排序XXXXXXXXX
信息学奥赛|常见排序算法总结(C+) - 腾讯云开发者社区-腾讯云 (tencent.com)
https://cloud.tencent.com/developer/news/975232
常用序号层级排序
一、序号
序号Sequence Number,有顺序的号码,如数字序号(1、2、3...),大写汉字数字序号(一、二、三...)
正确地运用序号,能使我们的文章层次清楚,逻辑分明,便于阅读和引述。
在我们在写文章,特别是在写论文中经常会用到数字序号。如果不加以重视,文章中很容易出现层次大小不分、中文数字与阿拉伯数字混用、前后序号形式不统一等问题。
二、序号的结构层次顺序
(一)数字序号的级别顺序为:
第一层,汉字数字加顿号:“一、” “二、” “三、”;
第二层,括号中包含汉字数字:“(一)” “(二)” “(三)”;
第三层,阿拉伯数字加下脚点:“1. ”“2.”“3.”;
第四层,括号中包含阿拉伯数字:“(1)” “(2)” “(3)”;
第五层,带圈的阿拉伯数字,例如:“①” “②” “③”或者“1)” “2)” “3)”;
第六层,大写英文字母,例如:“A.” “B.” “C.”或者“(A)” “(B)” “(C)”;
第七层,小写英文字母,例如: “a.” “b.” “c.”或者“(a)” “(b)” “(c)”;
(二)理科类论文的正文层次标题序号
理科类论文的各层次标题还可用阿拉伯数字连续编码,不同层次的2个数字之间用下圆点(.)分隔开,末位数字后面不加点号。如“1”,“1.2”,“1.2.1”等;
各层次的标题序号均左顶格排写,最后一个序号之后空一个字距接排标题。如“5.3.2 测量的方法”,表示第五章第三节第二条的标题是“测量的方法”。

