MMSeg无法使用单类自定义数据集训练
文章首发及后续更新:https://mwhls.top/4423.html,无图/无目录/格式错误/更多相关请至首发页查看。
新的更新内容请到mwhls.top查看。
欢迎提出任何疑问及批评,非常感谢!
摘要:将三通道图像转为一通道图像,并将类别的通道值统一为0, 1, 2,以解决MMSeg的报错与无法训练问题
描述
- 跑自定义数据集时报错,理论上其它东西都没错,那就只能是图片问题。
- 但我这次弄了两个数据集,上一个虽然也报这个错,不过用某些方式解决了,可行的数据集的 GT 是彩色图片,报错是黑白图片,检查发现黑白图片也是三通道,那就不该是通道问题。
- 但查官方 issue 后,发现他们推荐单通道:https://github.com/open-mmlab/mmsegmentation/issues/1625#issuecomment-1140384065
- 在更改为单通道后,以下报错消失,但出现了新的问题,指标/损失异常
ValueError: Input and output must have the same number of spatial dimensions, but got input with with spatial dimensions of [128, 128] and output size of torch.Size([512, 512, 3]). Please provide input tensor in (N, C, d1, d2, ...,dK) format and output size in (o1, o2, ...,oK) format.- 多次测试,将单分类分为两类,背景类与目标类,分别对应像素值
0,1(值域 0-255),而后解决。 - 但出现目标类难训练,改变损失权重后解决。
- ref: https://blog.patrickcty.cc/2021/05/21/mmsegmentation%E4%BA%8C%E5%88%86%E7%B1%BB%E9%85%8D%E7%BD%AE/
- 顺带一提,MMSeg 说更新了类别为 1 时的处理,但我更新到最新版后依然和老版一样。
- 见:https://github.com/open-mmlab/mmsegmentation/pull/2016
代码
- 排序代码有点难写,不想动脑子,因此只有一个量体裁衣的代码。
- 给定图片背景值为
(0, 0, 0),目标值为(255, 255, 255),代码将其改为(0)与(1) - 以下两个代码放在同级文件夹下,运行 chennel3to1.py,输入待处理文件夹(支持递归),输出结果见 log 文件夹。
- 我其实写了好多类似的小工具,但是就传了最初版到 GitHub 上,太懒了…
# channel3to1.py
from base_model import BaseModel
import cv2
import numpy as npclass Channels3to1(BaseModel):def __init__(self):super().__init__()self.change_log_path()passdef run(self):path = input("Input path: ")files_path = self.get_path_content(path, 'allfile')self.log(f"Path: {path}")for i, file_path in enumerate(files_path):self.log(f"{i+1}: {file_path}")for i, file_path in enumerate(files_path):img = cv2.imread(file_path)H, W, C = img.shapeimg = img[:, :, 0].tolist()for h in range(H):for w in range(W):if img[h][w] != 0:img[h][w] = [1]else:img[h][w] = [0]img = np.array(img)save_path = self.log_dir + "/"+ self.path2name(file_path, keep_ext=True)cv2.imwrite(save_path, img, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])self.log(f"{i+1}: {file_path} converted (H, W, 3) -> (H, W, 1) to {save_path}")if __name__ == "__main__":Channels3to1().run()
# base_model.py
import os
import os.path as osp
import re
import json
import time
import datetimeclass BaseModel():"""BaseModel, call it "utils" is OK."""def __init__(self, log_dir='', lang='en'):if log_dir == '':self.log_root = f"./log/{self.__class__.__name__}"else:self.log_root = log_dirself.log_dir = self.log_rootself.timestamp = time.time()self.log_file = f"{self.__class__.__name__}_{self.timestamp}.log"# self.lang_path = "./languages"# self.lang_dict = {# "en": "English.json",# "zh": "Chinese.json"# }# self.lang_encoding = {# "en": "utf-8",# "zh": "gb18030"# }# self.lang = {}# self.parse_from_language("zh")def help(self): """ Help functionPrint the help message"""self.log(self.__doc__)def change_log_path(self, mode="timestamp"):if mode == "timestamp":self.log_dir = osp.join(self.log_root, str(self.timestamp))elif mode == "root":self.log_dir = self.log_rootdef init_log_file(self):self.log_file = f"{self.__class__.__name__}_{time.time()}.log"def get_path_content(self, path, mode='allfile'):"""mode:allfile: All files in path, including files in subfolders.file: Files in path, only including files in this dir: pathdir: Dirs in path, only including Dir in this dir: path"""path_content = []index = 0for root, dirs, files in os.walk(path):index += 1if mode == 'allfile':for file in files:file_path = osp.join(root, file)path_content.append(file_path)if mode == 'file':for file in files:file_path = osp.join(root, file)path_content.append(file_path)breakif mode == 'dir':for dir in dirs:dir_path = osp.join(root, dir)path_content.append(dir_path)breakreturn path_contentdef is_file_meet(self, file_path, condition={'size_max': '10M', 'size_min': '10M', 'ext_allow': ['pth', 'pt', 't'],'ext_forbid': ['pth', 'pt', 't'],'name_allow': ['epoch_99.t'],'name_forbid': ['epoch_99.t']}):meet = Truefor k, v in condition.items():if k == 'size_max':# file size should <= size_maxmax_value = self.unit_conversion(v, 'B')file_size = os.path.getsize(file_path)if not file_size <= max_value:meet = Falseelif k == 'size_min':# file size should >= size_minmin_value = self.unit_conversion(v, 'B')file_size = os.path.getsize(file_path)if not file_size >= min_value:meet = Falseelif k == 'ext_allow':# file's extension name should in ext_allow[]_, file_name = os.path.split(file_path)_, ext = os.path.splitext(file_name)ext = ext[1:]if not ext in v:meet = Falseelif k == 'ext_forbid':# file's extension name shouldn't in ext_forbid[]_, file_name = os.path.split(file_path)_, ext = os.path.splitext(file_name)ext = ext[1:]if ext in v:meet = Falseelif k == 'name_allow':# file's name should in name_allow[]_, file_name = os.path.split(file_path)if not file_name