LeNet实验 四分类 与 四分类变为多个二分类
目录
1. 划分二分类
2. 训练独立的二分类模型
3. 二分类预测结果代码
4. 二分类预测结果
5 改进训练模型
6 优化后 预测结果代码
7 优化后预测结果
8 训练四分类模型
9 预测结果代码
10 四分类结果识别
1. 划分二分类
可以根据不同的类别进行多个划分,以实现NonDemented为例,划分为NonDemented和Demented两类,不属于NonDemented的全都属于Demented
2. 训练独立的二分类模型
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.preprocessing.image import ImageDataGeneratorfrom 文件准备 import data_dir# 数据生成器
train_datagen = ImageDataGenerator(rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,validation_split=0.2 # 20%用于验证
)train_generator = train_datagen.flow_from_directory(data_dir,target_size=(28, 28),batch_size=32,class_mode='binary',subset='training'
)validation_generator = train_datagen.flow_from_directory(data_dir,target_size=(28, 28),batch_size=32,class_mode='binary',subset='validation'
)# 构建LeNet-5模型
model = models.Sequential()
model.add(layers.Conv2D(6, (5, 5), activation='relu', input_shape=(28, 28, 3), padding='same'))
model.add(layers.AveragePooling2D((2, 2)))
model.add(layers.Conv2D(16, (5, 5), activation='relu', padding='same'))
model.add(layers.AveragePooling2D((2, 2)))
model.add(layers.Conv2D(120, (5, 5), activation='relu', padding='same'))
model.add(layers.Flatten())
model.add(layers.Dense(84, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(train_generator,steps_per_epoch=train_generator.samples // train_generator.batch_size,epochs=10,validation_data=validation_generator,validation_steps=validation_generator.samples // validation_generator.batch_size
)# 保存模型
model.save('lenet_binary_classification_model.h5')3. 预测结果代码
import tensorflow as tf
from tensorflow.keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt# 加载模型
model = tf.keras.models.load_model('lenet_binary_classification_model.h5')# 预处理图像
def preprocess_image(img_path):img = image.load_img(img_path, target_size=(28, 28))img_array = image.img_to_array(img) / 255.0img_array = np.expand_dims(img_array, axis=0)return img_array# 预测图像
img_path = 'D:\Pycharm_workspace\LeNet实验_二分类\Demented\moderateDem24.jpg' # 测试图像路径
img_array = preprocess_image(img_path)
prediction = model.predict(img_array)
predicted_class = 'Demented' if prediction[0][0] > 0.5 else 'NonDemented'print(f'The predicted class is: {predicted_class}')# 显示图像
img = image.load_img(img_path, target_size=(28, 28))
plt.imshow(img)
plt.title(f'Predicted: {predicted_class}')
plt.show()
4. 预测结果
Demented结果

NonDemented结果没有。。。。。。
竟然全都没有。。。。因为预测的全部都是Demented
疯狂找原因中
猜测是像素太低使得训练的模型准确率太低
于是重新训练
5 改进训练模型
进行重新训练
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt# 定义LeNet模型
def create_lenet_model(input_shape):model = Sequential([Conv2D(6, (5, 5), activation='relu', input_shape=input_shape, padding='same'),MaxPooling2D((2, 2), strides=2),Conv2D(16, (5, 5), activation='relu'),MaxPooling2D((2, 2), strides=2),Flatten(),Dense(120, activation='relu'),Dense(84, activation='relu'),Dense(1, activation='sigmoid')])model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])return model# 数据增强和数据生成器
train_datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2)# 训练数据生成器
train_generator = train_datagen.flow_from_directory('D:\Pycharm_workspace\LeNet实验_二分类\image',target_size=(176, 208),batch_size=32,class_mode='binary',subset='training'
)# 验证数据生成器
validation_generator = train_datagen.flow_from_directory('D:\Pycharm_workspace\LeNet实验_二分类\image',target_size=(176, 208),batch_size=32,class_mode='binary',subset='validation'
)# 创建并训练模型
input_shape = (176, 208, 3)
model = create_lenet_model(input_shape)
history = model.fit(train_generator, epochs=10, validation_data=validation_generator)# 保存模型
model.save('dementia_classification_model.h5')# 绘制训练和验证损失
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.title('训练和验证损失')
plt.xlabel('时期')
plt.ylabel('损失')
plt.legend()
plt.show()# 绘制训练和验证准确率
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.title('训练和验证准确率')
plt.xlabel('时期')
plt.ylabel('准确率')
plt.legend()
plt.show()
这里还有图形画loss与准确率但是我忘记保存了,就用控制台的输出

