【05】LLaMA-Factory微调大模型——初尝微调模型
上文【04】LLaMA-Factory微调大模型——数据准备介绍了如何准备指令监督微调数据,为后续的微调模型提供高质量、格式规范的数据支撑。本文将正式进入模型微调阶段,构建法律垂直应用大模型。
一、硬件依赖
LLaMA-Factory框架对硬件和软件的依赖可见以下链接的说明文档。
LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory · GitHub![]() https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md可根据该表格中方法和模型参数体量对应的硬件需求来评估自身硬件能否满足。
https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md可根据该表格中方法和模型参数体量对应的硬件需求来评估自身硬件能否满足。
| 方法 | 精度 | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full | AMP | 120GB | 240GB | 600GB | 1200GB | 2000GB | 900GB | 2400GB |
| Full | 16 | 60GB | 120GB | 300GB | 600GB | 900GB | 400GB | 1200GB |
| Freeze | 16 | 20GB | 40GB | 80GB | 200GB | 360GB | 160GB | 400GB |
| LoRA/GaLore/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 240GB | 120GB | 320GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | 140GB | 60GB | 160GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 72GB | 30GB | 96GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | 48GB | 18GB | 48GB |
二、微调设置
训练方法方面,LLaMA-Factory框架不仅支持预训练(Pre-Training)、指令监督微调训练(Supervised Fine-Tuning),还是支持奖励模型训练(Reward Modeling)、PPO、DPO、ORPO等强化学习训练,可使用各种方法完成全参数训练、部分参数训练、LoRA以及QLoRA。
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| Pre-Training | ✅ | ✅ | ✅ | ✅ |
| Supervised Fine-Tuning | ✅ | ✅ | ✅ | ✅ |
| Reward Modeling | ✅ | ✅ | ✅ | ✅ |
| PPO Training | ✅ | ✅ | ✅ | ✅ |
| DPO Training | ✅ | ✅ | ✅ | ✅ |
| KTO Training | ✅ | ✅ | ✅ | ✅ |
| ORPO Training | ✅ | ✅ | ✅ | ✅ |
| SimPO Training | ✅ | ✅ | ✅ | ✅ |
(1)首先进入虚拟环境,启动LLaMA-Factory框架的web网页

