MySQL--索引(2)
InnoDB
1.索引类型
主键索引(Primary Key)
数据表的主键列使用的就是主键索引。
一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
在 mysql 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
注:InnoDB主键索引中: B+树的叶子节点key为主键的值,data为数据的内容
二级索引(辅助索引)
二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。
唯一索引,普通索引,前缀索引等索引属于二级索引。
唯一索引(Unique Key) :唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
普通索引(Index) :普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。
全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
注:InnoDB二级索引中: B+树的叶子节点key为索引的值,data为主键的值
二级索引:(图片来源于网络)

2. 聚集索引与非聚集索引
2.1 聚集索引
聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。
在 Mysql 中,InnoDB 引擎的表的
.ibd文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。聚集索引的优点
聚集索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
聚集索引的缺点
依赖于有序的数据 :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
更新代价大 : 如果对索引列的数据被修改时,那么对应的索引也将会被修改, 而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的, 所以对于主键索引来说,主键一般都是不可被修改的。
2.2 非聚集索引
非聚集索引即索引结构和数据分开存放的索引。
二级索引属于非聚集索引。
MYISAM 引擎的表的.MYI 文件包含了表的索引, 该表的索引(B+树)的每个叶子非叶子节点存储索引, 叶子节点存储索引和索引对应数据的指针,指向.MYD 文件的数据。
非聚集索引的叶子节点并不一定存放数据的指针, 因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
非聚集索引的优点
更新代价比聚集索引要小 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
非聚集索引的缺点
跟聚集索引一样,非聚集索引也依赖于有序的数据
可能会二次查询(回表) :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
这是 Mysql 的表的文件截图:
2.3 聚集索引和非聚集索引示意图:


3. 非聚集索引的回表
3.1 为什么非聚集索引要回表操作
在InnoDB中,表数据是按照聚集索引(通常是主键索引)的顺序物理存储的。非聚集索引的叶子节点仅包含主键值和索引值,不包含实际的行数据。因此,当通过非聚集索引查询数据时,数据库首先通过非聚集索引找到主键值,然后再通过主键值去聚集索引中查找完整的行数据。这个过程就是回表操作。(非聚集索引的叶子节点的key是索引值,value是主键值)
3.2 非聚集索引一定回表查询吗(覆盖索引)?
非聚集索引不一定回表查询。
试想一种情况,用户准备使用 SQL 查询用户名,而用户名字段正好建立了索引。
SELECT name FROM table WHERE name='guang19';那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
即使是 MYISAM 也是这样,虽然 MYISAM 的主键索引确实需要回表, 因为它的主键索引的叶子节点存放的是指针。但是如果 SQL 查的就是主键呢?
SELECT id FROM table WHERE id=1;主键索引本身的 key 就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
4.覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了, 而无需回表查询。
如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。
再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引, 那么直接根据这个索引就可以查到数据,也无需回表。
覆盖索引:
5.联合索引和全文索引
5.1 全文索引
全文索引的使用主要涉及创建全文索引、插入数据、以及通过全文搜索查询数据。以下是一个具体的例子,以MySQL数据库为例进行说明:
1. 创建包含全文索引的表
首先,需要创建一个表,并在表中的某个或某些文本字段上创建全文索引。以下是一个创建表的例子,其中在
address字段上创建了全文索引:
CREATE TABLE `worker` (`id` int NOT NULL,`name` varchar(50) NOT NULL,`age` int NOT NULL,`address` varchar(100) NOT NULL,PRIMARY KEY (`id`),FULLTEXT INDEX `idx_fulltext` (`address`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;在这个例子中,
worker表有四个字段:id、name、age和address。其中,id是主键,而address字段上创建了名为idx_fulltext的全文索引。注意,从MySQL 5.7开始,InnoDB存储引擎也支持全文索引,但在早期版本中,只有MyISAM存储引擎支持全文索引。2. 插入数据
接下来,向表中插入一些包含文本数据的记录。以下是一些示例插入语句:
INSERT INTO worker (id, name, age, address) VALUES (1, 'aa', 18, '河北省保定市莲池区');INSERT INTO worker (id, name, age, address) VALUES (2, 'bb', 19, '河北省保定市竞秀区');INSERT INTO worker (id, name, age, address) VALUES (3, 'cc', 20, '河北省邢台市五四东路');-- 插入更多记录...3. 使用全文搜索查询数据
最后,通过全文搜索查询包含特定关键词的记录。在MySQL中,可以使用
MATCH()和AGAINST()函数来进行全文搜索。以下是一个查询示例,它搜索address字段中包含“河北省保定市”的记录:
SELECT * FROM worker WHERE MATCH(address) AGAINST('河北省保定市');这个查询将返回所有
address字段中包含“广东省深圳市”的记录。MySQL的全文搜索引擎会计算每个文档对象与查询的相关度,并基于匹配的关键词个数和在文档中出现的次数来排序结果。注意事项
- 在使用全文索引时,需要注意全文索引对文本长度的要求。MySQL InnoDB存储引擎的全文索引默认最短索引字符串长度为4个字符(可以通过
ft_min_word_len系统变量调整)。- 全文索引对于非常短的文本字段可能效果不佳,因为建立和维护索引的成本可能超过其带来的性能提升。
- 可以通过
IN BOOLEAN MODE进行布尔模式的搜索,这允许更复杂的查询条件,如包含或排除特定关键词。4.全文索引和like的区别
- 全文索引:
- 适用于需要处理大量文本数据、要求高效率和相关性排序的场景。
- 如搜索引擎、博客平台、新闻网站等需要对文本内容进行复杂搜索的应用。
- LIKE:
- 适用于简单的字符串模式匹配场景。
- 如在用户注册信息中查找包含特定关键字的用户名等
5.2 联合索引
了解联合索引首先先介绍两个概念:
单列索引单列索引即由一列属性组成的索引。联合索引(多列索引)联合索引即由多列属性组成索引。其次了解最左前缀原则
假设创建的联合索引由三个字段组成:
ALTER TABLE table ADD INDEX index_name (num,name,age)那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。再次强调:
最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。
select * from user where name=xx and city=xx ; //可以命中索引 select * from user where name=xx ; // 可以命中索引 select * from user where city=xx ; // 无法命中索引这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如city= xx and name =xx,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
例如创建了a,b,c联合索引
where a=xx and b>443 and c=32;(√)
where c=32 and b =-123 and a =123;(√)
where b=32 and c =-123;(×)
注:现在我给num和name和age字段建立联合索引,那么 B+Tree 在排序的时候,会首先按照 num排序,当 排序相同的时候,再按照 name进行排序。依次类推
6.如何创建索引
1.添加PRIMARY KEY(主键索引)
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )2.添加UNIQUE(唯一索引)
ALTER TABLE `table_name` ADD UNIQUE ( `column` )3.添加INDEX(普通索引)
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )4.添加FULLTEXT(全文索引)
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)5.添加多列索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
相关文章:

MySQL--索引(2)
InnoDB 1.索引类型 主键索引(Primary Key) 数据表的主键列使用的就是主键索引。 一张数据表有只能有一个主键,并且主键不能为 null,不能重复。 在 mysql 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是…...

JVM类加载机制详解
Java在运行期才对类进行加载到内存、连接、初始化过程。这使得Java应用具有极高的灵活性和拓展性,可以依赖运行期进行动态加载和动态连接。 主要加载哪些?Java中的数据类型分为基本数据类型和引用数据类型,基本数据类型由虚拟机预先定义&…...

【MATLAB实战】基于UNet的肺结节的检测
数据: 训练过程图 算法简介: UNet网络是分割任务中的一个经典模型,因其整体形状与"U"相似而得名,"U"形结构有助于捕获多尺度信息,并促进了特征的精确重建,该网络整体由编码器,解码器以及跳跃连接三部分组成。 编码器由…...

Elasticsearch基础(五):使用Kibana Discover探索数据
文章目录 使用Kibana Discover探索数据 一、添加样例数据 二、数据筛选 三、保存搜索 使用Kibana Discover探索数据 一、添加样例数据 登录Kibana。在Kibana主页的通过添加集成开始使用区域,单击试用样例数据。 在更多添加数据的方式页面下方,单击…...

爬取百度图片,想爬谁就爬谁
前言 既然是做爬虫,那么肯定就会有一些小心思,比如去获取一些自己喜欢的资料等。 去百度图片去抓取图片吧 打开百度图片网站,点击搜索xxx,打开后,滚动滚动条,发现滚动条越来越小,说明图片加载…...

HTTP 缓存
缓存 web缓存是可以自动保存常见的文档副本的HTTP设备,当web请求抵达缓存时,如果本地有已经缓存的副本,就可以从本地存储设备而不是从原始服务器中提取这个文档。使用缓存有如下的优先。 缓存减少了冗余的数据传输缓存环节了网络瓶颈的问题…...

设计模式实战:图形编辑器的设计与实现
简介 本篇文章将介绍如何设计一个图形编辑器系统,系统包括图形对象的创建、组合、操作及撤销等功能。我们将通过这一项目,应用命令模式、组合模式和备忘录模式来解决具体的设计问题。 问题描述 设计一个图形编辑器系统,用户可以创建并操作图形对象,将多个图形对象组合成…...

