数据结构与算法05堆|建堆|Top-k问题
一、堆
1、堆的介绍
堆(heap)是一种满足特定的条件的完全二叉树,主要可以分为大根堆和小根堆。
- 大根堆(max heap):任意节点的值大于等于其子节点的值。
- 小根堆(min heap):任意节点的值小于等于其子节点的值。

由于堆作为完全二叉树的一个特例,故其具有以下的特性,
1、最深一层的节点靠左填充,且前面所有层地节点均被填满。
2、将完全二叉树的根节点称为堆顶,将底层最靠右的节点称为堆底。
3、对于大根堆/小根堆,堆顶元素的值是最大/最小的。
2、堆的常用操作
需要指出的是,许多编程语言提供的是优先队列(priority queue),这是一种抽象的数据结构,定义为具有优先级排序的队列。
实际上,堆通常用于实现优先队列,大顶堆相当于元素按从大到小的顺序出队的优先队列。从使用角度来看,我们可以将“优先队列”和“堆”看作等价的数据结构。因此,本书对两者不做特别区分,统一称作“堆”。
import heapq# 初始化小顶堆
min_heap, flag = [], 1
# 初始化大顶堆
max_heap, flag = [], -1# Python 的 heapq 模块默认实现小顶堆
# 考虑将“元素取负”后再入堆,这样就可以将大小关系颠倒,从而实现大顶堆
# 在本示例中,flag = 1 时对应小顶堆,flag = -1 时对应大顶堆heapq.heappush(max_heap,flag * 1)
heapq.heappush(max_heap,flag * 3)
heapq.heappush(max_heap,flag * 2)
heapq.heappush(max_heap,flag * 5)
heapq.heappush(max_heap,flag * 4)# 获取堆顶元素
peek:int = flag * max_heap[0]
print(f"堆顶元素为{peek}")size:int = len(max_heap)
print(f"堆的大小为{size}")print("输出大顶堆为",end="")
# 堆顶元素出堆,会按照从大到小的顺序输出
for i in range(len(max_heap)):val = flag * heapq.heappop(max_heap)print(val,end="")print()
is_empty:bool = not max_heap
print(f"当前堆是否为空{is_empty}")# 输入列表并建堆
min_heap:list[int] = [1,3,2,5,4]
heapq.heapify(min_heap)
print(f"小顶堆对应的列表为{min_heap}")
3、堆的实现
下文实现的是大顶堆,若要将其转化为小顶堆则只需要将对应的大于等于改为小于等于即可。
3.1堆的存储与表示
在之前的二叉树章节中提到过,完全二叉树非常适合用数组表示,由于堆正好是一种完全二叉树,所以我们用数组的形式存储堆。
当使用数组表示二叉树时,元素代表节点值,索引代表节点在二叉树中的位置。节点指针通过索引映射公式来实现。
如图 8-2 所示,给定索引 i ,其左子节点的索引为 2i+1 ,右子节点的索引为 2i+2 ,父节点的索引为 (i−1)/2(向下整除)。当索引越界时,表示空节点或节点不存在。

堆的基本存储就是如上所示,查找当前节点i对应的左子节点,右子节点,以及其父节点都不过多讲述了,与二叉树的数组存储一样,还有求当前的堆顶元素,堆的大小等都在3.4的代码中展示,轻而易举就能看懂,下面着重讲解一下,堆的插入元素以及堆顶元素出堆的操作:
3.2、堆的元素插入
给定一个任意元素要将其插入堆中,首先应把这个元素放到堆底,添加后,由于是大顶堆,需要判断新加入的元素是否破坏了原本的大顶堆的结构,若破坏了(新插入的元素值大于其父节点的值),则需要从该节点开始从底向上进行堆化(就是需要不断调整交换位置,将新插入的节点与其父节点的值交换),就这样一直操作,直到越过根节点或遇到无需交换的节点时结束。
如下图1,2中的所示,新插入元素7,但其大于其父节点的值5,所以先进行一步交换,然后再把7与其父节点6进行比较,仍大于继续交换,最后判断7是否大于其父节点的值9,很明显不大于,则最后不交换7与9的值。