选择训练阶段,当前即 指令监督微调训练(SFT),载入数据集

可根据实际需求设置相应的学习率、训练轮数、验证集比例、日志间隔、保存间隔等信息。之后点击预览命令,可查看对应配置的命令行,命令可以本地保存,此后以命令行方式运行也是可行的,点击开始进行训练(需选择基础模型)。命令的具体说明如下(LoRA示例)
CUDA_VISIBLE_DEVICES=1 llamafactory-cli train \--stage sft \ #指定sft微调训练,可选rm,dpo等--do_train True \ #训练是do_train,预测是do_predict--model_name_or_path /hXXXXX \ #模型目录--finetuning_type lora \ #训练类型为lora,也可以进行full和freeze训练--quantization_bit 4 \ #量化精度,4bit,可选8bit和none不量化--template XXXX \ #模版,每个模型要选对应的模版,对应关系见上文--flash_attn auto \ #flash attention,闪光注意力机制,一种加速注意力计算的方法--dataset_dir data \ #数据目录--dataset oaast_sft_zh \ #数据集,可以通过更改dataset_info.json文件配置自己的数据集--cutoff_len 1024 \ #截断长度--learning_rate 5e-05 \ #学习率,AdamW优化器的初始学习率--num_train_epochs 20.0 \ #训练轮数,需要执行的训练总轮数--max_samples 100000 \ #最大样本数,每个数据集的最大样本数--per_device_train_batch_size 1 \ #批处理大小,每个GPU处理的样本数量,推荐为1--gradient_accumulation_steps 1 \ #梯度累积,梯度累积的步数,推荐为1--lr_scheduler_type cosine \ #学习率调节器,可选line,constant等多种--max_grad_norm 1.0 \ #最大梯度范数,用于梯度裁剪的范数--logging_steps 100 \ #日志间隔,每两次日志输出间的更新步数--save_steps 5000 \ #保存间隔,每两次断点保存间的更新步数。--warmup_steps 0.1 \ #预热步数,学习率预热采用的步数。--optim adamw_torch \ #优化器,使用的优化器:adamw_torch、adamw_8bit 或 adafactor--packing False \ --report_to none \--output_dir savesXXXXXX \ #数据目录--fp16 True \ #计算类型,可以fp16、bf16等--lora_rank 32 \ #LoRA秩,LoRA矩阵的秩大小,越大精度越高,推荐32--lora_alpha 16 \ #LoRA 缩放系数--lora_dropout 0 \--lora_target W_pack \ #模型对应的模块,具体对应关系见上文--val_size 0.1 \--evaluation_strategy steps \--eval_steps 5000 \--per_device_eval_batch_size 1 \--load_best_model_at_end True \--plot_loss True该参数的分析说明参考以下这篇博文
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用-CSDN博客![]() https://blog.csdn.net/weixin_48007632/article/details/138819599本文采用LoRA方法对模型进行微调。
https://blog.csdn.net/weixin_48007632/article/details/138819599本文采用LoRA方法对模型进行微调。
LoRA的基本原理是利用模型参数的稀疏性,通过学习模型参数的局部关系来高效地微调模型。具体来说,LoRA通过随机选择一部分模型参数进行微调,而不是对所有参数进行微调。这种方法可以大大减少模型的训练时间和计算资源,同时提高模型的性能。在实现上,LoRA可以分为两个阶段。在第一阶段,LoRA随机选择一部分模型参数进行训练,得到一个初步的微调模型。在第二阶段,LoRA对初步微调模型进行优化,进一步调整模型参数。这个过程可以重复多次,以得到更好的性能。
LoRA的优点在于它能够有效地利用模型参数的稀疏性,减少训练时间和计算资源。同时,由于LoRA只对部分参数进行微调,可以避免过拟合和泛化能力下降的问题。此外,LoRA还可以扩展到大规模深度学习模型中,具有广泛的应用前景。
在实际应用中,LoRA已经被应用于各种深度学习模型和任务中,取得了显著的效果。例如,在自然语言处理领域中,LoRA被用于文本分类、情感分析、机器翻译等任务中,取得了优秀的性能表现。在计算机视觉领域中,LoRA被用于图像分类、目标检测、人脸识别等任务中,也取得了很好的效果。
LoRA中具体每一参数的含义可参考这篇博客。
PEFT LoraConfig参数详解_深度学习_新缸中之脑-GitCode 开源社区 (csdn.net)![]() https://gitcode.csdn.net/662763f09c80ea0d2271339f.html?dp_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpZCI6NjUwMjE2LCJleHAiOjE3MjE4MDY0NjAsImlhdCI6MTcyMTIwMTY2MCwidXNlcm5hbWUiOiJINjY3Nzg4OTkifQ.GLkvRn5166k33ax3BiMR9H8KJLE8wV2JTOa4TGpZjbE
https://gitcode.csdn.net/662763f09c80ea0d2271339f.html?dp_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpZCI6NjUwMjE2LCJleHAiOjE3MjE4MDY0NjAsImlhdCI6MTcyMTIwMTY2MCwidXNlcm5hbWUiOiJINjY3Nzg4OTkifQ.GLkvRn5166k33ax3BiMR9H8KJLE8wV2JTOa4TGpZjbE
三、微调llama3-8b-chinese-chat模型
选择已经配置好路径的llama-9b-chinese模型

