【数据分析---Pandas实战指南:精通数据查询、增删改操作与高效索引和列名操作管理】
前言:
💞💞大家好,我是书生♡,本阶段和大家一起分享和探索数据分析,本篇文章主要讲述了:数据查询操作,数据增删改操作,索引和列名操作等等。欢迎大家一起探索讨论!!!
💞💞代码是你的画笔,创新是你的画布,用它们绘出属于你的精彩世界,不断挑战,无限可能!
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
- 1. Pandas数据查询操作
- 1.1 基本查询方法
- 1.1.1 从前从后查询---head和tail
- 1.1.2 查询一/多列数据--- 对象名[列名]
- 1.1.3 布尔值向量查询多行数据
- 1.1.4 行下标切片查询多行数据---对象名[起始下标值:结束下标值:步长]
- 1.2 loc查询行列数据
- 1.3 iloc查询行列数据
- 1.4 loc和iloc的区别
- 1.5 query方法
- 1.6 where 方法
- 1.7 isin 方法获取子集
- 1.8 方法小结(重点)
- 2. Pandas数据增删改操作
- 2.1 增加列
- 2.1.1 末尾增加列
- 2.1.2 insert方法指定位置增加列数据
- 2.2 DataFrame删除行列
- 2.3 数据去重
- 2.3.1 drop_duplicates()
- 2.3.2 unique 去重
- 2.4 Series 和 DataFrame 修改数据
- 2.4.1 直接修改数据
- 2.4.2 replace 替换数据
- 2.4.3 apply调用自定义函数修改
- 2.4.4 applymap方法
- 2.5 小结(重点)
- 3. DataFrame获取索引和列名
- 3.1 获取索引和列名
- 3.1.1 获取DF对象的索引和列名
- 3.1.2 获取S对象的索引和列名
- 3.2 修改索引和列名
- 3.2.1 指定列作为索引
- 3.2.2 重置索引
- 3.2.3 赋值修改
- 3.2.4 rename方法修改索引和列名
- 3.3 小结(重点)
1. Pandas数据查询操作
1.1 基本查询方法
准备数据:从文件中读取数据,使用read_csv方法
# 导入模块
import pandas as pd
import numpy as np# 加载链家租房数据
df = pd.read_csv('data/LJdata.csv')
1.1.1 从前从后查询—head和tail
- 从前面查询使用-----》
head(n) - 从后面查询使用-----》
tail(n) - n是我们查询的行数,默认是5行
# 前3条数据
print(df.head(n=3))
# 后3条数据
df.tail(n=3)

1.1.2 查询一/多列数据— 对象名[列名]
- 获取一列数据
df[列名] / df.列名-> 列名不能有空格/不能和属性名重名
# 获取一列数据
print(df['id'].head(n=5))
print(df.name.head(n=5))

- 获取多列数据
获取多列数据 select 列名1, 列名2, … from 表名
df[[列名1, 列名2, ...]]
# 获取多列数据
df[['name', 'age']].head(n=3)

1.1.3 布尔值向量查询多行数据
- 通过布尔值向量获取多行数据
# 通过布尔值向量获取多行数据
df_head = df.head()
df_head

- 布尔值s对象获取多行数据
注意:
df[‘age’] == df[‘age’].max()
这个表达式返回一个Series,其中包含布尔值(True 或
False),表示DataFrame中每一行的’age’列是否等于’age’列的最大值。 返回类型:
返回的是一个布尔Series,长度与原始DataFrame相同,每个元素表示对应行的’age’值是否为最大。
df[df[‘age’]==df[‘age’].max()]
描述: 这个表达式使用前面得到的布尔Series作为索引来筛选DataFrame,只保留那些满足条件(即’age’等于最大值)的行。
返回类型: 返回的是一个新的DataFrame,只包含那些’age’列值等于最大值的行。
# 布尔值s对象获取多行数据
print(df['age'] == df['age'].max())
df[df['age']==df['age'].max()]

- 布尔值列表获取多行数据
# 布尔值列表的个数要和df数据的行数一致
# 布尔值列表获取多行数据
list1 = [True, False, True, False, False, False,True, False, True, False, False, False,True, False, True, False,False]
df[list1]

- 布尔值数组获取多行数据
# 布尔值数组获取多行数据
n1 = np.array([True, False, True, False, False, False,True, False, True, False, False, False,True, False, True, False,False])
df[n1]

1.1.4 行下标切片查询多行数据—对象名[起始下标值:结束下标值:步长]
通过行下标切片获取多行数据, 语法等同于python容器索引切片
行下标从上到下从0开始, 从下到上从-1开始
df[起始下标值:结束下标值:步长]
左闭右开原则-> 包含起始下标对应的行数据, 不包含结束下标对应的行数据
起始下标为0, 可以省略不写
结束下标不写, 获取最后一行数据
步长不写默认为1, 可以修改; 可以为负数, 倒序查询
数据准备
# 获取准备的数据
df_head = df.head(n=10)
df_head # 取前十条数据
# 查询前五条数据
temp_df = df_head[0:5]
temp1_df = df[:5] # 起始下标值为0可以不写
temp2_df = df[3:] # 结束下标不写, 获取最后一行数据
temp3_df = df[::] # 全部省略,获取全部数据
temp4_df = df[::-1] # 倒序查询全部数据
temp5_df = df[::2] # 步长为2,查看奇数列,即id为1、3、5、7、9
temp6_df = df[::-2] # 步长为-2,查看偶数列,即id为2、4、6、8、10
temp7_df = df[9:6:-1]
temp7_df

