Python 爬虫入门(六):urllib库的使用方法
Python 爬虫入门(六):urllib库的使用方法
- 前言
- 1. urllib 概述
- 2. urllib.request 模块
- 2.1 发送GET请求
- 2.2 发送POST请求
- 2.3 添加headers
- 2.4 处理异常
- 3. urllib.error 模块
- 4. urllib.parse 模块
- 4.1 URL解析
- 4.2 URL编码和解码
- 4.3 拼接URL
- 5. urllib.robotparser 模块
- 6. 实战示例: 爬取豆瓣电影Top250
- 7. urllib vs requests
- 8. 注意事项
- 总结
前言
- 欢迎来到"Python 爬虫入门"系列的第六篇文章。今天我们来学习Python标准库中的urllib,这是一个用于处理URL的强大工具包。
- urllib是Python内置的HTTP请求库,不需要额外安装,就可以直接使用。它提供了一系列用于操作URL的函数和类,可以用来发送请求、处理响应、解析URL等。尽管现在很多人更喜欢使用requests库,但是了解和掌握urllib仍然很有必要,因为它是很多其他库的基础,而且在一些特殊情况下可能会更有优势。
- 在这篇文章里,我会详细介绍urllib的四个主要模块:request、error、parse和robotparser,并通过实际的代码示例来展示它们的用法。
1. urllib 概述
urllib是 Python 标准库中用于URL处理的模块集合,不需要通过 pip 安装。
它包含了多个处理URL的模块:
- urllib.request: 用于打开和读取URL
- urllib.error: 包含urllib.request抛出的异常
- urllib.parse: 用于解析URL
- urllib.robotparser: 用于解析robots.txt文件
这些模块提供了一系列强大的工具,可以帮助我们进行网络请求和URL处理。接下来,我们将逐一介绍这些模块的主要功能和使用方法。
2. urllib.request 模块
urllib.request模块是urllib中最常用的模块,它提供了一系列函数和类来打开URL(主要是HTTP)。
我们可以使用这个模块来模拟浏览器发送GET和POST请求。
2.1 发送GET请求
使用urllib.request发送GET请求非常简单,我们可以使用urlopen()函数:
import urllib.request
import gzip
import iourl = 'https://www.python.org/'
response = urllib.request.urlopen(url)# 获取响应头
content_type = response.headers.get('Content-Encoding')# 读取数据
data = response.read()# 检查是否需要解压缩
if content_type == 'gzip':buf = io.BytesIO(data)with gzip.GzipFile(fileobj=buf) as f:data = f.read()print(data.decode('utf-8'))这段代码会打开Python官网,并打印出网页的HTML内容。

2.2 发送POST请求
发送POST请求稍微复杂一些,我们需要使用Request对象:
import urllib.request
import urllib.parseurl = 'http://httpbin.org/post'
data = urllib.parse.urlencode({'name': 'John', 'age': 25}).encode('utf-8')
req = urllib.request.Request(url, data=data, method='POST')
response = urllib.request.urlopen(req)print(response.read().decode('utf-8'))
这段代码向httpbin.org发送了一个POST请求,包含了name和age两个参数。

2.3 添加headers
在实际的爬虫中,我们常常需要添加headers来模拟浏览器行为。
可以在创建Request对象时添加headers:
import urllib.request
import gzip
import iourl = 'https://www.python.org/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)# 获取响应头中的 Content-Encoding
content_encoding = response.headers.get('Content-Encoding')# 读取数据
data = response.read()# 如果数据被 gzip 压缩,则需要解压
if content_encoding == 'gzip':buf = io.BytesIO(data)with gzip.GzipFile(fileobj=buf) as f:data = f.read()# 尝试使用 'utf-8' 解码
try:print(data.decode('utf-8'))
except UnicodeDecodeError:print("Cannot decode data with 'utf-8' encoding.")添加headers后,运行结果如下:

