软件测试学习笔记
测试学习
- 1. 测试流程
- 2. Bug的提出
- 什么是bug
- bug 的描述
- bug 级别
- 3. 测试用例的设计
- 什么是测试用例
- 测试用例应如何设计
- 基于需求的设计方法
- 等价类
- 边界值
- 场景法
- 正交表法
- 判定表法
- 错误猜测法
- 4. 自动化测试
- 回归测试
- 自动化分类
- 5. 安装 webdriver-manager 和 selenium
- 第一个web自动化测试脚本
- 6. web端自动化测试常用函数
- 查找元素
- 操作元素
- 点击
- 模拟按键输入
- 清除输入内容
- 获取文本信息
- 获取页面标题和URL
- 窗口
- 切换窗口
- 窗口大小设置
- 屏幕截图
- 关闭窗口
- 弹窗
- 警告弹窗 + 确认弹窗
- 提示弹窗
- 等待
- 强制等待
- 隐式等待
- 显式等待
- 浏览器导航
- 打开 刷新 前进 后退
- 文件上传
- 浏览器参数设置
- 设置无头模式
- 页面加载策略
- 7. 性能测试
- 常见性能测试指标
- 性能测试工具JMeter
- JMeter的下载和配置
- JMeter的基本使用流程
- JMeter元件作用域和执行顺序
- JMeter的重点组件
- 线程组
- HTTP取样器
- 查看结果树
- HTTP Cookie管理器
- HTTP 请求默认值
- 用户自定义变量
- CSV数据文件设置
- JSON提取器
- JSON断言
- 同步定时器
- 事务控制器
- Jmeter插件
- 梯度压测线程组
- 常见监听器
- 性能测试报告
1. 测试流程
测试人员是要非常懂用户需求是什么,从而才能检测出一个产品是否为用户所需要的合格的产品 , 而测试贯穿于软件的整个生命周期,一般是以下流程:
需求分析 -> 测试计划 -> 测试设计,测试开发 -> 测试执行 -> 测试评估 -> 上线 -> 运行维护
2. Bug的提出
什么是bug
- 当且仅当规格说明是存在的并且正确,程序与规格说明之间的不匹配才是错误。
- 当需求规格说明书没有提到的功能,判断标准以最终⽤⼾为准:当程序没有实现其最终用户合理预期的功能要求时,就是软件错误。
bug 的描述
描述bug的基本要素(包括但不限):问题出现的版本、问题出现的环境、问题出现的步骤、预期结果、实际结果
bug 级别
bug级别⼀般分为:崩溃、严重、⼀般、次要
根据公司规定的标准来制定bug 等级,大多数的bug都是一般和次要级别的
3. 测试用例的设计
什么是测试用例
测试用例(Test Case) 是为了实施测试而向被测试的系统提供的一组集合,这组集合包含:测试环境,操作步骤,测试数据,预期结果等
测试用例应如何设计
常规思考 + 逆向思维 + 发散性思维
- 测试用例不仅要根据有效和预料到的输⼊情况,⽽且也应该根据⽆效和未预料到的输⼊情况。
- 检查程序是否“未做其应该做的”仅是成功的⼀半,测试的另⼀半是检查程序是否“做了其不应该做的”。(是上⼀条原则的必然结果)
- 计划测试⼯作时不应默许假定不会发现错误。
功能测试+界⾯测试+性能测试+兼容性测试+易⽤性测试+安全测试
除此之外还有: 弱网测试 , 安装卸载测试等
基于需求的设计方法
基于需求的设计方法也是总的设计测试用例的方法,在工作中,我们需要参考需求文档/产品规格说明书来设计测试用例。
测试人员接到需求之后,要对需求进行分析和验证,从合理的需求中进⼀步分析细化需求,从细化的需求中找出测试点,根据这些测试点再去设计测试用例。
等价类
依据需求将输入(特殊情况下会考虑输出)划分为若干个等价类,从等价类中选出⼀个测试用例,如果 这个测试用例测试通过,则认为所代表的等价类测试通过,这样就可以用较少的测试用例达到尽量多的 功能覆盖,解决了不能穷举测试的问题。
等价类分类:
• 有效等价类:对于程序的规格说明书是合理的、有意义的输⼊数据构成的集合,利⽤有效等价类验
证程序是否实现了规格说明中所规定的功能和性能
• ⽆效等价类:根据需求说明书,不满⾜需求的集合。
根据等价类设计测试⽤例的⽅式:
1.确定有效等价类和⽆效等价类
2.编写测试⽤例,设计具体测试数据
边界值
边界值分析法就是对输⼊或输出的边界值进⾏测试的⼀种⿊盒测试⽅法。通常边界值分析法是作为对等 价类划分法的补充,这种情况下,其测试⽤例来⾃等价类的边界。
边界值包含:边界值+次边界值
场景法
每个需求都存在一个基本的流程, 在主流程里每个阶段都有可能发生其他的情况,导致流程出现异常
因此要对每个场景下是否会有别的阶段发生变化进行测试
正交表法
正交表发是为了减少用例数目。用尽量少的用例覆盖输入的两两组合
因此可以使用allpairs工具
第一步打开cmd:

第二步切换到allpairs目录下:

第三步打开微软自带的excel并输入用例内容:

第四步在pairs目录下创建一个.txt文件并将excel中的内容复制上去后保存


最后一步输入命令将结果保存到ret-test01.txt文件中:

此时pair目录下就会出现ret-test01.txt , 完成:


判定表法
判定表是⼀种表达逻辑判断的⼯具,形如:

根据判定表法设计测试用例的步骤:
- 确认需求中输入条件和输出条件
- 找出输入条件和输出条件之间的关系
- 画判定表
- 根据判定表编写测试用例
错误猜测法
错误猜测法是对被测试软件设计的理解,过往经验以及个人直觉,推测出软件可能存在的缺陷,从而针对性地设计测试用例的方法。
这个方法强调的是对被测试软件的需求理解以及设计实现的细节把握,还有个⼈的经验和直觉。
错误推测法和目前流行的“探索式测试方法”的基本思想一致,这类方法在敏捷开发模式下的投⼊产出比很高,被⼴泛应用于测试。
4. 自动化测试
自动化测试是通过测试人员来编写测试脚本来代替人工测试一些机械简单的测试,但是并不能取代人工测试
自动化的主要目的是用来进行回归测试
回归测试
软件有多个版本需要进行功能的整体回归
新版本的软件相对旧版本会更改一些功能或内容,因此新版本发布可能会对旧版本的软件产生影响,所以旧版本的软件也要进行测试,这就是回归测试
自动化分类
- 接口自动化测试
- 前端自动化测试(web前端,客户端)
5. 安装 webdriver-manager 和 selenium
前提:有python环境和PyCharm
webdriver-manager是一个web驱动管理程序
selenium是常用的自动化测试脚本编写库(本次安装版本为selenium4.0.0)
只要安装了python换进,就可以直接在命令行进行安装:
pip install webdriver-manager
pip install selenium==4.0.0
第一个web自动化测试脚本
编写一个python脚本,使用谷歌浏览器进入百度并搜索"蔡徐坤",完成后关闭
脚本代码:
#编写自动化脚本
import timefrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager# 1. 打开浏览器
##创建谷歌驱动路径
ChromeIns = ChromeDriverManager().install()
##创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
time.sleep(2)
# 2. 输入网址,要写完整
driver.get("https://www.baidu.com")
time.sleep(2)
# 3. 找到输入框,输入关键词蔡徐坤
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("蔡徐坤")
time.sleep(2)
# 4. 点击"百度一下"按钮
driver.find_element(By.CSS_SELECTOR,"#su").click();
time.sleep(2)
# 5. 关闭浏览器
driver.quit()
运行:


注意: 创建驱动等记得引入对应的方法
6. web端自动化测试常用函数
selenium库中有很多常用的自动化测试函数,下面举出几个常见的函数
查找元素
find_element(方式,“元素定位”) //查找一个元素
find_elements(方式,“元素定位”) //查找多个元素
元素定位的方式有很多,常用的主要是cssSelector 和 xpath
- cssSelector
选择器的功能就是选中页面中指定的元素,一般是用id选择器对元素进行定位 - xpath
xml路径语言,不仅可以在xml文件中查找信息,还可以在html中选取节点,下面是一些详细用法,可能会需要手动输入:- 获取HTML页面所有的节点
//* - 获取HTML页面指定的节点
//[指定节点]
//ul :获取HTML页面所有的ul节点
//input:获取HTML页面所有的input节点 - 获取⼀个节点中的直接子节点
/
//span/input - 获取一个节点的父节点
…
//input/… 获取input节点的父节点 - 实现节点属性的匹配
[@…]
//*[@id=‘kw’] 匹配HTML页面中id属性为kw的节点
- 获取HTML页面所有的节点
操作元素
获取到元素后,就可以对元素进行操作了,常见的有:点击,提交,输入,清除,获取文本
点击
click()
操作方式有两种,一种是查找+点击,一种是先查找后点击:
#查找+点击driver.find_element(By,CSS_SELECTOR,"#su").click()#先查找,后点击ele = driver.find_element(By,CSS_SELECTOR,"#su")ele.click()
模拟按键输入
send_keys("") //模拟键盘对网页中可输入的元素进行输入信息操作
driver.find_element(By,CSS_SELECTOR,"#su").send_keys("蔡徐坤")
如果连续的send_keys()只会对文本进行拼接,并不会清空后重新输入
清除输入内容
clear() //清除刚才输入的文本内容
driver.find_element(By,CSS_SELECTOR,"#su").clear()
获取文本信息
text()
print(driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(1) > a > span.title-content-title").text)

注意:文本和属性值不要混淆了,比如"百度一下"的文本就无法通过文本获取。 获取属性值需要使用方法 get_attribute(“属性名称”) ;
attribute=driver.find_element(By.CSS_SELECTOR,"#su").get_attribute("v alue")print(attribute)

获取页面标题和URL
title
current_url
title=driver.titleprint(title)url=driver.current_urlprint(url)

窗口
切换窗口
- 获取当前⻚⾯句柄:
driver.current_window_handle - 获取所有⻚⾯句柄:
driver.window_handles - 切换当前句柄为最新⻚⾯
curWindow = driver.current_window_handle
allWindows = driver.window_handles
for window in allWindows:if window != curWindow:driver.switch_to.window(window)
举例:
#点击百度图片
print("before:"+driver.title)
print("before:"+driver.current_url)
driver.find_element(By.CSS_SELECTOR,"#s-top-left > a:nth-child(6)").click()
#获取当前页面句柄
curWindow=driver.current_window_handle
#获取所有页面句柄
allWindow=driver.window_handles
for window in allWindow:if window != curWindow: #切换句柄driver.switch_to.window(window)
print("after:"+driver.title)
print("after:"+driver.current_url)

