python中的线程
线程
线程概念
-
线程
在一个进程的内部, 要同时干多件事, 就需要同时运行多个"子任务", 我们把进程内的这些"子任务"叫做线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中, 是进程的实际运作单位。一条线程指的是进程中一个单一顺序的控制流, 一个进程中可以并发多个线程, 每条线程并行执行不同的任务。在Unix System V 及 SunOS 中也被称为轻量进程(lightweight processes), 但轻量进程更多指内核线程(kernel thread), 而把用户线程(user thread) 称为线程
线程通常叫做轻型的进程。线程是共享内存空间的并发执行的多任务, 每一个线程都共享一个进程的资源
线程是最小的执行单元, 而一个进程由至少一个线程组成。如何调度进程和线程, 完全由操作系统决定, 程序自己不能决定什么时候执行, 执行多长时间 -
多线程
是指从软件或硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程, 进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理器(Chip-level multithreading) 或同时多线程(Simultaneous multithreading) 处理器。 -
主线程
任何进程都会有一个默认的主线程, 如果主进程死掉, 子线程也死掉, 所以子线程依赖于主线程 -
GIL
其他语言, CPU多核是支持多个线程同时执行。但在Python中, 无论是单核还是多核, 同时只能有一个线程在执行。其根源是GIL的存在。
GIL的全称是Global Interpreter Lock(全局解释器), 来源是Python设计之初的考虑, 为了数据安全所做的决定。某个线程想要执行, 必须先拿到GIL, 我们可以把GIL看成是"通行证", 并且在一个Python进程中, GIL只有一个。拿不到通行证的线程, 就不允许进入CPU执行。
并且由于GIL锁存在, Python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行), 这就是为什么在多核CPU上, Python的多线程效率并不高的根本原因。 -
模块
_thread模块: 低级模块
threading模块: 高级模块, 对_thread进行了封装
使用 _thread 模块, 去创建线程
导入模块
import _thread
开启线程
_thread.start_new_thread(函数名, 参数)
注意:
- 参数必须为元组类型
- 如果主线程执行完毕 子线程就会死掉
- 如果线程不需要传参数的时候 也必须传递一个空元组占位
实例
import _thread
import timei = 0;def run():global i;print(i)i = i+1;def run1():print('main')if __name__ == "__main__":_thread.start_new_thread(run, ())time.sleep(3)run1()
threading创建线程(重点)
导入模块
import threading
threading创建线程的方式
myThread = threading.Thread(target=函数名[,args=(参数,),name=“你指定的线程名称”])
参数
- target: 指定线程执行的函数
- name: 指定当前线程的名称
- args: 传递子线程的参数, (元组形式)
开启线程
myThread.start()
线程等待
myThread.join()
返回当前线程对象
- threading.current_thread()
- threading.currentThread()
获取当前线程的名称
- threading.current_thread().name
- threading.currentThread().getName()
设置线程名
setName()
Thread(target=fun).setName(‘name’)
返回主线程对象
threading.main_thread()
返回当前活着的所有线程总数, 包括主线程main
- threading.active_count()
- threading.activeCount()
判断线程是不是活的, 即线程是否已经结束
- Thread.is_alive()
- Thread.isAlive()
线程守护
设置子线程是否随主线程一起结束
Thread.setDaemon(True)
还有一个要特别注意的: 必须在start()方法调用之前设置
if __name__ == '__main__':t = Thread(target=fun, args=(1,))t.setDaemon(True)t.start()print('over')
获取当前所有的线程名称
threading.enumerate() # 返回当前包含所有线程的列表
启动线程实现多任务