3.3、堆顶元素出堆
堆顶元素是完全二叉树的根节点,也就是列表首元素,若直接从列表中删除它,那么会导致列表中所有结点的索引都会发生变化,故会有以下的操作:
首先,交换堆顶元素与堆底元素,也就是根节点与最右边的叶子节点。
然后,交换完成后,将堆底元素从列表中删除,实际就是把原来的堆顶元素给删除了。
最后,从根节点开始,由顶到底进行堆化操作。
注意,这里的堆化操作是由顶至底进行的,在调整时,需要把根节点与最大的子节点进行交换,这样便会找到除了原本的头节点以外最大的元素,也就是次大元素,如此循环往复,直到越过叶子节点或遇到无需交换的节点为止。
如图3,4所示,要删除原来的堆顶元素9,故需要先将堆顶元素9与堆底元素5交换位置,然后直接将新的堆底元素删除;接下来就需要堆化操作:将元素5与其最大的子节点8交换,再把元素5与其当前的最大的子节点7进行交换,再把元素5与其最大的子节点6进行交换,这样便交换完成,元素6成为元素3和5的父节点,整体满足了大顶堆。


3.4代码
class MaxHeap:def __init__(self,num:list[int]):# 将列表中的元素添加到堆中self.max_heap = numdef left(self,i:int)->int:"""获取索引i节点的左子节点"""return 2 * i + 1def right(self,i:int)->int:"""获取右子节点的索引"""return 2 * i + 2def parent(self,i:int)->int:"""获取节点i的父亲节点索引"""return (i - 1) // 2 # 向下取整def peek(self)->int:"""获取堆顶元素"""return self.max_heap[0]def size(self)->int:"""堆的大小"""return len(self.max_heap)def push(self,val:int):"""元素入堆"""self.max_heap.append(val)# 从底至顶堆化self.sift_up(self.size() - 1)def swap(self,i:int,j:int):"""交换元素"""self.max_heap[i],self.max_heap[j] = self.max_heap[j],self.max_heap[i]def sift_up(self,i:int):"""从节点i开始,从底至顶堆化"""while True:# i节点的父节点p = self.parent(i)if self.max_heap[i] <= self.max_heap[p] or p < 0:breakself.swap(i,p)# 循环向上堆化i = pdef pop(self)->int:"""堆顶元素出堆"""if self.size() == 0:raise IndexError("堆为空")# 交换堆顶节点与堆底节点self.swap(0,self.size()-1)# 删除节点val = self.max_heap.pop()self.sift_down(0)# 返回堆顶元素return valdef sift_down(self,i:int):while True:l, r, ma = self.left(i),self.right(i),iif l < self.size() and self.max_heap[l] > self.max_heap[ma]:ma = lif r < self.size() and self.max_heap[r] > self.max_heap[ma]:ma = rif ma == i:break# 交换两个节点self.swap(i,ma)# 循环向下堆化i = ma4、堆的常见应用
- 优先队列通常作为实现优先队列的首选数据结构,其入队和出队操作的时间复杂度均为 O(log n) ,而建堆操作为 O(n) ,这些操作都非常高效。
- 堆排序给定一组数据,我们可以用它们建立一个堆,然后不断地执行元素出堆操作,从而得到有序数据。然而,我们通常会使用一种更优雅的方式实现堆排序,详见“堆排序”章节
- 获取最大的k个元素这是一个经典的算法问题,同时也是一种典型应用,例如选择热度前 10 的新闻作为微博热搜,选取销量前 10 的商品等。
二、建堆操作
在某些情况下,我们希望使用一个列表的所有元素来创建一个堆,这个过程被称为建堆操作。
1、借助入堆操作实现
先创建一个空堆,然后依次对每一个元素执行入堆操作,即先将元素添加至堆的尾部,再对元素执行从底至顶堆化。且每当一个新的元素入堆,堆的长度就要加1。由于元素的插入是按照从顶到底的方式插入的,因此这种方式是自上而下构建的堆。
若每个元素的入堆操作时间复杂度为O(log n),那么建堆方法(有n个元素)的时间复杂度就为O(n log n)。
2、通过遍历堆化实现
这是一种实现更高效的建堆方法,主要分为两步:
首先,将列表中的所有元素原封不动的添加到堆中,此时堆还尚未能满足大根堆或小根堆的性质;
然后,倒序遍历堆(层序遍历的倒序),依次对每个非叶子节点执行从顶至底堆化操作。
三、Top-k问题
Question:给定一个长度为n的无序数组nums,请返回数组中最大的k个元素。
对于该问题,可以先介绍比较直接的思路解法,再介绍比较更高的堆的解法。
解法1:遍历/迭代
类似于选择排序的思路:进行k轮遍历,每轮找到当前nums中剩余的未排序的最大的元素,时间复杂度为O(n*k),显然,当k<<n时,还比较使用,但当k无限接近于n的时候,时间复杂度与趋近于O(n^2),非常耗时。

