【课程总结】Day18:Seq2Seq的深入了解
前言
在上一章【课程总结】Day17(下):初始Seq2Seq模型中,我们初步了解了Seq2Seq模型的基本情况及代码运行效果,本章内容将深入了解Seq2Seq模型的代码,梳理代码的框架图、各部分组成部分以及运行流程。
框架图
工程目录结构
查看项目目录结构如下:
seq2seq_demo/
├── data.txt # 原始数据文件,包含训练或测试数据
├── dataloader.py # 数据加载器,负责读取和预处理数据
├── decoder.py # 解码器实现,用于生成输出序列
├── encoder.py # 编码器实现,将输入序列编码为上下文向量
├── main.py # 主程序入口,执行模型训练和推理
├── seq2seq.py # seq2seq 模型的实现,整合编码器和解码器
└── tokenizer.py # 分词器实现,将文本转换为模型可处理的格式
查看各个py文件整理关系图结构如下:
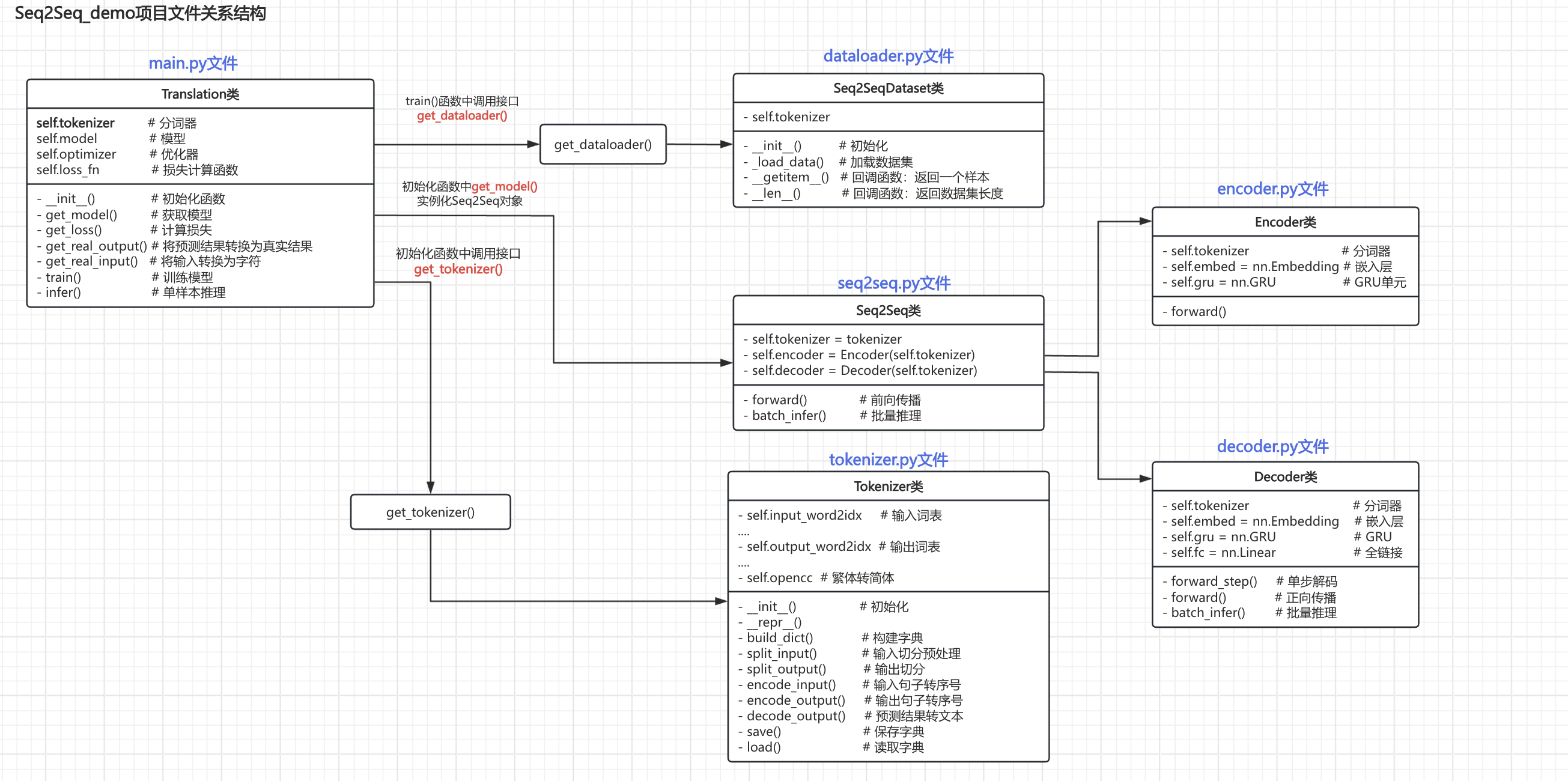
main.py文件是主程序入口,同时其中也定义了Translation类,用于训练和推理。Translation类在__init__()方法中调用get_tokenizer()方法实例化tokenizer对象。Translation类在__init__()方法中调用get_model()实例化seq2seq类对象,进而实例化Encoder和Decoder对象。Translation类在train()方法中调用get_dataloader()方法实例化dataloader对象。
核心逻辑
初始化过程
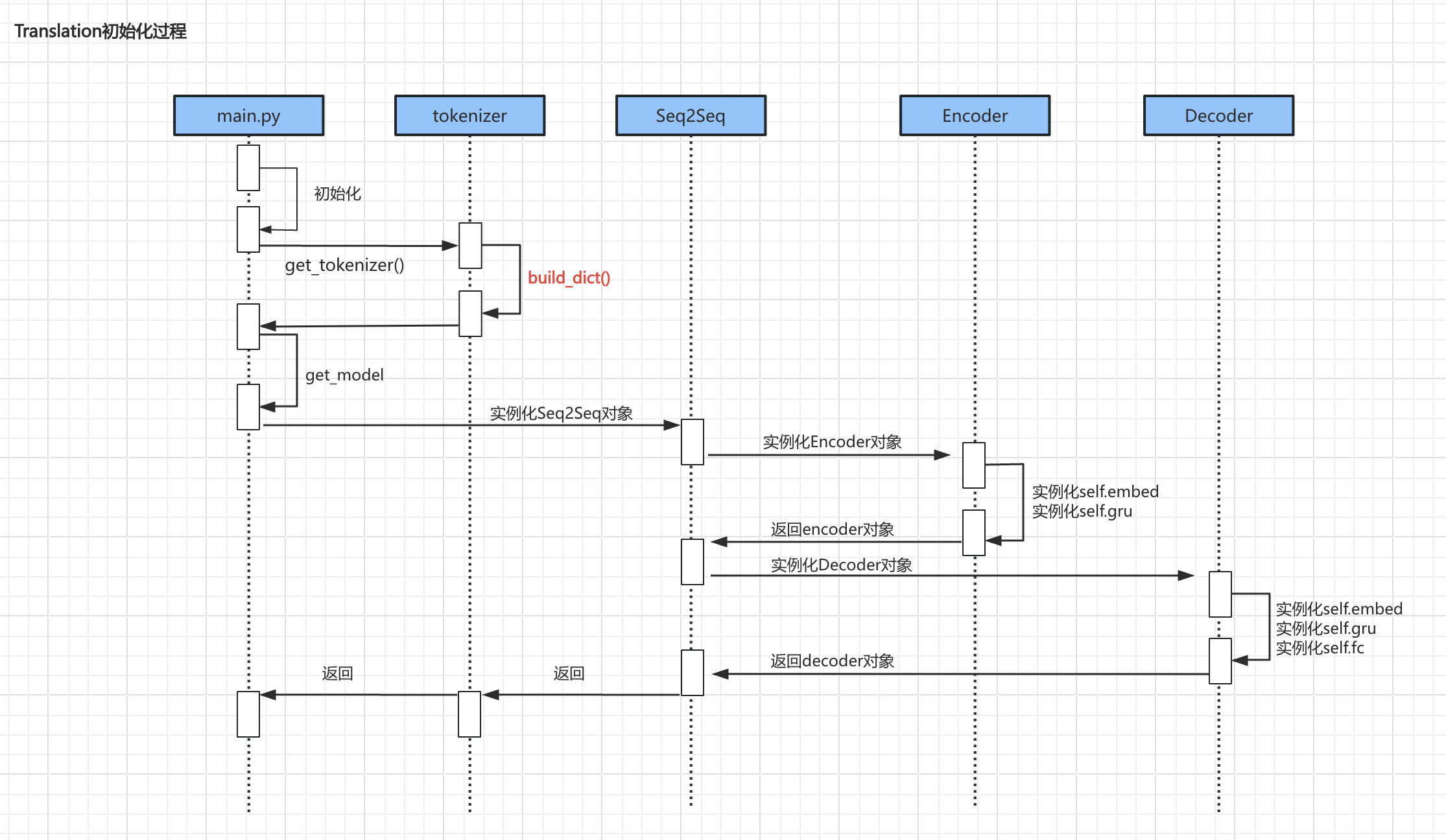
- 上述流程中较为重要的代码主要是
build_dict()、encoder实例化、decoder实例化初始化过程:
Build_dict()
def build_dict(self):"""构建字典"""if os.path.exists(self.saved_dict):self.load()print("加载本地字典成功")returninput_words = {"<UNK>", "<PAD>"}output_words = {"<UNK>", "<PAD>", "<SOS>", "<EOS>"}with open(file=self.data_file, mode="r", encoding="utf8") as f:for line in tqdm(f.readlines()):if line:input_sentence, output_sentence = line.strip().split("\t")input_sentence_words = self.split_input(input_sentence)output_sentence_words = self.split_output(output_sentence)input_words = input_words.union(set(input_sentence_words))output_words = output_words.union(set(output_sentence_words))# 输入字典self.input_word2idx = {word: idx for idx, word in enumerate(input_words)}self.input_idx2word = {idx: word for word, idx in self.input_word2idx.items()}self.input_dict_len = len(self.input_word2idx)# 输出字典self.output_word2idx = {word: idx for idx, word in enumerate(output_words)}self.output_idx2word = {idx: word for word, idx in self.output_word2idx.items()}self.output_dict_len = len(self.output_word2idx)# 保存self.save()print("保存字典成功")
代码解析:
- 首先,判断本地是否有字典,有的话直接加载;
- 其次,在
input_words和output_words集合中添加特殊符号(special tokens):<UNK>:表示未知单词,用于表示输入序列中未在字典中找到的单词;<PAD>:表示填充符号,用于填充输入序列和输出序列,使它们具有相同的长度;<SOS>:表示序列的开始,用于表示输出序列的起始位置;<EOS>:表示序列的结束,用于表示输出序列的结束位置。
- 然后,读取data.txt文件,以\t切分数据并切分单词:
- 输入的英文调用
split_input进行预处理,例如:I’m a student.→[‘i’, ‘m’, ‘a’, ‘student’, ‘.’] - 输出的中文调用
split_output进行切分,例如:我爱北京天安门→[‘我’, ‘爱’, ‘北京’, ‘天安门’]
- 输入的英文调用
- 最后,调用
self.save()方法将字典保存到本地文件self.saved_dict中。
encoder
import torch
