LLM推理入门实践:基于 Hugging Face Transformers 和 Qwen2模型 进行文本问答
文章目录
- 1. HuggingFace模型下载
- 2. 模型推理:文本问答
1. HuggingFace模型下载
模型在 HuggingFace 下载,如果下载速度太慢,可以在 HuggingFace镜像网站 或 ModelScope 进行下载。
使用HuggingFace的下载命令(需要先注册HuggingFace账号):
第一步:安装 git-lfs
curl https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
apt-get install git-lfs
第二步:下载 Qwen2-0.5B 模型
git lfs clone https://huggingface.co/Qwen/Qwen2-0.5B
下载完后的模型包括以下文件:
config.json # 模型配置文件,包含了模型的各种参数设置,例如层数、隐藏层大小、注意力头数
generation_config.json #文本生成相关的模型配置
merges.txt #训练tokenizer阶段所得到的合并词表结果
model.Safetensors #模型文件
tokenizer.json #分词器,将词转换为数字
tokenizer_config.json #分词模型的配置信息,如分词器的类型、词汇表大小、最大序列长度、特殊标记等
vocab.json #词表
2. 模型推理:文本问答
本文使用单卡 A100-80G 进行推理实验
注意:使用 Qwen2 模型需要将 transformers 库更新到最新版本
code:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM# 从本地加载预训练模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_path = "models/Qwen2-0.5B"
model = AutoModelForCausalLM.from_pretrained(model_path,device_map=device)
# 设置 device_map="auto" 会自动使用所有多卡
print(f"model: {model}")# 加载 tokenizer(分词器)
# 分词器负责将句子分割成更小的文本片段 (词元) 并为每个词元分配一个称为输入 id 的值(数字),因为模型只能理解数字。
# 每个模型都有自己的分词器词表,因此使用与模型训练时相同的分词器很重要,否则它会误解文本。
tokenizer = AutoTokenizer.from_pretrained(model_path, add_eos_token=True, padding_side='left')
# add_eos_token=True: 可选参数,表示在序列的末尾添加一个结束标记(end-of-sequence token),这有助于模型识别序列的结束。
# padding_side='left': 可选参数,表示 padding 应该在序列的哪一边进行,确保所有序列的长度一致。# 模型输入
input_text = "介绍一下悉尼这座城市。"# 对输入文本分词
input_ids = tokenizer(input_text, return_tensors="pt").to(device)
# return_tensors="pt": 指定返回的数值序列的数据类型。"pt"代表 PyTorch Tensor,表示分词器将返回一个PyTorch而不是TensorFlow对象# 生成文本回答
# max_new_tokens:模型生成的新的 token 的最大数量为 200
outputs = model.generate(input_ids["input_ids"], max_new_tokens=200)
print(f"type(outputs) = {type(outputs)}") # <class 'torch.Tensor'>
print(f"outputs.shape = {outputs.shape}") # torch.Size([1, 95]),outputs.shape是随机的,是不超过200的数# 将输出token解码为文本
decoded_outputs = tokenizer.decode(outputs[0])
print(f"decoded_outputs: {decoded_outputs}")
模型输出的文本回答如下:
decoded_outputs: 介绍一下悉尼这座城市。 悉尼这座城市位于澳大利亚东南部,是澳大利亚最大的城市之一。它是一个现代化的城市,拥有许多现代化的建筑和设施,如购物中心、博馆、剧院和音乐厅等。悉尼的气候宜人,四季分明,夏季炎热,冬季寒冷,适合旅游和度假。此外,悉尼还有许多著名的景点,如悉尼歌剧院、悉尼塔、悉尼海港大桥等,这些景点吸引来自世界各地的游客。<|endoftext|>
Qwen2-0.5B 模型结构:
Qwen2ForCausalLM((model): Qwen2Model((embed_tokens): Embedding(151936, 896)(layers): ModuleList((0-23): 24 x Qwen2DecoderLayer((self_attn): Qwen2SdpaAttention((q_proj): Linear(in_features=896, out_features=896, bias=True)(k_proj): Linear(in_features=896, out_features=128, bias=True)(v_proj): Linear(in_features=896, out_features=128, bias=True)(o_proj): Linear(in_features=896, out_features=896, bias=False)(rotary_emb): Qwen2RotaryEmbedding())(mlp): Qwen2MLP((gate_proj): Linear(in_features=896, out_features=4864, bias=False)(up_proj): Linear(in_features=896, out_features=4864, bias=False)(down_proj): Linear(in_features=4864, out_features=896, bias=False)(act_fn): SiLU())(input_layernorm): Qwen2RMSNorm()(post_attention_layernorm): Qwen2RMSNorm()))(norm): Qwen2RMSNorm())(lm_head): Linear(in_features=896, out_features=151936, bias=False)
)
参考资料:Hugging Face Transformers 萌新完全指南
相关文章:
LLM推理入门实践:基于 Hugging Face Transformers 和 Qwen2模型 进行文本问答
文章目录 1. HuggingFace模型下载2. 模型推理:文本问答 1. HuggingFace模型下载 模型在 HuggingFace 下载,如果下载速度太慢,可以在 HuggingFace镜像网站 或 ModelScope 进行下载。 使用HuggingFace的下载命令(需要先注册Huggin…...

