其右边都不会被保留* 如果当前节点的值介于范围内部, 那么就保留当前节点递归修建左子树跟右子树** 代码逻辑 : 我们的 "黑盒函数" 的功能是修建一颗二叉树, 并返回修剪之后的头节点* 实在不行自己画递归图去理解*/public TreeNode trimBST(TreeNode root, int low, int high) {//递归的终止条件if(root == null){return null;}if(root.val < low){return trimBST(root.right,low,high);}if(root.val > high){return trimBST(root.left,low,high);}root.left = trimBST(root.left,low,high);root.right = trimBST(root.right,low,high);return root;}9. 二叉树打家劫舍问题
这道题其实已经是树形dp了, 但是我们今天的解法大家都能听懂, 我们用递归去做这道题, 我们首先定义一个全局变量yes, 和一个全局变量no, 前者代表的含义是对一个头节点来说, 我偷了头节点的最大收益, 后者来说是我
不偷头节点的最大收益, 设置我们的当前节点的状态就是n(不偷当前节点), y(偷当前节点), 所以我们的状态转移方程就是
y += this.no;
n += Math.max(this.yes,this.no);
我们下面的func函数执行完毕之后就会更新全局的yes和no变量
class Solution {//yes的意思是偷头节点的情况下, 我们能获得的最大收益public int yes = 0;//no的意思是不偷头节点的情况下, 我们能获得的最大收益public int no = 0;public int rob(TreeNode root) {func(root);return Math.max(this.yes,this.no);}//该函数的功能就是给定一个头节点, 可以得到我们此时节点的两种最优解的情况private void func(TreeNode root){//递归终止条件if(root == null){this.yes = 0;this.no = 0;}else{int y = root.val;int n = 0;func(root.left);y += this.no;n += Math.max(this.no,this.yes);func(root.right);y += this.no;n += Math.max(this.no,this.yes);this.yes = y;this.no = n;}}
}
相关文章:
算法-二叉树常见问题详解
文章目录 1. 二叉树的三种遍历方式的实质2. 二叉树的序列化与反序列化3. 根据前序中序反序列创建二叉树4. 二叉树的路径问题5. LCA公共祖先问题6. 二叉搜索树的LCA问题7. 验证搜索二叉树8. 修建搜索二叉树9. 二叉树打家劫舍问题 1. 二叉树的三种遍历方式的实质 这个相信大家都不…...

【流媒体】 通过ffmpeg硬解码拉流RTSP并播放
简介 目前RTSP拉流是网络摄像头获取图片数据常用的方法,但通过CPU软解码的方式不仅延时高且十分占用资源,本文提供了一种从网络摄像头RTSP硬解码的拉流的方法,并且提供python代码以便从网络摄像头获取图片进行后续算法处理。 下载ffmpeg F…...

Go语言指针及不支持语法汇总
本文为Go语言中指针定义和示例及不支持语法汇总。 目录 指针 定义指针 关键字new定义 函数返回指针 空指针 Go不支持语法汇总 总结 指针 Go语言也有指针,结构体成员调用时,obj.name Go语言在使用指针时,会使用内容的垃圾回收机制&am…...

Why can‘t I access GPT-4 models via API, although GPT-3.5 models work?
题意:为什么我无法通过API访问GPT-4模型,尽管GPT-3.5模型可以工作? 问题背景: Im able to use the gpt-3.5-turbo-0301 model to access the ChatGPT API, but not any of the gpt-4 models. Here is the code I am using to tes…...
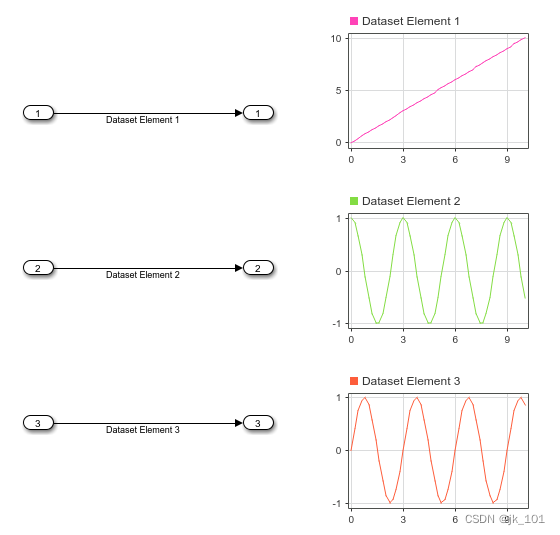
MATLAB中Simulink.SimulationData.Dataset用法
目录 语法 说明 示例 访问使用Dataset格式记录的数据 打开模型vdp 使用 Dataset 对象来组合模拟输入信号 Simulink.SimulationData.Dataset的功能是访问已记录的模拟数据或组合模拟输入数据。 语法 ds Simulink.SimulationData.Dataset ds Simulink.SimulationData.Da…...