注意:同一层次各段内容是否列标题应一致,各层次的下一级序号标法应一致,若层次较少可不用若干加括号的序号。
(三)正文中图、表、公式、算式等的序号
1.正文中的图、表、公式、算式等序号一律用阿拉伯数字分别依序连续编排序号,其标注形式应便于互相区别,如“图1、表2、式(5)”等;
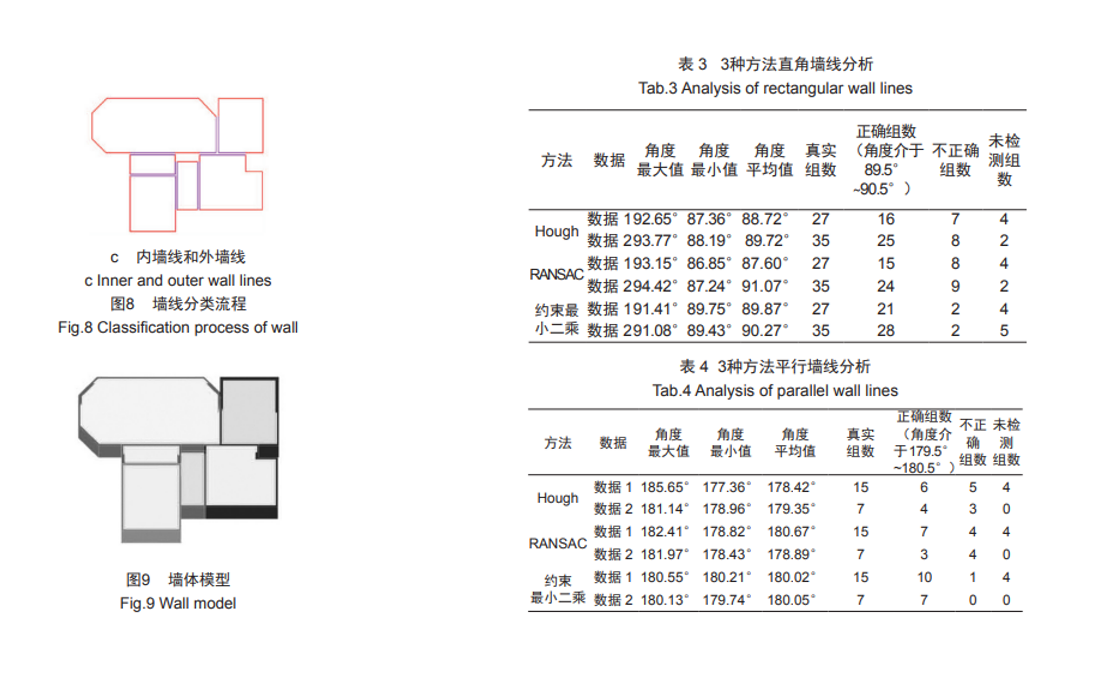
图片取自论文《基于约束最小二乘的三维点云墙体重建》(周刚、李霖)
2.对长篇研究报告也可以分章(条)依序编码,如“图2.1、表4.2、式(3.3)”等,其前一个数字表示章(条)序号,后一个数字表示本章中图表、公式的序号。
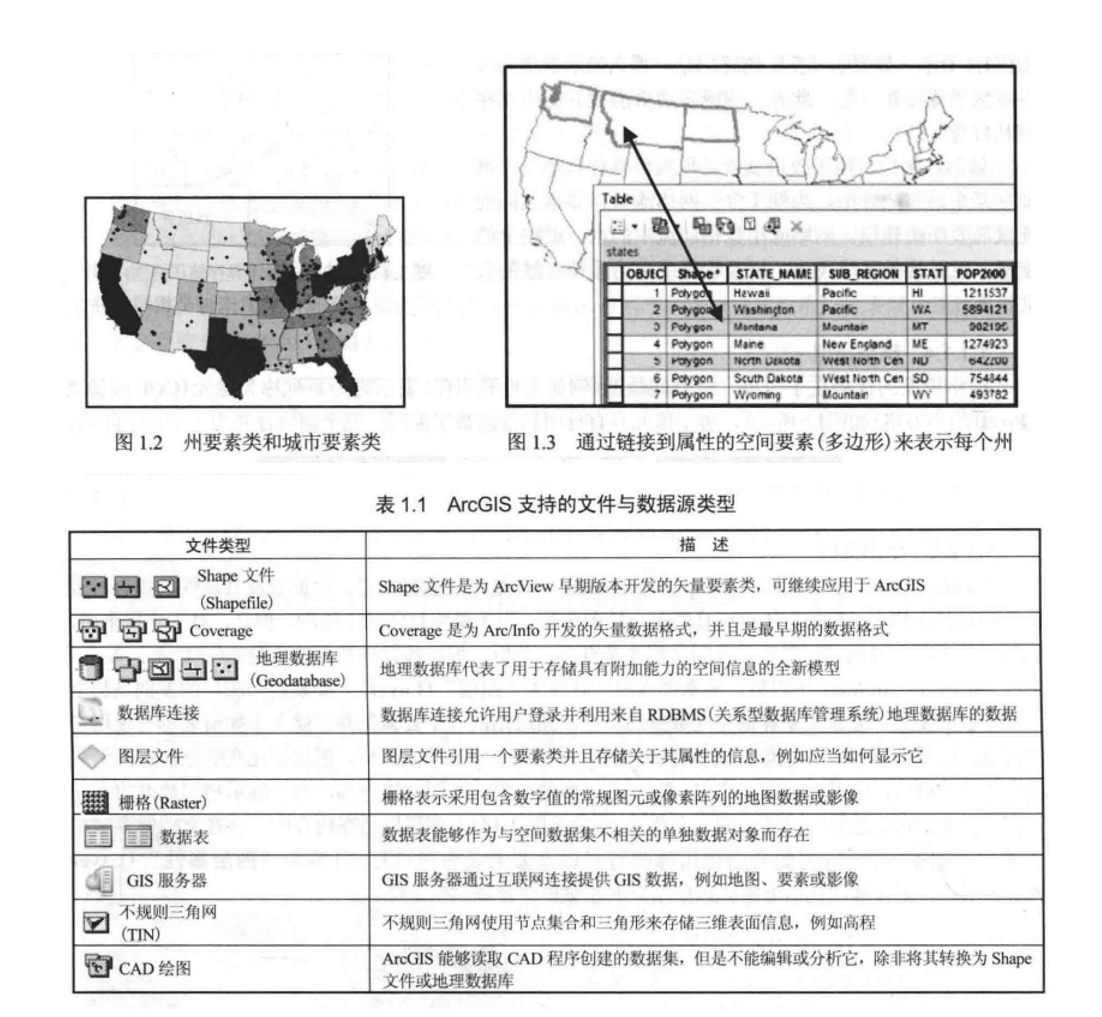
图片取自书籍《ArcGIS地理信息系统教程》(原书第7版)
33333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333
计算机综合基础知识记录(408、面试) - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/626540048
qtreeview 某一列排序 1 1-1 1-1-1
为了在QTreeView的某一列上进行排序,你可以使用QTreeView的sortByColumn()方法,并且可能需要重写QTreeView的sectionClicked信号处理函数。
以下是一个简单的例子,展示了如何对QTreeView的某一列进行排序。
from PyQt5.QtWidgets import QApplication, QTreeView, QTableWidgetItem, QHeaderView, QAbstractItemView
from PyQt5.QtCore import Qt, QModelIndex, QSortFilterProxyModel, QStringListModel
class CustomSortProxyModel(QSortFilterProxyModel):
def lessThan(self, left: QModelIndex, right: QModelIndex) -> bool:
left_data = left.data()
right_data = right.data()
# 对数据进行自定义排序规则
# 这里是按照数字、短横线数字、短横线数字短横线的顺序进行排序
def split_items(item):
return item.split('-')
left_parts = split_items(left_data)
right_parts = split_items(right_data)
for i in range(min(len(left_parts), len(right_parts))):
left_part = left_parts[i]
right_part = right_parts[i]
try:
# 尝试转换为整数,进行数字比较
left_num = int(left_part)
right_num = int(right_part)
if left_num != right_num:
return left_num < right_num
except ValueError:
# 如果不是整数,就直接比较字符串
if left_part != right_part:
return left_part < right_part
# 如果前面部分都相同,则比较部分的长度
return len(left_parts) < len(right_parts)
def main():
app = QApplication([])
model = QStringListModel()
data = ["1", "1-1", "1-1-1", "2", "2-1", "2-2", "3", "3-1", "3-1-1"]
model.setStringList(data)
tree = QTreeView()
tree.setModel(model)
# 设置代理模型以实现自定义排序
proxy_model = CustomSortProxyModel()
proxy_model.setSourceModel(model)
tree.setModel(proxy_model)
# 设置第一列可排序
tree.sortByColumn(0, Qt.AscendingOrder)
tree.header().setSectionResizeMode(QHeaderView.ResizeToContents)
tree.setEditTriggers(QAbstractItemView.NoEditTriggers)
tree.show()
app.exec_()
if __name__ == '__main__':
main()