1.2 loc查询行列数据
行索引值/列名:肉眼看到的值, 可以是任意值, 可以重复
df.loc[行索引名, 列名]- 索引/列下标: 从0开始, 或从-1开始 ,是看不见的
- 索引名/列名: 肉眼看到的值, 可以是任意值, 可以有重复的值

- 通过行索引名
# 获取行数据
# df.loc[[行索引名1, 行索引名2, ...]]
# 获取一行数据
print(df.loc[0]) # 返回Series对象
print(df.loc[[0]]) # 返回df对象
df.loc[[0, 1, 2]] # 返回df对象

- 行索引值切片获取多行数据
df.loc[起始索引值:结束索引值:步长]—左闭右闭
# 行索引值切片获取多行数据
# df.loc[起始索引值:结束索引值:步长]
# 左闭右闭原则print(df.loc[0:5:1])
# df[0:5:1] # 取到第五行
print(df.loc[2::]) #
print(df.loc[2:8:2]) # 步长为2,查看奇数列,即索引2,4,6,8
print(df.loc[::-1]) # 倒序查询全部数据
print(df.loc[9:6:-1]) # 倒序返回 9-6 的数据

- 布尔值向量获取多行数据
df.loc[布尔值向量]
# 布尔值向量获取多行数据
# df.loc[布尔值向量]
df.loc[df['age']==df['age'].max(), ['name', 'age']]

- 布尔值向量取行配合列名取子集
布尔值向量取行配合列名取子集,一个列名可以不加【】,但是多个列名必须加【】
df.loc[布尔值向量, [列名1, 列名2, ....]]
# 布尔值向量取行配合列名取子集,一个列名可以不加【】,但是多个列名必须加【】
# df.loc[布尔值向量, [列名1, 列名2, ....]]
df.loc[df['age']>25, ['name', 'age']]

- 行索引名取行配合列名取子集
df.loc[[行索引名1, 行索引名2, ...], [列名1, 列名2, ...]]
# 行索引名取行配合列名取子集
# df.loc[[行索引名1, 行索引名2, ...], [列名1, 列名2, ...]]
df.loc[[0, 1, 2, 3, 4], ['id', 'name', 'age']]

- 行索引值切片配合列名取子集
df.loc[起始索引值:结束索引值:步长, [列名1, 列名2, ...]]
# 行索引值切片配合列名取子集,左闭右闭规则
# df.loc[起始索引值:结束索引值:步长, [列名1, 列名2, ...]]
df.loc[0:4:1, ['id', 'name', 'age']]

- 行索引值切片取行配合列名切片取子集,左闭右闭规则
df.loc[起始索引值:结束索引值:步长, 起始列名:结束列名:步长]
# 行索引值切片取行配合列名切片取子集
# df.loc[起始索引值:结束索引值:步长, 起始列名:结束列名:步长]
df.loc[0:4:1, 'id':'age':1]

1.3 iloc查询行列数据
iloc -> index location
df.iloc[行索引下标, 列名下标]
下标: 从0开始或从-1开始
- 获取行数据
df.iloc[行索引下标1,行索引下标2,...]
获取一行数据
# 获取行数据
# df.iloc[行索引下标1,行索引下标2,...]
# 获取一行数据
print(df.iloc[0]) # 返回Series对象
print(df.iloc[[0]]) # 返回df对象
 获取多行数据
获取多行数据
# 获取多行数据
print(df.iloc[[0,2,4,6,8]])
print(df.iloc[[-1,-2,-3,-4]])

- 行索引下标切片获取多行数据 下标值,是左闭右开
df[起始下标值:结束下标值:步长]
# 行下标切片获取多行数据
# df.iloc[起始下标值:结束下标值:步长]
# 等同于df[起始下标值:结束下标值:步长]
# 查询前五条数据
iloc0_df = df_head.iloc[0:5]
iloc1_df = df.iloc[:5] # 起始下标值为0可以不写
iloc2_df = df.iloc[3:] # 结束下标不写, 获取最后一行数据
iloc3_df = df.iloc[::] # 全部省略,获取全部数据
iloc4_df = df.iloc[::-1] # 倒序查询全部数据
iloc5_df = df.iloc[::2] # 步长为2,查看奇数列,即id为1、3、5、7、9
iloc6_df = df.iloc[::-2] # 步长为-2,查看偶数列,即id为2、4、6、8
iloc7_df = df.iloc[9:6:-1]
iloc7_df

- 行列下标切片获取子集
df.iloc[行下标切片, 列下标切片]
# 行列下标切片获取子集
# df.iloc[行下标切片, 列下标切片]
df.iloc[::2, ::2]
- 行下标切片配合列下标获取子集
一个列下标可以不加【】,但是多个列下标必须加【】
df.iloc[行下标切片, [列下标, 列下标, ....]]
# 行下标切片取行配合列下标取子集,一个列下标可以不加【】,但是多个列下标必须加【】
# df.iloc[行下标切片, [列下标, 列下标, ....]]
iloc0_df = df.iloc[0:7:2,[0,1,2]]
iloc0_df

- 行下标配合列下标获取子集
df.iloc[[行下标, 行下标, ....], [列下标, 列下标, ....]]
# 行下标取行配合列下标取子集
# df.iloc[[行下标, 行下标, ....], [列下标, 列下标, ....]]
iloc0_df = df.iloc[[0,2,4,6,8], [0,1,2]]
iloc0_df

- 行下标配合列下标切片获取子集
df.iloc[起始下标值:结束下标值:步长, 起始列下标:结束列下标:步长]
# 行下标切片配合列下标切片取子集
# df.iloc[起始下标值:结束下标值:步长, 起始列下标:结束列下标:步长]
iloc_df = df.iloc[0:4:1, 0:3:1]
iloc_df