from torch import nnclass Encoder(nn.Module):"""定义一个 编码器"""def __init__(self, tokenizer):super(Encoder, self).__init__()self.tokenizer = tokenizer# 嵌入层self.embed = nn.Embedding(num_embeddings=self.tokenizer.input_dict_len,embedding_dim=self.tokenizer.input_embed_dim,padding_idx=self.tokenizer.input_word2idx.get("<PAD>"))# GRU单元self.gru = nn.GRU(input_size=self.tokenizer.input_embed_dim,hidden_size=self.tokenizer.input_hidden_size,batch_first=False)def forward(self, x, x_len):# [seq_len, batch_size] --> [seq_len, batch_size, embed_dim]x = self.embed(x)# 压紧被填充的序列x = nn.utils.rnn.pack_padded_sequence(input=x,lengths=x_len,batch_first=False)out, hn = self.gru(x)# 填充被压紧的序列out, out_len = nn.utils.rnn.pad_packed_sequence(sequence=out,batch_first=False,padding_value=self.tokenizer.input_word2idx.get("<PAD>"))# out: [seq_len, batch_size, hidden_size]# hn: [1, batch_size, hidden_size]return out, hn
代码解析:
- encoder是一个典型的RNN结构,其定义了embedding层用于词嵌入,以及GRU单元进行序列处理。
- 在
forward方法中,首先将输入序列进行词嵌入,然后使用pack_padded_sequence将被填充的序列压紧,以便于GRU单元处理。
decoder
import torch
from torch import nn
import randomdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")class Decoder(nn.Module):def __init__(self, tokenizer):super(Decoder, self).__init__()self.tokenizer = tokenizer# 嵌入self.embed = nn.Embedding(num_embeddings=self.tokenizer.output_dict_len,embedding_dim=self.tokenizer.output_embed_dim,padding_idx=self.tokenizer.output_word2idx.get("<PAD>"),)# 抽取特征self.gru = nn.GRU(input_size=self.tokenizer.output_embed_dim,hidden_size=self.tokenizer.output_hidden_size,batch_first=False,)# 转换维度,做概率输出self.fc = nn.Linear(in_features=self.tokenizer.output_hidden_size,out_features=self.tokenizer.output_dict_len,)def forward_step(self, decoder_input, decoder_hidden):"""单步解码:decoder_input: [1, batch_size]decoder_hidden: [1, batch_size, hidden_size]"""# [1, batch_size] --> [1, batch_size, embedding_dim]decoder_input = self.embed(decoder_input)# 输入:[1, batch_size, embedding_dim] [1, batch_size, hidden_size]# 输出:[1, batch_size, hidden_size] [1, batch_size, hidden_size]# 因为只有1步,所以 out 跟 decoder_hidden是一样的out, decoder_hidden = self.gru(decoder_input, decoder_hidden)# [batch_size, hidden_size]out = out.squeeze(dim=0)# [batch_size, dict_len]out = self.fc(out)# out: [batch_size, dict_len]# decoder_hidden: [1, batch_size, hidden_size]return out, decoder_hiddendef forward(self, encoder_hidden, y, y_len):"""训练时的正向传播- encoder_hidden: [1, batch_size, hidden_size]- y: [seq_len, batch_size]- y_len: [batch_size]"""# 计算输出的最大长度(本批数据的最大长度)output_max_len = max(y_len.tolist()) + 1# 本批数据的批量大小batch_size = encoder_hidden.size(1)# 输入信号 SOS 读取第0步,启动信号# decoder_input: [1, batch_size]# 输入信号 SOS [1, batch_size]decoder_input = torch.LongTensor([[self.tokenizer.output_word2idx.get("<SOS>")] * batch_size]).to(device=device)# 