java算法day26
java算法day26
- 207 课程表
- 208 实现Trie(前缀树)
207 课程表
这题对应的知识是图论里的拓扑排序的知识。从题意就可以感受出来了。题目说如果要学习某课程,那么就需要先完成某课程。
这里我描述比较复杂的情况:课程与课程之间也有可能是多对一的场景或者是1对多的场景。
对于多对1来说,就是要想学习某一门课,就必须要完成前面的好几门课程。
比如类比这样:

对于一对多来说

那么这样的思想,就和图论里的拓扑排序的思想不谋而合了。拓扑排序是不断的将入度为0的节点删除(对应没有前置节点的课程)。当某课程的前置课程被学完了,那么就相当于此时变成了入度为0的节点,那么这节课可以被学(节点可以被删除)。
总结:
这个课不断的被学习的过程,与拓扑排序的过程一模一样。都是需要入度为0,才能够被删除(课程被学习)。当如果图中存在环,那么就会导致删除到一定状态的时候,图中不存在入度为0的节点,此时不能够再继续删除。那么对应着课程就是不可能被学习完。如果不存在环,就算图不连通也好,也肯定能够删的完。
现在可以总结写代码的思路了。
明确核心就是拓扑排序的思想。
1、上来先找图中所有入度为0的节点,然后将节点放入队列当中。(为什么要用队列,其实这里感觉很像层序遍历,因为一开始,你把图想的大一点,肯定存在着很多入度为0的节点,而第一轮肯定想着把所有入度为0的节点全删了,删完之后会暴露出新的一轮入度为0的节点。之后删节点就靠这个队列了)
2、不断的从队列中取出节点,将其邻节点(依赖于它的课程)的入度-1。(这里邻节点关系怎么找,回答是自己写一个邻接表,注意这个邻接表的节点上存的是该课程的后续课程组成的链表)(入度怎么记录?用一个入度数组来记录)。
3、如果-1之后相邻节点的入度变为0,则将其加入队列(也就是-1和判断加入队列是在一轮完成的。不在一轮完成那后续队列中哪来节点)
4、重复这个过程,直到队列为空。
具体步骤:
a.构建邻接表和入度数组
b. 将所有入度为0的节点加入队列
c. 当队列不为空时,不断取出节点进行处理:
1.将当前节点的所有相邻节点的入度减1
2.如果相邻节点入度变为0,将其加入队列
d. 检查是否所有节点都被处理过
class Solution { public boolean canFinish(int numCourses, int[][] prerequisites) { // 1. 创建图的邻接表,表示每个门课的后续的课。这是为了方便进行后续节点入度-1.//下标就代表了课的编号 List<List<Integer>> graph = new ArrayList<>(); for (int i = 0; i < numCourses; i++) { graph.add(new ArrayList<>()); } // 2. 创建入度数组,方便快速定位入度为0的点 int[] inDegree = new int[numCourses]; // 3. 遍历给的点和点之间的关系,构建图的出度和入度。 for (int[] prereq : prerequisites) { //后续课程int course = prereq[0];//前置课程 int prerequisite = prereq[1]; //获取前置课程的下标,其表示链表,然后把其后续课程挂到该链表上 graph.get(prerequisite).add(course); //后续课程的入度++inDegree[course]++; } // 4. 创建队列,将所有入度为0的课程加入队列 Queue<Integer> queue = new LinkedList<>(); for (int i = 0; i < numCourses; i++) { if (inDegree[i] == 0) { queue.offer(i); } } // 5. 记录已学习的课程数量。这里进行统计是有好处的,方便返回结果时的判断 int count = 0; // 6. BFS //将入度为0的可删除节点不断的进行扩展。BFS的思想。while (!queue.isEmpty()) {//队头出队,表示 当前 这节课学了。然后课程统计++ int course = queue.poll(); count++; // 将当前课程的所有后续课程的入度减1 for (int nextCourse : graph.get(course)) { //入度表成功匹配的进行--inDegree[nextCourse]--; // 如果入度变为0,加入队列//这里我之前还想着要每次如何把入度为0的点加入队列,一开始以为每次都要遍历入度数组//其实在进行删除的时候,就可以判断当前点是不是即将要成为入度为0的点,然后被删除。 if (inDegree[nextCourse] == 0) { queue.offer(nextCourse); } } } // 7. 判断是否所有课程都已学习//什么时候会不成立?那当然是能删的都删完了,最后还有剩下没学的课程。//所以如果课程全部学完了,count肯定为numCourses。 return count == numCourses; }
}
做的时候是否产生这样的疑问,这个疑问决定了你真的模拟理解了这个题。
每次都要遍历当前课程的邻接表里面的链表,对里面的课程进行入度–。那么某节点的度数会被减成负数吗?
回答是不会。因为链表上面的课程是后续课程,我们处理课程是从前面进行处理的。所以其入度实际上是代表了该节点前面还有多少前序节点。
208 实现Trie(前缀树)
先了解什么是前缀树:

就像这样,如果两字符串他们前缀相同,则他们后面的字符都挂在同一节点下面。可以看到,这样存储的效率很高,查找效率也并不差。
然后来看例题。这个掌握这个例题,就是掌握了字典树的基本使用。
1、如何定义字典树?
2、字典树的插入操作?
3、字典树的查找操作?
4、判断某前缀在字典树中是否存在?
我们逐个击破
1、如何定义字典树?
目前我们遇见的这个题目对于字典树的要求,存的仅仅只是小写字母。
对于字典树而言,他的定义和我们之前见到的树的定义非常的不相同,并不是像我们所想的,有节点值,然后还有后驱指针。
定义字典树就要从这个图中来观察,我们任取一个节点,比如a来进行观察,那么可以理解目前有一个字符串,它的前缀为ca。如果之后我们插入更多前缀为ca的字符串,那么从节点a往后来想。这个节点a的最大分叉应该是26分叉对吧。所以,对于任意一个节点。它都有可能最大能取到26分叉。对于根节点而言,字符串首字母肯定也是26种可能性。
因此现在可以总结。这个字典树定义的结构里,肯定有一个TrieNode数组。长度为26。用来存储它的26分叉。
还需要什么结构?需要一个末尾节点的表示判断。在定义中加上一个isWord。可以非常方便我们进行很多操作的完成,比如查找操作。
现在就可以总结出定义怎么写了:
class TrieNode {boolean isWord;TrieNode[] children = new TrieNode[26];
}
对于初始化来说,想象你正在初始化一个字典树,根节点为root。那么这个初始化显而易见。因为从这个root开始,那么肯定也是26分叉。所以说就是直接创建一个Trie作为root节点。
class Trie {TrieNode root;public Trie() {root = new TrieNode();}
}

简单总结就是,26分叉树。
这里相当于用字母下标存储了26个字母,可以这么理解,里面的数组不为空的地方的就是该节点之后的节点。
class TrieNode {boolean isWord;TrieNode[] children = new TrieNode[26];
}class Trie {TrieNode root;public Trie() {root = new TrieNode();}//插入操作//实际上就是遍历字符串,然后将每个字符加入到字典树中,始终结合图来想。public void insert(String word) {//创建一个遍历指针,这个遍历指针专门用来检查每个节点的后续数组,cur的起点为root,因为要从root开始检查分支是否存在,字符串是从root开始挂字符的。TrieNode cur = root;for(int i = 0;i<word.length();i++){//寻找当前遍历字符对应的数组下标int c = word.charAt(i)-'a';//判断该节点的后续数组里有没有这个字符//如果为null,表示这个字符在这个节点的分支上并不存在,那么就要新开一个分支了,所以new一个TrieNode。//如果往后都是null,那么这其实就是插入新字符串的过程。//总结就是如果节点存在,那么就用存在的,如果不存在,那么就加新分支if(cur.children[c] == null){cur.children[c] = new TrieNode();}//如果存在,或者是刚刚开了一个新分支,那么就沿着这个分支往下面走。cur = cur.children[c];}//由于指针一开始在root,都是每次构造完毕指针才进行后移,因此最后构造完毕的时候,指针就在指在最后一个节点上。所以把最后一个节点的判断赋值为true。cur.isWord = true;}//搜索操作,搜索该字符串是否存在。//思想还是遍历字符串,但是如果遍历的过程中,发现遍历的字符在后续分支上不存在(也就是null),那么直接返回false。//如果能把这个字符串完整的遍历完,那么最后肯定就是会停留在最后一个节点上。此时返回该点是否是最后一个节点就行了,或者直接返回true也行。public boolean search(String word) {TrieNode cur = root;for(int i = 0;i<word.length();i++){//计算当前字符在哪个分支。int c = word.charAt(i)-'a';//看看该分支是否为null,为null说明不存在直接返回false。if(cur.children[c]==null){return false;}//向下一个点遍历cur = cur.children[c];}//能遍历完说明字符都存在了,返回这个最后的节点的isWord属性也可以,直接返回true也可以return cur.isWord;}//判断某字符串前缀是否存在,还是和上面的思路意义,不过就是变成了遍历前缀字符串。public boolean startsWith(String prefix) {TrieNode cur = root;for(int i = 0;i<prefix.length();i++){int c = prefix.charAt(i)-'a';if(cur.children[c] == null){return false;}cur = cur.children[c];}return true;}
}/*** Your Trie object will be instantiated and called as such:* Trie obj = new Trie();* obj.insert(word);* boolean param_2 = obj.search(word);* boolean param_3 = obj.startsWith(prefix);*/
相关文章:
java算法day26
java算法day26 207 课程表208 实现Trie(前缀树) 207 课程表 这题对应的知识是图论里的拓扑排序的知识。从题意就可以感受出来了。题目说如果要学习某课程,那么就需要先完成某课程。 这里我描述比较复杂的情况:课程与课程之间也有可能是多对一的场景或者…...