2.4 处理异常
在进行网络请求时,可能会遇到各种异常情况。我们可以使用try-except语句来处理这些异常:
import urllib.request
import urllib.error
import gzip
import iotry:# 发送请求并获取响应response = urllib.request.urlopen('https://www.python.org/')# 获取响应头中的 Content-Encodingcontent_encoding = response.headers.get('Content-Encoding')# 读取数据data = response.read()# 如果数据被 gzip 压缩,则需要解压if content_encoding == 'gzip':buf = io.BytesIO(data)with gzip.GzipFile(fileobj=buf) as f:data = f.read()# 尝试使用 'utf-8' 解码print(data.decode('utf-8'))
except urllib.error.URLError as e:print(f'URLError: {e.reason}')
except urllib.error.HTTPError as e:print(f'HTTPError: {e.code}, {e.reason}')
except UnicodeDecodeError:print("Cannot decode data with 'utf-8' encoding.")这段代码会捕获URLError和HTTPError,这两种异常都定义在urllib.error模块中。
3. urllib.error 模块
urllib.error模块定义了urllib.request可能抛出的异常类。主要有两个异常类:
- URLError: 由urllib.request产生的异常的基类。
- HTTPError: URLError的子类,用于处理HTTP和HTTPS URL的错误。
我们已经在上面的例子中看到了如何捕获和处理这些异常。
4. urllib.parse 模块
urllib.parse模块提供了许多URL处理的实用函数,例如解析、引用、拆分和组合。
4.1 URL解析
from urllib.parse import urlparseurl = 'https://www.python.org/doc/?page=1#introduction'
parsed = urlparse(url)print(parsed)
print(f'Scheme: {parsed.scheme}')
print(f'Netloc: {parsed.netloc}')
print(f'Path: {parsed.path}')
print(f'Params: {parsed.params}')
print(f'Query: {parsed.query}')
print(f'Fragment: {parsed.fragment}')
这段代码会解析URL,并打印出各个组成部分。

4.2 URL编码和解码
在处理URL时,我们经常需要对参数进行编码和解码:
from urllib.parse import urlencode, unquoteparams = {'name': 'John Doe', 'age': 30, 'city': 'New York'}
encoded = urlencode(params)
print(f'Encoded: {encoded}')decoded = unquote(encoded)
print(f'Decoded: {decoded}')
urlencode()函数将字典转换为URL编码的字符串,而unquote()函数则进行解码。

4.3 拼接URL
from urllib.parse import urljoinbase_url = 'https://www.python.org/doc/'
relative_url = 'tutorial/index.html'
full_url = urljoin(base_url, relative_url)print(full_url)
urljoin()函数可以方便地将一个基础URL和相对URL拼接成一个完整的URL。

5. urllib.robotparser 模块
urllib.robotparser模块提供了一个RobotFileParser类,用于解析robots.txt文件。
robots.txt是一个网站用来告诉爬虫哪些页面可以爬取,哪些不可以爬取的文件。
from urllib.robotparser import RobotFileParserrp = RobotFileParser()
rp.set_url('https://www.python.org/robots.txt')
rp.read()print(rp.can_fetch('*', 'https://www.python.org/'))
print(rp.can_fetch('*', 'https://www.python.org/admin/'))
这段代码会读取Python官网的robots.txt文件,然后检查是否允许爬取某些URL。