in v:meet = Falseelif k == 'name_forbid':# file's name shouldn't in name_forbid[]_, file_name = os.path.split(file_path)if file_name in v:meet = Falsereturn meetdef unit_conversion(self, size, output_unit='B'):# convert [GB, MB, KB, B] to [GB, MB, KB, B]if not isinstance(size, str):return size# to Bytesize = size.upper()if 'GB' == size[-2:] or 'G' == size[-1]:size = size.replace("G", '')size = size.replace("B", '')size_num = float(size)size_num = size_num * 1024 * 1024 * 1024elif 'MB' == size[-2:] or 'M' == size[-1]:size = size.replace("M", '')size = size.replace("B", '')size_num = float(size)size_num = size_num * 1024 * 1024elif 'KB' == size[-2:] or 'K' == size[-1]:size = size.replace("K", '')size = size.replace("B", '')size_num = float(size)size_num = size_num * 1024elif 'B' == size[-1]:size = size.replace("B", '')size_num = float(size)else:raise# to output_unitif output_unit in ['GB', 'G']:size_num = size_num / 1024 / 1024 / 1024if output_unit in ['MB', 'M']:size_num = size_num / 1024 / 1024if output_unit in ['KB', 'K']:size_num = size_num / 1024if output_unit in ['B']:size_num = size_num# returnreturn size_numdef mkdir(self, path):if not osp.exists(path):os.makedirs(path)def split_content(self, content):if isinstance(content[0], str):content_split = []for path in content:content_split.append(osp.split(path))return content_splitelif isinstance(content[0], list):contents_split = []for group in content:content_split = []for path in group:content_split.append(osp.split(path))contents_split.append(content_split)return contents_splitdef path_to_last_dir(self, path):dirname = osp.dirname(path)last_dir = osp.basename(dirname)return last_dirdef path2name(self, path, keep_ext=False):_, filename = osp.split(path)if keep_ext:return filenamefile, _ = osp.splitext(filename)return filedef sort_list(self, list):# copy from: https://www.modb.pro/db/162223# To make 1, 10, 2, 20, 3, 4, 5 -> 1, 2, 3, 4, 5, 10, 20list = sorted(list, key=lambda s: [int(s) if s.isdigit() else s for s in sum(re.findall(r'(\D+)(\d+)', 'a'+s+'0'), ())])return listdef file_last_subtract_1(self, path, mode='-'):"""Just for myself.file:xxx.png 1ccc.png 2---> mode='-' --->file:xxx.png 0ccc.png 1"""with open(path, 'r') as f:lines = f.readlines()res = []for line in lines:last = -2 if line[-1] == '\n' else -1line1, line2 = line[:last], line[last]if mode == '-':line2 = str(int(line2) - 1)elif mode == '+':line2 = str(int(line2) + 1)line = line1 + line2 + "\n"if last == -1:line = line1 + line2res.append(line)with open(path, 'w') as f:f.write("".join(res))def log(self, content):time_now = datetime.datetime.now()content = f"{time_now}: {content}\n"self.log2file(content, self.log_file, mode='a')print(content, end='')def append2file(self, path, text):with open(path, 'a') as f:f.write(text)def log2file(self, content, log_path='log.txt', mode='w', show=False):self.mkdir(self.log_dir)path = osp.join(self.log_dir, log_path)with open(path, mode, encoding='utf8') as f:if isinstance(content, list):f.write("".join(content))elif isinstance(content, str):f.write(content)elif isinstance(content, dict):json.dump(content, f, indent=2, sort_keys=True, ensure_ascii=False)else:f.write(str(content))if show:self.log(f"Log save to: {path}")def list2tuple2str(self, list):return str(tuple(list))def dict_plus(self, dict, key, value=1):if key in dict.keys():dict[key] += valueelse:dict[key] = valuedef sort_by_label(self, path_label_list):"""list:["mwhls.jpg 1", # path and label"mwhls.png 0", # path and label"mwhls.gif 0"] # path and label-->list:[["0", "1"], # label["mwhls.png 0", "mwhls.gif 0"], # class 0["mwhls.jpg 1"]] # class 1"""label_list = []for path_label in path_label_list:label = path_label.split()[-1]label_list.append(label)label_set = set(label_list)res_list = []res_list.append(list(label_set))for label in label_set:index_equal = [] # why index_equal = label_list == label isn't working?for i, lab in enumerate(label_list):if lab == label:index_equal.append(i)res = [path_label_list[i] for i in index_equal] # why path_label_list[index_equal] isn't working either??res_list.append(res)return res_listdef clear_taobao_link(self, text):# try:link = "https://item.taobao.com/item.htm?"try:id_index_1 = text.index('&id=') + 1id_index = id_index_1except:passtry:id_index_2 = text.index('?id=') + 1id_index = id_index_2except:passtry:id = text[id_index: id_index+15]text = link + idexcept:passreturn text# except:# return textdef parse_from_language(self, lang='en'):path = osp.join(self.lang_path, self.lang_dict[lang])with open(path, "rb") as f:self.lang = json.load(f)if __name__ == '__main__':# .py to .exe# os.system("pyinstaller -F main.py")# print(get_path_content("test2"))# file_last_subtract_1("path_label.txt")pass
相关文章:

MMSeg无法使用单类自定义数据集训练
文章首发及后续更新:https://mwhls.top/4423.html,无图/无目录/格式错误/更多相关请至首发页查看。 新的更新内容请到mwhls.top查看。 欢迎提出任何疑问及批评,非常感谢! 摘要:将三通道图像转为一通道图像,…...

Redis使用方式
一、Redis基础部分: 1、redis介绍与安装比mysql快10倍以上 *****************redis适用场合**************** 1.取最新N个数据的操作 2.排行榜应用,取TOP N 操作 3.需要精确设定过期时间的应用 4.计数器应用 5.Uniq操作,获取某段时间所有数据排重值 6.实时系统,反垃圾系统7.P…...
 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播)
无主之地3重型武器节奏评分榜(9.25) 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播
无主之地3重型武器节奏评分榜(9.25) 枪械名 红字效果 元素属性 清图评分 Boss战评分 泛用性评分 特殊性评分 最终评级 掉落点 掉率 图片 瘟疫传播者 发射巨大能量球,能量球会额外生成追踪附近敌人的伴生弹 全属性 SSS SSS SSS - T0 伊甸6号-…...

什么是编程什么是算法
1.绪论 编程应在一个开发环境中完成源程序的编译和运行。首先,发现高级语言开发环境,TC,Windows系统的C++,R语言更适合数学专业的学生。然后学习掌握编程的方法,在学校学习,有时间的人可以在网上学习,或者购买教材自学。最后,编写源程序,并且在开发环境中实践。 例如…...

【c++】函数
文章目录函数的定义函数的调用值传递常见样式函数的声明函数的分文件编写函数的作用: 将一段经常使用的代码封装起来,减少重复代码。 一个较大的程序,一般分为若干个程序块,每个模板实现特定的功能。 函数的定义 返回值类型 函数…...