.NET 情报 | 分析某云系统添加管理员漏洞
01阅读须知 此文所提供的信息只为网络安全人员对自己所负责的网站、服务器等(包括但不限于)进行检测或维护参考,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作。利用此文所提供的信息而造成的直接或间接后果和损失…...

vue检测页面手指滑动距离,执行回调函数,使用混入的语法,多个组件都可以使用
mixin.ts 定义滑动距离的变量和检测触摸开始的方法,滑动方法,并导出两个方法 sendTranslateX.value > 250 && sendTranslateY.value < -100是向上滑动,满足距离后执行回调函数func,并在一秒内不再触发,一…...

opencv 优势
OpenCV(开源计算机视觉库)是一个广泛使用的计算机视觉和机器学习软件框架。它最初由Intel开发,后来由Itseez公司维护,最终于2015年成为非营利组织OpenCV.org的一部分。OpenCV的目的是实现一个易于使用且高效的计算机视觉框架,支持实时视觉应用。 以下是关于OpenCV的一些关…...

1-如何挑选Android编译服务器
前几天,我在我的星球发了一条动态:入手洋垃圾、重操老本行。没错,利用业余时间,我又重新捣鼓捣鼓代码了。在接下来一段时间,我会分享我从服务器的搭建到完成Android产品开发的整个过程。这些东西之前都是折腾过的&…...

【JS逆向课件:第十六课:Scrapy基础2】
ImagePipeLines的请求传参 环境安装:pip install Pillow USER_AGENT Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36需求:将图片的名称和详情页中图片的数据进行爬取&a…...

使用 PowerShell 自动化图像识别与鼠标操作
目录 前言功能概述代码实现1. 引入必要的程序集2. 定义读取文件行的函数3. 定义加载图片的函数4. 定义查找小图像在大图像中的位置的函数5. 定义截取全屏的函数6. 定义模拟鼠标点击的函数7. 定义主函数 配置文件示例运行脚本结语全部代码提示打包exe 下载地址 前言 在日常工作…...

组队学习——支持向量机
本次学习支持向量机部分数据如下所示 IDmasswidthheightcolor_scorefruit_namekind 其中ID:1-59是对应训练集和验证集的数据,60-67是对应测试集的数据,其中水果类别一共有四类包括apple、lemon、orange、mandarin。要求根据1-59的数据集的自…...

【数据中心】数据中心的IP封堵防护:构建网络防火墙的基石
数据中心的IP封堵防护:构建网络防火墙的基石 引言一、理解IP封堵二、IP封堵的功能模块及其核心技术三、实施IP封堵的关键策略四、结论 引言 在当今高度互联的世界里,数据中心成为信息流动和存储的神经中枢,承载着企业和组织的大量关键业务。…...
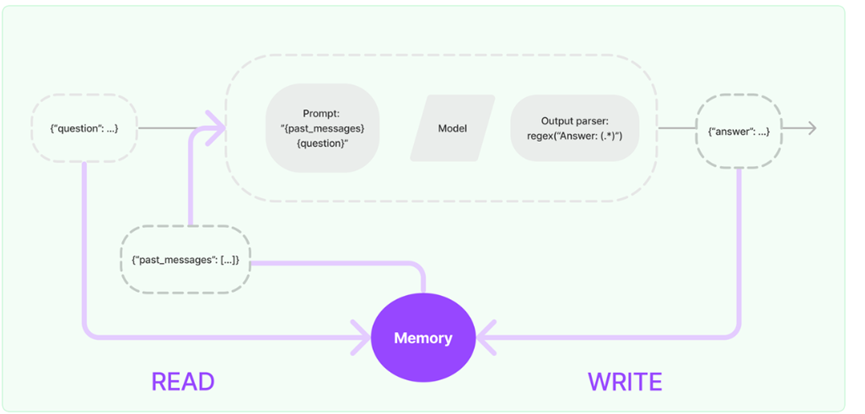
LangChain的使用详解
一、 概念介绍 1.1 Langchain 是什么? 官方定义是:LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序,它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供…...
Modbus转BACnet/IP网关快速对接Modbus协议设备与BA系统
摘要 在智能建筑和工业自动化领域,Modbus和BACnet/IP协议的集成应用越来越普遍。BA(Building Automation,楼宇自动化)系统作为现代建筑的核心,需要高效地处理来自不同协议的设备数据,负责监控和管理建筑内…...

万字长文之分库分表里无分库分表键如何查询【后端面试题 | 中间件 | 数据库 | MySQL | 分库分表 | 其他查询】
在很多业务里,分库分表键都是根据主要查询筛选出来的,那么不怎么重要的查询怎么解决呢? 比如电商场景下,订单都是按照买家ID来分库分表的,那么商家该怎么查找订单呢?或是买家找客服,客服要找到对…...