import threadingdef run():print(threading.current_thread().name)if __name__ == '__main__':thread_list = []for i in range(5):thread_list.append(threading.Thread(target=run, args=(),name=f"child_thread_{i}"))thread_list[i].start()for item in thread_list:item.join()run()
线程间共享数据
概述
多线程和多进程最大的不同在于, 多进程中, 同一个变量, 各自有一份拷贝存在每个进程中, 互不影响。而多线程中, 所有变量都由所有线程共享。所以, 任何一个变量都可以被任意一个线程修改, 因此, 线程之间共享数据的最大危险在于多个线程同时修改一个变量, 容易把内容改乱了。
Lock线程锁(多线程内存错乱问题)
- 概述
Lock锁是线程模块中的一个类, 有两个主要方法: acquire()和release()当调用acquire()方法时, 它锁定锁的执行并阻塞锁定执行,直到其他线程调用release()方法将其设置为解锁状态。锁帮助我们有效地访问程序中的共享资源, 以防止数据损坏, 它遵循互斥, 因为一次只能有一个线程访问特定的资源。 - 作用
避免线程冲突 - 锁: 确保了这段代码只能由一个线程从头到尾的完整执行阻止了多线程的并发执行, 包含锁的某段代码实际上只能以单线程模式执行, 所以效率大大的降低了 由于可以存在多个锁, 不同线程持有不同的!锁, 并试图获取其他的锁,可能造成死锁, 导致多个线程只能挂起, 只能靠操作系统强行终止
- 注意:
- 当前线程锁定以后 后面的线程会等待(线程等待/线程阻塞)
- 需要release解锁以后才正常
- 不能重复锁定
Timer定时执行
- 概述
Timer是Thread的子类, 可以指定时间间隔后再执行某个操作 - 使用
import threadingdef go():print("go")# t = threading.Timer(秒数, 函数名)
t = threading.Timer(3, go)
t.start()
print('我是主线程的代码')
线程池ThreadPoolExecutor
- 模块
concurrent.futures - 导入 Executor
from concurrent.futures
方法
- submit(fun[, args]) 传入放入线程池的函数以及传参
- map(fun[, iterable_args]) 统一管理
区别
- submit与map参数不同 submit每次都需要提交一个目标函数和对应的参数map只需要提交一次目标函数
目标函数的参数放在一个可迭代对象(列表、字典…)里就可以
使用
from concurrent.futures import ThreadPoolExecutor
import time
# 线程池 统一管理 线程
def go(str):print("hello", str)time.sleep(2)name_list = ['lucky', 'zhangsan', 'lisi', 'wangwu', 'zhaoliu']
pool = ThreadPoolExecutor(5) # 控制线程的并发数方式一:
for i in name_list:pool.submit(go, i)
简写:
all_task = [pool.submit(go, i) for i in name_list]方式二:
# 统一放到线程池使用
pool.map(go, name_list)
# 多个参数
# pool.map(go, name_list1, name_list2...)
map(fn, *iterables, timeout=None)
fn: 第一个参数 fn 是需要线程执行的函数;
iterables: 第二个参数接受一个可迭代对象;
timeout: 第三个参数timeout 跟 wait() 的 timeout 一样, 但由于 map 是返回线程执行的结果, 如果 timeout 小于线程执行时间会抛异常 TimeoutError。
注意: 使用 map 方法, 无需提前使用 submit 方法, map 方法与 python 高阶函数 map 的含义相同, 都是将序列中的每个元素都执行同一个函数。
获取返回值
- 方式一:
import random
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# 线程池 统一管理 线程def go(str):print("hello", str)time.sleep(random.randint(1, 4))return str
name_list = ['lucky', 'zhangsan', 'lisi', 'wangwu', 'zhaoliu']
pool = ThreadPoolExecutor(5) # 控制线程的并发数
all_task = [pool.submit(go, i) for i in name_list]