[golang gin框架] 1.Gin环境搭建,程序的热加载,路由GET,POST,PUT,DELETE
一.Gin 介绍Gin 是一个 Go (Golang) 编写的轻量级 http web 框架,运行速度非常快,如果你是性能和高效的追求者,推荐你使用 Gin 框架.Gin 最擅长的就是 Api 接口的高并发,如果项目的规模不大,业务相对简单,这…...
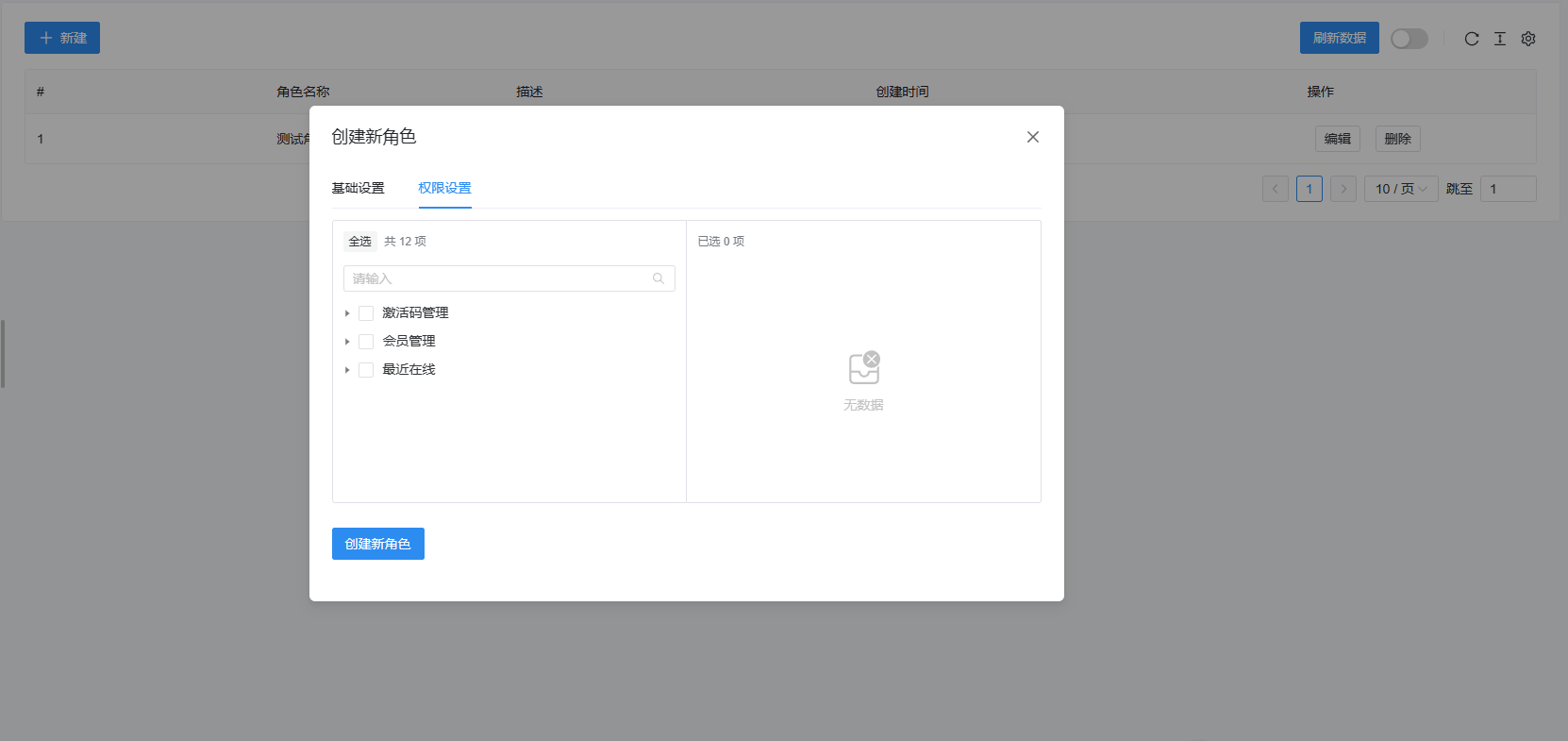
【开源】祁启云网络验证系统V1.11
简介 祁启云免费验证系统 一个使用golang语言、Web框架beego、前端Naive-Ui-Admin开发的免费网络验证系统 版本 当前版本1.11 更新方法 请直接将本目录中的verification.exe/verification直接覆盖到你服务器部署的目录,更新前,请先关闭正在运行的验…...