如何查看jvm资源占用情况
如何设置jar的内存 java -XX:MetaspaceSize256M -XX:MaxMetaspaceSize256M -XX:AlwaysPreTouch -XX:ReservedCodeCacheSize128m -XX:InitialCodeCacheSize128m -Xss512k -Xmx2g -Xms2g -XX:UseG1GC -XX:G1HeapRegionSize4M -jar your-application.jar以上配置为堆内存4G jar项…...

科研绘图系列:R语言TCGA分组饼图(multiple pie charts)
介绍 在诸如癌症基因组图谱(TCGA)等群体研究项目中,为了有效地表征和比较不同群体的属性分布,科研人员广泛采用饼图作为数据可视化的工具。饼图通过将一个完整的圆形划分为若干个扇形区域,每个扇形区域的面积大小直接对应其代表的属性在整体中的占比。这种图形化的展示方…...

Z-Image-Turbo在艺术创作中的实战:将文字灵感转化为超写实画作
Z-Image-Turbo在艺术创作中的实战:将文字灵感转化为超写实画作 你是否曾经有过绝妙的创意画面,却苦于无法将其具现化?Z-Image-Turbo极速云端创作室正是为解决这一痛点而生。这个基于先进AI技术的文生图工具,能够将你的文字描述在…...

CVE-2024-36401复现
一.漏洞概述 CVE-2024-36401 是 GeoServer 中的一个严重级远程代码执行漏洞(CVSS 9.8),允许未经身份验证的远程攻击者在服务器上执行任意代码。该漏洞源于 GeoServer 调用的 GeoTools 库 API 在评估 XPath 表达式时存在不安全处理࿰…...

实战指南:基于快马平台生成Spring Boot电商后端并部署于腾讯云龙虾
最近在做一个电商平台的后端开发项目,需要快速搭建一套完整的API服务。考虑到腾讯云龙虾服务器性价比高,特别适合中小型Web应用部署,我决定用Spring Boot框架来实现。整个过程在InsCode(快马)平台上完成,从代码生成到部署上线一气…...

3步精通Path of Building PoE2:流放之路2玩家的角色规划零门槛指南
3步精通Path of Building PoE2:流放之路2玩家的角色规划零门槛指南 【免费下载链接】PathOfBuilding-PoE2 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding-PoE2 你是否曾在《流放之路2》中遭遇这样的困境:投入数十小时培养的…...

Phi-4-mini-reasoning应对软件测试:自动生成测试用例与缺陷分析
Phi-4-mini-reasoning应对软件测试:自动生成测试用例与缺陷分析 1. 引言:软件测试的痛点与AI解决方案 在软件开发的生命周期中,测试环节往往占据30%-50%的项目时间。传统测试工作面临两大核心挑战:一是测试用例设计需要大量人工…...

Cursor Pro免费激活终极指南:3种方法永久解锁AI编程助手
Cursor Pro免费激活终极指南:3种方法永久解锁AI编程助手 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

忍者绘卷Z-Image Turbo新手避坑:3个技巧搞定负向提示词
忍者绘卷Z-Image Turbo新手避坑:3个技巧搞定负向提示词 1. 负向提示词在忍者绘卷中的特殊价值 在忍者绘卷Z-Image Turbo这个专为二次元/火影忍者风格优化的AI绘画工具中,负向提示词扮演着"封印术"般的角色。它不仅仅是简单的排除列表&#x…...

CefFlashBrowser:终极Flash浏览器解决方案,轻松玩转经典Flash游戏与课件
CefFlashBrowser:终极Flash浏览器解决方案,轻松玩转经典Flash游戏与课件 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 你是否还在为无法打开珍藏的Flash游戏而烦…...

图图的嗨丝造相-Z-Image-Turbo效果对比:8bit vs 16bit精度推理对渔网袜边缘锐度的影响
图图的嗨丝造相-Z-Image-Turbo效果对比:8bit vs 16bit精度推理对渔网袜边缘锐度的影响 1. 引言:当AI绘画遇上“渔网袜”细节 最近在玩一个挺有意思的AI绘画模型——图图的嗨丝造相-Z-Image-Turbo。这个模型专门针对“大网渔网袜”这种特定服饰的生成做…...

Phi-3-mini-4k-instruct-gguf应用案例:HR招聘话术生成、产品FAQ自动整理、日报模板填充
Phi-3-mini-4k-instruct-gguf应用案例:HR招聘话术生成、产品FAQ自动整理、日报模板填充 1. 模型简介 Phi-3-mini-4k-instruct-gguf是微软推出的轻量级文本生成模型,特别适合处理问答、文本改写和内容整理等任务。这个GGUF版本的模型经过优化࿰…...