设置对应的输出目录和配置路径,开启训练 
整个指令微调过程耗时约8个小时,需要耐心等待

检查显卡的运行情况
nvidia-smi
在训练的过程中也可随时保存参数,中断训练


之后,可选择相应的配置进行恢复

此后,可接着中断点继续训练模型

模型训练完成后会显示训练情况

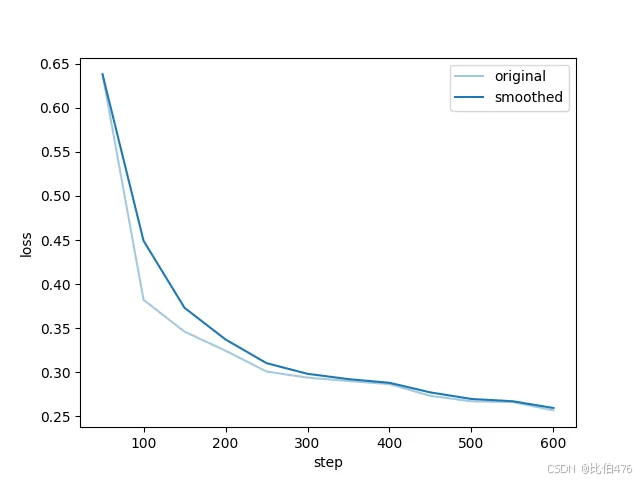
导出损失率和训练轮数的折线图

随着训练epoch的增加,损失值总体呈下降趋势。这通常表明模型在学习和改进,对数据的拟合逐渐变得更好。
四、微调Qwen-2模型
模型选择与训练开启的方法与llama3-8b-chinese-chat相同

训练开启后,命令行如图所示

通过网页端可观察训练过程中损失率的变化以及进度

模型微调的耗时约为7个小时

训练结果如下:

【注意】两个模型微调时不是一致的参数,Qwen-2的训练在LoRA的秩为32,日志间隔50,保存间隔200。
小结
本文介绍了如何对模型进行微调。下文【06】LLaMA-Factory微调大模型——微调模型评估将对微调后的模型进行应用与评估,欢迎您持续关注,如果本文对您有所帮助,感谢您一键三连,多多支持。
相关文章:
【05】LLaMA-Factory微调大模型——初尝微调模型
上文【04】LLaMA-Factory微调大模型——数据准备介绍了如何准备指令监督微调数据,为后续的微调模型提供高质量、格式规范的数据支撑。本文将正式进入模型微调阶段,构建法律垂直应用大模型。 一、硬件依赖 LLaMA-Factory框架对硬件和软件的依赖可见以下…...

Training for Stable Diffusion
1.Training for Stable Diffusion 笔记来源: 1.Denoising Diffusion Probabilistic Models 2.最大似然估计(Maximum likelihood estimation) 3.Understanding Maximum Likelihood Estimation 4.How to Solve ‘CUDA out of memory’ in PyTorch 5.pytorch-stable-d…...

初学51单片机之指针基础与串口通信应用
开始之前推荐一个电路学习软件,这个软件笔者也刚接触。名字是Circuit有在线版本和不在线版本,这是笔者在B站看视频翻到的。 Paul Falstadhttps://www.falstad.com/这是地址。 离线版本在网站内点这个进去 根据你的系统下载你需要的版本红线的是windows…...

【启明智显分享】甲醛检测仪HMI方案:ESP32-S3方案4.3寸触摸串口屏,RS485、WIFI/蓝牙可选
今年,“串串房”一词频繁引发广大网友关注。“串串房”,也被称为“陷阱房”“贩子房”——炒房客以低价收购旧房子或者毛坯房,用极度节省成本的方式对房子进行装修,之后作为精修房高价租售,因甲醛等有害物质含量极高&a…...