震源机制(Focal Mechanisms)之沙滩球(Bench Ball)
沙滩球包含如下信息: a - 判断断层类型,可根据球的颜色快速判断 b - 判断断层的走向(strike),倾角(dip) c - 确定滑移角/滑动角(rake) 走向 ,倾角,滑移角 如不了解断层的定义,可以先阅读:震…...

C++入门:多态
多态按字面的意思就是多种形态。当类之间存在层次结构,并且类之间是通过继承关联时,就会用到多态。C 多态意味着调用成员函数时,会根据调用函数的对象的类型来执行不同的函数。1、纯虚函数声明如下: virtual void funtion1()0; 纯…...
(C++实现))
华为OD真题_工位序列统计友好度最大值(100分)(C++实现)
题目描述 工位由序列F1,F2…Fn组成,Fi值为0、1或2。其中0代表空置,1代表有人,2代表障碍物。 1、某一空位的友好度为左右连续老员工数之和 2、为方便新员工学习求助,优先安排友好度高的空位 给出工位序列,求所有空位中友好度的最大值。 输入描述 第一行为工位序列:F1,F…...

[ruby on rails]MD5、SHA1、SHA256、Base64、aes-128-cbc、aes-256-ecb
md5 puts Digest::MD5.hexdigest(admin) sha1 require digest/sha1 puts Digest::SHA1.hexdigest(admin)base64 require base64 code Base64.encode64(admin) source Base64.decode64(code)aes-128-cbc # base64 解密数据 session_key Base64.decode64(session_ke…...

《NFL星计划》:拉斯维加斯突袭者·橄榄1号位
拉斯维加斯袭击者(英语: Las Vegas Raiders)又译拉斯维加斯侵略者或拉斯维加斯突击者,是一支主场位于美国内华达州拉斯维加斯的职业美式橄榄球球队,属全国橄榄球联盟 (NFL) 的美国橄榄球联合会 (AFC) 西区。实际上&…...

韩顺平Linux基础学习(1)
内容概括...
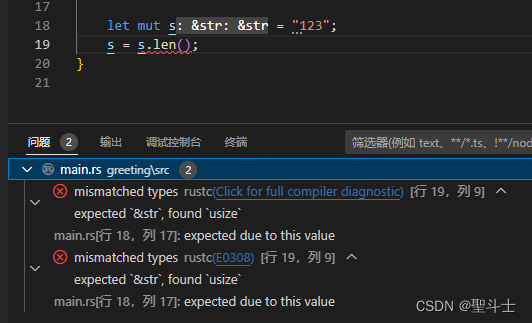
Rust学习入门--【6】Rust 基础语法
Rust 基础语法 变量,数据类型,注释,函数和控制流,这些是大部分编程语言都具有的编程概念。 本节将学习理解这些概念。 变量 Rust 是强类型语言,但具有自动判断变量类型的能力。这很容易让人与弱类型语言产生混淆。…...
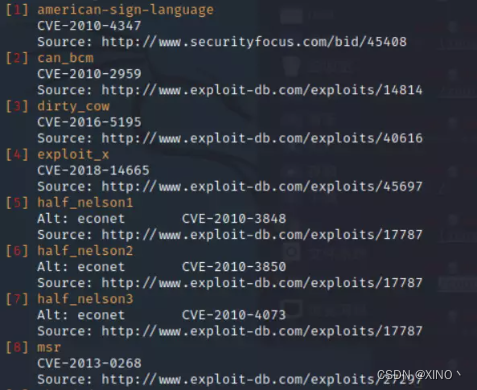
LINUX提权入门手册
前言 发点存货 LINUX权限简介 在学习提权之前我们先了解一下linux里面的权限我们使用命令: ls -al即可查看列出文件所属的权限: 文件头前面都有一段类似的字符,下面我们仔细分析一下里面符号分别代表什么。 -rw-r--r-- 1 root root 第一个符号-的…...
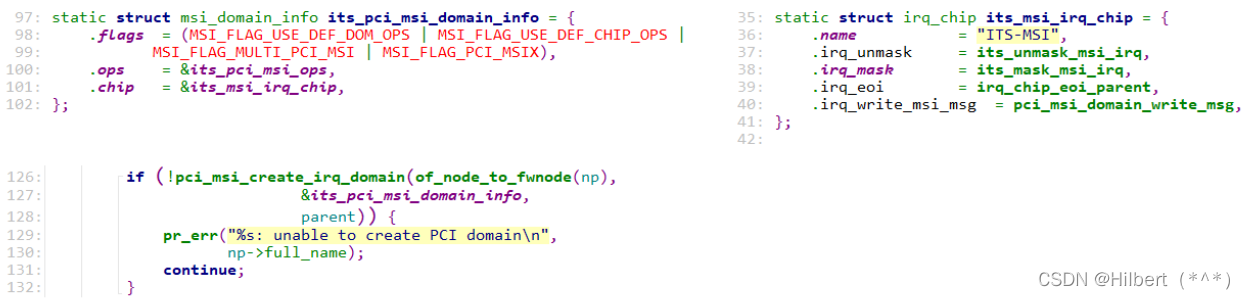
MSI_MSI-X中断之源码分析
MSI_MSI-X中断之源码分析 文章目录MSI_MSI-X中断之源码分析一、 怎么发出MSI/MSI-X中断1.1 在RK3399上体验1.1.1 安装工具1.1.2 查看设备MSI-X信息1.1.3 验证MSI-X信息二、 怎么使用MSI/MSI-X三、 MSI/MSI-X中断源码分析3.1 IRQ Domain创建流程3.1.1 GIC3.1.2 ITS3.1.3 PCI MSI…...