6. 实战示例: 爬取豆瓣电影Top250
现在,让我们用我们学到的知识来写一个实际的爬虫,爬取豆瓣电影Top250的信息。
import urllib.request
import urllib.error
import re
from bs4 import BeautifulSoupdef get_movie_info(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}try:req = urllib.request.Request(url, headers=headers)response = urllib.request.urlopen(req)html = response.read().decode('utf-8')soup = BeautifulSoup(html, 'html.parser')movie_list = soup.find('ol', class_='grid_view')for movie_li in movie_list.find_all('li'):rank = movie_li.find('em').stringtitle = movie_li.find('span', class_='title').stringrating = movie_li.find('span', class_='rating_num').stringif movie_li.find('span', class_='inq'):quote = movie_li.find('span', class_='inq').stringelse:quote = "N/A"print(f"Rank: {rank}")print(f"Title: {title}")print(f"Rating: {rating}")print(f"Quote: {quote}")print('-' * 50)except urllib.error.URLError as e:if hasattr(e, 'reason'):print(f'Failed to reach the server. Reason: {e.reason}')elif hasattr(e, 'code'):print(f'The server couldn\'t fulfill the request. Error code: {e.code}')# 爬取前5页
for i in range(5):url = f'https://movie.douban.com/top250?start={i*25}'get_movie_info(url)
这个爬虫会爬取豆瓣电影Top250的前5页,每页25部电影,共125部电影的信息。它使用了我们之前学到的urllib.request发送请求,使用BeautifulSoup解析HTML,并处理了可能出现的异常。

7. urllib vs requests
虽然urllib是Python的标准库,但在实际开发中,很多人更喜欢使用requests库。
这是因为:
- 易用性: requests的API设计更加人性化,使用起来更加直观和简单。
- 功能强大: requests自动处理了很多urllib需要手动处理的事情,比如保持会话、处理cookies等。
- 异常处理: requests的异常处理更加直观和统一。
然而,urllib作为标准库仍然有其优势:
- 无需安装: 作为标准库,urllib无需额外安装即可使用。
- 底层操作: urllib提供了更多的底层操作,在某些特殊情况下可能更有优势。
在大多数情况下,如果你的项目允许使用第三方库,requests可能是更好的选择。但了解和掌握urllib仍然很有必要,因为它是Python网络编程的基础,而且在一些特殊情况下可能会更有用。
8. 注意事项
在使用urllib进行爬虫时,有一些重要的注意事项:
- 遵守robots.txt: 使用urllib.robotparser解析robots.txt文件,遵守网站的爬取规则。
- 添加合适的User-Agent: 在headers中添加合适的User-Agent,避免被网站识别为爬虫而被封禁。
- 控制爬取速度: 添加适当的延时,避免对目标网站造成过大压力。
- 处理异常: 正确处理可能出现的网络异常和HTTP错误。
- 解码响应: 注意正确解码响应内容,处理不同的字符编码。
- URL编码: 在构造URL时,注意对参数进行正确的URL编码。
总结
-
在本文中,我们学习了Python标准库urllib的使用方法,包括发送GET和POST请求、异常处理、URL解析和构造,以及robots.txt文件解析,并将这些知识应用到了实际的爬虫案例中。
-
虽然requests库在实际开发中更受欢迎,但掌握urllib仍然十分重要。它不仅是Python网络编程的基础,而且在某些特殊情况下可能会更有优势。
-
希望通过本文,你对urllib有了更深入的理解,并能在你的爬虫项目中灵活运用。无论使用何种工具,都要遵守网络爬虫的伦理规范,尊重网站的规则和其他用户的权益。
如果你有任何问题或者好的想法,欢迎随时和我交流。
相关文章:
Python 爬虫入门(六):urllib库的使用方法
Python 爬虫入门(六):urllib库的使用方法 前言1. urllib 概述2. urllib.request 模块2.1 发送GET请求2.2 发送POST请求2.3 添加headers2.4 处理异常 3. urllib.error 模块4. urllib.parse 模块4.1 URL解析4.2 URL编码和解码4.3 拼接URL 5. ur…...

个人开发神器,一应俱全,有你想要的!
哈喽,各位小伙伴们好,我是给大家带来各类黑科技与前沿资讯的小武。 经常有很多小伙伴问小武,是从哪里获取到这么多资源,其实除了熟知的吾爱、酷安等知名论坛集聚地,还有一些强大的资源聚合类软件也非常重要。 如之前安…...