窗口大小设置
#窗口最大化
driver.maximize_window()
#窗口最小化
driver.minimize_window()
#窗口全屏
driver.fullscreen_window()
#手动设置窗口大小
driver.set_window_size(1024,768)
屏幕截图
我们的自动化脚本⼀般部署在机器上自动的去运行,如果出现了报错,我们是不知道的,可以通过抓拍来记录当时的错误场景
driver.save_screenshot('./images/image.png')
#简单版本
driver.save_screenshot('路径+图片名称.png') //不加路径则保存在脚本文件所在路径#但是因为图片名称是固定的,因此多次运行时将被覆盖,因此需要使用下面的方法#⾼阶版本
filename = "autotest-"+datetime.datetime.now().strftime('%Y-%m-%d-
%H%M%S')+'.png'
driver.save_screenshot('./images/'+filename)
关闭窗口
close()
关闭窗口和关闭浏览器驱动quit不同,关闭窗口仅仅只是关闭当前驱动窗口,若有多个窗口,则关闭完成后需要对driver重新定义
弹窗
弹窗的页面是找不到元素的,因此需要用到selenium的Alert接口
警告弹窗 + 确认弹窗
1.切换到弹窗
2.点击确认/取消
alert = driver.switch_to.alert
//确认
alert.accept()
//取消
alert.dismiss()
提示弹窗
1.切换到弹窗
2.输入信息
3.点击确认
alert = driver.switch_to.alert
//输入文本
alert.send_keys("haha")
//确认
alert.accept()
//取消
alert.dismiss()
等待
通常代码执行的速度比页面渲染的速度要快,这样就会出现因为渲染过慢出现的自动化误报的问题,使用selenium中提供的三种等待方法可以解决问题
强制等待
time.sleep() //单位为秒
优点:使用简单,调试的时候比较有效
缺点:影响运行效率,浪费大量的时间
隐式等待
隐式等待是⼀种智能等待,他可以规定在查找元素时,在指定时间内不断查找元素。如果找到则代码继续执行,直到超时没找到元素才会报错.
driver.implicitly_wait() //单位为秒
隐式等待作用域是整个脚本的所有元素。
即只要driver对象没有被释放掉( driver.quit() ),隐式等待就⼀直生效。这样的话无论查找什么元素,都会等待到规定时间内,若隐式等待规定时间内还是没有找到对应元素,则会报错
优点:智能等待,作用于全局
显式等待
显式等待也是⼀种智能等待,在指定超时时间范围内只要满足操作的条件就会继续执行后续代码
WebDriverWait(driver,sec).until(functions)
functions :涉及到selenium.support.ui.ExpectedConditions包下的ExpectedConditions类
ExpectedConditions下涉及到的方法
下面是一个显式等待百度搜索蔡徐坤后是否title为"蔡徐坤_百度搜索"的例子
import time
import datetime
import osfrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC #太长了命别名为EC
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManagerChromeInt = ChromeDriverManager().install()
driver = webdriver.Chrome(service=Service(ChromeInt))
driver.get("https://www.baidu.com")#隐式等待
#driver.implicitly_wait(2)#显示等待
#创建显示等待类对象
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("蔡徐坤")
driver.find_element(By.CSS_SELECTOR,"#su").click()
curr=driver.current_window_handle
allwindow = driver.window_handles
for window in allwindow:if window != curr:driver=window
time.sleep(2)
wait = WebDriverWait(driver,3)
wait.until(EC.title_is("蔡徐坤_百度搜索"))
time.sleep(2)
driver.close()driver.quit()
ExpectedConditions 预定义方法的一些示例:
title_is(title) //检查页面标题的期望值
title_contains(title) 检查标题是否包含区分⼤⼩写的⼦字符串的期望值
visibility_of_element_located(locator, str])检查元素是否存在于⻚⾯的DOM上并且可⻅的期望值。
presence_of_element_located(locator,str])⽤于检查元素是否存在于⻚⾯的DOM上的期望值
visibility_of(element) 检查已知存在于⻚⾯DOM上的元素是否可⻅的期望
alert_is_present() 检查是否出现弹窗
优点:显式等待是智能等待,可以自定义显式等待的条件,操作灵活
缺点:写法复杂
注意:不要混合隐式和显式等待,可能会导致不可预测的等待时间。
浏览器导航
打开 刷新 前进 后退
driver.get("https://www.baidu.com") //打开百度
driver.refresh() //刷新页面
driver.forward() //页面前进
driver.back() //页面后退
文件上传
点击文件上传的场景下会弹窗系统窗口,进行文件的选择。
selenium无法识别非web的控件,上传文件窗口为系统自带,无法识别窗口元素但是可以使用send_keys来上传指定路径的文件,达到的效果是⼀样的
例如:
driver.get("需要上传文件的url")
ele = driver.find_element(By.CSS_SELECTOR,"上传文件的元素").click()
ele.send_keys("D:\\file\\test.txt") #在这里上传文件路径即可
driver.find_element(By.CWW_SELECT,"点击上传按钮").click()
浏览器参数设置
自动化打开浏览器默认是有头模式
设置无头模式
无头模式:程序在后台运行,看不到界面表现
#安装驱动类
ChromeInt = ChromeDriverManager().install()
#设置浏览器参数
options = webdriver.ChromeOptions()
#将浏览器参数设置为无头模式
options.add_argument("-headless")
#添加到驱动类中
driver = webdriver.Chrome(service=Service(ChromeInt),options=options)
页面加载策略
driver.get()方法是等待所有资源加载完成的
但是我们可以更改一页面的加载方式,但这需要用到对浏览器参数的设置
options.page_load_strategy = '加载⽅式'
页面加载方式有三种
normal # 默认值, 等待所有资源下载
eager # 最常用的方式 : DOM 访问已准备就绪, 但诸如图像的其他资源可能仍在加载
none # 基本不用的方式:完全不会阻塞WebDriver ,这样可能会大量报错
7. 性能测试
为了发现系统性能问题或获取系统性能相关指标而进行的测试。
常见性能测试指标
- 并发数
- 吞吐量 (1.请求数量 2. 网络数据包 :KB)
- 响应时间
- 资源利用率
性能测试工具JMeter
性能测试中我们需要重点关注接口的性能问题,此时需要用到性能测试工具JMeter
JMeter的下载和配置
Jmeter使用前提是有java8以上的环境,下载前需要先配置java环境
下载链接(Windows环境下载.zip文件的就行)
下载完成后无需安装,直接解压即可使用,找到jmeter的bin目录,打开Jmeter.bat即可使用,但是最好还是配置环境变量使用cmd唤起更方便
在bin目录下的jmeter.properties文件中编辑language=zh_CN即可改为简体中文,配置完成后就可以开始使用了