收集所有的预测结果# decoder_outputs: [seq_len, batch_size, dict_len]decoder_outputs = torch.zeros(output_max_len, batch_size, self.tokenizer.output_dict_len)# 隐藏状态 [1, batch_size, hidden_size]decoder_hidden = encoder_hidden# 手动循环for t in range(output_max_len):# 输入:decoder_input: [batch_size, dict_len], decoder_hidden: [1, batch_size, hidden_size]# 返回值:decoder_output_t: [batch_size, dict_len], decoder_hidden: [1, batch_size, hidden_size]decoder_output_t, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)# 填充结果张量 [seq_len, batch_size, dict_len]decoder_outputs[t, :, :] = decoder_output_t# teacher forcing 教师强迫机制use_teacher_forcing = random.random() > 0.5# 0.5 概率 实行教师强迫if use_teacher_forcing:# [1, batch_size] 取标签中的下一个词decoder_input = y[t, :].unsqueeze(0)else:# 取出上一步的推理结果 [1, batch_size]decoder_input = decoder_output_t.argmax(dim=-1).unsqueeze(0)# decoder_outputs: [seq_len, batch_size, dict_len]return decoder_outputs# ...(其他函数暂略)
代码解析:
- decoder定义了三个层:embed(词嵌入)、gru和fc(全链接层)。
- 全链接层用于输出的是字典长度,即每个位置代表着每个字的概率。
- decoder的forward_step方法,用于一步一步地执行,属于手动循环;forward方法,把所有步都执行完进行推理,属于自动循环。
- 在
forward方法中:- 首先,计算本批数据的最大长度(用于标签对齐)
- 其次,使用
encoder_hidden.size(1)获取批量大小 - 然后,增加启动信号,即
<SOS> - 然后,准备全0的张量
decoder_outputs - 然后,开始循环
- 在循环每一步中,将输入和隐藏状态传给forward_step进行处理,得到输出概率
decoder_output_t - 将结果概率放在
decoder_outputs中 - 启用教师强迫机制(teacher forcing):
- 即有50%概率,使用标准答案作为下一步的输入;
- 否则,使用上一步的推理结果中概率最大的词作为下一步的输入。
- 在循环每一步中,将输入和隐藏状态传给forward_step进行处理,得到输出概率
- 最后,返回结果概率张量
decoder_outputs
训练过程
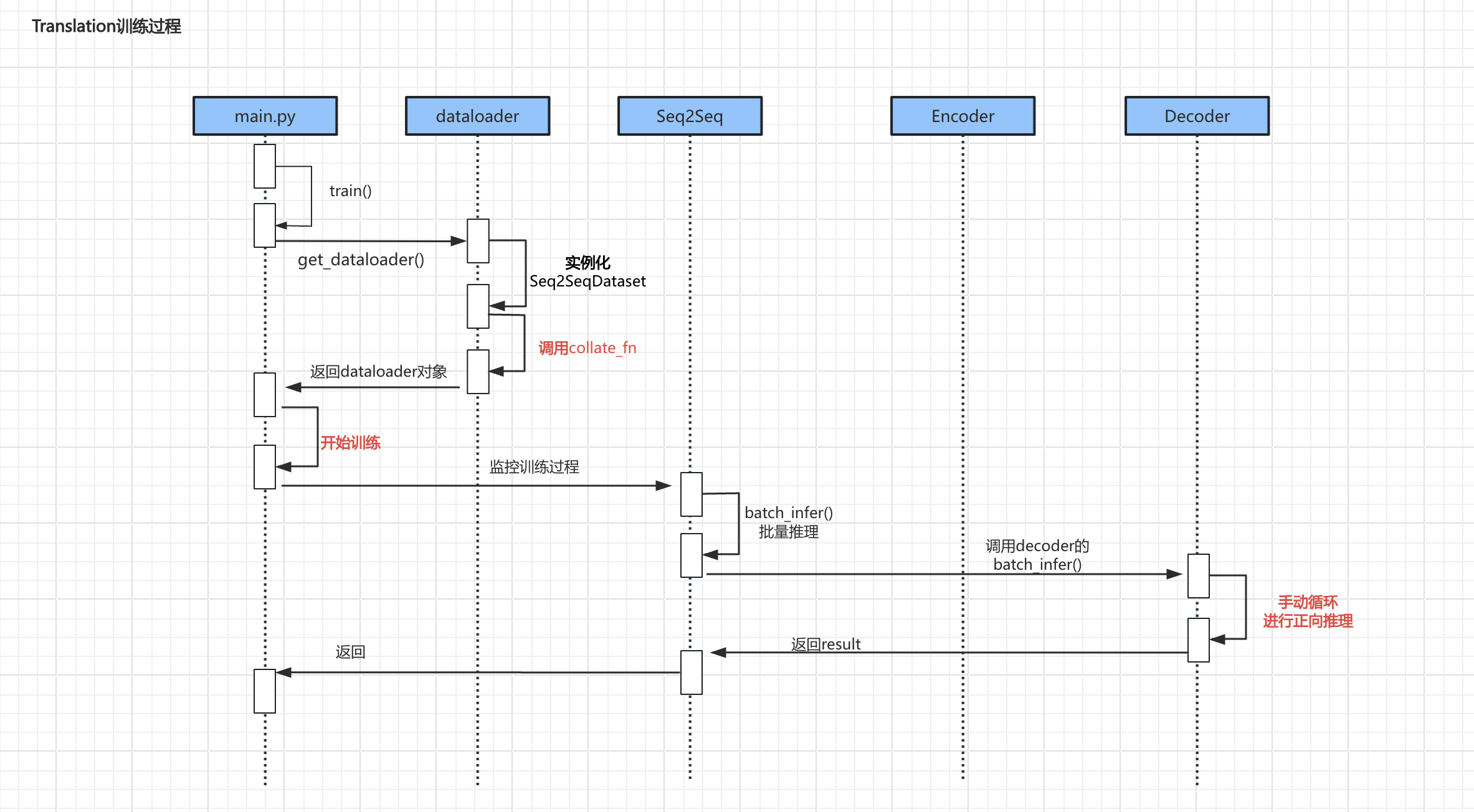
- 上述流程中较为重要的代码主要是
调用collate_fn、具体训练过程、手动循环进行正向推理
调用collate_fn
def collate_fn(batch, tokenizer):# 根据 x 的长度来 倒序排列batch = sorted(batch, key=lambda ele: ele[1], reverse=True)# 合并整个批量的每一部分input_sentences, input_sentence_lens, output_sentences, output_sentence_lens = zip(*batch)# 转索引【按本批量最大长度来填充】input_sentence_len = input_sentence_lens[0]input_idxes = []for input_sentence in input_sentences:input_idxes.append(tokenizer.encode_input(input_sentence, input_sentence_len))# 转索引【按本批量最大长度来填充】output_sentence_len = max(output_sentence_lens)output_idxes = []for output_sentence in output_sentences:output_idxes.append(tokenizer.encode_output(output_sentence, output_sentence_len))# 转张量 [seq_len, batch_size]input_idxes = torch.LongTensor(input_idxes).t()output_idxes = torch.LongTensor(output_idxes).t()input_sentence_lens = torch.LongTensor(input_sentence_lens)output_sentence_lens = torch.LongTensor(output_sentence_lens)return input_idxes, input_sentence_lens, output_idxes, output_sentence_lens
代码解析:
- 当文字长度不一样齐的时候,需要进行补充<PAD>,以保持所有序列长度一致
例如:
I’m a student.
I’m OK.
Here is your change.
- 但是补充<PAD>本身对训练过程会造成干扰,所以我们需要采用一种机制:既保证对齐数据批量化训练,又能消除填充对训练过程的影响。
- 这种机制原理:在训练时知道实际的数据长度,这样在训练时就可以略过<PAD>。
- torch提供了相应的API,其大致过程是:
- 首先,根据 x(上句) 的长度倒序排序
- 其次,获取本批量最大的长度
- 然后,将数据填充到本批量最大长度
- 最后,在返回数据时,不知返回数据,还会带着真实长度
具体训练过程
# (其他部分代码略)# 训练过程is_complete = Falsefor epoch in range(self.epochs):self.model.train()for batch_idx, (x, x_len, y, y_len) in enumerate(train_dataloader):x = x.to(device=self.device)y = y.to(device=self.device)results = self.model(x, x_len, y, y_len)loss = self.get_loss(decoder_outputs=results, y=y)# 简单判定一下,如果损失小于0.5,则训练提前完成if loss.item() < 0.3:is_complete = Trueprint(f"训练提前完成, 本批次损失为:{loss.item()}")breakloss.backward()self.optimizer.step()self.optimizer.zero_grad()# 过程监控with torch.no_grad():if batch_idx % 100 == 0:print(f"第 {epoch + 1} 轮 {batch_idx + 1} 批, 当前批次损失: {loss.item()}")x_true = self.get_real_input(x)y_pred = self.model.batch_infer(x, x_len)y_true = self.get_real_output(y)samples = random.sample(population=range(x.size(1)), k=2)for idx in samples:print("\t真实输入:", x_true[idx])print("\t真实结果:", y_true[idx])print("\t预测结果:", y_pred[idx])print("\t----------------------------------------------------------")# 外层提前退出if is_complete:# print("训练提前完成")break# 保存模型torch.save(obj=self.model.state_dict(), f="./model.pt")
手动循环进行正向推理
#(其他部分略)def batch_infer(self, encoder_hidden):"""推理时的正向传播- encoder_hidden: [1, batch_size, hidden_size]"""# 推理时,设定一个最大的固定长度output_max_len = self.tokenizer.output_max_len# 获取批量大小batch_size = encoder_hidden.size(1)# 输入信号 SOS [1, batch_size]decoder_input = torch.LongTensor([[self.tokenizer.output_word2idx.get("<SOS>")] * batch_size]).to(device=device)# print(decoder_input)results = []# 隐藏状态# encoder_hidden: [1, batch_size, hidden_size]decoder_hidden = encoder_hiddenwith torch.no_grad():# 手动循环for t in range(output_max_len):# decoder_input: [1, batch_size]# decoder_hidden: [1, batch_size, hidden_size]decoder_output_t, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)# 取出结果 [1, batch_size]decoder_input = decoder_output_t.argmax(dim=-1).unsqueeze(0)results.append(decoder_input)# [seq_len, batch_size]results = torch.cat(tensors=results, dim=0)return results
代码解析:
- 相比训练的时候,推理的时候函数入参没有
y标准答案。 - 推理的过程:
- (与训练类似)获取最大长度、获取批量大小、构建启动信号。
- (与训练不同)在无梯度环境里,调用
forward_step函数,进行循环推理。 - (与训练不同)因为推理时不需要teacher forcing机制,所以直接使用贪心思想获得概率最大的词。
- 循环结束后,将结果拼接起来,返回。
补充知识
tqdm
定义
tqdm 是一个用于在 Python 中显示进度条的库,非常适合在长时间运行的循环中使用。
安装方法
pip install tqdm
使用方法
from tqdm import tqdm
import time# 示例:在一个简单的循环中使用 tqdm
for i in tqdm(range(10)):time.sleep(1) # 模拟某个耗时操作
运行结果:

OpenCC
定义
OpenCC(Open Chinese Convert)是一个用于简体中文和繁体中文之间转换的工具
安装方法
pip install OpenCC
使用方法
import opencc# 创建转换器,使用简体到繁体的配置
converter = opencc.OpenCC('s2t') # s2t: 简体到繁体# 输入简体中文
simplified_text = "我爱编程"# 进行转换
traditional_text = converter.convert(simplified_text)print(traditional_text)
# 输出结果:我愛編程
内容小结
- Seq2Seq项目整体组成由tokenizer(分词器)、dataloader(数据加载)、encoder(编码器)、decoder(解码器)、seq2seq和main六个部分组成
- 在分词器中重点工作是构建自定义字典,并添加特殊符号(special tokens)
<UNK>:表示未知单词,用于表示输入序列中未在字典中找到的单词;<PAD>:表示填充符号,用于填充输入序列和输出序列,使它们具有相同的长度;<SOS>:表示序列的开始,用于表示输出序列的起始位置;上文不会增加。<EOS>:表示序列的结束,用于表示输出序列的结束位置,上文不会增加。
- 在decoder的
forward函数中,增加了一个teacher_forcing_ratio参数,用于控制是否使用教师强迫机制。- 有50%概率,使用标准答案作为下一步的输入;
- 有50%概率,使用上一步的推理结果中概率最大的词作为下一步的输入。
- 该机制用于提升训练速度。
- 在训练过程中会使用
collate_fn用于数据对齐时消除PAD的影响。
参考资料
(暂无)
相关文章:
【课程总结】Day18:Seq2Seq的深入了解
前言 在上一章【课程总结】Day17(下):初始Seq2Seq模型中,我们初步了解了Seq2Seq模型的基本情况及代码运行效果,本章内容将深入了解Seq2Seq模型的代码,梳理代码的框架图、各部分组成部分以及运行流程。 框…...