1.4 loc和iloc的区别
- loc(location)是通过行索引值或列名获取数据,
- iloc(index location)是通过行下标或列下标获取数据
- 索引值: 肉眼看到的值, 可以是任意值, 可以重复
- 下标: 从0开始或从-1开始,看不见的值
- 一般建议使用loc获取行列数据(调整行列顺序, 不会影响查询结果)
1.5 query方法
准备数据:
df = pd.read_csv('data/LJdata.csv').head(10)
df

表达式:
df.query(expr)
注意:
- 列名不需要加引号, 数据值为字符串类型需要加引用
单个条件查询
# df.query(expr)
# 通过expr表达式(字符串类型)获取条件为True的数据
print(df.query('面积>80'))
# 列名不需要加引号, 数据值为字符串类型需要加引用
print(df.query('朝向=="南"'))

多个条件查询
query方法还可以使用in关键字,可以使用&或and |或or
# query方法还可以使用in关键字,可以使用&或and |或or,
df.query('区域 in ["望京租房","天通苑租房","回龙观租房"] and 朝向 in ["东" ,"南"]')

1.6 where 方法
where() 方法 保留满足条件的数据,不满足条件的数据用nan填充
我们也可以做指定 other参数来填充nan ,也可以使用dropna方法删除不满足条件的
# where() 方法 保留满足条件的数据,不满足条件的数据用nan填充
# 我们也可以做指定 other参数来填充nan ,也可以使用dropna方法删除不满足条件的
print(df.where(df['朝向'] == "南"))
df.where(df['朝向']=="南",other=" ") # 不满足条件的填充为空格

不满足的直接删除,使用dropna方法
df.where(df['朝向']=="南").dropna()

1.7 isin 方法获取子集
df/s.isin(values=[])
判断df或s对象的值是否在values列表中, 返回True或Fasle
使用场景: 判断df中某列(s对象)的值是否在values列表中
# df/s.isin(values=[])
# 判断df或s对象的值是否在values列表中, 返回True或Fasle
print(df.isin(values=['2室1厅', '南']))
# 使用场景: 判断df中某列(s对象)的值是否在values列表中
df[df['户型'].isin(values=['2室1厅']) & df['朝向'].isin(values=['南'])]

1.8 方法小结(重点)
| 方法说明 | 子集操作方法 |
|---|---|
| 获取前n行数据,默认5行 | df.head(n) |
| 获取最后n行数据,默认5行 | df.tail(n) |
| 获取一列数据 | df[列名] 或 df.列名 |
| 获取多列数据 | df[[列名1,列名2,...]] |
| df[[True, False, …]]取出对应为True的数据行 | df[[布尔值向量]] |
| 行下标(索引下标)切片获取数据行 | df[起始行下标:结束行下标:步长] |
| 索引值(行名)获取1行数据 | df.loc[行索引值] |
| 索引值(行名)获取多行数据 | df.loc[[行索引值1, 行索引值2, ...]] |
| 索引值(行名)切片获取多行数据,注意与df[起始行下标:结束行下标:步长]不同 | df.loc[起始行索引值:结束行索引值:步长] |
| 布尔值向量获取行数据,等同于df[[布尔值向量]] | df.loc[[布尔值向量]] |
| 布尔值向量取行再配合列名取子集 | df.loc[布尔值向量,[列名1, 列名2, ...]] |
| 索引值取行再配合列名取子集 | df.loc[[行索引值1, 行索引值2, ...], [列名1, 列名2, ...]] |
| 列名取子集 | df.loc[行索引值起始值:行索引值结束值:步长, [列名1, 列名2, ...]] |
| 行下标取1行 | df.iloc[行下标] |
| 行下标取多行 | df.iloc[[行下标1, 行下标2, ...]] |
| 行下标切片取多行 | df.iloc[起始行下标:结束行下标:步长] |
| 行列下标切片取子集 | df.iloc[起始行下标:结束行下标:步长,起始列下标:结束列下标:步长] |
| 行下标切片和列下标取子集 | df.iloc[起始行下标:结束行下标:步长,[列下标1, 列下标2, ...]] |
| 行下标和列下标取子集 | df.iloc[[行下标1, 行下标2, ...], [列下标1, 列下标2, ...]] |
| 行下标和列下标切片取子集 | df.iloc[[行下标1, 行下标2, ...], 起始列下标:结束列下标:步长] |
| 依据判断表达式返回符合条件的df子集 | df.query('判断表达式字符串') 与 df[[布尔值向量]]效果相同 |
| 判断是否存在某个值 | df.isin([值1, 值2, ...]) |

2. Pandas数据增删改操作
数据准备:
# 加载数据
df = pd.read_csv('data/LJdata.csv').head(10)
df

2.1 增加列
2.1.1 末尾增加列
df[列名]= 常数/s对象/list对象/数组对象
数值个数必须与df行数一致
## 末尾增加一列数据
#df[列名]= 常数/s对象/list对象/数组对象
# 注意点:数值个数必须与df行数一致
temp_df = df.head(5).copy()
temp_df
- 常数
df[列名]= 常数
# 常数
temp_df['省份'] = '北京'
temp_df

- s 对象
df[列名]= s对象
# s 对象
print(temp_df['价格']+500)
temp_df['新价格'] = temp_df['价格']+500
temp_df

- list 对象
df[列名]=list对象
# list 对象
# 添加区县列,# 增加区县列, 列值 ['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区']
# 数据值个数要和df行数据一致
temp_df['区县'] = ['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区']
temp_df