在这个例子中,我们创建了一个QTreeView来展示一个字符串列表。我们定义了一个CustomSortProxyModel类,它重写了lessThan方法来实现自定义的排序逻辑。这里的逻辑是尝试将每个条目分割成部分,并尝试将每个部分转换为整数进行比较,如果转换失败则直接比较字符串。这样就可以按照数字、短横线数字、短横线数字短横线…的顺序进行排序。当你点击列头时,QTreeView会自动调用sortByColumn方法进行排序,并使用我们定义的CustomSortProxyModel来实现自定义的排序逻辑。
44444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444
https://blog.csdn.net/in_void/article/details/111720221
C++数据结构的一些代码(排序部分)_c++利用结构体排序插入代码l-CSDN博客
555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555
排序算法原理及C++实现(桶排序、冒泡排序、快速排序) - 知乎 (zhihu.com)
排序算法原理及C++实现(桶排序、冒泡排序、快速排序) - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/431933290
66666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666
https://www.cnblogs.com/starboy/p/11693675.html
C++|关于各种排序的总结 - =Icarus= - 博客园 (cnblogs.com)
777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777
1 1-1 1-1-1 排序 C++
要对这种格式的数字字符串进行排序,我们可以将它们分割为子串,并将每个子串转换为数字,然后比较数字的大小。以下是一个C++函数,它接受一个字符串向量作为输入,并按照这种格式的数字大小对其进行排序。
#include <iostream>
#include <vector>
#include <algorithm>
bool compareVersion(const std::string& a, const std::string& b) {
std::vector<int> a_version, b_version;
int num = 0;
for (char c : a) {
if (c == '-') {
a_version.push_back(num);
num = 0;
} else if (c >= '0' && c <= '9') {
num = num * 10 + (c - '0');
}
}
a_version.push_back(num);
num = 0;
for (char c : b) {
if (c == '-') {
b_version.push_back(num);
num = 0;
} else if (c >= '0' && c <= '9') {
num = num * 10 + (c - '0');
}
}
b_version.push_back(num);
for (size_t i = 0; i < a_version.size() && i < b_version.size(); ++i) {
if (a_version[i] < b_version[i]) return true;
if (a_version[i] > b_version[i]) return false;
}
return a_version.size() < b_version.size();
}
int main() {
std::vector<std::string> versions = {"1-1", "1-1-1", "1-1-2", "1-2", "2-1", "2-2"};
std::sort(versions.begin(), versions.end(), compareVersion);
for (const auto& version : versions) {
std::cout << version << std::endl;
}
return 0;
}
这段代码定义了一个compareVersion函数,它将字符串版本号分割为子版本号,并将它们转换为整数,然后按照从左到右的顺序比较它们。main函数中的代码展示了如何使用这个比较函数对版本号数组进行排序。
相关文章:
排序XXXXXXXXX
信息学奥赛|常见排序算法总结(C+) - 腾讯云开发者社区-腾讯云 (tencent.com) https://cloud.tencent.com/developer/news/975232 常用序号层级排序 一、序号 序号Sequence Number,有顺序的号码,如数字序号…...