电子电气架构 --- SOVD在域控制器的应用
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

React(四):DOCX文件在线预览
效果 注意 ⚠️注意:部分文件预览存在问题 依赖 $ yarn add docx-preview $ yarn add jszip源码 import ./index.scss; import {useRef} from react; import type {UploadRequestOption} from rc-upload/lib/interface; import {Upload, Button, message} from an…...

Java IO.字符集,流,缓冲流 转换流 对象操作流
一.字符集 如果使用字节流 , 把文本文件中的内容读取到内存时, 可能会出现乱码 如果使用字节流 , 把中文写入文本文件中 , 也有可能会出现乱码 读取n.txt"你好" 两个汉字 字节流读中文,每次只能读一部分所以出现了乱码 字符集(Character se…...

线性稳压器的内部电路与构成分析
线性稳压器的一般的引脚构成 线性稳压器基本上由VIN (输入)、VO (输出)、GND (接地)三个引脚构成。在输出可变的线性稳压器上添加了用于反馈输出电压的FB(反馈引脚)。 简单来说&am…...

Go语言实现多协程文件下载器
文章目录 前言流程图主函数下载文件初始化分片下载worker分发下载任务获取下载文件的大小下载文件分片错误重试项目演示最后 前言 你好,我是醉墨居士,最近在开发文件传输相关的项目,然后顺手写了一个多协程文件下载器,代码非常精…...

本地方法详解
本地方法(Native Methods)是指那些由Java程序调用,但其实现是用非Java语言(如C、C等)编写的方法。它们通常用于访问操作系统底层的功能或进行高效的计算,这些是Java本身不能直接实现的。下面详细解释本地方…...

每日新闻掌握【2024年8月3日 星期六】
2024年8月3日 星期六 农历六月廿九 大公司/大事件 微信地震预警全国上线 36氪获悉,国家地震烈度速报与预警工程已于7月25日正式通过国家验收。8月2日,在中国地震局指导下,中国地震台网中心、中央广播电视总台国家应急广播与腾讯联合推出“中…...

python入门基础篇(一)
基础篇 Python基础安装与配置Python环境理解Python解释器第一个Python程序:"Hello, World!" 基础语法注释与文档字符串变量与数据类型数字类型:整数、浮点数、复数字符串布尔值None值 运算符算术运算符比较运算符逻辑运算符赋值运算符位运算符…...

windows下在线预览服务kkFileView4.4.0问题记录
前几天找到一个开源项目:kkFileView,感觉可能以后可能会用到,所以尝试了下。 通过git下载下来,版本是4.4.0,通过idea打开项目,发现老是无法找到组件aspose-cad,版本是23.9. 找了好多文章&#x…...

Java:通过反射获取class类的属性
有如下一个普通类,我想获取他的所有属性值 package com.demo.bean;import lombok.Data;import java.util.List;Data public class UserBean {private String name;private Integer age;private List<String> tags; }可以通过反射的方式获取属性值 package c…...

07.FreeRTOS列表与列表项
文章目录 07. FreeRTOS列表与列表项1. 列表和列表项的简介2. 列表相关API函数3. 代码验证 07. FreeRTOS列表与列表项 1. 列表和列表项的简介 列表的定义: typedef struct xLIST {listFIRST_LIST_INTEGRITY_CHECK_VALUE /* 校验值 */volatile UBaseType_t uxN…...

餐饮业油烟净化器安装势在必行,切勿侥幸
我最近分析了餐饮市场的油烟净化器等产品报告,解决了餐饮业厨房油腻的难题,更加方便了在餐饮业和商业场所有需求的小伙伴们。 随着环保法规的日益严格和公众环保意识的提升,餐饮业油烟排放问题成为社会关注的焦点。油烟不仅影响环境质量&am…...