Spring Security学习笔记(一)Spring Security架构原理
前言:本系列博客基于Spring Boot 2.6.x依赖的Spring Security5.6.x版本 Spring Security中文文档:https://springdoc.cn/spring-security/index.html 一、什么是Spring Security Spring Security是一个安全控制相关的java框架,它提供了一套全…...

nginx的access.log日志输出请求数
适用格式 #log_format main $remote_addr - $remote_user [$time_local] "$request" # $status $body_bytes_sent "$http_referer" # "$http_user_agent" "$http_x_forwarded_for"; 形如: 12…...

前端网站(三)-- 记事本【附源码】
开篇(请大家看完):此网站写给挚爱,后续页面还会慢慢更新,大家敬请期待~ ~ ~ 此前端框架,主要侧重于前端页面的视觉效果和交互体验。通过运用各种前端技术和创意,精心打造了一系列引人入胜的页面…...

java——Junit单元测试
测试分类 黑盒测试:不输入代码,给输入值,看程序能够给出期望的值。 白盒测试:写代码,关注程序具体执行流程。 JUnit单元测试 一个测试框架,供java开发人员编写单元测试。 是程序员测试,即白…...

Scala学习笔记17: Try与异常处理
目录 第十七章 Try与异常处理1- 异常的抛出和捕获1. 异常抛出2. 异常捕获 2- 函数式的错误处理1. Try 类型2. 使用 Try3. 处理 Try 结果4. Try 的常用方法5. Try 的优势总结 end 第十七章 Try与异常处理 1- 异常的抛出和捕获 Scala 的异常处理机制与 Java非常相似, 但也有一些…...

内网信息收集——MSF信息收集浏览器记录配置文件敏感信息
文章目录 一、配置文件敏感信息收集二、浏览器密码&记录三、MSF信息收集 域控:windows server 2008 域内机器:win7 攻击机:kali 就是红日靶场(一)的虚拟机。 一、配置文件敏感信息收集 使用searchall64.exe&#…...

C++ STL中的std::remove_if 的用法详解
在现代C++编程中,标准模板库(STL)提供了一系列功能强大的算法,这些算法极大地简化了日常的编程任务。其中,std::remove_if是一个非常实用的函数,它允许我们从容器中移除满足特定条件的所有元素。本文将深入探讨std::remove_if的使用方法,并通过一个具体的例子——基于St…...

基于AT89C51单片机的16×16点阵LED显示器字符滚动显示设计(含文档、源码与proteus仿真,以及系统详细介绍)
本篇文章论述的是基于AT89C51单片机的1616点阵LED显示器字符滚动显示设计的详情介绍,如果对您有帮助的话,还请关注一下哦,如果有资源方面的需要可以联系我。 目录 仿真效果图 仿真图 代码 系统论文 资源下载 设计的内容和要求 熟悉51系…...

Docker 日志丢失 - 解决方案
Docker 日志默认使用的是 journald 的方式. RateLimitBurst 是 journald 的一个参数,用于限制日志的速率。如果日志的生成速度超过这个限制,journald 可能会丢弃日志。你可以通过调整这个参数来避免日志被丢弃。 调整 RateLimitBurst 和 RateLimitInte…...

物联网环境下机器人隐私保护法律框架研究-隐私保护法律监管平台
1. 引言 物联网技术的发展推动了机器人在家庭、医疗、工业等领域的广泛应用。然而,这些智能设备在数据采集和处理过程中面临着巨大的隐私保护挑战。本设计方案旨在构建一个全面的隐私保护法律监管平台,确保物联网环境下机器人的隐私数据得到有效保护,并符合相关法律法规的要…...

设计模式-创建型模式之工厂方法模式
和简单工厂模式中工厂负责生产所有产品相比,工厂方法模式将生成具体产品的任务分发给具体的产品工厂,定义一个用于创建对象的接口,让子类决定实例化哪个产品类对象。 工厂方法模式的主要角色: 抽象工厂(AbstractFactory):提供了创建产品的接…...

婚礼成本与筹备策略:一场梦幻婚礼的理性规划
婚礼成本与筹备策略:一场梦幻婚礼的理性规划 摘要 婚礼,作为人生中的重要仪式,承载着新人的爱情与梦想,同时也伴随着不菲的经济投入。本文旨在探讨婚礼所需的大致成本、影响成本的主要因素以及婚礼筹备过程中的关键注意事项&…...

