浅学爬虫-处理复杂网页
在处理实际项目时,网页通常比示例页面复杂得多。我们需要应对分页、动态加载和模拟用户行为等问题。以下是一些常见的场景及其解决方案。
处理分页
许多网站将内容分成多个页面,称为分页。要抓取这些数据,需要编写一个能够遍历所有分页的爬虫。
示例:抓取一个分页网站
假设我们要抓取一个分页网站,每页包含10条数据,分页链接的URL格式如下:
- 第一页:
http://example.com/page/1 - 第二页:
http://example.com/page/2 - 第三页:
http://example.com/page/3
步骤1:编写分页爬虫代码
import requests
from bs4 import BeautifulSoup# 基础URL
base_url = "http://example.com/page/"# 最大页码
max_page = 5for page in range(1, max_page + 1):url = f"{base_url}{page}"response = requests.get(url)if response.status_code == 200:soup = BeautifulSoup(response.content, 'html.parser')# 假设每条数据在class为'item'的div中items = soup.find_all('div', class_='item')for item in items:title = item.find('h2').textdescription = item.find('p').textprint(f"标题: {title}")print(f"描述: {description}")else:print(f"请求失败,状态码: {response.status_code}")代码解释:
- 基础URL: 设置分页网站的基础URL。
- 遍历页面: 使用
for循环遍历所有分页,生成每个分页的URL。 - 发送请求并解析页面: 使用
requests发送请求,使用BeautifulSoup解析页面。 - 提取数据: 假设每条数据在class为'item'的div中,提取数据并打印。
处理AJAX请求
一些网站通过AJAX(异步JavaScript和XML)加载数据,导致页面初始加载时看不到所有内容。要抓取这些数据,我们需要分析AJAX请求并直接请求相应的API。
示例:处理AJAX请求
假设我们要抓取一个通过AJAX请求加载的数据,AJAX请求的URL如下:
http://example.com/api/data?page=1http://example.com/api/data?page=2
步骤1:编写处理AJAX请求的爬虫代码
import requests
import json# 基础URL
api_url = "http://example.com/api/data"# 最大页码
max_page = 5for page in range(1, max_page + 1):params = {'page': page}response = requests.get(api_url, params=params)if response.status_code == 200:data = response.json()for item in data['items']:title = item['title']description = item['description']print(f"标题: {title}")print(f"描述: {description}")else:print(f"请求失败,状态码: {response.status_code}")代码解释:
- API URL: 设置AJAX请求的基础URL。
- 遍历页面: 使用
for循环遍历所有分页,生成每个分页的请求参数。 - 发送请求并解析响应: 使用
requests发送请求,解析JSON响应。 - 提取数据: 从响应数据中提取所需的信息并打印。
模拟用户行为
有些网站通过JavaScript动态生成内容,无法通过直接请求获取数据。这时我们可以使用Selenium模拟用户行为,抓取动态内容。
示例:使用Selenium模拟用户行为
步骤1:安装Selenium和浏览器驱动
pip install selenium步骤2:编写Selenium爬虫代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time# 设置浏览器驱动
driver = webdriver.Chrome()# 目标URL
url = "http://example.com"# 打开网页
driver.get(url)# 等待页面加载
time.sleep(5)# 查找元素并提取数据
items = driver.find_elements(By.CLASS_NAME, 'item')for item in items:title = item.find_element(By.TAG_NAME, 'h2').textdescription = item.find_element(By.TAG_NAME, 'p').textprint(f"标题: {title}")print(f"描述: {description}")# 关闭浏览器
driver.quit()代码解释:
- 设置浏览器驱动: 使用Selenium的Chrome驱动打开浏览器。
- 打开网页: 使用
driver.get方法打开目标URL。 - 等待页面加载: 使用
time.sleep等待页面加载完成。 - 查找元素并提取数据: 使用
driver.find_elements方法查找页面中的元素并提取数据。 - 关闭浏览器: 使用
driver.quit方法关闭浏览器。
结论
本文介绍了处理复杂网页的几种方法,包括处理分页、处理AJAX请求和模拟用户行为。这些技巧将帮助我们应对实际项目中的各种复杂场景。在下一篇文章中,我们将探讨更多高级的爬虫技术和优化方法。
相关文章:

浅学爬虫-处理复杂网页
在处理实际项目时,网页通常比示例页面复杂得多。我们需要应对分页、动态加载和模拟用户行为等问题。以下是一些常见的场景及其解决方案。 处理分页 许多网站将内容分成多个页面,称为分页。要抓取这些数据,需要编写一个能够遍历所有分页的爬…...

nginx反向代理严重错误[crit] (13: Permission denied) while reading upstream问题
nginx作为使用最广泛的一款反向代理软件,其性能也是非常优秀的,一般情况下,直接配置就可以使用,而且也都是稳定高效的,但是在实际应用中,对于不同的应用场景,总是会出现各种各样的问题ÿ…...

精通Python爬虫中的XPath:从安装到实战演示
🔸 插件安装 首先,我们需要安装用于处理XPath的库lxml。在命令行中运行以下命令: pip install lxml🔹 lxml是一个强大的库,支持XPath查询和XML处理,是爬虫开发中的重要工具。 🔸 DOM节点学习 …...

redis的使用场景
目录 1. 热点数据缓存 1.1 什么是缓存? 1.2 缓存的原理 1.3 什么样的数据适合放入缓存中 1.4 哪个组件可以作为缓存 1.5 java使用redis如何实现缓存功能 1.5.1 需要的依赖 1.5.2 配置文件 1.5.3 代码 1.5.4 发现 1.6 使用缓存注解完成缓存功能 2. 分布式锁…...
的各种方法以及时间差的计算方法)
记录new Date()的各种方法以及时间差的计算方法
new Date().toLocaleDateString() —— 2024/8/2new Date().toLocaleTimeString() —— 10:21:48new Date().toLocaleString() —— 2024/8/2 10:21:48new Date().toLocaleDateString() —— Fri Aug 02 2024new Date().toDateString() —— Fri Aug 02 2024new Date…...
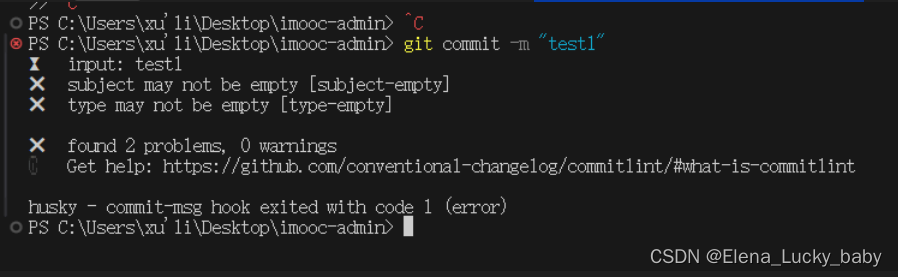
vue项目创建+eslint+Prettier+git提交规范(commitizen+hooks+husk)
# 步骤 1、使用 vue-cli 创建项目 这一小节我们需要创建一个 vue3 的项目,而创建项目的方式依然是通过 vue-cli 进行创建。 不过这里有一点大家需要注意,因为我们需要使用最新的模板,所以请保证你的 vue-cli 的版本在 4.5.13 以上ÿ…...

从Docker拉取镜像一直失败超时?这些解决方案帮你解决烦恼
设置国内源: 提示:常规方案(作用不大) 阿里云提供了镜像源:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors 登录后你会获得一个专属的地址 使用命令设置国内镜像源:通过vim /etc/docker/d…...

R语言大尺度空间数据分析模拟预测及可视化:地统计与空间自相关、空间数据插值、机器学习空间预测、空间升降尺度、空间模拟残差订正、空间制图等
目录 专题一 R语言空间数据介绍及数据挖掘关键技术 专题二 R语言空间数据高级处理技术 专题三 R语言多维时空数据处理技术、数据清洗整合和时间序列分析 专题四 R语言地统计与空间自相关、空间插值方法 专题五 R语言机器学习与空间模型预测及不确定性评估 专题六 R语言空…...