SpringBoot集成阿里百炼大模型 原子的学习日记Day01
文章目录 概要下一章SpringBoot集成阿里百炼大模型(多轮对话) 原子的学习日记Day02 整体架构流程技术名词解释集成步骤1,选择大模型以及获取自己的api-key(前面还有一步开通服务就没有展示啦!)2,…...

【网络编程】网络原理(一)
系列文章目录 1、 初识网络 2、网络编程的基础使用(一) 文章目录 系列文章目录前言一、端口号的使用二、UDP报文学习1.报文格式2.MD5算法 总结 前言 在前文中,主要对UDP和TCP协议有了简单的了解,而这两种协议是负责传输层的内容…...

鲁班上门维修安装系统源码开发之功能模式
鲁班上门维修安装系统在当今的趋势呈现出显著的增长与创新。随着物联网、智能家居的普及,以及消费者对便捷、高效生活方式的追求,鲁班上门维修安装系统凭借其多渠道预约、智能派单、在线支付与费用明细透明等优势,赢得了市场的广泛认可。 …...

图数据处理的新时代:阿里FraphCompute与蚂蚁金服TuGraph对比综述
目录 前言 阿里FraphCompute与蚂蚁金服TuGraph的主要特性和功能的比较: 阿里FraphCompute与蚂蚁金服TuGraph在不同应用场景分析对比: 阿里FraphCompute与蚂蚁金服TuGraph未来趋势的对比: FraphCompute与TuGraph详解 缺点劣势深入比较 前言…...
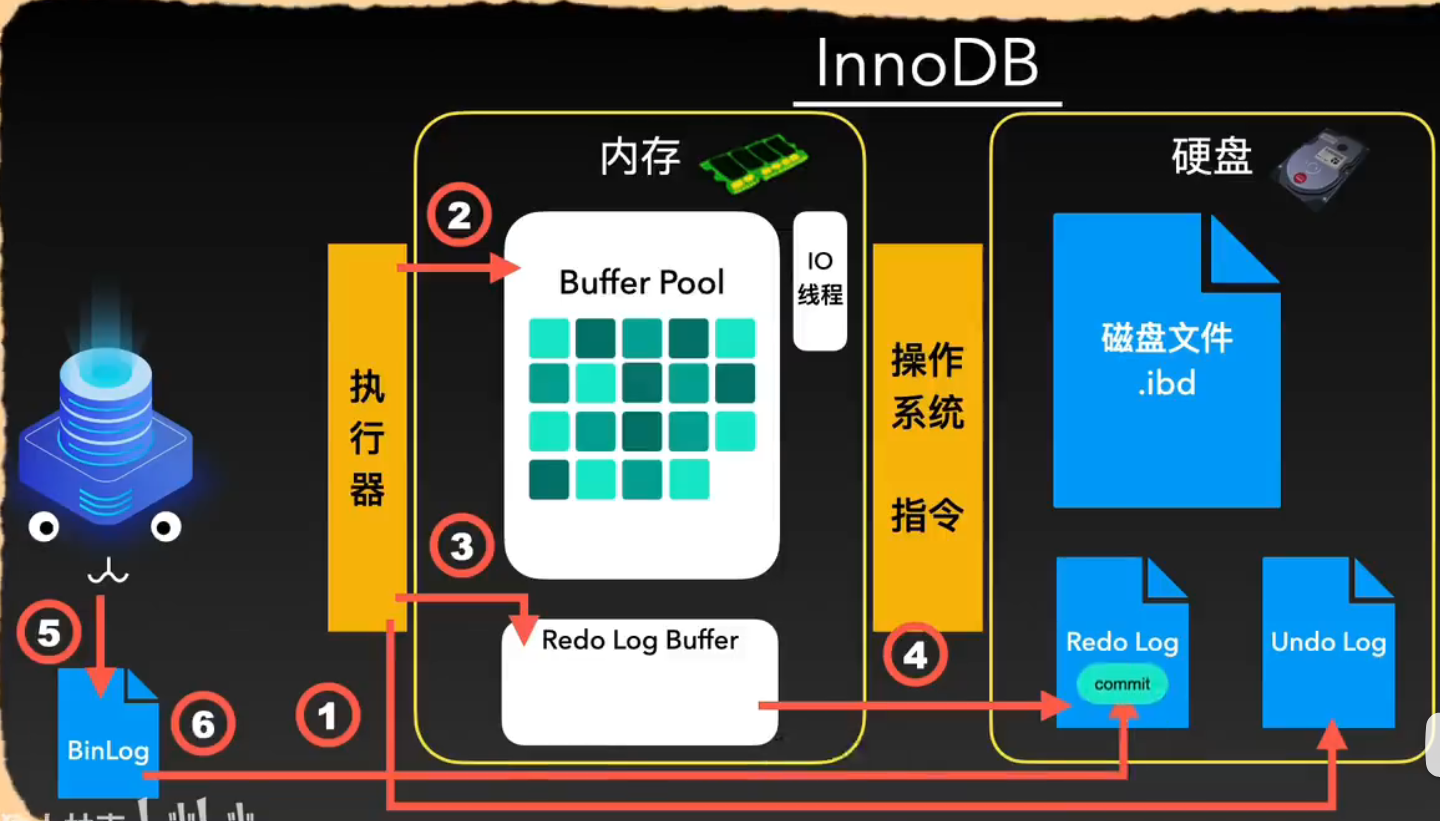
InnoDB引擎下SQL的执行流程
SQL执行流程 连接器 客户端连接驱动与mysql连接池连接 半双工通信传入客户端的sql 查询缓存(8.0之后没有) 删除原因 如果每次查询条件不同导致命中率低没有命中缓存 创建新缓存在创建缓存的时候会添加表级锁缓存更新需要批量失效 sql解析器 对传入的sql 词法分析 分解成各种t…...