Linux 驱动学习笔记
1、驱动程序分为几类? • 内核驱动程序(Kernel Drivers):这些是运行在操作系统内核空间的驱动程序,用于直接访问和控制硬件设备。它们提供了与硬件交互的底层功能,如处理中断、访问寄存器、数据传输等。 •…...

ip地址设置了重启又改变了怎么回事
在数字世界的浩瀚星海中,IP地址就如同每个设备的“身份证”,确保它们在网络中准确无误地定位与通信。然而,当我们精心为设备配置好IP地址后,却时常遭遇一个令人费解的现象:一旦设备重启,原本设定的IP地址竟…...

layui table 浮动操作内容收缩,展开
layui table 隐藏浮动操作内容 fixed: right, style:, title: 操作,align:left, minWidth: 450, toolbar:#id分析: 浮动一块新增一个class layui-table-fixed-r 可以隐藏整块内容进行,新增一个按钮点击时间,然后进行收缩和展开 $(‘.layui-…...
Ubuntu24.04 NFS 服务配置
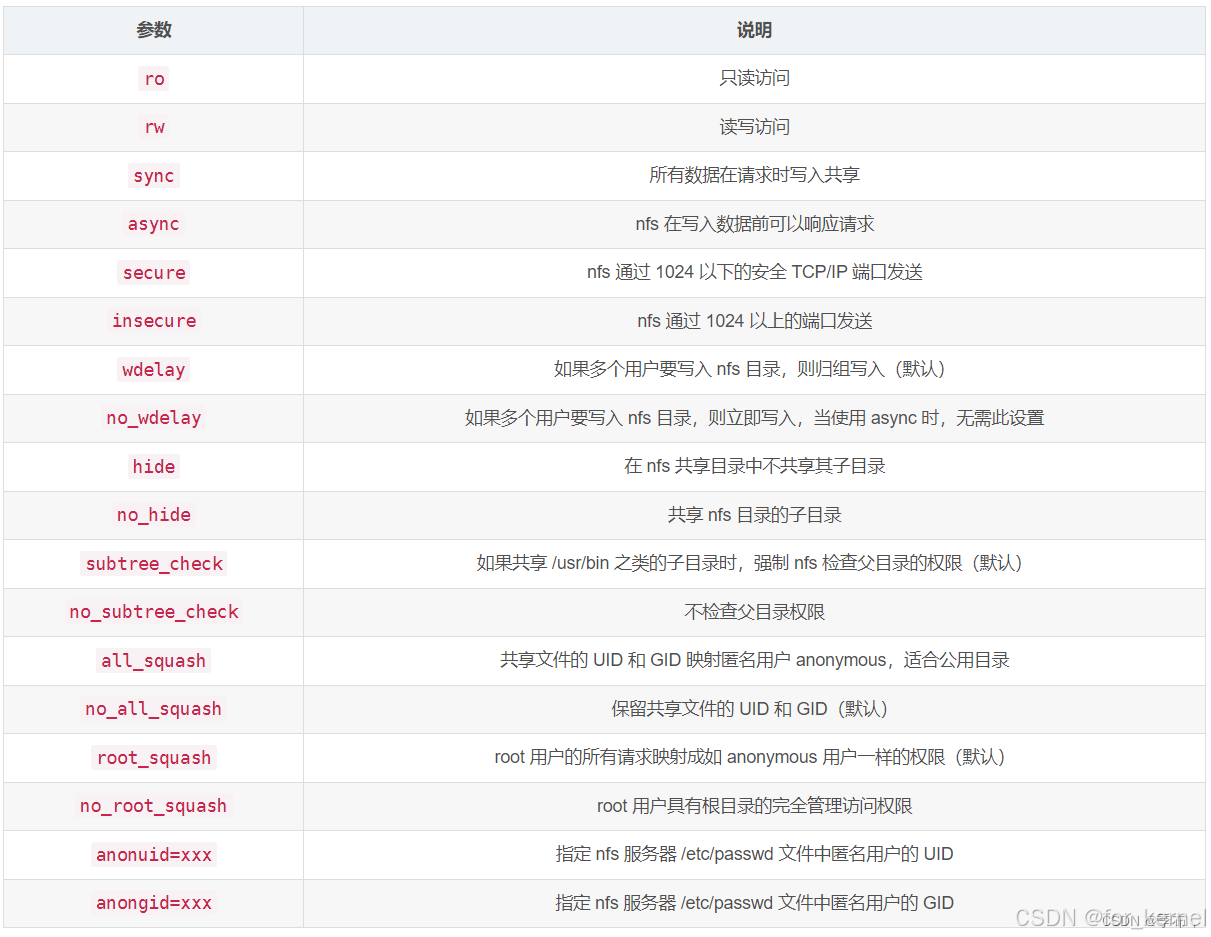
1、NFS 介绍 NFS 是 Network FileSystem 的缩写,顾名思义就是网络文件存储系统,它允许网络中的计算机之间通过 TCP/IP 网络共享资源。通过 NFS,我们本地 NFS 的客户端应用可以透明地读写位于服务端 NFS 服务器上的文件,就像访问本…...