docker笔记7-dockerfile
docker笔记7-dockerfile 一、dockerfile介绍二、dockerfile指令三、构建自己的镜像 一、dockerfile介绍 Dockerfile是用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本。 以下是常用的 Dockerfile 关键字的完整列表和说明: 二、docker…...

Spring-cloud Alibaba组件--Dubbo
远程调用技术 RestFul风格 基于HTTP协议实现,而HTTP是一种网络传输协议,基于TCP,规定了数据传输的格式。 RPC协议 Remote Produce Call 远程过程调用,类似的还有 RMI ( remote method invoke)。自定义数…...

右值引用--C++11
左值引用和右值引用 传统的C语法中就有引用的语法,而C11中新增了的右值引用语法特性,所以从现在开始我们 之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。 什么是左值?什么是左值引用?…...
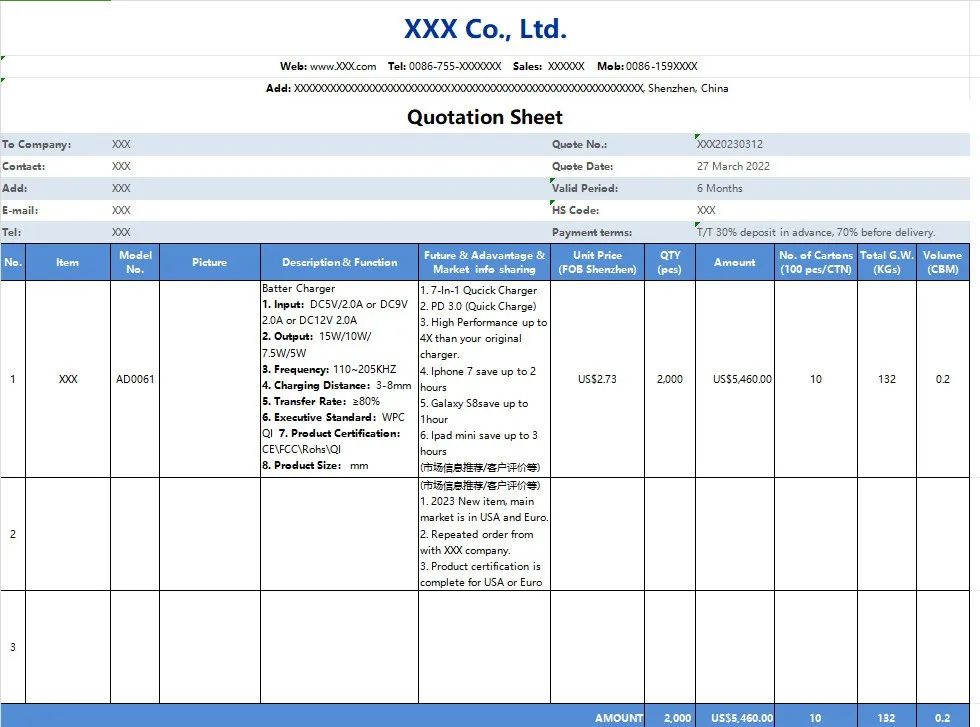
这样做外贸报价表,客户看了才想下单
报价,是外贸业务中最重要的一步,作为外贸人,不会做报价表可不行。有人说,直接在邮件里回复价格不就好了?是的,产品简单的可以这么做,但你也不能忽视报价表的价值,一份完美的价格表对…...

