3.特征工程-特征抽取、特征预处理、特征降维
文章目录
- 环境配置(必看)
- 头文件引用
- 1.数据集: sklearn
- 代码
- 运行结果
- 2.字典特征抽取: DictVectorizer
- 代码
- 运行结果
- 稀疏矩阵
- 3.文本特征抽取(英文文本): CountVectorizer()
- 代码
- 运行结果
- 4.中文文本分词(中文文本特征抽取使用)
- 代码
- 运行结果
- 5.中文文本特征抽取
- 代码
- 运行结果
- 6.文本特征抽取: TfidfVectorizer
- 代码
- 运行结果
- 7.归一化:MinMaxScaler
- 代码
- 运行结果
- 8.标准化: StandardScaler
- 代码
- 运行结果
- 9.过滤低方差特征: VarianceThreshold
- 代码
- 运行结果
- 结果1:threshold=0时运行的结果
- 结果2:threshold=10时运行的结果
- 10.数据降维: StandardScaler
- 代码
- 运行结果
- n_components=2
- n_components=0.95 代表保留95%的特征
- 本章学习资源
环境配置(必看)
Anaconda-创建虚拟环境的手把手教程相关环境配置看此篇文章,本专栏深度学习相关的版本和配置,均按照此篇文章进行安装。
头文件引用
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.decomposition import PCA
from sklearn.feature_selection import VarianceThreshold
from scipy.stats import pearsonr
import pandas as pd
import jieba
1.数据集: sklearn
代码
1.load_iris() 获取鸢尾花数据集,数据集的形状为(150, 4)
2.train_test_split()调用划分数据集的函数,test_size=0.2意思是将150个数据中的20%划分为测试集,剩下的80%为训练集。从代码运行的图中 x_train.shape: (120, 4)可以看出,训练集为150 * 0.8 = 120个
3.其他的打印,可以自己运行程序去看一下
def datasets_demo():"""获取鸢尾花数据集:return:"""# 获取鸢尾花数据集iris = load_iris()print(f"鸢尾花数据集的返回值: {iris}")# print("查看数据集描述: \n", iris["DESCR"])print(f"查看特征值的名字:{iris.feature_names}")# print(f"查看特征值:{iris.data} \n 特征值的形状:{iris.data.shape}")print(f"标签组:{iris.target}")print(f"标签名:{iris.target_names}")# 数据集划分 特征数据 目标数据 测试集比例 随机种子x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=20)print(f"x_train: \n {x_train} \n x_train.shape: {x_train.shape}")return None
运行结果
鸢尾花数据集的返回值:


查看特征值的名字、标签组、标签名

划分数据集后,训练集的形状

2.字典特征抽取: DictVectorizer
代码
1.从运行结果可以看出,'city’有北京、上海、深圳三个类别,对应one-hot编码就是001 010 100三种情况;'temperature’只有就是顺应数值。
2.DictVectorizer()默认返回的是稀疏矩阵,结果在下边的运行结果中。其中的:
(0, 1) 1.0
(1, 0) 1.0
(2, 2) 1.0
可以看出是对应非稀疏矩阵的坐标位置。
3.数据需要处理成字典的类型才可以使用DictVectorizer()
def dict_demo():"""字典特征抽取: DictVectorizer:return:"""data = [{'city': '北京', 'temperature': 100},{'city': '上海', 'temperature': 60},{'city': '深圳', 'temperature': 30}]# 1.实例化一个转换器类 不填写参数默认返回的是稀疏矩阵transfer = DictVectorizer(sparse=False)# 2.调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)print("特征名字: \n", transfer.get_feature_names())return None
运行结果

稀疏矩阵

3.文本特征抽取(英文文本): CountVectorizer()
代码
1.CountVectorizer()没有像DictVectorizer()通过输入参数来控制是否返回稀疏矩阵,而是通过data_new.toarray()来转换为非稀疏矩阵
2.CountVectorizer(stop_words=[“is”, “too”]),可以通过入参stop_words=[“is”, “too”]来控制不统计某些单词。
def count_demo():"""文本特征抽取: CountVectorizer:return:"""data = ["Life is short, i like like python", "life is too long, i dislike python"]# 1.实例化一个转换器类transfer = CountVectorizer()# 2.调用fit_transform()data_new = transfer.fit_transform(data)# data_new.toarray()生成非稀疏矩阵print("data_new:\n", data_new.toarray())print("特征名字: \n", transfer.get_feature_names())return None
运行结果

4.中文文本分词(中文文本特征抽取使用)
代码
1.运行函数: cut_word(“我爱北京天安门”), 得到运行结果
def cut_word(text):"""中文分词: 我爱北京天安门:param text::return:"""# jieba.cut(text)对字符串进行分词处理# " ".join() 转换为字符串tmp = " ".join(list(jieba.cut(text)))print(f"{tmp}\n{type(tmp)}")return tmp
运行结果