2.1.2 insert方法指定位置增加列数据
df指定位置添加列数据
df.insert(loc=, column=, value=)
loc: 列下标值, 只能使用正数 0,1,2,…
column: 列名
value: 列值, 常数/s对象/list对象/数组对象\
为了避免对原始数据进行修改,先将数据复制一份
new_df = df.head(5).copy()
new_df
- 常数
# 在区域前面加上一列常数数据, 列名为省份,值为北京
new_df.insert(loc=0,column='省份',value='北京')
new_df

- S对象
#%%
# 添加一个s对象,添加一个新的价格 ,值为价格+500
new_df.insert(loc=6,column='新价格',value=df['价格']+500)
new_df

- list列表
# list 对象
# 添加区县列,# 增加区县列, 列值 ['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区']
# 数据值个数要和df行数据一致
new_df.insert(loc=1,column="区县",value=['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区'])
new_df

2.2 DataFrame删除行列
df.drop(labels=, axis=, inplace=)
labels: 根据行索引值或列名删除, 可以删除多行多列 -> 列表
axis: 0或index -> 删除行数据, 默认 1或columns -> 删除列数据
inplace: True->原df上删除 False->不在原df上删除, 默认False
- 删除一行数据
根据labels的行索引值
# 删除一行数据
drop_df = temp_df.drop(0)
drop_df

- 删除多行数据
行索引值 使用【】包起来,axis为0,表示删除行
# 删除多行数据
drop1_df = temp_df.drop([0,1],axis=0)
drop1_df

- 删除一列数据
指定被删除的列索引值(列名),axis为1 ,表示删除列
# 删除一列数据
drop2_df = temp_df.drop(labels='价格',axis=1)
drop2_df

- 删除多列信息
行索引值(列名) 使用【】包起来,axis为1 ,表示删除列
# 删除多列信息
drop4_df= temp_df.drop(labels=['省份','新价格'],axis=1)
drop4_df
- 删除在原始数据删除数据
指定 inplace=True 就可以删除原始数据,默认为False不删除
#%%
# 删除在原始数据删除数据
temp_df.drop(labels=['地址'],axis=1,inplace=True)
temp_df
2.3 数据去重
2.3.1 drop_duplicates()
df/s.drop_duplicates(subset=, keep=, inplace=)
subset: 列名列表, 根据指定的列进行去重(distinct 列名1, 列名2); 不写的话需要根据所有列进行去重(distinct *)
keep: 保留哪条重复的行数据 first:第一条(默认) last:最后一条 False:全部删除
inplace: 是否在原数据上删除
- 全部去重,直接使用drop_duplicates(),不指定任何参数
# 全部数据去重
temp_df.drop_duplicates()

- 根据指定列去重,默认保留第一条
# 根据指定列去重,默认保留第一条
temp_df.drop_duplicates(subset=['户型'])

- 根据指定列去重,保留最后一条
keep的参数可以指定first和last first为第一条数据,last为最后一条数据
# 根据指定多列去重,保留最后一条
temp_df.drop_duplicates(subset=['户型','朝向'],keep='last')

- 删除重复数据 ,keep 的参数设置为False
# 删除重复数据
temp_df.drop_duplicates(subset=['户型','朝向'],keep=False)

- 在原数据进行去重删除
将inplace=True ,默认为false不删除
# 在原数据进行去重删除
(new_df.drop_duplicates(subset=['户型','朝向'],keep='first',inplace=True))
new_df

2.3.2 unique 去重
准备数据:测试使用只取一列数据
s1 = temp_df.head().copy()['朝向']
print(s1)

使用drop_duplicates() 但回的是列数据

unique() 返回的是一个数组
在这里插入代码片
s1.unique() # 返回的是一个数组
s1.nunique() # 返回唯一值的个数,去重计数

2.4 Series 和 DataFrame 修改数据
2.4.1 直接修改数据
直接修改数据
df[列名] = 新值 s[下标] = 新值
新值: 常数/s对象/list对象/数组对象
- 常数
df[列名] = 常数
# 常数
temp_df['户型']='3室2厅'
temp_df

- s对象
# s对象
# 将面积增加10,在保存在面积列中
temp_df['面积']=temp_df['面积']+10
temp_df

- list对象
直接将一列数据改为列表中的数据,注意个数要一致
# list对象
temp_df['朝向']=['东','南','西','北','南']
temp_df

- 数组对象
直接将一列数据改为数组中的数据,注意个数要一致
# 数组对象
temp_df['价格']=np.arange(0,5)
temp_df

2.4.2 replace 替换数据
replace方法替换数据
df.replace(to_replace=, value=, inplace=)
to_replace: 旧值
value: 新值
inplace: 是否在原数据上修改

- 替换一个值
df.replace(to_replace=, value=)
# 替换一个值
temp_df.replace(to_replace=['3室2厅'],value='3室1厅')

- 替换多个值
必须用【】括起来
# 替换多个值
temp_df.replace(to_replace=['东','南'],value='中')

- 使用字典替换,哪一列的哪些值
df.replace(to_replace={'列名': 值, '列名': 值}, value=新值)
print(temp_df.replace(to_replace={'价格': 0, '面积': 60}, value=8888))
temp_df.replace(to_replace={'价格': {0: 888, 1: 999, 2: 777, 3: 666, 4: 555}})