可以看到loss值非常小而且准确率是100
6 优化后 预测结果代码
import tensorflow as tf
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
import os# 加载模型
model = load_model('dementia_classification_model.h5')# 定义类别标签
class_labels = ['Demented', 'NonDemented']# 预测函数
def predict_image(img_path):img = image.load_img(img_path, target_size=(176, 208))img_array = image.img_to_array(img)img_array = np.expand_dims(img_array, axis=0)img_array /= 255.0prediction = model.predict(img_array)predicted_class = class_labels[int(prediction[0] > 0.5)]# 显示图像和预测结果plt.imshow(image.load_img(img_path))plt.title(f'Predicted: {predicted_class}')plt.axis('off')plt.show()# 预测并展示结果
img_path = r'D:\Pycharm_workspace\LeNet实验_二分类\image\NonDemented\nonDem1.jpg' # 替换为你的图片路径
predict_image(img_path)7 优化后预测结果
图片与预测结果对应上了(右侧是图片链接可以看到是Dem的类型)
NonDem的也是对应上了
就此训练完成
8 训练四分类模型
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt# 定义LeNet模型
def create_lenet_model(input_shape):model = Sequential([Conv2D(6, (5, 5), activation='relu', input_shape=input_shape, padding='same'),MaxPooling2D((2, 2), strides=2),Conv2D(16, (5, 5), activation='relu'),MaxPooling2D((2, 2), strides=2),Flatten(),Dense(120, activation='relu'),Dense(84, activation='relu'),Dense(4, activation='softmax')])model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])return model# 数据增强和数据生成器
train_datagen = ImageDataGenerator(rescale=1./255, validation_split=0.2)# 训练数据生成器
train_generator = train_datagen.flow_from_directory('D:\Pycharm_workspace\LeNet实验_四分类\image',target_size=(176, 208),batch_size=32,class_mode='categorical',subset='training'
)# 验证数据生成器
validation_generator = train_datagen.flow_from_directory('D:\Pycharm_workspace\LeNet实验_四分类\image',target_size=(176, 208),batch_size=32,class_mode='categorical',subset='validation'
)# 创建并训练模型
input_shape = (176, 208, 3)
model = create_lenet_model(input_shape)
history = model.fit(train_generator, epochs=10, validation_data=validation_generator)# 保存模型
model.save('dementia_classification_model.h5')# 绘制训练和验证损失
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.title('训练和验证损失')
plt.xlabel('时期')
plt.ylabel('损失')
plt.legend()
plt.show()# 绘制训练和验证准确率
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.title('训练和验证准确率')
plt.xlabel('时期')
plt.ylabel('准确率')
plt.legend()
plt.show() 
loss值与准确率的变化图

可以看到才第四轮准确率就已经很高了
9 预测结果代码
import tensorflow as tf
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt# 加载模型
model = load_model('dementia_classification_model.h5')# 定义类别标签
class_labels = ['MildDemented', 'ModerateDemented', 'NonDemented', 'VeryMildDemented']# 预测函数
def predict_image(img_path):img = image.load_img(img_path, target_size=(176, 208))img_array = image.img_to_array(img)img_array = np.expand_dims(img_array, axis=0)img_array /= 255.0prediction = model.predict(img_array)predicted_class = class_labels[np.argmax(prediction)]# 显示图像和预测结果plt.imshow(image.load_img(img_path))plt.title(f'Predicted: {predicted_class}')plt.axis('off')plt.show()# 预测并展示结果
img_path = r'D:\Pycharm_workspace\LeNet实验_四分类\image\VeryMildDemented\verymildDem0.jpg' # 你的图片路径
predict_image(img_path)
10 四分类结果识别
1 MildDem成功识别(右侧有图片名称)