Swift学习入门,新手小白看过来
😄作者简介: 小曾同学.com,一个致力于测试开发的博主⛽️,主要职责:测试开发、CI/CD 如果文章知识点有错误的地方,还请大家指正,让我们一起学习,一起进步。 😊 座右铭:不…...

【Ant Design Pro】快速上手
初始化 初始化脚手架:快速开始 官方默认使用 umi4,这里文档还没有及时更新(不能像文档一样选择 umi 的版本),之后我选择 simple。 然后安装依赖。 在 package.json 中: "start": "cross-e…...

Hive3:Hive初体验
1、创建表 CREATE TABLE test(id INT, name STRING, gender STRING);2、新增数据 INSERT INTO test VALUES(1, 王力红, 男); INSERT INTO test VALUES(2, 钉钉盯, 女); INSERT INTO test VALUES(3, 咔咔咔, 女);3、查询数据 简单查询 select * from test;带聚合函数的查询 …...

blender顶点乱飞的问题解决
初学blender,编辑模式下移动某些顶点,不管是移动还是滑动都会出现定点乱飞的问题,后来才发现是开了吸附工具的原因!!!! 像下面这样,其实我只是在Z轴上移动,但是就跑的很…...
 集群脑裂)
Elasticsearch(ES) 集群脑裂
脑裂问题(split-brain problem)是指一个分布式系统中,当网络分裂(network partition)发生时,导致系统内部的两个或多个节点相互独立地认为自己仍然与其他节点连接,每个节点组都试图执行操作,这可能会导致数…...
spark 3.0.0源码环境搭建
环境 Spark版本:3.0.0 java版本:1.8 scala版本:2.12.19 Maven版本:3.8.1 编译spark 将spark-3.0.0的源码导入到idea中 执行mvn clean package -Phive -Phive-thriftserver -Pyarn -DskipTests 执行sparksql示例类SparkSQLExam…...

3.3、matlab彩色图和灰度图的二值化算法汇总
1、彩色图和灰度图的二值化算法汇总原理及流程 彩色图和灰度图的二值化算法的原理都是将图像中的像素值转化为二值(0或1),以便对图像进行简化或者特定的图像处理操作。下面分别介绍彩色图和灰度图的二值化算法的原理及流程: 1)彩色图的二值化算法原理及流程 (1)原理:…...

新手必看:Elasticsearch 入门全指南
Elasticsearch 入门介绍 Elasticsearch 是一个开源的分布式搜索和分析引擎,广泛应用于处理大规模数据和实时搜索需求。它基于 Apache Lucene 构建,具备高可扩展性和分布式特性,能够快速、可靠地存储、搜索和分析大量数据。本文将介绍 Elasti…...

【Linux】TCP全解析:构建可靠的网络通信桥梁
文章目录 前言1. TCP 协议概述2. TCP报头结构3. 如何理解封装和解包呢?4. TCP的可靠性机制4.1 TCP的确认应答机制4.2 超时重传机制 5. TCP链接管理机制5.1 经典面试题:为什么建立连接是三次握手?5.2 经典面试题:为什么要进行四次挥…...

图像处理 -- ISP中的3DNR与2DNR区别及实现原理
ISP中的3DNR与2DNR区别及实现原理 2DNR(2D Noise Reduction) 2DNR的原理: 2DNR主要针对单帧图像进行降噪处理。它利用空间域内的像素值,采用空间滤波的方法来减少噪声。常用的方法包括均值滤波、中值滤波和高斯滤波等。这些方法…...

硬盘分区读不出来的解决之道:从自救到专业恢复
在日常的计算机使用过程中,硬盘分区读不出来的问题常常令人头疼不已。这一问题不仅阻碍了用户对数据的正常访问,还可能预示着数据安全的潜在威胁。硬盘分区读不出来,通常是由于分区表损坏、文件系统错误、物理扇区损坏、驱动程序冲突或硬件连…...
盘点2024年网上很火的4个语音识别转文字工具。
语音识别转文字是一项非常实用的技术,可以帮助我们在会议记录中省去手动记录,在采访中迅速得到文字稿,在学习中快速生成课堂笔...运用十分广泛。但是很多人不知道要怎么转换,在这里我便给大家介绍几款效率非常高的语音转文字的工具…...