C++利用开发人员命令提示工具查看对象模型
1.跳转文件路径 cd 具体路径 2.输入c1 /d1 reportSingleClassLayout类名 文件名 操作示例如下图:...

白骑士的PyCharm教学高级篇 3.4 服务器部署与配置
系列目录 上一篇:白骑士的PyCharm教学高级篇 3.3 Web开发支持 在开发完成后,将代码部署到服务器上是一个关键步骤。PyCharm不仅提供了强大的本地开发支持,还为远程服务器配置与部署、自动化部署流程提供了便捷的工具和功能。本文将详细介绍如…...
数据库管理-第226期 内存至超线程(20240805)
数据库管理226期 2024-08-05 数据库管理-第226期 内存至超线程(20240805)1 CPU内缓存结构2 缓存与内存3 单核单线程4 超线程5 超线程的利弊总结 数据库管理-第226期 内存至超线程(20240805) 作者:胖头鱼的鱼缸…...

Django学习-数据迁移与数据导入导出
文章目录 一、数据迁移二、数据导入导出1. 数据导出2. 数据导入 一、数据迁移 数据迁移是将项目里定义的模型生成相应的数据表。主要的迁移指令如下: # 第一次生成自定义模型与django admin自带模型迁移文件,后续只生成新增模型迁移文件。后面加App名…...