vue3使用html2canvas
安装 yarn add html2canvas 代码 <template><div class"container" ref"container"><div class"left"><img :src"logo" alt"" class"logo"><h2>Contractors pass/承包商通行证&l…...

OpenCV分水岭算法watershed函数的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 描述 我们将学会使用基于标记的分水岭算法来进行图像分割。我们将看到:watershed()函数的用法。 任何灰度图像都可以被视为一个地形表…...
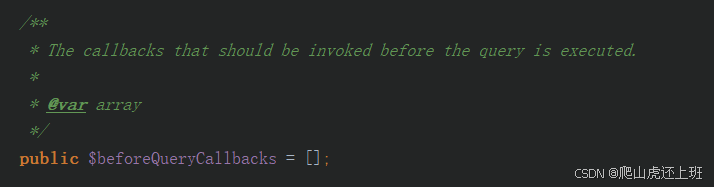
laravel为Model设置全局作用域
如果一个项目中存在这么一个sql条件在任何情况下或大多数情况都会被使用,同时很容易被开发者遗忘,那么就非常适用于今天要提到的这个功能,Eloquent\Model的全局作用域。 首先看一个示例,有个数据表,结构如下࿱…...

Leetcode之string
目录 前言1. 字符串相加2. 仅仅反转字母3. 字符串中的第一个唯一字符4. 字符串最后一个单词的长度5. 验证回文串6. 反转字符串Ⅱ7. 反转字符串的单词Ⅲ8. 字符串相乘9. 打印日期 前言 本篇整理了一些关于string类题目的练习, 希望能够学以巩固. 博客主页: 酷酷学!!! 点击关注…...
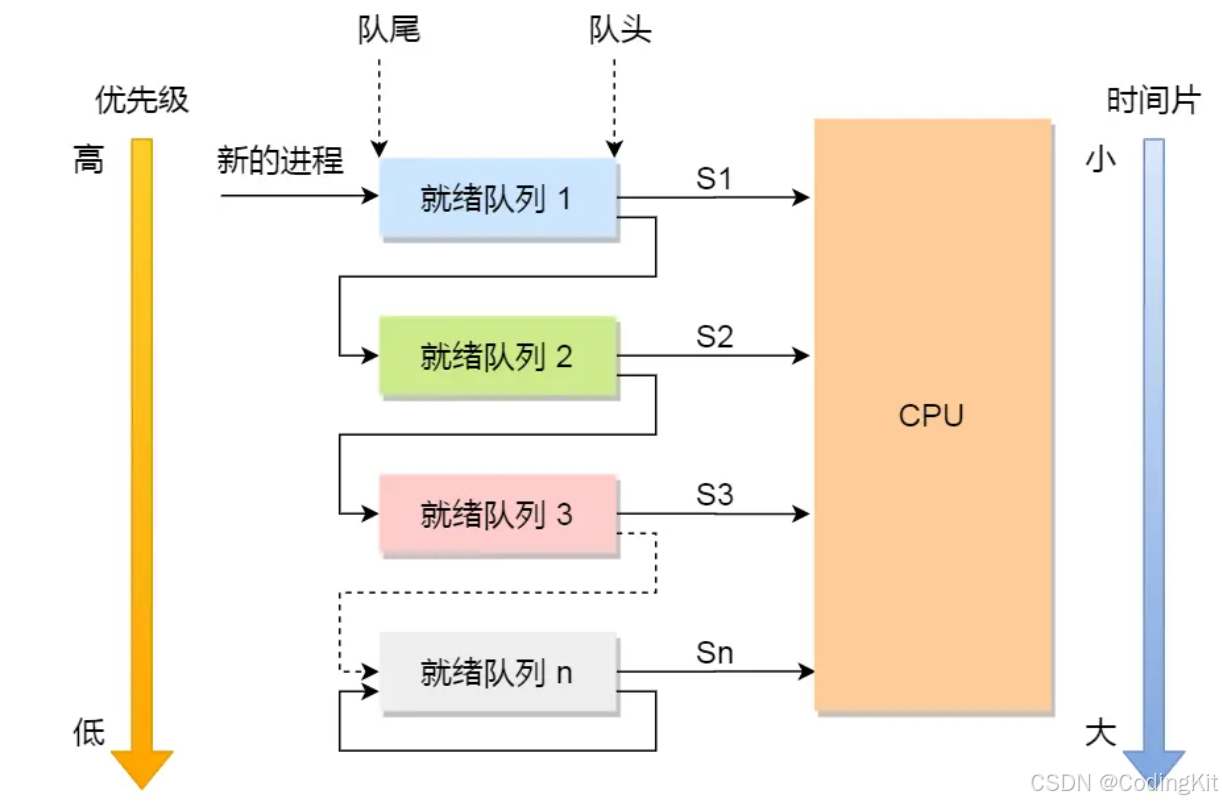
OS:处理机进程调度