2.4.3 apply调用自定义函数修改
s对象或df对象如何执行自定函数? -> 借助apply方法
s/df.apply(func=,axis=,args=)
func: 自定义函数名
axis: df中按行(1)或按列(0,默认的)执行
args: 自定义函数带其他有参数时, 需要通args传参
- s对象的apply方法
s对象的apply方法
自定义函数中的第一个参数值是s对象的每一个值
自定义函数返回值为一个值
apply_df = df.head(10).copy()
apply_df
def func1(x):if x=='天通苑租房':return '好地方'else:return '不好地方'
apply_df['区域']=apply_df['区域'].apply(func=func1)
apply_df

如果自定义函数中有其他的参数, 需要通过args=()传递参数值
# 定义函数
def func2(x, arg1, arg2):if x == "不好地方":return arg1elif x == "好地方":return arg2else:return x# 如果自定义函数中有其他的参数, 需要通过args=()传递参数值
apply_df['区域'].apply(func=func2, args=('昌平租房', '朝阳租房'))
# 如果自定义函数中有其他的参数, 可以通过 参数名=参数值 形式传递参数值
apply_df['区域'].apply(func=func2, arg1='昌平11租房', arg2='朝阳11租房')

- df对象的apply方法
#df对象的apply方法
#自定义函数中的第一个参数值是s对象(df中的一行或一列)
#自定义函数返回值是s对象
s._name是判断是否有列名等于值,有的话就进行判断。
默认是按列执行 args=(‘新值’,) 【逗号不能省略】
df_apply_df = df.head().copy()
df_apply_df
def func4(s, arg1):# print(f"s的值是:{s}")# print(f"s的类型是:{type(s)}")# print(s.__dict__)# print(s._name) # 查看s对象的name属性值if s._name == "区域":# s.replace(to_replace=['燕莎租房'], value=arg1)return s.replace(to_replace=['燕莎租房'], value=arg1)return s
# 默认是按列执行 ,axis=0 ,(可以不写)
df_apply_df.apply(func=func4,args=('朝阳租房',))
按行执行----》axis=1
如果区域这一列中,某一行的值等于设的值,那么就将参数的值赋值给这一行的数据
# 按行执行 axis=1
def func5(s, arg1):# print(f"s的值是:{s}")# print(f"s的类型是:{type(s)}")# print(s['区域'])if s['区域'] == '天通苑租房':s['区域'] = arg1return sreturn s# 按行执行 axis=1
temp_df.apply(func=func5, axis=1, args=('昌平租房',))
# 使用自定义函数处理df中某列数据时, df[列名].apply(func=自定义函数名)
# 使用自定义函数处理df中每行数据时, df.apply(func=自定义函数名, axis=1)

- 使用自定义函数处理df中某列数据时, df[列名].apply(func=自定义函数名)
- 使用自定义函数处理df中每行数据时,df.apply(func=自定义函数名, axis=1)
2.4.4 applymap方法
df对象的applymap方法是将df对象中的每一个值,都进行筛选判断,符合就修改,不需要指定列或者行
# df对象的applymap方法
# df.applymap(func=)
# 将df对象中的每个值放到自定义函数中执行
def func7(x):# print(f"x的值是:{x}")if x == "2室1厅":return '3室1厅'return xdf_apply_df.applymap(func=func7)

2.5 小结(重点)
df['列名'] = 标量或向量修改或添加列df.insert(列下标数字, 列名, 该列所有值)指定位置添加列<df/s>.drop([索引值1, 索引值2, ...])根据索引删除行数据df.drop([列名1, 列名2, ...], axis=1)根据列名删除列数据<df/s>.drop_duplicates()df或s对象去除重复的行数据s.unique()s对象去除重复的数据<df/s>.replace('原数据', '新数据', inplace=True)替换数据- df或series对象替换数据,返回的还是原来相同类型的对象,不会对原来的df造成修改
- 如果加上inplace=True参数,则会修改原始df
apply函数s.apply(自定义函数名, arg1=xx, ...)对s对象中的每一个值,都执行自定义函数,且该自定义函数除了固定接收每一个值作为第一参数以外,还可以接收其他自定义参数df.apply(自定义函数名, arg1=xx, ...)对df对象中的每一列,都执行自定义函数,且该自定义函数除了固定接收列对象作为第一参数以外,还可以接收其他自定义参数df.apply(自定义函数名, arg1=xx, ..., axis=1)对df对象中的每一行,都执行自定义函数,且该自定义函数除了固定接收行对象作为第一参数以外,还可以接收其他自定义参数applymap函数df.applymap(自定义函数名)对df对象中的每个值, 都执行自定义函数, 且该自定义函数只能接收每个值作为参数, 不能接收其他自定义参数
3. DataFrame获取索引和列名
加载数据:
import pandas as pd
# 加载数据集合
df = pd.read_csv('data/LJdata.csv')
print(df.head())
# 获取天通院租房的数据
test_df = df[df['区域']=='天通苑租房']
print(test_df.head())
# 获取上面的价格列
price_df = test_df['价格']
price_df.head()


3.1 获取索引和列名
3.1.1 获取DF对象的索引和列名
获取索引:index【下标】
获取列名:columns【下标】或者 keys()
- 获取索引
# 获取索引
print(test_df.index)
# 获取某一个索引,类似于列表
print(test_df.index[0])
print(test_df.index[-1])

- 获取列名
# 获取列名,返回一个列表
print(test_df.columns)
# 获取某一个列名
print(test_df.columns[0])
# 获取列名,返回一个列表
print(test_df.keys())

3.1.2 获取S对象的索引和列名
Series只有索引值没有列名
获取索引:index【下标】
# 获取series的索引
print(price_df.index)
# 获取某一个索引,类似于列表
print(price_df.index[-1])
# 获取列名,返回一个列表
print(price_df.keys())