python:YOLO格式数据集图片和标注信息查看器
作者:CSDN _养乐多_ 本文将介绍如何实现一个可视化图片和标签信息的查看器,代码使用python实现。点击下一张和上一张可以切换图片。 文章目录 一、脚本界面二、完整代码 一、脚本界面 界面如下图所示, 二、完整代码 使用代码时࿰…...
AGI思考探究的意义、价值与乐趣 Ⅴ
搞清楚模型对知识或模式的学习与迁移对于泛化意味什么,或者说两者间的本质?相信大家对泛化性作为大语言模型LLM的突出能力已经非常了解了 - 这也是当前LLM体现出令人惊叹的通用与涌现能力的基础前提,这里不再过多赘述,但仍希望大家…...

c++: mangle命名规则
其实可用根据binutils/c++filt的源代码看。找到mangle的命名规则, 但是从网上找到了一个总结,但是github有时候上不去,摘录再次。 https://github.com/gchatelet/gcc_cpp_mangling_documentation https://itanium-cxx-abi.github.io/cxx-abi/abi.html#mangling 举例: _ZN8…...

系统化学习 H264视频编码(05)码流数据及相关概念解读
说明:我们参考黄金圈学习法(什么是黄金圈法则?->模型 黄金圈法则,本文使用:why-what)来学习音H264视频编码。本系列文章侧重于理解视频编码的知识体系和实践方法,理论方面会更多地讲清楚 音视频中概念的…...
【VMware】如何演示使用U盘在VMware虚拟机上安装Windows11
一、前置准备 在开始使用U盘演示在VMware虚拟机上装Windows11前,我们需要做以下前置的准备: 已制作好的Windows引导盘;WMware软件 如何制作Windows引导盘? 推荐参考: 【建议收藏】2024年最新Windows系统重装教程&…...

HanLP和Jieba区别
HanLP和Jieba都是中文分词工具,但它们在多个方面存在区别。以下是对两者区别的详细分析: 一、开发背景与语言支持 HanLP:由大连理工大学自然语言处理与社会人文计算实验室开发,是一个开源的自然语言处理工具包。它主要使用Java语…...

荒原之梦考研:考研二战会很难吗?
考研二战是不是很难,其实很大程度上取决于我们自己,我们能否认清自己的优势,能否指定和执行合理的计划,有没有强大的心理支撑等,都是决定考研二战能否成功,或者能否比较轻松的成功的关键。 在本文中&#…...

【Git企业级开发实战指南①】Git安装、基本操作!
目录 一、Git是什么?1.1特点1.2功能1.3基本概念 二、Git安装2.1Ubuntu下安装2.2Centos下安装Git 三、Git基本操作3.1创建git本地仓库3.2配置Git3.3 工作区&暂存区&版本库3.4 实操案例3.4.1添加文件 3.5 修改文件3.6版本回退3.7查看历史操作日志3.7撤销修改3…...