1.BackGround:为什么要进行进程调度? 在多进程环境下,内存中存在着多个进程,其数目往往多于处理机核心数目。这就要求系统可以按照某种算法,动态的将处理机CPU资源分配给处于就绪状态的进程。调度算法的实质其实是一种…...
——DBSCAN算法)
【车辆轨迹处理】python实现轨迹点的聚类(一)——DBSCAN算法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、单辆车轨迹的聚类与分析1.引入库2.聚类3.聚类评价 二、整个数据集多辆车聚类1.聚类2.整体评价 前言 空间聚类是基于一定的相似性度量对空间大数据集进行分组…...

Apache Kylin
Apache Kylin 是一个开源的分布式分析引擎,提供 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据集。它能在亚秒级的时间内提供 PB 级数据的查询能力,非常适合大数据分析和报表系统。 ### 入门指南 #### 1. 环境准备 首先…...

为何Vue3比Vue2快
Proxy响应式 PatchFlag 编译模板时,动态节点做标记标记,分为不同的类型,如TEXT PROPSdiff算法时,可以区分静态节点,以及不同类型的动态节点 <div>Hello World</div> <span>{{ msg }}</span>…...

人工智能与社交变革:探索Facebook如何领导智能化社交平台
在过去十年中,人工智能(AI)技术迅猛发展,彻底改变了我们与数字世界互动的方式。Facebook作为全球最大的社交媒体平台之一,充分利用AI技术,不断推动社交平台的智能化,提升用户体验。本文将深入探…...