# 统一放到进程池使用
for future in as_completed(all_task):print("finish the task")obj_data = future.result()print("obj_data is", obj_data)
as_completed
当子线程中的任务执行完后, 使用 result() 获取返回结果
该方法是一个生成器, 在没有任务完成的时候, 会一直阻塞, 除非设置了 timeout。当有某个任务完成的时候, 会 yield 这个任务, 就能执行 for 循环下面的语句, 然后继续阻塞住, 循环到所有任务结束, 同时, 先完成的任务会先返回给主线程
- 方式二
for result in poor.map(go, name_list):print("task:{}".format(result))
- wait等待线程执行完毕 再继续向下执行
from concurrent.futures import ThreadPoolExecutor, wait
import time# 参数times用来模拟下载的时间
def down_video(times):time.sleep(times)print("down video {}s finished".format(times))return timesexecutor = ThreadPoolExecutor(max_workers=2)
# 通过submit函数提交执行的函数到线程池中, submit函数立即返回, 不阻塞
task1 = executor.submit(down_video, 3)
task1 = executor.submit(down_video, 1)# done方法用于判定某个任务是否完成
print("任务1是否已经完成: ", task1.done())
time.sleep(4)
print('wait')
print('任务1是否已经完成: ', task1.done())
print('任务2是否已经完成: ', task2.done())
result方法可以获取task的执行结果
print(task1.result())
线程池与线程对比
线程池是在程序运行开始, 创建好的n个线程挂起等待任务的到来。而多线程是在任务到来得时候进行创建, 然后执行任务。
线程池中的线程执行完之后不会回收线程, 会继续将线程放在等待队列中; 多线程程序在每次任务完成之后会回收该线程。
由于线程池中线程是创建好的, 所以在效率上相对于多线程会高很多。
线程池在高并发的情况下有着较好的性能; 不容易挂掉。多线程在创建线程数较多的情况下, 很容易挂掉。
队列模块queue
- 导入队列模块
import queue - 概述
queue是python标准库中的线程安全的队列(FIFO)实现, 提供了一个适用于多线程编程的先进先出的数据结构, 及队列, 用来在生产者和消费者线程之间的信息传递 - 基本FIFO队列
queue.Queue(maxsize=0)
FIFO及First in First Out, 先进先出。Queue提供了一个基本的FIFO容器, 使用方法很简单, maxsize是个整数, 指明了队列中能存放的数据个数的上限, 插入会导致阻塞, 直到队列中的数据被消费掉。
如果maxsize小于或者等于0, 队列大小没有限制。
举个例子:
import queue
q = queue.Queue()
for i in range(5):q.put(i)
while not q.empty():print(q.get())
- 一些常用方法
- task_done()
意味着之前入队的一个任务已经完成。由队列的消费者线程调用。每一个get()调用得到一个任务, 接下来的task_done()调用告诉队列该任务已经处理完毕。
如果当前一个join()正在阻塞, 它将在队列中的所有任务都处理完时恢复执行(即每一个由put()调用入队的任务都有一个对应的task_done()调用)。 - join()
阻塞调用线程, 直到队列中的所有任务被处理掉。
只要有数据被加入队列, 未完成的任务数就会增加。当消费者线程调用task_done()(意味着有消费者取得任务并完成任务), 未完成的任务数就会减少。当未完成的任务数降到0, join()解除阻塞。 - put(item[, block[, timeout]])
将item放入队列中- 如果可选的参数block为True且timeout为空对象(默认的情况,阻塞调用,无超时)。
- 如果timeout是个正整数, 阻塞调用进程最多timeout秒, 如果一直无空间可用, 抛出Full异常(带超时的阻塞调用)
- 如果block为False, 如果有空闲空间可用将数据放入队列, 否则立即抛出异常
- 其非阻塞版本为put_nowait等同于put(item, False)
- get([block[, timeout]])
从队列中移除并返回一个数据。 block跟timeout参数同 put 方法
其非阻塞方法为get_nowait()相当于get(False) - empty()
如果队列为空, 返回True, 反之返回False
- task_done()
相关文章:

python中的线程
线程 线程概念 线程 在一个进程的内部, 要同时干多件事, 就需要同时运行多个"子任务", 我们把进程内的这些"子任务"叫做线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中, 是进程的实际运作单位。一条线程指的是进程中一个单一顺序的控制流…...

hcip学习 多实例生成树,VRRP工作原理
一、STP 和 RSTP 解决了什么问题 1、STP:解决了在冗余的二层网络中所出现的环路问题 2、RSTP:在 STP 的基础上,解决了 STP 收敛速度慢的问题,引入了一些 STP 保护机制,使其网络更加稳定 二、MSTP 针对 RSTP 的改进 …...
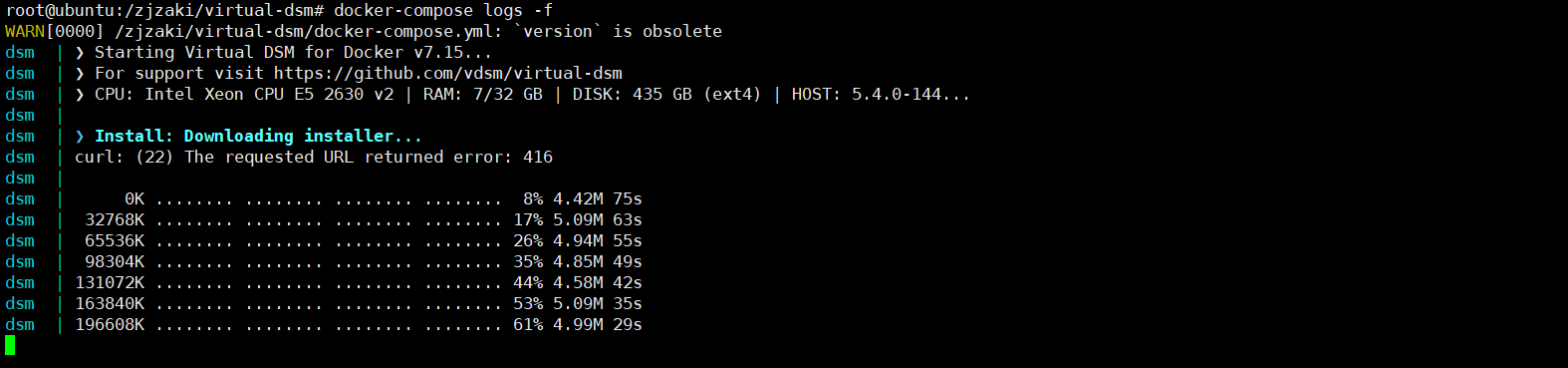
Docker搭建群晖
Docker搭建群晖 本博客介绍在docker下搭建群晖 1.编辑docker-compose.yml文件 version: "3" services:dsm:container_name: dsmimage: vdsm/virtual-dsm:latestenvironment:DISK_SIZE: "16G"cap_add:- NET_ADMIN ports:- 8080:50…...