深入理解Java内存管理机制
Java内存管理是Java开发中一个至关重要的主题。理解内存管理机制不仅有助于编写高效的代码,还可以帮助我们避免常见的内存问题,如内存泄漏和内存不足。本篇博客将详细介绍Java内存管理机制,并通过代码示例帮助读者更好地理解这一过程。 1. J…...
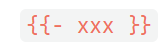
Helm 学习之路,一文弄懂
1. 什么是 Helm 1.1 概述 Helm 是 Kubernetes 应用程序的包管理器,和redhat中yum 管理包类似. 1.2 架构图v3 1.3 下载 官当 最新版本 官方github curl -LO https://get.helm.sh/helm-v3.15.2-linux-amd64.tar.gz 1.4 安装 解压 #由于是二进制,直接解压到/usr/local/b…...

【面试题解答】一个有序数组 nums ,原地删除重复出现的元素
面试题解答 仅供学习 文章目录 面试题解答题目一、python代码1.1 代码1.2 示例用法1.2.1 示例11.2.2 示例2 二、讲解2.1 初始化2.2 遍历2.3 返回 题目 要解决这个问题,可以使用双指针方法进行原地修改,以确保每个元素最多出现两次。 一、python代码 1.1…...

【数据结构算法经典题目刨析(c语言)】随机链表的复制(图文详解)
💓 博客主页:C-SDN花园GGbond ⏩ 文章专栏:数据结构经典题目刨析(c语言) 目录 一、题目描述 二、思路分析 三、代码实现 一、题目描述 二、思路分析 要完成一个带随机指针的链表的复制,有一个巧妙的办法:分三步走 1.完成节…...

cqyjldfx
CVE-2023-27179 靶标介绍: GDidees CMS v3.9.1及更低版本被发现存在本地文件泄露漏洞,漏洞通过位于 /_admin/imgdownload.php 的 filename 参数进行利用。攻击者可以通过向 filename 参数传递恶意输入来下载服务器上的任意文件。 提示有本地文件泄露&a…...

大数据——HBase原理
摘要 HBase 是一个开源的、非关系型的分布式数据库系统,主要用于存储海量的结构化和半结构化数据。它是基于谷歌的 Bigtable 论文实现的,运行在 Hadoop 分布式文件系统(HDFS)之上,并且可以与 Hadoop 生态系统的其他组…...
《电视技术》是什么级别的期刊?是正规期刊吗?能评职称吗?
问题解答 问:《电视技术》是不是核心期刊? 答:不是,是知网收录的第一批认定学术期刊。 问:《电视技术》级别? 答:国家级。主管单位:中国电子科技集团公司 主办单位ÿ…...

网络编程 --------- 2、socket网络编程接口
1、什么是socket 套接字 socke套接字是一个编程的接口 (网络编程的接口)、是一种特殊的文件描述符 (read/write),不局限于TCP/IP 。socket是独立于具体协议的网络编程接口这个接口是位于 应用层和传输层之间 。 类型: (1)流式套接字 SOCK_ST…...

C# Deconstruct详解
总目录 前言 该文来源于探索弃元的使用,由弃元了解到元组,由元组又了解到解构方法Deconstruct。 另外本文中 解构和析构一个意思,不要在意! 一、Deconstruct是什么? 1. 关于元组 如果我们想了解Deconstruct 的使用&…...

Java 面试常见问题之——为什么重写equals时必须重写hashCode方法
Java 面试常见问题之——为什么重写equals时必须重写hashCode方法 当重写 equals 方法时,通常也应该重写 hashCode 方法,原因主要有以下几点: 一致性原则:根据 Java 的约定,如果两个对象通过 equals 方法比较返回 tr…...

后端给的树形结构 递归 改造成阶联选择器所需要的lable、value结构
赋值:this.newTreeData this.renameFields(this.treeData) 递归方法:renameFields (tree) {return tree.map(node > {// 创建一个新对象来存放修改后的字段名const newNode {value: node.id,label: node.title,// 如果有子节点,则递归处理…...

文献阅读:基于拓扑结构模型构建ICI收益诊断模型
介绍 Custom scoring based on ecological topology of gut microbiota associated with cancer immunotherapy outcome是来自法国Gustave Roussy Cancer Campus的Laurence Zitvogel实验室最近发表在cell的关于使用肠道微生物拓扑结构预测免疫治疗疗效的文章。 该研究提供基于…...