Leetcode 3239. Minimum Number of Flips to Make Binary Grid Palindromic I
Leetcode 3239. Minimum Number of Flips to Make Binary Grid Palindromic I 1. 解题思路2. 代码实现 题目链接:3239. Minimum Number of Flips to Make Binary Grid Palindromic I 1. 解题思路 这一题思路上的话就是分别考察一下把所有行都变成回文所需要的fli…...

C++面试基础算法的简要介绍
C是一种广泛使用的编程语言,尤其在算法和数据结构的实现中占据重要地位。以下是对C基础算法的一些介绍,涵盖了排序、查找、搜索算法以及基本的遍历算法等方面。 排序算法 快速排序(Quick Sort) 快速排序是一种分而治之的排序算法…...

【Linux网络编程】套接字Socket(UDP)
网络编程基础概念: ip地址和端口号 ip地址是网络协议地址(4字节32位,形式:xxx.xxx.xxx.xxx xxx在范围[0, 255]内),是IP协议提供的一种统一的地址格式,每台主机的ip地址不同,一个…...

jvm方法返回相关指令ireturn,areturn,return等分析
正文 看图: 做的事情如下: 1:弹出当前的方法栈帧 2:获取上一个方法 3:从当前方法的操作数栈中获取执行结果,并推送到上一个方法的操作数栈中对应的伪代码: Override public void execute(Frame frame) {Thread thread frame.thread();Frame curren…...

宝塔部署springboot vue ruoyi前后端分离项目,分离lib、resources
1、“文件”中创建好相关项目目录,并将项目相关文件传到对应目录 例如:项目名称/ #项目总目录 api/ #存放jar项目的Java项目文件 manage/ #vue管理后端界面 …...
的使用)
Python 基础教程:List(列表)的使用
《Python 基础教程:List(列表)的使用》 在 Python 中,列表是最基本的数据结构之一,它是一种有序的、可变的数据集合,可以包含任意类型的元素,包括数字、字符串、其他列表等。 1. 列表的创建 …...

kubebuilder常用标签
kubebuilder 标签是用于注解 Kubernetes CRD(Custom Resource Definition) 的标签,主要用于在 Operator SDK 和 Kubebuilder 框架中生成代码、验证规则以及自定义 CRD 的生成。以下是常用的 kubebuilder 标签: 1. 字段验证标签 …...
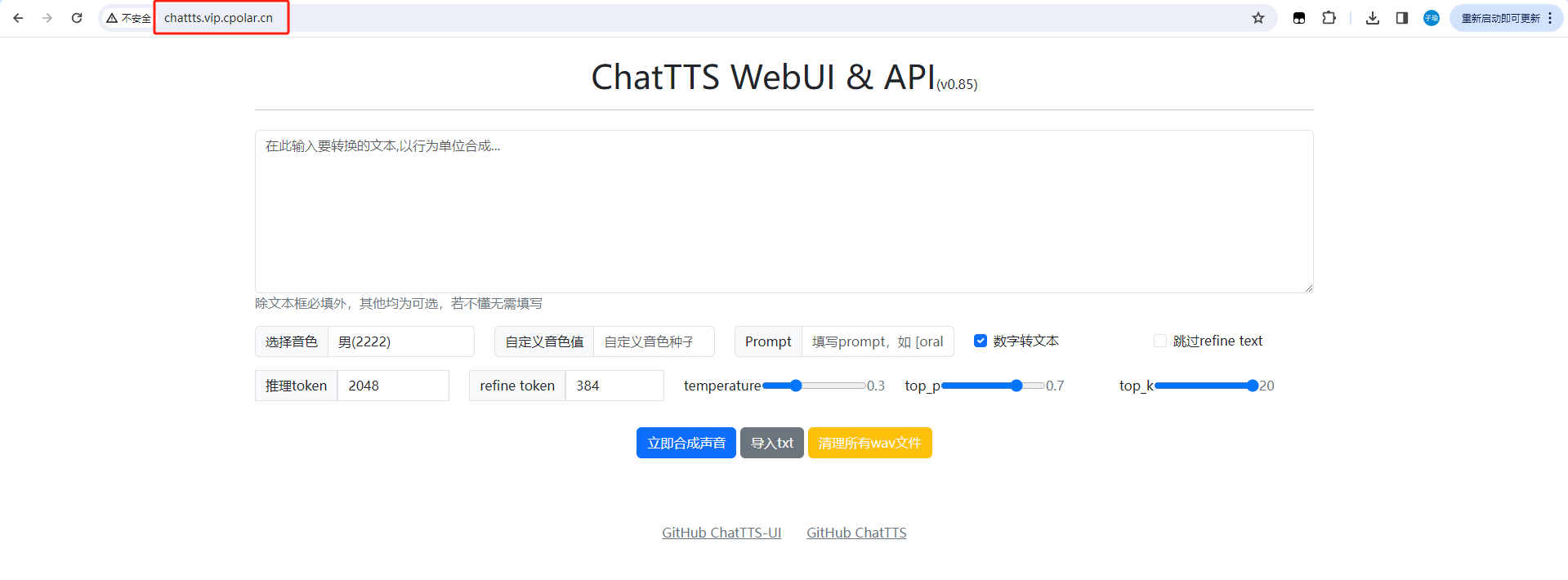
ChatTTS文本转语音本地部署结合内网穿透实现远程使用生成AI音频
文章目录 前言1. 下载运行ChatTTS模型2. 安装Cpolar工具3. 实现公网访问4. 配置ChatTTS固定公网地址 前言 本篇文章主要介绍如何快速地在Windows系统电脑中本地部署ChatTTS开源文本转语音项目,并且我们还可以结合Cpolar内网穿透工具创建公网地址,随时随…...