JMeter的基本使用流程
1.打开jmeter
2.在测试计划下添加线程组


3.在线程组下添加HTTP请求

4.填写HTTP相关内容
5.在 线程组 下添加 查看结果树 监听器

6.点击 启动 即可查看接口测试结果
JMeter元件作用域和执行顺序
作用域:JMeter元件的作用域主要由测试计划的树形结构中的元件父子关系来确定。
执行顺序:
- 取样器(sampler)元件内组件不依赖其他元件就可执行,因此取样器不存在作用问题
- 元件作用域只对它的子节点有作用,
- 其他作用域默认根据测试计划中树形结构来定;
JMeter的重点组件
线程组
控制JMeter将用于执行测试的线程数,也可以把一个线程理解为⼀个测试用户。

线程数:一个线程即一个测试用户,设置发送的请求次数
Ramp-up时间(秒):设置性能测试运行时间,单位为秒
循环次数:
- 配置指定次数:控制脚本循环执行的次数
- 配置循环永远
▪ 需要调度器配置使用
▪ 运行时间:脚本执行时间
▪ 延迟启动时间:脚本等待指定时间才能运行
HTTP取样器
加必需的配置:
http协议
http主机名/IP
端口
◦ http协议端口号80
◦ https端口号443
请求方法
路径(目录+参数)
内容编码(默认的ISO国际标准,但对中文支持不友好,可以使⽤utf-8)
参数
◦ 参数可以拼在路径里,也可以卸载参数中
◦ POST参数要放到消息体数据中{wd:test}

查看结果树
查看测试结果的元件
取样器结果:统计请求相关的信息
1 Thread Name:线程组名称
2 Sample time:发送请求时间
3 load time:响应时间
4 Response code :接口响应状态码
HTTP Cookie管理器
作用:自动保存cookie,不用重复配置
线程组->添加->配置元件->HTTP Cookie管理器

HTTP Cookie管理器像Web浏览器一样存储和发送Cookie。如果HTTP请求并且响应包含cookie,则Cookie管理器会自动存储该cookie,并将其用于将来对该特定用站的所有请求。每个JMeter线程都有自己的"cookie存储区"。因此,正在测试使用cookie存储会话信息的网站,则每个JMeter线程都将拥有自己的会话。此类Cookie不会显示在Cookie管理器显示屏上,可以使⽤"查看结果树监听器"查看。
缓存配置可选择standard(标准)或compatibility(兼容的),当然也可以手工添加⼀些cookie.
HTTP 请求默认值
作用:配置http信息,避免重复填写


用户自定义变量
作用:设置自定义变量
线程组->添加->配置元件->用户自定义变量

比如添加了一个studentId的变量

使用:在HTTP请求的取样器中引入定义的变量。${参数名}
例如: ${studentId}
CSV数据文件设置
作用:从外部CSV(逗号分隔值)文件中读取数据,并在测试过程中使用这些数据,使得数据的管理和更新更加方便
线程组->添加->配置元件->CSV Data Set Config


说明:
文件名:填写csv文件的路径。建议使用绝对路径。
• 文件编码:UTF-8
• 变量名称:从csv数据文件中读起的数据需要保存到的变量名。有多个变量时用逗号分隔(英文符号)
• 是否忽略首行:是否从csv数据⽂件第一行开始读取。
• 分隔符:要求与csv数据文件中多列的分隔符⼀致
• 遇到文件结束符再次循环:若选择为True当数据不够的时候会从头取。若选择False,则需要勾选
下⾯的配置,遇到⽂件结束符停⽌线程,这⾥如果不勾选,请求将会报错。
可以导入csv文件
配置如下:

创建csv文件步骤:
创建一个文本文件,并改名后缀为.csv,

然后用excel打开

输入信息:

完成后保存
然后在http请求里添加参数(需要使用 ${变量名} ):

然后修改线程组和线程数,使得每次取到的数据不一样,配置完成后进行测试每次测试的数据就会不一样

JSON提取器
作用:接口响应成功后,通过提取返回值对应字段,可用于其他接⼝的参数配置,可以针对某一个HTTP请求接口添加JSON提取器
添加->后置处理器,JSON提取器

JSON操作符参考:
$ 表⽰根元素
@ 当前元素
* 通配符。所有节点
.. 选择所有符合条件的节点
.<name> ⼦元素
['<name>' (, '<name>')] 括号表⽰⼦元素或⼦元素列表
[<number> (, <number>)] 数组索引或索引列表
[start:end] 数组切⽚操作符
[?(<expression>)] 过滤器表达式。表达式必须评估为布尔值。
比如 $…studentId 就是提取所有的studentId
$.[0]studentId 就是提取列表中第一个studentIdId