Java小白入门到实战应用教程-重写和重载
引言 在上一节中我们学习了面向对象中的继承,然后在那一节中我们提到了一个知识点叫做:重写。 通过上节的代码样例我们也观察到了,重写是发生在子类和父类的这种继承关系中。 继承的特点就是提取所有子类共有的属性和方法,但是…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...

League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理?
League Akari:如何通过LCU API实现英雄联盟游戏流程的智能化管理? 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit Leag…...
)
ArduPilot飞行模式实战:从代码角度看Stabilize、Acro、Loiter模式如何切换(附避坑指南)
ArduPilot飞行模式深度解析:从状态机到实战避坑指南 在开源飞控领域,ArduPilot以其强大的飞行模式系统著称。不同于普通用户只需了解模式功能,开发者更需要掌握模式切换的底层机制——这直接关系到飞行安全与二次开发效率。本文将带您深入Sta…...

告别KITTI!用TartanAir数据集在Unreal Engine+AirSim里复现那些让VSLAM算法“翻车”的雨天和黑夜
超越KITTI:用TartanAir数据集在虚拟极端环境中锤炼VSLAM算法当视觉SLAM算法在KITTI数据集上取得95%的准确率时,开发者们常常会松一口气——直到这些算法被部署到真实世界的雨夜街道上。突然之间,那些在阳光明媚的德国道路上表现优异的特征点检…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...

3步终结Windows热键冲突:Hotkey Detective终极排查指南
3步终结Windows热键冲突:Hotkey Detective终极排查指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾…...
)
告别Appium!用Python+UIAutomator2搞定Android自动化测试(附完整环境搭建与实战代码)
PythonUIAutomator2:Android自动化测试的高效实践指南 在移动应用测试领域,效率与稳定性始终是工程师们追求的核心目标。传统方案如Appium虽然功能全面,但在执行速度和资源消耗方面往往难以满足高频测试需求。本文将带您探索基于Python和UIA…...