【java】BIO,NIO,多路IO复用,AIO
在Java中,处理I/O操作的模型主要有四种:阻塞I/O (BIO), 非阻塞I/O (NIO), 异步I/O (AIO), 以及IO多路复用。下面详细介绍这四种I/O模型的工作原理和应用场景。 1. 阻塞I/O (BIO) 工作原理 阻塞I/O是最传统的I/O模型。在这种模型中,当一个线…...

服务器怎样减少带宽消耗的问题?
择业在使用服务器的过程中会消耗大量的带宽资源,而减少服务器的带宽消耗则可以帮助企业降低经济成本,同时还能够提高用户的访问速度,那么服务器怎样能减少带宽的消耗呢?本文就来带领大家一起来探讨一下吧! 企业可以选择…...

linux 报错:bash: /etc/profile: 行 32: 语法错误:未预期的文件结束符
目录 注意错误不一定错在最后一行 i进入编辑 esc退出编辑 :wq 保存编辑退出 :q!不保存退出 if [ $# -eq 3 ] then if [ ! -e "$1" ]; then miss1 $1 elif [ ! -e "$2" -a ! -e "$3" ]; then miss2and3…...

MySQL练习(5)
作业要求: 实现过程: 一、触发器 (1)建立两个表:goods(商品表)、orders(订单表) (2)在商品表中导入商品记录 (3)建立触发…...

泛型新理解
1.创建三个类,并写好对应关系 package com.jmj.gulimall.study;public class People { }package com.jmj.gulimall.study;public class Student extends People{ }package com.jmj.gulimall.study;public class Teacher extends People{ }2.解释一下这三个方法 pub…...