可以在查看结果树中查看json表达式


JSON断言
在JSON断言中填写相应变量和期望的值,若不相同,则会发生断言
添加->断言->JSON断言

在添加JSON断言的时候最好添加在HTTP请求的子节点上,否则会断言该作用域下所有的HTTP请求

同步定时器
作用:使得每个测试线程并发,从而模拟真实的多数量用户并发
线程组->添加->定时器-> Synchronizing Timer


官方说明


事务控制器
作用:可以对多个事务进行统一管理,使之成为一个事务集合体
线程组->添加->逻辑控制器->事务控制器

添加完成后,将需要管理的事务拖动到事务控制器内即可
Jmeter插件
下载链接
下载完成并放在对应路径下

然后打开jmeter,右上角就会出现插件管理的标志,点击就可以下载插件


下载监听器插件和线程组相关插件


梯度压测线程组
作用:梯度增加线程数并发测试
线程组->添加->线程->Stepping Thread Group


说明:
This group will start:启动多少个线程,同线程组中的线程数
First, wait for:等待多少秒才开始压测,般默认为0
Then start:⼀开始有多少个线程数,⼀般默认为0
Next,add:下⼀次增加多少个线程数
threads every:当前运⾏多⻓时间后再次启动线程,即每⼀次线程启动完成之后的的持续时间;
using ramp-up:启动线程的时间;若设置为5秒,表⽰每次启动线程都持续5秒
thenhold loadfor:线程全部启动完之后持续运⾏多⻓时间
finally,stop/threadsevery:多⻓时间释放多少个线程;若设置为5个和1秒,表⽰持续负载结 束之后每1秒钟释放5个线程
常见监听器

1.聚合报告
聚合报告可以看到性能测试过程中整体的数据变化
响应时间均为毫秒

2.Respons Times Over Time
作用:监听整个事务运行期间的响应时间。
3.Transactions per Second
作用:于分析每秒事务通过率,即系统吞吐量的重要工具.
TPS,即每秒事务数,表示一个客⼾机向服务器发送请求后服务器做出反应的过程。这个指标反映了系统在同一时间内处理业务的最大能力。TPS值越高,说明系统的处理能力越强。
性能测试报告
只能在命令行运行
Jmeter -n -t 脚本⽂件 -l ⽇志⽂件 -e -o ⽬录
说明:
-n : ⽆图形化运⾏
-t : 被运⾏的脚本
-l : 将运⾏信息写⼊⽇志⽂件,后缀为jtl的⽇志⽂件
-e : ⽣成测试报告
-o : 指定报告输出⽬录
注意:日志文件和目录可以不存在,若为已经存在的情况下需要保证内容为空,否则会出现错误!
例如:

相关文章:
软件测试学习笔记
测试学习 1. 测试流程2. Bug的提出什么是bugbug 的描述bug 级别 3. 测试用例的设计什么是测试用例测试用例应如何设计基于需求的设计方法等价类边界值场景法正交表法判定表法错误猜测法 4. 自动化测试回归测试自动化分类 5. 安装 webdriver-manager 和 selenium第一个web自动化…...
)
Centos 8系统ext4文件系统类型进行扩容缩容 (LVM)
Centos 8系统ext4文件系统类型进行扩容缩容 (LVM) 1.磁盘情况:2.缩容home分区1.备份home数据:2.查找使用 /home 的进程:3.终止这些进程:4.卸载 /home 分区5.检查文件系统一致性 (e2fsck):6.调整…...

常考常考高频率
1.快排(双指针) 快排,归并排序,堆排序 #快速排序O(nlogn) def quick_sort(array, left, right):if left < right:mid partition(array, left, right)quick_sort(array, left, mid)quick_sort(array, …...
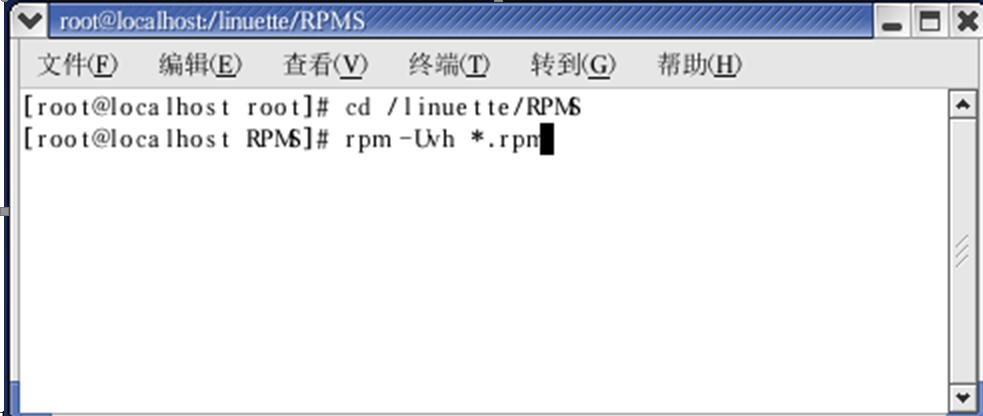
Linux项目环境的搭建 (Red hat 9.0Linux操作系统)
一、目的: 1.搭建Linux操作系统项目所需的项目环境构件; 2.了解 Linux的组成,学会编译内核。 二、内容: 安装Red hat 9.0Linux操作系统; 三、步骤: 3.1 正确安装Redhat9.0操作系统。 3.2 rpm -Uvh *.…...

Study--Oracle-08-ORACLE数据备份与恢复(一)
一、ORACLE数据保护方案 1、oracle数据保护方案 2、数据库物理保护方案 oracle数据库备份可以备份到本地集群存储,也可以备份到云存储。 3、数据库逻辑数据保护方案 二、ORACLE数据体系 1、ORACLE 数据库的存储结构 2、oracle物理和逻辑存储结构 3、数据库进程 4、数据库日…...