5.中文文本特征抽取
代码
1.需要调用cut_word()进行分词,然后再进行特征抽取
2.中文文本特征抽取与英文文本抽取唯一的不同就是分词,后续是一样的处理
3.与TfidfVectorizer()计算出的结果不同,CountVectorizer()统计的是特征出现的个数,TfidfVectorizer()统计的是特征的重要程度
def count_chinses_demo():"""中文文本特征提取,自动分词:return:"""# 将中文文本进行分词data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))print(f"data_new = \n{data_new}")# 1.实例化一个转换器类transfer = CountVectorizer()# 2.调用fit_transform()data_final = transfer.fit_transform(data_new)# data_final.toarray()生成非稀疏矩阵print("data_final:\n", data_final.toarray())print("特征名字: \n", transfer.get_feature_names())return None
运行结果

6.文本特征抽取: TfidfVectorizer
代码
1.TfidfVectorizer(stop_words=[“is”, “too”]),可以通过入参stop_words=[“is”, “too”]来控制不统计某些单词。
2.计算出的结果矩阵,是代表各个特征的重要程度
def tfidf_demo():"""用TF-IDF的方法进行文本特征抽取:return:"""# 将中文文本进行分词data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。","我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。","如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]data_new = []for sent in data:data_new.append(cut_word(sent))# 1.实例化一个转换器类transfer = TfidfVectorizer()# 2.调用fit_transform()data_final = transfer.fit_transform(data_new)print("data_final:\n", data_final.toarray())print("特征名字: \n", transfer.get_feature_names())return None
运行结果

7.归一化:MinMaxScaler
代码
1.需要dating.txt数据的可以把邮箱留在评论区
2.如果样本的最大值或者最小值是异常点,对归一化的结果有很大的影响,所以对数据进行处理更建议使用下边的标准化
def minmax_demo():"""归一化:return:"""# 1、获取数据data = pd.read_csv("dating.txt")# 获取前3列数据data = data.iloc[:, :3]# print("data:\n", data)# 2、实例化一个转换器类# feature_range=[2, 3] 归一化放缩的范围[2, 3]transfer = MinMaxScaler(feature_range=[2, 3])# 3、调用fit_transform# data数据的形状(n_samples, n_features) 行:样本数 列:特征数data_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None
运行结果
可以看到归一化后的数值全部在[2, 3]范围内,通过MinMaxScaler的入参feature_range=[2, 3]来进行调整

8.标准化: StandardScaler
代码
1.处理之后,对于每列来说,所有数据都聚集在均值为0,标准差为1的附近
def stand_demo():"""标准化:return:"""# 1、获取数据data = pd.read_csv("dating.txt")data = data.iloc[:, :3]# print("data:\n", data)# 2、实例化一个转换器类transfer = StandardScaler()# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None
运行结果

9.过滤低方差特征: VarianceThreshold
代码
1.pearsonr()得出皮尔逊相关系数,相关系数r的值介于-1至1之间
- r > 0,表示两变量正相关, r < 0,两变量负相关;
- |r| = 1,表示两变量为完全正相关, r = 0,表示两变量无相关关系;
2.相关系数,只看第一个值即可,不需要看第二个值。例如:
相关系数: (-0.004389322779936271, 0.8327205496564927)
只看-0.004389322779936271即可。
def variance_demo():"""过滤低方差特征:return:"""# 1、获取数据data = pd.read_csv("factor_returns.csv")data = data.iloc[:, 1:-2]print("data:\n", data)# 2、实例化一个转换器类transfer = VarianceThreshold(threshold=10)# 3、调用fit_transformdata_new = transfer.fit_transform(data)print("data_new:\n", data_new, data_new.shape)# 计算某两个变量之间的相关系数r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print("相关系数:\n", r1)r2 = pearsonr(data['revenue'], data['total_expense'])print("revenue与total_expense之间的相关性:\n", r2)return None
运行结果
结果1:threshold=0时运行的结果
可以看到数据原本是具有9个特征,设置threshold=0后,过滤掉0个特征,还剩下9个特征

结果2:threshold=10时运行的结果
可以看到数据原本是具有9个特征,设置threshold=10后,过滤掉2个特征,还剩下7个特征

10.数据降维: StandardScaler
StandardScaler()的作用:数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量的信息
代码
1.n_components=2减少到2个特征,代码中是将4个特征减少到2个特征
def pca_demo():"""PCA降维:主成分分析:return:"""data = [[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]# 1.实例化一个转换器类# n_components 1.整数:留下特征数 2.小数: 保留特征的百分比transfer = PCA(n_components=2)# 2.调用fit_transform()data_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None
运行结果
n_components=2

n_components=0.95 代表保留95%的特征
从结果看,保留95%的信息依旧还保留2个特征,说明这个PCA的方法还是不错的!