Docker--consul
目录 前言 一、Consul 简介 1.1、 consul 概述 1.2 、consul 的两种模式 1.3、consul 提供的一些关键特性 二、Consul 容器服务更新与发现 三、consul 部署 3.2、查看集群信息 四、registrator服务器 consul-template 五、consul 多节点 前言 服务注册与发现是微服…...

ESP-01S使用AT指令连接阿里云
ESP-01S使用AT指令连接阿里云 烧录MQTT AT固件 出厂的ESP-01S是基本的AT指令固件,没有MQTT的,所以无法通过MQTT指令与云平台通信,需要烧录固件(如果测试到有MQTT相关的指令,则不用重新烧录固件) 固件烧录…...
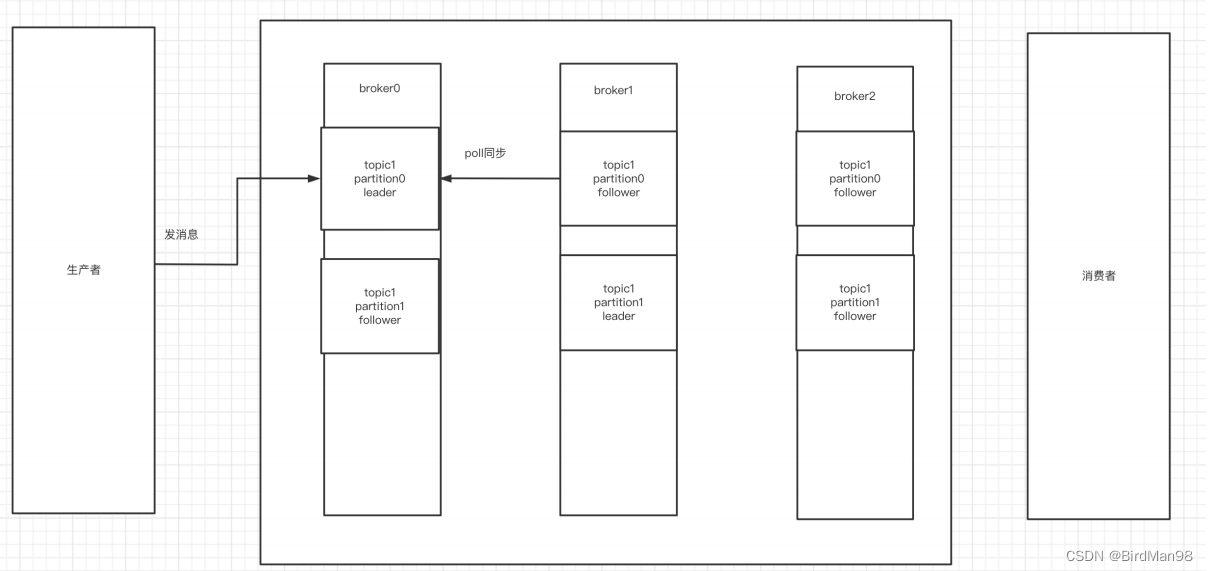
【Kafka】【三】安装Kafka服务器
Kafka基本知识 Kafka介绍 Kafka是最初由Linkedin公司开发,是⼀个分布式、⽀持分区的(partition)、多副本的 (replica),基于zookeeper协调的分布式消息系统,它的最⼤的特性就是可以实时的处理 …...