【文件解析漏洞】实战详解!
漏洞描述: 文件解析漏洞是由于中间件错误的将任意格式的文件解析成网页可执行文件,配合文件上传漏洞进行GetShell的漏洞! IIS解析漏洞: IIS6.X: 方式一:目录解析 在网站下建立文件夹的名字为.asp/.asa 的文件夹,其目…...

【杂谈】学会让你节省三秒钟——Dev-c++的缺省源
【杂谈】学会让你节省三秒钟——Dev-c的缺省源 1.前言2.缺省源的介绍3.注意 1.前言 你是否在为每次写程序都要自己手打一遍框架而感到苦恼?为什么大佬的Dev-C一新建文件就会自动出现程序框架?看完这篇文章,让你也能成为大佬,不用再…...

推荐一款前端滑动验证码插件(Vue、uniapp)
uniapp版本:滑块拼图验证码,有后端,简单几步即可实现,小程序、h5都可以用 - DCloud 插件市场 Vue版本及cdn版本可以查阅文档: 行为验证 | Poster 文档 示例代码: <template><view id"app&…...

【Git】git stash
目录 基本概念参数详解listshowsavepushpop|applydropclearbranch 参考文章 Git的stash命令是一个非常实用的功能,它允许开发者临时保存工作目录和暂存区的更改,以便能够切换到其他分支或进行其他操作,而不会丢失当前的修改。以下是git stash…...

不得不安利的程序员开发神器,太赞了!!
作为一名程序员,你是否常常为繁琐的后端服务而感到头疼?是否希望有一种工具可以帮你简化开发流程,让你专注于创意和功能开发?今天,我要向大家隆重推荐一款绝佳的开发神器——MemFire Cloud。它专为懒人开发者准备&…...