2 ModerateDem 成功识别

3 NonDem成功识别
 4 VeryMildDem成功识别
4 VeryMildDem成功识别

相关文章:
LeNet实验 四分类 与 四分类变为多个二分类
目录 1. 划分二分类 2. 训练独立的二分类模型 3. 二分类预测结果代码 4. 二分类预测结果 5 改进训练模型 6 优化后 预测结果代码 7 优化后预测结果 8 训练四分类模型 9 预测结果代码 10 四分类结果识别 1. 划分二分类 可以根据不同的类别进行多个划分,以…...

【BUG】已解决:java.lang.reflect.InvocationTargetException
已解决:java.lang.reflect.InvocationTargetException 欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 欢迎来到我的主页,我是博主英杰,211科班出身,就职于医疗科技公司,热衷分享知识,武汉城市开发…...

配置kali 的apt命令在线安装包的源为国内源
目录 一、安装VMware Tools 二、配置apt国内源 一、安装VMware Tools 点击安装 VMware Tools 后,会加载一个虚拟光驱,里面包含 VMware Tools 的安装包 鼠标右键单击 VMware Tools 的安装包,点击复制到 点击 主目录,再点击选择…...

JAVA 异步编程(线程安全)二
1、线程安全 线程安全是指你的代码所在的进程中有多个线程同时运行,而这些线程可能会同时运行这段代码,如果每次运行的代码结果和单线程运行的结果是一样的,且其他变量的值和预期的也是一样的,那么就是线程安全的。 一个类或者程序…...

Golang | Leetcode Golang题解之第260题只出现一次的数字III
题目: 题解: func singleNumber(nums []int) []int {xorSum : 0for _, num : range nums {xorSum ^ num}lsb : xorSum & -xorSumtype1, type2 : 0, 0for _, num : range nums {if num&lsb > 0 {type1 ^ num} else {type2 ^ num}}return []in…...

IDEA自带的Maven 3.9.x无法刷新http nexus私服
问题: 自建的私服,配置了域名,使用http协议,在IDEA中或本地Maven 3.9.x会出现报错,提示http被blocked,原因是Maven 3.8.1开始,Maven默认禁止使用HTTP仓库地址,只允许使用HTTPS仓库地…...

56、本地数据库迁移到阿里云
现有需求,本地数据库迁移到阿里云上。 库名xy102表 test01test02test01 test023条数据。1、登录阿里云界面创建免费试用ECS实列。 阿里云登录页 (aliyun.com)](https://account.aliyun.com/login/login.htm?oauth_callbackhttps%3A%2F%2Fusercenter2.aliyun.com%…...

新时代多目标优化【数学建模】领域的极致探索——数学规划模型
目录 例1 1.问题重述 2.基本模型 变量定义: 目标函数: 约束条件: 3.模型分析与假设 4.模型求解 5.LINGO代码实现 6.结果解释 编辑 7.敏感性分析 8.结果解释 例2 奶制品的销售计划 1.问题重述 编辑 2.基本模型 3.模…...

单例模式详解
文章目录 一、概述1.单例模式2.单例模式的特点3.单例模式的实现方法 二、单例模式的实现1. 饿汉式2. 懒汉式3. 双重校验锁4. 静态内部类5. 枚举 三、总结 一、概述 1.单例模式 单例模式(Singleton Pattern)是一种创建型设计模式,确保一个类…...

WebGIS主流的客户端框架比较|OpenLayers|Leaflet|Cesium
实现 WebGIS 应用的主流前端框架主要包括 OpenLayers、Leaflet、Mapbox GL JS 和 Cesium 等。每个框架都有其独特的功能和优势,适合不同的应用场景。 WebGIS主流前端框架的优缺点 前 端 框架优点缺点OpenLayers较重量级的开源库,二维GIS功能最丰富全面…...