3.2 修改索引和列名
3.2.1 指定列作为索引
df.set_index(keys=[列名1, 列名2, ...], drop=, inplace=)
keys:指定某列/某些列作为df索引
drop:是否删除指定列, 默认True
inplace:是否修改原数据, 默认False
- 指定一列作为索引
print(test_df.set_index(keys=['区域'], drop=True, inplace=False).head(3))
test_df.set_index(keys=['区域'], drop=False, inplace=False).head(3)

- 指定多列作为索引
# 指定多列作为索引
test_df.set_index(keys=['区域', '地址']).head(3)

test_df.set_index(keys=['区域', '地址']).index

- 加载数据的时候指定索引
读取数据的时候,加上一个参数
index_col=[‘列名’ / 列下标]
# 加载数据的时候指定索引
print(pd.read_csv('data/LJdata.csv', index_col=["区域"]).head(5))
pd.read_csv('data/LJdata.csv', index_col=[0,1]).head(5)

3.2.2 重置索引
重置索引:
df/s.reset_index(drop=, inplace=)
drop: 是否删除原索引, 默认False
inplace: 是否修改原数据, 默认False
- DF对象重置索引
设置索引:
test_df= test_df.head(5)
test_df.set_index(keys=['区域'],inplace=True)

重置索引
# 重置
test_df.reset_index()

查看索引
test_df.reset_index()

删除原始索引
test_df.reset_index(drop=True)

- S对象重置索引
重置索引
price_df.reset_index()

S对象重置索引后删除原索引
print(type(price_df.reset_index(drop=True)))
price_df.reset_index(drop=True)

3.2.3 赋值修改
赋值修改索引和列名
df.index = 新值 df.columns = 新值
修改df中所有的索引和列名
# # 新值个数要和行数据一致
temp_df.index = ['a', 'b', 'c', 'd', 'e']
temp_df
temp_df.columns = ['区域11', '地址11']
temp_df

3.2.4 rename方法修改索引和列名
df.rename(index={}, columns={}, inplace=)
{原值:新值}
可以修改指定的索引和列名
查看数据
temp_df

temp_df.rename(index={'a':'A'}, columns={'区域11':'区域'})

3.3 小结(重点)
查看或修改索引
<s/df>.index查看或修改列名
df.columns=[col_name1, col_name2, ...]读取数据时指定某列为索引
pd.read_csv('csv_path', index_col=[列名])设置某列为df的索引
df.set_index(列名)重置df的索引为默认自增索引
df.reset_index(drop=)指定修改部分索引值或列名
'原索引名1': '新索引名1','原索引名2': '新索引名2',...},columns={'原列名a': '新列名a','原列名b': '新列名b',...} ) ```
相关文章:
【数据分析---Pandas实战指南:精通数据查询、增删改操作与高效索引和列名操作管理】
前言: 💞💞大家好,我是书生♡,本阶段和大家一起分享和探索数据分析,本篇文章主要讲述了:数据查询操作,数据增删改操作,索引和列名操作等等。欢迎大家一起探索讨论&#x…...

Spring Cloud全解析:注册中心之Eureka服务获取和服务续约
服务获取和服务续约 eureka客户端通过定时任务的方式进行服务获取和服务续约,在com.netflix.discovery.DiscoveryClient类中,启动了两个定时任务来进行处理 private void initScheduledTasks() {// 是否需要拉取if (clientConfig.shouldFetchRegistry(…...

三相整流电路交流侧谐波仿真分析及计算
一、三相桥式全控整流电路和功率因数测量电路SIMULINK 模型 如图4-1,根据高频焊机的主电路机构和工作原理,可将高频焊机三相整流部分等效为阻感负载的三相桥式全控整流电路模型,其由三相交流电压源、三相晶闸管整流桥、同步六脉冲触发器和阻感…...

了解Java中的反射,带你如何使用反射
反射的定义 反射(Reflection)是Java的一种强大机制,它允许程序在运行时动态地查询和操作类的属性和方法。通过反射,Java程序可以获取类的信息,比如类的名称、方法、字段,以及可以动态地创建对象、调用方法…...

【c++】基础知识——快速入门c++
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:C 目录 前言 一、手搓一个Hello World 二、命名空间namespace 1.命名空间的定义 2.命名空间的使用 3.命名空间补充知识 三、c中的输入和输出 四、缺省参…...

AI学习记录 - 自注意力机制的计算流程图
过段时间解释一下,为啥这样子计算,研究这个自注意力花了不少时间,网上很多讲概念,但是没有具体的流程图和计算方式总结…...
JavaScript快速入门,满满干货总结,快速掌握JS语法,DOM,BOM,事件
目录 一. JavaScript、HTML、CSS简介 1.1 HTML简介和举例说明 1.2 CSS简介和举例说明 1.3 JavaScript 简介和举例说明 二. JavaScript 基本语法 2.1 变量类型和定义方式 2.2 逻辑运算符,比较运算符 2.3 流程控制,if,if...else...&…...

【C++】C++入门基础【类与对象】
目录 1.类 1.1类的定义 1.2struct 与 class对比 2.访问限定符 3. 类域 4.实例化 5.存储大小----内存对齐 6.this指针 1.类 1.1类的定义 class作为类的关键字,后面跟的是类的名字,如Stack,{}中的为类的主体,类定义结束时…...

Qt | QScatterSeries 散点图
点击上方"蓝字"关注我们 01、QScatterSeries QScatterSeries 的类,它将代表散点图中的一个系列。这个类将包含数据点、颜色和样式等属性,以及用于绘制散点图的方法。 02、main.cpp #include <QtWidgets/QApplication>#include <QtWidgets/QMainWindow…...