JavaSE--基础语法--继承和多态(第三期)
一.继承 1.1我们为什么需要继承? 首先,Java中使用类对现实世界中实体来进行描述,类经过实例化之后的产物对象,则可以用来表示现实中的实体,但是 现实世界错综复杂,事物之间可能会存在一些关联,那在设计程…...

高级java每日一道面试题-2024年7月23日-什么时候用包装类, 什么时候用原始类
面试官: 你在什么时候用包装类, 什么时候用原始类? 我回答: 在Java开发中,理解何时使用包装类(Wrapper Classes)和何时使用原始类(Primitive Types)是非常重要的。这主要取决于你的具体需求以及Java语言本身的一些限…...

LINUX之MMC子系统分析
目录 1. 概念1.1 MMC卡1.2 SD卡1.3 SDIO 2. 总线协议2.1 协议2.2 一般协议2.3 写数据2.4 读数据2.5 卡模式2.5.1 SD卡模式2.5.2 eMMC模式 2.6 命令2.6.1 命令类2.6.2 详细命令 2.7 应答2.8 寄存器2.8.1 OCR2.8.2 CID2.8.3 CSD2.8.4 RCA2.8.5 扩展CSD 3. 关键结构3.1 struct sdh…...

VulnHub:cengbox1
靶机下载地址,下载完成后,用VirtualBox打开靶机并修改网络为桥接即可搭建成功。 信息收集 主机发现和端口扫描 扫描攻击机(192.168.31.218)同网段存活主机确认目标机ip,并对目标机进行全面扫描。 nmap 192.168.31.…...
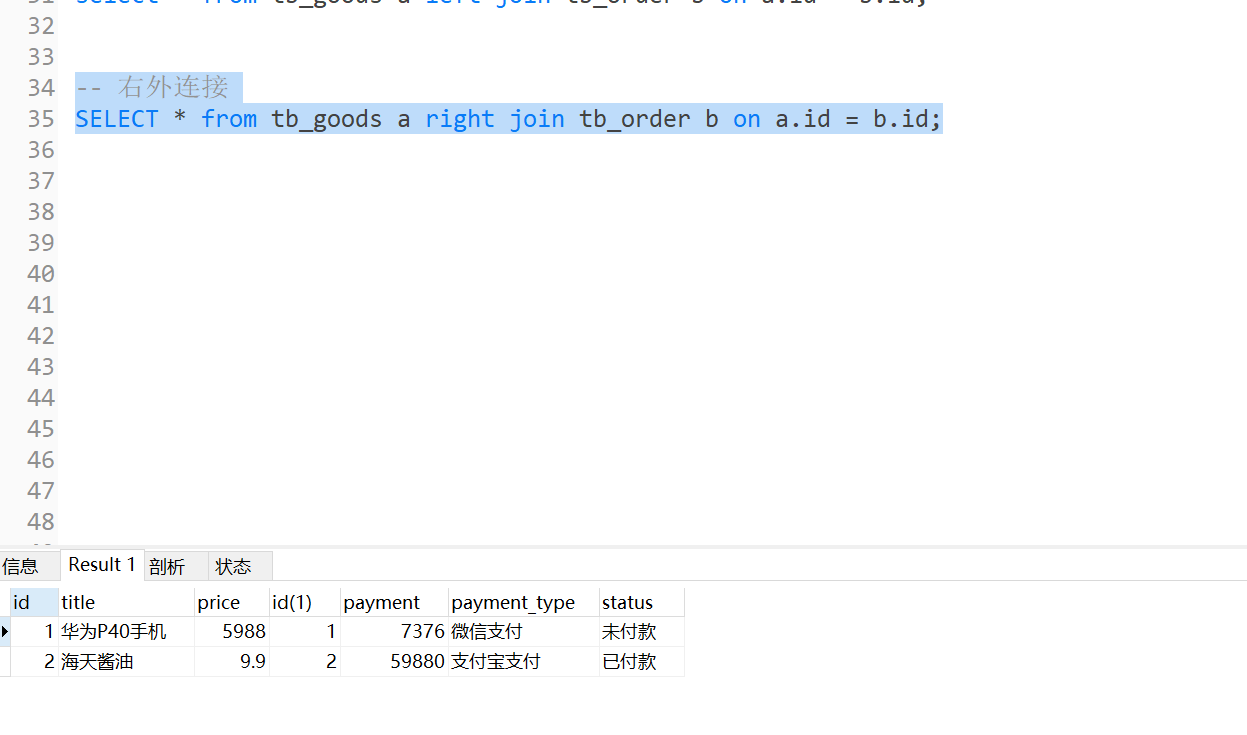
MySQL第一阶段:多表查询、事务
继续我的MySQL之旅,继续上篇的DDL、DML、DQL、以及一些约束,该到了多表查询和事务的学习总结,以及相关的案例实现,为未来的复习以及深入的理解做好知识储备。 目录 多表查询 连接查询 内连接 外连接 子查询 事务 事务简介…...