关于适配器模式,我遗漏了什么
近期有些tasks需要 重构or适配 老的代码。 与其向上面堆💩,不如优雅的去解决。 首先我的问题在于,错误的把 堆屎的操作 ,当作了适配器模式的操作。 比如原函数入参,需要更改某个属性,把这种操作外包一层…...

为什么92%的DeepSeek私有化部署在K8s上遭遇OOMKilled?——GPU内存隔离、vLLM适配与cgroups v2调优三重解法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek私有化部署的Kubernetes现状与OOMKilled困局 当前,DeepSeek系列大模型在企业私有化场景中广泛采用Kubernetes进行容器化编排部署。然而,实际落地过程中,内存…...
:Claude在长文档法律分析胜出32%,Gemini在实时多跳检索快4.8倍——你的业务该选谁?)
大模型选型生死局(企业CTO私藏对比清单):Claude在长文档法律分析胜出32%,Gemini在实时多跳检索快4.8倍——你的业务该选谁?
更多请点击: https://intelliparadigm.com 第一章:大模型选型生死局:Claude vs Gemini核心能力全景图 在企业级AI应用落地的关键阶段,模型选型已远非单纯比拼参数量或基准分数,而是对推理鲁棒性、上下文工程适配度、多…...

Jsxer:Adobe ExtendScript JSXBIN反编译终极指南与深度解析
Jsxer:Adobe ExtendScript JSXBIN反编译终极指南与深度解析 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer Jsxer是一款高性能的Adobe ExtendScript二进制格式(JSXBIN&#…...

2026程序员危机:AI岗位暴涨12倍,传统开发即将“毕业”?转型AI大模型开发,才是破局关键!
2026年技术圈将面临巨大变革,AI岗位需求激增,传统编程岗位面临淘汰风险。企业更看重懂AI、能提效的复合型人才。程序员需转型AI大模型开发,掌握系统设计、代码审查及AI工具应用能力。北大青鸟推出AI大模型开发实战营,聚焦落地开发…...

WarcraftHelper:3步解决魔兽争霸3卡顿与兼容性问题终极指南
WarcraftHelper:3步解决魔兽争霸3卡顿与兼容性问题终极指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3在现代电…...

从零到精通:AI大模型学习路线图,手把手带你入门!
本文提供了一条从基础到高级的AI大模型学习路线图,涵盖数学与编程基础、机器学习入门、深度学习实践、大模型探索以及进阶应用等方面。文章推荐了丰富的学习资源,包括经典书籍、在线课程、实践项目和开源平台,旨在帮助新手小白系统学习AI大模…...

大模型提示词驱动的工业图像标注流水线实战
1. 这不是“打标签”,而是让大模型替你做标注决策的整套工作流“Prompt-Based Automated Data Labeling and Annotation”——光看这个标题,很多人第一反应是:“哦,用大模型自动打标签”。但干过三年以上NLP数据工程、带过两个以上…...

企业内如何安全地通过Taotoken管理各部门的AI模型使用权限
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何安全地通过Taotoken管理各部门的AI模型使用权限 对于中大型企业而言,引入大模型能力是提升效率的关键一步&a…...

构建第二大脑的实战框架:Obsidian模板如何实现知识管理效率倍增
构建第二大脑的实战框架:Obsidian模板如何实现知识管理效率倍增 【免费下载链接】obsidian-template Starter templates for Obsidian 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-template 在信息过载的时代,知识工作者面临的核心挑战…...

3步视频PPT智能提取:告别繁琐截图,拥抱自动化高效工作流
3步视频PPT智能提取:告别繁琐截图,拥抱自动化高效工作流 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 还在为从视频中手动截取PPT幻灯片而烦恼吗࿱…...