无缝协作的艺术:Codigger 视频会议(Meeting)的用户体验
在当今数字化的时代,远程协作已经成为工作和学习中不可或缺的一部分。然而,远程协作也面临着诸多挑战,如沟通不畅、信息同步不及时、协作工具的复杂性等。而 Codigger 视频会议(Meeting)作为一款创新的工具,…...

C基础练习(学生管理系统)
1.系统运行,打开如下界面。列出系统帮助菜单(即命令菜单),提示输入命令 2.开始时还没有录入成绩,所以输入命令 L 也无法列出成绩。应提示“成绩表为空!请先使用命令 T 录入学生成绩。” 同理,当…...

网络安全抓包封包WEB
目录 1.抓包 1. 网络故障排除 应用 意义 2. 网络安全监控 应用 意义 3. 性能优化 应用 意义 4. 协议分析与开发 应用 意义 5. 数据分析与合规性审计 应用 意义 抓包工具 总结 2.抓包的应用对象 1. 网络设备 路由器和交换机 防火墙和入侵检测系统ÿ…...

Spring Boot - 在Spring Boot中实现灵活的API版本控制(上)
文章目录 为什么需要多版本管理?在Spring Boot中实现多版本API的常用方法1. URL路径中包含版本号2. 请求头中包含版本号3. 自定义注解和拦截器 注意事项 为什么需要多版本管理? API接口的多版本管理在我们日常的开发中很重要,特别是当API需要…...

普中51单片机:DS18B20温度传感器操作指南(十三)
文章目录 引言电路图引脚讲解初始化时序写时序读时序温度变换温度读取完整代码 引言 DS18B20是一款单总线接口的数字温度传感器,仅需一个IO口即可实现数据通信。这里只对如何简单操作开发板的DS1802进行讲解,关于DS18B20温度传感器的详细操作原理&#…...

【网络】网络的发展历程及其相关概念
1.什么是网络 计算机网络是指将一群具有独立功能的计算机通过通信设备以及传输媒体被互联起来的,在通信软件的支持下,实现计算机间资源共享、信息交换或协同工作的系统。计算机网络是计算机技术与通信技术紧密结合的产物,两者的迅速发展渗透形…...

鸿蒙HarmonyOS开发:如何使用第三方库,加速应用开发
文章目录 一、如何安装 ohpm-cli二、如何安装三方库1、在 oh-package.json5 文件中声明三方库,以 ohos/crypto-js 为例:2、安装指定名称 pacakge_name 的三方库,执行以下命令,将自动在当前目录下的 oh-package.json5 文件中自动添…...

C++的标准模板库简单介绍
C的标准模板库(STL, Standard Template Library)是一个强大的工具,旨在提供高效和灵活的数据结构和算法。STL的设计目的是使C程序更加通用和可重用。以下是对STL的详细介绍: 1. STL的组成部分 STL主要由以下几部分组成ÿ…...
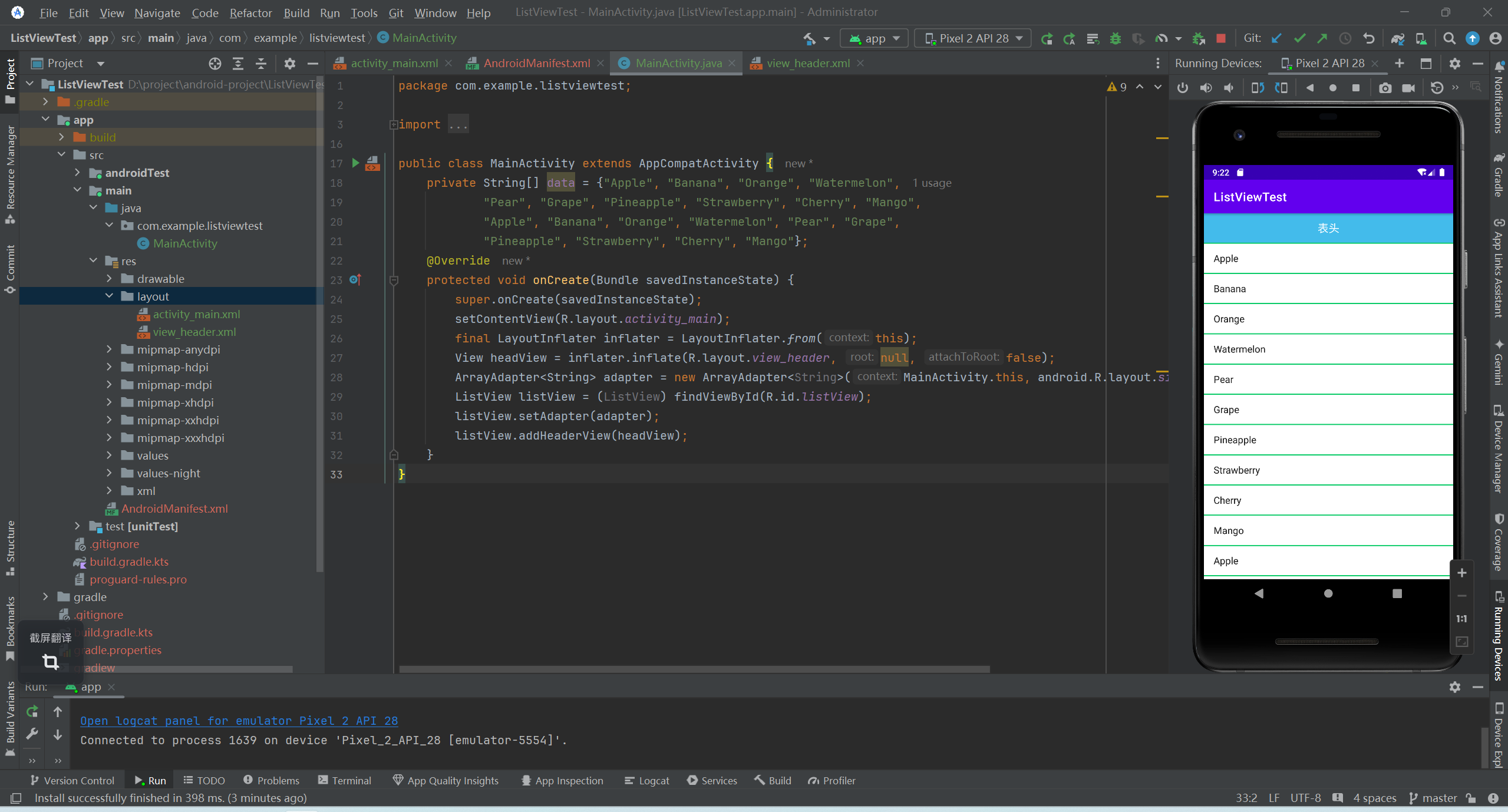
安卓常用控件ListView
文章目录 ListView的常用属性ListView的常用APIListView的简单使用 ListView是一个列表样式的 ViewGroup,将若干 item 按行排列。它是一个很基本的控件也是 Android 中最重要的控件之一。它可以实现多个 View 的垂直排列并支持滚动显示效果。 ListView的常用属性 常…...