吴恩达机器学习C1W2Lab06-使用Scikit-Learn进行线性回归
前言 有一个开源的、商业上可用的机器学习工具包,叫做scikit-learn。这个工具包包含了你将在本课程中使用的许多算法的实现。 目标 在本实验室你可以: 利用scikit-learn实现基于正态方程的近似解线性回归 工具 您将使用scikit-learn中的函数以及ma…...

CSS实现表格无限轮播
<div className{styles.tableTh}><div className{styles.thItem} style{{ width: 40% }}>报警名称</div><div className{styles.thItem} style{{ width: 35% }}>开始时间</div><div className{styles.thItem} style{{ width: 25% }}>状态&…...

编程小白如何从迷茫走出
针对新生们常常感到的迷茫,以下是如何选择适合自己的编程语言、如何制定有效的学习计划以及如何避免常见的学习陷阱的详细建议: 一、如何选择适合自己的编程语言 明确需求和目标:不同的编程语言有不同的特点和适用场景。例如,Py…...

14 B端产品的运营管理
通过运营找到需求并通过交换价值提供供给,再逐步扩大规模、站稳脚跟,辅助产品在商业竞争中获胜。 B端产品运营框架 1. 打通渠道 目的:触达客户。 环节:文案策划、活动策划→广告渠道推广→线下BD。 线下BD:通过见面…...

STM32_RTOS学习笔记——1(列表与列表项)
总体RTOS笔记目录 一,列表与列表项(本文) 二,待定 视频参考:B站野火 一,C语言列表概念 列表就是C语言中的链表,链表就如同下面的衣架一样,需要的各种内容可以参考 C语言链表可…...

子网划分案例
划分子网是将一个较大的网络划分为多个较小的子网,以提高网络管理和安全性 子网划分可以更有效地利用 IP 地址空间,并且有助于控制网络流量、提高网络性能和安全性。 子网划分的主要步骤如下: 确定需要划分的子网数量以及每个子网所需的主…...

javaweb_02:Maven
一、引入 在javaweb的开发中,需要使用大量的jar包,我们得手动去导入,而Maven可以自动帮我们导入和配置这个jar包。 二、Maven项目框架管理工具 核心思想:约定大于配置(有约束不违反):Maven会…...

19.延迟队列优化
问题 前面所讲的延迟队列有一个不足之处,比如现在有一个需求需要延迟半个小时的消息,那么就只有添加一个新的队列。那就意味着,每新增一个不同时间需求,就会新创建一个队列。 解决方案 应该讲消息的时间不要跟队列绑定…...

P10477 Subway tree systems 题解,c++ 树相关题目
题目 poj 链接 洛谷链接 n n n 组数据,每组数据给定两个 01 01 01 串(长度不超过 3000 3000 3000),意思如下: 对于每一个 0 0 0,代表该节点有一个子节点,并前往该子节点。对于每一个 1 1 …...

18.jdk源码阅读之CopyOnWriteArrayList
1. 写在前面 CopyOnWriteArrayList 是 Java 中的一种线程安全的 List 实现,基于“写时复制”(Copy-On-Write)机制。下面几个问题大家可以先思考下,在阅读源码的过程中都会解答: CopyOnWriteArrayList 适用于哪些场景…...

美股:AMD展现乐观前景,挑战AI加速器市场霸主
在科技行业的激烈竞争中,AMD公司近期发布了对当前季度收入的乐观预测,显示出其新推出 一、AMD第三季度营收预期超越分析师平均预期 AMD在周二的声明中预计,第三季度营收将达到约67亿美元,这一数字超出了分析师此前平均预期的66.…...

如何提高计算机视觉技术在复杂环境和低光照条件下的物体识别准确率?
要在复杂环境和低光照条件下提高计算机视觉技术的物体识别准确率,可以采取以下几个方法: 数据增强:在训练集中添加各种复杂环境和低光照条件下的图片,通过增加数据的多样性,使算法能够更好地适应各种场景。 预处理&am…...

ubuntu cmake使用自己版本的qt
给一篇文章参考 https://blog.csdn.net/bank_dreamer/article/details/138678909 自己使用的范例 set(Qt5_DIR "/home/peak/Qt5.14.0/5.14.0/gcc_64/lib/cmake/Qt5")# 设置Qt5的安装目录 #set(CMAKE_PREFIX_PATH "/home/peak/Qt5.14.0")find_package(Qt5…...