Java的序列化和反序列化
序列化: 将数据结构或对象转换成二进制串的过程 反序列化:将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程 至于为什么要序列化和反序列化呢? 因为互联网的产生带来了机器间通讯的需求,而互联通讯的双方需要采用约…...

本地连接远程阿里云K8S
1.首先安装kubectl 1.1验证自己系统 uname -m 1.2 按照步骤安装 在 Linux 系统中安装并设置 kubectl | Kubernetes 1.3 阿里云配置 通过kubectl连接Kubernetes集群_容器服务 Kubernetes 版 ACK(ACK)-阿里云帮助中心 2.验证 阿里云config直接导出,直接扔到.…...

CasaOS设备使用Docker安装SyncThing文件同步神器并实现远程管理
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
(直线检测、边缘检测、色块追踪))
k210 图像操作详解(一)(直线检测、边缘检测、色块追踪)
1、直线检测 ##################################################################################################### # file main.py # author 正点原子团队(ALIENTEK) # version V1.0 # date 2024-01-17 # brief image图像特征检测实…...

【Java版数据结构】初识泛型
看到这句话的时候证明:此刻你我都在努力 加油陌生人 br />个人主页:Gu Gu Study专栏:Java版数据结构 喜欢的一句话: 常常会回顾努力的自己,所以要为自己的努力留下足迹 喜欢的话可以点个赞谢谢了。 作者࿱…...
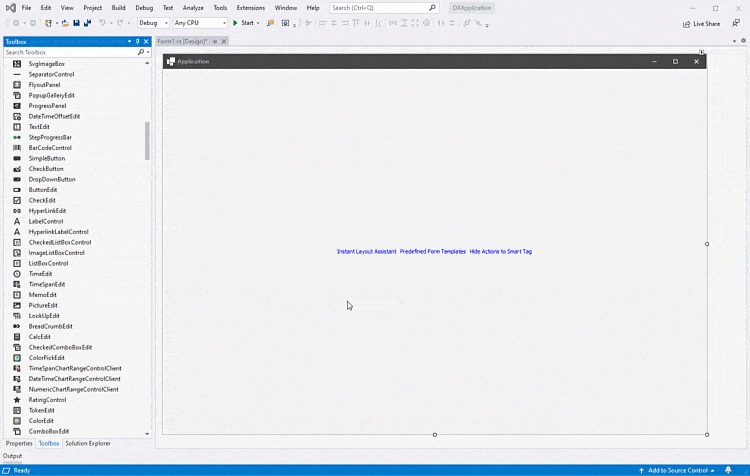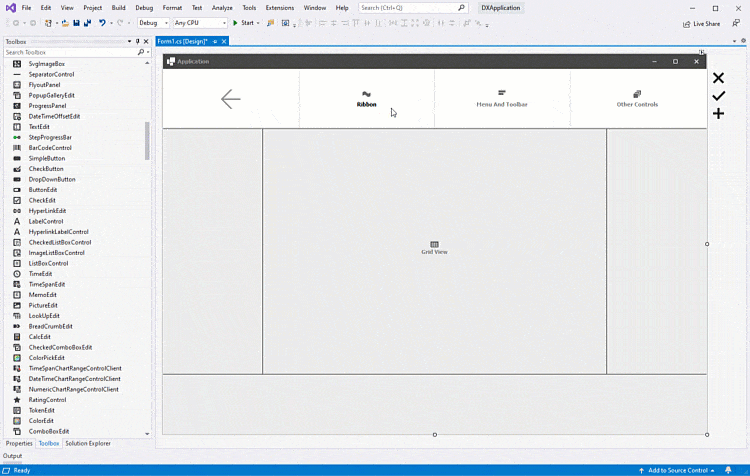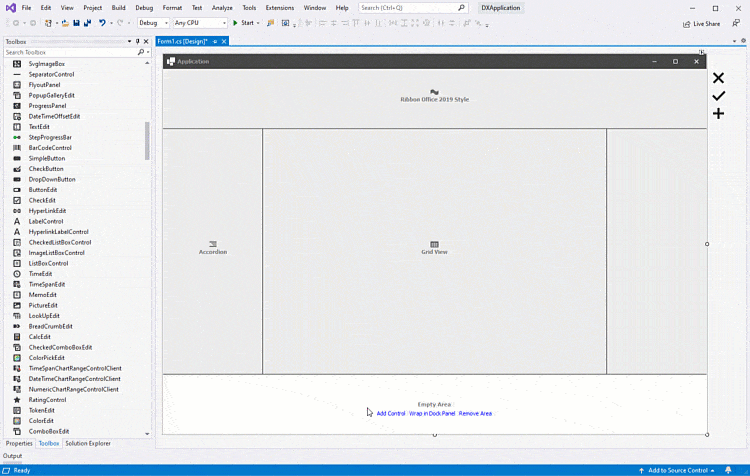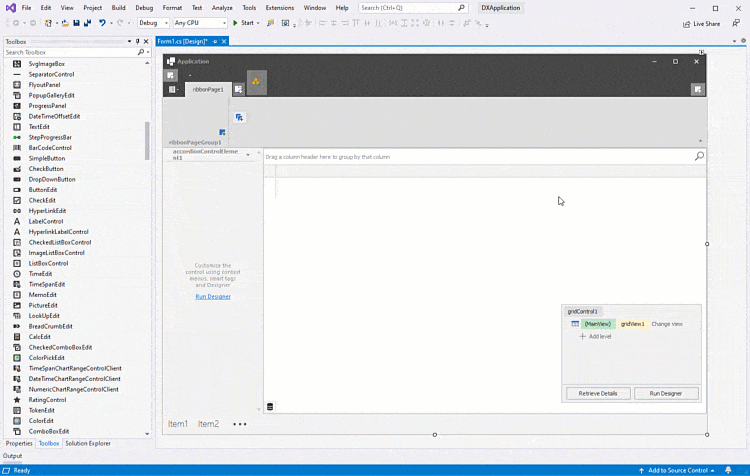
DevExpress WinForms自动表单布局,创建高度可定制用户体验(二)
使用DevExpress WinForms的表单布局组件可以创建高度可定制的应用程序用户体验,从自动安排UI控件到按比例调整大小,DevExpress布局和数据布局控件都可以让您消除与基于像素表单设计相关的麻烦。 P.S:DevExpress WinForms拥有180组件和UI库&a…...

vue中v-if和v-for
vue中v-if和v-for Vue 官方建议不要在同一个元素上同时使用 v-if 和 v-for 指令,主要有以下几个原因: 性能问题: 当 v-if 和 v-for 一起使用时,Vue 在每次渲染时都需要先执行循环,然后再对每个元素进行条件判断。这可能…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

航空发动机叶片三维扫描-诺斯顿
航空发动机叶片作为发动机的核心动力部件,其精度与性能直接决定发动机的推力、燃油效率及运行安全性,三维扫描技术作为航空制造领域的核心数字化手段,已广泛应用于叶片全生命周期的多个关键环节。其应用涵盖叶片研发设计阶段的逆向工程&#…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...