【Nuxt】编程式导航和动态路由
编程式导航 navigateTo: 更多用法:navigateTo <template><div class"app-container"><button click"goToCategory">Category</button><NuxtPage/></div> </template> <script setup&…...

14. 计算机网络HTTPS协议(二)
1. 前言 上一章节中我们主要就 HTTPS 协议的前置知识进行介绍,下面会继续介绍 HTTPS 的通信过程以及抛出一些常见问题的探讨。因为候选人准备面试的时间和精力是比较有限的,我们在学习的过程要抓住重点,如果感觉对于细节缺乏了解,可以通过维基百科和查阅 StackOverflow 等…...

【算法设计题】实现以字符串形式输入的简单表达式求值,第2题(C/C++)
目录 第2题 实现以字符串形式输入的简单表达式求值 得分点(必背) 题解 1. 初始化和变量定义 2. 获取第一个数字并存入队列 3. 遍历表达式字符串,处理运算符和数字 4. 初始化 count 并处理加减法运算 代码详解 🌈 嗨…...

Kylin系列-入门
Kylin系列-入门 Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力,以支持超大规模数据。以下是对Kylin系列的入门介绍: 一、基本概念 1. 定义 Apache Kylin是由eBa…...

力扣-46.全排列
刷力扣热题–第二十六天:46.全排列 新手第二十六天 奋战敲代码,持之以恒,见证成长 1.题目简介 2.题目解答 这道题目想了会,思路比较好想,但一直没调试成功,所以就参考了力扣官网的代码,积累一下回溯算法的实现和基本实现思路,即先试探后回溯,结果在下面…...

博物馆展厅AI交互数字人,解锁创新的文化交互体验
在智能化时代,博物馆展厅融入AI交互数字人,可以为游客给予实时交互的旅游服务,AI交互数字人可以承担智能引导、讲解、接待、客服与导游等多重角色,为游客塑造崭新的旅游体验。 AI交互数字人相比传统的录屏解说相比,AI…...

DS18B20数字温度传感器操作解析
文章目录 引言特点工作原理引脚说明配置寄存器温度寄存器时序初始化时序写时序读时序 引言 DS18B20 是一种广泛使用的数字温度传感器,具有高精度和易用性。是Dallas Semiconductor公司(现为Maxim Integrated公司)生产的单总线数字温度传感器…...

你的财富正在被一个叫做通货膨胀的怪兽给吞噬掉,你却浑然不觉。
据统计,2024年全球总体通货膨胀率预计达到5.8%,这意味着:你的财富正在被一个叫做通货膨胀的怪兽给吞噬掉,你却浑然不觉。 数据来源:国际货币基金组织 如何跑赢通货膨胀? 家庭财富的积累速度,要…...

医疗设备漏费控制管理系统的必然性及未来发展性
医疗设备控费的必然性 医疗改革的要求 随着医疗改革的不断深入,原有的医药模式已经发生了改变。药品和耗材零差价的执行,使得医院需要寻找新的开源节流、降耗增效的方法。医疗设备控费系统的出现,正是为了满足这种管理需求。 控制成本和优…...

软件设计师笔记-网络基础知识
计算机网络的发展 计算机网络(计算机技术通信技术)的发展是一个逐步演进的过程,从简单的具有通信功能的单机系统,到复杂的以局域网及因特网为支撑环境的分布式计算机系统,这一历程经历了多个关键阶段: #me…...

MMC和eMMC的区别
MMC 和 eMMC 的区别 1. MMC MMC(MultiMediaCard)是一种接口协议,定义了符合这一接口的内存器,称为 MMC 储存体或 MMC 卡。它是一种非易失性存储器件,广泛应用于消费类电子产品中。 1.1 外观及引脚定义 MMC卡共有七个…...