【LabVIEW作业篇 - 2】:分数判断、按钮控制while循环暂停、单击按钮获取book文本
文章目录 分数判断按钮控制while循环暂停按钮控制单个while循环暂停 按钮控制多个while循环暂停单击按钮获取book文本 分数判断 限定整型数值输入控件值得输入范围,范围在0-100之间,判断整型数值输入控件的输入值。 输入范围在0-59之间,显示…...
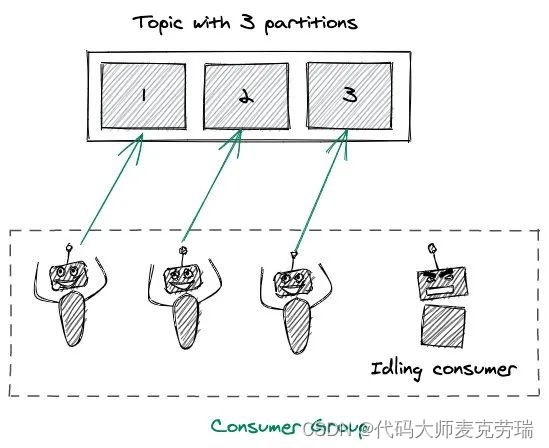
Kafka架构详解之分区Partition
目录 一、简介二、架构三、分区Partition1.分区概念2.Offsets(偏移量)和消息的顺序3.分区如何为Kafka提供扩展能力4.producer写入策略5.consumer消费机制 一、简介 Apache Kafka 是分布式发布 - 订阅消息系统,在 kafka 官网上对 kafka 的定义…...

SSM之Mybatis
SSM之Mybatis 一、MyBatis简介1、MyBatis特性2、MyBatis的下载3、MyBatis和其他持久化层技术对比 二、MyBatis框架搭建三、MyBatis基础功能1、MyBatis核心配置文件2、MyBatis映射文件3、MyBatis实现增删改查4、MyBatis获取参数值的两种方式5、MyBatis查询功能6、MyBatis自定义映…...

Python list comprehension (列表推导式 - 列表解析式 - 列表生成式)
Python list comprehension {列表推导式 - 列表解析式 - 列表生成式} 1. Python list comprehension (列表推导式 - 列表解析式 - 列表生成式)2. Example3. ExampleReferences Python 中的列表解析式并不是用来解决全新的问题,只是为解决已有问题提供新的语法。 列…...

2024年7月12日理发记录
上周五天气还算好,不太热,晚上下班打车回家后,将目的地设置成日常去的那个理发店。 下车走到门口,熟悉的托尼帅哥正在抽烟,他一眼看到了我,马上掐灭烟头,从怀里拿出口香糖,咀嚼起来&…...

几种常用排序算法
1 基本概念 排序是处理数据的一种最常见的操作,所谓排序就是将数据按某字段规律排列,所谓的字段就是数据节点的其中一个属性。比如一个班级的学生,其字段就有学号、姓名、班级、分数等等,我们既可以针对学号排序,也可…...

Spring3(代理模式 Spring1案例补充 Aop 面试题)
一、代理模式 在代理模式(Proxy Pattern)中,一个类代表另一个类的功能,这种类型的设计模式属于结构型模式。 代理模式通过引入一个代理对象来控制对原对象的访问。代理对象在客户端和目标对象之间充当中介,负责将客户端…...

Github报错:Kex_exchange_identification: Connection closed by remote host
文章目录 1. 背景介绍2. 排查和解决方案 1. 背景介绍 Github提交或者拉取代码时,报错如下: Kex_exchange_identification: Connection closed by remote host fatal: Could not read from remote repository.Please make sure you have the correct ac…...
LabVIEW在CRIO中串口通讯数据异常问题
排查与解决步骤 检查硬件连接: 确保CRIO的串口模块正确连接,并且电缆无损坏。 确认串口模块在CRIO中被正确识别和配置。 验证串口配置: 在LabVIEW项目中,检查CRIO目标下的串口配置,确保波特率、数据位、停止位和校验…...