FreeIPA安装
一、环境准备 主机名IP角色master. bhlu. com192.168.22.10服务端node1. bhlu. com192.168.22.11客户端 两台服务器关闭防火墙和 selinux配置好 yum 源 1.1 配置 chronyd 配置好 chronyd,使用 chronyc source -v 可以验证 # 这里写了一个playbook作为示例了 --…...

mysql数据库:SQL语言基础和基本查询
mysql数据库:SQL语言基础和基本查询 SQL语言简介 Structured Query Language, 结构化查询语言非过程性语言为加强SQL的语言能力,各厂商增强了过程性语言的特征如:Oracle的PL/SQL 过程性处理能力,SQL Server、Sybase的T-SQLSQL是用…...
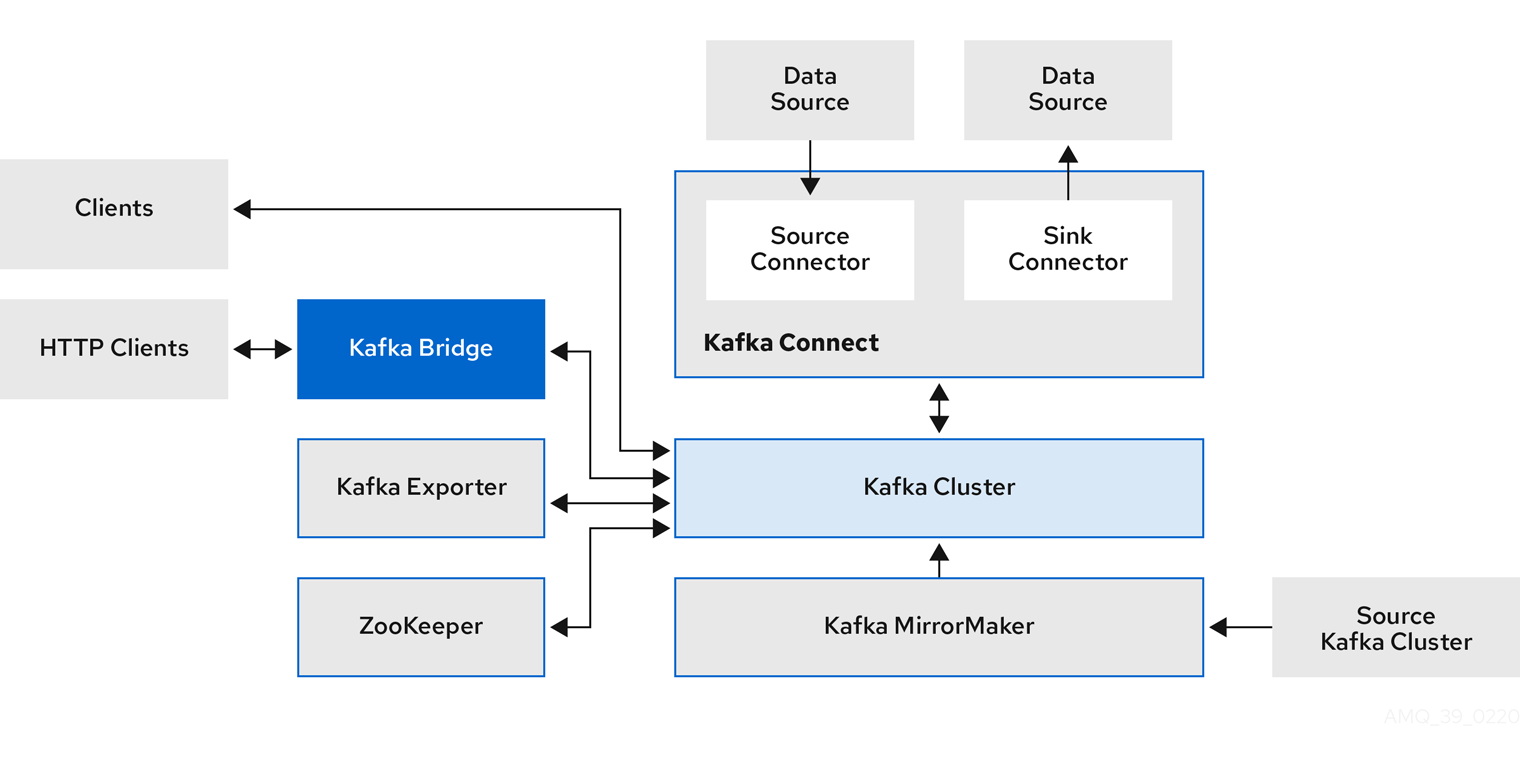
strimzi operator 部署kafka集群(可外部访问)
Strimzi介绍 官方文档:https://strimzi.io/docs/operators/0.42.0/overview#kafka-components_str Strimzi介绍 Strimzi 是一个用于 Apache Kafka 在 Kubernetes 上部署和管理的开源项目。它提供了一组 Kubernetes 自定义资源定义(Custom Resource Definitions,CRDs)、控制…...
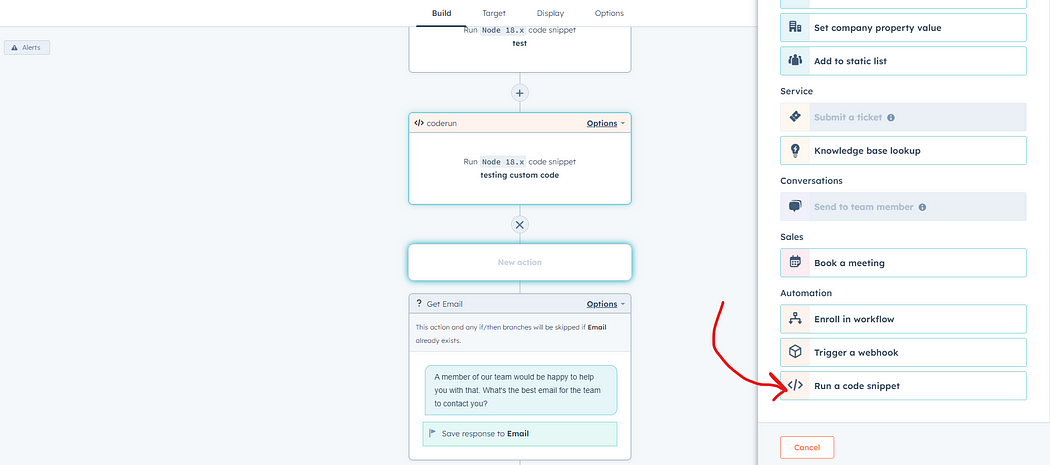
【网络安全】探索AI 聊天机器人工作流程实现RCE
未经许可,不得转载。 文章目录 前言正文前言 我发现了一个广泛使用的AI聊天机器人平台中的远程代码执行漏洞。该漏洞存在于聊天机器人的自定义工作流响应代码中,这些工作流允许开发人员通过创建定制的流程来扩展机器人的功能。 正文 在浏览自动化聊天机器人的多个特定功能…...