解法2:排序
可以先对数组排序,然后根据排序的顺序截取k个元素即可,但时间复杂度为O(n log n),显然这种做法有点冗余了,我们并不需要一直求解到第n大的元素,求解到第k大的元素即可。故我们只需要找出最大的k个元素即可(以k为限制条件),而不需要排序其他的元素。
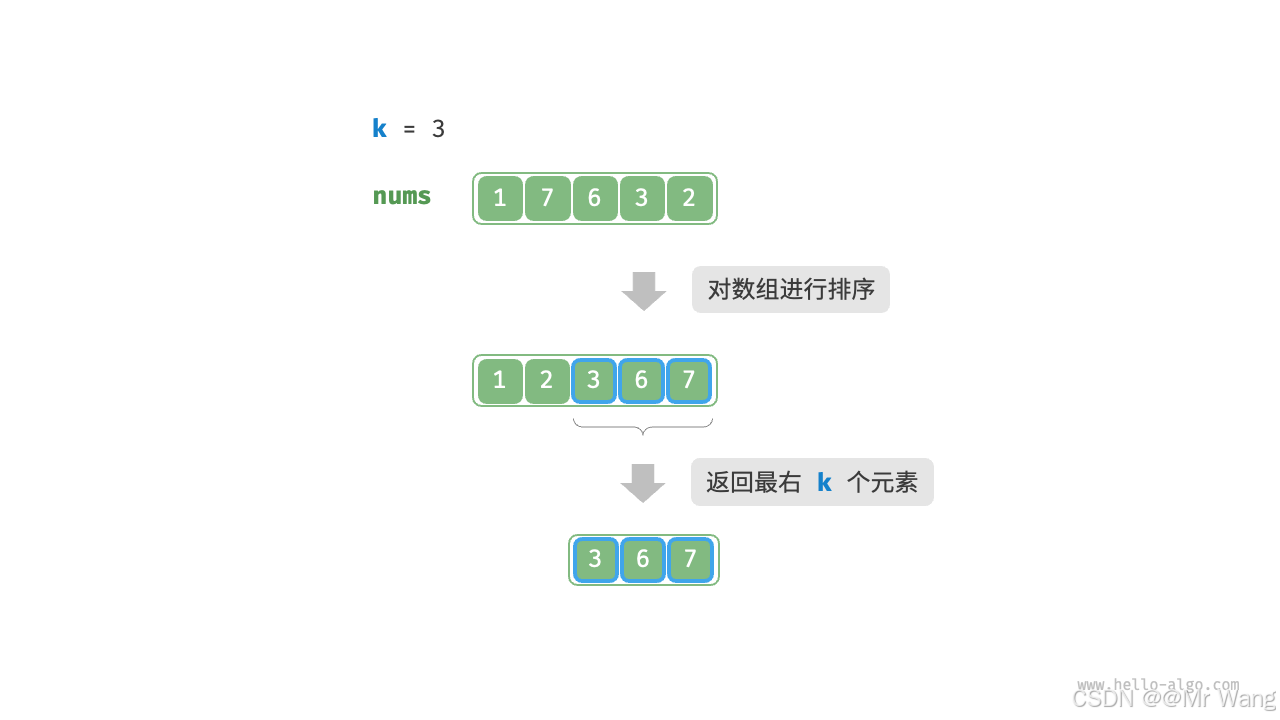
解法3:基于堆的解法
因为是需要返回前k个大的元素,所以我们使用一个小根堆,保证其堆顶的元素最小;然后将数组的前k个元素分别入堆;接着从第k+1个元素开始,若当前元素大于堆顶元素,将堆顶元素出堆,将当前元素入堆;遍历完所有元素后,堆中保存的就是最大的k个元素。
import heapqdef top_k_heap(nums:list[int],k:int)->list[int]:"""基于小顶堆查找数组中的最大的k个元素"""heap = []for i in range(k):heapq.heappush(heap,nums[i])for i in range(k,len(nums)):if nums[i]>heap[0]:heapq.heappop(heap)heapq.heappush(heap,nums[i])return heapnum = [1,7,6,3,2,5]
l = top_k_heap(num,4)
print(f"前k个最大的元素为{l}") # output:前k个最大的元素为[3, 5, 6, 7]总共执行了n轮入堆和出堆,堆的最大长度为k,因此时间复杂度为O(n log k),该方法的效率很高,当k较小时,时间复杂度趋于O(n);当k很大时,时间复杂度不会超过O(n log n)。
四、交换两个元素值
方法1
在Python中,可以通过元组解包或多重赋值来交换两个元素的值。
# 方法1
a,b = 10,1
a,b = b,a方法2
添加中间变量,这也是在一些其他编程语言中常会用到的思想。
a,b = 10,1
tmp = a
a = b
b = tmp方法3
不使用中间变量,或者是Python所自带的多重赋值,那么使用算术运算和逻辑运算也同样可以实现两个元素值的交换。
3.1算术运算
算术运算就比如一些可以先是正运算,再是逆运算的运算规则进行求解。
3.1.1加减法
# 加减法
a,b = 10,1
a = a + b
b = a - b
a = a - b3.1.2乘除法
# 乘除法
a,b = 10,1
a = a * b
b = a / b
a = a / b方法4
使用逻辑运算符号异或
a,b = 10,1
a = a ^ b
b = a ^ b
a = a ^ b相关文章:
数据结构与算法05堆|建堆|Top-k问题
一、堆 1、堆的介绍 堆(heap)是一种满足特定的条件的完全二叉树,主要可以分为大根堆和小根堆。 大根堆(max heap):任意节点的值大于等于其子节点的值。小根堆(min heap)࿱…...