本章学习资源
黑马程序员3天快速入门python机器学习
我是跟着视频进行的学习,欢迎大家一起来学习!
相关文章:
3.特征工程-特征抽取、特征预处理、特征降维
文章目录 环境配置(必看)头文件引用1.数据集: sklearn代码运行结果 2.字典特征抽取: DictVectorizer代码运行结果稀疏矩阵 3.文本特征抽取(英文文本): CountVectorizer()代码运行结果 4.中文文本分词(中文文本特征抽取使用)代码运行结果 5.中文文本特征抽…...

RISC-V (五)上下文切换和协作式多任务
任务(task) 所谓的任务就是寄存器的当前值。 -smp后面的数字指的是hart的个数,qemu模拟器最大可以有8个核,此文围绕一个核来讲。 QEMU qemu-system-riscv32 QFLAG -nographic -smp 1 -machine virt -bios none 协作式多任务 …...
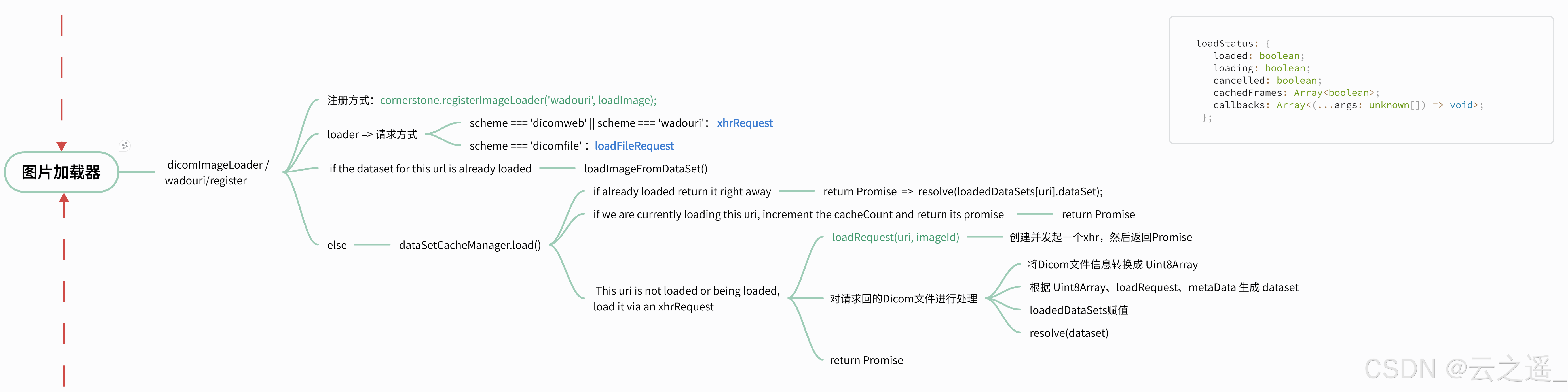
Cornerstone加载本地Dicom文件第二弹 - Blob篇
🍀 引言 当我们刚接触Cornerstone或拿到一组Dicom文件时,如果没有ImageID和后台接口,可能只是想简单测试Cornerstone能否加载这些Dicom文件。在这种情况下,可以使用本地文件加载的方法。之前我们介绍了通过node启动服务器请求文件…...

C语言中整数类型及其类型转换
1.数据的存储和排列 是的,在C语言中,整数类型通常以补码(twos complement)形式存储在内存中。这是因为补码表示法在处理有符号整数的加减运算上更为简便和高效。 2.有符号数和无符号数之间的转换 在C语言中,有符号数和…...

powerjob连接postgresql数据库(支持docker部署)
1.先去pg建一个powerjob-product库 2.首先去拉最新的包,然后找到server模块,把mysql的配置文件信息替换成pg的 spring.datasource.hikari.auto-committrue spring.datasource.remote.hibernate.properties.hibernate.dialecttech.powerjob.server.pers…...
)
浅谈位运算及其应用(c++)
目录 一、位运算的基础(一)位与(&)(二)位或(|)(三)位异或(^)(四)位取反(~)&#x…...

Git版本管理中下列不适于Git的本地工作区域的是
Git版本管理中下列不适于Git的本地工作区域的是 A. 工作目录 B. 代码区 C. 暂存区 D. 资源库 选择B Git本地有四个工作区域: 工作目录(Working Directory)、 暂存区(Stage/Index)、 资源库(Repository或Git Directory)、 git仓库(Remote Di…...

webGL + WebGIS + 数据可视化
webGL: 解释:用于在浏览器中渲染 2D 和 3D 图形。它是基于 OpenGL ES 的,提供了直接操作 GPU 的能力。 库: Three.jsBabylon.jsPixiJSReglGlMatrixOsgjs WebGIS: 解释:用于在 Web 浏览器中处理和展示地…...