虚拟DOM、Vue渲染流程
虚拟DOM(Virtual DOM)是一种在前端开发中广泛使用的技术,它用JavaScript对象来表示真实DOM(文档对象模型)的结构和状态。虚拟DOM的核心思想是将页面的状态和结构保存在内存中,而不是直接操作真实的DOM。这一…...

centos7 启动python后端服务与停止服务的sh脚本
centos7 启动python后端服务与停止服务 分别在工程目录下新建启动脚本和停止脚本。 1、启动服务脚本 start_srv.sh: python3 start_srv.py运行 nohup ./start_srv.sh & 以守护进程的方式启动这个服务。 2、停止服务脚本 stop_srv.sh: sp_pidps -ef | grep start_srv…...
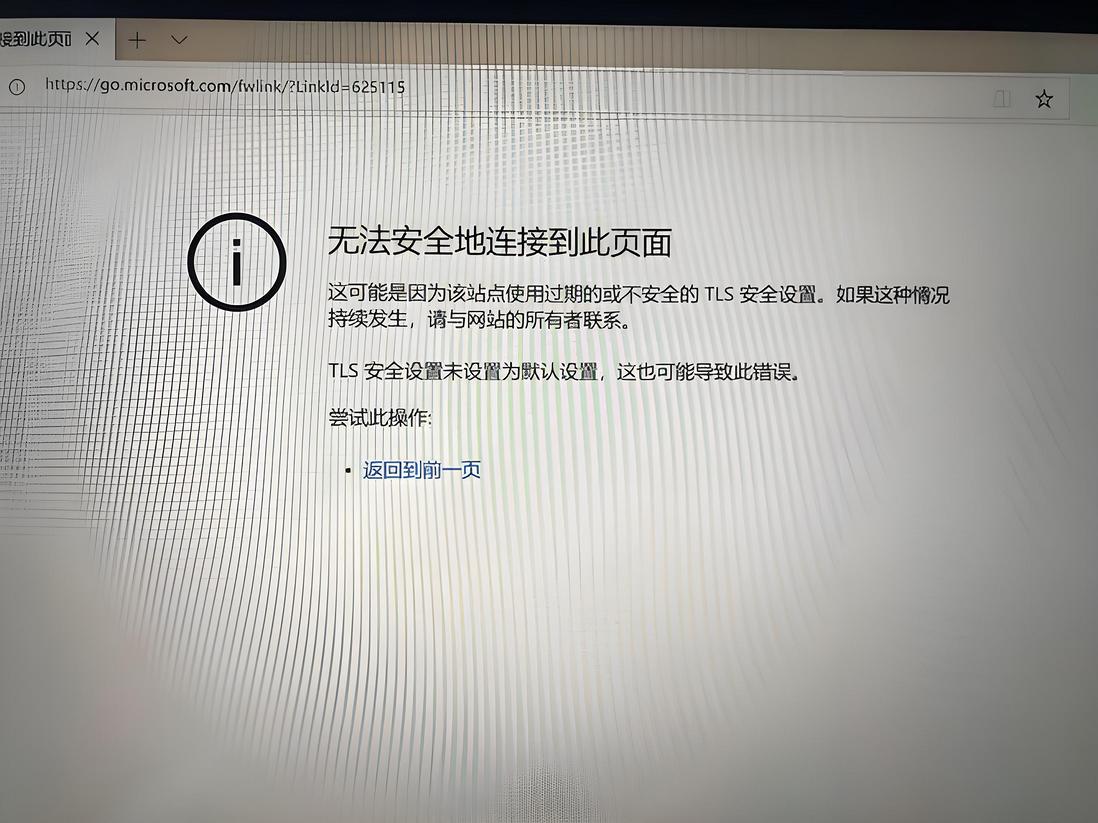
访问网站显示不安全怎么办?
访问网站时显示“不安全”,针对不同的原因有不同的解决方式,下面是常见的几种原因和对应的解决办法。 1.未启用HTTPS协议 如果网站仅使用HTTP协议,数据传输没加密,因此会被浏览器标记为“不安全”。解决办法是启用HTTPS协议,给…...

Scala与集合框架:高效数据处理的利器
Scala与集合框架:高效数据处理的利器 Scala 是一种现代化的编程语言,融合了面向对象编程和函数式编程的特性。其集合框架为处理数据提供了强大而灵活的工具,使得数据处理变得高效且富有表达力。本文将深入探讨 Scala 的集合框架,…...