【精简版】jQuery 中的 Ajax 详解
目录 一、概念 二、jQuery 发送 GET 请求 三、jQuery 发送 POST 请求 四、$.ajax() 方法 1、含义 2、settings 选项 ① type 属性 ② async 属性 ③ headers 属性 ④ contentType 属性 ⑤ processData 属性 ⑥ data 属性 ⑦ timeout 属性 ⑧ beforeSend(jqXHR) 方…...

win10删除鼠标右键选项
鼠标右键菜单时,发现里面的选项特别多,找一下属性,半天找不到。删除一些不常用的选项,让右键菜单变得干净整洁。 1、按下键盘上的“winR”组合按键,调出“运行”对话框,输入“regedit”命令,点击…...

分层评估的艺术:sklearn中的策略与实践
分层评估的艺术:sklearn中的策略与实践 在机器学习中,评估模型性能是一个至关重要的步骤。然而,对于不平衡的数据集,传统的评估方法可能会产生误导性的结果。分层评估(Stratified Evaluation)是一种确保评…...

排序系列 之 快速排序
!!!排序仅针对于数组哦本次排序是按照升序来的哦代码后边有图解哦 介绍 快速排序英文名为Quick Sort 基本思路 快速排序采用的是分治思想,即在一个无序的序列中选取一个任意的基准元素base,利用base将待排序的序列分…...

【银河麒麟服务器操作系统】java进程oom现象分析及处理建议
了解银河麒麟操作系统更多全新产品,请点击访问麒麟软件产品专区:https://product.kylinos.cn 现象描述 某服务器系统升级内核至4.19.90-25.22.v2101版本后仍会触发oom导致java进程被kill。 现象分析 oom现象分析 系统messages日志分析,故…...

Redis的AOF持久化策略(AOF的工作流程、AOF的重写流程,操作演示、注意事项等)
文章目录 缓冲AOF 策略(append only file)AOF 的工作流程AOF 缓冲区策略AOF 的重写机制重写完的AOF文件为什么可以变小?AOF 重写流程 缓冲AOF 策略(append only file) AOF 的核心思路是 “实时备份“,只要我添加了新的数据或者更新了新的数据࿰…...