Python基础知识笔记---保留字
保留字,也称关键字,是指被编程语言内部定义并保留使用的标识符。 一、保留字概览 二、保留字用途 1. False:表示布尔值假。 2. None:表示空值或无值。 3. True:表示布尔值真。 4. not:布尔逻辑操作符…...

Python爬虫实战:requests + BeautifulSoup4采集经典标靶网站哲理名言,并导出结构化文件!
㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~ ㊙️本期爬虫难度指数:⭐ (入门级) 🉐福利: 一次订阅后,专栏内的所有文章…...

番茄小说下载器终极指南:三步打造你的私人数字图书馆
番茄小说下载器终极指南:三步打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时突然断网?或者想在地铁上继续阅读却发…...

【巴洛克AI生成合规白皮书】:基于梵蒂冈档案馆高清藏品训练的192个版权安全Prompt模板
更多请点击: https://codechina.net 第一章:巴洛克AI生成合规白皮书导论 巴洛克AI生成合规白皮书旨在为组织在部署和运营生成式人工智能系统时,提供一套可落地、可审计、可演进的合规治理框架。该白皮书聚焦于中国《生成式人工智能服务管理暂…...

选错bpp,你的App内存就炸了?聊聊图像格式、内存与性能的实战权衡
选错bpp,你的App内存就炸了?聊聊图像格式、内存与性能的实战权衡 在移动应用开发中,图像处理往往是性能瓶颈的重灾区。我曾见过一个社交类App因为图片加载策略不当,在低端设备上频繁触发OOM(内存溢出)崩溃。…...

避开DSP28335内存管理的坑:堆、栈、CMD文件配置全解析与最佳实践
DSP28335内存管理深度优化:从堆栈原理到CMD文件实战配置 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。对于基于TI C2000系列DSP28335的开发者而言,合理规划有限的内存资源不仅能提升系统性能,更能避免那些难以…...

【限时解密】ElevenLabs未公开的瑞典文语料权重配置表:仅限前200名开发者获取的/sv-SE/声道微调参数
更多请点击: https://codechina.net 第一章:瑞典文语音合成的技术背景与ElevenLabs架构定位 瑞典语作为北日耳曼语支的重要语言,拥有丰富的元音系统(9个长元音、9个短元音)、独特的声调重音(accent 1 和 a…...

为什么我强烈推荐大学生打CTF!看完你就懂了!
前言 写这个文章是因为我很多粉丝都是学生,经常有人问: 感觉大一第一个学期忙忙碌碌的过去了,啥都会一点,但是自己很难系统的学习到整个知识体系,很迷茫,想知道要如何高效学习。 这篇文章我主要就围绕两点…...

3步解锁百度文库纯净阅读:告别广告干扰的智能解决方案
3步解锁百度文库纯净阅读:告别广告干扰的智能解决方案 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否曾在百度文库找到宝贵资料却被广告栏、推荐模块和导航菜单包围,…...

2026企业网盘怎么选?十大产品深度测评:从合规到协作一次讲清
企业网盘已经不只是“存文件”这么简单了。2026年,远程办公常态化、数据合规持续收紧、企业开始把“文件”当作数字资产来治理——网盘也从“云端U盘”进化为企业数字资产管理的底座。 过去选网盘,很多企业只看容量和价格;现在真正拉开差距的…...
2026)
郑州市科技局:科技成果汇编(第01册)2026
这份文档是郑州市科学技术局 2026 年发布的第 1 期科技成果汇编,共收录112 项优质科技成果,覆盖装备制造、环境治理、新材料、电子信息、新能源与节能、生物医药、粮油食品、其他八大核心领域,由郑州大学、华北水利水电大学、河南工业大学等高…...