解决 Git 访问 GitHub 时的 SSL 错误
引言 在使用 Git 进行版本控制时,我们可能会遇到各种网络相关的错误。其中一种常见的错误是 SSL 连接问题,这会导致 Git 无法访问远程仓库。本文将介绍一个具体的错误 OpenSSL SSL_read: SSL_ERROR_SYSCALL, errno 0,以及如何通过禁用 SSL 证…...

LinuxCentos中安装apache网站服务详细教程
🏡作者主页:点击! 🐧Linux基础知识(初学):点击! 🐧Linux高级管理防护和群集专栏:点击! 🔐Linux中firewalld防火墙:点击! ⏰️创作…...

LUA脚本改造redis分布式锁
在redis集群模式下,我们会启动多个tomcat实例,每个tomcat实例都有一个JVM,且不共享。而synchronize锁的作用范围仅仅是当前JVM,所以我们需要一个作用于集群下的锁,也就是分布式锁。(就是不能用JVM自带的锁了…...

企业上云选型:四家主流云厂商的硬指标对比
在数字化转型进入深水区的2026年,企业IT部门的任务已不再是简单的“资源扩容”,而是如何在保障业务连续性的前提下,实现安全免运维与成本控制的完美平衡。 针对官网、小程序等互联网业务,各大公有云厂商均有成熟方案。但当涉及到…...

从量子自旋到量子比特:原理、应用与工程实践全解析
1. 从“旋转的电子”到“内禀角动量”:自旋概念的祛魅如果你在大学里上过量子力学课,大概率在某个时刻被“自旋”这个概念迎面撞上。我记得当时教授在黑板上写下“电子自旋为1/2”,然后试图用一个小球绕自身轴旋转的经典图像来解释࿰…...

CTF新手必看:用010Editor和CRC校验,5分钟揪出被篡改的PNG图片宽高
CTF新手实战:5分钟掌握PNG图片宽高篡改检测技巧 当你第一次参加CTF比赛,面对一张无法正常显示的PNG图片时,是否感到无从下手?这很可能是题目设计者修改了图片的宽高参数。作为MISC方向的基础题型,掌握快速检测PNG图片…...

FastAPI新手快速入门
一、认识FastAPI1.什么是apiapi接口其实就是应用程序器对外提供操作数据的入口,这个入口可以是函数、方法或者url接口当客户端调用入口,应用程序会执行对应代码操作,完成相对应的功能(应用服务器只负责对外提供统一API,…...

为什么选择update-golang:5大优势对比传统安装方式
为什么选择update-golang:5大优势对比传统安装方式 【免费下载链接】update-golang update-golang is a script to easily fetch and install new Golang releases with minimum system intrusion 项目地址: https://gitcode.com/gh_mirrors/up/update-golang …...

face-recognition.js 模型训练与保存:构建可复用的人脸识别系统
face-recognition.js 模型训练与保存:构建可复用的人脸识别系统 【免费下载链接】face-recognition.js Simple Node.js package for robust face detection and face recognition. JavaScript and TypeScript API. 项目地址: https://gitcode.com/gh_mirrors/fa/f…...

system24高级功能探索:透明背景、模糊效果和自定义窗口控制
system24高级功能探索:透明背景、模糊效果和自定义窗口控制 【免费下载链接】system24 a tui-style discord theme 项目地址: https://gitcode.com/gh_mirrors/sy/system24 system24是一款tui风格的Discord主题,它通过简约的设计和强大的自定义功…...

谱域图算子与边缘计算优化实践
1. 图算子技术背景与核心价值图神经网络(GNN)在工业场景的应用正面临两大核心挑战:一是传统消息传递机制在深层网络中的过平滑现象,二是边缘设备上的计算资源限制。我们团队在热交换器监测项目中首次发现,当GNN层数超过…...

低功耗CPLD技术演进与便携设备应用解析
1. 低功耗CPLD的技术演进与市场定位在数字电路设计领域,可编程逻辑器件(CPLD)已经走过了三十多年的发展历程。早期的CPLD主要应用于工业控制和通信设备,其高功耗特性使得消费电子领域的设计师们望而却步。2000年前后,随着半导体工艺的进步&am…...

RTLSeek:强化学习驱动的Verilog代码多样性生成技术
1. RTLSeek:当强化学习遇上硬件设计自动化在芯片设计领域,Verilog作为主流的硬件描述语言(HDL),其代码质量直接影响着芯片的性能、功耗和面积。传统RTL设计高度依赖工程师经验,一个资深工程师可能需要5-7年才能熟练掌握复杂芯片的…...