共享模型之无锁
一、问题提出 1.1 需求描述 有如下的需求,需要保证 account.withdraw() 取款方法的线程安全,代码如下: interface Account {// 获取余额Integer getBalance();// 取款void withdraw(Integer amount);/*** 方法内会启动 1000 个线程…...

下载安装VSCode并添加插件作为仓颉编程入门编辑器
VSCode下载地址:下载 Visual Studio Code - Mac、Linux、Windows 插件下载:GitCode - 全球开发者的开源社区,开源代码托管平台 仓颉社区中下载解压 cangjie.vsix 插件 打开VSCode 按 Ctrl Shift X 弹出下图 按照上图步骤依次点击选中我们下…...

解决:Linux上SVN 1.12版本以上无法直接存储明文密码
问题:今天在Linux机器上安装了SVN,作为客户端使用,首次执行SVN相关操作,输入账号密码信息后,后面再执行SVN相关操作(比如"svn update")还是每次都需要输入密码。 回想以前在首次输入…...
Mongodb多键索引中索引边界的混合
学习mongodb,体会mongodb的每一个使用细节,欢迎阅读威赞的文章。这是威赞发布的第93篇mongodb技术文章,欢迎浏览本专栏威赞发布的其他文章。如果您认为我的文章对您有帮助或者解决您的问题,欢迎在文章下面点个赞,或者关…...

如何利用windows本机调用Linux服务器,以及如何调用jupyter界面远程操控
其实这篇文章没必要存在,教程太多了 参考博客(1 2 3),如侵删 奈何网上的大神总是会漏掉一些凡人遇到的小问题 (1) 建议下载PuTTy for windows,从而建立与远程服务器的SSH连接 需要确认目标服…...

如何定位Milvus性能瓶颈并优化
假设您拥有一台强大的计算机系统或一个应用,用于快速执行各种任务。但是,系统中有一个组件的速度跟不上其他部分,这个性能不佳的组件拉低了系统的整体性能,成为了整个系统的瓶颈。在软件领域中,瓶颈是指整个路径中吞吐…...

阿里云服务器 篇三:提交搜索引擎收录
文章目录 系列文章推荐:为网站注册域名判断网站是否已被搜索引擎收录主动提交搜索引擎收录未查询到收录结果时,根据提示进行提交网站提交网站时一般需要登录账号主动提交网站可缩短爬虫发现网站链接时间,但不保证一定能够收录所提交的网站百度提交地址360搜索提交地址搜狗提…...

powe bi界面认识及矩阵表基本操作 - 1
powe bi界面认识及矩阵表操作 1. 界面认识1.1 选择数据源1.2 选择相关表及点击加载1.3 表字段显示位置1.4 表属性按钮位置1.5 界面布局按钮认识 2. 矩阵表基本操作2.1 选择矩阵表2.2 创建矩阵表2.3 设置字体大小2.4 行填充:修改高度2.5 列宽:设置列的宽度…...

SpringBoot 项目 pom.xml 中 设置 Docker Maven 插件
在Spring Boot项目中,使用Docker Maven插件(通常是docker-maven-plugin或者fabric8io/docker-maven-plugin)来自动化构建Docker镜像并将其推送到远程仓库。 这里分别介绍这两种插件的基本配置,并说明如何设置远程仓库推送。 1、…...

k8s二次开发-kubebuiler一键式生成deployment,svc,ingress
一 Kubebuilder环境搭建 注:必须在当前的K8S集群有 nginx这个ingressclass rootk8s:~# kubectl get ingressclass NAME CONTROLLER PARAMETERS AGE nginx k8s.io/ingress-nginx <none> 19h1.1 下载kubebuilder wget https://gi…...
Flutter 状态管理新境界:多Provider并行驱动UI
前言 在上一篇文章中,我们讨论了如何使用 Provider 在 Flutter 中进行状态管理。 本篇文章我们来讨论如何使用多个 Provider。 在 Flutter 中,使用 Provider 管理多个不同的状态时,你可以为每个状态创建一个单独的 ChangeNotifierProvider…...

标识符和关键字的区别是什么,常用的关键字有哪些?自增自减运算符,移位运算符continue、break、return的区别是什么?
标识符和关键字的区别是什么,常用的关键字有哪些? 标识符标识符就是当我们给变量,方法,类命名时候的名字,而被赋予特殊含义的标识符就是关键字。例如生活中,当我们需要开一家店时候,我们不能将…...