基于微信小程序的高校大学生信息服务平台设计与实现
基于微信小程序的高校大学生信息服务平台设计与实现 Design and Implementation of a College Student Information Service Platform based on WeChat Mini Program 完整下载链接:基于微信小程序的高校大学生信息服务平台设计与实现 文章目录 基于微信小程序的高校大学生信息…...

YOLOV8替换Lion优化器
YOLOV8替换Lion优化器 1 优化器介绍博客 参考bilibili讲解视频 论文地址:https://arxiv.org/abs/2302.06675 代码地址:https://github.com/google/automl/blob/master/lion/lion_pytorch.py """PyTorch implementation of the Lion …...

uniapp页面里面的登录注册模板
<!-- 账号密码登录页 --> <template><view class"page"><view class"uni-content"><view class"login-logo"><image :src"logo"></image></view><text class"title title-bo…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

【DeepSeek集成测试黄金标准】:20年专家亲授5大避坑指南与自动化落地框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试黄金标准的演进与核心价值 集成测试在大语言模型工程化落地过程中已从“验证功能可用”跃迁为“保障推理一致性、上下文鲁棒性与安全边界的三位一体质量门禁”。DeepSeek系列模型&…...

使用libusb-win32驱动复活老旧USB硬件:以Elektor Magic Eye为例
1. 项目概述:让老硬件在新时代焕发新生手头有一台十多年前的《Elektor》杂志上刊登的“Magic Eye EM84”复古VFD显示屏项目,想把它接到Windows 10电脑上当个酷炫的CPU占用率显示器,却发现官方提供的“AVR309”USB驱动在新系统上彻底罢工了。这…...

智能烹饪助手:基于传感器融合与AI的厨房自动化实践
1. 项目概述:一个让厨房小白也能自信下厨的智能伙伴每次站在灶台前,你是不是也经历过这样的场景:一边手忙脚乱地翻着菜谱,一边担心锅里的菜是不是快糊了,还要分心去计算各种调料该放多少?对于很多刚接触烹饪…...

告别繁琐审核!实测AI Agent如何重塑复杂非结构化票据与合同处理流程?
摘要:在企业数字化转型步入深水区的2026年,处理复杂非结构化票据与合同已成为横亘在财务、法务部门面前的“最后一公里”难题。传统RPA因UI变动易崩溃、主流智能体因缺乏API适配而无法落地,导致大量业务仍依赖低效的人工操作。本文由「企服AI…...

Mysql?基础语法!!!
作为程序员、数据分析从业者,甚至是产品运营,SQL都是必须掌握的核心技能。不管是后端开发对数据库增删改查,还是数据分析提取业务数据,本质都是在写SQL语句。很多新手觉得SQL难,其实是没有理清逻辑。SQL的核心逻辑非常…...