ALTERA芯片解密FPGA、CPLD、PLD芯片解密解密
Altera是世界一流的FPGA、CPLD和ASIC半导体生产商,所提供的解决方案与传统DSP、ASSP和ASIC解决方案相比,缩短了产品面市时间,提高了性能和效能,降低了系统成本。针对Altera芯片解密,益臻芯片解密中心经过多年的芯片解…...

ARM架构TLB失效指令VALE1IS/VALE1ISNXS详解
1. ARM TLB失效指令基础解析在ARMv8/v9架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,缓存了虚拟地址到物理地址的转换结果。当操作系统修改页表后,必须通过TLB失效…...
)
HFSS新手避坑指南:手把手教你设置Floquet Port和主从边界(附矩形波导实例)
HFSS阵列仿真实战:从Floquet Port到主从边界的精准设置 第一次打开HFSS准备仿真周期性结构时,那种既兴奋又忐忑的心情我至今记忆犹新。作为计算电磁学领域的黄金标准工具,HFSS在阵列天线、频率选择表面等周期性结构分析中展现出无可替代的价…...

告别云服务器:手把手教你用QEMU在Ubuntu 18.04上搭建专属内核调试环境
从零构建QEMU内核调试环境:Ubuntu 18.04下的UEFI开发实战手册 当深夜的调试灯亮起,你是否还在为云服务器高昂的费用和网络延迟苦恼?本文将带你用一台普通Ubuntu机器,打造媲美物理机的内核开发环境。不同于常规教程,我…...

Android数据存储终极指南:SharedPreferences与ContentProviders完全解析
Android数据存储终极指南:SharedPreferences与ContentProviders完全解析 【免费下载链接】android-best-practices Dos and Donts for Android development, by Futurice developers 项目地址: https://gitcode.com/gh_mirrors/an/android-best-practices 在…...
,搞定业务中的因果推断难题)
别再只做AB测试了!用Python实战倾向性得分匹配(PSM),搞定业务中的因果推断难题
用Python实战倾向性得分匹配(PSM):超越AB测试的因果推断利器 在数据驱动的决策时代,企业经常面临一个核心问题:如何准确评估策略或干预措施的真实效果?传统AB测试虽然简单直观,但在面对历史数据、观测数据等非随机实验…...

收藏!AI时代程序员是消失还是逆袭?小白程序员必看大模型逆袭指南
收藏!AI时代程序员是消失还是逆袭?小白程序员必看大模型逆袭指南 文章探讨了AI对程序员行业的影响,指出AI抢走了程序员一半的饭碗,但也为另一半人打开了高阶职场的大门。初级岗位因AI工具普及而面临失业风险,但高级技术…...

准备转型AI产品经理的朋友,建议看看这本书
本文从《AI即未来:普通人用好人工智能的18大工作场景》出发,深入探讨了AI大模型的选择、部署及评估。文章指出,面对众多AI工具,应根据任务需求、输出质量、成本等因素进行选择,并强调AI更像助手,需人类监督…...

Docker部署Unifi控制器:从环境隔离到设备管理的完整实践
1. 项目概述:为什么选择Docker部署Unifi控制器?如果你和我一样,折腾过Ubiquiti(优倍快)的全家桶,大概率会对那个官方的硬件控制器——Cloud Key——又爱又恨。爱的是它开箱即用,把Unifi Network…...

基于Puppeteer的网页结构化检查工具:原理、实现与优化
1. 项目概述:一个面向开发者的网页内容检查与结构化工具最近在折腾一个很有意思的小项目,起因是团队里经常需要从各种网页上抓取信息,然后手动整理成结构化的数据。比如,产品经理丢过来一个竞品网站链接,让你分析一下他…...

vibe-to-ui:让AI助手将你的“感觉”翻译成专业设计系统
1. 项目概述:当“感觉”成为设计语言如果你和我一样,是一个能写出复杂业务逻辑,但一碰到UI设计就头疼的开发者,那今天聊的这个工具,可能会彻底改变你的工作流。我们常常陷入一个困境:心里有一个模糊的“感觉…...