前端a-tree遇到的问题
在使用a-tree时候,给虚拟滚动的高度,然后展开a-tree滑动一段距离 比如这样 随后你切换页面,在返回这个页面的时候 就会出现这样的bug 解决方法: onBeforeRouteLeave((to, from, next) > {// 可以在路由参数变化时执行的逻辑ke…...

SpringCloud教程 | 第十篇: 读取Nacos的配置
1、引入依赖 <dependency><groupId>com.alibaba.boot</groupId><artifactId>nacos-config-spring-boot-starter</artifactId><version>0.2.7</version></dependency> 2、在启动类加上 NacosPropertySource(dataId"nac…...

漏洞-Alibaba Nacos derby 远程代码执行漏洞
【漏洞详情】 漏洞描述:Alibaba Nacos derby 存在远程代码执行漏洞,由于Alibaba Nacos部分版本中derby数据库默认可以未授权访问,恶意攻击者利用此漏洞可以未授权执行SQL语句,从而远程加载恶意构造的jar包,最终导致任意…...

3分钟搞定Figma中文界面:FigmaCN汉化插件完整指南
3分钟搞定Figma中文界面:FigmaCN汉化插件完整指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma复杂的英文界面而烦恼吗?作为中文设计师࿰…...

CyberChef:网络安全工程师的终极数据处理瑞士军刀
CyberChef:网络安全工程师的终极数据处理瑞士军刀 【免费下载链接】CyberChef The Cyber Swiss Army Knife - a web app for encryption, encoding, compression and data analysis 项目地址: https://gitcode.com/GitHub_Trending/cy/CyberChef 你是否曾遇到…...

git reset 怎么用?2026年最完整操作指南,撤销提交不再手足无措
代码提交了才发现写错了,或者本地 commit 堆了一堆想整理——你是直接新建一个"撤回"commit,还是对着搜索结果一脸茫然不敢乱动? 如果你还没搞清楚 git reset 的三种模式,随时可能把代码撤没了。学完本文,你…...

告别Excel人工统计!学生考勤自动分析系统搭建实录
实验背景 本实验基于“数智教育”大赛数据集,设计并实现学生多维度考勤统计转换流,目标是掌握ETL数据处理全过程,包括数据接入、数据清洗、多表关联、字段衍生、指标聚合以及结果落地等核心技能,完成学生考勤主题标签构建任务&am…...

Steam创意工坊下载器深度解析:WorkshopDL架构揭秘与实战指南
Steam创意工坊下载器深度解析:WorkshopDL架构揭秘与实战指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 在跨平台游戏生态日益成熟的今天,Steam创意…...

跨平台项目实战:完整UI组件库与状态管理方案
一、项目实战概述随着移动端、Web端、桌面端多终端统一开发的需求日益普及,跨平台开发已成为企业级项目的主流选型。传统分端开发模式存在代码冗余、迭代效率低、UI风格不统一、状态逻辑复用困难等痛点。本项目以一套代码多端适配、UI标准化、状态统一管控为核心目标…...

3步快速上手:gmpublisher帮你轻松发布Garry‘s Mod工坊内容
3步快速上手:gmpublisher帮你轻松发布Garrys Mod工坊内容 【免费下载链接】gmpublisher ⚙️ Workshop Publishing Utility for Garrys Mod, written in Rust & Svelte and powered by Tauri 项目地址: https://gitcode.com/gh_mirrors/gm/gmpublisher 还…...

AI气象模型统一基准:可复现、多源真值、时空一致的评测标尺
1. 这不是又一个“天气数据集”,而是一把标尺:为什么AI气象建模急需统一基准“AI Weather Models”这个词组最近两年在气象学会议、AI顶会和工业界技术白皮书里出现的频率,已经快赶上“大模型”本身了。但我和团队在去年参与三个不同机构的AI…...

驱动教学模式革新:广凌智慧教学融合平台如何实现个性化教学?
随着高等教育从“知识为主”向“能力为先”深刻转型,千人千面的个性化学习已成为未来教育的核心诉求。传统的统一内容、统一路径的教学模式,已难以满足学生差异化的发展需要。如何借助技术手段实现真正的因材施教?广凌智慧教学融合平台以人工…...

新手入门使用 Python 快速接入 Taotoken 调用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门使用 Python 快速接入 Taotoken 调用大模型 对于刚开始接触大模型 API 调用的开发者而言,如何快速、正确地接入…...