优秀的行为验证码的应用场景与行业案例
应用场景 登录注册 : 验证码适用于App、Web及小程序等用户注册场景,可以抵御自动机恶意注册,垃圾注册、抵御撞库登录、暴力破解、验证账号敏感信息的修改,同时可以有效阻止撞库攻击,从源头进行防护,保障正…...
《程序猿入职必会(10) · SpringBoot3 整合 MyBatis-Plus》
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗 🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数…...

CPUDoc性能优化工具:释放CPU潜能的智能管家
CPUDoc性能优化工具:释放CPU潜能的智能管家 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 在数字时代,无论是游戏玩家追求极致帧率,还是专业创作者需要稳定的多任务处理能力,CPU性能都是决…...

彻底告别风扇噪音:用FanControl 264版实现电脑静音控制的终极指南
彻底告别风扇噪音:用FanControl 264版实现电脑静音控制的终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_…...

VRM Addon for Blender全流程指南:从安装到高级角色创作
VRM Addon for Blender全流程指南:从安装到高级角色创作 【免费下载链接】VRM-Addon-for-Blender VRM Importer, Exporter and Utilities for Blender 2.93 to 5.0 项目地址: https://gitcode.com/gh_mirrors/vr/VRM-Addon-for-Blender VRM Addon for Blende…...

解锁Noria查询重用机制:如何智能复用数据流组件实现应用性能飞跃
解锁Noria查询重用机制:如何智能复用数据流组件实现应用性能飞跃 【免费下载链接】noria Fast web applications through dynamic, partially-stateful dataflow 项目地址: https://gitcode.com/gh_mirrors/no/noria 在现代Web应用开发中,性能优化…...

一键部署GLM-4.6V-Flash-WEB:GitCode镜像真香,省去半天环境搭建时间
一键部署GLM-4.6V-Flash-WEB:GitCode镜像真香,省去半天环境搭建时间 1. 为什么选择GLM-4.6V-Flash-WEB 在多模态大模型快速发展的今天,开发者最头疼的不是模型性能,而是如何快速部署和运行。GLM-4.6V-Flash-WEB作为智谱AI最新开…...

扩展你的 RAG:基于 Rust 的 LanceDB 和 Candle 索引管道
原文:towardsdatascience.com/scale-up-your-rag-a-rust-powered-indexing-pipeline-with-lancedb-and-candle-cc681c6162e8?sourcecollection_archive---------2-----------------------#2024-07-11 构建大规模文档处理的高性能嵌入和索引系统 https://medium.co…...

Qwen2.5-14B-Instruct深度适配|像素剧本圣殿8-Bit UI渲染原理揭秘
Qwen2.5-14B-Instruct深度适配|像素剧本圣殿8-Bit UI渲染原理揭秘 1. 项目概述 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct大模型深度微调的专业剧本创作工具。它将先进的AI推理能力与复古8-Bit视觉美学相结合&…...

手把手教你部署MiniCPM-V-2_6:最强视觉多模态模型,小白也能快速体验
手把手教你部署MiniCPM-V-2_6:最强视觉多模态模型,小白也能快速体验 1. 认识MiniCPM-V-2_6:视觉多模态新标杆 MiniCPM-V-2_6是目前最先进的视觉多模态模型之一,它基于SigLip-400M和Qwen2-7B构建,总参数量达到80亿。这…...

SecGPT-14B模型微调:OpenClaw自动化准备标注数据与训练脚本
SecGPT-14B模型微调:OpenClaw自动化准备标注数据与训练脚本 1. 为什么需要自动化微调流程 当我第一次尝试微调SecGPT-14B模型时,最让我头疼的不是模型本身,而是那些繁琐的前期准备工作。作为安全领域的从业者,我深知专业数据的价…...

Spring AI:Java开发者的AI应用开发利器
Spring AI:Java开发者的AI应用开发利器 一、什么是Spring AI Spring AI是一个专为AI工程应用设计的AI应用程序框架,它将AI模型的能力集成到Spring生态系统之中。作为Spring家族的新成员,Spring AI秉承了Spring的设计理念,为Java…...