职场“老油条”的常规操作,会让你少走许多弯路,尤其这三点
有句话说得好:“在成长的路上,要么受教育,要么受教训。” 挨过打才知道疼,吃过亏才变聪明,从职场“老油条”身上能学到很多经验,不一定全对,但至少有可以借鉴的地方,至少能让你少走…...

Ceres Cuda加速
文章目录 一、简介二、准备工作三、实现代码四、实现效果参考资料一、简介 字Ceres2.2.1版本之后,作者针对于稠密矩阵的分解计算等操作进行了Cuda加速,因此这里就基于此项改动测试一下效果。 二、准备工作 1、首先是需要安装Cuda这个英伟达第三方库,https://developer.nvidi…...

微信小程序生成小程序转发链接,携带参数跳转到另外一个页面
🤵 作者:coderYYY 🧑 个人简介:前端程序媛,目前主攻web前端,后端辅助,其他技术知识也会偶尔分享🍀欢迎和我一起交流!🚀(评论和私信一般会回!!) 👉 个人专栏推荐:《前端项目教程以及代码》 ✨一、前言 需求:在页面A生成分享链接(携带参数),分享到微信…...
图解RocketMQ之消息如何存储
大家好,我是苍何。 人一辈子最值得炫耀的不应该是你的财富有多少(虽然这话说得有点违心,呵呵),而是你的学习能力。技术更新迭代的速度非常快,那作为程序员,我们就应该拥有一颗拥抱变化的心&…...

2024年中国信创产业发展白皮书精简版
获取方式: 链接:https://pan.baidu.com/s/1rEHMfcCfJm4A40vzrewoCw?pwda5u1 提取码:a5u1 得益于中国数字经济的迅猛发展,2023年中国信创产业规模达20961.9亿元,2027年有望达到37011.3亿元,中国信创市场…...

Redis2-Redis常见命令
目录 Redis数据结构介绍 Redis通用命令 KEYS DEL EXISTS EXPIRE String类型 Key的层级格式 Hash类型 List类型 Set类型 SortedSet类型 Redis数据结构介绍 Redis是一个key-value的数据库,key一般是String数据库,value的类型多种多样 可以通过…...

一天攻克一个知识点 —— 设计模式之动态代理
一、设计模式之代理设计 代理设计是在Java开发中使用较多的一种设计模式,所谓的代理设计模式就是指一个代理主体操作真实主体,真实主体操作具体业务,代理主体负责给具体业务添砖加瓦。 就好比在生活中你有一套房子想要出租(你真实主体)&…...

数据采集与预处理【大数据导论】
各位大佬好 ,这里是阿川的博客,祝您变得更强 个人主页:在线OJ的阿川 大佬的支持和鼓励,将是我成长路上最大的动力 阿川水平有限,如有错误,欢迎大佬指正 数据采集与预处理前 必看 【大数据导论】—大数据序…...

白骑士的PyCharm教学进阶篇 2.2 高级调试技术
系列目录 上一篇:白骑士的PyCharm教学进阶篇 2.1 高效编码技巧 在Python开发中,调试是一个非常重要的环节。PyCharm作为一款功能强大的IDE,不仅提供了基本的调试功能,还包含了许多高级调试工具与技巧。本篇将详细介绍这些高级调试…...

[网鼎杯]2018Unfinish
使用ctf在线靶场https://adworld.xctf.org.cn/home/index。 进入靶场,发现是一个登录页面。 使用awvs进行扫描,发现存在login.php和register.php,并且register.php存在sql注入漏洞。 访问一下register.php试试,发现是一个注册页面…...

Java算法-力扣leetcode-383. 赎金信
383. 赎金信 给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。 如果可以,返回 true ;否则返回 false 。 magazine 中的每个字符只能在 ransomNote 中使用一次。 示例 1:…...

使用idea对spring全家桶的各种项目进行创建
目录 1. 简介2. spring2.1 简介2.2 创建 3. springmvc3.1 介绍3.2 创建 4. springboot4.1 简介4.2 创建(仅仅就其中一种) 5. 其他:maven6. 参考链接 1. 简介 因为总是分不清spring全家桶,所以就在这里进行一个总结。 2. spring …...

sudo企业级应用【20260525】001篇
文章目录 一、总体设计思路 1️⃣ 设计原则 2️⃣ 日志策略(重点) 二、10 个真实生产场景(含 sudoers 配置) 🔹 Linux 系统管理(3 个) ✅ 场景 1:基础运维(用户 / 权限) ✅ 场景 2:磁盘与文件系统 ✅ 场景 3:网络与防火墙 🔹 云管理(2 个) ✅ 场景 4:云 CLI …...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题
终极解决方案:Windows Cleaner免费开源工具,3步彻底解决C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否也经历过这样的…...