基于 JWT 的模拟登录爬取实战
准备工作 1. 了解 JWT 相关知识 2. 安装 requests 库,并了解其基本使用 案例介绍 爬取网站: https://login3.scrape.center/ 用户名和密码是: admin 模拟登录 基于 JWT 的网站通常采用的是前后端分离式, 前后端的数据传输依…...
)
力扣(2024.08.06)
1. 144:二叉树的前序遍历 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, leftNone, rightNone): # self.val val # self.left left # self.right right class Solution:def preorderTravers…...

如何快速入门 PyTorch ?
PyTorch是一个机器学习框架,主要依靠深度神经网络,目前已迅速成为机器学习领域中最可靠的框架之一。 PyTorch 的大部分基础代码源于 Ronan Collobert 等人 在 2007 年发起的 Torch7 项目,该项目源于 Yann LeCun 和 Leon Bottou 首创的编程语…...

Qt 快速部署环境(windeployqt.exe)
windeployqt.exe 是 Qt 框架提供的一个工具,主要用于将 Qt 应用程序部署到 Windows 环境中。它自动将所需的所有库、插件和文件复制到应用程序的目录中,以便用户能够直接运行应用程序,而无需额外的配置。 主要功能 自动识别依赖项ÿ…...

白骑士的PyCharm教学实战项目篇 4.2 数据分析与可视化
系列目录 上一篇:白骑士的PyCharm教学实战项目篇 4.1 Web应用开发 数据分析和可视化是现代数据科学和工程中的重要环节。借助PyCharm的强大功能,数据分析与可视化的开发工作变得更加高效和便捷。本文将详细介绍如何在PyCharm中进行数据分析工具的集成与…...

el-form-item,label在上方显示,输入框在下方展示
本来是两排展示去写,设计要求一排展示,label再上方,输入框、勾选框在下方;只能调整样式去修改;参考label-position这个属性 代码如下: <el-form ref"form" :model"formData" clas…...

Centos7.9操作系统kdump crash文件vmcore未生成问题
Centos7.9操作系统kdump crash文件未生成问题 一、背景说明1、问题背景 二、排查思路1、先了解下crashkernelcrashkernel设置方式示例如何配置crashkernel验证crashkernel配置 2、再了解下kdump2.1 Kdump 的基本概念2.1.1. 生产内核(Production Kernel)2…...

从噪声整形到高精度:Delta-Sigma ADC核心原理深度剖析
1. Delta-Sigma ADC的独特魅力 第一次接触Delta-Sigma ADC时,我被它的"魔法"惊呆了——一个看似简单的1位核心,居然能输出24位甚至32位的高精度数据!这就像用一把刻度粗糙的尺子,通过特殊测量方法获得了比游标卡尺还精确…...

3步实现Figma全界面中文适配:面向设计团队的本地化解决方案
3步实现Figma全界面中文适配:面向设计团队的本地化解决方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 价值定位:打破语言壁垒的设计效率革命 设计工具的语…...

主流AI命理工具实测:八字紫微梅花六爻避坑指南
1. 当大模型遇上传统命理:AI算命实测背景 最近身边不少科技圈朋友都在讨论用AI工具辅助命理分析:做技术的研究起了八字排盘,产品经理案头放着命理相关资料,连程序员开会间隙都会聊两句卦象。作为长期关注AI应用的从业者࿰…...

novelWriter国际化支持:如何为多语言写作优化设置
novelWriter国际化支持:如何为多语言写作优化设置 【免费下载链接】novelWriter novelWriter is an open source plain text editor designed for writing novels. 项目地址: https://gitcode.com/gh_mirrors/no/novelWriter novelWriter是一款专为小说创作设…...

给CUDA新手的3DGS代码保姆级拆解:从forward.cu到backward.cu的完整学习路径
给CUDA新手的3DGS代码保姆级拆解:从forward.cu到backward.cu的完整学习路径 当你第一次打开3D Gaussian Splatting的代码仓库时,那些密密麻麻的CUDA核函数和复杂的线程同步操作可能让你望而生畏。但别担心,这篇文章将带你像拆解乐高积木一样&…...

抖音无水印视频下载工具:5分钟快速上手完整指南
抖音无水印视频下载工具:5分钟快速上手完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖…...

Science Bulletin-2026 | 首套中国40年城市土地利用数据集
数据介绍 Fig. 1. Study areas for time-series urban land use mapping in China. Spatial distribution of urban area density (defined as the ratio of built-up area to the total administrative area) across China and six representative subregions: (a) Xinjiang, …...

告别《空洞骑士》模组管理噩梦:Lumafly如何让300+模组配置化繁为简
告别《空洞骑士》模组管理噩梦:Lumafly如何让300模组配置化繁为简 【免费下载链接】Lumafly A cross platform mod manager for Hollow Knight written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/lu/Lumafly 《空洞骑士》作为一款备受欢迎的独…...

STP学习
STP生成树当二层交换机意外成环路的时候会发生:1.广播风暴:当广播帧进入环路时,会被不断复制并传输,导致网络中的广播流量急剧增加,消耗大量的网络带宽,降低网络性能,形成广播风暴。2.MAC地址表…...

Youtu-VL-4B-Instruct企业应用:电商商品图OCR识别+视觉问答构建智能客服中台
Youtu-VL-4B-Instruct企业应用:电商商品图OCR识别视觉问答构建智能客服中台 1. 引言:当客服遇到商品图,一场效率革命正在发生 想象一下这个场景:一位顾客在电商平台看中了一款商品,但他对商品详情页上的信息有疑问。…...