八股文之java基础
jdk9中对字符串进行了一个什么优化? jdk9之前 字符串的拼接通常都是使用进行拼接 但是的实现我们是基于stringbuilder进行的 这个过程通常比较低效 包含了创建stringbuilder对象 通过append方法去将stringbuilder对象进行拼接 最后使用tostring方法去转换成最终的…...
深度挖掘行情接口:股票市场中的关键金融数据API接口解析
在股票市场里,存在若干常见的股票行情数据接口,每一种接口皆具备独特的功能与用途。以下为一些常见的金融数据 API 接口,其涵盖了广泛的金融数据内容,其中就包含股票行情数据: 实时行情接口 实时行情接口:…...

逆向破解 对汇编的 简单思考
逆向破解汇编非常之简单 只是一些反逆向技术非常让人难受 但网络里都有方法破解 申请变量 : int a 0; 00007FF645D617FB mov dword ptr [a],0 char b b; 00007FF645D61802 mov byte ptr [b],62h double c 0.345; 00007FF645D61…...
)
SITS 2026正式版将于2024Q3封版,这7类测试团队必须在GA前掌握的AI原生适配策略(限内部技术预览通道)
更多请点击: https://intelliparadigm.com 第一章:AI原生测试方法革新:SITS 2026自动化测试新思路 SITS 2026(Semantic Intelligence Testing Suite)标志着测试范式从脚本驱动向语义感知与上下文自适应的跃迁。它不再…...

Windows Cleaner:专业级Windows系统优化终极指南
Windows Cleaner:专业级Windows系统优化终极指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设计的开源系统…...

从卡顿到流畅:WaveTools如何让你的《鸣潮》体验脱胎换骨
从卡顿到流畅:WaveTools如何让你的《鸣潮》体验脱胎换骨 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 你是否曾经在《鸣潮》的激烈战斗中因为突然的卡顿而错失良机?是否觉得60帧的…...

【SITS大会独家内幕】:20年技术出版人亲述图书签售背后的5大行业趋势与3个未公开合作线索
更多请点击: https://intelliparadigm.com 第一章:【SITS大会独家内幕】:20年技术出版人亲述图书签售背后的5大行业趋势与3个未公开合作线索 在2024年SITS(Software Innovation & Tech Symposium)大会主会场外的“…...

从零开始搭建 AI 应用时如何利用 Taotoken 简化模型选型与接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始搭建 AI 应用时如何利用 Taotoken 简化模型选型与接入 当你着手为一个新项目引入大模型能力时,面对市场上众多…...

ANSYS Workbench接触分析实战:从算法选择到收敛难题破解
1. 接触分析基础:为什么你的模型总是不收敛? 刚接触ANSYS Workbench的工程师常会遇到这样的场景:明明模型看起来没问题,一跑接触分析就各种报错。我十年前第一次做齿轮啮合分析时,连续两周卡在收敛问题上,差…...

如何用WeChatMsg将微信聊天记录永久保存为个人数字资产
如何用WeChatMsg将微信聊天记录永久保存为个人数字资产 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg …...

Java源码学习:深入剖析Java的concurrent包源码之`Lock` 接口的设计哲学与云原生演进
引言:超越 synchronized 的灵活并发控制 在 Java 的并发世界中,synchronized 关键字曾是开发者控制线程同步的唯一选择。然而,随着应用复杂度的提升,其固有的局限性——如无法中断、无法设置超时、严格的块结构等——逐渐成为构建…...

ChatGpt-Pro项目解析:构建可私有化部署的多模型AI生产力平台
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“Roycegao/ChatGpt-Pro”。光看名字,你可能会觉得这又是一个简单的ChatGPT套壳应用,市面上不是一抓一大把吗?但当我真正点进去,花时间研究了一下它的代…...

9.深度剖析MySQL约束的工程设计:自增主键的分布式局限、外键约束的权衡,与CHECK的版本适配实践
目录 一、上节课复习:MySQL到底是个啥玩意儿 主键的坑,你踩过吗? 二、外键约束:父表和子表的爱恨情仇 实战场景:电商网站的商品下架 三、check约束 一、上节课复习:MySQL到底是个啥玩意儿 首先&#…...