亚马逊爬虫(Amazonbot)IP地址,真实采集数据
一、数据来源: 1、这批亚马逊爬虫(Amazonbot)IP来源于尚贤达猎头公司网站采集数据; 2、数据采集时间段:2023年10月-2024年7月; 3、判断标准:主要根据用户代理是否包含“Amazonbot”和IP核…...
:集成Thumbnailator来生成缩略图)
Spring Boot(八十四):集成Thumbnailator来生成缩略图
1 Thumbnailator简介 Thumbnailator是一个用于Java的缩略图生成库。通过Thumbnailator提供的流畅接口(fluent interface)的方式可以完成复杂的缩略图处理任务,无需访问Image I/O API并通过Graphics2D对象手动操作BufferedImages。 2 代码示例 2.1 引入依赖 <dependency&g…...

MySQL基础操作全攻略:增删改查实用指南(上)
本节目标: NOT NULL - 指示某列不能存储 NULL 值。 UNIQUE - 保证某列的每行必须有唯一的值。 DEFAULT - 规定没有给列赋值时的默认值。 PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标 识&am…...

SAP MM学习笔记 - 豆知识02 - MR21 修改物料原价,MM02 修改基本数量单位/评价Class,MMAM 修改物料类型/评价Class
上一章讲了一些豆知识。比如 - MM50 批量扩张品目 - XK05/06 Block/消除供应商 - MM06/MM16 品目消除 - SE11/SE16/SE16/SE16N/SE16H/DB02 等查看常用的操作Table和数据的T-code SAP MM学习笔记- 豆知识01 - MM50 批量扩张,XK05/XK06 Block/消除供应商…...
)
2026年青少年信息素养大赛备赛指南(含历年真题)
📢 2026年青少年信息素养大赛备赛指南各位家长、老师好!随着教育的不断发展,少儿编程已成为孩子综合能力培养的重要一环。今天给大家整理一下近期备受关注的青少年信息素养大赛相关资讯,以及备赛资源。🏆 赛事简介全国…...

YOLO X Layout在新闻行业的应用:版面自动排版
YOLO X Layout在新闻行业的应用:版面自动排版 每天清晨,当大多数人还在睡梦中时,新闻编辑部的排版编辑已经开始了一天中最紧张的工作:将记者们连夜赶制的稿件、摄影师捕捉的精彩瞬间、设计师制作的图表,精准地排列在有…...

像素剧本圣殿详细步骤:如何重置时空+保存平行宇宙创作记录
像素剧本圣殿详细步骤:如何重置时空保存平行宇宙创作记录 1. 认识像素剧本圣殿 像素剧本圣殿是一款基于Qwen2.5-14B-Instruct深度微调的专业剧本创作工具。它将强大的AI推理能力与独特的8-Bit复古美学相结合,为创作者提供了一个沉浸式的剧本开发环境。…...

Java程序员终于有自己的AI Agent框架了:Spring AI Alibaba上手实录
Java程序员终于有自己的AI Agent框架了:Spring AI Alibaba上手实录 说实话,作为一个写了多年Java的人,看着Python那边各种AI框架、Agent工具层出不穷,心里是有点酸的。LangChain、AutoGPT、CrewAI…全是Python的天下。Java开发者想…...

OpenClaw性能调优:降低Phi-3-mini-128k-instruct长任务token消耗的技巧
OpenClaw性能调优:降低Phi-3-mini-128k-instruct长任务token消耗的技巧 1. 问题背景:长任务带来的token消耗困境 上周我在用OpenClaw处理一个文档整理任务时,遇到了一个棘手的问题。这个任务需要读取50多份Markdown格式的技术文档ÿ…...

OpenClaw截图分析进阶:千问3.5-9B识别UI元素与操作建议
OpenClaw截图分析进阶:千问3.5-9B识别UI元素与操作建议 1. 为什么需要截图分析能力? 上周我在测试一个内部工具时遇到了一个典型问题——某个按钮在特定分辨率下会消失不见。手动排查需要反复调整窗口尺寸并肉眼检查,效率极低。这时我想到了…...

突破音频限制:OpenCore-Legacy-Patcher焕新老Mac音质体验
突破音频限制:OpenCore-Legacy-Patcher焕新老Mac音质体验 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当经典Mac设备升级到最新macOS系统后&am…...

终极AI图像分层指南:3分钟将复杂插画变成可编辑PSD图层
终极AI图像分层指南:3分钟将复杂插画变成可编辑PSD图层 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾面对一幅精美的数字插画&…...

5个高效步骤:直链技术让网盘用户实现下载速度跃升
5个高效步骤:直链技术让网盘用户实现下载速度跃升 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

告别B站缓存格式困扰:m4s-converter让视频文件处理效率提升80%
告别B站缓存格式困扰:m4s-converter让视频文件处理效率提升80% 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 一、痛点直击…...