Python爬虫项目架构解析:从Requests到数据清洗的工程化实践
1. 项目概述:一个Python驱动的自动化数据采集与分析工具最近在GitHub上看到一个挺有意思的项目,叫Niceck/hhxg-top-hhxg-python。光看这个仓库名,可能有点摸不着头脑,但点进去研究一下就会发现,这其实是一个用Python编…...

从新手到老手:四类Ozon卖家选品工具选择指南
选品工具没有“最好”,只有“最匹配你当前阶段”。四类卖家,四种方案。市面上的Ozon选品工具,功能各有侧重。有的擅长给数据,有的擅长给结论,有的擅长管店铺。不同阶段的卖家,痛点不同,适合的工…...
)
Serverless平台为何总让人“又爱又恨”?揭秘Lovable设计的3层情感化架构(开发者体验×运维韧性×业务敏捷)
更多请点击: https://intelliparadigm.com 第一章:Serverless平台为何总让人“又爱又恨”? Serverless 架构在现代云原生开发中已成为主流选择,它承诺“无需管理服务器”,让开发者专注业务逻辑。然而,在真…...

DLP Pico技术与近眼显示系统设计解析
1. DLP Pico技术解析:微镜阵列如何重塑显示未来 在2014年,德州仪器(TI)推出了一项颠覆性的显示技术——基于DLP TRP架构的Pico芯片组。这项技术的核心是一块布满微小铝镜的芯片,每个微镜尺寸仅5.4微米,比人类头发直径的十分之一还…...

【AI工具推荐】Awesome DESIGN.md - 让AI生成像素级完美UI的设计神器
有兴趣的朋友,点点关注。每天分享一个AI工具。每天分享一个AI工具,今天推荐:Awesome DESIGN.md - 一个让AI代理能够生成像素级完美UI的开源设计系统集合项目简介 Awesome DESIGN.md 是一个精心策划的DESIGN.md文件集合,灵感来源于…...

Cerebro:为AI构建持久记忆与认知能力的本地化MCP工具系统
1. 项目概述:为AI赋予持久记忆与认知能力如果你和我一样,每天都在和Claude、ChatGPT这类大语言模型打交道,那你一定遇到过这个让人头疼的问题:每次开启一个新的对话会话,AI就像得了“健忘症”,之前聊过的项…...

Articuler.Ai 技术深度解析:海量人脉匹配、数字足迹解析与高转化冷触达引擎
摘要Articuler.Ai 是一款面向商业人脉精准匹配与高效触达的 AI 引擎,核心定位为 “商业关系搜索引擎 智能触达工作台”,彻底重构传统关键词搜索失效背景下的 B2B 人脉连接逻辑。本文从9.8 亿级公开档案数据底座、语义匹配引擎架构、Playbook 深度解析技…...
)
告别底噪与失真:手把手教你用STM32 I2C驱动WM8988音频Codec(附完整寄存器配置代码)
嵌入式音频开发实战:WM8988音质优化全攻略 在嵌入式音频系统开发中,WM8988作为一款高性能低功耗的音频编解码芯片,因其出色的音质表现和灵活的配置选项,成为众多开发者的首选。然而,很多工程师在完成基础驱动后&#x…...
)
Sora 2与3D Gaussian结合实战指南(工业级部署避坑手册)
更多请点击: https://intelliparadigm.com 第一章:Sora 2与3D Gaussian结合的工业级部署全景图 Sora 2作为OpenAI新一代视频生成模型,在长时序建模与物理一致性方面取得显著突破;而3D Gaussian Splatting(3DGS&#x…...

谷歌seo如何发布外链? 推荐3个外贸SOHO全自动工具
身处外贸圈的人都明白,空有一身好产品,网站在谷歌搜不到也是白搭。现在的算法比五年前聪明太多,靠那种五块钱一千条的群发软件纯属给自己的域名“投毒”。我在操作几十个独立站的过程中发现,外链的数量早就不吃香了,现…...