在VS Code上搭建Vue项目教程(Vue-cli 脚手架)
1.前期环境准备 搭建Vue项目使用的是Vue-cli 脚手架。前期环境需要准备Node.js环境,就像Java开发要依赖JDK环境一样。 1.1 Node.js环境配置 1)具体安装步骤操作即可: npm 安装教程_如何安装npm-CSDN博客文章浏览阅读836次。本文主要在Win…...

有机颜料哪个更前沿
下游行业不断升级,从环保要求到个性化着色需求都在提升,很多采购和技术负责人都会问:现在有机颜料哪个方向更前沿?其实有机颜料的技术迭代始终围绕下游需求走,没有绝对的“最优前沿”,只有更适配自身需求的…...

开题报告一次通关密码:告别反复修改,虎贲等考 AI 重新定义高效开题
每一位本硕博学生都懂:开题不顺,论文全乱。开题报告是毕业论文的 “总设计图”,选题、框架、文献、技术路线只要一项不达标,就会被导师反复打回,浪费时间、消耗心态,甚至直接拖慢整个毕业节奏。可自己写开题…...

迭代式代码进化:基于进化算法与LLM的自动化代码优化系统
1. 项目概述:当代码学会自我进化最近在GitHub上看到一个挺有意思的项目,叫aaronjmars/iterative-code-evolution。光看名字,你可能会觉得这又是一个关于“代码生成”或者“AI编程”的常规项目。但当我深入进去,把玩了一番之后&…...
)
从手动导入到自动溯源:Perplexity提问→Mendeley定位原文→高亮引用段落→一键生成BibTeX(全流程图解)
更多请点击: https://intelliparadigm.com 第一章:从手动导入到自动溯源:Perplexity提问→Mendeley定位原文→高亮引用段落→一键生成BibTeX(全流程图解) 科研写作中,文献溯源与引用管理长期面临“知其然不…...

InputTip:提升表单体验的动态输入引导组件设计与实战
1. 项目概述:一个被低估的输入增强工具 在桌面应用开发中,我们常常会花费大量精力去构建复杂的业务逻辑和炫酷的界面,却容易忽略一个直接影响用户体验的细节: 输入引导 。回想一下,你是否遇到过这样的场景࿱…...

基于MCP协议构建AI助手业务工具适配器:从原理到实践
1. 项目概述:用MCP协议为AI助手装上“业务之眼”如果你和我一样,日常开发中需要频繁地在Stripe看支付数据、在Sentry查线上错误、在Notion里翻文档、在Linear跟进任务状态,那你一定懂那种在十几个浏览器标签页和不同SaaS平台间反复横跳的疲惫…...

2026年录音转换文字的软件推荐:从微信小程序到专业工具的实用对比
做视频或音频素材处理的时候,经常卡在这几个环节:转出来的文字有错别字需要反复核对、处理一个长视频得等半天、格式导出后没法直接用到其他软件。这些都是常见的痛点。本文会从实际应用出发,先重点讲一个相对高效的方案——微信小程序提词匠…...

GPU加速网络爬虫:OpenCL异构计算在数据采集中的实践
1. 项目概述:一个面向硬件加速的开源抓取工具包最近在折腾一些数据采集和自动化任务时,我常常遇到一个瓶颈:当需要处理海量网页、进行高频次请求或者解析复杂的动态内容时,传统的基于CPU的抓取框架(比如Scrapy、Reques…...

原生TypeScript待办清单:纯前端架构、观察者模式与拖拽排序实践
1. 项目概述:一个由AI辅助构思的现代化待办清单最近在整理个人项目时,我重新审视了一个之前用TypeScript写的待办清单应用。这个项目的初衷很简单:我需要一个极简、快速、完全由我掌控的待办工具,它不需要登录,数据就存…...

告别手动传包!用Pypiserver在内网搭建Python私有源,团队协作效率翻倍
告别手动传包!用Pypiserver在内网搭建Python私有源,团队协作效率翻倍 在团队开发中,Python依赖管理常常成为效率瓶颈。想象这样的场景:新同事加入项目,需要配置开发环境,却因为内网限制无法直接访问PyPI&a…...